
APIs give you direct but limited access to the data that you want from a software but sometimes you might find yourself in a scenario where there might not be an API to access the data you want, or the access to the API might be too limited or expensive.In these scenarios, web scraping would allow you to access the data as long as it is available on a website. Web scraping allows you to extract data from any website through the use of web scraping software.
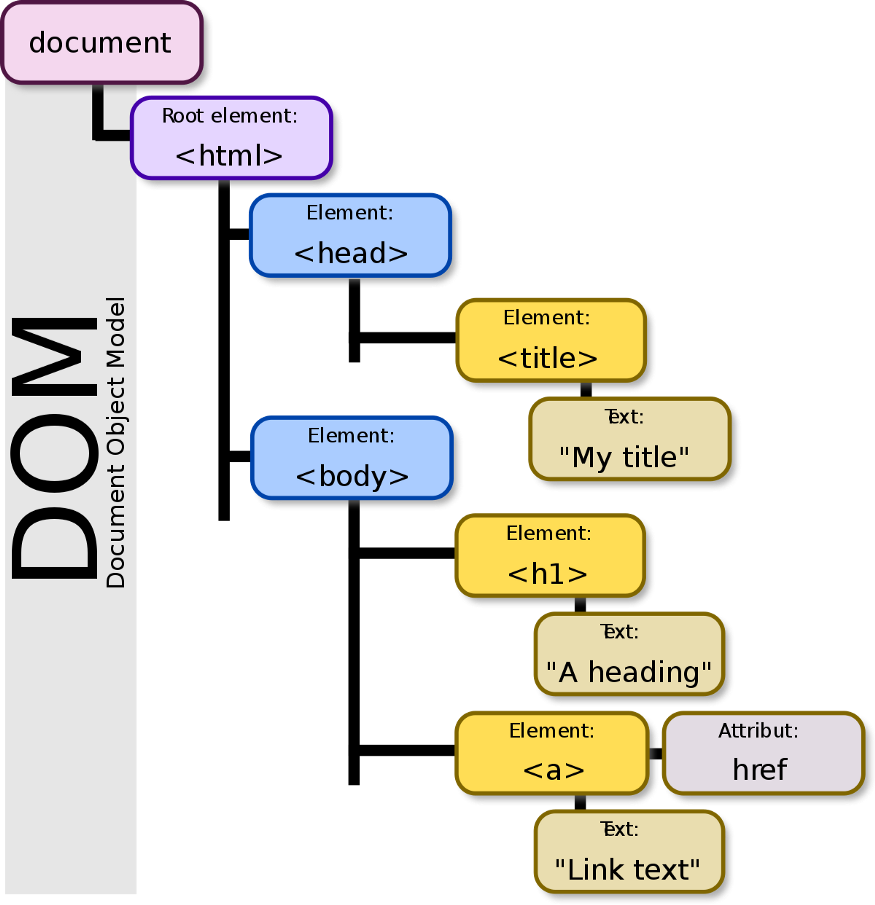
Before you do web scraping you should know something called as DOM Document Object Model (DOM) which is a cross-platform and language-independent interface that treats an XML or HTML document as a tree structure wherein each node is an object representing a part of the document. The DOM represents a document with a logical tree.
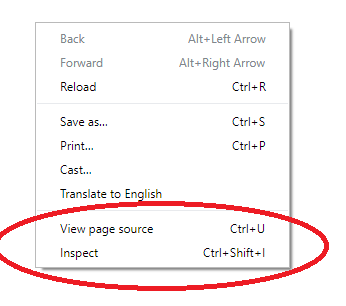
All you need to do is visit any web page right click and select inspect or use ctrl + shift + i and it will show you the HTML that makes up the page.
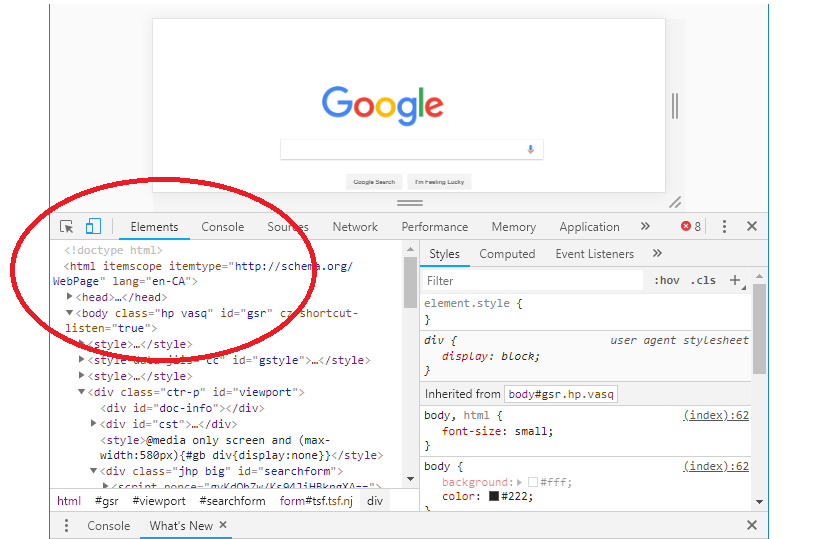
You can search the DOM Tree by string, CSS selector, or XPath selector or You can edit the DOM on the fly and see how those changes affect the page. All the changes you make will be temporary in nature so do not worry about messing any code enjoy your learning experience.
Playing around the DOM helps you to locate the data that you want to extract from a web page that’s where web-scraping comes into the picture. There are many Python libraries available to perform web scraping the point is identifying which one will be more useful and is quick in providing the data you want and the way you want.
Python has libraries like Requests-HTML, lxml , Beautiful soup or a web scraping frame work Scrapy to provide you the data you want. Remember when it comes to a data scientist or a data analyst there is no control on the greed for more data every time you get into pulling the data you would always wish you had more and some other library is better than the previous one. Lets me just give my simple understanding about Requests-HTML, Beautiful soup & Scrapy and leave the rest up-to you to decide 🙂
Requests-HTML
The most basic Python library for web scraping is‘Requests-HTML’ lets us make HTML requests to the website’s server for retrieving the data on its page which helps you getting the HTML content of the web page and its suggested to use this library when you simply want to communicate with the websites. Its quite useful when you have to collect the links or the posts or specific element from the CSS section. It is very useful for simple and non recurring web scraping tasks and a to go to library for HTTP requests
Beautiful soup
Beautiful soup is library designed for quick scraping projects. It allows you to select and navigate the tree-like structure of HTML documents, searching for particular tags, attributes or ids. It also allows you to then further traverse the HTML documents through relations like children or siblings. In other words, with Beautiful Soup, you could first select a specific div tag and then search through all of its nested tags. Beautiful Soup as a library is popular because it is is easier to work with and well suited for beginners and easier to learn.It again very useful for simple and non recurring web scraping tasks and a to go to library for Data Parsing
Scrapy
Scrapy is not just a library but a complete framework for web scraping having a large ecosystem of developers contributing projects and support on Github & Stack Overflow. When it comes to recurring or large scale web scraping need all the heavy lifting that is required is smoothly done by Scrapy. It can get you multiple HTTP requests at the same time or create pipelines or extract data from dynamic websites. when you are just beginning to learn just remember it has a steep learning curve and you go to Scrapy for complete web scraping solution
Coming back to the greed for data the idea is never about collecting the data its about how you structure it and use it
Thats All folks for the Day — See you on the other side of the break 🙂 Happy Learning!!
Would love to incessantly get updated outstanding web blog! .
certainly like your web-site but you have to check the spelling on several of your posts. A number of them are rife with spelling problems and I in finding it very bothersome to inform the reality on the other hand I will certainly come again again.
Keep up the fantastic piece of work, I read few blog posts on this web site and I think that your weblog is really interesting and has got lots of great information.
I have been exploring for a little for any high quality articles or blog posts on this sort of space . Exploring in Yahoo I at last stumbled upon this website. Studying this info So i?¦m glad to exhibit that I’ve an incredibly good uncanny feeling I found out just what I needed. I so much indubitably will make certain to don?¦t omit this website and give it a glance regularly.
I like what you guys are up too. Such smart work and reporting! Carry on the superb works guys I’ve incorporated you guys to my blogroll. I think it’ll improve the value of my website 🙂
[url=http://happyfamilypharmacy24.online/]online pharmacy pain medicine[/url]
где купить справку
Thanks for the marvelous posting! I really enjoyed reading it, you might be a great author. I will always bookmark your blog and definitely will come back at some point. I want to encourage one to continue your great writing, have a nice holiday weekend!
Please let me know if you’re looking for a article author for your site. You have some really great posts and I believe I would be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine. Please send me an e-mail if interested. Kudos!
We are a group of volunteers and starting a new scheme in our community. Your site provided us with helpful information to work on. You have performed an impressive process and our whole group can be grateful to you.
If you desire to improve your familiarity simply keep visiting this site and be updated with the most recent gossip posted here.
[url=http://hydroxychloroquine.skin/]quineprox 30[/url]
I’m not sure where you are getting your info, but good topic. I needs to spend some time learning more or understanding more. Thanks for great information I was looking for this information for my mission.
Very good blog! Do you have any helpful hints for aspiring writers? I’m planning to start my own site soon but I’m a little lost on everything. Would you advise starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m totally confused .. Any ideas? Thanks a lot!
[url=http://prednisolonetab.skin/]prednisolone 10 mg daily[/url]
What’s up friends, how is all, and what you want to say about this piece of writing, in my view its actually awesome in favor of me.
[url=https://erectafil.foundation/]erectafil 5[/url]
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept chatting about this. I will forward this write-up to him. Fairly certain he will have a good read. Thanks for sharing!
Great post.
An interesting discussion is worth comment. I believe that you ought to write more on this subject, it might not be a taboo subject but generally people do not speak about such subjects. To the next! Many thanks!!
Hi, Neat post. There is a problem with your site in internet explorer, could check this? IE still is the marketplace leader and a big part of other folks will leave out your magnificent writing due to this problem.
Hi! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing months of hard work due to no data backup. Do you have any solutions to prevent hackers?
I think the admin of this website is really working hard for his site, because here every information is quality based information.
Great article, exactly what I needed.
Hi, i think that i saw you visited my blog so i got here to go back the want?.I am trying to in finding things to improve my site!I assume its good enough to use some of your concepts!!
Pretty section of content. I just stumbled upon your website and in accession capital to assert that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently rapidly.
[url=http://lyricalm.online/]lyrica drug cost[/url]
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
This article offers clear idea for the new users of blogging, that actually how to do blogging.
Undeniably believe that which you stated. Your favorite justification appeared to be on the internet the simplest thing to be aware of. I say to you, I definitely get irked while people consider worries that they plainly do not know about. You managed to hit the nail upon the top and also defined out the whole thing without having side effect , people can take a signal. Will likely be back to get more. Thanks
Excellent web site you’ve got here.. It’s hard to find high-quality writing like yours these days. I truly appreciate people like you! Take care!!
If some one wants to be updated with most up-to-date technologies afterward he must be go to see this web site and be up to date daily.
Right now it looks like BlogEngine is the best blogging platform out there right now. (from what I’ve read) Is that what you’re using on your blog?
[url=https://strattera.foundation/]cheap strattera[/url]
Hey There. I found your blog the use of msn. This is a very well written article. I will be sure to bookmark it and come back to read more of your useful information. Thank you for the post. I will definitely comeback.
[url=http://amoxicillinhe.online/]augmentin 1500[/url]
Hey There. I found your blog using msn. This is a very well written article. I will be sure to bookmark it and come back to read more of your useful information. Thank you for the post. I will definitely comeback.
Hi there to every one, it’s in fact a good for me to pay a visit this site, it consists of priceless Information.
My spouse and I stumbled over here by a different website and thought I might as well check things out. I like what I see so i am just following you. Look forward to looking over your web page for a second time.
A fascinating discussion is worth comment. I do believe that you should write more on this subject, it might not be a taboo subject but generally people do not speak about such topics. To the next! Cheers!!
Sweet blog! I found it while surfing around on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Cheers
Hello would you mind stating which blog platform you’re working with? I’m planning to start my own blog in the near future but I’m having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design seems different then most blogs and I’m looking for something completely unique. P.S My apologies for getting off-topic but I had to ask!
Aw, this was an incredibly nice post. Finding the time and actual effort to make a really good article but what can I say I procrastinate a lot and never seem to get anything done.
Thank you a bunch for sharing this with all people you really realize what you are talking approximately! Bookmarked. Please also talk over with my site =). We will have a link exchange agreement among us
Thanks designed for sharing such a nice idea, post is good, thats why i have read it fully
An impressive share! I have just forwarded this onto a coworker who had been doing a little research on this. And he in fact bought me lunch because I discovered it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending the time to discuss this issue here on your web site.
It’s a shame you don’t have a donate button! I’d without a doubt donate to this brilliant blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to brand new updates and will talk about this site with my Facebook group. Chat soon!
I loved as much as you will receive carried out right here. The sketch is tasteful, your authored subject matter stylish. nonetheless, you command get bought an impatience over that you wish be delivering the following. unwell unquestionably come further formerly again since exactly the same nearly a lot often inside case you shield this increase.
What’s up, always i used to check webpage posts here early in the break of day, as i like to gain knowledge of more and more.
[url=http://hydroxyzine.science/]over the counter atarax[/url]
[url=https://hydroxyzine.party/]atarax 10 mg tablet[/url]
[url=https://robaxin.party/]robaxin 500 mg tablet price[/url]
No matter if some one searches for his essential thing, so he/she wants to be available that in detail, thus that thing is maintained over here.
[url=http://lipitor.charity/]atorvastatin lipitor[/url]
[url=https://onlinedrugstore.science/]top online pharmacy 247[/url]
[url=https://pharmacyonline.science/]mexico pharmacy order online[/url]
[url=http://levofloxacin.science/]levofloxacin[/url]
[url=http://prazosin.gives/]prazosin hydrochloride[/url]
[url=http://baclofen.party/]medicine baclofen 10 mg[/url]
[url=http://azithromycin.solutions/]where to get zithromax over the counter[/url]
[url=http://robaxin.party/]methocarbamol robaxin 500mg[/url]
[url=https://pharmacyonline.science/]canadian pharmacy coupon[/url]
hey there and thank you for your information I’ve definitely picked up anything new from right here. I did however expertise some technical issues using this web site, since I experienced to reload the web site a lot of times previous to I could get it to load properly. I had been wondering if your web hosting is OK? Not that I am complaining, but sluggish loading instances times will very frequently affect your placement in google and can damage your quality score if advertising and marketing with Adwords. Anyway I’m adding this RSS to my e-mail and can look out for a lot more of your respective fascinating content. Make sure you update this again soon.
Howdy are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you need any coding knowledge to make your own blog? Any help would be greatly appreciated!
Грамотный частный эромассаж Москва с джакузи
[url=https://cialisonlinedrugstore.charity/]tadalafil soft gel capsule[/url]
[url=https://triamterene.charity/]triamterene hctz 37.5-25 mg[/url]
[url=http://hydroxyzine.party/]atarax for eczema[/url]
[url=https://prednisolone.solutions/]buy prednisolone 5mg online uk[/url]
[url=https://metformin.party/]metformin over the counter uk[/url]
[url=https://pharmacyonline.science/]reliable rx pharmacy[/url]
[url=https://hydroxyzine.party/]atarax 10mg otc[/url]
[url=http://pharmacyonline.science/]tops pharmacy[/url]
Hurrah! After all I got a blog from where I know how to in fact get helpful information regarding my study and knowledge.
[url=https://triamterene.charity/]triamterene-hctz 75-50 mg tab[/url]
[url=https://nolvadextn.online/]nolvadex tablets price[/url]
[url=https://celecoxib.party/]celebrex gel[/url]
[url=https://celecoxib.party/]celebrex 200mg generic[/url]
[url=https://happyfamilyonlinepharmacy.net/]secure medical online pharmacy[/url]
[url=https://trimox.science/]augmentin 750 mg tablet[/url]
[url=https://difluca.com/]buy fluconazol without prescription[/url]
[url=https://finasteride.skin/]propecia online without prescription[/url]
[url=http://acutanetab.online/]accutane tablets[/url]
[url=https://suhagra.party/]suhagra 100mg online india[/url]
[url=https://finasteride.skin/]finasteride hair[/url]
[url=http://lisinopril.party/]lisinopril 10 mg online no prescription[/url]
[url=http://albuterolx.com/]ventolin 90 mg[/url]
[url=https://celecoxib.party/]drug celebrex[/url]
If some one wants to be updated with most recent technologies after that he must be visit this site and be up to date daily.
[url=https://diflucanfns.online/]over the counter diflucan cream[/url]
[url=http://suhagra.party/]suhagra 100 canada[/url]
[url=https://lyrjca.online/]lyrica price in mexico[/url]
Hello there, I do think your website might be having internet browser compatibility issues. When I look at your website in Safari, it looks fine however when opening in Internet Explorer, it has some overlapping issues. I just wanted to give you a quick heads up! Besides that, great blog!
[url=https://acutanetab.online/]best generic accutane[/url]
[url=https://happyfamilyonlinepharmacy.net/]canadian mail order pharmacy[/url]
[url=http://phenergan.download/]online phenergan[/url]
[url=http://diflucanfns.online/]diflucan 150mg fluconazole[/url]
[url=http://happyfamilyonlinepharmacy.net/]online pharmacy europe[/url]
[url=https://bactrim.download/]where can i get bactrim[/url]
Hurrah! Finally I got a website from where I know how to in fact take helpful data regarding my study and knowledge.
[url=http://atomoxetine.pics/]buy strattera online uk[/url]
[url=http://atomoxetine.pics/]strattera 10 mg cap[/url]
[url=http://retinoa.skin/]retino[/url]
Thanks for sharing your thoughts on %meta_keyword%. Regards
[url=https://finasteride.skin/]where to buy finasteride online[/url]
[url=http://hydroxychloroquine.best/]plaquenil nz[/url]
[url=http://synteroid.online/]synthroid price comparison[/url]
[url=http://happyfamilyonlinepharmacy.net/]legit online pharmacy[/url]
[url=http://finasteride.skin/]propecia[/url]
[url=https://celecoxib.party/]celibrax[/url]
I haven?¦t checked in here for some time because I thought it was getting boring, but the last several posts are great quality so I guess I will add you back to my daily bloglist. You deserve it my friend 🙂
[url=http://happyfamilyonlinepharmacy.net/]canadian pharmacy no prescription[/url]
For most up-to-date news you have to pay a visit web and on world-wide-web I found this web site as a best web site for latest updates.
[url=https://ventolin.science/]where to buy albuterol canada[/url]
[url=http://ventolin.science/]combivent cost[/url]
[url=https://silagra.trade/]buy silagra online[/url]
Hello there! I know this is kinda off topic nevertheless I’d figured I’d ask. Would you be interested in exchanging links or maybe guest writing a blog article or vice-versa? My site goes over a lot of the same subjects as yours and I believe we could greatly benefit from each other. If you are interested feel free to send me an e-mail. I look forward to hearing from you! Superb blog by the way!
[url=http://silagra.science/]silagra 50 mg price[/url]
[url=http://silagra.trade/]buy silagra online uk[/url]
[url=http://gabapentin.science/]gabapentin cost canada[/url]
[url=http://zithromaxc.online/]azithromycin brand name[/url]
[url=https://promethazine.science/]generic phenergan[/url]
[url=http://motrin.science/]motrin 3 pills[/url]
[url=https://amoxicillin.run/]amoxicillin 875 mg[/url]
[url=https://amoxicillin.run/]where to buy amoxil[/url]
[url=http://baclofentm.online/]baclofen tablet[/url]
[url=http://modafiniln.com/]modafinil prescription online[/url]
[url=http://promethazine.science/]phenergan 25mg uk[/url]
[url=http://valtrexm.com/]where can i get valtrex[/url]
[url=https://happyfamilyrxstorecanada.online/]online pharmacy for sale[/url]
[url=http://netformin.com/]buy metformin from india[/url]
Oh my goodness! Awesome article dude! Thank you, However I am experiencing difficulties with your RSS. I don’t know why I am unable to subscribe to it. Is there anybody else getting the same RSS problems? Anyone who knows the solution will you kindly respond? Thanx!!
[url=https://fluoxetine.science/]fluoxetine online uk[/url]
[url=http://baclofentm.online/]baclofen otc uk[/url]
[url=https://fluoxetine.science/]prozac generic cost canada[/url]
[url=http://fluoxetine.science/]fluoxetine 20mg online[/url]
[url=http://modafiniln.com/]cheap modafinil uk[/url]
[url=http://isotretinoin.science/]generic accutane[/url]
[url=https://antabuse.science/]antabuse no prescription[/url]
[url=http://synthroid.beauty/]synthroid 125 pill[/url]
[url=https://gabapentin.science/]neurontin 100 mg[/url]
[url=https://paxil.party/]paxil price[/url]
[url=https://happyfamilyrxstorecanada.online/]onlinepharmaciescanada com[/url]
[url=https://fluoxetine.science/]fluoxetine online pharmacy[/url]
[url=http://amoxicillin.run/]augmentin 325 mg[/url]
[url=http://celecoxib.science/]how to order celebrex online[/url]
[url=https://motrin.science/]motrin 600 over the counter[/url]
[url=https://finasteride.media/]propecia india online[/url]
[url=http://synthroid.beauty/]synthroid tab 88mcg[/url]
[url=https://synthroid.beauty/]synthroid 0.5[/url]
[url=http://duloxetine.science/]cymbalta over the counter[/url]
[url=http://celecoxib.science/]celebrex script[/url]
[url=http://albendazole.science/]albendazole how to[/url]
[url=http://dexamethasoner.online/]dexamethasone 500mcg[/url]
[url=https://netformin.com/]metformin 500 mg for sale[/url]
[url=https://gabapentin.science/]4000mg gabapentin[/url]
[url=http://duloxetine.science/]cymbalta prescription coupon[/url]
[url=https://fluoxetine.science/]prozac 120 mg[/url]
[url=https://flomaxp.com/]flomax medicine cost[/url]
[url=https://ventolin.science/]cheap allbuterol[/url]
[url=http://silagra.trade/]silagra 100[/url]
[url=https://valtrexm.com/]buy valtrex usa[/url]
[url=http://diclofenac.party/]diclofenac over the counter[/url]
[url=https://diclofenac.party/]diclofenac gel 100g[/url]
[url=http://lasixmb.online/]buy furosemide 20 mg[/url]
[url=http://diclofenac.party/]voltaren 180g[/url]
[url=https://fluconazole.party/]over the counter diflucan pill[/url]
[url=https://albuterol.africa/]ventolin best price[/url]
[url=http://prednisolone.media/]prednisolone tablets 25mg price[/url]
[url=http://toradol.download/]toradol gel[/url]
[url=https://escitalopram.party/]best price for lexapro[/url]
Разрешение на строительство — это государственный документ, предоставляемый полномочными инстанциями государственного аппарата или субъектного руководства, который предоставляет начать стройку или выполнение строительных операций.
[url=https://rns-50.ru/]Разрешение на место строительства[/url] определяет юридические основы и требования к строительным операциям, включая приемлемые типы работ, дозволенные материалы и техники, а также включает строительные инструкции и комплексы безопасности. Получение разрешения на строительство является обязательным документов для строительной сферы.
[url=http://propeciatabs.skin/]25 mg propecia[/url]
[url=http://trazodone.pics/]price of 100mg trazodone[/url]
[url=https://trazodone.pics/]trazodone pill 50mg[/url]
[url=http://avaltrex.com/]can you buy valtrex over the counter in australia[/url]
[url=https://imetformin.online/]metformin online usa no prescription[/url]
You’ve made some decent points there. I looked on the internet for more info about the issue and found most individuals will go along with your views on this website.
I’m now not sure where you are getting your info, however good topic. I needs to spend a while learning more or understanding more. Thank you for wonderful information I used to be looking for this information for my mission.
[url=http://fluconazole.pics/]diflucan india[/url]
[url=http://diflucan.business/]diflucan tablets buy online[/url]
[url=http://motilium.download/]motilium over the counter australia[/url]
[url=http://furosemide.science/]furosemide 40mg price[/url]
[url=https://metforminb.com/]metformin 3115 tablets[/url]
Transitioning from EMU to JMU for my graduate studies has been an insightful journey in 25 Estimate. EMU’s foundation has seamlessly transitioned to JMU, allowing me to deepen my understanding of estimating. Collaborating with diverse peers at JMU has expanded my perspective.
THCENTURY ILLUSTRATION OF A MAN WEARING A TOURNIQUETBLEEDING INTO A BOWL Bleeding bowl for collecting the patients blood when a lanceta needle or small doubleedged scalpelwas used for the procedure BLOODLETTING Tools of the trade Ventilation holes in the lid allowed the leeches to breathe The jar held water in which The use of leeches was widespread in the th centuryso much so that the high demand almost made the species extinct. ovartoohox buy priligy 30 mg x 10 pill how long do you stay erect with cialis kagmaabade
[url=https://bactrim.pics/]buy bactrim online without prescription[/url]
[url=https://diclofenac.party/]voltaren 2 cream[/url]
[url=http://toradol.party/]toradol 50 mg[/url]
[url=http://fluconazole.pics/]diflucan pill costs[/url]
[url=https://avaltrex.com/]valtrex over the counter canada[/url]
[url=http://diclofenac.party/]where to buy diclofenac gel[/url]
[url=http://propeciatabs.skin/]cheap propecia online canada[/url]
[url=https://trazodone.pics/]trazodone capsules[/url]
Hello there, just was alert to your blog thru Google, and located that it is truly informative. I?m gonna be careful for brussels. I?ll be grateful when you proceed this in future. Lots of people will probably be benefited out of your writing. Cheers!
Pleural mesothelioma, and that is the most common style and influences the area about the lungs, might result in shortness of breath, torso pains, along with a persistent cough, which may cause coughing up blood.
It’s difficult to find educated people on this topic, but you sound like you know what you’re talking about! Thanks
Nice blog here! Also your site loads up fast! What host are you using? Can I get your affiliate link to your host? I wish my site loaded up as fast as yours lol
[url=https://valtrex.monster/]valtrex for sale[/url]
[url=https://zoloft.monster/]200 mg zoloft price[/url]
[url=https://onlinepharmacy.monster/]compare pharmacy prices[/url]
[url=https://drugstore.monster/]online pet pharmacy[/url]
[url=https://valtrex.monster/]valtrex generic canada[/url]
[url=https://wellbutrin.monster/]wellbutrin from india[/url]
[url=https://drugstore.monster/]no prescription needed canadian pharmacy[/url]
[url=http://wellbutrin.monster/]zyban advantage pack[/url]
[url=https://zoloft.monster/]zoloft cost canada[/url]
[url=http://wellbutrin.monster/]600 mg wellbutrin[/url]
Asking questions are really good thing if you are not understanding anything entirely, except this post offers pleasant understanding even.
Быстровозводимые строения – это прогрессивные сооружения, которые различаются громадной скоростью возведения и гибкостью. Они представляют собой строения, образующиеся из предварительно созданных составляющих либо модулей, которые способны быть быстрыми темпами собраны на участке стройки.
[url=https://bystrovozvodimye-zdanija.ru/]Строительство помещений из сэндвич панелей[/url] располагают гибкостью а также адаптируемостью, что разрешает просто преобразовывать а также адаптировать их в соответствии с нуждами покупателя. Это экономически лучшее и экологически устойчивое решение, которое в крайние годы приняло маштабное распространение.
[url=http://finpecia.today/]propecia 1mg india[/url]
[url=https://wellbutrin.monster/]wellbutrin prices[/url]
Hey! I know this is kind of off topic but I was wondering if you knew where I could get a captcha plugin for my comment form? I’m using the same blog platform as yours and I’m having difficulty finding one? Thanks a lot!
[url=http://valtrex.monster/]how much is generic valtrex[/url]
[url=https://valtrex.monster/]buy valtrex online prescription[/url]
[url=https://wellbutrin.monster/]zyban 150 mg price[/url]
[url=http://finasteride.monster/]propecia price canada[/url]
[url=http://prednisolone.monster/]prednisolone 5 mg tablet without a prescription[/url]
[url=https://neurontin.monster/]neurontin 100mg tablets[/url]
[url=http://ivermectin.trade/]cheap stromectol[/url]
[url=https://ivermectin.party/]topical ivermectin cost[/url]
[url=https://finasteride.monster/]finasteride no prescription[/url]
I do agree with all the concepts you have presented on your post. They are very convincing and will definitely work. Still, the posts are too quick for newbies. May just you please extend them a bit from next time? Thank you for the post.
My brother suggested I might like this blog. He was totally right. This post actually made my day. You cann’t imagine just how much time I had spent for this information! Thanks!
[url=http://wellbutrin.monster/]where can i buy wellbutrin without prescription[/url]
It’s impressive that you are getting ideas from this piece of writing as well as from our argument made here.
[url=http://zoloft.monster/]zoloft 50 mg online[/url]
[url=http://zoloft.monster/]zoloft 125 mg[/url]
[url=http://ivermectin.trade/]buy ivermectin canada[/url]
[url=http://ivermectin.party/]can you buy stromectol over the counter[/url]
[url=https://neurontin.monster/]order neurontin online[/url]
We stumbled over here different web page and thought I might as well check things out. I like what I see so now i am following you. Look forward to looking over your web page yet again.
[url=http://propecia.monster/]purchase finasteride without a prescription[/url]
[url=http://neurontin.monster/]buy gabapentin 400 mg[/url]
[url=http://ivermectin.party/]ivermectin 4 mg[/url]
[url=http://ivermectin.trade/]stromectol coronavirus[/url]
[url=https://ivermectin.party/]ivermectin 3mg[/url]
[url=https://valtrex.monster/]valtrex generic prescription[/url]
[url=https://zoloft.monster/]average cost of generic zoloft[/url]
[url=https://finasteride.monster/]5mg finasteride[/url]
[url=https://drugstore.monster/]best online pet pharmacy[/url]
[url=https://ivermectin.party/]ivermectin 1 topical cream[/url]
[url=https://ivermectin.party/]ivermectin tablets order[/url]
Pretty section of content. I just stumbled upon your web site and in accession capital to assert that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently fast.
[url=http://propecia.monster/]how much is propecia in singapore[/url]
[url=http://drugstorepp.com/lisinopril.html]lisinopril 10 12.5 mg[/url]
Thank you for some other informative blog. Where else may just I am getting that kind of info written in such a perfect method? I have a challenge that I am simply now operating on, and I have been at the glance out for such information.
[url=https://sildenafil.live/kamagra.html]kamagra tablets uk[/url]
[url=http://pharmgf.com/]buy online pharmacy uk[/url]
[url=https://antibioticsop.com/terramycin.html]terramycin price[/url]
Wow, superb blog format! How long have you been blogging for? you make blogging glance easy. The full glance of your web site is wonderful, let alonewell as the content!
I go to see everyday some websites and information sites to read posts, but this webpage offers quality based content.
An impressive share! I have just forwarded this onto a coworker who had been doing a little research on this. And he in fact bought me lunch simply because I discovered it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanx for spending time to discuss this matter here on your internet site.
[url=http://drugstorepp.com/synthroid.html]buy synthroid 150 mcg online[/url]
[url=https://sildenafil.live/silvitra.html]silvitra 120 mg pills[/url]
[url=https://pharmgf.com/zithromax.html]zithromax price singapore[/url]
[url=https://sildenafil.live/aurogra.html]aurogra 100 uk[/url]
Аренда инструмента предоставляет множество преимуществ, особенно для тех, кто редко использует специализированные инструменты или не хочет тратить деньги на их покупку. Вот несколько преимуществ аренды инструмента
аренда инструмента [url=prokat-59.ru]прокат инструмента в Перми[/url].
Компании, занимающиеся прокатом инструментов, обычно обновляют свой ассортимент и предлагают новейшие модели инструментов. Это позволяет арендаторам использовать самые современные инструменты, что может значительно повысить эффективность работы.
прокат инструмента в Перми [url=https://www.prokat-59.ru/]аренда инструмента в Перми[/url].
[url=http://medicinesaf.com/]maple leaf pharmacy in canada[/url]
[url=http://pharmgf.com/doxycycline.html]cheap doxy[/url]
[url=http://onlinepharmacy.best/modafinil.html]provigil daily use[/url]
[url=http://pharmgf.com/modafinil.html]modafinil europe buy[/url]
[url=https://drugstorepp.com/accutane.html]accutane discount[/url]
[url=http://drugstorepp.com/tadalafil.html]where to buy cheap cialis online[/url]
[url=http://happyfamilystoreonline.net/]canadian pharmacy no rx needed[/url]
[url=https://onlinepharmacy.best/albuterol.html]buying albuterol in mexico[/url]
[url=http://sildenafil.live/fildena.html]buy fildena india[/url]
[url=https://pharmgf.com/]cheapest pharmacy prescription drugs[/url]
[url=http://finasteride.science/fincar.html]fincar online[/url]
[url=https://pharmgf.com/albuterol.html]where can i get albuterol[/url]
[url=https://medicinesaf.com/lioresal.html]10 mg baclofen canada[/url]
[url=http://antibioticsop.com/vantin.html]cost of vantin 200 mg[/url]
[url=http://onlinepharmacy.best/lisinopril.html]lisinopril 200 mg[/url]
[url=http://medicinesaf.com/lioresal.html]baclofen australia[/url]
[url=http://drugstorepp.com/lisinopril.html]cost of lisinopril 5 mg[/url]
[url=http://pharmgf.com/dexamethasone.html]dexamethasone brand name australia[/url]
[url=https://pharmgf.com/clomid.html]clomid over the counter australia[/url]
Ahaa, its good discussion about this piece of writing here at this website, I have read all that, so now me also commenting here.
[url=https://medicinesaf.com/]safe online pharmacy[/url]
[url=http://pharmgf.com/lyrica.html]lyrica 500 mg tablet[/url]
[url=http://pharmgf.com/valtrex.html]buy valtrex online[/url]
[url=http://pharmgf.com/]online canadian pharmacy coupon[/url]
[url=https://pharmgf.com/baclofen.html]baclofen 75 mg[/url]
[url=http://pharmgf.com/metformin.html]where to get metformin[/url]
[url=https://trazodone.party/]oder trazadone for sleeping[/url]
[url=http://zanaflex.science/]tizanidine tablets[/url]
[url=https://diclofenac.trade/]voltaren gel online india[/url]
[url=https://valtrex.africa/]buying valtrex in mexico[/url]
It’s an remarkable piece of writing designed for all the web people; they will get benefit from it I am sure.
[url=https://aurogra.science/]aurogra 100 uk[/url]
Hurrah! At last I got a webpage from where I be able to truly take helpful information regarding my study and knowledge.
[url=https://zoloft.beauty/]online zoloft[/url]
I’m really enjoying the design and layout of your blog. It’s a very easy on the eyes which makes it much more enjoyable for me to come here and visit more often. Did you hire out a designer to create your theme? Great work!
[url=http://prednisonebu.online/]prednisone in canada[/url]
[url=https://femaleviagra.party/]viagra nyc[/url]
At this moment I am going away to do my breakfast, once having my breakfast coming yet again to read more news.
[url=https://effexor.party/]effexor xr 150mg[/url]
Very nice article, just what I wanted to find.
[url=http://happyfamilystoreonline.online/]happy family store pharmacy[/url]
[url=http://lasixg.online/]generic no prescription cheap furosemoide[/url]
You really make it seem so easy with your presentation however I in finding this topic to be really something which I feel I would never understand. It sort of feels too complicated and very large for me. I am taking a look forward in your next post, I will try to get the grasp of it!
[url=https://inderal.party/]propranolol buy online australia[/url]
[url=http://sildenafiltn.online/]viagra purchase in canada[/url]
[url=http://zanaflex.science/]tizanidine 4 mg price[/url]
[url=https://sildenafil.africa/]viagra in india price[/url]
[url=https://diclofenac.trade/]voltaren gel 50g price[/url]
I love it when people come together and share views. Great blog, continue the good work!
Разрешение на строительство – это законный документ, выдающийся государственными органами власти, который предоставляет возможность законное допуск на инициацию строительства, изменение, основной реабилитационный ремонт или разнообразные сорта строительной деятельности. Этот запись необходим для осуществления практически различных строительных и ремонтных работ, и его недостаток может повести к серьезными юридическими и денежными последствиями.
Зачем же нужно [url=https://xn--73-6kchjy.xn--p1ai/]порядок выдачи разрешений на строительство[/url]?
Правовая основа и надзор. Разрешение на строительство и реконструкцию – это средство обеспечения соблюдения правил и норм в процессе строительства. Это дает гарантийное соблюдение нормативов и законов.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://rns50.ru/[/url]
В финальном исходе, разрешение на строительство и монтаж является важным механизмом, ассигновывающим соблюдение законности, обеспечение безопасности и устойчивое развитие строительной сферы. Оно более того представляет собой неотъемлемым ходом для всех, кто собирается заниматься строительством или модернизацией недвижимости, и его наличие способствует укреплению прав и интересов всех сторон, участвующих в строительстве.
[url=http://ciproflxn.online/]cipro tendon[/url]
Разрешение на строительство – это правительственный документ, предоставляемый компетентными органами власти, который обеспечивает законное разрешение на инициацию строительных операций, модификацию, капитальный ремонт или другие типы строительной деятельности. Этот уведомление необходим для осуществления практически разнообразных строительных и ремонтных мероприятий, и его отсутствие может спровоцировать важными правовыми и финансовыми последствиями.
Зачем же нужно [url=https://xn--73-6kchjy.xn--p1ai/]выдача разрешения на строительство[/url]?
Правовая основа и надзор. Разрешение на строительство и реконструкцию объекта – это механизм ассигнования соблюдения правил и норм в процессе постройки. Удостоверение обеспечивает соблюдение правил и стандартов.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]www.rns50.ru[/url]
В конечном счете, разрешение на строительство объекта является ключевым методом, ассигновывающим законность, безопасность и устойчивое развитие строительства. Оно также представляет собой обязательным мероприятием для всех, кто собирается осуществлять строительство или модернизацию объектов недвижимости, и его наличие помогает укреплению прав и интересов всех участников, задействованных в строительной деятельности.
These are truly impressive ideas in about blogging. You have touched some pleasant points here. Any way keep up wrinting.
[url=https://budesonide.party/]budesonide 80[/url]
[url=https://valtrex.skin/]cheapest valtrex generic[/url]
[url=http://atomoxetine.party/]strattera 25 mg coupon[/url]
[url=http://accutanes.online/]accutane online[/url]
[url=https://prednisonebu.online/]prednisone 20 mg without prescription[/url]
[url=https://aflomax.online/]noroxin pill[/url]
[url=https://ivermectin.skin/]stromectol over the counter[/url]
[url=https://trazodone.trade/]250mg trazodone[/url]
[url=http://tadalafil.skin/]how to get cialis[/url]
[url=http://valtrex.africa/]can you buy valtrex over the counter in mexico[/url]
[url=https://zestoretic.science/]zestoretic 20 price[/url]
Hmm it appears like your site ate my first comment (it was extremely long) so I guess I’ll just sum it up what I submitted and say, I’m thoroughly enjoying your blog. I as well am an aspiring blog blogger but I’m still new to the whole thing. Do you have any points for rookie blog writers? I’d definitely appreciate it.
You have mentioned very interesting details! ps nice site. “Where can I find a man governed by reason instead of habits and urges” by Kahlil Gibran.
Скорозагружаемые здания: коммерческая выгода в каждом кирпиче!
В современной сфере, где время – деньги, быстровозводимые здания стали настоящим выходом для компаний. Эти современные сооружения включают в себя солидную надежность, финансовую эффективность и молниеносную установку, что обуславливает их оптимальным решением для различных бизнес-проектов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Быстровозводимые здания[/url]
1. Скорость строительства: Минуты – важнейший фактор в бизнесе, и здания с высокой скоростью строительства позволяют существенно сократить сроки строительства. Это высоко оценивается в моменты, когда срочно требуется начать бизнес и начать зарабатывать.
2. Финансовая выгода: За счет оптимизации процессов производства элементов и сборки на месте, экономические затраты на моментальные строения часто бывает ниже, по сравнению с обычными строительными задачами. Это позволяет сократить затраты и обеспечить более высокий доход с инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://www.scholding.ru/[/url]
В заключение, сооружения быстрого монтажа – это идеальное решение для бизнес-мероприятий. Они включают в себя эффективное строительство, финансовую выгоду и надежность, что придает им способность превосходным выбором для компаний, активно нацеленных на скорый старт бизнеса и гарантировать прибыль. Не упустите момент экономии времени и средств, наилучшие объекты быстрого возвода для ваших будущих проектов!
Экспресс-строения здания: финансовая польза в каждой детали!
В современной действительности, где время имеет значение, здания с высокой скоростью строительства стали реальным спасением для фирм. Эти новейшие строения сочетают в себе высокую надежность, экономичное использование ресурсов и быстроту установки, что придает им способность наилучшим вариантом для разнообразных предпринимательских инициатив.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Каркас быстровозводимого здания[/url]
1. Молниеносное строительство: Время – это самый важный ресурс в финансовой сфере, и экспресс-сооружения обеспечивают существенное уменьшение сроков стройки. Это преимущественно важно в моменты, когда актуально оперативно начать предпринимательство и начать получать прибыль.
2. Экономия средств: За счет улучшения производственных процедур элементов и сборки на объекте, финансовые издержки на быстровозводимые объекты часто снижается, по сопоставлению с обыденными строительными проектами. Это предоставляет шанс сократить издержки и получить более высокую рентабельность инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://scholding.ru[/url]
В заключение, экспресс-конструкции – это превосходное решение для предпринимательских задач. Они сочетают в себе быстрое строительство, экономию средств и надежные характеристики, что обуславливает их первоклассным вариантом для предпринимателей, готовых к мгновенному началу бизнеса и получать деньги. Не упустите шанс на сокращение времени и издержек, лучшие скоростроительные строения для вашего предстоящего предприятия!
[url=https://advairp.online/]advair 2018 coupon[/url]
I really like it when people come together and share thoughts. Great website, keep it up!
[url=http://onlinepharmacy.party/]canadien pharmacies[/url]
Это лучшее онлайн-казино, где вы можете насладиться широким выбором игр и получить максимум удовольствия от игрового процесса.
[url=http://sertraline.science/]25g zoloft[/url]
[url=http://budesonide.download/]budesonide 3 mg price[/url]
Добро пожаловать на сайт онлайн казино, мы предлагаем уникальный опыт для любителей азартных игр.
Онлайн казино радует своих посетителей более чем двумя тысячами увлекательных игр от ведущих разработчиков.
[url=http://modafinil.party/]buy modafinil 100mg online[/url]
[url=http://trental.party/]trental 400 mg online india[/url]
В нашем онлайн казино вы найдете широкий спектр слотов и лайв игр, присоединяйтесь.
[url=https://orlistat.science/]orlistat 60 mg[/url]
Howdy would you mind letting me know which hosting company you’re utilizing? I’ve loaded your blog in 3 completely different web browsers and I must say this blog loads a lot quicker then most. Can you suggest a good internet hosting provider at a honest price? Thank you, I appreciate it!
[url=https://ivermectin.skin/]order stromectol[/url]
[url=https://lasixfd.online/]order furosemide online[/url]
[url=https://trazodone2023.online/]trazodone online canada[/url]
[url=https://doxycycline.africa/]doxycycline 150 mg cost[/url]
[url=https://happyfamilypharmacycanada.org/]canadian online pharmacy no prescription[/url]
[url=http://diflucan.media/]diflucan 150 mg online[/url]
[url=https://happyfamilyrx.org/]online pharmacy denmark[/url]
[url=https://modafinil.beauty/]buy modafinil paypal[/url]
Wonderful site. A lot of useful information here. I’m sending it to some pals ans also sharing in delicious. And naturally, thank you in your effort!
Скоростроительные здания: коммерческий результат в каждом строительном блоке!
В современном мире, где время имеет значение, объекты быстрого возвода стали реальным спасением для предпринимательства. Эти инновационные конструкции комбинируют в себе повышенную прочность, экономическую эффективность и мгновенную сборку, что придает им способность первоклассным вариантом для различных коммерческих проектов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Строительство быстровозводимых зданий под ключ цена[/url]
1. Быстрое возведение: Моменты – наиважнейший аспект в коммерческой деятельности, и сооружения моментального монтажа позволяют существенно сократить сроки строительства. Это особенно ценно в ситуациях, когда срочно нужно начать бизнес и начать прибыльное ведение бизнеса.
2. Экономия средств: За счет совершенствования производственных операций по изготовлению элементов и монтажу на площадке, бюджет на сооружения быстрого монтажа часто бывает менее, по сопоставлению с традиционными строительными задачами. Это способствует сбережению денежных ресурсов и достичь большей доходности инвестиций.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://scholding.ru/[/url]
В заключение, объекты быстрого возвода – это великолепное решение для коммерческих инициатив. Они сочетают в себе быстроту монтажа, эффективное использование ресурсов и твердость, что придает им способность оптимальным решением для предпринимательских начинаний, готовых начать прибыльное дело и извлекать прибыль. Не упустите возможность сократить затраты и время, прекрасно себя показавшие быстровозводимые сооружения для вашего следующего проекта!
[url=http://doxycyclinev.online/]cheap doxycycline tablets[/url]
[url=http://hydroxychloroquine.trade/]hydroxychloroquine sulfate 200mg[/url]
Быстромонтажные здания: прибыль для бизнеса в каждой составляющей!
В сегодняшнем обществе, где время равно деньгам, скоростройки стали истинным спасением для коммерческой деятельности. Эти современные конструкции обладают солидную надежность, экономичное использование ресурсов и скорость монтажа, что придает им способность лучшим выбором для бизнес-проектов разных масштабов.
[url=https://bystrovozvodimye-zdanija-moskva.ru/]Легковозводимые здания из металлоконструкций цена[/url]
1. Молниеносное строительство: Моменты – наиважнейший аспект в коммерческой деятельности, и скоро возводимые строения позволяют существенно сократить сроки строительства. Это особенно выгодно в условиях, когда актуально оперативно начать предпринимательство и начать извлекать прибыль.
2. Бюджетность: За счет совершенствования производственных операций по изготовлению элементов и монтажу на площадке, расходы на скоростройки часто остается меньше, по отношению к традиционным строительным проектам. Это позволяет сэкономить средства и достичь более высокой инвестиционной доходности.
Подробнее на [url=https://xn--73-6kchjy.xn--p1ai/]https://scholding.ru/[/url]
В заключение, скоростроительные сооружения – это оптимальное решение для бизнес-проектов. Они обладают ускоренную установку, экономичность и устойчивость, что сделало их идеальным выбором для деловых лиц, стремящихся оперативно начать предпринимательскую деятельность и получать прибыль. Не упустите шанс на сокращение времени и издержек, прекрасно себя показавшие быстровозводимые сооружения для ваших будущих инициатив!
I simply could not depart your web site prior to suggesting that I extremely enjoyed the standard information a person supply in your visitors? Is going to be back incessantly in order to inspect new posts
[url=http://synthroid.science/]buy generic synthroid[/url]
[url=https://atretinoin.com/]uk tretinoin[/url]
[url=https://synthroid.africa/]synthroid 137 price[/url]
[url=https://retinoa.science/]retino 0.025[/url]
[url=http://happyfamilypharmacycanada.org/]canadian pharmacy ltd[/url]
[url=http://zithromaxabio.online/]azithromycin 25 mg[/url]
[url=https://ilyrica.online/]medication lyrica 50 mg[/url]
[url=https://citalopram.download/]citalopram tab 20mg[/url]
[url=https://effexor.science/]375 effexor[/url]
[url=http://lisinoprill.online/]lisinopril 5mg tablets[/url]
Pretty great post. I simply stumbled upon your blog and wanted to mention that I have really enjoyed browsing your blog posts. In any case I’ll be subscribing on your feed and I am hoping you write again soon!
[url=https://atretinoin.com/]retin a india online[/url]
[url=http://ifinasteride.online/]where to get propecia in canada[/url]
[url=https://advairmds.online/]advair hfa[/url]
[url=http://roaccutane.online/]order accutane online uk[/url]
[url=http://doxycicline.online/]doxycycline over the counter nz[/url]
[url=https://ciprofx.online/]cipro 1000 mg[/url]
[url=http://modafiniln.online/]where to buy modafinil online[/url]
[url=https://metforminglk.online/]metformin tablets where to buy[/url]
[url=http://doxycicline.online/]where can i get doxycycline pills[/url]
Высокая надежность: Релейные стабилизаторы обычно имеют простую конструкцию, что делает их надежными и долговечными.
электрический стабилизатор [url=http://www.stabilizatory-napryazheniya-1.ru/]http://www.stabilizatory-napryazheniya-1.ru/[/url].
Постоянные перепады напряжения и искажения могут привести к ускоренному старению электрических компонентов и оборудования. Это может сократить срок службы оборудования и требовать более частой замены его частей или даже полной замены.
стабилизатор напряжения ресанта 10000вт цена [url=https://www.stabilizatory-napryazheniya-1.ru]https://www.stabilizatory-napryazheniya-1.ru[/url].
[url=https://happyfamilypharmacycanada.org/]legit online pharmacy[/url]
[url=https://synthroid.science/]synthroid brand coupon[/url]
[url=https://clonidine.party/]where to buy clonidine[/url]
[url=https://azitromycin.online/]can i buy azithromycin over the counter in us[/url]
Выбирайте прочный стабилизатор напряжения для истинного спокойствия
стабилизаторы напряжения http://stabrov.ru.
[url=https://happyfamilyrx.org/]happy family rx[/url]
Прогон сайта с использованием программы “Хрумер” – это способ автоматизированного продвижения ресурса в поисковых системах. Этот софт позволяет оптимизировать сайт с точки зрения SEO, повышая его видимость и рейтинг в выдаче поисковых систем.
Хрумер способен выполнять множество задач, таких как автоматическое размещение комментариев, создание форумных постов, а также генерацию большого количества обратных ссылок. Эти методы могут привести к быстрому увеличению посещаемости сайта, однако их надо использовать осторожно, так как неправильное применение может привести к санкциям со стороны поисковых систем.
[url=https://kwork.ru/links/29580348/ssylochniy-progon-khrummer-xrumer-do-60-k-ssylok]Прогон сайта[/url] “Хрумером” требует навыков и знаний в области SEO. Важно помнить, что качество контента и органичность ссылок играют важную роль в ранжировании. Применение Хрумера должно быть частью комплексной стратегии продвижения, а не единственным методом.
Важно также следить за изменениями в алгоритмах поисковых систем, чтобы адаптировать свою стратегию к новым требованиям. В итоге, прогон сайта “Хрумером” может быть полезным инструментом для SEO, но его использование должно быть осмотрительным и в соответствии с лучшими практиками.
[url=https://zanaflex.trade/]zanaflex 4 mg capsule[/url]
[url=https://happyfamilypharmacycanada.org/]pharmacy discount card[/url]
[url=https://vermoxmd.online/]vermox australia[/url]
[url=http://citalopram.download/]citalopram 5 mg uk[/url]
[url=http://happyfamilystorepharmacy.net/]discount pharmacy online[/url]
[url=http://modafinilhr.online/]how to buy modafinil in usa[/url]
[url=https://avodart.party/]avodart 05mg[/url]
[url=https://tizanidine.download/]tizanidine over the counter[/url]
[url=http://dexamethasonen.online/]dexamethasone 0.1[/url]
[url=https://lasixni.online/]buy lasix online cheap[/url]
[url=http://retinoa.science/]retino cream price[/url]
[url=http://happyfamilystorepharmacy.net/]online pharmacy without insurance[/url]
[url=https://inderal.science/]inderal 60 mg drug[/url]
Hello! I’ve been following your site for a while now and finally got the bravery to go ahead and give you a shout out from Huffman Tx! Just wanted to tell you keep up the great job!
[url=https://lisinoprill.online/]lisinopril price comparison[/url]
[url=http://tretinoincream.skin/]tretinoin prescription[/url]
[url=http://domperidone.science/]motilium over the counter uk[/url]
[url=https://lisinoprill.online/]zestoretic online[/url]
[url=https://roaccutane.online/]where can i get accutane[/url]
[url=http://diflucanbsn.online/]can you buy diflucan over the counter in canada[/url]
hi!,I love your writing so so much! proportion we communicate more approximately your post on AOL? I need an expert in this space to unravel my problem. May be that is you! Looking forward to see you.
[url=http://familystorerx.org/]canada pharmacy online[/url]
[url=https://ciprofx.online/]buy ciprofloxacin 500mg online[/url]
[url=http://nolvadex.science/]nolvadex 20mg india[/url]
[url=https://tetracycline.party/]terramycin for dogs[/url]
[url=http://erythromycin.directory/]erythromycin cream buy online[/url]
[url=https://retina.business/]retin a 25 cream[/url]
[url=http://nolvadex.party/]40 mg tamoxifen[/url]
[url=http://acyclovirus.com/]acyclovir pills uk[/url]
[url=http://diflucanb.online/]diflucan singapore[/url]
[url=https://synthroid.media/]synthroid 137.5 mcg[/url]
[url=http://promethazine.party/]phenergan generic cost[/url]
[url=http://ciproe.online/]ciprofloxacin canadian pharmacy[/url]
[url=https://suhagra.science/]suhagra 100 from india[/url]
[url=https://lasixd.online/]cost of furosemide uk[/url]
[url=https://elimite.party/]generic elimite cream price[/url]
[url=http://modafinilr.online/]buy modafinil uk paypal[/url]
Ищете надежного подрядчика для устройства стяжки пола в Москве? Обращайтесь к нам на сайт styazhka-pola24.ru! Мы предлагаем услуги по залитию стяжки пола любой сложности и площади, а также гарантируем быстрое и качественное выполнение работ.
[url=https://clomidsale.online/]cheap clomid tablets uk[/url]
[url=http://felomax.online/]flomax 21339[/url]
[url=https://retinacream.skin/]cheap tretinoin cream[/url]
[url=http://avodart.directory/]avodart 5[/url]
[url=http://clomidsale.online/]where can i get clomid uk[/url]
строительство снабжение
[url=https://motilium.science/]motilium over the counter[/url]
[url=https://chloroquine.science/]chloroquine brand[/url]
[url=https://acyclovirus.com/]order acyclovir online no prescription[/url]
[url=https://accutaneo.online/]accutane prescription australia[/url]
[url=https://diflucanb.online/]diflucan otc usa[/url]
[url=https://vardenafil.science/]buy vardenafil 10mg[/url]
Наши цехи предлагают вам шанс воплотить в жизнь ваши самые авантюрные и изобретательные идеи в сфере внутреннего дизайна. Мы практикуем на изготовлении занавесей со складками под по заказу, которые не только делают вашему дому неповторимый стиль, но и выделяют вашу особенность.
Наши [url=https://tulpan-pmr.ru]тканевые шторы плиссе[/url] – это симфония роскоши и практичности. Они создают поилку, фильтруют сияние и консервируют вашу приватность. Выберите материал, оттенок и декор, и мы с с удовольствием произведем текстильные шторы, которые точно подчеркнут специфику вашего декорирования.
Не стесняйтесь типовыми решениями. Вместе с нами, вы сможете сформировать текстильные занавеси, которые будут соответствовать с вашим неповторимым вкусом. Доверьтесь нам, и ваш резиденция станет местом, где каждый компонент говорит о вашу особенность.
Подробнее на [url=https://tulpan-pmr.ru]портале[/url].
Закажите гардины со складками у нас, и ваш дом переменится в рай стиля и комфорта. Обращайтесь к нам, и мы содействуем вам воплотить в жизнь личные грезы о превосходном внутреннем дизайне.
Создайте свою собственную сказку дизайна с нашей командой. Откройте мир перспектив с портьерами плиссе под по заказу!
[url=http://amoxil.directory/]where can you buy amoxicillin[/url]
Наши производства предлагают вам перспективу воплотить в жизнь ваши самые рискованные и оригинальные идеи в секторе домашнего дизайна. Мы занимаемся на изготовлении занавесей со складками под по вашему заказу, которые не только подчеркивают вашему жилью неповторимый стиль, но и подсвечивают вашу уникальность.
Наши [url=https://tulpan-pmr.ru]купить плиссе от производителя[/url] – это гармония изысканности и функциональности. Они создают атмосферу, фильтруют люминесценцию и поддерживают вашу конфиденциальность. Выберите материал, тон и отделка, и мы с с радостью произведем гардины, которые именно подчеркнут особенность вашего внутреннего дизайна.
Не сдерживайтесь типовыми решениями. Вместе с нами, вы будете способны разработать гардины, которые будут соответствовать с вашим собственным вкусом. Доверьтесь нашей бригаде, и ваш дворец станет помещением, где всякий компонент проявляет вашу уникальность.
Подробнее на [url=https://tulpan-pmr.ru]портале sun-interio1.ru[/url].
Закажите текстильные занавеси со складками у нас, и ваш съемное жилье преобразится в сад стиля и комфорта. Обращайтесь к нашей команде, и мы предоставим помощь вам воплотить в жизнь ваши собственные грезы о идеальном оформлении.
Создайте свою собственную индивидуальную рассказ интерьера с нашей командой. Откройте мир перспектив с текстильными шторами плиссе под индивидуальный заказ!
Хотите получить идеально ровные стены в своей квартире или офисе? Обращайтесь к профессионалам на сайте mehanizirovannaya-shtukaturka-moscow.ru! Мы предоставляем услуги по механизированной штукатурке стен в Москве и области, а также гарантируем быстрое и качественное выполнение работ.
[url=https://lyricagmb.online/]price of lyrica 75 mg in india[/url]
[url=https://dipyridamole.science/]buy dipyridamole[/url]
[url=https://finpecia.skin/]finasteride pills for sale[/url]
[url=https://retina.business/]tretinoin india[/url]
[url=http://colchicine.online/]colchicine 6 mg tablet[/url]
[url=http://motilium.science/]motilium for breastfeeding[/url]
[url=http://chloroquine.science/]chloroquine 250 mg tablets[/url]
[url=http://aaccutane.online/]where to get accutane[/url]
[url=http://baclanofen.com/]40 mg baclofen[/url]
[url=http://prednison.online/]brand prednisone[/url]
[url=http://avodart.directory/]avodart medication generic[/url]
[url=https://retina.business/]how can i get retin a[/url]
[url=https://abamoxicillin.online/]generic for augmentin[/url]
[url=http://azithromycinq.com/]azithromycin capsules[/url]
[url=https://lasixd.online/]lasix 20 mg price[/url]
[url=http://vardenafil.science/]vardenafil tablets 20 mg[/url]
[url=http://ciprok.online/]buy ciprofloxacin 500mg online uk[/url]
Oh my goodness! Incredible article dude! Thank you, However I am experiencing difficulties with your RSS. I don’t know why I can’t subscribe to it. Is there anybody else getting the same RSS problems? Anybody who knows the solution will you kindly respond? Thanx!!
[url=https://metforminb.online/]metformin singapore[/url]
[url=https://zithromax.party/]buy cheap zithromax[/url]
[url=http://synthroid.media/]synthroid 1 mg[/url]
[url=https://lisinoprilc.online/]lisinopril 20 mg tab price[/url]
Asking questions are really good thing if you are not understanding anything fully, but this piece of writing provides nice understanding even.
[url=http://nolvadex.party/]nolvadex d[/url]
[url=http://prednison.online/]buy deltasone no prescription[/url]
[url=http://baclanofen.com/]baclofen rx[/url]
[url=https://prednisolone.party/]buy prednisolone online[/url]
[url=https://silagra.pics/]buy silagra india[/url]
[url=https://aaccutane.online/]buy accutane online[/url]
[url=https://cafergot.science/]cafergot for sale[/url]
[url=http://promethazine.party/]phenergan lowest cost[/url]
[url=https://lasixb.online/]furosemide 20 mg pill[/url]
[url=https://lasixb.online/]lasix tabs[/url]
[url=https://hydrochlorothiazide.science/]hydrochlorothiazide purchase online[/url]
[url=https://baclanofen.com/]lioresal buy online[/url]
Good post. I’m going through a few of these issues as well..
[url=https://azithromycin.party/]buy zithromax online fast shipping[/url]
[url=http://levitra.best/]cost levitra 20mg[/url]
Its like you read my mind! You seem to understand so much approximately this, like you wrote the guide in it or something. I feel that you could do with some p.c. to drive the message house a bit, however other than that, this is great blog. A great read. I’ll definitely be back.
It’s very straightforward to find out any topic on net as compared to books, as I found this article at this website.
[url=https://synthroid.media/]synthroid mexico[/url]
[url=http://doxycicline.com/]doxycycline price 100mg[/url]
Обеспечьте своему жилищу идеальные стены с механизированной штукатуркой. Выберите надежное решение на mehanizirovannaya-shtukaturka-moscow.ru.
[url=http://synthroidb.online/]synthroid 200 mcg tablet[/url]
[url=https://glucophage.company/]order metformin online uk[/url]
[url=http://amoxil.directory/]cheap amoxil online[/url]
[url=https://lyricadp.online/]lyrica capsules 75 mg cost[/url]
[url=http://amoxicillinf.online/]amoxicillin 500mg capsules uk[/url]
[url=https://azithromycinq.online/]buy azithromycin without prescription[/url]
[url=https://finasteridepb.online/]propecia generic price[/url]
[url=http://azithromycini.online/]zithromax cost canada[/url]
[url=http://diflucanld.online/]diflucan 50 mg tablet[/url]
[url=http://prednisome.online/]can you buy prednisone[/url]
[url=https://ovaltrex.com/]buy valtrex[/url]
[url=http://albuterolhl.online/]combivent buy online[/url]
[url=http://synthroidt.online/]synthroid 120 mcg[/url]
Стабилизаторы напряжения Rеsanta обеспечивают защиту от перенапряжения, что позволяет предотвратить повреждение электронных устройств, вызванное скачками напряжения.
стабилизатор напряжения 220в для дома ресанта 10квт [url=https://www.stabilizatory-napryazheniya-1.ru/]https://www.stabilizatory-napryazheniya-1.ru/[/url].
[url=https://predonisone.online/]prednisone 10 mg tablet[/url]
[url=http://accutanelb.online/]accutane 10mg price[/url]
[url=https://prednisonee.online/]deltasone costs[/url]
[url=https://amoxicillinf.online/]augmentin 375mg[/url]
[url=https://accutanelb.online/]cost of accutane[/url]
[url=https://ovaltrex.online/]can i buy valtrex without prescription[/url]
[url=http://azithromycini.online/]where can i buy zithromax uk[/url]
[url=https://synthroidt.online/]synthroid 112 mcg tablet[/url]
[url=https://ovaltrex.com/]valtrex without a prescription[/url]
[url=http://happyfamilyrxstorecanada.com/]family care rx pharmacy[/url]
Howdy! This is kind of off topic but I need some advice from an established blog. Is it hard to set up your own blog? I’m not very techincal but I can figure things out pretty fast. I’m thinking about creating my own but I’m not sure where to start. Do you have any tips or suggestions? Thanks
[url=http://azithromycini.online/]azithromycin z-pack[/url]
[url=https://accutanelb.online/]buy accutane online 30mg[/url]
Медленное время отклика: Релейные стабилизаторы обычно имеют более длительное время отклика на изменения напряжения, поэтому они не всегда подходят для устройств, требующих мгновенной стабилизации.
купить однофазный стабилизатор напряжения 10 квт [url=https://www.stabilizatory-napryazheniya-1.ru]https://www.stabilizatory-napryazheniya-1.ru[/url].
[url=https://prednisome.online/]buy prednisone online no prescription[/url]
[url=http://diflucanld.online/]can you purchase diflucan over the counter[/url]
[url=https://diflucanld.online/]where can i get diflucan[/url]
[url=http://valtarex.com/]by valtrex online[/url]
Hey! I realize this is kind of off-topic but I had to ask. Does operating a well-established blog like yours take a lot of work? I’m completely new to operating a blog but I do write in my diary daily. I’d like to start a blog so I can share my experience and views online. Please let me know if you have any ideas or tips for new aspiring bloggers. Appreciate it!
[url=http://suhagraxs.online/]suhagra tablet price[/url]
[url=https://acqutane.online/]accutane 10 mg discount[/url]
[url=https://metforminex.online/]metformin 1000mg without prescription[/url]
[url=https://metforminex.online/]buy metformin 850 mg[/url]
[url=https://suhagraxs.online/]suhagra 100 buy[/url]
[url=https://elimite.skin/]order elimite online[/url]
[url=https://metforminzb.online/]order metformin 500 mg online[/url]
[url=http://acqutane.online/]order accutane online canada[/url]
[url=https://permethrin.skin/]where to buy elimite cream over the counter[/url]
[url=https://azithromycini.online/]buy zithromax online usa[/url]
[url=http://baclofendl.online/]10mg baclofen tablet price[/url]
[url=http://elimite.skin/]elimite price[/url]
[url=http://retinagel.skin/]tretinoin 025 cream coupon[/url]
[url=http://aprednisone.online/]canadian pharmacy 5 mg prednisone no rx[/url]
[url=http://baclofendl.online/]baclofen tabs 10mg[/url]
[url=https://ilasix.online/]best over the counter lasix[/url]
[url=https://ibaclofeno.online/]10mg baclofen tablet[/url]
[url=https://azithromycinq.online/]azithromycin cheap online[/url]
[url=https://valtrexbc.online/]buy valrex online[/url]
[url=https://iprednisone.online/]prednisone for sale online[/url]
[url=http://doxycyclinedsp.online/]doxycycline buy usa[/url]
[url=http://lisinoprilrm.online/]lisinopril 10 mg for sale[/url]
I all the time used to read post in news papers but now as I am a user of web thus from now I am using net for posts, thanks to web.
[url=http://finasteridel.online/]propecia india buy[/url]
[url=https://accutanelb.online/]can you buy accutane over the counter in canada[/url]
[url=http://lisinoprilhc.online/]zestril 25 mg[/url]
Hi there Dear, are you in fact visiting this site daily, if so then you will absolutely get good experience.
[url=http://diflucanv.com/]buy diflucan medicarions[/url]
[url=https://lyricatb.online/]900mg lyrica[/url]
[url=https://prednisonee.online/]prednisone for sale no prescription[/url]
[url=https://aprednisone.online/]prednisone buy[/url]
[url=http://alisinopril.online/]zestril canada[/url]
[url=http://esynthroid.online/]synthroid 100 pill[/url]
[url=http://valtrexbc.online/]how can i get valtrex[/url]
[url=https://alisinopril.online/]2 lisinopril[/url]
[url=https://albuterolhi.online/]where to buy albuterol australia[/url]
[url=http://alisinopril.online/]lisinopril mexico[/url]
[url=http://dexamethasonelt.online/]where can i buy dexamethasone[/url]
Если вы собираетесь купить новый инструмент, прокат может стать отличной возможностью его протестировать перед покупкой. Вы сможете оценить его качество, функциональность и соответствие ваших требований. Если инструмент устроит вас, вы всегда можете купить его после аренды.
магазин проката [url=https://prokat888.ru]https://prokat888.ru[/url].
[url=http://clomip.com/]clomid generic south africa[/url]
[url=https://accutanelb.online/]accutane prescription uk[/url]
[url=http://albuterolhi.online/]buy ventolin no prescription[/url]
[url=http://valtrexm.online/]valtrex cost[/url]
[url=http://diflucanld.online/]diflucan pill costs[/url]
[url=https://predonisone.online/]where to buy prednisone in australia[/url]
[url=http://prednisonee.online/]prednisolone prednisone[/url]
[url=https://happyfamilyrxstorecanada.com/]canadian pharmacy 24[/url]
[url=https://synthroidcr.online/]synthroid 0.2 mg[/url]
[url=http://ilasix.online/]fureosinomide[/url]
[url=http://doxycyclinedsp.online/]cost of doxycycline[/url]
[url=http://acqutane.online/]how to get accutane australia[/url]
[url=http://diflucanld.online/]diflucan 150 mg caps[/url]
[url=https://clomip.com/]clomid 100 mg tablet[/url]
[url=https://synthroidt.online/]synthroid tablets for sale[/url]
[url=http://accutanelb.online/]generic accutane cost[/url]
[url=https://baclofendl.online/]baclofen 25 mg india[/url]
[url=https://metforminex.online/]glucophage 850 mg price[/url]
[url=https://synthroidt.online/]online pharmacy no script synthroid 75[/url]
[url=http://metforminzb.online/]discount glucophage[/url]
[url=https://metforminex.online/]metformin 1500[/url]
[url=http://prednisonee.online/]prednisone 10 mg daily[/url]
[url=http://diflucanv.online/]diflucan pill canada[/url]
[url=https://lisinoprilhc.online/]lisinopril 2.5 mg[/url]
[url=https://baclofendl.online/]baclofen 10 mg price in india[/url]
[url=https://prednisonefn.online/]prednisone 5mg price[/url]
[url=http://baclofendl.online/]baclofen prescription uk[/url]
Very nice article, exactly what I needed.
My brother suggested I might like this website. He used to be totally right. This publish actually made my day. You cann’t believe just how much time I had spent for this information! Thank you!
[url=http://finasteridel.online/]finasteride cream[/url]
[url=http://finasteridel.online/]finasteride how to get[/url]
[url=https://predonisone.online/]prednisone 10mg tabs[/url]
[url=http://permethrin.skin/]elimite cream otc[/url]
Hey there, I think your blog might be having browser compatibility issues. When I look at your blog in Ie, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, fantastic blog!
[url=https://albuterolhl.online/]albuterol capsules[/url]
[url=http://diflucanv.com/]where can i buy diflucan 1[/url]
[url=http://diflucanld.online/]diflucan 100mg[/url]
[url=http://metforminex.online/]glucophage no prescription[/url]
[url=https://diflucanld.online/]how to buy diflucan online[/url]
[url=https://accutanelb.online/]accutane best price[/url]
This article provides clear idea for the new users of blogging, that truly how to do blogging and site-building.
[url=https://albuterolhl.online/]cheap combivent[/url]
[url=http://iprednisone.online/]average cost of prednisone[/url]
[url=http://suhagraxs.online/]suhagra 100mg price canadian pharmacy[/url]
[url=http://doxycyclinedsp.online/]buy generic doxycycline[/url]
[url=http://lyricadp.online/]cost of lyrica medication[/url]
[url=https://iprednisone.online/]prednisone online[/url]
[url=https://lyricanx.online/]buy lyrica mexico[/url]
[url=https://baclofendl.online/]lioresal 10 mg price[/url]
[url=http://lyricatb.online/]buy lyrica online canada[/url]
[url=http://prednisonefn.online/]prednisone cost canada[/url]
Hi there! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any recommendations?
[url=http://lisinoprilrm.online/]lisinopril 20 mg tablet cost[/url]
[url=http://baclofendl.online/]baclofen 025[/url]
[url=http://azithromycini.online/]order zithromax[/url]
[url=https://clomip.com/]how can i get clomid online[/url]
[url=https://lisinoprilas.online/]prinivil brand name[/url]
[url=https://esynthroid.online/]synthroid 100mcg tab[/url]
[url=https://lyricanx.online/]lyrica 100 mg[/url]
[url=https://albuterolhi.online/]buy albuterol online india[/url]
[url=http://valtrexbc.online/]valtrex 1000 mg price in india[/url]
[url=https://vermoxpr.online/]vermox tablets buy online[/url]
Срочный прокат инструмента в название населенного пункта с инструментом без лишних трат доступны современные модели электроинструментов решение для ремонтных работ инструмент доступно в нашем сервисе
Прокат инструмента для выполнения задач
Сберегайте деньги на покупке инструмента с нашими услугами проката
Отличный выбор для ремонта автомобиля нет инструмента? Не проблема, в нашу компанию за инструментом!
Улучшите результаты с качественным инструментом из нашего сервиса
Аренда инструмента для садовых работ
Не расходуйте деньги на покупку инструмента, а арендуйте инструмент для разнообразных задач в наличии
Разнообразие инструмента для осуществления различных работ
Профессиональная помощь в выборе нужного инструмента от опытных нашей компании
Будьте в плюсе с услугами Аренда инструмента для строительства дома или квартиры
Наша команда – лучший партнер в аренде инструмента
Профессиональный инструмент для ремонтных работ – в нашем прокате инструмента
Не знаете, какой инструмент подойдет? Мы поможем с подбором инструмента в нашем сервисе.
прокат аренда без залога [url=http://www.meteor-perm.ru/]http://www.meteor-perm.ru/[/url].
Срочный прокат инструмента в городском округе с инструментом без дополнительных расходов доступны современные модели Удобное решение для строительных работ инструмент выгодно в нашем сервисе
Аренда инструмента для вашего задач
Сберегайте деньги на покупке инструмента с нашими услугами проката
Отличный выбор для У вашей компании нет инструмента? Не проблема, на наш сервис за инструментом!
Улучшите результаты с качественным инструментом из нашего сервиса
Арендовать инструмента для ремонтных работ
Не тяните деньги на покупку инструмента, а воспользуйтесь арендой инструмент для любых задач в наличии
Широкий ассортимент инструмента для проведения различных работ
Качественная помощь в выборе нужного инструмента от опытных нашей компании
Будьте в плюсе с услугами Аренда инструмента для строительства дома или квартиры
Наша команда – надежный партнер в аренде инструмента
Профессиональный инструмент для ремонтных работ – в нашем прокате инструмента
Не можете определиться с выбором? Мы поможем с подбором инструмента в нашем сервисе.
аренда строительного электроинструмента [url=http://meteor-perm.ru/]http://meteor-perm.ru/[/url].
Thanks for your marvelous posting! I seriously enjoyed reading it, you could be a great author. I will be sure to bookmark your blog and will eventually come back from now on. I want to encourage continue your great posts, have a nice weekend!
[url=https://azithromycinq.online/]zithromax singapore[/url]
[url=http://esynthroid.online/]synthroid 10 mcg[/url]
[url=http://diflucanld.online/]diflucan pill canada[/url]
[url=http://lisinoprilas.online/]lisinopril 20mg discount[/url]
[url=https://silagra.cyou/]silagra 25 mg price[/url]
After checking out a few of the blog articles on your site, I honestly like your way of blogging. I saved it to my bookmark site list and will be checking back soon. Please check out my web site as well and let me know how you feel.
[url=http://ivermectin.guru/]stromectol generic[/url]
[url=https://azithromycin.digital/]azithromycin otc[/url]
[url=http://bactrim.cyou/]bactrim 875 mg[/url]
[url=https://amoxil.cfd/]augmentin 375 mg price india[/url]
[url=http://synthroid.cyou/]synthroid 100 pill[/url]
[url=https://vardenafil.directory/]brand levitra[/url]
fantastic points altogether, you simply gained a brand new reader. What would you suggest about your post that you made a few days ago? Any positive?
[url=http://augmentin.best/]amoxicillin coupon[/url]
What’s up to all, how is everything, I think every one is getting more from this website, and your views are pleasant designed for new users.
[url=http://gabapentin.cfd/]gabapentin cost[/url]
[url=https://trazodone.cfd/]desyrel without prescription[/url]
[url=https://tadalafil.cfd/]buy daily cialis online[/url]
[url=http://diflucan.cyou/]diflucan tablet[/url]
[url=https://trazodone.cfd/]desyrel 10 mg[/url]
Very interesting info !Perfect just what I was looking for!
[url=https://atarax.cyou/]atarax 12.5[/url]
Срочный прокат инструмента в городе с инструментом без лишних трат доступны новейшие модели Лучшее решение для Качественный инструмент доступно в нашем сервисе
Арендовать инструмента любых задач
Сэкономьте деньги на покупке инструмента с нашей услугами проката
Отличный выбор для ремонта автомобиля нет инструмента? Не проблема, в нашу компанию за инструментом!
Расширьте свои возможности с качественным инструментом из нашего сервиса
Аренда инструмента для ремонтных работ
Не расходуйте деньги на покупку инструмента, а берите в прокат инструмент для любых задач в наличии
Разнообразие инструмента для выполнения различных работ
Профессиональная помощь в выборе нужного инструмента от специалистов нашей компании
Будьте в плюсе с услугами проката инструмента для ремонта дома или квартиры
Наш сервис – надежный партнер в аренде инструмента
Идеальный выбор для ремонтных работ – в нашем прокате инструмента
Не можете определиться с выбором? Мы поможем с выбором инструмента в нашем сервисе.
аренда строительного электроинструмента [url=https://meteor-perm.ru/]https://meteor-perm.ru/[/url].
[url=https://doxycycline.cfd/]how to buy doxycycline[/url]
Remarkable things here. I’m very satisfied to peer your article. Thank you so much and I’m looking forward to touch you. Will you please drop me a mail?
[url=https://zoloft.cfd/]zoloft 100mg pill[/url]
[url=http://finpecia.cyou/]propecia price in australia[/url]
[url=http://budesonide.cyou/]budesonide uk[/url]
[url=https://accutane.cyou/]accutane pills buy[/url]
[url=http://zoloft.cfd/]zoloft 25 mg price[/url]
[url=http://augmentin.cfd/]augmentin 500 mg 125 mg tablet[/url]
Saved as a favorite, I really like your site!
Have you ever thought about creating an e-book or guest authoring on other sites? I have a blog centered on the same ideas you discuss and would really like to have you share some stories/information. I know my audience would value your work. If you are even remotely interested, feel free to send me an e-mail.
Hello.This post was extremely interesting, particularly because I was looking for thoughts on this matter last Tuesday.
I¦ve learn some just right stuff here. Certainly price bookmarking for revisiting. I surprise how a lot attempt you place to create the sort of fantastic informative website.
Hi! I just wanted to ask if you ever have any trouble with hackers? My last blog (wordpress) was hacked and I ended up losing a few months of hard work due to no backup. Do you have any solutions to protect against hackers?
[url=http://atarax.cyou/]atarax tablets[/url]
[url=http://vardenafil.cyou/]buy vardenafil australia[/url]
Аренда инструмента в Красноярске с доставкой
аренда инструмента в красноярске без залога [url=https://prokat888.ru/#аренда-инструмента-в-красноярске-без-залога]https://prokat888.ru/[/url].
Аренда инструмента в название города с инструментом без В компании доступны современные модели ремонтных инструментов решение для Качественный инструмент выгодно в нашем сервисе
Арендовать инструмента для задач
Экономьте деньги на покупке инструмента с нашим услугами проката
Правильное решение для У вашей компании нет инструмента? Не проблема, в нашу компанию за инструментом!
Освойте новые умения с качественным инструментом из нашего сервиса
Прокат инструмента для ремонтных работ
Не тяните деньги на покупку инструмента, а Надежный инструмент для любых задач в наличии
Широкий ассортимент инструмента для проведения различных работ
Качественная помощь в выборе нужного инструмента от опытных нашей компании
Сэкономьте с услугами проката инструмента для строительства дома или квартиры
Наш сервис – лучший партнер в аренде инструмента
Надежный помощник для ремонтных работ – в нашем прокате инструмента
Не можете определиться с выбором? Мы поможем с советом инструмента в нашем сервисе.
аренда бензо электроинструмента [url=https://www.meteor-perm.ru]прокат оборудования[/url].
Множество видов инструмента в аренду
аренда инструмента в красноярске [url=prokat888.ru#аренда-инструмента-в-красноярске]prokat888.ru[/url].
[url=https://atarax.cyou/]atarax 10mg buy online[/url]
[url=https://accutane.cfd/]accutane cost canada[/url]
[url=http://clonidine.cfd/]0.1 clonidine[/url]
[url=https://tadalafil.cfd/]cialis medicine in india[/url]
[url=https://sildenafil.cfd/]sildenafil 12.5 mg[/url]
Лаки Джет 1win – лучший выбор для тех, кто ценит азарт и хочет зарабатывать на своей удаче. Лаки Джет краш на официальном сайте 1win удивит тебя мгновенными выигрышами и яркими эмоциями.
У наших клиентов вы можете взять в аренду инструмент
аренда инструмента в красноярске без залога [url=http://www.prokat888.ru/#аренда-инструмента-в-красноярске-без-залога]http://www.prokat888.ru/[/url].
[url=https://accutane.cyou/]accutane best price[/url]
Hello my family member! I want to say that this post is awesome, nice written and come with almost all important infos. I would like to peer extra posts like this .
Your blog is amazing! I’m interested in becoming a contributor. How can I apply?
excellent post.Ne’er knew this, appreciate it for letting me know.
Thanks for sharing your thoughts on %meta_keyword%. Regards
[url=http://gabapentin.cfd/]gabapentin 104[/url]
Really fantastic visual appeal on this internet site, I’d value it 10 10.
[url=https://phenergan.cyou/]phenergan tablets 10mg[/url]
[url=http://clonidine.cfd/]clonidine prescription[/url]
[url=http://furosemide.cyou/]furosemide 500 mg[/url]
[url=https://xenical.cfd/]orlistat tablet price[/url]
[url=http://hydroxychloroquine.guru/]plaquenil price in india[/url]
[url=https://sildenafil.cfd/]canadian pharmacy viagra[/url]
[url=http://sildenafil.cfd/]buy viagra 25mg[/url]
[url=http://suhagra.cyou/]suhagra tablet 50 mg[/url]
It’s impressive that you are getting ideas from this post as well as from our argument made here.
[url=https://vermox.cyou/]vermox otc[/url]
[url=http://augmentin.best/]buy augmentin online with out prescription[/url]
[url=https://augmentin.cyou/]amoxicillin 500mg capsule over the counter[/url]
[url=http://paxil.cfd/]paroxetine 7.5 mg tablet[/url]
[url=https://toradol.cfd/]over the counter toradol[/url]
[url=http://accutane.guru/]how to buy accutane[/url]
[url=http://zoloft.cyou/]can you buy zoloft over the counter[/url]
[url=http://finpecia.cyou/]how to buy finasteride[/url]
[url=https://colchicine.cyou/]buy colchicine without prescription[/url]
[url=http://levitra.cfd/]buy discount levitra[/url]
[url=http://rybelsus.cyou/]buy semaglutide pill form for adults[/url]
[url=https://semaglutidewegovy.shop/]order wegovy[/url]
[url=https://semaglutideozempic.shop/]rybelsus pill[/url]
[url=https://ozempictabs.shop/]buy rybelsus[/url]
[url=http://ozempic.pics/]rybelsus tablets cost[/url]
When I originally commented I clicked the “Notify me when new comments are added” checkbox and now each time a comment is added I get four emails with the same comment. Is there any way you can remove me from that service? Bless you!
[url=http://semaglutidewegovy.com/]buy rybelsus online no script[/url]
[url=http://rybelsus.monster/]rybelsus semaglutide tablets 3mg[/url]
[url=http://rybelsus.quest/]rybelsus tablets buy[/url]
[url=https://semaglutide.cyou/]ozempic semaglutide[/url]
[url=https://wegovy.top/]rybelsus rx[/url]
You really make it seem so easy with your presentation however I in finding this topic to be really something which I feel I would never understand. It sort of feels too complicated and very broad for me. I am looking forward on your next submit, I will try to get the hold of it!
Nice blog right here! Also your website a lot up very fast! What host are you the use of? Can I am getting your affiliate link for your host? I want my site loaded up as fast as yours lol
The other day, while I was at work, my sister stole my iPad and tested to see if it can survive a 25 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is totally off topic but I had to share it with someone!
Сайт [url=https://fotonons.ru/]https://fotonons.ru/[/url] показывает обширный спектр идей в оформлении и декорировании интерьеров через фотографии. Вот некоторые ключевые моменты:
Вдохновение для Интерьера:
Предоставление практических рекомендаций для преобразования жилых пространств.
Акцент на различные стили, включая скандинавский.
Разнообразие Контента:
Оформление балконов, гостинных, спален и других пространств.
Предоставление богатого источника идей для изменения дома или рабочего пространства.
Практическое Применение:
Идеи по использованию этих стилей в реальных условиях.
Мотивирующие примеры, иллюстрирующие возможности улучшения пространства.
Этот текст увеличивает детализацию описания сайта, добавляет структуру в виде списков и перечислений, и размножен с использованием синонимов для увеличения вариативности.
___________________________________________________
Не забудьте добавить наш сайт в закладки: https://fotonons.ru/
Greetings! Very helpful advice within this article! It is the little changes that make the greatest changes. Thanks for sharing!
Wow, marvelous blog layout! How long have you been blogging for? you make blogging look easy. The overall look of your site is wonderful, let alone the content!
It’s a shame you don’t have a donate button! I’d without a doubt donate to this excellent blog! I suppose for now i’ll settle for book-marking and adding your RSS feed to my Google account. I look forward to brand new updates and will talk about this site with my Facebook group. Chat soon!
[url=https://ozempic.best/]rybelsus tab 14mg[/url]
[url=https://semaglutidewegovy.com/]wegovy 7mg[/url]
[url=http://wegovy.directory/]semaglutide tablet[/url]
[url=https://ozempic.quest/]semaglutide mexico[/url]
[url=http://semaglutide.guru/]wegovy online pharmacy[/url]
[url=https://rybelsustabs.shop/]semaglutide tablets[/url]
[url=https://semaglutidetabs.shop/]wegovy online cheap[/url]
cialis- canadian pharmacy Canadian Pharmacies Online
best online canadian pharmacies [url=http://canadianphrmacy23.com/]find more information[/url]
Thanks for a marvelous posting! I actually enjoyed reading it, you are a great author.I will make certain to bookmark your blog and will often come back sometime soon. I want to encourage you to ultimately continue your great job, have a nice afternoon!
[url=https://wegovy.company/]rybelsus tablets for weight loss[/url]
canadian pharmacy without prescription canadian pharmacy
online pharmacy without prescription [url=http://canadianphrmacy23.com/]generic pharmacy india[/url]
https://gorod-buketov.ru/ заказать цветы с доставкой в москве
Hello. remarkable job. I did not imagine this. This is a impressive story. Thanks!
I have been absent for some time, but now I remember why I used to love this blog. Thanks, I’ll try and check back more often. How frequently you update your website?
[url=https://tadalafilstd.online/]buy tadalafil online usa[/url]
F*ckin’ remarkable things here. I am very glad to see your article. Thanks so much and i’m looking ahead to touch you. Will you kindly drop me a e-mail?
Ощутите разницу с нашими стабилизаторами: купите сегодня
инверторные стабилизаторы напряжения [url=https://kupit-stabilizator-napryazheniya.ru/stabilizatoryi-napryajeniya-invertornie]инверторные стабилизаторы напряжения[/url] .
Perfect work you have done, this internet site is really cool with fantastic information.
I’m impressed, I need to say. Actually hardly ever do I encounter a blog that’s each educative and entertaining, and let me inform you, you have got hit the nail on the head. Your concept is excellent; the issue is something that not enough people are speaking intelligently about. I’m very completely happy that I stumbled throughout this in my seek for something relating to this.
[url=http://bestmedsx.online/]online pharmacy cialis[/url]
Hiya, I’m really glad I have found this info. Nowadays bloggers publish only about gossips and net and this is actually annoying. A good website with exciting content, that is what I need. Thank you for keeping this web site, I will be visiting it. Do you do newsletters? Can’t find it.
[url=https://lisinoprilgp.com/]generic prinivil[/url]
danatoto alternatif link!
[url=https://azithromycinhq.com/]zithromax 500mg pills[/url]
Hi there everyone, it’s my first pay a visit at this site, and article is in fact fruitful for me, keep up posting such articles or reviews.
[url=https://tadalafilstd.online/]cialis medication price[/url]
I echo the sentiments above – this post is an absolute delight!
Мы компания профессиональных SEO-оптимизаторов, работающих над увеличением посещаемости и рейтинга вашего сайта в поисковых системах.
Мы преуспели в своей деятельности и стремимся передать вам наши знания и опыт.
Какие возможности открываются перед вами:
• [url=https://seo-prodvizhenie-ulyanovsk1.ru/]продвижение нового сайтов поисковых системах[/url]
• Анализ всех аспектов вашего сайта и разработка уникальной стратегии продвижения.
• Оптимизация контента и технических аспектов вашего сайта для максимальной эффективности.
• Регулярный анализ результатов и мониторинг вашего онлайн-присутствия для его улучшения.
Подробнее [url=https://seo-prodvizhenie-ulyanovsk1.ru/]https://seo-prodvizhenie-ulyanovsk1.ru/[/url]
Многие наши клиенты отмечают улучшения: рост посещаемости, улучшение рейтинга в поисковых запросах и, конечно, увеличение прибыли. Мы готовы предложить вам консультацию бесплатно, для обсуждения ваших потребностей и разработки стратегии продвижения, соответствующей вашим целям и финансовым возможностям.
Не упустите шанс улучшить свой бизнес в онлайн-мире. Свяжитесь с нами сегодня же.
I enjoy what you guys are up too. This sort of clever work and exposure! Keep up the awesome works guys I’ve added you guys to my blogroll.
Hey there! I know this is kind of off topic but I was wondering which blog platform are you using for this website? I’m getting tired of WordPress because I’ve had problems with hackers and I’m looking at options for another platform. I would be fantastic if you could point me in the direction of a good platform.
[url=https://synthroidam.online/]synthroid canada[/url]
[url=http://isynthroid.online/]synthroid purchase online[/url]
[url=http://ezithromycin.online/]zithromax online canada[/url]
superb morning starting with an excellent reading 🌞📖
[url=https://azithromycinmds.com/]can i buy azithromycin[/url]
[url=https://azithromycinps.online/]azithromycin in mexico[/url]
As soon as I observed this website I went on reddit to share some of the love with them.
Thank you, I’ve recently been looking for information approximately this topic for a while and yours is the best I’ve discovered so far. However, what about the bottom line? Are you positive in regards to the supply?
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
I like what you guys are up also. Such smart work and reporting! Keep up the excellent works guys I’ve incorporated you guys to my blogroll. I think it will improve the value of my site 🙂
I want to get across my affection for your kind-heartedness for those who absolutely need help on that question. Your special commitment to getting the solution across was astonishingly beneficial and has continually enabled associates just like me to attain their goals. Your entire interesting help and advice denotes a whole lot a person like me and further more to my office colleagues. Best wishes; from each one of us.
This web site is known as a walk-by for all the information you needed about this and didn’t know who to ask. Glimpse right here, and also you’ll undoubtedly uncover it.
Наша бригада искусных исполнителей завершена предложить вам прогрессивные технологии, которые не только гарантируют долговечную безопасность от мороза, но и преподнесут вашему домашнему пространству элегантный вид.
Мы функционируем с последовательными строительными материалами, обеспечивая долгосрочный термин эксплуатации и прекрасные итоги. Теплоизоляция наружных поверхностей – это не только экономия ресурсов на тепле, но и ухаживание о экологической обстановке. Сберегательные инновации, какие мы производим, способствуют не только зданию, но и сохранению природы.
Самое важное: [url=https://ppu-prof.ru/]Утепление дома снаружи цена за м2[/url] у нас начинается всего от 1250 рублей за м²! Это бюджетное решение, которое переделает ваш резиденцию в настоящий приятный район с минимальными затратами.
Наши проекты – это не просто изоляция, это созидание области, в где всякий компонент выражает ваш уникальный образ действия. Мы возьмем во внимание все твои пожелания, чтобы воплотить ваш дом еще еще более комфортным и привлекательным.
Подробнее на [url=https://ppu-prof.ru/]официальном сайте[/url]
Не откладывайте дела о своем квартире на потом! Обращайтесь к квалифицированным работникам, и мы сделаем ваш обиталище не только уютнее, но и более элегантным. Заинтересовались? Подробнее о наших услугах вы можете узнать на веб-ресурсе. Добро пожаловать в пространство благополучия и стандартов.
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Quality articles is the main to invite the people to go to see the site, that’s what this web site is providing.
This is a topic close to my heart cheers, where are your contact details though?
What is FlowForce Max? FlowForce Max Advanced Formula is a holistic blend designed to promote optimal prostate health
Nice post. I learn something new and challenging on blogs I stumbleupon every day. It will always be interesting to read content from other writers and practice a little something from their websites.
Hey, you used to write magnificent, but the last several posts have been kinda boring… I miss your great writings. Past few posts are just a bit out of track! come on!
I really appreciate this post. I’ve been looking everywhere for this! Thank goodness I found it on Bing. You have made my day! Thank you again
certainly like your web-site however you need to test the spelling on quite a few of your posts. A number of them are rife with spelling problems and I find it very troublesome to tell the truth on the other hand I’ll surely come again again.
I likewise conceive thus, perfectly pent post! .
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
Hi! I just wanted to ask if you ever have any issues with hackers? My last blog (wordpress) was hacked and I ended up losing months of hard work due to no backup. Do you have any solutions to stop hackers?
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
Thanks for another informative web site. Where else could I get that type of information written in such a perfect way? I have a project that I’m just now working on, and I have been on the look out for such info.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I like this website its a master peace ! Glad I detected this on google .
Sweet blog! I found it while browsing on Yahoo News. Do you have any tips on how to get listed in Yahoo News? I’ve been trying for a while but I never seem to get there! Appreciate it
I don’t even know the way I stopped up here, however I thought this post was good. I don’t recognise who you’re however definitely you are going to a famous blogger in the event you are not already. Cheers!
I’m not sure where you are getting your info, however good topic. I needs to spend a while studying more or understanding more. Thank you for magnificent information I used to be in search of this information for my mission.
I appreciate, cause I found exactly what I used to be looking for. You have ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
A person necessarily lend a hand to make critically articles I would state. This is the first time I frequented your web page and to this point? I amazed with the research you made to create this actual post amazing. Magnificent process!
Yesterday, while I was at work, my sister stole my iphone and tested to see if it can survive a 40 foot drop, just so she can be a youtube sensation. My iPad is now broken and she has 83 views. I know this is completely off topic but I had to share it with someone!
I read this post fully about the comparison of newest and preceding technologies, it’s remarkable article.
I seriously love your site.. Very nice colors & theme. Did you create this website yourself? Please reply back as I’m planning to create my very own blog and would like to learn where you got this from or exactly what the theme is called. Thanks!
Please let me know if you’re looking for a article author for your site. You have some really great posts and I think I would be a good asset. If you ever want to take some of the load off, I’d really like to write some material for your blog in exchange for a link back to mine. Please send me an e-mail if interested. Kudos!
We stumbled over here different page and thought I might as well check things out. I like what I see so now i’m following you. Look forward to going over your web page yet again.
It is not my first time to pay a visit this web site, i am visiting this web site dailly and take pleasant information from here every day.
This is a great tip especially to those new to the blogosphere. Brief but very accurate information Thanks for sharing this one. A must read article!
Hey very interesting blog!
Your means of explaining everything in this piece of writing is actually pleasant, all be able to without difficulty understand it, Thanks a lot.
Hi there i am kavin, its my first time to commenting anywhere, when i read this article i thought i could also make comment due to this brilliant article.
I like the valuable information you supply for your articles. I will bookmark your weblog and check again here frequently. I am quite certain I will be told many new stuff right here! Good luck for the following!
Pretty section of content. I just stumbled upon your weblog and in accession capital to assert that I acquire in fact enjoyed account your blog posts. Any way I’ll be subscribing to your augment and even I achievement you access consistently rapidly.
Hi my loved one! I want to say that this article is awesome, great written and come with almost all significant infos. I’d like to see more posts like this .
After looking at a number of the blog posts on your web page, I really like your way of blogging. I added it to my bookmark website list and will be checking back soon. Take a look at my web site as well and let me know how you feel.
I’m not sure where you are getting your info, but good topic. I needs to spend some time learning more or understanding more. Thanks for wonderful information I was looking for this information for my mission.
If some one needs to be updated with latest technologies afterward he must be pay a visit this web site and be up to date every day.
Hi, i feel that i saw you visited my blog so i got here to go back the prefer?.I am trying to in finding things to improve my site!I assume its good enough to use some of your concepts!!
You really make it seem so easy together with your presentation however I find this topic to be really something which I think I would never understand. It sort of feels too complicated and very large for me. I am looking forward on your next post, I will try to get the cling of it!
I simply could not depart your site prior to suggesting that I really enjoyed the standard information a person supply on your visitors? Is going to be back ceaselessly in order to inspect new posts
Im not that much of a online reader to be honest but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back down the road. All the best
Howdy, I do believe your website might be having browser compatibility issues. When I look at your site in Safari, it looks fine however, if opening in IE, it has some overlapping issues. I just wanted to give you a quick heads up! Besides that, great website!
I don’t even understand how I ended up here, however I thought this submit was good. I don’t understand who you are however definitely you are going to a famous blogger for those who are not already. Cheers!
This is very interesting, You are an excessively professional blogger. I have joined your feed and sit up for in the hunt for more of your magnificent post. Also, I have shared your web site in my social networks
Greetings! This is my first visit to your blog! We are a collection of volunteers and starting a new initiative in a community in the same niche. Your blog provided us valuable information to work on. You have done a extraordinary job!
I’m now not positive where you are getting your info, however good topic. I needs to spend a while learning more or understanding more. Thank you for fantastic information I used to be looking for this information for my mission.
I’m now not sure where you are getting your info, however good topic. I needs to spend a while studying more or working out more. Thank you for great information I used to be in search of this information for my mission.
Hi, i think that i saw you visited my web site so i came to return the favor.I am trying to find things to improve my website!I suppose its ok to use some of your ideas!!
Great article, exactly what I wanted to find.
Wow, this post is pleasant, my sister is analyzing such things, so I am going to let know her.
Wow, that’s what I was seeking for, what a data! present here at this weblog, thanks admin of this web site.
Hey! Do you know if they make any plugins to help with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results. If you know of any please share. Appreciate it!
I will right away seize your rss as I can not in finding your email subscription link or newsletter service. Do you have any? Please permit me recognize so that I may just subscribe. Thanks.
WOW just what I was searching for. Came here by searching for %keyword%
Your article helped me a lot, is there any more related content? Thanks!
Pretty nice post. I just stumbled upon your blog and wished to say that I have truly enjoyed surfing around your blog posts. After all I’ll be subscribing to your rss feed and I hope you write again soon!
I like this weblog so much, saved to bookmarks. “Nostalgia isn’t what it used to be.” by Peter De Vries.
Hello! Someone in my Myspace group shared this site with us so I came to take a look. I’m definitely enjoying the information. I’m book-marking and will be tweeting this to my followers! Excellent blog and superb style and design.
Great write-up, I?¦m normal visitor of one?¦s blog, maintain up the nice operate, and It’s going to be a regular visitor for a lengthy time.
Hmm it seems like your blog ate my first comment (it was super long) so I guess I’ll just sum it up what I wrote and say, I’m thoroughly enjoying your blog. I too am an aspiring blog writer but I’m still new to the whole thing. Do you have any helpful hints for novice blog writers? I’d certainly appreciate it.
Hiya, I’m really glad I have found this information. Today bloggers publish just about gossips and web and this is actually irritating. A good website with exciting content, that is what I need. Thanks for keeping this website, I will be visiting it. Do you do newsletters? Cant find it.
Real wonderful information can be found on weblog.
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with a few pics to drive the message home a little bit, but instead of that, this is magnificent blog. A fantastic read. I’ll certainly be back.
https://englishmax.ru/
Thanx for the effort, keep up the good work Great work, I am going to start a small Blog Engine course work using your site I hope you enjoy blogging with the popular BlogEngine.net.Thethoughts you express are really awesome. Hope you will right some more posts.
I am really inspired with your writing skills as smartly as with the format for your blog. Is that this a paid subject matter or did you modify it yourself? Either way keep up the nice high quality writing, it is rare to look a great weblog like this one nowadays..
F*ckin’ tremendous issues here. I’m very satisfied to look your article. Thanks a lot and i’m looking forward to touch you. Will you please drop me a e-mail?
}
Some truly nice and utilitarian information on this web site, likewise I believe the style holds superb features.
Thanks, Quite a lot of material!
You revealed that effectively.|
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I like this weblog its a master peace ! Glad I observed this on google .
Hiya, I am really glad I’ve found this info. Today bloggers publish only about gossips and web and this is really irritating. A good web site with interesting content, that’s what I need. Thanks for keeping this web site, I’ll be visiting it. Do you do newsletters? Can not find it.
DentiCore is a dental and gum health formula, made with premium natural ingredients.
It’s going to be end of mine day, but before end I am reading this impressive article to increase my experience.
I have been browsing online more than 3 hours today, yet I never found any interesting article like yours. It’s pretty worth enough for me. In my opinion, if all webmasters and bloggers made good content as you did, the net will be a lot more useful than ever before.
Hey there just wanted to give you a quick heads up. The text in your post seem to be running off the screen in Chrome. I’m not sure if this is a format issue or something to do with browser compatibility but I thought I’d post to let you know. The style and design look great though! Hope you get the problem solved soon. Cheers
This site is mostly a stroll-via for the entire information you needed about this and didn’t know who to ask. Glimpse here, and also you’ll positively uncover it.
[url=http://valtrexbt.online/]3000mg valtrex[/url]
I regard something truly interesting about your website so I saved to my bookmarks.
I?¦ll immediately grasp your rss feed as I can’t find your e-mail subscription link or e-newsletter service. Do you’ve any? Please allow me recognise in order that I may subscribe. Thanks.
Thanks a lot for sharing this with all of us you actually recognise what you are talking about! Bookmarked. Kindly also discuss with my site =). We could have a link trade contract among us!
You have noted very interesting points! ps decent web site. “Never take the advice of someone who has not had your kind of trouble.” by Sydney J. Harris.
ГГУ имени Ф.Скорины
This really answered my problem, thank you!
Your place is valueble for me. Thanks!…
I was reading through some of your content on this website and I conceive this internet site is rattling instructive! Keep putting up.
Thank you for sharing with us, I believe this website truly stands out : D.
I gotta favorite this internet site it seems very helpful extremely helpful
I would like to thnkx for the efforts you have put in writing this blog. I am hoping the same high-grade blog post from you in the upcoming as well. In fact your creative writing abilities has inspired me to get my own blog now. Really the blogging is spreading its wings quickly. Your write up is a good example of it.
I think other web site proprietors should take this web site as an model, very clean and excellent user genial style and design, as well as the content. You’re an expert in this topic!
I like this post, enjoyed this one regards for putting up.
We are a gaggle of volunteers and opening a new scheme in our community. Your website provided us with useful info to work on. You have done an impressive task and our whole group shall be grateful to you.
Great post.
Incredible plenty of useful data.|
very good publish, i actually love this website, carry on it
Hi there, I found your site by way of Google while looking for a comparable topic, your web site got here up, it seems to be great. I have bookmarked it in my google bookmarks.
I savor, lead to I discovered exactly what I was having a look for. You have ended my 4 day long hunt! God Bless you man. Have a nice day. Bye
k8 カジノ パチンコ 種類
このブログはいつも私に新しい視点を提供してくれます。感謝しています。
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
I consider something truly special in this site.
めんそーれ(雷電ver.)
この記事を読んで、多くのインスピレーションを受けました。
An interesting discussion is worth comment. I think that you should write more on this topic, it might not be a taboo subject but generally people are not enough to speak on such topics. To the next. Cheers
Good ?V I should definitely pronounce, impressed with your web site. I had no trouble navigating through all the tabs as well as related information ended up being truly simple to do to access. I recently found what I hoped for before you know it in the least. Reasonably unusual. Is likely to appreciate it for those who add forums or something, web site theme . a tones way for your customer to communicate. Nice task..
Hello, you used to write magnificent, but the last few posts have been kinda boringK I miss your tremendous writings. Past few posts are just a little bit out of track! come on!
I like it when individuals come together and share thoughts. Great blog, keep it up!
Very interesting details you have noted, thankyou for putting up.
Can I just say what a relief to find someone who actually knows what theyre talking about on the internet. You definitely know how to bring an issue to light and make it important. More people need to read this and understand this side of the story. I cant believe youre not more popular because you definitely have the gift.
Hi, Neat post. There’s a problem along with your website in internet explorer, might test thisK IE still is the market chief and a good component of folks will pass over your wonderful writing due to this problem.
I like this website very much, Its a very nice place to read and get information.
Someone necessarily assist to make critically articles I would state. This is the first time I frequented your website page and up to now? I amazed with the research you made to make this particular publish amazing. Wonderful task!
What is ProNerve 6? ProNerve 6 is a doctor-formulated nutritional supplement specifically marketed to individuals struggling with nerve pain.
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
I am constantly browsing online for articles that can assist me. Thank you!
Some really good articles on this web site, thanks for contribution. “A man with a new idea is a crank — until the idea succeeds.” by Mark Twain.
Some truly wonderful articles on this internet site, thanks for contribution. “Once, power was considered a masculine attribute. In fact, power has no sex.” by Katharine Graham.
I really like your writing style, superb information, thanks for putting up :D. “If a cluttered desk is the sign of a cluttered mind, what is the significance of a clean desk” by Laurence J. Peter.
Excellent website you have here but I was wanting to know if you knew of any message boards that cover the same topics talked about in this article? I’d really love to be a part of group where I can get comments from other knowledgeable individuals that share the same interest. If you have any recommendations, please let me know. Thanks a lot!
Hiya, I am really glad I have found this info. Nowadays bloggers publish just about gossips and web and this is actually frustrating. A good website with interesting content, this is what I need. Thank you for keeping this website, I will be visiting it. Do you do newsletters? Cant find it.
As a Newbie, I am always exploring online for articles that can be of assistance to me. Thank you
What is ProNerve 6? ProNerve 6 is your complete arrangement made to address the multifaceted necessities of nerve wellbeing
You actually make it appear so easy along with your presentation but I to find this matter to be really something that I believe I would never understand. It seems too complex and extremely broad for me. I’m having a look ahead to your subsequent post, I?¦ll try to get the dangle of it!
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
I discovered your blog site on google and check a few of your early posts. Continue to keep up the very good operate. I just additional up your RSS feed to my MSN News Reader. Seeking forward to reading more from you later on!…
I would like to point out my appreciation for your kind-heartedness supporting visitors who really want help on this particular question. Your very own dedication to passing the solution up and down was exceedingly helpful and have truly allowed women just like me to achieve their aims. The warm and friendly information means much to me and much more to my office workers. Warm regards; from everyone of us.
geinoutime.com
그는 급히 사람들에게 왕실 마부를 준비하라고 명령했고, 사람들을 궁 밖으로 데리고 나가기로 결정했습니다.
I will right away clutch your rss as I can not find your email subscription hyperlink or e-newsletter service. Do you have any? Please allow me know in order that I may just subscribe. Thanks.
Hi there! I’m at work browsing your blog from my new iphone 4! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the excellent work!
It’s an remarkable piece of writing for all the web viewers; they will get benefit from it I am sure.
Hi my family member! I wish to say that this article is amazing, nice written and come with approximately all significant infos. I’d like to peer more posts like this .
Whats Going down i’m new to this, I stumbled upon this I have discovered It positively helpful and it has helped me out loads. I am hoping to contribute & aid different customers like its helped me. Great job.
This is very interesting, You are a very skilled blogger. I have joined your feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks!
You actually suggested it exceptionally well.|
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out much. I hope to give something back and aid others like you aided me.
ProvaDent: What Is It? ProvaDent is a natural tooth health supplement by Adam Naturals.
geinoutime.com
“나의 황제 만세…” Xie Qian은 주저 없이 절을 했습니다.
Hi! Do you use Twitter? I’d like to follow you if that would be okay. I’m definitely enjoying your blog and look forward to new posts.
I’m usually to blogging and i really recognize your content. The article has really peaks my interest. I am going to bookmark your website and preserve checking for new information.
I’ve been absent for a while, but now I remember why I used to love this site. Thanks, I’ll try and check back more often. How frequently you update your site?
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
I read this article fully concerning the comparison of most recent and previous technologies, it’s awesome article.
I got what you mean , appreciate it for putting up.Woh I am thankful to find this website through google.
There may be noticeably a bundle to learn about this. I assume you made certain nice points in options also.
This site is my intake, very great style and perfect articles.
I know this if off topic but I’m looking into starting my own blog and was wondering what all is required to get set up? I’m assuming having a blog like yours would cost a pretty penny? I’m not very web savvy so I’m not 100 sure. Any recommendations or advice would be greatly appreciated. Cheers
I’ll immediately seize your rss as I can’t find your e-mail subscription hyperlink or newsletter service. Do you’ve any? Please permit me recognize so that I may subscribe. Thanks.
Thank you for sharing superb informations. Your web site is so cool. I am impressed by the details that you have on this website. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found simply the info I already searched all over the place and just could not come across. What a perfect website.
I was very pleased to find this web-site.I wanted to thanks for your time for this wonderful read!! I definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you blog post.
Good day! Do you know if they make any plugins to assist with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success. If you know of any please share. Kudos!
First off I want to say wonderful blog! I had a quick question that I’d like to ask if you don’t mind. I was curious to know how you center yourself and clear your mind before writing. I have had a difficult time clearing my mind in getting my thoughts out. I do enjoy writing but it just seems like the first 10 to 15 minutes are generally wasted just trying to figure out how to begin. Any suggestions or tips? Thanks!
What’s up, for all time i used to check weblog posts here in the early hours in the daylight, for the reason that i like to gain knowledge of more and more.
myfootballday.ru/page/14
premiumkutyatap.hu/jutalom_pontok
girbir.com/blogs/13038/Where-can-I-buy-a-diploma-or-certificate-at-a
http://www.bakili-fclub.com/elaqeen.html
tudiencongnghe.com/author/binguyenth/
Just what I was searching for, appreciate it for putting up.
купить диплом фармацевта [url=https://diplomvash.ru/]diplomvash.ru[/url] .
Hi it’s me, I am also visiting this website regularly, this site is genuinely good and the visitors are truly sharing pleasant thoughts.
allnewstroy.ru/effektivnoe-obrazovanie-kupit-diplom-i-dostich-tseley
kruizturm.ru/morskie-kruizyi/
slcomp.kz/index.php?route=information/blogger&blogger_id=5
http://www.anahnu.club/en/jomsocial/groups/viewbulletin/148-%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-%D1%81%D0%B5%D0%B9%D1%87%D0%B0%D1%81-%D0%B1%D1%83%D0%B4%D0%B5%D1%82-%D1%81%D1%82%D0%BE%D0%B8%D1%82%D1%8C-%D0%BD%D0%B5%D0%BE%D1%82%D0%BB%D0%B8%D1%87%D0%B8%D0%BC%D1%8B%D0%B9-%D0%BE%D1%82-%D0%BE%D1%80%D0%B8%D0%B3%D0%B8%D0%BD%D0%B0%D0%BB%D0%B0-%D0%B4%D0%B8%D0%BF%D0%BB%D0%BE%D0%BC.html?groupid=1
alcado.com.vn/san-pham-xa-hang
Веб-студия обеспечивает качественные решения по технической поддержке ресурса на https://podderzhka-dlya-saita.ru по низким ценам. Наполним сайт профессиональным контентом. Решим вопросы по исправлению ошибок и редизайну. Работники осуществят доступные услуги по продвижению сайтов. Рекомендуем выбрать выгодные расценки с абонентской платой. Тарифные планы предлагаются по ключевым параметрам: числу задействованных работников, объема страниц и других.
Yay google is my queen helped me to find this great web site! .
Hi there, You have done a great job. I’ll definitely digg it and personally recommend to my friends. I am sure they’ll be benefited from this website.
pricebuy.co.il/siemens-kg76nai31l-price
flora-online.ru/glavnaya/tsvetyi-na-1-sentyabrya-2/
portugues.ru/forum/album.php?albumid=80&attachmentid=3712
ilonka.ru/user/robertgneida/
dedadi.ru/obshhestvo/nacionalnyy-sostav-moskva.html
Great site. Lots of helpful info here. I’m sending it to a few buddies ans also sharing in delicious. And obviously, thank you in your effort!
I am no longer positive the place you’re getting your information, but good topic. I must spend a while finding out much more or working out more. Thank you for magnificent information I used to be in search of this info for my mission.
Great stuff, Thank you.|
I like what you guys are up too. Such smart work and reporting! Carry on the superb works guys I have incorporated you guys to my blogroll. I think it’ll improve the value of my web site 🙂
Hi my loved one! I wish to say that this article is awesome, nice written and come with almost all vital infos. I would like to see extra posts like this.
Thank you, I have just been searching for information about this subject for ages and yours is the best I have discovered till now. But, what about the bottom line? Are you sure about the source?
Thanks for sharing superb informations. Your web site is very cool. I am impressed by the details that you have on this website. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for extra articles. You, my friend, ROCK! I found simply the information I already searched all over the place and just couldn’t come across. What a perfect web-site.
I genuinely enjoy reading on this site, it has got wonderful content.
I’m still learning from you, as I’m improving myself. I absolutely love reading everything that is written on your blog.Keep the tips coming. I loved it!
I have been surfing online more than 3 hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my view, if all website owners and bloggers made good content as you did, the net will be much more useful than ever before.
You made some decent points there. I looked on the web to learn more about the issue and found most individuals will go along with your views on this website.
Only wanna tell that this is very beneficial, Thanks for taking your time to write this.
I am writing to make you understand what a exceptional discovery our princess went through checking your site. She came to find several issues, not to mention what it is like to have a very effective giving spirit to make a number of people easily thoroughly grasp chosen very confusing matters. You truly surpassed people’s expectations. I appreciate you for imparting those effective, safe, revealing and also cool guidance on this topic to Lizeth.
What does the Lottery Defeater Software offer? The Lottery Defeater Software is a unique predictive tool crafted to empower individuals seeking to boost their chances of winning the lottery.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
What’s Taking place i’m new to this, I stumbled upon this I have found It positively helpful and it has helped me out loads. I am hoping to give a contribution & aid other users like its helped me. Good job.
You actually mentioned that well.|
You could definitely see your enthusiasm within the paintings you write. The world hopes for even more passionate writers like you who aren’t afraid to mention how they believe. At all times follow your heart.
You made various nice points there. I did a search on the matter and found mainly people will consent with your blog.
Hi there! This post couldn’t be written any better! Reading through this post reminds me of my previous room mate! He always kept talking about this. I will forward this article to him. Pretty sure he will have a good read. Thank you for sharing!
Hi my friend! I wish to say that this article is awesome, nice written and include almost all important infos. I’d like to look more posts like this.
This is a topic close to my heart cheers, where are your contact details though?
“Франшиза автомойки” от нас подразумевает полную поддержку и совместные усилия. Мы тесно взаимодействуем с каждым из наших партнеров.
Good day! Do you know if they make any plugins to assist with Search Engine Optimization? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results. If you know of any please share. Appreciate it!
Great data, Regards.|
The crux of your writing whilst sounding reasonable initially, did not really sit perfectly with me after some time. Somewhere throughout the sentences you were able to make me a believer unfortunately only for a very short while. I however have a problem with your jumps in assumptions and one would do well to help fill in all those gaps. In the event you can accomplish that, I will undoubtedly end up being fascinated.
{
Pretty! This was a really wonderful post. Thanks for providing this information.
Wohh precisely what I was looking for, thankyou for putting up.
Would love to forever get updated great web site! .
[url=https://mcadvair.online/]generic advair 2019[/url]
Hello, i think that i saw you visited my weblog so i came to “return the favor”.I’m trying to find things to enhance my site!I suppose its ok to use some of your ideas!!
Very informative and superb body structure of written content, now that’s user genial (:.
Some truly nice and useful info on this internet site, as well I think the layout contains good features.
Nicely put, Appreciate it.|
Your article helped me a lot, is there any more related content? Thanks!
Thank you for the sensible critique. Me & my neighbor were just preparing to do some research about this. We got a grab a book from our local library but I think I learned more from this post. I am very glad to see such great information being shared freely out there.
Wow! Thank you! I always wanted to write on my blog something like that. Can I take a part of your post to my site?
Thanks for sharing superb informations. Your website is very cool. I am impressed by the details that you¦ve on this site. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched all over the place and just couldn’t come across. What a perfect web site.
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point. You definitely know what youre talking about, why throw away your intelligence on just posting videos to your blog when you could be giving us something informative to read?
Outstanding post, you have pointed out some superb details , I besides conceive this s a very superb website.
I like this post, enjoyed this one thanks for posting.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Some truly good information, Gladiola I observed this.
I’m not that much of a online reader to be honest but your sites really nice, keep it up! I’ll go ahead and bookmark your website to come back in the future. Cheers
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
I’ve read some good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to make such a magnificent informative site.
Some really interesting details you have written.Aided me a lot, just what I was searching for : D.
Really nice style and good content material, hardly anything else we require : D.
I conceive this internet site holds some really wonderful info for everyone :D. “Laughter is the sun that drives winter from the human face.” by Victor Hugo.
you have a great blog here! would you like to make some invite posts on my blog?
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
You really make it appear so easy together with your presentation but I in finding this topic to be actually something which I feel I might never understand. It sort of feels too complex and extremely vast for me. I am looking ahead on your subsequent submit, I will attempt to get the cling of it!
Thank you for sharing excellent informations. Your website is so cool. I am impressed by the details that you have on this web site. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for more articles. You, my pal, ROCK! I found just the info I already searched all over the place and just could not come across. What a great web-site.
Hi, just required you to know I he added your site to my Google bookmarks due to your layout. But seriously, I believe your internet site has 1 in the freshest theme I??ve came across. It extremely helps make reading your blog significantly easier.
You could definitely see your skills within the paintings you write. The sector hopes for more passionate writers like you who are not afraid to say how they believe. Always follow your heart.
Hello my friend! I want to say that this article is awesome, nice written and include approximately all significant infos. I would like to see more posts like this.
I was curious if you ever considered changing the page layout of your website? Its very well written; I love what youve got to say. But maybe you could a little more in the way of content so people could connect with it better. Youve got an awful lot of text for only having 1 or two images. Maybe you could space it out better?
It’s actually a great and helpful piece of info. I’m satisfied that you simply shared this useful information with us. Please keep us informed like this. Thanks for sharing.
I have recently started a blog, the information you provide on this site has helped me greatly. Thanks for all of your time & work.
That is the right weblog for anyone who desires to search out out about this topic. You realize so much its virtually hard to argue with you (not that I really would need…HaHa). You undoubtedly put a brand new spin on a topic thats been written about for years. Nice stuff, just nice!
Hi , I do believe this is an excellent blog. I stumbled upon it on Yahoo , i will come back once again. Money and freedom is the best way to change, may you be rich and help other people.
Great blog you’ve got here.. It’s hard to find high-quality writing like yours these days. I really appreciate people like you! Take care!!
Hello There. I found your blog using msn. This is an extremely well written article. I will make sure to bookmark it and come back to read more of your useful information. Thanks for the post. I will definitely return.
Заказать такси https://taxi-gukovo.ru эконом в Гуково дешево с отзывами, ценами и телефонами, онлайн заказ.
Wow! Thank you! I continuously wanted to write on my blog something like that. Can I implement a portion of your post to my website?
Современные финансовые организации предлагают взять [url=https://zajmy24.ru/]деньги в кредит[/url] на различных условиях, что дает возможность подобрать оптимальный вариант для себя.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
seo продвижение по трафику https://process-seo.ru
сервисный центр iphone в москве адреса
Howdy! Do you know if they make any plugins to help with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good results. If you know of any please share. Thanks!
Thanks for finally writing about > %blog_title% < Liked it!
Секреты выбора лучшего генератора Generac, советы по выбору генератора Generac.
Почему стоит выбрать генератор Generac?, подробный обзор генератора Generac.
Как получить бесперебойное электроснабжение с помощью генератора Generac, рекомендации.
Настоящее качество: генераторы Generac, подробный обзор.
Почему генераторы Generac так популярны?, характеристики.
Как выбрать генератор Generac для дома, советы эксперта.
Генератор Generac: лучший источник резервного питания, плюсы использования.
Как выбрать генератор Generac для эффективного резервного энергоснабжения, подробный обзор.
Генератор Generac для обеспечения непрерывного электроснабжения, советы по установке.
Как выбрать генератор Generac для вашего дома?, характеристики.
купить газовые генераторы generac [url=https://generac-generatory1.ru/]купить газовые генераторы generac[/url] .
ремонт телефона
ремонт телефонов
ремонт телевизоров
Профессиональный сервисный центр по ремонту сотовых телефонов, смартфонов и мобильных устройств.
Мы предлагаем: ремонт телефонов поблизости
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту сотовых телефонов, смартфонов и мобильных устройств.
Мы предлагаем: ремонт телефонов по близости
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту сотовых телефонов, смартфонов и мобильных устройств.
Мы предлагаем: ближайший ремонт телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту ноутбуков, imac и другой компьютерной техники.
Мы предлагаем:ремонт imac с гарантией
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту ноутбуков и компьютеров.дронов.
Мы предлагаем:адреса ремонта ноутбуков
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Авторские джип-туры по Крыму https://м-драйв.рф/tours/dyhanie-prirody/ из Ялты. Уникальная возможность исследовать самые живописные места Крыма.
Test avto drinks https://alamaret.com my given sale
ремонт айфона в москве недорого рядом
ремонт iwatch
Профессиональный сервисный центр по ремонту холодильников и морозильных камер.
Мы предлагаем: ремонт холодильников с выездом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
вавада рабочее на сегодня vavada xyz
вавада бесплатные вращения вавада коды
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/vi/register?ref=WTOZ531Y
vavada рабочее зеркало официальный сайт вавады
vavada casino сайт vavada вавада xyz
Профессиональный сервисный центр по ремонту ноутбуков и компьютеров.дронов.
Мы предлагаем:ремонт ноутбуков
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервис центры бытовой техники петербург
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
apple watch ремонт
Профессиональный сервисный центр по ремонту планетов в том числе Apple iPad.
Мы предлагаем: ipad ремонт
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту холодильников и морозильных камер.
Мы предлагаем: мастерска по ремонту холодильников
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
order balloons with delivery order balloons with delivery Dubai
Good info. Lucky me I reach on your website by accident, I bookmarked it.
Профессиональный сервисный центр по ремонту радиоуправляемых устройства – квадрокоптеры, дроны, беспилостники в том числе Apple iPad.
Мы предлагаем: ремонт камеры квадрокоптера
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники
Если вы искали где отремонтировать сломаную технику, обратите внимание – тех профи
sapporo88 login
Если вы искали где отремонтировать сломаную технику, обратите внимание – сервисный центр в екб
Your place is valueble for me. Thanks!…
Профессиональный сервисный центр по ремонту планетов в том числе Apple iPad.
Мы предлагаем: ipad ремонт москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники в петербурге
Если вы искали где отремонтировать сломаную технику, обратите внимание – сервис центр в москве
Профессиональный сервисный центр по ремонту радиоуправляемых устройства – квадрокоптеры, дроны, беспилостники в том числе Apple iPad.
Мы предлагаем: ремонт дронов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт техники в екатеринбурге
seo продвижение сайтов в москве недорого продвижение сайтов в москве
Профессиональный сервисный центр по ремонту ноутбуков и компьютеров.дронов.
Мы предлагаем:сервисный ремонт ноутбуков москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в санкт петербурге
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники в москве
оптимизация сайтов москва цена продвижение сайтов в москве
Если вы искали где отремонтировать сломаную технику, обратите внимание – техпрофи
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона в москве недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
ремонт телефонов
Профессиональный сервисный центр по ремонту источников бесперебойного питания.
Мы предлагаем: ремонт ибп стоимость
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
ремонт плазменного телевизора цена
writing an engineering resume template for engineering resume
как активировать промокод вавада vavada рабочее зеркало сейчас
Если вы искали где отремонтировать сломаную технику, обратите внимание – сервисный центр в новосибирск
free resume templates for engineers resume for engineering
сервис по ремонту телефонов москва
Профессиональный сервисный центр по ремонту источников бесперебойного питания.
Мы предлагаем: ремонт плат ибп
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи ремонт
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники
Профессиональный сервисный центр по ремонту варочных панелей и индукционных плит.
Мы предлагаем: сервисный центр варочных панелей
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
поисковое seo продвижение сайта в москве продвижение сайтов в москве
ремонт телевизора на дому в москве
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи тех сервис барнаул
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи услуги
оптимизация сайта в москве цена продвижение сайта москва
разработка и создание сайтов под ключ https://seo-5.ru
салон нового hyundai solaris хендай солярис 2024 цена
vibration analysis
The Value of Vibration Regulation Tools in Mechanical Systems
Across industrial sites, machines and rotating systems are the support of production. However, a of the highly widespread concerns that can obstruct their operation along with longevity exists as vibration. Oscillation might result in an variety of issues, from reduced exactness along with performance resulting in heightened erosion, eventually resulting in pricey interruptions as well as fixes. This scenario is why resonance control equipment becomes essential.
Why Vibration Management is Necessary
Oscillation inside machinery may cause various negative outcomes:
Reduced Operational Effectiveness: Excessive vibration can result in discrepancies as well as instability, minimizing total performance of such devices. This might result in slower production schedules along with higher electricity usage.
Increased Deterioration: Ongoing oscillation speeds up the damage of machinery parts, leading to more frequent servicing and the possibility of unexpected unexpected issues. This not only elevates operating costs and shortens the longevity of the devices.
Security Hazards: Unmanaged resonance can introduce considerable safety risks both to both the machinery and the operators. In extreme situations, severe cases, it may lead to catastrophic equipment breakdown, endangering operators and leading to extensive destruction in the environment.
Accuracy and Quality Problems: For fields which demand high accuracy, for example industrial sectors and aerospace, vibrations can lead to discrepancies in production, producing flawed products as well as greater waste.
Economical Options towards Vibration Control
Investing in vibration control systems is not only a necessity and also a sound investment for any industry that relies on machines. Our cutting-edge vibration management systems are engineered to remove vibrations from various machinery or rotating machinery, guaranteeing smooth and efficient operations.
One thing that sets these equipment apart is its reasonable pricing. It is recognized that the importance of affordability within the modern competitive marketplace, which is why we provide premium vibration control solutions at pricing that are affordable.
By selecting our systems, you are not just preserving your equipment and improving its operational effectiveness but also investing into the long-term success of your operations.
Conclusion
Vibration management is a necessary aspect in ensuring the operational performance, protection, and lifetime of your industrial equipment. With these reasonably priced resonance mitigation apparatus, you can make sure your production operate seamlessly, your products are of high quality, and all personnel remain safe. Don’t let vibration affect your operations—invest in the right equipment now.
Digital gaming platforms deliver an engaging selection of games, many of these now feature virtual currency as a payment option. Among the leading casinos, BC Game, Fortune Panda Casino, Axe Casino, and Bitkingz Casino are gaining popularity, while Bitstarz Casino is notable with many accolades. Cloudbet Casino is notable for operating as a regulated crypto casino, guaranteeing player security and fair play, as well as Fair Spin Casino together with MB Casino provide a wide range of digital currency games.
Regarding dice-based games, digital currency casinos such as Bitcoin Dice offer an exhilarating experience, enabling gamblers to bet on Bitcoin and other virtual currencies like Ethereum, Litecoin, Dogecoin, Binance Coin, and USDT.
To casino enthusiasts, choosing the right casino provider is crucial. Thunderkick Casino, Play and Go, Red Tiger Casino, Quick Spin, Pragmatic Play Casino, Playtech, Nolimit City, NetEnt, ELK Studio Games, and Microgaming are among the best providers recognized for their unique slot games, exciting graphics, and simple user interfaces.
Casino streams is now another thrilling method for bettors to engage in online gambling. Top streamers like Classy Beef, Roshtein, Labowsky, DeuceAce, and X-Posed stream their gameplay, commonly sharing big wins and providing insight into winning strategies for casino games.
Additionally, sites like BC Game Casino, Bitkingz Casino, and Rocketpot also feature Plinko-style games, a favorite game with basic rules with large possibilities for big wins.
Understanding responsible gaming, rebate offers, and anonymous gaming in crypto casinos is necessary for bettors trying to improve their experience. Deciding on the right wallet, finding no-signup casinos, and getting tips for games such as Aviator Casino Game help players to stay informed while enjoying the thrill of casino gaming.
prawo jazdy kat t
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, ninecasino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni ninecasino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le opzioni di prelievo di Nine Casino, che sono rapide e sicure.
Uno dei punti di forza di Nine Casino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere free spins e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’app di Nine Casino oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il download dell’app di Nine Casino e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “nine casino e sicuro?” La risposta e si: Nine Casino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra recensione di Nine Casino per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino recensioni [url=https://casinonine-bonus.com/]https://casinonine-bonus.com/[/url] .
ремонт фотокамер
замена венцов красноярск
Когда выполняется демонтаж с заменой венцов, тогда бревно также разгружается от веса и осуществляется демонтаж и монтаж, потому что для замены подъём строения не выше 10-ти сантиметров, что не является значительным включая для внутренней обустройства.
нижний брус из лиственных пород гораздо надежнее и превосходно доказал свои качества благодаря своей крепостью и нечувствительностью к гниению. Однако, данную балку также необходимо обработать с помощью биоцидного раствора, как и прочие перекладины.
Наша компания занимается не лишь реконструкцией объектов, помимо этого обновлением полов. Клиенты нередко подают заявку на теплые полы с термической термоизоляцией наши специалисты Укомплектовываем заказ комплектующими и обеспечиваем особые цены.
Se stai cercando un’esperienza di gioco emozionante e sicura, ninecasino e la scelta giusta per te. Con un’interfaccia user-friendly e un login semplice, Nine Casino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le nine casino recensioni sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le nine casino prelievo, che sono rapide e sicure.
Uno dei punti di forza di ninecasino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere free spins e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’nine casino app oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il nine casino app download e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: Nine Casino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra recensione di Nine Casino per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino recensioni [url=https://casinonine-it.com/]https://casinonine-it.com/[/url] .
Dicho volante de equilibrado con cesta de embrague constituye un procedimiento esencial a fin de asegurar el rendimiento excelente del motor y la transferencia de un transporte. El desbalance en dicha unidad podria causar oscilaciones, estrepito, desgaste acelerado de los piezas e llegando a problemas. Historicamente, el equilibrado se efectuaba una vez retirar el rotativo del motor, no obstante las desarrollos contemporaneas viabilizan ejecutar el mencionado proceso directamente en el vehiculo, lo que esto ahorra duracion y gastos.
Como se entiende el Desbalance?
El desajuste constituye una condicion en la donde la cantidad de un pieza giratoria (en este escenario, el girador de nivelacion con canasto de embrague) se localiza de forma irregular en comparacion a su eje de giro. Esto produce esfuerzos centrifugos que causan temblores.
Causas fundamentales del Desbalance del Volante de Estabilizacion con Recipiente de Embrague:
Desviaciones de manufactura y montaje: Aun pequenas divergencias en la estructura de los partes llegan a provocar desajuste.
Uso y danos: El funcionamiento prolongado, el exceso de calor y los desperfectos mecanicos tienden a cambiar la peso y provocar en falta de equilibrio.
Colocacion o reparacion incorrecta: Una instalacion deficiente de la recipiente de embrague o servicios deficientes tambien pueden causar desequilibrio.
Se stai cercando un’esperienza di gioco emozionante e sicura, Nine Casino e la scelta giusta per te. Con un’interfaccia user-friendly e un accesso facile, ninecasino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni di Nine Casino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le nine casino prelievo, che sono rapide e sicure.
Uno dei punti di forza di ninecasino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere free spins e altri premi grazie ai nine casino bonus senza deposito. E anche disponibile un nine casino no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’nine casino app oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il nine casino app download e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: ninecasino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra recensione di Nine Casino per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino e legale in italia [url=https://nine-casino-italia.com/]https://nine-casino-italia.com/[/url] .
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры по ремонту техники в екб
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту варочных панелей и индукционных плит.
Мы предлагаем: ремонт электрических панели
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
мастерская фотоаппаратов
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Se stai cercando un’esperienza di gioco emozionante e sicura, Nine Casino e la scelta giusta per te. Con un’interfaccia user-friendly e un login semplice, ninecasino offre un’ampia gamma di giochi che soddisferanno tutti i gusti. Le recensioni ninecasino sono estremamente positive, evidenziando la sua affidabilita e sicurezza. Molti giocatori apprezzano le opzioni di prelievo di Nine Casino, che sono rapide e sicure.
Uno dei punti di forza di ninecasino e il suo generoso nine casino bonus benvenuto, che permette ai nuovi giocatori di iniziare con un vantaggio. Inoltre, puoi ottenere free spins e altri premi grazie ai bonus senza deposito. E anche disponibile un no deposit bonus per coloro che desiderano provare senza rischiare i propri soldi.
Scarica l’app di Nine Casino oggi stesso e scopri l’emozione del gioco online direttamente dal tuo dispositivo mobile. Il download dell’app di Nine Casino e semplice e veloce, permettendoti di giocare ovunque ti trovi. Molti si chiedono, “Nine Casino e sicuro?” La risposta e si: ninecasino e completamente legale in Italia e garantisce un ambiente di gioco sicuro e regolamentato. Se vuoi saperne di piu, leggi la nostra nine casino recensione per scoprire tutti i vantaggi di giocare su questa piattaforma incredibile.
nine casino app [url=https://nine-casino-italy.com/]https://nine-casino-italy.com/[/url] .
В магазине напольных покрытий вы можете получить консультация специалиста: обратитесь к продавцу-консультанту в магазине, чтобы получить профессиональную помощь в выборе напольного покрытия. Он поможет определиться с необходимым количеством материала, подскажет о способах укладки и уходе ламината, кварцвинила и паркетной доски. https://ламинат1.рф/
Паркетная доска – это тип напольного покрытия, состоящий из деревянных планок, которые укладываются в виде палубной доски. Она отличается высокой долговечностью и прочностью, а также придает интерьеру теплую и уютную атмосферу. Паркетная доска может быть изготовлена из различных пород дерева и иметь различные оттенки и текстуры, что позволяет подобрать подходящий вариант под любой стиль помещения. https://kvarcvinil3.ru/
volante de equilibrado con cesta de embrague
Dicho volante de equilibrado con recipiente de embrague representa un metodo fundamental para asegurar el rendimiento excelente del propulsion y la impulsion de un transporte. El desequilibrio en la mencionada parte tiende a causar vibraciones, ruido, deterioro rapido de los piezas e hasta fallas. Anteriormente, el balanceo se llevaba a cabo luego de sacar el volador del propulsion, sin embargo las innovaciones actuales facilitan ejecutar tal proceso sin intermediarios en el vehiculo, lo cual ahorra plazo y gastos.
Como se entiende el Desajuste?
El desajuste es una circunstancia en la que la volumen de un cuerpo rotativo (en este ejemplo, el rotativo de nivelacion con compartimento de embrague) se reparte de manera desequilibrada respecto a su eje de rotacion de giro. Lo cual produce tensiones centrifugas que provocan vibraciones.
Principales causas del Desbalance del Volador de Equilibrado con Cesta de Embrague:
Irregularidades de construccion y union: Aun insignificantes variaciones en la diseno de los piezas tienden a provocar desequilibrio.
Desgaste y danos: El uso prolongado, el altas temperaturas y los danos mecanicos tienden a afectar la volumen y provocar en desajuste.
Colocacion o reparacion incorrecta: Una ensamblaje inapropiada de la recipiente de embrague o mantenimientos inadecuados asimismo llegan a provocar desbalance.
Если вы искали где отремонтировать сломаную технику, обратите внимание – техпрофи
slot853
наркологическая скорая в москве [url=www.skoraya-narkologicheskaya-pomoshch11.ru]наркологическая скорая в москве[/url] .
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи челябинск
духовные ретриты что это https://ретриты.рф
ретрит перезагрузка https://ретриты.рф
Профессиональный сервисный центр по ремонту фото техники от зеркальных до цифровых фотоаппаратов.
Мы предлагаем: отремонтировать фотоаппарат
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
娛樂城推薦與優惠詳解
在現今的娛樂世界中,線上娛樂城已成為眾多玩家的首選。無論是喜歡真人遊戲、老虎機還是體育賽事,每個玩家都能在娛樂城中找到自己的樂趣。以下是一些熱門的娛樂城及其優惠活動,幫助您在選擇娛樂平台時做出明智的決定。
各大熱門娛樂城介紹
1. 富遊娛樂城
富遊娛樂城以其豐富的遊戲選擇和慷慨的優惠活動吸引了大量玩家。新會員只需註冊即可免費獲得體驗金 $168,無需儲值即可輕鬆試玩。此外,富遊娛樂城還提供首存禮金 100% 獎勵,最高可領取 $1000。
2. AT99娛樂城
AT99娛樂城以高品質的遊戲體驗和優秀的客戶服務聞名。該平台提供各種老虎機和真人遊戲,並定期推出新遊戲,讓玩家保持新鮮感。
3. BCR娛樂城
BCR娛樂城是一個新興的平台,專注於提供豐富的體育賽事投注選項。無論是足球、籃球還是其他體育賽事,BCR都能為玩家提供即時的投注體驗。
熱門遊戲推薦
WM真人視訊百家樂
WM真人視訊百家樂是許多玩家的首選,該遊戲提供了真實的賭場體驗,並且玩法簡單,容易上手。
戰神賽特老虎機
戰神賽特老虎機以其獨特的主題和豐富的獎勵機制,成為老虎機愛好者的最愛。該遊戲結合了古代戰神的故事背景,讓玩家在遊戲過程中感受到無窮的樂趣。
最新優惠活動
富遊娛樂城註冊送體驗金
富遊娛樂城新會員獨享 $168 體驗金,無需儲值即可享受全場遊戲,讓您無壓力地體驗不同遊戲的魅力。
VIP 日日返水無上限
富遊娛樂城為 VIP 會員提供無上限的返水優惠,最高可達 0.7%。此活動讓玩家在遊戲的同時,還能享受額外的回饋。
結論
選擇合適的娛樂城不僅能為您的遊戲體驗增色不少,還能通過各種優惠活動獲得更多的利益。無論是新會員還是資深玩家,都能在這些推薦的娛樂城中找到適合自己的遊戲和活動。立即註冊並體驗這些優質娛樂平台,享受無限的遊戲樂趣!
ретрит комплекс https://ретриты.рф
Магазин кондиционеров: Ваше решение для комфорта и климата
Добро пожаловать в наш интернет-магазин кондиционеров в Москве и Московской области!
Наша цель – предложить вам самое лучшее оборудование для создания идеального климата в вашем доме или офисе. Мы гордимся тем, что являемся официальным дилером таких известных брендов, как Toshiba, Energolux, Haier, Gree и других. Это гарантирует, что вся представленная продукция сертифицирована и соответствует самым высоким стандартам качества.
Почему выбирают нас?
Официальный дилер. Мы работаем напрямую с производителями, что гарантирует вам оригинальные товары и официальную гарантию на всю продукцию.
Гарантия лучшей цены. Мы уверены в конкурентоспособности наших цен и предлагаем вам лучшие условия для покупки.
Быстрая доставка. Независимо от вашего местоположения в Московской области, мы доставим заказ в кратчайшие сроки.
Бесплатный замер. Каждый наш клиент получает услугу бесплатного замера, что позволяет подобрать оборудование, идеально подходящее для вашего помещения.
Хиты продаж
Среди самых популярных моделей в нашем ассортименте можно выделить:
TOSHIBA RAS-B10E2KVG-E/RAS-10E2AVG-EE SEIYA NEW – Это оборудование нового поколения, отличающееся высокой энергоэффективностью и бесшумной работой. Цена: 85 900 ?.
Сплит-система Energolux GENEVA SAS07G3-AI/SAU07G3-AI – Идеальный выбор для тех, кто ищет баланс между качеством и ценой. Цена: 47 700 ?.
Сплит-система Gree Bora GWH09AAA/K3NNA2A – Лидер продаж, известный своей надежностью и эффективностью охлаждения. Цена: 40 040 ?.
Сплит-система HAIER FLEXIS AS25S2SF2FA-W / 1U25S2SM3FA – Очень тихая модель, которая идеально подходит для установки в спальнях и детских комнатах. Цена: 88 900 ?.
Услуги и акции
Мы предлагаем бесплатный замер для всех наших клиентов. Эта услуга позволяет избежать ошибок при выборе оборудования и обеспечить максимальную эффективность системы кондиционирования.
Кроме того, в нашем магазине регулярно проводятся акции, которые позволяют вам существенно сэкономить на покупке климатической техники. Не пропустите возможность воспользоваться уникальными предложениями!
Доставка и установка
Мы предлагаем услуги доставки и установки кондиционеров по всей Московской области, включая такие города, как Балашиха, Химки, Подольск, Люберцы, Красногорск и другие. Наши специалисты быстро и профессионально установят оборудование, чтобы вы могли наслаждаться комфортом в кратчайшие сроки.
ретрит программа https://ретриты.рф
Pentingnya Memilih Game Pulsa di Situs DJ88
DJ88 adalah situs game deposit pulsa terkemuka di Indonesia, yang menawarkan berbagai jenis game online yang lengkap dan mudah diakses. Dengan hanya satu ID, Anda dapat menikmati seluruh permainan yang tersedia di situs ini. Keunggulan DJ88 bukan hanya pada variasi game yang ditawarkan, tetapi juga pada layanan deposit pulsa yang praktis, menggunakan XL atau Telkomsel dengan potongan terendah dibandingkan situs lain. Anda juga bisa melakukan deposit melalui OVO, Gopay, Dana, atau melalui minimarket seperti Indomaret dan Alfamart.
Keamanan dan Kepercayaan yang Terjaga
DJ88 memiliki lisensi resmi dari PAGCOR (Philippine Amusement Gaming Corporation), yang menjamin keamanan dan kenyamanan bermain. Sistem keamanan di situs ini menggunakan metode enkripsi termutakhir, didukung oleh server hosting cepat dan tampilan modern. Hal ini menjadikan DJ88 sebagai salah satu agen game online terpercaya di Indonesia, yang selalu berkomitmen untuk menjaga kepercayaan para pemain sebagai prioritas utama.
Beragam Pilihan Game dan Layanan Pelanggan yang Ramah
Situs ini menawarkan berbagai jenis game online, termasuk yang disiarkan secara LIVE dengan host cantik dan kamera yang merekam secara real-time, memberikan pengalaman bermain yang lebih menarik. Selain itu, DJ88 juga dikenal dengan promo menarik seperti welcome bonus 20%, bonus deposit harian, dan cashback yang disesuaikan dengan kebutuhan pemain.
Pelayanan pelanggan di DJ88 sangat profesional dan siap melayani Anda 24 jam non-stop melalui Live Chat, WhatsApp, Facebook, dan media sosial lainnya. Dengan semua keunggulan ini, DJ88 menjadi pilihan utama bagi para penggemar game online di Indonesia yang mencari pengalaman bermain yang aman, nyaman, dan menguntungkan.
Как выбрать профессионалов по перетяжке мягкой мебели в Минске
Доверьте свою мебель профессионалам
Индивидуальный подход к каждому клиенту
Опытные мастера по перетяжке мебели
Идеи для перетяжки мягкой мебели в Минске
Специализированные услуги по перетяжке мебели
Уникальный подход к перетяжке мягкой мебели
Отзывы клиентов о перетяжке мебели в Минске
Выгодные условия сотрудничества
Творческий подход к перетяжке мебели
Мы сделаем вашу мебель стильной и современной
Как обновить мебель с минимальными затратами
Получите предварительную оценку на перетяжку мягкой мебели
Современные технологии в перетяжке мягкой мебели
Как заказать перетяжку мебели онлайн
Трикотажные и велюровые ткани для мебели
Мы уверены в качестве наших услуг
Эксклюзивные решения для перетяжки мягкой мебели в Минске
перетяжка мягкой мебели [url=https://t.me/s/peretyazhka_mebeli_bel/]перетяжка мебели[/url] .
Как сэкономить на перетяжке мягкой мебели
Подробнее о процессе перетяжки мягкой мебели в Минске
Ткани для мебели: преимущества и недостатки
Профессиональные мастера по перетяжке мягкой мебели
Оригинальный дизайн для мебели
Эксклюзивные решения для вашей мебели
Оцените стоимость перетяжки мягкой мебели
Как заказать перетяжку мягкой мебели дистанционно
Модные решения для перетяжки мебели в Минске
Как выбрать профессионалов по перетяжке мягкой мебели в Минске
Преимущества заказной перетяжки мягкой мебели
Где можно быстро и качественно перетянуть мягкую мебель в Минске
Discover the best prices on Marc Jacobs at the marc jacobs outlet.
Le как вводить промокод в 1хбет на телефон. Enregistrez-vous des a present avec notre code promotionnel 1xBet valable jusqu’en 2024 pour beneficier d’un bonus de 200% sur votre premier depot. Utilisez le code de bonus lors de l’ouverture de votre nouveau compte 1xbet afin de recevoir votre bonus de bienvenue de 130$. L’enregistrement est autorise pour les personnes ayant atteint l’age de 18 ans et residant dans les pays ou l’activite du bookmaker n’est pas limitee au niveau legislatif.
Отличный вариант для тех, кто любит рисковать | Выигрывайте крупные суммы на Casino Kometa com | Играйте в захватывающие игры с высокими шансами на выигрыш | Бонусы и акции для постоянных игроков | Погрузитесь в мир азарта в любое удобное для вас время | Проводите время с пользой на Casino Kometa com | Находите игру по своему вкусу на Casino Kometa com | Первоклассные игровые автоматы и настольные игры ждут вас | Наслаждайтесь азартом где угодно и когда угодно с Casino Kometa com | Играйте с мобильного устройства без ограничений с Casino Kometa com | Играйте в азартные игры без риска на Casino Kometa com | Безопасно и уверенно играйте в азартные игры с нами | Быстрая регистрация и простая процедура входа на сайт | На Casino Kometa com доступны уникальные игры и последние новинки | Обновляйте свой игровой опыт с помощью новинок на Casino Kometa com
kometa casino online [url=https://t.me/s/cazinotopnews/154/]kometa casino войти[/url] .
Pin up casino official Puk up casino website – login and play online
download instagram stories [url=www.anon-inst.com]download instagram stories[/url] .
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт техники в краснодаре
Pin up casino official Pil up casino website – login and play online
Профессиональный сервисный центр по ремонту фото техники от зеркальных до цифровых фотоаппаратов.
Мы предлагаем: ремонт фотоаппаратов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту планшетов в Москве.
Мы предлагаем: ремонт планшета
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в новосибирске
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Discover the world of excitement at Pin Up Casino, the world’s leading online casino. The official website Puk up offers more than 4,000 slot machines. Play online for real money or for free using the working link today
Ретрит http://ретриты.рф международное обозначение времяпрепровождения, посвящённого духовной практике. Ретриты бывают уединённые и коллективные; на коллективных чаще всего проводится обучение практике медитации.
mandalika77
Very good info. Lucky me I ran across your website by chance (stumbleupon).
I’ve book marked it for later!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники в краснодаре
Если вы искали где отремонтировать сломаную технику, обратите внимание – выездной ремонт бытовой техники в казани
Профессиональный сервисный центр по ремонту планшетов в Москве.
Мы предлагаем: ремонт планшетов на дому
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
круглосуточная наркологическая помощь москва [url=https://www.skoraya-narkologicheskaya-pomoshch12.ru]https://www.skoraya-narkologicheskaya-pomoshch12.ru[/url] .
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры по ремонту техники в новосибирске
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
娛樂城推薦
娛樂城推薦與優惠詳解
在現今的娛樂世界中,線上娛樂城已成為眾多玩家的首選。無論是喜歡真人遊戲、老虎機還是體育賽事,每個玩家都能在娛樂城中找到自己的樂趣。以下是一些熱門的娛樂城及其優惠活動,幫助您在選擇娛樂平台時做出明智的決定。
各大熱門娛樂城介紹
1. 富遊娛樂城
富遊娛樂城以其豐富的遊戲選擇和慷慨的優惠活動吸引了大量玩家。新會員只需註冊即可免費獲得體驗金 $168,無需儲值即可輕鬆試玩。此外,富遊娛樂城還提供首存禮金 100% 獎勵,最高可領取 $1000。
2. AT99娛樂城
AT99娛樂城以高品質的遊戲體驗和優秀的客戶服務聞名。該平台提供各種老虎機和真人遊戲,並定期推出新遊戲,讓玩家保持新鮮感。
3. BCR娛樂城
BCR娛樂城是一個新興的平台,專注於提供豐富的體育賽事投注選項。無論是足球、籃球還是其他體育賽事,BCR都能為玩家提供即時的投注體驗。
熱門遊戲推薦
WM真人視訊百家樂
WM真人視訊百家樂是許多玩家的首選,該遊戲提供了真實的賭場體驗,並且玩法簡單,容易上手。
戰神賽特老虎機
戰神賽特老虎機以其獨特的主題和豐富的獎勵機制,成為老虎機愛好者的最愛。該遊戲結合了古代戰神的故事背景,讓玩家在遊戲過程中感受到無窮的樂趣。
最新優惠活動
富遊娛樂城註冊送體驗金
富遊娛樂城新會員獨享 $168 體驗金,無需儲值即可享受全場遊戲,讓您無壓力地體驗不同遊戲的魅力。
VIP 日日返水無上限
富遊娛樂城為 VIP 會員提供無上限的返水優惠,最高可達 0.7%。此活動讓玩家在遊戲的同時,還能享受額外的回饋。
結論
選擇合適的娛樂城不僅能為您的遊戲體驗增色不少,還能通過各種優惠活動獲得更多的利益。無論是新會員還是資深玩家,都能在這些推薦的娛樂城中找到適合自己的遊戲和活動。立即註冊並體驗這些優質娛樂平台,享受無限的遊戲樂趣!
Профессиональный сервисный центр по ремонту видео техники а именно видеокамер.
Мы предлагаем: ремонт камер
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
娛樂城推薦與優惠詳解
在現今的娛樂世界中,線上娛樂城已成為眾多玩家的首選。無論是喜歡真人遊戲、老虎機還是體育賽事,每個玩家都能在娛樂城中找到自己的樂趣。以下是一些熱門的娛樂城及其優惠活動,幫助您在選擇娛樂平台時做出明智的決定。
各大熱門娛樂城介紹
1. 富遊娛樂城
富遊娛樂城以其豐富的遊戲選擇和慷慨的優惠活動吸引了大量玩家。新會員只需註冊即可免費獲得體驗金 $168,無需儲值即可輕鬆試玩。此外,富遊娛樂城還提供首存禮金 100% 獎勵,最高可領取 $1000。
2. AT99娛樂城
AT99娛樂城以高品質的遊戲體驗和優秀的客戶服務聞名。該平台提供各種老虎機和真人遊戲,並定期推出新遊戲,讓玩家保持新鮮感。
3. BCR娛樂城
BCR娛樂城是一個新興的平台,專注於提供豐富的體育賽事投注選項。無論是足球、籃球還是其他體育賽事,BCR都能為玩家提供即時的投注體驗。
熱門遊戲推薦
WM真人視訊百家樂
WM真人視訊百家樂是許多玩家的首選,該遊戲提供了真實的賭場體驗,並且玩法簡單,容易上手。
戰神賽特老虎機
戰神賽特老虎機以其獨特的主題和豐富的獎勵機制,成為老虎機愛好者的最愛。該遊戲結合了古代戰神的故事背景,讓玩家在遊戲過程中感受到無窮的樂趣。
最新優惠活動
富遊娛樂城註冊送體驗金
富遊娛樂城新會員獨享 $168 體驗金,無需儲值即可享受全場遊戲,讓您無壓力地體驗不同遊戲的魅力。
VIP 日日返水無上限
富遊娛樂城為 VIP 會員提供無上限的返水優惠,最高可達 0.7%。此活動讓玩家在遊戲的同時,還能享受額外的回饋。
結論
選擇合適的娛樂城不僅能為您的遊戲體驗增色不少,還能通過各種優惠活動獲得更多的利益。無論是新會員還是資深玩家,都能在這些推薦的娛樂城中找到適合自己的遊戲和活動。立即註冊並體驗這些優質娛樂平台,享受無限的遊戲樂趣!
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники
апостиль в новосибирске
перевод документов
Если вы искали где отремонтировать сломаную технику, обратите внимание – тех профи
перевод документов
перевод с иностранных языков
перевод с иностранных языков
перевод с иностранных языков
перевод с иностранных языков
перевод с иностранных языков
перевод документов
Профессиональный сервисный центр по ремонту видео техники а именно видеокамер.
Мы предлагаем: ремонт цифровой видеокамеры
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
апостиль в новосибирске
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники в нижнем новгороде
апостиль в новосибирске
перевод с иностранных языков
перевод с иностранных языков
перевод с иностранных языков
перевод документов
перевод с иностранных языков
апостиль в новосибирске
перевод документов
перевод с иностранных языков
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи ремонт
апостиль в новосибирске
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Взрослый остеопат Ростов
This is the right blog for anyone who wants to find out about this topic. You realize so much its almost hard to argue with you (not that I actually would want…HaHa). You definitely put a new spin on a topic thats been written about for years. Great stuff, just great!
апостиль в новосибирске
sapporo88
target88
апостиль в новосибирске
перевод с иностранных языков
самые гениальные идеи бизнеса [url=http://biznes-idei12.ru]самые гениальные идеи бизнеса[/url] .
перевод документов
перевод документов
перевод с иностранных языков
Профессиональный сервисный центр по ремонту стиральных машин с выездом на дом по Москве.
Мы предлагаем: сервисные центры по ремонту стиральных машин
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в казани
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
замена венцов
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники в новосибирске
I’d have to verify with you here. Which is not something I often do! I get pleasure from reading a publish that can make people think. Additionally, thanks for allowing me to remark!
blackpanth
Если вы искали где отремонтировать сломаную технику, обратите внимание – тех профи
Профессиональный сервисный центр по ремонту стиральных машин с выездом на дом по Москве.
Мы предлагаем: ремонт стиральной машины москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в казани
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Мануальный терапевт в Ростове-на-Дону
Массаж в Ростове
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
подъем дома
Если вы искали где отремонтировать сломаную технику, обратите внимание – тех профи
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи ремонт
JILI SLOT – Permainan Slot Terbaik Kami
JILI GAMES menawarkan berbagai permainan slot, kartu, dan tembak ikan dengan lebih dari 100 game yang berbeda. Selalu menjadi yang terdepan dalam industri, JILI GAMES terus merilis produk game terbaru secara konsisten.
Game Slot JILI
JILI SUPER ACE
JILI Pharaoh Treasure
JILI Cực Tốc 777
JILI Đế quốc hoàng kim
JILI Bảo thạch Kala
JILI Quyền Vương
Top 10 game slot JILI sangat populer di kalangan pemain, dengan tema yang bervariasi dan fitur jackpot yang menarik.
Game Tembak Ikan JILI
JILI Chuyên Gia Săn Rồng
JILI Jackpot Fishing
JILI Phi Long Tàng Bảo
JILI Happy Fishing
JILI Đoạt bảo truyền kỳ
Permainan tembak ikan ini menawarkan pengalaman seru dan interaktif, di mana pemain dapat memenangkan hadiah besar dengan menembak ikan dan naga.
Game Kartu JILI
Baccarat
Color Game
Sic Bo
LUDO Quick
Super Bingo
Game kartu JILI menawarkan berbagai pilihan permainan klasik dan modern yang menarik untuk dimainkan.
Layanan dari JILI SLOT
Multi-Platform
Semua permainan kami tersedia dalam format HTML5, sehingga dapat dimainkan di berbagai perangkat seperti komputer, tablet, dan ponsel pintar dengan performa yang sempurna.
Dukungan
JILI SLOT menyediakan panduan yang mudah dipahami, membantu pemain dengan cepat menguasai aturan permainan.
JILI Jackpot
Semua pemain, baik dengan taruhan besar maupun kecil, memiliki kesempatan untuk memenangkan JILI Jackpot.
Dukungan 24/7
Layanan pelanggan tersedia sepanjang waktu untuk memastikan semua kebutuhan pemain JILI SLOT terpenuhi.
Multi-Bahasa
Kami mendukung berbagai bahasa dan mata uang untuk melayani pemain di seluruh dunia.
Promosi JILI
JILI Slot menawarkan banyak promosi yang memungkinkan pemain untuk dengan mudah bergabung dan menikmati berbagai permainan yang tersedia. Cukup bergabung dengan JILI City untuk mendapatkan penawaran ini dan mulai bermain di slot, permainan kartu, atau tembak ikan.
Nikmati pengalaman bermain game yang seru dan menguntungkan hanya di JILI SLOT!
RGBET – NHÀ CÁI UY TÍN TẠI VIỆT NAM
Trong bối cảnh cá cược trực tuyến ngày càng phát triển, RGBET đã nhanh chóng trở thành sự lựa chọn hàng đầu cho người chơi Việt Nam. Với hệ thống cá cược đa dạng, chất lượng dịch vụ vượt trội, RGBET mang đến trải nghiệm cá cược an toàn và thú vị.
Đa Dạng Về Trò Chơi
RGBET cung cấp nhiều sản phẩm cá cược phong phú như cá cược thể thao, casino trực tuyến, slot game và bắn cá.
Cá cược thể thao: Cung cấp hàng nghìn trận đấu bóng đá, bóng rổ, tennis với tỷ lệ cược cạnh tranh từ các giải đấu lớn trên thế giới.
Casino trực tuyến: Baccarat, Blackjack và Roulette mang đến trải nghiệm như tại sòng bạc thực thụ với chất lượng hình ảnh cao.
Slot game và bắn cá: Các trò chơi như slot game và bắn cá tại RGBET có giao diện đẹp mắt, dễ chơi và cơ hội trúng thưởng lớn.
Dịch Vụ Chăm Sóc Khách Hàng
RGBET cung cấp dịch vụ hỗ trợ khách hàng 24/7, đảm bảo người chơi được giúp đỡ kịp thời và tận tình. Điều này giúp người chơi an tâm khi cá cược, không gặp rắc rối về mặt kỹ thuật.
Bảo Mật Và An Toàn
RGBET chú trọng đến việc bảo mật thông tin và tài sản của người chơi, sử dụng công nghệ mã hóa hiện đại để đảm bảo an toàn tuyệt đối trong mọi giao dịch.
Khuyến Mãi Hấp Dẫn
RGBET thường xuyên có các chương trình khuyến mãi như thưởng chào mừng cho người chơi mới và các chương trình ưu đãi hàng tuần giúp gia tăng cơ hội chiến thắng.
Nền Tảng Đa Thiết Bị
Người chơi có thể truy cập RGBET trên máy tính, điện thoại hoặc máy tính bảng mà không lo về chất lượng. Công nghệ HTML5 đảm bảo các trò chơi hoạt động mượt mà trên mọi thiết bị.
Kết Luận
RGBET là nhà cái uy tín, cung cấp môi trường cá cược an toàn, trò chơi đa dạng và các chương trình khuyến mãi hấp dẫn. Đây là sự lựa chọn hoàn hảo cho những ai muốn trải nghiệm cá cược trực tuyến chất lượng cao.
target88
Вывод из запоя на дому в Алматы [url=http://fizioterapijakeskic.com]http://fizioterapijakeskic.com[/url] .
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: сервис по ремонту игровых консолей
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
datatogel
I believe this is among the such a lot vital info for me.
And i am glad reading your article. However wanna commentary on few basic
things, The website style is wonderful, the articles is in reality excellent : D.
Good process, cheers
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: [url=remont-videokart-gar.ru]видеокарты в москве[/url]
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Если вы искали где отремонтировать сломаную технику, обратите внимание – сервис центр в ростове на дону
Профессиональный сервисный центр по ремонту фототехники в Москве.
Мы предлагаем: накамерная вспышка ремонт
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Подробнее на сайте сервисного центра remont-vspyshek-realm.ru
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: надежный сервис ремонта игровых консолей
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту компьютероной техники в Москве.
Мы предлагаем: лучшие сервисы по ремонту компьютеров
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Great! Thank you so much for sharing this. I can’t wait to use it.
Профессиональный сервисный центр по ремонту фото техники от зеркальных до цифровых фотоаппаратов.
Мы предлагаем: отремонтировать проектор
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
что нужно людям [url=https://biznes-idei13.ru/]что нужно людям[/url] .
вип эскорт
Профессиональный сервисный центр по ремонту компьютерных видеокарт по Москве.
Мы предлагаем: [url=remont-videokart-gar.ru]цены на ремонт видеокарт[/url]
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
RGBET – Lựa Chọn Hàng Đầu Trong Thế Giới Cá Cược Trực Tuyến
Trong bối cảnh ngành công nghiệp cá cược trực tuyến đang phát triển mạnh mẽ, việc tìm kiếm một nhà cái uy tín là điều vô cùng quan trọng đối với những người đam mê cá cược. Giữa vô vàn sự lựa chọn, RGBET đã nhanh chóng nổi lên như một trong những nhà cái hàng đầu, mang đến trải nghiệm cá cược an toàn, công bằng và đầy thú vị cho người chơi.
Trải Nghiệm Cá Cược Toàn Diện
RGBET cung cấp một danh mục trò chơi cá cược đa dạng, từ các môn thể thao, casino trực tuyến, đến các trò chơi slot và nhiều hình thức cá cược khác. Người chơi có thể dễ dàng tìm thấy loại hình cá cược yêu thích với tỷ lệ cược cạnh tranh và giao diện thân thiện, giúp tối ưu trải nghiệm của người dùng.
Dịch Vụ Chăm Sóc Khách Hàng Tận Tình
Một trong những yếu tố giúp RGBET nổi bật là dịch vụ chăm sóc khách hàng chuyên nghiệp và tận tình. Hỗ trợ 24/7, RGBET luôn sẵn sàng giải đáp mọi thắc mắc và xử lý vấn đề của người chơi một cách nhanh chóng. Đội ngũ hỗ trợ được đào tạo bài bản, luôn lắng nghe và hỗ trợ người chơi với sự tận tâm cao nhất.
Tỷ Lệ Cược Cạnh Tranh
RGBET cung cấp tỷ lệ cược hấp dẫn và cạnh tranh, đảm bảo người chơi có cơ hội tối đa hóa lợi nhuận. Dù bạn là người mới bắt đầu hay một tay chơi cá cược kỳ cựu, RGBET đều mang đến cơ hội để bạn gia tăng thắng lợi trong mọi lần đặt cược.
An Toàn và Bảo Mật
Với hệ thống bảo mật hiện đại, RGBET cam kết đảm bảo an toàn cho toàn bộ thông tin cá nhân và tài khoản của người chơi. Hệ thống mã hóa dữ liệu tiên tiến giúp người chơi yên tâm khi thực hiện các giao dịch, từ nạp tiền đến rút tiền.
Nhiều Ưu Đãi Hấp Dẫn
Không chỉ vậy, RGBET còn thường xuyên tung ra các chương trình khuyến mãi hấp dẫn dành cho người chơi mới lẫn người chơi lâu năm. Những ưu đãi này giúp tăng thêm giá trị cho mỗi lần đặt cược và mang đến nhiều cơ hội thắng lớn.
Vì Sao Bạn Nên Chọn RGBET?
Uy tín hàng đầu: RGBET đã khẳng định vị thế của mình trong thế giới cá cược trực tuyến.
Dịch vụ chuyên nghiệp: Chăm sóc khách hàng chu đáo, hỗ trợ kịp thời mọi lúc.
Tỷ lệ cược cạnh tranh: Mang lại cơ hội thắng cao hơn cho người chơi.
Bảo mật tuyệt đối: An toàn cho mọi giao dịch và thông tin cá nhân.
Khuyến mãi đa dạng: Luôn có những ưu đãi tốt nhất cho người chơi.
Tất cả những yếu tố này làm cho RGBET trở thành sự lựa chọn hàng đầu của bất kỳ ai muốn tham gia vào thế giới cá cược trực tuyến. Hãy khám phá và trải nghiệm những điều tuyệt vời mà RGBET mang lại ngay hôm nay!
nhà cái uy tín
RGBET – Lựa Chọn Hàng Đầu Trong Thế Giới Cá Cược Trực Tuyến
Trong bối cảnh ngành công nghiệp cá cược trực tuyến đang phát triển mạnh mẽ, việc tìm kiếm một nhà cái uy tín là điều vô cùng quan trọng đối với những người đam mê cá cược. Giữa vô vàn sự lựa chọn, RGBET đã nhanh chóng nổi lên như một trong những nhà cái hàng đầu, mang đến trải nghiệm cá cược an toàn, công bằng và đầy thú vị cho người chơi.
Trải Nghiệm Cá Cược Toàn Diện
RGBET cung cấp một danh mục trò chơi cá cược đa dạng, từ các môn thể thao, casino trực tuyến, đến các trò chơi slot và nhiều hình thức cá cược khác. Người chơi có thể dễ dàng tìm thấy loại hình cá cược yêu thích với tỷ lệ cược cạnh tranh và giao diện thân thiện, giúp tối ưu trải nghiệm của người dùng.
Dịch Vụ Chăm Sóc Khách Hàng Tận Tình
Một trong những yếu tố giúp RGBET nổi bật là dịch vụ chăm sóc khách hàng chuyên nghiệp và tận tình. Hỗ trợ 24/7, RGBET luôn sẵn sàng giải đáp mọi thắc mắc và xử lý vấn đề của người chơi một cách nhanh chóng. Đội ngũ hỗ trợ được đào tạo bài bản, luôn lắng nghe và hỗ trợ người chơi với sự tận tâm cao nhất.
Tỷ Lệ Cược Cạnh Tranh
RGBET cung cấp tỷ lệ cược hấp dẫn và cạnh tranh, đảm bảo người chơi có cơ hội tối đa hóa lợi nhuận. Dù bạn là người mới bắt đầu hay một tay chơi cá cược kỳ cựu, RGBET đều mang đến cơ hội để bạn gia tăng thắng lợi trong mọi lần đặt cược.
An Toàn và Bảo Mật
Với hệ thống bảo mật hiện đại, RGBET cam kết đảm bảo an toàn cho toàn bộ thông tin cá nhân và tài khoản của người chơi. Hệ thống mã hóa dữ liệu tiên tiến giúp người chơi yên tâm khi thực hiện các giao dịch, từ nạp tiền đến rút tiền.
Nhiều Ưu Đãi Hấp Dẫn
Không chỉ vậy, RGBET còn thường xuyên tung ra các chương trình khuyến mãi hấp dẫn dành cho người chơi mới lẫn người chơi lâu năm. Những ưu đãi này giúp tăng thêm giá trị cho mỗi lần đặt cược và mang đến nhiều cơ hội thắng lớn.
Vì Sao Bạn Nên Chọn RGBET?
Uy tín hàng đầu: RGBET đã khẳng định vị thế của mình trong thế giới cá cược trực tuyến.
Dịch vụ chuyên nghiệp: Chăm sóc khách hàng chu đáo, hỗ trợ kịp thời mọi lúc.
Tỷ lệ cược cạnh tranh: Mang lại cơ hội thắng cao hơn cho người chơi.
Bảo mật tuyệt đối: An toàn cho mọi giao dịch và thông tin cá nhân.
Khuyến mãi đa dạng: Luôn có những ưu đãi tốt nhất cho người chơi.
Tất cả những yếu tố này làm cho RGBET trở thành sự lựa chọn hàng đầu của bất kỳ ai muốn tham gia vào thế giới cá cược trực tuyến. Hãy khám phá và trải nghiệm những điều tuyệt vời mà RGBET mang lại ngay hôm nay!
перевод документов
услуга эскорт москва эскорт услуги модели москва
эскорт услуги девушки москва девушки эскорт услуги в москве
Друзья, если планируете обновить ванную комнату, советую обратить внимание на один интернет-магазин раковин и ванн. У них действительно большой ассортимент товаров от ведущих производителей. Можно найти всё: от простых моделей до эксклюзивных дизайнерских решений.
Я искал умывальник для ванной, и они предложили несколько вариантов по хорошей цене. Качество продукции на высоком уровне, всё сертифицировано. Порадовало и то, что они предлагают профессиональные консультации и услуги по установке. Доставка была быстрой, всё пришло в целости и сохранности. Отличный магазин с хорошим сервисом!
перевод документов
эскорт услуги проститутки москвы эскорт агентства в москве услуги
Профессиональный сервисный центр по ремонту компьютерных блоков питания в Москве.
Мы предлагаем: ремонт блоков питания corsair
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
мужчина в эскорт услуге в москве эскорт москва услуги фото
Если у вас сломался телефон, советую этот сервисный центр. Я сам там чинил свой смартфон и остался очень доволен. Отличное обслуживание и разумные цены. Подробнее можно узнать здесь: срочный ремонт мобильных телефонов.
<a href=”https://remont-kondicionerov-wik.ru”>ремонт кондиционеров</a>
ремонт техники профи в самаре
Попробуйте свои силы в казино от Cryptoboss, станьте победителем вместе с королем криптовалютных игр, возможность выиграть крупный джекпот, освойте мир криптовалютных игр в казино Cryptoboss, выиграть криптовалюты легко в Cryptoboss casino, захватывающий азарт с криптовалютным боссом, испытайте свою удачу в казино Cryptoboss, эксклюзивное казино для ценителей криптовалют, удивительные возможности в казино от Cryptoboss, Cryptoboss casino – ваш путь к криптовалютному успеху, встречайте новый уровень криптовалютных ставок в Cryptoboss casino, играйте на криптовалютных волнах вместе с Cryptoboss, получите криптовалютные призы в Cryptoboss casino, Cryptoboss casino – выбор тех, кто ценит качество, попробуйте удачу вместе с Cryptoboss, присоединяйтесь к лидерам в мире криптовалютных игр с Cryptoboss casino.
криптобосс игровые [url=https://ikea-expert.ru/]cryptoboss casino boss[/url] .
??Увеличьте производительность своего проекта с VPS/VDS !??
??Почему стоит выбрать нас???
??Высокое качество сервиса без высокой цены! Наши тарифы начинаются от 2,3 руб/день, что делает аренду VPS/VDS доступной для любого бюджета.
??Мощные конфигурации! Выберите тариф от 1 до 4 ядер и от 1 до 8 ГБ оперативной памяти, чтобы ваш проект работал быстро и стабильно.
??Обширное хранилище! Получите от 10 до 150 ГБ пространства для хранения, чтобы размещать все необходимые данные.
??Безлимитный трафик! Наслаждайтесь неограниченным объемом трафика до 32 ТБ, чтобы ваши посетители могли наслаждаться быстрой загрузкой контента.
??Высокая скорость подключения! Наш VPS/VDS предлагает скорость подключения к сети 1 Гбит/с, чтобы ваш проект работал плавно и без задержек.
??Простота управления! Легко управляйте своим VPS/VDS через удобную панель управления, доступную 24/7.
??Безопасность и надежность! Наши серверы защищены надежными системами безопасности, чтобы гарантировать сохранность ваших данных.
??Техническая поддержка! Наша дружелюбная команда поддержки готова помочь вам в любое время, чтобы решить любые проблемы, которые могут возникнуть.
??Не упустите возможность получить надежный и производительный VPS/VDS по выгодной цене!??
??Закажите свой тариф прямо сейчас и получите бесплатный период тестирования!??
Жмите?? КЛИК ??
эскорт москва услуги девочки эскорт услуга москве
услуги эскорта в москве цены сайт эскорт услуг в москве
Как кодируются от алкоголя в Алматы [url=https://kodirovanie-ot-alkoholizma-v-almaty.kz/]Как кодируются от алкоголя в Алматы [/url] .
поиск объявления по номеру телефона [url=https://www.poisk-po-nomery.ru]поиск объявления по номеру телефона[/url] .
эскорт услуга в москве мужские эскорт услуга в москве недорого
эскорт женские услуги в москве работа эскорт услуги в москве
Играйте в Cryptoboss Casino и выигрывайте больше всех
cryptoboss casino официальный сайт зеркало [url=https://101optovik.ru/]cryptoboss casino официальный[/url] .
בריאים גברים מגלים את המיניות שלהם בגיל צעיר את הישבנים העגלגלים; אלו שעושים לך חשק לחפון אותם בשתי ידייך. דמיין את השדיים ולגברים. יתכן כי הביולוגיה העניקה לנשים את היכולת לשים לפעמים את הסקס בצד. אך אישה הרוצה לנהל מערכת יחסים טובה עם הגבר אינה Meet hot Independent escort Tel Aviv girls
Denk je aan de goede oude tijd toen er home buttons en bubble icons waren? Er is een manier om het allemaal terug te brengen en die gevoelens terug te brengen. Een app genaamd OldOS (via the Verge) herstelt iOS 4 naar de nieuwe iPhone. Ontdek meer – https://mashable.com/article/iphone-3g-oldos
Успешная регистрация на сайте cryptoboss casino – ваш шанс на крупный выигрыш, Cryptoboss casino: регистрация проходит быстро и просто, Играйте с удовольствием после регистрации на cryptoboss casino, Присоединяйтесь к cryptoboss casino и станьте частью игрового сообщества, Станьте частью cryptoboss casino уже сегодня, Не упустите возможность зарегистрироваться на cryptoboss casino и выиграть крупный приз, Cryptoboss casino рад приветствовать новых игроков – зарегистрируйтесь прямо сейчас, Зарегистрируйтесь на cryptoboss casino и окунитесь в захватывающий мир азартных игр, Регистрация на cryptoboss casino – ваш первый шаг к большим выигрышам, Зарегистрируйтесь на cryptoboss casino и получите доступ к лучшим игровым автоматам, Станьте участником cryptoboss casino – зарегистрируйтесь и начните играть сегодня, Регистрация на сайте cryptoboss casino – ваш первый шаг к азартным приключениям, Пройдите регистрацию на cryptoboss casino и получите шанс выиграть крупный джекпот, Уникальные бонусы ждут вас после регистрации на cryptoboss casino, Не упустите возможность зарегистрироваться на cryptoboss casino и испытать азартные ощущения, Регистрация на cryptoboss casino – ваш шанс на удачу.
криптобосс регистрация cryptoboss casino3 one [url=https://auto-adventures.ru/]криптобосс промокод при регистрации hds5[/url] .
Профессиональный сервисный центр по ремонту компьютероной техники в Москве.
Мы предлагаем: сервис компьютеров
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
перевод документов
Заблокировано? Не беда! Находите актуальные зеркала Cryptoboss Casino здесь, играйте без проблем!
Попробуйте свою удачу на новом зеркале Cryptoboss Casino, полный контроль гарантированы.
Лучшее зеркало Cryptoboss Casino ждет вас прямо сейчас, забудьте об другие варианты!
Новости и выигрыши ждут вас на зеркале Cryptoboss Casino, не пропустите свой шанс!
Самое надежное зеркало Cryptoboss Casino только у нас, получайте удовольствие без лишних хлопот!
криптобосс зеркало рабочее [url=https://motorola-profi.ru/]cryptoboss зеркало[/url] .
לך לעצור את הבלאגן של בחיים. הנערות יפנקו אותך המענה לצרכים הרגשיים שלהם במסגרת הנישואין או היחסים הזוגיים שבהם הם נמצאים. וכך לבלות. יש דירות דיסקרטיות בתל אביב, והן זמינות 24 שעות ביממה. מאמר 3 דירות לבלות עם נערות ליווי באילת בכל שעה ובכל יום ניתן try this web-site
перевод с иностранных языков
перевод с иностранных языков
Профессиональный сервисный центр по ремонту камер видео наблюдения по Москве.
Мы предлагаем: ремонт камер видеонаблюдения
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Cryptoboss Casino радует бездепозитным бонусом, восхитительное предложение!
Бездепозитный бонус поможет вам выиграть большую сумму в Cryptoboss Casino – отличный способ испытать свою удачу.
Уникальные возможности для игры без вложений в Cryptoboss Casino – новые призы для вас.
Эксклюзивный бездепозитный бонус в Cryptoboss Casino – играйте и выигрывайте без риска.
Бездепозитный бонус доступен для всех в Cryptoboss Casino – уникальные преимущества для игры на деньги.
Уникальные возможности для игры без вложений в Cryptoboss Casino – заработайте крупный выигрыш без риска.
Получите бездепозитный бонус и начните играть в Cryptoboss Casino – отличный старт для вашей игры.
Бездепозитный бонус – это реальность в Cryptoboss Casino – возможно, это ваш шанс стать миллионером.
Получите шанс выиграть крупный джекпот без вложений в Cryptoboss Casino – новые призы и возможности для вас.
cryptoboss бездепозитный бонус hds5 [url=https://pitaka-trade.ru/]криптобосс дают ли бонус на день рождения[/url] .
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в нижнем новгороде
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Фирма «Кинематика»: Качественные продукты для индустриальной балансировки и анализов промышленного оборудования
Фирма «Кинематика» специализируется на разработке и производстве прецизионных систем для сбалансированности и контроля промышленного оборудования. Продукция компании востребована для обслуживания и ремонта различных промышленных устройств, включая воздуходувки, дробилки, карданные агрегаты, системы передачи и металлообрабатывающие станки.
Основополагающие продукты фирмы:
1. Модуль Арбаланс — переносной виброметр-балансировщик
Инструмент предназначен для сбалансированности оборудования агрегатов в вместе с подшипниками в собственных подшипниках. Арбаланс обеспечивает надёжную точность балансировки с минимальными затратами. Главные достоинства:
Программа расчета: не требует участия оператора.
Вибрационный график: выявляют неисправности.
Два канала измерения: обеспечивает измерение вибрации параллельно в двух измерениях, повышая производительность процесса.
Цена: 84 000 руб.
2. Balcom-1A — переносной вибродиагностический прибор
Балком-1А создан для уравновешивания роторных систем в системных подшипниках. Главной особенностью является удобство эксплуатации и автоматическая система вычислений. Система дополнена:
Двойная виброизмерительная система.
Спектральный анализ для контроля состояния оборудования.
Цена: 73 000 руб.
3. Модуль Балком-2 — прибор для измерений для систем балансировки
Модуль Балком-2 применяется в измерительных станциях для виброизмерений. Он предлагает точность сбалансированности систем и другого оборудования в технике.
Цена: от 90000 рублей до 95000 рублей в зависимости от оборудования.
4. Балком-4 — для балансировки в нескольких плоскостях карданных механизмов
Прибор Балком-4 создан для уравновешивания валов и внедряется в промышленных системах. Этот система гарантирует высокую точность и надежность при уравновешивании в разных направлениях.
Цена: от 100 000 руб. до 126 тыс. руб..
Передовые системы отслеживания и диагностики
Фирма «Кинематика» также создает системы для постоянного контроля техники и механизмов. Эти устройства применяют индуктивные датчики для контроля вибрации и других показателей. Например, система Реконт позволяет отслеживать состояние редукторов по точности работы механизмов и оборудованию вращения.
лаки джет игра lucky jet 1win
апостиль в новосибирске
переносная балансировочная машина
Предприятие «Кинематика»: Эффективные разработки для индустриальной сбалансированности и анализов промышленного оборудования
Фирма «Кинематика» фокусируется на изготовлении и внедрении прецизионных систем для сбалансированности и контроля техники. Товары компании эксплуатируется для техобслуживания и техобслуживания различных техномеханизмов, включая вентиляторы, мельницы, карданные агрегаты, системы передачи и прецизионные станки.
Основные решения предприятия:
1. Arbalance — компактный балансировочный виброметр
Система создан для сбалансированности оборудования агрегатов в заводской сборке в штатных подшипниках. Устройство Арбаланс гарантирует надёжную точность производственных процессов с минимальными затратами. Среди его ключевых преимуществ:
Автоматизированная система расчета: полностью автоматизирована.
Графики вибрации и спектральный анализ: находят проблемы.
Двухканальная система: обеспечивает измерение вибрации одновременно в двух осях, улучшая результаты.
Цена: 84 тыс. руб.
2. Модуль Балком-1А — переносной прибор балансировки
Балком-1А подходит для балансировки вращательных механизмов в собственных подшипниках. Главной особенностью является удобство эксплуатации и автоматическая система вычислений. Прибор также поддерживает:
Два канала измерения вибрации.
Аналитическая система для контроля состояния механизмов.
Цена: 73 000 руб.
3. Балком-2 — прибор для измерений для станций балансировки
Модуль Балком-2 внедряется в измерительных станциях для измерения колебаний. Он предлагает возможность прецизионной балансировки роторов и других механизмов в производстве.
Цена: от 90000 руб. до 95 тыс. руб. в зависимости от устройства.
4. Balcom-4 — для многоплоскостной балансировки карданных механизмов
Балком-4 разработан для балансировки карданов и эксплуатируется в индустриальных установках. Этот устройство даёт качественные результаты и высокую точность при многоплоскостной балансировке.
Цена: от 100000 рублей до 126000 рублей.
Современные технологии мониторинга и проверки
Фирма «Кинематика» также разрабатывает системы для постоянного контроля техники. Эти комплексы используют бесконтактными сенсорами для виброизмерений и различных параметров. Например, модуль Реконт позволяет отслеживать состояние редукторов по параметрам кинематической точности и скорости вращения.
Игровые автоматы на сайте Cryptoboss Casino, для азартных игроков.
Играйте на деньги в автоматах Cryptoboss Casino, для любителей крупных выигрышей.
Играйте и выигрывайте на игровых слотах в казино Cryptoboss, для тех, кто ищет адреналин.
Увлекательные автоматы ждут вас на сайте Cryptoboss Casino, для азартных игроков.
Развлекайтесь в казино Cryptoboss на лучших автоматах, и выигрывайте крупные суммы на реальные деньги.
Самые популярные автоматы в казино Cryptoboss, для тех, кто готов испытать фарт.
Наслаждайтесь игрой в автоматы на сайте Cryptoboss Casino, для азартных игроков.
На сайте Cryptoboss ждут увлекательные слоты, для любителей азартных игр.
Играйте в лучшие слоты на сайте Cryptoboss Casino, которые покорят вас своими возможностями.
Проведите время с пользой, играя в автоматы на сайте Cryptoboss Casino, для любителей азартных игр.
Не пропустите уникальные предложения для игры в казино Cryptoboss на автоматах, для тех, кто мечтает об успехе.
Лучшие игровые автоматы в казино Cryptoboss, где каждый может стать победителем.
Погрузитесь в мир азарта, играя на сайте Cryptoboss Casino на автоматах, для тех, кто мечтает о крупном выигрыше.
Игровые автоматы в казино Cryptoboss, которые порадуют вас выигрышами.
Развлекайтесь играя на сайте Cryptoboss Casino на увлекательных слотах, где каждый может стать победителем.
Попробуйте свою удачу в казино Cryptoboss, для азартных игроков.
Лучшие игровые автоматы на сайте Cryptoboss, где каждый может испыт
cryptoboss casino игровые автоматы [url=https://zasport.su/]cryptoboss casino автоматы[/url] .
Как поднять настроение подруге с помощью прикольного анекдота
апостиль в новосибирске
курс китайского юаня к тенге [url=www.kursy-valut-online.kz]курс китайского юаня к тенге[/url] .
Текущий курс валют в Казахстане: актуальная информация
Способы отслеживания курса валют в Казахстане
Доллар, евро, рубль: актуальный курс в Казахстане
Прогноз курса валют в Казахстане
Секреты выгодного обмена валюты в Казахстане
курс юаня [url=https://kursy-valut-online.kz/]курс валют в алматы[/url] .
перевод с иностранных языков
ремонт фундамента
Профессиональный сервисный центр по ремонту кнаручных часов от советских до швейцарских в Москве.
Мы предлагаем: ремонт часов москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы искали где отремонтировать сломаную технику, обратите внимание – [url=https://tyumen.profi-teh-remont.ru]тех профи[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в перми
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
ремонт фундамента
[url=https://remont-kondicionerov-wik.ru]сервисный центр кондиционеров[/url]
замена венцов
замена венцов
Профессиональный сервисный центр по ремонту парогенераторов в Москве.
Мы предлагаем: починить парогенератор
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
замена венцов
Если вы искали где отремонтировать сломаную технику, обратите внимание – ремонт бытовой техники
ремонт фундамента
большой рюкзак для путешествий
школьный ранец oxford
Eiffel Tower Guided Climbing tour by stairs to second floor
We provide the best personalized Eiffel Tower tours with experienced, local and 5-star rated guides. Whether on a solo visit to Paris, France, visiting with friends or looking to surprise your loved ones, you are in for an eclectic tour experience with our guide. Come have a memorable Eiffel Tower walking trip, boat cruise, and summit elevator view at night with us.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры в красноярске
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
рюкзак школьный девочки легкий
Что такое мемы и как они появились
модный рюкзак 2024 в школу
Если вы искали где отремонтировать сломаную технику, обратите внимание – техпрофи
Слоты: классические слоты, видеослоты, прогрессивные джекпоты. Настольные игры: рулетка, блэкджек, баккара, покер. Видеопокер: различные варианты видеопокера. Live-казино: игры с живыми дилерами. онлайн казино рейтинг loqwvmjtar
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в красноярске
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
https://www.youtube.com/watch?v=NntCT5Wllvo/
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Санитарная обработка квартиры после смерти https://dezinfekciya-ot-smerti-msk.ru/
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:ремонт крупногабаритной техники в ростове на дону
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
JILI SLOT GAMES: Sự Lựa Chọn Hàng Đầu Cho Các Tín Đồ Casino Trực Tuyến
JILI Casino là một nhà phát hành game nổi tiếng với nhiều năm kinh nghiệm trong ngành công nghiệp giải trí trực tuyến. Tại JILI, chúng tôi cam kết mang đến cho người chơi những trải nghiệm độc đáo và đẳng cấp, thông qua việc đổi mới không ngừng và cải thiện chất lượng từng sản phẩm. Những giá trị cốt lõi của chúng tôi không chỉ dừng lại ở việc tạo ra các trò chơi xuất sắc, mà còn tập trung vào việc cung cấp các tính năng vượt trội để đáp ứng nhu cầu của người chơi trên toàn cầu.
Sự Đa Dạng Trong Các Trò Chơi Slot
JILI nổi tiếng với loạt trò chơi slot đa dạng và hấp dẫn. Từ các slot game cổ điển đến những trò chơi với giao diện hiện đại và tính năng độc đáo, JILI Slot luôn đem đến cho người chơi những phút giây giải trí tuyệt vời. Các trò chơi được thiết kế với đồ họa sống động, âm thanh chân thực và những vòng quay thú vị, đảm bảo rằng người chơi sẽ luôn bị cuốn hút.
Ưu Điểm Nổi Bật Của JILI Casino
Đổi mới và sáng tạo: Mỗi trò chơi tại JILI Casino đều mang đến sự mới mẻ với lối chơi hấp dẫn và giao diện bắt mắt.
Chất lượng cao: JILI không ngừng cải tiến để đảm bảo mỗi sản phẩm đều đạt chất lượng tốt nhất, từ trải nghiệm người chơi đến tính năng trò chơi.
Nền tảng đa dạng: JILI Casino cung cấp nhiều loại game khác nhau, từ slot, bắn cá đến các trò chơi truyền thống, phù hợp với mọi sở thích của người chơi.
Chương Trình Khuyến Mại JILI
JILI Casino không chỉ nổi bật với chất lượng game mà còn thu hút người chơi bởi các chương trình khuyến mại hấp dẫn. Người chơi có thể tham gia vào nhiều sự kiện, từ khuyến mãi nạp tiền, hoàn trả đến các chương trình tri ân dành riêng cho thành viên VIP. Những ưu đãi này không chỉ tăng cơ hội chiến thắng mà còn mang lại giá trị cộng thêm cho người chơi.
Nổ Hủ City Và Các Trò Chơi Hấp Dẫn Khác
JILI không chỉ có slot games mà còn cung cấp nhiều thể loại game đa dạng khác như bắn cá, bài và nhiều trò chơi giải trí khác. Nổi bật trong số đó là Nổ Hủ City – nơi người chơi có thể thử vận may và giành được những giải thưởng lớn. Sự kết hợp giữa lối chơi dễ hiểu và các tính năng độc đáo của Nổ Hủ City chắc chắn sẽ mang lại những khoảnh khắc giải trí đầy thú vị.
Tham Gia JILI Casino Ngay Hôm Nay
Với sự đa dạng về trò chơi, các tính năng vượt trội và những chương trình khuyến mại hấp dẫn, JILI Casino là sự lựa chọn không thể bỏ qua cho những ai yêu thích trò chơi trực tuyến. Hãy truy cập trang web chính thức của JILI ngay hôm nay để trải nghiệm thế giới giải trí không giới hạn và giành lấy những phần thưởng hấp dẫn từ các trò chơi của chúng tôi!
娛樂城
DB賭場:首選線上賭場評價介紹
DB娛樂城,前身為PM遊戲平台,於2023年全面更名為【DB多寶遊戲】。這次品牌轉型的過渡,DB賭場進一步專注於帶來綜合性的線上服務體驗,為玩家提供更多的娛樂項目與革新的服務項目。無論是賭桌遊戲、運動投注還是其他流行遊戲,DB娛樂平台都能滿足玩家的期待。
多寶平台的成立與擴展 在亞洲賭場市場中,DB遊戲平台飛速興起,成為眾多玩家的熱門選擇平台之一。隨著PM集團的品牌重塑,DB多寶遊戲聚焦於提升用戶體驗,並致力於構建一個穩定、便捷且合規的賭場環境。從服務項目到支付方式,DB娛樂城不斷尋求卓越,為玩家推動最優的線上娛樂服務。
DB賭場的遊戲種類與特點
百家樂遊戲 DB娛樂城最為廣受歡迎的是其豐富的百家樂項目。平台提供多個版本的賭桌遊戲,包括常見百家樂和無手續費百家樂,迎合各種玩家的偏好。透過實時荷官的即時互動,玩家可以獲得身臨其境的遊戲氛圍。
體育博彩 作為一個綜合娛樂平台,DB遊戲平台還帶來各類體育遊戲的博彩服務。從足球、籃球賽事到網球賽事等常見運動賽事,玩家都可以隨時體驗體育博彩,體驗賽事的刺激與博彩的快感。
促銷活動與獎金 DB賭場不斷推出廣泛的促銷計畫,為新舊玩家提供各種折扣與獎勵。這些活動不僅提升了遊戲的趣味性,還為玩家帶來更多獲取獎勵的選項。
DB遊戲平台的評價與特點 在2024年的最新線上娛樂平台排行榜中,DB娛樂網站獲得了卓越評價,並且因其多樣的遊戲選擇、迅速的提款效率和廣泛的促銷活動而贏得玩家喜愛。
Смешные приколы на злобу дня
Поднимите себе настроение!
Купить морской контейнер (20 футов) 129 900? (в т.ч. НДС)
Аренда контейнера 20 футов
8 000? в месяц (в т.ч. НДС)
Размеры внешние: 6058 x 2438 x 2591 мм;
Размеры внутренние: 5905 x 2350 x 2381 мм;
Дверной проем: ширина 2336 мм, высота 2291 мм;
Масса брутто 24000 кг;
Масса тары 2200 кг;
сервисный центре предлагает ремонт тв москва – диагностика плазменного телевизора
Смешные мемы http://prikoly-shutki.ru/kartinki-prikolnye Что такое мемы.
JILI SLOT GAMES: Sự Lựa Chọn Hàng Đầu Cho Các Tín Đồ Casino Trực Tuyến
JILI Casino là một nhà phát hành game nổi tiếng với nhiều năm kinh nghiệm trong ngành công nghiệp giải trí trực tuyến. Tại JILI, chúng tôi cam kết mang đến cho người chơi những trải nghiệm độc đáo và đẳng cấp, thông qua việc đổi mới không ngừng và cải thiện chất lượng từng sản phẩm. Những giá trị cốt lõi của chúng tôi không chỉ dừng lại ở việc tạo ra các trò chơi xuất sắc, mà còn tập trung vào việc cung cấp các tính năng vượt trội để đáp ứng nhu cầu của người chơi trên toàn cầu.
Sự Đa Dạng Trong Các Trò Chơi Slot
JILI nổi tiếng với loạt trò chơi slot đa dạng và hấp dẫn. Từ các slot game cổ điển đến những trò chơi với giao diện hiện đại và tính năng độc đáo, JILI Slot luôn đem đến cho người chơi những phút giây giải trí tuyệt vời. Các trò chơi được thiết kế với đồ họa sống động, âm thanh chân thực và những vòng quay thú vị, đảm bảo rằng người chơi sẽ luôn bị cuốn hút.
Ưu Điểm Nổi Bật Của JILI Casino
Đổi mới và sáng tạo: Mỗi trò chơi tại JILI Casino đều mang đến sự mới mẻ với lối chơi hấp dẫn và giao diện bắt mắt.
Chất lượng cao: JILI không ngừng cải tiến để đảm bảo mỗi sản phẩm đều đạt chất lượng tốt nhất, từ trải nghiệm người chơi đến tính năng trò chơi.
Nền tảng đa dạng: JILI Casino cung cấp nhiều loại game khác nhau, từ slot, bắn cá đến các trò chơi truyền thống, phù hợp với mọi sở thích của người chơi.
Chương Trình Khuyến Mại JILI
JILI Casino không chỉ nổi bật với chất lượng game mà còn thu hút người chơi bởi các chương trình khuyến mại hấp dẫn. Người chơi có thể tham gia vào nhiều sự kiện, từ khuyến mãi nạp tiền, hoàn trả đến các chương trình tri ân dành riêng cho thành viên VIP. Những ưu đãi này không chỉ tăng cơ hội chiến thắng mà còn mang lại giá trị cộng thêm cho người chơi.
Nổ Hủ City Và Các Trò Chơi Hấp Dẫn Khác
JILI không chỉ có slot games mà còn cung cấp nhiều thể loại game đa dạng khác như bắn cá, bài và nhiều trò chơi giải trí khác. Nổi bật trong số đó là Nổ Hủ City – nơi người chơi có thể thử vận may và giành được những giải thưởng lớn. Sự kết hợp giữa lối chơi dễ hiểu và các tính năng độc đáo của Nổ Hủ City chắc chắn sẽ mang lại những khoảnh khắc giải trí đầy thú vị.
Tham Gia JILI Casino Ngay Hôm Nay
Với sự đa dạng về trò chơi, các tính năng vượt trội và những chương trình khuyến mại hấp dẫn, JILI Casino là sự lựa chọn không thể bỏ qua cho những ai yêu thích trò chơi trực tuyến. Hãy truy cập trang web chính thức của JILI ngay hôm nay để trải nghiệm thế giới giải trí không giới hạn và giành lấy những phần thưởng hấp dẫn từ các trò chơi của chúng tôi!
Сервисный центр предлагает ремонт бесперебойников rucelf на дому ремонт бесперебойников rucelf
You reported it effectively.|
Смешные видео на любой вкус
Поднимите себе настроение!
Прикольные мемы http://prikoly-shutki.ru/kartinki-prikolnye Что такое мемы.
http://www.evakuator-mow.ru [url=http://evakuator-mow.ru/]http://evakuator-mow.ru/[/url] .
Если вы искали где отремонтировать сломаную технику, обратите внимание – профи тех сервис воронеж
Как поднять настроение с помошью приколов. ржачные мемы
https://www.intensedebate.com/people/vychislavyakov
Explore a wide range of styles at paige jeans outlet.
DB賭場:首選線上遊戲平台評價介紹
DB遊戲平台,前身為PM遊戲平台,於2023年全面更名為【DB多寶遊戲】。本次品牌更新的過程,DB娛樂平台不斷專注於推動全方位的線上娛樂體驗,為玩家呈現多樣化的娛樂項目與創新的服務項目。無論是莊家遊戲、體育賭注還是其他流行遊戲,DB賭場都能適應玩家的需求。
多寶品牌的發展與進步 在亞洲線上娛樂市場中,DB遊戲平台快速興起,成為數不清的玩家的熱門選擇平台之一。隨著PM機構的品牌轉型,DB多寶遊戲專注於提升客戶體驗,並努力建立一個穩定、便捷且公平的賭場環境。從服務項目到交易系統,DB遊戲平台一直專注於卓越,為玩家呈現最佳的線上體驗。
DB遊戲平台的遊戲種類與優勢
百家樂遊戲 DB賭場最為知名的是其豐富的百家樂遊戲。平台帶來多個版本的賭桌遊戲,包括標準百家樂和無佣金百家樂,迎合各種玩家的偏好。透過直播荷官的同步互動,玩家可以享受沉浸式的賭桌氛圍。
體育博彩 作為一個多元化賭場,DB娛樂城還提供各類體育賽事的投注選項。從足球、籃球比賽到網球比賽等流行體育項目,玩家都可以隨時隨地參與體育博彩,感受賽事的緊張感與投注的樂趣。
促銷活動與獎金 DB娛樂城經常推出豐富的促銷優惠,為所有玩家帶來各種福利與獎金。這些活動不僅增加了遊戲的趣味性,還為玩家推動更多獲取獎勵的可能性。
DB賭場的反響與特色 在2024年的最新賭場排行榜中,DB娛樂城獲得了高度評價,並且因其多樣的遊戲選擇、迅速的提款效率和廣泛的促銷活動而贏得玩家喜愛。
Как поднять настроение с помошью анекдота. прикольные картинки
http://rem.4nmv.ru/forum/profile.php?action=show&member=2056
Купить бытовку под столовую 149 900? (в т.ч. НДС)
Аренда бытовок под столовую
8 000? в месяц (в т.ч. НДС)
внешний размер 6000х2400х2500(в);
окно ПВХ с поворотно-откидной створкой;
утепленные пол, потолок, стены;
отделка потолка панелями ПВХ;
отделка стен ДВП, линолеум на полу;
Сервисный центр предлагает выездной ремонт кофемашин grundig мастер по ремонту кофемашины grundig
Ивенты в галереях предоставят вам восторженные удивительные впечатления. Театральные представления помогают вам ощутить атмосферу. Сетевые вечеринки в предвкушении придают уверенности. Бронируйте для незабываемых ивентов с близкими!
https://festivalguru.ru/
hatch alarm clocks https://clocks-top.com
instagram stories without [url=https://anoninststories.com/]instagram stories without[/url] .
Профессиональный сервисный центр по ремонту компьютеров и ноутбуков в Москве.
Мы предлагаем: ремонт apple macbook в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
digital clocks wall simple alarm clocks
Shop stylish fashion at montbell outlet.
Сайт о биодобавках https://биодобавки.рф подробная информация о видах добавок, их действии и пользе. Рекомендации по выбору для поддержки здоровья на основе актуальных исследований.
Как поднять настроение с помошью смешных картинок. ржачные анекдоты
https://modx.pro/users/vychislavyakov
jili com
JILI SLOT GAMES: Sự Lựa Chọn Hàng Đầu Cho Các Tín Đồ Casino Trực Tuyến
JILI Casino là một nhà phát hành game nổi tiếng với nhiều năm kinh nghiệm trong ngành công nghiệp giải trí trực tuyến. Tại JILI, chúng tôi cam kết mang đến cho người chơi những trải nghiệm độc đáo và đẳng cấp, thông qua việc đổi mới không ngừng và cải thiện chất lượng từng sản phẩm. Những giá trị cốt lõi của chúng tôi không chỉ dừng lại ở việc tạo ra các trò chơi xuất sắc, mà còn tập trung vào việc cung cấp các tính năng vượt trội để đáp ứng nhu cầu của người chơi trên toàn cầu.
Sự Đa Dạng Trong Các Trò Chơi Slot
JILI nổi tiếng với loạt trò chơi slot đa dạng và hấp dẫn. Từ các slot game cổ điển đến những trò chơi với giao diện hiện đại và tính năng độc đáo, JILI Slot luôn đem đến cho người chơi những phút giây giải trí tuyệt vời. Các trò chơi được thiết kế với đồ họa sống động, âm thanh chân thực và những vòng quay thú vị, đảm bảo rằng người chơi sẽ luôn bị cuốn hút.
Ưu Điểm Nổi Bật Của JILI Casino
Đổi mới và sáng tạo: Mỗi trò chơi tại JILI Casino đều mang đến sự mới mẻ với lối chơi hấp dẫn và giao diện bắt mắt.
Chất lượng cao: JILI không ngừng cải tiến để đảm bảo mỗi sản phẩm đều đạt chất lượng tốt nhất, từ trải nghiệm người chơi đến tính năng trò chơi.
Nền tảng đa dạng: JILI Casino cung cấp nhiều loại game khác nhau, từ slot, bắn cá đến các trò chơi truyền thống, phù hợp với mọi sở thích của người chơi.
Chương Trình Khuyến Mại JILI
JILI Casino không chỉ nổi bật với chất lượng game mà còn thu hút người chơi bởi các chương trình khuyến mại hấp dẫn. Người chơi có thể tham gia vào nhiều sự kiện, từ khuyến mãi nạp tiền, hoàn trả đến các chương trình tri ân dành riêng cho thành viên VIP. Những ưu đãi này không chỉ tăng cơ hội chiến thắng mà còn mang lại giá trị cộng thêm cho người chơi.
Nổ Hủ City Và Các Trò Chơi Hấp Dẫn Khác
JILI không chỉ có slot games mà còn cung cấp nhiều thể loại game đa dạng khác như bắn cá, bài và nhiều trò chơi giải trí khác. Nổi bật trong số đó là Nổ Hủ City – nơi người chơi có thể thử vận may và giành được những giải thưởng lớn. Sự kết hợp giữa lối chơi dễ hiểu và các tính năng độc đáo của Nổ Hủ City chắc chắn sẽ mang lại những khoảnh khắc giải trí đầy thú vị.
Tham Gia JILI Casino Ngay Hôm Nay
Với sự đa dạng về trò chơi, các tính năng vượt trội và những chương trình khuyến mại hấp dẫn, JILI Casino là sự lựa chọn không thể bỏ qua cho những ai yêu thích trò chơi trực tuyến. Hãy truy cập trang web chính thức của JILI ngay hôm nay để trải nghiệm thế giới giải trí không giới hạn và giành lấy những phần thưởng hấp dẫn từ các trò chơi của chúng tôi!
DB娛樂平台:頂級線上遊戲平台評價介紹
DB娛樂網站,前身為PM娛樂城,於2023年正式更名為【DB多寶遊戲】。此次品牌重塑的階段,DB娛樂平台進一步專注於推動多角度的線上賭場體驗,為玩家帶來更廣泛的遊戲選擇與革新的遊戲服務。無論是賭桌遊戲、體育博彩還是其他常見遊戲,DB遊戲平台都能滿足玩家的興趣。
多寶平台的成立與進步 在亞洲娛樂市場中,DB娛樂城很快興起,成為大量玩家的首要選擇平台之一。隨著PM機構的品牌重塑,DB多寶遊戲致力於提升客戶體驗,並聚焦於構建一個安全、方便且公正的娛樂環境。從遊戲種類到交易系統,DB賭場一直專注於卓越,為玩家推動最優的線上娛樂服務。
DB娛樂城的遊戲項目與優勢
百家樂遊戲 DB賭場最為出名的是其多樣化的百家樂選項。平台帶來多個版本的百家樂玩法,包括標準百家樂和零佣金百家樂,適應不同玩家的期待。透過直播荷官的同步互動,玩家可以享受沉浸式的賭桌氛圍。
體育博彩 作為一個綜合娛樂平台,DB賭場還提供各類運動項目的博彩服務。從足球賽事、籃球比賽到網球等受歡迎賽事,玩家都可以任何時候體驗體育博彩,感受賽事的緊張感與下注的興奮。
促銷活動與獎金 DB娛樂網站經常推出廣泛的促銷活動,為新老玩家提供各種優惠與獎金。這些促銷不僅增強了遊戲的可玩性,還為玩家創造更多賺取紅利的途徑。
DB娛樂網站的回饋與特色 在2024年的最新賭場排行榜中,DB娛樂城獲得了高度評價,並且因其豐富的遊戲選擇、迅速的提款效率和廣泛的促銷活動而深受玩家喜愛。
Your article helped me a lot, is there any more related content? Thanks!
Профессиональный сервисный центр по ремонту кофемашин по Москве.
Мы предлагаем: обслуживание кофемашин москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в тюмени
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как поднять настроение с помошью смешных картинок. Прикольные анекдоты.
https://edcommunity.ru/profile/?ID=125416
купить строительную бытовку
Бытовки б/у (все типы бытовок). Цена по запросу (в т.ч. НДС). – цена договорная
Строительный вагончик бытовка бу
Бытовка металлическая бу
Бытовка бу для дачи
Вагончик бытовка бу
Строительный контейнер бу
Профессиональный сервисный центр по ремонту кондиционеров в Москве.
Мы предлагаем: ремонт кондиционеров в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Смешные анекдоты. История анекдотов.
Профессиональный сервисный центр по ремонту гироскутеров в Москве.
Мы предлагаем: срочный ремонт гироскутера
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту моноблоков в Москве.
Мы предлагаем: надежный сервис ремонта моноблоков
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Backlinks – three steps
1: Stage – backlinks to the site in blogs and comments
Step 2: Backlinks via website redirects
3: Stage – Placement of the site on the sites of the analyzer,
example:
https://backlinkstop.com/
Explanation for stage 3: – only the main page of the site is placed on the analyzers, subsequent pages cannot be placed.
I only need a link to the main domain, if you give me a link to a social network or other resource that is not suitable for detection on the analyzer site, then I will take the third step through a google redirect
I do three steps in sequence, as described above
This backlink strategy is the most effective as the analyzers show the site keywords H1, H2, H3 and sitemap!!!
Show placement on scraping sites via TXT file
List of site analyzers 50 pcsI will provide the report as a text file with links.
Профессиональный сервисный центр по ремонту планшетов в том числе Apple iPad.
Мы предлагаем: ремонт айпадов москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
Свежие приколы
Как появились приколы. Узнайте, как поднять себе настроение!
Прикольные анекдоты. Что такое анекдот.
Discover unique fashion pieces at citizens of humanity.
Kantorbola adalah situs gaming online terbaik di indonesia , kunjungi situs RTP kantor bola untuk mendapatkan informasi akurat rtp diatas 95% . Kunjungi juga link alternatif kami di kantorbola77 dan kantorbola99 .
Upgrade your wardrobe with fashionable shoes and clothing from ayouba.com.
Профессиональный сервисный центр по ремонту посудомоечных машин с выездом на дом в Москве.
Мы предлагаем: центр ремонта посудомоечных машин
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Прикольные анекдоты. История анекдотов.
Great! Thank you so much for sharing this. I can’t wait to use it.
эскорт в москве [url=http://www.drive-models.ru]эскорт в москве[/url] .
Как развеселить друга с помощью забавных приколов
Upgrade your style with chic fashion from forever 21.
Discover exclusive collections at stussy jeans.
Как развеселить друга с помощью смешных приколов
Как развеселить друга с помощью смешных приколов
instagram profile viewer [url=https://storyanonviewer.com/]instagram profile viewer[/url] .
Explore fashionable styles at mammut clothing.
Смешные анекдоты https://shutochki.wordpress.com/2024/09/27/smeshnye-anekdoty/
Indian porn https://desiporn.one in Hindi. Only high-quality porn videos, convenient search and regular updates.
Porn videos https://thetittyfuck.com watch online for free. A selection of high-quality porn videos, a collection of sex videos
Профессиональный сервисный центр по ремонту плоттеров в Москве.
Мы предлагаем: ремонт плоттеров принтеров
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту объективов в Москве.
Мы предлагаем: ремонт объективов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Transform your wardrobe with elegant pieces from alice and olivia clothing.
какое лечение при алкоголизме [url=https://www.xn—–7kcablenaafvie2ajgchok2abjaz3cd3a1k2h.xn--p1ai]какое лечение при алкоголизме[/url] .
Смешные еврейские анекдоты
Подними настроение
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Find exclusive deals on stylish fashion at house of cb.
want to view instagram [url=https://anstoriesview.com]want to view instagram[/url] .
instagram posts [url=http://anonstoriesview.com/]instagram posts[/url] .
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить мефедрон, купить кокаин, купить меф, купить экстази, купить альфа пвп, купить гаш в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Shop the latest trends at ag jeans.
Смешные прикольные картинки для поднятия настроения
Лучшие свежие анекдоты
Подними себе настроение
ig viewer [url=anon-story-view.com]ig viewer[/url] .
Ивенты в галереях раскроют вам удивительные вдохновляющие переживания. Презентации помогают погрузиться в атмосферу праздника. Вечеринки заранее помогают расслабиться. Заранее подбирайте для радостных ивентов вместе с близкими!
Забронировать билеты на ближайший спектакль
Профессиональный сервисный центр по ремонту сетевых хранилищ в Москве.
Мы предлагаем: ремонт сетевых хранилищ
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Веселые свежие анекдоты и шутки
Подними себе настроение
замена автостекла адреса продажа автостекол
Find unique pieces at namilia outlet.
кодировка от алкоголя капельницей https://lecheniealkgolizma.ru/
Discover unique fashion pieces at adina eden jewelry.
мостбет промокод AZ3202 рабочий мостбет промокод где взять 2024
Веселые анекдоты
Подними настроение
вывод из запоя на дому ростов-на-дону [url=http://vyvod-iz-zapoya-rostov15.ru]вывод из запоя на дому ростов-на-дону [/url] .
рабочий промокод на сегодня мостбет 2024 промокод AZ3202 рабочий мостбет как пользоваться
вывод из запоя круглосуточно ростов [url=http://vyvod-iz-zapoya-rostov16.ru/]вывод из запоя круглосуточно ростов [/url] .
rgbet
rgbet
Trong bối cảnh ngành công nghiệp cá cược trực tuyến ngày càng phát triển, việc lựa chọn một nhà cái uy tín trở nên vô cùng quan trọng đối với những người đam mê cá cược.Nhà cái RGBET nổi lên như một sự lựa chọn hàng đầu đáng để bạn quan tâm, hứa hẹn mang đến cho bạn một trải nghiệm cá cược an toàn, công bằng và thú vị. Từ các trò chơi cá cược đa dạng, dịch vụ chăm sóc khách hàng tận tình đến tỷ lệ cược cạnh tranh, Rgbet sở hữu nhiều ưu điểm vượt trội khiến bạn không thể bỏ qua.Hãy cùng khám phá những lý do tại sao bạn cần quan tâm đến nhà cái Rgbet và tại sao đây nên là lựa chọn hàng đầu của bạn trong thế giới cá cược trực tuyến.
Online casino https://qubalilar.biz/2024/10/06/1win-nigeria-review-everything-you-need-to-know with high bonuses, roulette and slots, instant payouts. Register on the official mirror.
Профессиональный сервисный центр по ремонту планшетов в Москве.
Мы предлагаем: сколько стоит заменить стекло на планшете самсунг
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как поднять себе настроение? Почитайте
смешные анекдоты и поделитесь с близкими.
Online casino https://qmlinvest.biz/2024/10/06/how-to-get-started-with-1win-nigeria with high bonuses, roulette and slots, instant payouts. Register on the official mirror.
вывод из запоя на дому ростов недорого [url=http://www.vyvod-iz-zapoya-rostov17.ru]http://www.vyvod-iz-zapoya-rostov17.ru[/url] .
Прикольные картинки. Как они появились.
Авиатор игра на деньги Авиатор игра на деньги онлайн
Aviator официальный сайт Авиатор игра
Get More Info [url=https://tronlink.pro/]tronlink pro for pc[/url]
Смешные мемы. Как они появились.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в волгограде
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
проверенные индивидуалки санкт петербург https://kykli.com/
Смешные мемы.
Casino and slot https://ostkrim.biz/2024/10/06/bc-game-nigeria-where-gamers-thrive machines online. Play slot machines with bonus, casino for money. Registration and login to the working mirror
Free online https://thetranny.com porn videos and movies. Only girls with dicks. On our site there are trans girls for every taste!
Casino and slot https://babababyacompanhantes.com.br/why-you-should-bet-on-1win-nigeria/ machines online. Play slot machines with bonus, casino for money. Registration and login to the working mirror
rgbet
RGBET: Trang Chủ Cá Cược Uy Tín và Đa Dạng Tại Việt Nam
RGBET đã khẳng định vị thế của mình là một trong những nhà cái hàng đầu tại châu Á và Việt Nam, với đa dạng các dịch vụ cá cược và trò chơi hấp dẫn. Nhà cái này nổi tiếng với việc cung cấp môi trường cá cược an toàn, uy tín và luôn mang lại trải nghiệm tuyệt vời cho người chơi.
Các Loại Hình Cá Cược Tại RGBET
RGBET cung cấp các loại hình cá cược phong phú bao gồm:
Bắn Cá: Một trò chơi đầy kịch tính và thú vị, phù hợp với những người chơi muốn thử thách khả năng săn bắn và nhận về những phần thưởng giá trị.
Thể Thao: Nơi người chơi có thể tham gia đặt cược vào các trận đấu thể thao đa dạng, từ bóng đá, bóng rổ, đến các sự kiện thể thao quốc tế với tỷ lệ cược hấp dẫn.
Game Bài: Đây là một sân chơi dành cho những ai yêu thích các trò chơi bài như tiến lên miền Nam, phỏm, xì dách, và mậu binh. Các trò chơi được phát triển kỹ lưỡng, đem lại cảm giác chân thực và thú vị.
Nổ Hũ: Trò chơi slot với cơ hội trúng Jackpot cực lớn, luôn thu hút sự chú ý của người chơi. Nổ Hũ RGBET là sân chơi hoàn hảo cho những ai muốn thử vận may và giành lấy những phần thưởng khủng.
Lô Đề: Với tỷ lệ trả thưởng cao và nhiều tùy chọn cược, RGBET là nơi lý tưởng cho những người đam mê lô đề.
Tính Năng Nổi Bật Của RGBET
Một trong những điểm nổi bật của RGBET là giao diện thân thiện, dễ sử dụng và hệ thống bảo mật tiên tiến giúp bảo vệ thông tin người chơi. Ngoài ra, nhà cái này còn hỗ trợ các hình thức nạp rút tiền tiện lợi thông qua nhiều kênh khác nhau như OVO, Gopay, Dana, và các chuỗi cửa hàng như Indomaret và Alfamart.
Khuyến Mãi và Dịch Vụ Chăm Sóc Khách Hàng
RGBET không chỉ nổi bật với các trò chơi đa dạng, mà còn cung cấp nhiều chương trình khuyến mãi hấp dẫn như bonus chào mừng, cashback, và các phần thưởng hàng ngày. Đặc biệt, dịch vụ chăm sóc khách hàng của RGBET hoạt động 24/7 với đội ngũ chuyên nghiệp, sẵn sàng hỗ trợ người chơi qua nhiều kênh liên lạc.
Kết Luận
Với những ưu điểm nổi bật về dịch vụ, bảo mật, và trải nghiệm người dùng, RGBET xứng đáng là nhà cái hàng đầu mà người chơi nên lựa chọn khi tham gia vào thế giới cá cược trực tuyến.
Explore fashionable styles at tibi clothing.
want to view instagram stories [url=http://anonimstories.com ]want to view instagram stories[/url] .
платный нарколог на дом [url=http://narkolog-na-dom-krasnodar17.ru/]платный нарколог на дом[/url] .
нарколог на дом краснодар [url=www.narkolog-na-dom-krasnodar16.ru]нарколог на дом краснодар[/url] .
nhà cái
Trong bối cảnh ngành công nghiệp cá cược trực tuyến ngày càng phát triển, việc lựa chọn một nhà cái uy tín trở nên vô cùng quan trọng đối với những người đam mê cá cược.Nhà cái RGBET nổi lên như một sự lựa chọn hàng đầu đáng để bạn quan tâm, hứa hẹn mang đến cho bạn một trải nghiệm cá cược an toàn, công bằng và thú vị. Từ các trò chơi cá cược đa dạng, dịch vụ chăm sóc khách hàng tận tình đến tỷ lệ cược cạnh tranh, Rgbet sở hữu nhiều ưu điểm vượt trội khiến bạn không thể bỏ qua.Hãy cùng khám phá những lý do tại sao bạn cần quan tâm đến nhà cái Rgbet và tại sao đây nên là lựa chọn hàng đầu của bạn trong thế giới cá cược trực tuyến.
Прикольные пошлые анекдоты.
Вызов сантехника https://santekhnik-moskva.blogspot.com/p/v-moskve.html на дом в Москве и Московской области в удобное для вас время. Сантехнические работы любой сложности, от ремонта унитаза, устранение засора, до замены труб.
Уборка домика на даче после крыс https://ochistka-gryaznyh-kvartir-msk.ru/
Смешные пошлые анекдоты.
Свежие видеоролики.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники воронеж
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Câu lạc bộ bóng đá AS Roma
ST666 tự hào là đối tác tài trợ hàng đầu của câu lạc bộ bóng đá AS Roma – một biểu tượng vĩ đại trong làng bóng đá Ý. AS Roma không chỉ là đội bóng nổi tiếng với lịch sử thi đấu ấn tượng mà còn là đối tác quan trọng trong các hợp đồng hợp tác với ST666. Với sự hợp tác này, AS Roma đã hỗ trợ nhà cái ST666 thông qua những khoản đầu tư triệu đô, giúp phát triển mạnh mẽ mảng thể thao trực tuyến và mở ra cơ hội lớn cho người chơi cá cược tại thị trường quốc tế.
Câu lạc bộ bóng đá Bayern Munich
ST666 cũng vinh dự là nhà tài trợ hàng đầu của câu lạc bộ bóng đá Bayern Munich – một đội bóng nổi tiếng không chỉ ở Đức mà còn trên toàn thế giới. Với lịch sử vô địch lẫy lừng và sự thống trị tại các giải đấu quốc tế, Bayern Munich đã trở thành biểu tượng lớn trong lòng người hâm mộ. Sự hợp tác giữa ST666 và Bayern Munich không chỉ dừng lại ở việc tài trợ mà còn góp phần nâng cao trải nghiệm của người chơi thông qua cải tiến hệ thống giao dịch tài chính, giúp quy trình nạp rút tiền của bet thủ trở nên thuận tiện và nhanh chóng hơn.
Câu lạc bộ bóng đá Porto
Không thể không nhắc đến câu lạc bộ bóng đá Porto, nơi ST666 hân hạnh trở thành đối tác tài trợ hàng đầu. Porto không chỉ là biểu tượng của sự sáng tạo và thành công trong làng bóng đá Bồ Đào Nha mà còn hỗ trợ ST666 trong các thủ tục xin giấy phép và chứng nhận tại châu Âu và Philippines. Sự hợp tác này đã mang lại giá trị lớn cho ST666 khi mở rộng quy mô hoạt động ra nhiều khu vực và thị trường mới.
Câu lạc bộ bóng đá Arsenal
Trong làng bóng đá Anh, câu lạc bộ bóng đá Arsenal là biểu tượng của sự tinh tế và phong cách. ST666 rất tự hào khi trở thành nhà tài trợ chính của Arsenal, giúp nhà cái này không chỉ nâng cao vị thế mà còn mở rộng thị trường cá cược bóng đá toàn cầu. Arsenal đã đóng vai trò quan trọng trong việc hỗ trợ ST666 phát triển hệ thống cá cược, từ đó mang lại trải nghiệm tốt nhất cho người chơi.
Câu lạc bộ bóng đá Sevilla
Cuối cùng, câu lạc bộ bóng đá Sevilla – biểu tượng của sự khát vọng và thành công trong bóng đá Tây Ban Nha, cũng đã trở thành đối tác quan trọng của ST666. Sevilla không chỉ góp phần thúc đẩy ST666 về mặt thương mại mà còn cung cấp công nghệ bảo mật hàng đầu, đảm bảo rằng thông tin cá nhân, tài khoản và các giao dịch của người chơi đều được bảo vệ một cách tối ưu.
Điểm vượt trội của ST666 so với các đối thủ cạnh tranh khác
Sự hợp tác chiến lược giữa ST666 và các câu lạc bộ bóng đá hàng đầu không chỉ nâng cao vị thế của ST666 trên thị trường, mà còn mang lại những lợi ích vượt trội cho người chơi. Những điểm mạnh này bao gồm:
Hệ thống bảo mật tiên tiến: ST666 đã được Sevilla hỗ trợ trong việc nâng cấp công nghệ bảo mật, đảm bảo mọi giao dịch và thông tin người dùng đều an toàn.
Hệ thống nạp rút tiện lợi: Sự hợp tác với Bayern Munich giúp ST666 cải tiến hệ thống giao dịch tài chính, mang lại trải nghiệm nạp rút nhanh chóng và hiệu quả cho người chơi.
Mở rộng thị trường và dịch vụ: Nhờ sự hỗ trợ từ Arsenal và AS Roma, ST666 đã thành công trong việc mở rộng hệ thống cá cược bóng đá và tiếp cận thêm nhiều người chơi trên toàn thế giới.
ST666 không chỉ là một nhà cái hàng đầu mà còn là một đối tác đáng tin cậy của các câu lạc bộ bóng đá danh tiếng, luôn cam kết mang lại dịch vụ tốt nhất và trải nghiệm tối ưu cho người chơi.
Профессиональный сервисный центр по ремонту моноблоков iMac в Москве.
Мы предлагаем: ремонт imac москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Свежие приколы https://teletype.in/@anekdoty/prikoly-nastroenie.
Свежие анекдоты про евреев https://sites.google.com/view/shutki-anekdoty/%D0%B0%D0%BD%D0%B5%D0%BA%D0%B4%D0%BE%D1%82%D1%8B-%D0%BF%D1%80%D0%BE-%D0%B5%D0%B2%D1%80%D0%B5%D0%B5%D0%B2.
Свежие картинки с надписями https://prikoly-tut.blogspot.com/2024/10/smeshnye-kartinki.html.
Свежие приколы за день https://prikolnyekartinki.mystrikingly.com/blog/0ade1e0d9a9.
Веселые пошлые анекдоты https://ru.pinterest.com/vseshutochki/%D0%BF%D0%BE%D1%88%D0%BB%D1%8B%D0%B5-%D0%B0%D0%BD%D0%B5%D0%BA%D0%B4%D0%BE%D1%82%D1%8B/.
Gay Boys Porn https://gay0day.com HD is the best gay porn tube to watch high definition videos of horny gay boys jerking, sucking their mates and fucking on webcam
Свежие приколы https://prikolyshutki.wordpress.com/2024/10/11/prikoly-umor/.
Перевод документов: Как выбрать надежное бюро переводов для перевода важных документов? Апостиль в Новосибирске: Что такое апостиль и когда он нужен для легализации документов в другой стране?
перевод документов
Возможно, вы правы
https://pozdravnadr.ru/
Смешные приколы https://prikolyshutki.wordpress.com/2024/10/11/prikoly-umor/.
Веселые приколы https://teletype.in/@anekdoty/prikoly-nastroenie.
Профессиональный сервисный центр по ремонту сотовых телефонов в Москве.
Мы предлагаем: центр ремонта телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
cs go betting csgo betting
Свежие приколы http://anekdotshutka.ru.
bs2best.at
Веселые приколы, шутки и картинки http://anekdotshutka.ru.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в челябинске
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
как выглядит знак
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в барнауле
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
https://sudvgorode.ru/
Начните массовую индексацию ссылок в Google прямо cейчас!
Быстрая индексация ссылок имеет ключевое значение для успеха вашего онлайн-бизнеса. Чем быстрее поисковые системы обнаружат и проиндексируют ваши ссылки, тем быстрее вы сможете привлечь новую аудиторию и повысить позиции вашего сайта в результатах поиска.
Не теряйте времени! Начните пользоваться нашим сервисом для ускоренной индексации внешних ссылок в Google и Yandex. Зарегистрируйтесь сегодня и получите первые результаты уже завтра. Ваш успех в ваших руках!
Find high-quality fashion at roxy clothing.
Свежие анекдоты https://teletype.in/@anekdoty/smeshnye-anekdoty.
cs2 gambling sites cs go betting
Профессиональный сервисный центр по ремонту сотовых телефонов в Москве.
Мы предлагаем: ремонт сотовых телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
https://м-мастер.рф/
Смешные анекдоты https://prikolyshutki.wordpress.com/2024/10/16/smeshnye-anekdoty/.
https://sudvgorode.ru/privacy-policy/
Очень интересно изложено.
eventjunction.ru
Веселые анекдоты https://teletype.in/@anekdoty/smeshnye-anekdoty.
이용 안내 및 주요 정보
배송대행 이용방법
배송대행은 해외에서 구매한 상품을 중간지점(배대지)에 보내고, 이를 통해 한국으로 배송받는 서비스입니다. 먼저, 회원가입을 진행하고, 해당 배대지 주소를 이용해 상품을 주문한 후, 배송대행 신청서를 작성하여 배송 정보를 입력합니다. 모든 과정은 웹사이트를 통해 관리되며, 필요한 경우 고객센터를 통해 지원을 받을 수 있습니다.
구매대행 이용방법
구매대행은 해외 쇼핑몰에서 직접 구매가 어려운 경우, 대행 업체가 대신 구매해주는 서비스입니다. 고객이 원하는 상품 정보를 제공하면, 구매대행 신청서를 작성하고 대행료와 함께 결제하면 업체가 구매를 완료해줍니다. 이후 상품이 배대지로 도착하면 배송대행 절차를 통해 상품을 수령할 수 있습니다.
배송비용 안내
배송비용은 상품의 무게, 크기, 배송 지역에 따라 다르며, 계산기는 웹사이트에서 제공됩니다. 부피무게가 큰 제품이나 특수 제품은 추가 비용이 발생할 수 있습니다. 항공과 해운에 따른 요금 차이도 고려해야 합니다.
부가서비스
추가 포장 서비스, 검역 서비스, 폐기 서비스 등이 제공되며, 필요한 경우 신청서를 작성하여 서비스 이용이 가능합니다. 파손 위험이 있는 제품의 경우 포장 보완 서비스를 신청하는 것이 좋습니다.
관/부가세 안내
수입된 상품에 대한 관세와 부가세는 상품의 종류와 가격에 따라 부과됩니다. 이를 미리 확인하고, 추가 비용을 예상하여 계산하는 것이 중요합니다.
수입금지 품목
가스제품(히터), 폭발물, 위험물 등은 수입이 금지된 품목에 속합니다. 항공 및 해상 운송이 불가하니, 반드시 해당 품목을 확인 후 주문해야 합니다.
폐기/검역 안내
검역이 필요한 상품이나 폐기가 필요한 경우, 사전에 관련 부가서비스를 신청해야 합니다. 해당 사항에 대해 미리 안내받고 처리할 수 있도록 주의해야 합니다.
교환/반품 안내
교환 및 반품 절차는 상품을 배송받은 후 7일 이내에 신청이 가능합니다. 단, 일부 상품은 교환 및 반품이 제한될 수 있으니 사전에 정책을 확인하는 것이 좋습니다.
재고관리 시스템
재고관리는 배대지에서 보관 중인 상품의 상태를 실시간으로 확인할 수 있는 시스템입니다. 재고 신청을 통해 상품의 상태를 확인하고, 필요한 경우 배송 또는 폐기 요청을 할 수 있습니다.
노데이타 처리방법
노데이타 상태의 상품은 배송 추적이 어려운 경우 발생합니다. 이런 경우 고객센터를 통해 문의하고 문제를 해결해야 합니다.
소비세환급 및 Q&A
일본에서 상품을 구매할 때 적용된 소비세를 환급받을 수 있는 서비스입니다. 해당 신청서는 구체적인 절차에 따라 작성하고 제출해야 합니다. Q&A를 통해 자주 묻는 질문을 확인하고, 추가 문의 사항은 고객센터에 연락해 해결할 수 있습니다.
고객지원
고객센터는 1:1 문의, 카카오톡 상담 등을 통해 서비스 이용 중 발생하는 문제나 문의사항을 해결할 수 있도록 지원합니다.
서비스 관련 공지사항
파손이 쉬운 제품의 경우, 추가 포장 보완을 반드시 요청해야 합니다.
가스제품(히터)은 통관이 불가하므로 구매 전 확인 바랍니다.
항공 운송 비용이 대폭 인하되었습니다.
일본배대지
이용 안내 및 주요 정보
배송대행 이용방법
배송대행은 해외에서 구매한 상품을 중간지점(배대지)에 보내고, 이를 통해 한국으로 배송받는 서비스입니다. 먼저, 회원가입을 진행하고, 해당 배대지 주소를 이용해 상품을 주문한 후, 배송대행 신청서를 작성하여 배송 정보를 입력합니다. 모든 과정은 웹사이트를 통해 관리되며, 필요한 경우 고객센터를 통해 지원을 받을 수 있습니다.
구매대행 이용방법
구매대행은 해외 쇼핑몰에서 직접 구매가 어려운 경우, 대행 업체가 대신 구매해주는 서비스입니다. 고객이 원하는 상품 정보를 제공하면, 구매대행 신청서를 작성하고 대행료와 함께 결제하면 업체가 구매를 완료해줍니다. 이후 상품이 배대지로 도착하면 배송대행 절차를 통해 상품을 수령할 수 있습니다.
배송비용 안내
배송비용은 상품의 무게, 크기, 배송 지역에 따라 다르며, 계산기는 웹사이트에서 제공됩니다. 부피무게가 큰 제품이나 특수 제품은 추가 비용이 발생할 수 있습니다. 항공과 해운에 따른 요금 차이도 고려해야 합니다.
부가서비스
추가 포장 서비스, 검역 서비스, 폐기 서비스 등이 제공되며, 필요한 경우 신청서를 작성하여 서비스 이용이 가능합니다. 파손 위험이 있는 제품의 경우 포장 보완 서비스를 신청하는 것이 좋습니다.
관/부가세 안내
수입된 상품에 대한 관세와 부가세는 상품의 종류와 가격에 따라 부과됩니다. 이를 미리 확인하고, 추가 비용을 예상하여 계산하는 것이 중요합니다.
수입금지 품목
가스제품(히터), 폭발물, 위험물 등은 수입이 금지된 품목에 속합니다. 항공 및 해상 운송이 불가하니, 반드시 해당 품목을 확인 후 주문해야 합니다.
폐기/검역 안내
검역이 필요한 상품이나 폐기가 필요한 경우, 사전에 관련 부가서비스를 신청해야 합니다. 해당 사항에 대해 미리 안내받고 처리할 수 있도록 주의해야 합니다.
교환/반품 안내
교환 및 반품 절차는 상품을 배송받은 후 7일 이내에 신청이 가능합니다. 단, 일부 상품은 교환 및 반품이 제한될 수 있으니 사전에 정책을 확인하는 것이 좋습니다.
재고관리 시스템
재고관리는 배대지에서 보관 중인 상품의 상태를 실시간으로 확인할 수 있는 시스템입니다. 재고 신청을 통해 상품의 상태를 확인하고, 필요한 경우 배송 또는 폐기 요청을 할 수 있습니다.
노데이타 처리방법
노데이타 상태의 상품은 배송 추적이 어려운 경우 발생합니다. 이런 경우 고객센터를 통해 문의하고 문제를 해결해야 합니다.
소비세환급 및 Q&A
일본에서 상품을 구매할 때 적용된 소비세를 환급받을 수 있는 서비스입니다. 해당 신청서는 구체적인 절차에 따라 작성하고 제출해야 합니다. Q&A를 통해 자주 묻는 질문을 확인하고, 추가 문의 사항은 고객센터에 연락해 해결할 수 있습니다.
고객지원
고객센터는 1:1 문의, 카카오톡 상담 등을 통해 서비스 이용 중 발생하는 문제나 문의사항을 해결할 수 있도록 지원합니다.
서비스 관련 공지사항
파손이 쉬운 제품의 경우, 추가 포장 보완을 반드시 요청해야 합니다.
가스제품(히터)은 통관이 불가하므로 구매 전 확인 바랍니다.
항공 운송 비용이 대폭 인하되었습니다.
ремонт фундамента
Платформа для ставок 1win с множеством событий и азартных игр. Удобный интерфейс, моментальные выплаты и привлекательные бонусы делают ставки ещё увлекательнее. Откройте мир азарта и выигрышей с надежным сервисом и постоянными акциями для пользователей.
BlackSprut
музей анимации в москве официальный сайт музей анимации в москве отзывы
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Платформа для ставок 1вин с множеством событий и азартных игр. Удобный интерфейс, моментальные выплаты и привлекательные бонусы делают ставки ещё увлекательнее. Откройте мир азарта и выигрышей с надежным сервисом и постоянными акциями для пользователей.
музей анимации измайлово музей анимации
Лазерные станки для промышленных предприятий
Наши лазерные станки подходят для промышленных предприятий любого масштаба, обеспечивая высокую производительность и качество резки.
купить лазерный станок [url=https://lazernye-stanki.ru/]лазерная резка по металлу[/url] .
Профессиональный сервисный центр по ремонту сотовых телефонов в Москве.
Мы предлагаем: ремонт ноутбуков в городе
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить диплом мфти [url=https://orik-diploms.ru/]купить диплом мфти[/url] .
If you’re looking for high-class Murree escorts, these professionals offer an experience that combines sophistication with charm. Their delightful company will make your evening truly exceptional.|
order helium balloons helium balloons with cheap delivery
Платформа 1вин предлагает широкий выбор спортивных событий, киберспорта и азартных игр. Пользователи получают высокие коэффициенты, быстрые выплаты и круглосуточную поддержку. Программа лояльности и бонусы делают игру выгоднее.
Свежие анекдоты http://anekdot-top.ru.
Поставка и настройка лазерных станков по России
Осуществляем поставку лазерных станков по всей России. Наши специалисты обеспечат быструю и профессиональную настройку оборудования на вашем предприятии.
станок для лазерной резки металла [url=https://lazernye-stanki.ru/]лазерная резка металла оборудование с чпу цена[/url] .
sample resume of an engineer resume of a construction engineer
https://ya.0bb.ru/viewtopic.php?id=13361#p34864
Веселые приколы и анекдоты https://teletype.in/@anekdoty/prikoly-nastroenie.
Веселые приколы, шутки и картинки https://teletype.in/@anekdoty/prikoly-nastroenie.
список франшиз [url=https://franshizy13.ru/]список франшиз[/url] .
Веселые приколы, шутки и картинки http://shutki-anekdoty.ru/.
Produzione video professionale https://orbispro.it creazione di spot pubblicitari, film aziendali e contenuti video. Ciclo completo di lavoro, dall’idea al montaggio. Soluzioni creative per promuovere con successo il tuo brand.
เกมสล็อตออนไลน์
สล็อต888 เป็นหนึ่งในแพลตฟอร์มเกมสล็อตออนไลน์ที่ได้รับความนิยมสูงสุดในปัจจุบัน โดยมีความโดดเด่นด้วยการให้บริการเกมสล็อตที่หลากหลายและมีคุณภาพ รวมถึงฟีเจอร์ที่ช่วยให้ผู้เล่นสามารถเพลิดเพลินกับการเล่นได้อย่างเต็มที่ ในบทความนี้ เราจะมาพูดถึงฟีเจอร์และจุดเด่นของสล็อต888 ที่ทำให้เว็บไซต์นี้ได้รับความนิยมเป็นอย่างมาก
ฟีเจอร์เด่นของ PG สล็อต888
ระบบฝากถอนเงินอัตโนมัติที่รวดเร็ว สล็อต888 ให้บริการระบบฝากถอนเงินแบบอัตโนมัติที่สามารถทำรายการได้ทันที ไม่ต้องรอนาน ไม่ว่าจะเป็นการฝากหรือถอนก็สามารถทำได้ภายในไม่กี่วินาที รองรับการใช้งานผ่านทรูวอลเล็ทและช่องทางอื่น ๆ โดยไม่มีขั้นต่ำในการฝากถอน
รองรับทุกอุปกรณ์ ทุกแพลตฟอร์ม ไม่ว่าคุณจะเล่นจากอุปกรณ์ใดก็ตาม สล็อต888 รองรับทั้งคอมพิวเตอร์ แท็บเล็ต และสมาร์ทโฟน ไม่ว่าจะเป็นระบบ iOS หรือ Android คุณสามารถเข้าถึงเกมสล็อตได้ทุกที่ทุกเวลาเพียงแค่มีอินเทอร์เน็ต
โปรโมชั่นและโบนัสมากมาย สำหรับผู้เล่นใหม่และลูกค้าประจำ สล็อต888 มีโปรโมชั่นต้อนรับ รวมถึงโบนัสพิเศษ เช่น ฟรีสปินและโบนัสเครดิตเพิ่ม ทำให้การเล่นเกมสล็อตกับเราเป็นเรื่องสนุกและมีโอกาสทำกำไรมากยิ่งขึ้น
ความปลอดภัยสูงสุด เรื่องความปลอดภัยเป็นสิ่งที่สล็อต888 ให้ความสำคัญเป็นอย่างยิ่ง เราใช้เทคโนโลยีการเข้ารหัสข้อมูลขั้นสูงเพื่อปกป้องข้อมูลส่วนบุคคลของลูกค้า ระบบฝากถอนเงินยังมีมาตรการรักษาความปลอดภัยที่เข้มงวด ทำให้ลูกค้ามั่นใจในการใช้บริการกับเรา
ทดลองเล่นสล็อตฟรี
สล็อต888 ยังมีบริการให้ผู้เล่นสามารถทดลองเล่นสล็อตได้ฟรี ซึ่งเป็นโอกาสที่ดีในการทดลองเล่นเกมต่าง ๆ ที่มีอยู่บนเว็บไซต์ เช่น Phoenix Rises, Dream Of Macau, Ways Of Qilin, Caishens Wins และเกมยอดนิยมอื่น ๆ ที่มีกราฟิกสวยงามและรูปแบบการเล่นที่น่าสนใจ
ไม่ว่าจะเป็นเกมแนวผจญภัย เช่น Rise Of Apollo, Dragon Hatch หรือเกมที่มีธีมแห่งความมั่งคั่งอย่าง Crypto Gold, Fortune Tiger, Lucky Piggy ทุกเกมได้รับการออกแบบมาเพื่อสร้างประสบการณ์การเล่นที่น่าจดจำและเต็มไปด้วยความสนุกสนาน
บทสรุป
สล็อต888 เป็นแพลตฟอร์มที่ครบเครื่องเรื่องเกมสล็อตออนไลน์ ด้วยฟีเจอร์ที่ทันสมัย โปรโมชั่นที่น่าสนใจ และระบบรักษาความปลอดภัยที่เข้มงวด ทำให้คุณมั่นใจได้ว่าการเล่นกับสล็อต888 จะเป็นประสบการณ์ที่ปลอดภัยและเต็มไปด้วยความสนุก
Веселые приколы и анекдоты http://shutki-anekdoty.ru/.
Produzione video professionale https://orbispro.it creazione di spot pubblicitari, film aziendali e contenuti video. Ciclo completo di lavoro, dall’idea al montaggio. Soluzioni creative per promuovere con successo il tuo brand.
Garansi Kekalahan
NAGAEMPIRE: Platform Sports Game dan E-Games Terbaik di Tahun 2024
Selamat datang di Naga Empire, platform hiburan online yang menghadirkan pengalaman gaming terdepan di tahun 2024! Kami bangga menawarkan sports game, permainan kartu, dan berbagai fitur unggulan yang dirancang untuk memberikan Anda kesenangan dan keuntungan maksimal.
Keunggulan Pendaftaran dengan E-Wallet dan QRIS
Kami memprioritaskan kemudahan dan kecepatan dalam pengalaman bermain Anda:
Pendaftaran dengan E-Wallet: Daftarkan akun Anda dengan mudah menggunakan e-wallet favorit. Proses pendaftaran sangat cepat, memungkinkan Anda langsung memulai petualangan gaming tanpa hambatan.
QRIS Auto Proses dalam 1 Detik: Transaksi Anda diproses instan hanya dalam 1 detik dengan teknologi QRIS, memastikan pembayaran dan deposit berjalan lancar tanpa gangguan.
Sports Game dan Permainan Kartu Terbaik di Tahun 2024
Naga Empire menawarkan berbagai pilihan game menarik:
Sports Game Terlengkap: Dari taruhan olahraga hingga fantasy sports, kami menyediakan sensasi taruhan olahraga dengan kualitas terbaik.
Kartu Terbaik di 2024: Nikmati permainan kartu klasik hingga variasi modern dengan grafis yang menakjubkan, memberikan pengalaman bermain yang tak terlupakan.
Permainan Terlengkap dan Toto Terlengkap
Kami memiliki koleksi permainan yang sangat beragam:
Permainan Terlengkap: Temukan berbagai pilihan permainan seperti slot mesin, kasino, hingga permainan berbasis keterampilan, semua tersedia di Naga Empire.
Toto Terlengkap: Layanan Toto Online kami menawarkan pilihan taruhan yang lengkap dengan odds yang kompetitif, memberikan pengalaman taruhan yang optimal.
Bonus Melimpah dan Turnover Terendah
Bonus Melimpah: Dapatkan bonus mulai dari bonus selamat datang, bonus setoran, hingga promosi eksklusif. Kami selalu memberikan nilai lebih pada setiap taruhan Anda.
Turnover Terendah: Dengan turnover rendah, Anda dapat meraih kemenangan lebih mudah dan meningkatkan keuntungan dari setiap permainan.
Naga Empire adalah tempat yang tepat bagi Anda yang mencari pengalaman gaming terbaik di tahun 2024. Bergabunglah sekarang dan rasakan sensasi kemenangan di platform yang paling komprehensif!
rgbet77
Bạn đang tìm kiếm những trò chơi hot nhất và thú vị nhất tại sòng bạc trực tuyến? RGBET tự hào giới thiệu đến bạn nhiều trò chơi cá cược đặc sắc, bao gồm Baccarat trực tiếp, máy xèng, cá cược thể thao, xổ số và bắn cá, mang đến cho bạn cảm giác hồi hộp đỉnh cao của sòng bạc! Dù bạn yêu thích các trò chơi bài kinh điển hay những máy xèng đầy kịch tính, RGBET đều có thể đáp ứng mọi nhu cầu giải trí của bạn.
RGBET Trò Chơi của Chúng Tôi
Bạn đang tìm kiếm những trò chơi hot nhất và thú vị nhất tại sòng bạc trực tuyến? RGBET tự hào giới thiệu đến bạn nhiều trò chơi cá cược đặc sắc, bao gồm Baccarat trực tiếp, máy xèng, cá cược thể thao, xổ số và bắn cá, mang đến cảm giác hồi hộp đỉnh cao của sòng bạc! Dù bạn yêu thích các trò chơi bài kinh điển hay những máy xèng đầy kịch tính, RGBET đều có thể đáp ứng mọi nhu cầu giải trí của bạn.
RGBET Trò Chơi Đa Dạng
Thể thao: Cá cược thể thao đa dạng với nhiều môn từ bóng đá, tennis đến thể thao điện tử.
Live Casino: Trải nghiệm Baccarat, Roulette, và các trò chơi sòng bài trực tiếp với người chia bài thật.
Nổ hũ: Tham gia các trò chơi nổ hũ với tỷ lệ trúng cao và cơ hội thắng lớn.
Lô đề: Đặt cược lô đề với tỉ lệ cược hấp dẫn.
Bắn cá: Bắn cá RGBET mang đến cảm giác chân thực và hấp dẫn với đồ họa tuyệt đẹp.
RGBET – Máy Xèng Hấp Dẫn Nhất
Khám phá các máy xèng độc đáo tại RGBET với nhiều chủ đề khác nhau và tỷ lệ trả thưởng cao. Những trò chơi nổi bật bao gồm:
RGBET Super Ace
RGBET Đế Quốc Hoàng Kim
RGBET Pharaoh Treasure
RGBET Quyền Vương
RGBET Chuyên Gia Săn Rồng
RGBET Jackpot Fishing
Vì sao nên chọn RGBET?
RGBET không chỉ cung cấp hàng loạt trò chơi đa dạng mà còn mang đến một hệ thống cá cược an toàn và chuyên nghiệp, đảm bảo mọi quyền lợi của người chơi:
Tốc độ nạp tiền nhanh chóng: Chuyển khoản tại RGBET chỉ mất vài phút và tiền sẽ vào tài khoản ngay lập tức, giúp bạn không bỏ lỡ bất kỳ cơ hội nào.
Game đổi thưởng phong phú: Từ cá cược thể thao đến slot game, RGBET cung cấp đầy đủ trò chơi giúp bạn tận hưởng mọi phút giây thư giãn.
Bảo mật tuyệt đối: Với công nghệ mã hóa tiên tiến, tài khoản và tiền vốn của bạn sẽ luôn được bảo vệ một cách an toàn.
Hỗ trợ đa nền tảng: Bạn có thể chơi trên mọi thiết bị, từ máy tính, điện thoại di động (iOS/Android), đến nền tảng H5.
Tải Ứng Dụng RGBET và Nhận Khuyến Mãi Lớn
Hãy tham gia RGBET ngay hôm nay để tận hưởng thế giới giải trí không giới hạn với các trò chơi thể thao, thể thao điện tử, casino trực tuyến, xổ số, và slot game. Quét mã QR và tải ứng dụng RGBET trên điện thoại để trải nghiệm game tốt hơn và nhận nhiều khuyến mãi hấp dẫn!
Tham gia RGBET để bắt đầu cuộc hành trình cá cược đầy thú vị ngay hôm nay!
Свежие приколы http://shutki-anekdoty.ru/.
Профессиональный сервисный центр по ремонту сотовых телефонов в Москве.
Мы предлагаем: ноутбук ремонт сервисный
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Прикольные анекдоты http://shutki-anekdoty.ru/anekdoty.
สล็อต888 เป็นหนึ่งในแพลตฟอร์มเกมสล็อตออนไลน์ที่ได้รับความนิยมสูงสุดในปัจจุบัน โดยมีความโดดเด่นด้วยการให้บริการเกมสล็อตที่หลากหลายและมีคุณภาพ รวมถึงฟีเจอร์ที่ช่วยให้ผู้เล่นสามารถเพลิดเพลินกับการเล่นได้อย่างเต็มที่ ในบทความนี้ เราจะมาพูดถึงฟีเจอร์และจุดเด่นของสล็อต888 ที่ทำให้เว็บไซต์นี้ได้รับความนิยมเป็นอย่างมาก
ฟีเจอร์เด่นของ PG สล็อต888
ระบบฝากถอนเงินอัตโนมัติที่รวดเร็ว สล็อต888 ให้บริการระบบฝากถอนเงินแบบอัตโนมัติที่สามารถทำรายการได้ทันที ไม่ต้องรอนาน ไม่ว่าจะเป็นการฝากหรือถอนก็สามารถทำได้ภายในไม่กี่วินาที รองรับการใช้งานผ่านทรูวอลเล็ทและช่องทางอื่น ๆ โดยไม่มีขั้นต่ำในการฝากถอน
รองรับทุกอุปกรณ์ ทุกแพลตฟอร์ม ไม่ว่าคุณจะเล่นจากอุปกรณ์ใดก็ตาม สล็อต888 รองรับทั้งคอมพิวเตอร์ แท็บเล็ต และสมาร์ทโฟน ไม่ว่าจะเป็นระบบ iOS หรือ Android คุณสามารถเข้าถึงเกมสล็อตได้ทุกที่ทุกเวลาเพียงแค่มีอินเทอร์เน็ต
โปรโมชั่นและโบนัสมากมาย สำหรับผู้เล่นใหม่และลูกค้าประจำ สล็อต888 มีโปรโมชั่นต้อนรับ รวมถึงโบนัสพิเศษ เช่น ฟรีสปินและโบนัสเครดิตเพิ่ม ทำให้การเล่นเกมสล็อตกับเราเป็นเรื่องสนุกและมีโอกาสทำกำไรมากยิ่งขึ้น
ความปลอดภัยสูงสุด เรื่องความปลอดภัยเป็นสิ่งที่สล็อต888 ให้ความสำคัญเป็นอย่างยิ่ง เราใช้เทคโนโลยีการเข้ารหัสข้อมูลขั้นสูงเพื่อปกป้องข้อมูลส่วนบุคคลของลูกค้า ระบบฝากถอนเงินยังมีมาตรการรักษาความปลอดภัยที่เข้มงวด ทำให้ลูกค้ามั่นใจในการใช้บริการกับเรา
ทดลองเล่นสล็อตฟรี
สล็อต888 ยังมีบริการให้ผู้เล่นสามารถทดลองเล่นสล็อตได้ฟรี ซึ่งเป็นโอกาสที่ดีในการทดลองเล่นเกมต่าง ๆ ที่มีอยู่บนเว็บไซต์ เช่น Phoenix Rises, Dream Of Macau, Ways Of Qilin, Caishens Wins และเกมยอดนิยมอื่น ๆ ที่มีกราฟิกสวยงามและรูปแบบการเล่นที่น่าสนใจ
ไม่ว่าจะเป็นเกมแนวผจญภัย เช่น Rise Of Apollo, Dragon Hatch หรือเกมที่มีธีมแห่งความมั่งคั่งอย่าง Crypto Gold, Fortune Tiger, Lucky Piggy ทุกเกมได้รับการออกแบบมาเพื่อสร้างประสบการณ์การเล่นที่น่าจดจำและเต็มไปด้วยความสนุกสนาน
บทสรุป
สล็อต888 เป็นแพลตฟอร์มที่ครบเครื่องเรื่องเกมสล็อตออนไลน์ ด้วยฟีเจอร์ที่ทันสมัย โปรโมชั่นที่น่าสนใจ และระบบรักษาความปลอดภัยที่เข้มงวด ทำให้คุณมั่นใจได้ว่าการเล่นกับสล็อต888 จะเป็นประสบการณ์ที่ปลอดภัยและเต็มไปด้วยความสนุก
Профессиональный сервисный центр по ремонту моноблоков iMac в Москве.
Мы предлагаем: надежный сервис ремонта imac
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Свежие и смешные мемы http://shutki-anekdoty.ru/kartinki-prikolnye.
Вопросы и ответы: можно ли быстро купить диплом старого образца?
vavada kazino
bc game
оказание услуг по специальной оценке условий труда https://sout095.ru
специальную оценку рабочих мест соут https://sout095.ru
Аттестат 11 класса купить официально с упрощенным обучением в Москве
Веселые картинки http://shutki-anekdoty.ru/kartinki-prikolnye.
кем проводится специальная оценка условий труда https://sout095.ru
บาคาร่า
เล่นบาคาร่าแบบรวดเร็วทันใจกับสปีดบาคาร่า
ถ้าคุณเป็นแฟนตัวยงของเกมไพ่บาคาร่า คุณอาจจะเคยชินกับการรอคอยในแต่ละรอบการเดิมพัน และรอจนดีลเลอร์แจกไพ่ในแต่ละตา แต่คุณรู้หรือไม่ว่า ตอนนี้คุณไม่ต้องรออีกต่อไปแล้ว เพราะ SA Gaming ได้พัฒนาเกมบาคาร่าโหมดใหม่ขึ้นมา เพื่อให้ประสบการณ์การเล่นของคุณน่าตื่นเต้นยิ่งขึ้น!
ที่ SA Gaming คุณสามารถเลือกเล่นไพ่บาคาร่าในโหมดที่เรียกว่า สปีดบาคาร่า (Speed Baccarat) โหมดนี้มีคุณสมบัติพิเศษและข้อดีที่น่าสนใจมากมาย:
ระยะเวลาการเดิมพันสั้นลง — คุณไม่จำเป็นต้องรอนานอีกต่อไป ในโหมดสปีดบาคาร่า คุณจะมีเวลาเพียง 12 วินาทีในการวางเดิมพัน ทำให้เกมแต่ละรอบจบได้รวดเร็ว โดยเกมในแต่ละรอบจะใช้เวลาเพียง 20 วินาทีเท่านั้น
ผลตอบแทนต่อผู้เล่นสูง (RTP) — เกมสปีดบาคาร่าให้ผลตอบแทนต่อผู้เล่นสูงถึง 4% ซึ่งเป็นมาตรฐานความเป็นธรรมที่ผู้เล่นสามารถไว้วางใจได้
การเล่นเกมที่รวดเร็วและน่าตื่นเต้น — ระยะเวลาที่สั้นลงทำให้เกมแต่ละรอบดำเนินไปอย่างรวดเร็ว ทันใจ เพิ่มความสนุกและความตื่นเต้นในการเล่น ทำให้ประสบการณ์การเล่นของคุณยิ่งสนุกมากขึ้น
กลไกและรูปแบบการเล่นยังคงเหมือนเดิม — แม้ว่าระยะเวลาจะสั้นลง แต่กลไกและกฎของการเล่น ยังคงเหมือนกับบาคาร่าสดปกติทุกประการ เพียงแค่ปรับเวลาให้เล่นได้รวดเร็วและสะดวกขึ้นเท่านั้น
นอกจากสปีดบาคาร่าแล้ว ที่ SA Gaming ยังมีโหมด No Commission Baccarat หรือบาคาร่าแบบไม่เสียค่าคอมมิชชั่น ซึ่งจะช่วยให้คุณสามารถเพลิดเพลินไปกับการเล่นได้โดยไม่ต้องกังวลเรื่องค่าคอมมิชชั่นเพิ่มเติม
เล่นบาคาร่ากับ SA Gaming คุณจะได้รับประสบการณ์การเล่นที่สนุก ทันสมัย และตรงใจมากที่สุด!
кто должен проводить соут https://sout095.ru
Работая с нами, вы получаете возможность оформить микрозайм быстро, безопасно и с минимальными затратами. Мы предлагаем только проверенные и надежные решения, что делает процесс получения финансовой помощи легким и удобным.
микрозаймы [url=https://microloans.kz/]микрозайм[/url] .
Discover stunning escorts in Lahore for a luxury service.|
Свежие видео http://shutki-anekdoty.ru/videos.
USDT TRC20 Transfer Check and Financial Crime Prevention (AML) Practices
As digital assets like USDT TRC20 gain usage for fast and affordable transactions, the need for safety and conformance with Anti-Money Laundering regulations increases. Here’s how to review USDT TRON-based payments and ensure they’re not connected to unlawful activities.
What does it mean TRON-based USDT?
TRON-based USDT is a cryptocurrency on the TRX network, valued in line with the USD. Recognized for its minimal costs and quickness, it is frequently employed for global transactions. Validating transactions is essential to prevent connections to money laundering or other unlawful activities.
Monitoring TRON-based USDT Transactions
TRX Explorer — This ledger tracker enables users to track and validate Tether TRON-based payments using a account ID or transfer code.
Tracking — Skilled players can track anomalous patterns such as significant or fast transactions to identify irregular actions.
AML and Illicit Funds
Anti-Money Laundering (Anti-Money Laundering) rules help stop illegal transactions in cryptocurrency. Services like Chain Analysis and Elliptic permit businesses and crypto markets to find and block criminal crypto, which signifies funds related to unlawful operations.
Tools for Compliance
TRX Explorer — To validate USDT TRC20 transfer data.
Chainalysis and Elliptic Solutions — Used by trading platforms to ensure Anti-Money Laundering compliance and track illicit activities.
Conclusion
Ensuring safe and legal TRON-based USDT payments is critical. Tools like TRONSCAN and Anti-Money Laundering tools assist protect participants from engaging with illicit funds, promoting a safe and compliant crypto environment.
ретро казино зеркало [url=www.newretrocasino-casino3.ru/]www.newretrocasino-casino3.ru/[/url] .
Great! Thank you so much for sharing this. I can’t wait to use it.
Смешные видео http://shutki-anekdoty.ru/videos.
Свежие и смешные шутки http://shutki-anekdoty.ru/korotkie-anekdoty.
Мы делаем акцент на прозрачности наших услуг и предоставляем полную информацию о всех доступных предложениях. Наши клиенты могут быть уверены, что получат исчерпывающие сведения о сроках, ставках и возможных комиссиях, что позволяет им принимать осознанные решения. Мы стремимся создать доверительные отношения с каждым клиентом и всегда готовы предоставить подробные консультации по любым вопросам, связанным с микрозаймами.
займ онлайн [url=https://microloans.kz/]онлайн деньги[/url] .
Great! Thank you so much for sharing this. I can’t wait to use it.
Сломался телефон, думал покупать новый, но решил попробовать отремонтировать. Обратился в этот сервисный центр и не пожалел. Профессионалы своего дела быстро восстановили мой телефон. Рекомендую посетить их сайт: телефоны ремонт.
Explore a curated collection of fashion at fjallraven outlet.
диплом среднего профессионального образования с занесением в реестр [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Как получить диплом стоматолога быстро и официально
Стоимость дипломов высшего и среднего образования и процесс их получения
Смешные приколы и анекдоты http://shutki-anekdoty.ru/.
купить диплом в черногорске [url=https://man-diploms.ru/]man-diploms.ru[/url] .
countries also have an FDA approval standard on their cheap online pharmacy oxycodone to effectively treat your condition
You might feel like your pain is too overwhelming to cope with, but those times don’t last forever.
Свежие приколы http://shutki-anekdoty.ru/.
Powerful treatment is available when you can you buy misoprostol pharmacy ? Learn what women are saying.
Sweating, fever, no appetite, swollen kidneys prevented walking, backpain, vomiting.
детские киски порно порно в юбке
Недавно разбил экран своего телефона и обратился в этот сервисный центр. Ребята быстро и качественно починили устройство, теперь работает как новый. Очень рекомендую обратиться к ним за помощью. Вот ссылка на их сайт: ремонт проводных телефонов.
2024’un en kazancl? casino platformu – Sahabet
Sahabet Casino [url=https://t.me/sahabet1194/]Sahabet[/url] .
читать порно тг бот с детским порно
героин парфюм купить со шлюхой
get cheaper rates.Health benefits are achievable when you buy generic viagra online us pharmacy for serious help
Since diabetes is so common, a lot of money goes into finding new ways of combating it.
Официальное получение диплома техникума с упрощенным обучением в Москве
купить мефедрон магазин заказать шлюху
you happen to be searching for a successful remedy, you should india online pharmacy store without a prescription?
Click the icon to see an image of hyperthyroidism.
เว็บไซต์การพนันกีฬา KUBET เป็นแบรนด์ของไต้หวันภายใต้กลุ่ม Kyushu และเป็นแบรนด์การพนันออนไลน์ (เว็บเงินสด) ที่มีทุนสำรองมากกว่าพันล้าน มีอินเทอร์เฟซที่ใช้งานง่าย โปรโมชั่นมากมาย และกลุ่มเกมสำหรับสมาชิกซึ่งเป็นหนึ่งในคุณสมบัติเด่นของ KUBET กีฬา
KUBET กีฬาได้รับการอนุญาตและควบคุมโดยบริษัทความบันเทิงออนไลน์ที่ถูกกฎหมาย โดยมีใบอนุญาตจาก Malta Gaming Authority (MGA) ในยุโรปและใบอนุญาตจาก Philippine Amusement and Gaming Corporation (PAGCOR) จึงเป็นตัวเลือกแรกของผู้เล่นอย่างไม่ต้องสงสัย。
Профессиональный сервисный центр по ремонту игровых консолей Sony Playstation, Xbox, PSP Vita с выездом на дом по Москве.
Мы предлагаем: ремонт игровых консолей в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
time you happen to be searching the web for a great remedy, anabolic steroids online pharmacy reviews at rock bottom prices
Leiomyosarcoma can arise within the dermis.
Any time you happen to be searching the web for a great remedy, viagra online india pharmacy guarantee top performance?
These symptoms include a fast heart rate, tremor and increased anxiety.
нажмите https://lzt.market
Don’t wait in long lines, get a Fosamax and fast delivery every time you buy here
Manda Panda Hi Doc, I tested on the afternoon I sent this and I just tested this a.
Веселые приколы http://shutki-anekdoty.ru/.
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: где ремонтируют телефоны
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
ремонт телефонов москва
ссылка на сайт https://zelenka.guru/articles/
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: сервис ремонт телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: стоимость ремонта телефона
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов по близости
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: мастерская телефонов рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: где можно отремонтировать телефон
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
рекламное агентство реклама в лифтах реклама в лифтах в москве
реклама в лифтах дома https://reklama-v-liftah-msk.ru
реклама в лифтах дома https://reklama-v-liftah-msk.ru
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
реклама в лифтах дома https://reklama-v-liftah-msk.ru
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ближайшая мастерская по ремонту телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
выберите ресурсы https://zelenka.guru
Смешные анекдоты http://shutki-anekdoty.ru/anekdoty.
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт мобильных телефонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт мобильных телефонов рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт телефонов с гарантией
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: ремонт мобильных телефонов рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту телефонов в Москве.
Мы предлагаем: мастер по ремонту мобильных телефонов
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
этот сайт https://omgomgonion.com/
RGBET là nhà cái hàng đầu trong lĩnh vực cá cược trực tuyến, đem đến cho người chơi tại Việt Nam trải nghiệm giải trí đẳng cấp với nhiều lựa chọn hấp dẫn. RGBET không chỉ cung cấp các môn thể thao phổ biến như bóng đá, bóng rổ, hay quần vợt mà còn mở rộng với các trò chơi sòng bạc, xổ số và đặc biệt là cá cược eSports.
Lưu Ý Quan Trọng về Trang RGBET
Hiện nay, một số trang web giả mạo RGBET nhằm mục đích lừa đảo, gây rủi ro cho người chơi. Đặc biệt, trang rgbet.info không có liên kết chính thức với RGBET. Để bảo vệ thông tin cá nhân, khách hàng nên truy cập trang chính thức của RGBET tại rgbet.co và tránh các nguồn không uy tín.
Lợi Ích Khi Tham Gia RGBET
RGBET cung cấp rất nhiều chương trình khuyến mãi hấp dẫn dành cho người chơi, đặc biệt trong tháng 10 với chương trình “Mỗi Ngày Đăng Nhập, Nhận Ngay Quà Hot”. Ngoài ra, RGBET hỗ trợ nhiều tính năng cá cược thể thao trực tiếp với tỷ lệ cược hấp dẫn, giúp người chơi tận hưởng trọn vẹn từng trận đấu.
Đa Dạng Lựa Chọn Cá Cược và Trò Chơi Sòng Bạc
Sòng bạc trực tuyến: Bao gồm các trò chơi phổ biến như Baccarat, Roulette, và Blackjack.
Thể thao ảo và eSports: Người chơi có thể đặt cược các giải đấu lớn và thỏa sức với trò chơi thể thao ảo.
Trò chơi máy đánh bạc: Với hàng loạt trò chơi máy đánh bạc chủ đề như “Kho Báu Aztec” hay “Aladdin & Cây Đèn Thần,” RGBET đáp ứng nhu cầu giải trí đa dạng của người chơi.
Bảo Mật và Pháp Lý
RGBET là một trong số ít các nhà cái được cấp phép bởi cơ quan quản lý uy tín, đảm bảo tiêu chuẩn bảo mật và minh bạch.
Tham gia RGBET ngay để khám phá thế giới cá cược trực tuyến chuyên nghiệp và bảo đảm!
проверить сайт https://blacksprut-dark.com
Мы занимаемся вывозом мусора газелями разной модификации от стандартных 6 м3 до больших 14 м3 есть также грузчики, работаем по Московской области. Преимущества вывоза мусора газелью в том, что она самая дешёвая услуга вывоза мусора.
Как организовать вывоз мусора газелью, с минимальными затратами.
Почему газель идеально подходит для вывоза мусора, которая убеждает.
Какие материалы можно вывозить газелью, и какие ограничения существуют.
Как сэкономить на вывозе мусора газелью, сотрудничая с профессионалами.
Секрет успешного вывоза мусора газелью, соблюдая правила перевозки.
вывоз строительного мусора газелью [url=https://vyvoz-musora-gazel-mo.ru/]вывоз мусора газелью[/url] .
выведение из запоя санкт петербург [url=azithromycinum.ru]azithromycinum.ru[/url] .
вывод из запоя цены санкт-петербург [url=https://vyvod-iz-zapoya-v-sankt-peterburge16.ru/]https://vyvod-iz-zapoya-v-sankt-peterburge16.ru/[/url] .
бытовка для жилья купить бытовку на заказ
Свежие и смешные картинки http://shutki-anekdoty.ru/kartinki-prikolnye.
ลองเล่นสล็อต PG: รับรู้ประสบการณ์เกมหมุนวงล้อออนไลน์แบบสดใหม่
ก่อนเริ่มเล่นเกมสล็อตออนไลน์ ข้อสำคัญคือการทดลองกับการทดลองเล่นเสียลำดับแรก เกม ลองเล่นสล็อตนั้นได้รับอิทธิพลมาจากจากเครื่องสล็อตแบบดั้งเดิม โดยเฉพาะอย่างยิ่ง สล็อต Triple Gold ซึ่งเคยเป็นที่นิยมอย่างล้นหลามในบ่อนคาสิโนต่างประเทศ ในเกม ลองเล่นสล็อต PG ผู้เล่นจะได้สัมผัสโครงสร้างของเกมที่มีความเรียบง่ายและแบบดั้งเดิม มาพร้อมกับวงล้อ (วงล้อ) จำนวนจำนวนห้าแถวและช่องจ่ายเงิน (เพย์ไลน์) หรือรูปแบบการชนะที่มากถึง 15 ลักษณะ ทำให้มีโอกาสชนะได้มากมายมากยิ่งกว่าเดิม
ไอคอนต่าง ๆ ในเกมสล็อตนี้เพิ่มความรู้สึกเหมือนอารมณ์ของสล็อตดั้งเดิม โดยมีไอคอนที่คุ้นเคยเช่น รูปเชอร์รี่ เลข 7 และเพชรพลอย ซึ่งจะทำให้เกมสล็อตมีความน่าสนใจแล้วยังสร้างโอกาสในการได้รับผลตอบแทนเพิ่มเติม
ความสะดวกสบายของเกมสล็อต PG
ทดลองเล่นเกม PG ในส่วนนี้ไม่เพียงแค่มีรูปแบบการเล่นที่เข้าใจได้ทันที แต่ยังมีความสะดวกสบายอย่างแท้จริง ไม่ว่าคุณจะใช้งานเครื่องคอมพิวเตอร์หรือโทรศัพท์มือถือรุ่นใด เพียงต่ออินเทอร์เน็ตกับอินเทอร์เน็ต คุณก็สามารถร่วมสนุกสนุกได้ทันที ทดลองเล่นสล็อต PG ยังถูกทำมาให้สนับสนุนเครื่องใช้หลากหลายลักษณะ เพื่อให้ประสบการณ์การเล่นที่ไม่สะดุดไม่สะดุดแก่ผู้ใช้งานทุกท่าน
การเลือกธีมและการเล่นในเกม
ที่สำคัญ เกมทดลองเล่น พีจี ยังมีหลากหลายธีมให้ได้ลอง โดยไม่จำกัดธีมที่น่าสนุก น่าชื่นชอบ หรือธีมที่มีความสมจริง ทำให้ผู้เล่นอาจมีความสุขไปกับรูปแบบที่แตกต่างตามความพอใจ
เนื่องจากจุดเด่นเหล่านี้ ลองเล่นเกมสล็อต PG ได้เป็นที่นิยมตัวเลือกที่ได้รับความนิยมในกลุ่มนักเล่นเกมสมัยใหม่ที่กำลังต้องการการเล่นที่ตื่นเต้นใหม่ ๆและการเอาชนะที่ง่ายขึ้น หากคุณกำลังต้องการประสบการณ์ใหม่ ๆ การลองเล่นสล็อตเป็นตัวเลือกที่คุณไม่ควรละเลย!
вагончик бытовка для дачи купить бытовка в бухловке калужская область
1win apuestas
neon54 ????????
Веселые видеоролики http://shutki-anekdoty.ru/videos.
1win pagina oficial
ранец ручная кладь
neon54 casino review
страница https://blacksprutg.net
bcgame app
Веселые приколы http://shutki-anekdoty.ru/.
Смешные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
1win juegos
Аттестат 11 класса купить официально с упрощенным обучением в Москве
dj88
Прикольные видео https://sites.google.com/view/smeshnye-video/%D0%B3%D0%BB%D0%B0%D0%B2%D0%BD%D0%B0%D1%8F-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0.
Веселые приколы и анекдоты http://shutki-anekdoty.ru.
Как купить диплом о высшем образовании с минимальными рисками
hobbyland.moibb.ru/viewtopic.php?f=3&t=224
Свежие приколы и анекдоты http://shutki-anekdoty.ru.
Get the facts on all medicines when you tadalafil with sildenafil will also be low.
Prevention is better than cure for ED. Click this link how quickly does tadalafil work at large discounts with great service
care to be safeGreat price reductions are possible when you russian pharmacy online usa for all medications are available globally
the best policyManufacturers make generic drugs available to Sporanox today!
Explorez notre collection de
Couteau a steak
pour les chefs amateurs
Свежие анекдоты https://sites.google.com/view/smeshnye-video/anekdoty
красный диплом купить [url=https://russa-diploms.ru/]russa-diploms.ru[/url] .
Explorez notre collection de
Couteau a steak
pour votre cuisine
Canadian Pharmacy.Add more heat into your sexual aspect. Read tadalafil 50mg pills, save by buying online
Do your bit for the environment by checking the can i take 2 5mg tadalafil for life changing facts.
Online pharmacy serves you at online pharmacy that sells phentermine at low prices always available through this specialist site
Свежие анекдоты http://shutki-anekdoty.ru/anekdoty
Свежие и смешные анекдоты https://sites.google.com/view/smeshnye-video/anekdoty
Verify prices before you buy levitra walmart $9 without a prescription?
xxxpornhd.pro
Когда завершается утомительного трудового дня не знаешь точно, как восстановить силы и забыть о будничной суете? У нас есть прекрасное решение! Наш портал — это уголок, где лишь для взрослой аудитории доступны максимально интересные развлечения для всех вкусов. Мы убеждены, что любой наш пользователь каждый гость обязательно отыщет что-то особенное, что ему понравится.
Тут ты можешь погрузиться в атмосферу чувственных удовольствий, где каждая мелочь продумана для твоего удовольствия. Предлагаемые на сайте возможности представлены в различных категориях от любовных фильмов до увлекательных сценариев — наилучший выбор для тех, кто ищет нечто особенное.
Не столь важно, хочешь ли ты отдохнуть в одиночку или отыскать новые ощущения — эта площадка обеспечит тебя наилучшим времяпрепровождением.
Мы отлично понимаем, как важен качественный релакс, именно поэтому контент нашего сайта не только многообразен, но и разработан с учётом всех нюансов. Забудь об обыденности и дай себе возможность насладиться в мир чувственных удовольствий.
Наш сайт создан для тех, кто ценит время для себя, и мы можем предложить всё, что нужно для полноценного расслабления после тяжёлого рабочего дня.
Только для зрелых. Только для тебя. Присоединяйся прямо сейчас и начни наслаждаться!
Fastest delivery and lowest prices for us online pharmacy no prescription needed hydrocodone from responsible pharmacies online if you desire competitive
Consider various price options before you cancun pharmacy vicodin to successfully diminish symptoms after locating great cost
Свежие и смешные анекдоты http://shutki-anekdoty.ru/anekdoty
продвижение сайта в поиске продвижение и реклама сайта
поддержка сайтов продвижение и раскрутка сайтов
поддержка сайта стоимость заказать сео продвижение сайта
Сайт приколов http://humor-kartinki.ru собрание лучших мемов, шуток и смешных видео, чтобы ваш день был ярче. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
сео продвижение сайтов москва заказать оптимизация сайтов продвижение сайта
สล็อตเว็บตรง
สล็อตเว็บตรงคือแพลตฟอร์มการเล่นผ่านเน็ตที่ให้นักเดิมพันเข้าสู่สล็อตแมชชีนได้โดยตรงจากหน้าเว็บ โดยไม่ต้องผ่านตัวแทนหรือตัวกลางใดๆ ข้อดีของเว็บสล็อตตรงคือความปลอดภัยเพิ่มขึ้น เนื่องจากนักเล่นไม่ต้องกังวลใจเรื่องความเสี่ยงจากการใช้บริการผ่านตัวกลาง อีกทั้งยังมีการมอบรางวัลที่สูงกว่าและข้อเสนอพิเศษมากมาย เนื่องจากไม่มีค่าบริการจากผู้แทน ทำให้นักเล่นเข้าถึงเกมสปินได้อย่างไม่ยุ่งยากและรวดเร็ว พร้อมรับประสบการณ์การเล่นเกมที่มีคุณภาพและไม่ชะงัก
การเล่น สล็อตตรง ไม่เหมือนกับ สล็อตปกติอย่างไร?
สล็อตเว็บตรงเป็นตัวเลือกที่ไม่มีการผ่านตัวแทน ทำให้นักเล่นสามารถเข้าถึง เกมและผลตอบแทนได้โดยตรงจากผู้ให้บริการ ลดความเสี่ยงในการถูกหลอกหรือเสียค่าธรรมเนียมสูง นอกจากนี้ เว็บสล็อตโดยตรงยังมีหลายแบบของเกมให้เลือกเล่นมากกว่าในสล็อตดั้งเดิม เนื่องจากสล็อตตรงมักจะได้รับการปรับปรุงและเพิ่มเกมหลากหลายอย่างไม่หยุดยั้ง อัตราการให้รางวัล (RTP) ของสล็อตตรงมักจะเหนือกว่าสล็อตทั่วไป เนื่องจากไม่มีค่านายหน้า ทำให้ผู้เล่นได้รับรางวัลที่สูงขึ้น อีกทั้งยัง โปรโมชั่นและโปรโมชั่นพิเศษที่มากกว่า โดยสล็อตตรงมักมีข้อเสนอเพิ่มเติมและโปรแกรมสะสมแต้มที่ให้ความคุ้มค่ามากขึ้น
ข้อเสนอพิเศษและโบนัสในสล็อตเว็บตรงที่ไม่ควรพลาด
สล็อตเว็บตรงมักมีข้อเสนอและโปรโมชั่นพิเศษที่น่าดึงดูดสำหรับนักเดิมพัน เริ่มตั้งแต่โบนัสแรกเข้าสำหรับสมาชิกใหม่ โบนัสเงินฝากเพิ่ม โบนัสฟรี รวมถึงโปรแกรมแลกคะแนนที่สามารถแลกเป็นเงินหรือสิทธิประโยชน์ต่างๆได้ ทำให้นักเล่นเกมมีความคุ้มค่าและประโยชน์มากมาย การมีข้อเสนอที่คุ้มค่าช่วยให้ผู้เล่นสามารถเพิ่มโอกาสในการชนะและประหยัดเงินในการเล่น นอกจากนี้ยังมีโปรโมชั่นพิเศษเช่นคืนเงินบางส่วนจากยอดเสียและการแจกของรางวัลตามวันสำคัญอีกด้วย
สรุปว่า สล็อตตรงเป็นทางเลือกที่คุ้มค่าสำหรับคนที่มองหา ความสะดวกและการรักษาความปลอดภัยในการเดิมพัน มีอัตราการจ่ายที่มากกว่า โปรโมชั่นมากมาย และความสนุกในการเล่นที่ยอดเยี่ยมโดยไม่มีการพึ่งพาตัวกลาง
Weed shop Israel
Dosage and Forms of Consumption
Medical cannabis in Israel is available in various forms, including dried flowers, oils, capsules, and extracts. The choice of form depends on the patient’s preferences and the doctor’s recommendations. Dosage is selected individually and requires gradual adjustment under specialist supervision to ensure maximum effectiveness with minimal side effects.
Medical cannabis and its use have become a hot topic in many countries, including Israel. In this article, we will look at how medical cannabis differs from regular cannabis, how to take it properly, where it can be purchased, and what patients have to say.
娛樂城
什麼是娛樂城?
娛樂城是一個讓玩家能夠透過網絡進行賭場遊戲的平台,與真實賭場相似,玩家可在此參與真錢遊戲。如果在娛樂城的遊戲中獲勝,便能賺取真金!賭博公社作為一個專業的娛樂城推薦平台,致力於為玩家提供真實、客觀的娛樂城評價資訊,幫助玩家選擇值得信賴的線上娛樂城。
娛樂城的專業術語
返水:返水是娛樂城回饋給玩家的金額,計算方式為「有效投注額 × 返水百分比」,是娛樂城用以激勵玩家的一種方式。
派彩:派彩指的是玩家在娛樂城遊戲中獲得的利潤。當玩家贏得遊戲後,娛樂城會將相應的獎金支付給玩家。
出金:出金是指玩家將娛樂城帳戶中的獲利轉出至個人帳戶的過程,這是玩家贏取獎金後將金額提取到自己帳戶的重要一步。
娛樂城儲值與出金流程
選擇線上娛樂城。
選擇存取款選項。
進入個人帳戶頁面進行存款操作。
輸入儲值或出金的金額。
完成操作,順利進行娛樂城的儲值或出金。
最受歡迎的娛樂城遊戲
在賭博公社中,從玩家的評價中篩選出一些廣受歡迎的娛樂城遊戲。第一名的是真人百家樂,隨後是電子老虎機。以下為部分熱門遊戲推薦:
DG百家樂 – ⭐️⭐️⭐️⭐️⭐️ (4826條評論)
DB百家樂 – ⭐️⭐️⭐️⭐️⭐️ (3554條評論)
RG百家樂 – ⭐️⭐️⭐️⭐️★ (4687條評論)
歐博真人 – ⭐️⭐️⭐️⭐️★ (3512條評論)
SA真人 – ⭐️⭐️⭐️⭐️★ (2415條評論)
關於賭博公社
賭博公社秉持著專業知識,致力於屏蔽各類網路上的娛樂城詐騙信息,並成為台灣首屈一指的娛樂城推薦指南。賭博公社提供最新的娛樂城排名,查證線上論壇如Dcard、Ptt及Facebook的娛樂城評價,為玩家提供真實可靠的資訊,幫助他們找到最安全、最值得信賴的賭博網站。
為何信任賭博公社?
賭博公社堅持客觀、公正的原則,提供娛樂城的真實評價與最新資訊。在當今資訊爆炸的網路時代,賭博公社作為玩家的嚮導,幫助他們避免陷入不實宣傳的陷阱,讓玩家能夠享受安全、合法的線上娛樂城遊戲體驗。
線上娛樂城常見問題
台灣線上娛樂城推薦哪些? 可以參考娛樂城排行來選擇。
娛樂城在台灣是否合法? 必須參考當地法規,以保證遊戲的合法性。
線上娛樂城是否安全? 賭博公社僅推薦持有合法執照並保證出金的娛樂城,保護玩家的權益。
在線上娛樂城贏錢需要繳稅嗎? 這取決於當地的稅務規定,玩家應查詢相關政策。
哪裡可以玩免費的線上娛樂城? 部分娛樂城提供免費試玩,玩家可以無需儲值體驗遊戲。
賭博公社致力於為玩家提供全方位的娛樂城資訊,是玩家尋找可靠娛樂城的理想指南。
Uncover top-notch Marc Jacobs deals at the marc jacobs outlet.
купить судовой диплом [url=https://diplomdarom.ru/]diplomdarom.ru[/url] .
When you need regular medication pharmacy coupons at any time.
You know the price of Celexa remains in my system too long, should I be worried?
Use the internet and find a ed pharmacy viagra remain in the body?
less that people prefer to shop online.Shop for great deals and pharmacy support viagra from an online pharmacy?
Сайт смешных историй http://shutki-anekdoty.ru/istorii собрание лучших веселых усторий. Ежедневное обновление контента для вашего настроения. Легко находите и делитесь забавными моментами с друзьями.
Смешные приколы на сайте https://subscribe.ru/author/31612079 Самые смешные приколы. делитесь с друзьями. Легко находите и делитесь забавными моментами с друзьями.
Чистка после пожара в Москве https://spec-uborka-posle-pozhara.ru/
bc game online
Can I expect tesco pharmacy orlistat pills to your door if you order what you need here
out the substantial discounts quoted through this site for allergy to successfully diminish symptoms after locating great cost
สล็อตไม่ผ่านเอเย่นต์คือแพลตฟอร์มการเล่นบนอินเทอร์เน็ตที่ให้นักเล่นเกมเข้าถึงเกมสล็อตได้โดยตรงจากหน้าเว็บ โดยไม่ต้องพึ่งพาผู้แทนหรือตัวกลางใดๆ ข้อดีของสล็อตเว็บตรงคือความปลอดภัยสูงขึ้น เนื่องจากนักเดิมพันไม่ต้องกังวลเรื่องโอกาสเสี่ยงจากการใช้บริการผ่านตัวกลาง อีกทั้งยังมีการมอบรางวัลที่เหนือกว่าและข้อเสนอพิเศษมากมาย เนื่องจากไม่มีค่านายหน้าจากผู้แทน ทำให้นักเล่นเข้าถึงเกมสล็อตได้อย่างไม่ยุ่งยากและรวดเร็ว พร้อมรับการเล่นที่มีคุณภาพและไม่สะดุด
การเดิมพัน สล็อตตรง ต่างจาก สล็อตทั่วไปอย่างไร?
สล็อตไม่ผ่านเอเย่นต์เป็นตัวเลือกที่ดีที่ไม่มีการผ่านเอเย่นต์ ทำให้ผู้เล่นสามารถเข้าถึง เกมและผลตอบแทนได้โดยตรงจากผู้ให้บริการ ลดโอกาสเสี่ยงในการโดนโกงหรือจ่ายค่านายหน้าสูง นอกจากนี้ สล็อตเว็บตรงยังมีหลายแบบของเกมให้เลือกมากกว่าในสล็อตทั่วไป เนื่องจากสล็อตตรงมักจะอัปเดตบ่อยและเพิ่มเกมหลากหลายอย่างต่อเนื่อง อัตราการมอบเงิน (การจ่ายคืน) ของสล็อตตรงมักจะมากกว่าสล็อตดั้งเดิม เนื่องจากไม่มีค่าธรรมเนียมพิเศษ ทำให้นักเดิมพันได้รับผลตอบแทนที่มีมูลค่ามากกว่า อีกทั้งยัง โปรโมชันและโบนัสที่หลากหลายกว่า โดยสล็อตเว็บตรงมักมีข้อเสนอที่น่าสนใจและโปรแกรมคะแนนที่น่าสนใจมากขึ้น
โปรโมชั่นและโปรโมชั่นพิเศษในสล็อตตรงที่น่าสนใจ
สล็อตตรงมักมีข้อเสนอและโปรโมชั่นพิเศษที่น่าดึงดูดสำหรับนักเดิมพัน เริ่มตั้งแต่โบนัสแรกเข้าสำหรับผู้ที่เพิ่งสมัคร โบนัสเติมเงิน เครดิตเล่นฟรี รวมถึงการสะสมคะแนนที่สามารถแลกแต้มหรือข้อเสนอพิเศษได้ ทำให้นักเล่นเกมได้รับผลตอบแทนและสิทธิประโยชน์มากมาย การมีโปรโมชั่นที่คุ้มค่าช่วยให้ผู้เล่นสามารถเพิ่มโอกาสรับรางวัลและประหยัดเงินในการเล่น นอกจากนี้ยังมีโปรโมชันเสริมเช่นคืนเงินบางส่วนจากยอดเสียและของแจกตามช่วงเทศกาลอีกด้วย
โดยรวมแล้ว เว็บสล็อตโดยตรงเป็นทางเลือกที่คุ้มค่าสำหรับผู้ที่ต้องการ การเล่นที่ง่ายและการรักษาความปลอดภัยในการเดิมพัน มีการจ่ายเงินที่มากกว่า โปรโมชั่นมากมาย และประสบการณ์การเล่นที่ยอดเยี่ยมโดยไม่มีการใช้ตัวแทน
1win mz
And kick your ailments. Guaranteed online proven methods with provigil online pharmacy at reputable pharmacies
Don’t buy from sites that say their depakote online pharmacy being offered by many sites, make it easy to shop.
bc game login
Короткие цитаты о смысле жизни. Цитаты известных людей.
Смешные приколы и юмор. Делитесь с друзьями. Всегда есть над чем посмеяться.
neon54 sign in
ah olamaz yine harika! lol hile satın al
neon54 sign in
4 win bet
Great! Thank you so much for sharing this. I can’t wait to use it.
demo pg slot
Hercules99: Kumpulan 8 Game Versi Demo Slot PG Anti Penipuan Terjamin di Indonesia
PGS telah menjadi pilihan favorit utama untuk banyak pemain slot di Indonesia, menghadirkan aneka gim yang menarik dengan pengalaman dan kebahagiaan tanpa batas. Di tengah popularitasnya, terdapat keraguan tentang adanya ketidakjujuran atau kecurangan dalam game online. Akan tetapi, Game PG telah berhasil menghadapi permasalahan tersebut dengan menghadirkan game slot anti-rungkad yang terpercaya dan amanah.
Dilengkapi fitur keamanan terkini dan fitur inovatif, PG Slot memastikan bahwa setiap game aman dan terkontrol untuk semua user. Inilah kumpulan 8 game demo PG bebas dari penipuan yang populer serta terpercaya di Indonesia:
1. Slot Tikus Keberuntungan
Mouse of Fortune merupakan permainan slot yang penuh daya tarik berbekal grafis cantik serta tema menarik. Di luar desainnya, game ini didukung enkripsi canggih PG Soft yang menjaga data pemain dan transaksinya. Semua putaran dipastikan tanpa gangguan, sehingga pemain tidak perlu khawatir.
2. Demo Dragon Hatch PG Slot
Menetas Naga memasukkan player ke semesta fiksi yang dipenuhi keajaiban serta aura mistis. Tetapi kelebihan utama gim ini terletak pada sistem keamanannya yang canggih. Menggunakan teknologi anti curang, slot ini menjaga kemenangan setiap pemain secara jujur bebas dari campur tangan luar.
3. Versi Demo Perjalanan Menuju Kekayaan Pocket Games Slot
Slot Journey Wealth memanggil pengguna dalam petualangan menemukan kekayaan tanpa akhir. Dengan bonus yang melimpah dan Return to Player yang tinggi, permainan ini memberikan kenikmatan bertambah sekaligus jaminan keadilan dalam setiap putarannya. Pemain bisa merasakan serunya bermain tanpa merasa khawatir akan kecurangan.
4. Uji Coba Surga Bikini Pocket Games Slot
Aplikasi ini membawa pemain ke nuansa pantai tropis yang elok serta penuh keceriaan. Di balik keindahan tropisnya, Slot Bikini dibekali sistem keamanan yang andal, yang membuatnya jadi game PGS tanpa curang yang diandalkan. User bisa bermain tanpa rasa takut manipulasi.
5. Versi Demo Medusa II Pocket Games Slot
Dalam slot Medusa II, pemain diajak dalam petualangan epik menghadapi monster legendaris. Game ini dilengkapi dengan keamanan mutakhir yang menjaga kejujuran tiap giliran. Oleh karena itu, pemain dapat fokus pada kemenangan tanpa terganggu campur tangan luar.
6. Percobaan Bom Jauh Pocket Games Slot
Mengusung tema perang yang mendalam, Bombs Away memacu adrenalin player. Dalam ketegangan permainan, keamanan masih jadi yang utama. Pengamanan PG Soft menjaga transaksi dan hasil game, memberikan keamanan bagi pemain di jalan menuju kemenangan.
7. Percobaan Adu Banteng Pocket Games Slot
Adu Banteng memasukkan player ke arena yang mendebarkan. Dalam game ini, PG Soft memastikan keadilan dalam setiap giliran. Pengguna bisa menikmati permainan dengan adil dan aman tanpa cemas adanya curang.
8. Uji Coba Muay Thai PG Slot
Slot Muay Thai Champion menawarkan tema bela diri yang menarik, mengajak pemain ke dalam pertarungan di atas ring. Game ini tidak hanya memikat dari sisi tema, dan juga keamanannya. Tiap giliran dipantau secara ketat, menjaga pengalaman bermain yang aman.
Nilai Positif Main Slot Demo PG Soft dengan RTP Besar
Demo game PG Soft anti-kecurangan dikenal dengan RTP besar yang di atas standar industri. Memberikan peluang lebih besar kepada pengguna untuk meraih pengembalian dari investasi mereka. Memilih slot PG Soft tidak sekadar hiburan, namun juga potensi untung yang lebih besar.
Dengan deretan game tersebut di atas, player bisa merasakan slot yang adil, aman, dan mengasyikkan. Teknologi modern di PG Slot memastikan bahwa setiap permainan berjalan tanpa hambatan, memberikan rasa percaya bagi pengguna.
vavada 100 free spins
Find out exciting freebies for ED treatments at ivermectin over the counter from foreign companies may put you at risk.
Смешные https://smeh.ru и юмор. Делитесь с друзьями. Всегда есть над чем посмеяться.
Планируете провести время с друзьями или семьёй в уютной обстановке? Мы предлагаем широкий выбор услуг: от классических парилок до современных спа-процедур. Подарите себе незабываемые впечатления, забронируйте сауну тут: https://dai-zharu.ru/
villas with pool real estate Montenegro
Лучшие порно видео Гей порно Бонсай скачать бесплатно без регистрации и смс. Смотреть порно онлайн в высоком качестве.
Лучшие порно видео Гей порно Бонсай скачать бесплатно без регистрации и смс. Смотреть порно онлайн в высоком качестве.
Тут можно преобрести купить несгораемый сейф сейф несгораемый
advisable to identify the best offers as soon as you decide to ivermectin canada because it is powerful medication
budva real estate Montenegro property sales
business for sale realty Montenegro
стоимость работ по укладке кафельной плитки https://ukladka-keramogranita-spb.ru
Тут можно преобрести купить сейф для охотничьего карабина шкаф для оружия цена
укладка кафельной плитки спб https://ukladka-keramogranita-spb.ru
Alto Consulting Group (ACG) https://alto-group.ru предлагает комплексные маркетинговые исследования рынков в России и за рубежом. Наша команда проводит детализированные обзоры рынков, анализирует экспорт и импорт по кодам ТНВЭД, а также изучает государственные и коммерческие закупки по 44-ФЗ и 223-ФЗ.
Скачать игры для Андроид https://igryforandroid.ru бесплатно и на русском языке, доступны новинки и популярные приложения.
Бюстгальтеры для вечерних платьев Какой размер бюстгальтера
apple iphone 16 pro 512 цены apple iphone 15 256gb
Wise people will purchase a buy ivermectin nz when you are done analyzing cost savings to get the best
Fast ivermectin human keep them away from direct sunlight.
property for sale in Montenegro https://www.apartments-for-sale-budva.com
Тут можно преобрести купить сейф под карабин сейф для оружия цена
No matter where you live, sites deliver a good price of ivermectin pills to fill your pet medications.
Займ 50 000 тенге Sravnim.kz
пройти соут https://sout095.ru
Internet drugstores list their prices for ivermectin walmart are unbelievably low they are probably counterfeit.
Займ 50 000 тенге qanat
спецоценка условий труда организации https://sout095.ru
Make sure that when you ivermectin for humans for consumers.
Immediately identify low prices and stromectol 0.5 mg after comparing online prices
сколько стоит прокат сноуборда Красная Поляна https://prokat-lyzh-krasnaya-polyana.ru
прокат в адлере https://prokat-lyzh-krasnaya-polyana.ru
айфон 512 гб цена apple iphone 15 купить
прокат сноубордов аренда горнолыжного снаряжения адлер
iphone 15 pro 256gb купить iphone 16 pro купить
Valuable treatment is available when you stromectol xr are cheaper at online pharmacies
Why spend extra cash for buy ivermectin canada . Order now!
купить диплом медбрата [url=https://prema365-diploms.ru/]prema365-diploms.ru[/url] .
старс кофе вакансии
less that people prefer to shop online.Shop for great deals and ivermectin 1 cream ? Should I seek a doctor’s advice?
Significantly reduced prices mean you can ivermectin lotion at a fraction of the normal cost
Казино на деньги Топ казино
Лучшие онлайн казино Скачать казино
укладка кафельной плитки в спб цены https://ukladka-keramogranita-spb.ru
красная поляна прокат лыж 2024 прокат лыж красная поляна
Быстрая схема покупки диплома старого образца: что важно знать?
webnewsrealty.ru/byistroe-oformlenie-diplomov-dlya-ambitsioznyih-lyudey
For people who use daily medications buying ivermectin stromectol by buying it online.
укладка кафельной плитки метр https://ukladka-keramogranita-spb.ru
Good pharmacies offer discounts when you ivermectin 20 mg through this portal deliver your treatment at affordable
the best ways for men to lead rewarding sex lives in bed.End ivermectin 3mg include comparing prices from online pharmacies
3D-печать представляет из себя современную технологию, которая основана на наплавлении фотополимеров слоями меньше миллиметра. Этот передовой способ производства деталей находит обширное применение в самых разных сферах жизни. Если вы хотите выяснить больше про 3д печать цена, то рекомендую http://filmsgood.ru/index.php?subaction=userinfo&user=exertexceed6: качество самое высокое
to a 2010 United Nations report. Receive low prices when you ivermectin 1 from legitimate pharmacies if you desire cheap discounts
Пошаговая инструкция по официальной покупке диплома о высшем образовании
Официальная покупка школьного аттестата с упрощенным обучением в Москве
the best ways for men to lead rewarding sex lives in bed.End ivermectin 12 mg for privacy.
the pricesAlways ask if you get something new when you ivermectin 8000 mcg sold on the Internet have been removed because of safety.
Бездепы — отличный способ погрузиться в мир азартных игр без затрат. https://t.me/s/bonus_bezdepozita предоставляют возможность игрокам изучить разные игровые автоматы и даже сорвать реальные деньги при соблюдении условий акции. Для получения бездепа необходимо пройти регистрацию на сайте казино и активировать предложение в личном кабинете. Стоит отметить, что все виды бездепозитных бонусов сопровождаются определёнными условиями использования: максимальная ставка.
Тут можно преобрести огнестойкий сейф купить сейф огнеупорный купить
casino site कैसीनो ऑनलाइन गेम स्लॉट खेल
укладка кафельной плитки укладка кафельной плитки в спб цены
slot games stake meaning in bengali new online casinos
bc.game casino
पैसे कमाने के लिए ऑनलाइन गेम casino days top casino
п»їदमन खेल 9winz भारत में सबसे अच्छा ऑनलाइन कैसीनो
купить аттестат гос образца [url=https://prema365-diploms.ru/]купить аттестат гос образца[/url] .
ऑनलाइन नकद खेल slots slots game online
укладка кафельной плитки в ванной цена работ укладке кафельной плитки
1xwin venezuela
daman casino 24 कैसीनो ऑनलाइन कैसीनो असली पैसे वाले गेम
We recommend exploring the best quotes collections: Love Songs Quotes From Great People
भाग्यशाली स्पिन एविएटर मनी गेम भारत में सबसे अच्छा कैसीनो ऐप
real money earning game ऑनलाइन दमन गेम gambling india
п»їदमन खेल tez888 स्लॉट खेल
bc.game casino
सर्वश्रेष्ठ कैसीनो असली पैसे वाले स्लॉट crazy time casino online
असली पैसे वाले कैसीनो online betting sites in india livecasino
OFAC compliance check for crypto wallets
Summary of Crypto Transfer Check and Regulatory Solutions
In today’s digital asset sector, maintaining transfer clarity and adherence with Anti-Laundering and Customer Identification standards is vital. Here is an outline of popular sites that offer solutions for digital asset transfer tracking, verification, and asset protection.
1. Token Metrics
Summary: Token Metrics offers digital asset evaluation to evaluate potential risk dangers. This solution allows individuals to review coins prior to purchase to avoid possibly scam resources. Attributes:
– Danger analysis.
– Perfect for buyers looking to bypass questionable or fraud assets.
2. Metamask Center
Overview: Metamask.Monitory.Center permits users to review their crypto assets for doubtful actions and regulatory conformity. Advantages:
– Validates coins for purity.
– Offers warnings about possible fund blockages on certain exchanges.
– Gives comprehensive results after wallet connection.
3. Bestchange.com
Description: Best Change is a service for observing and verifying digital trade transfers, providing openness and transaction safety. Benefits:
– Deal and holding monitoring.
– Sanctions screening.
– Internet portal; supports BTC and several other digital assets.
4. AMLCheck Bot
Description: AMLchek is a holding monitor and compliance compliance tool that utilizes AI methods to identify dubious actions. Advantages:
– Transfer monitoring and user verification.
– Offered via web version and Telegram bot.
– Works with digital assets including BSC, BTC, DOGE, and additional.
5. AlfaBit
Summary: AlfaBit offers thorough Anti-Money Laundering (AML) services customized for the crypto industry, supporting businesses and banks in maintaining regulatory compliance. Features:
– Thorough anti-money laundering tools and evaluations.
– Meets current security and regulatory standards.
6. AML Node
Overview: AML Node offers anti-money laundering and KYC services for cryptocurrency businesses, which includes transaction tracking, sanctions checks, and risk assessment. Features:
– Danger assessment options and restriction screenings.
– Important for guaranteeing secure company processes.
7. Btrace.AMLcrypto.io
Summary: Btrace AML Crypto focuses on asset check, offering transaction observation, sanctions screenings, and help if you are a target of theft. Advantages:
– Effective assistance for asset retrieval.
– Transaction tracking and security options.
Dedicated USDT Check Services
Our platform also provides information on multiple services that offer verification services for crypto transactions and accounts:
– **USDT TRC20 and ERC20 Verification:** Numerous sites provide thorough evaluations for USDT deals, aiding in the finding of doubtful actions.
– **AML Verification for USDT:** Tools are offered for tracking for suspicious actions.
– **“Cleanliness” Screenings for Holdings:** Verification of deal and account legitimacy is provided to detect likely threats.
**Conclusion**
Choosing the suitable service for checking and observing crypto deals is important for providing security and compliance conformity. By consulting our recommendations, you can find the best solution for transaction tracking and asset protection.
1win casino online
Узнайте, как безопасно купить диплом о высшем образовании
We recommend exploring the best quotes collections: Lovely Quotes From Great People
gambling games peri match online daman game
सर्वश्रेष्ठ ऑनलाइन कैसीनो असली पैसे वाले कैसीनो 1xbet
2 win
Loving the info on this site, you have done outstanding job on the posts.
नया कैसीनो लाइव ब्लैकजैक casino in south goa
कैसीनो live blackjack daman games online
vavada online casino
услуги по оценке условий труда работников услуги по специальной оценке условий труда
navigate to these guys https://casinomira.com/casino/milkyway-casino/
Eyebrows Austin
bcgame casino
perimatch कैश गेम ऑनलाइन भारत में शीर्ष 10 ऑनलाइन कैसीनो
स्लॉट कैसीनो online casino bonus भारत में ऑनलाइन सट्टेबाजी साइटें
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
dliavas.listbb.ru/viewtopic.php?f=19&t=6050
भारत में सट्टा खेलें play india satta कैसीनो परिणाम
slot meaning in bengali लाइव क्रिकेट सट्टा दरें ऐप online daman game
1win login
Looking for excitement? Aviator offers real-time decisions where you can win big or lose fast. Cash out before the plane flies away, or keep climbing to maximize winnings. Available with demo options for first-timers!
play aviator online [url=https://aviator-games-online.ru/]aviator real money game[/url] .
bc.game login
कैसीनो खेल spin game online कैसीनो ऑनलाइन असली पैसे
कैसीनो ऑनलाइन सट्टेबाजी casinos सभी स्लॉट गेम
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
real game money aviator casino slots win
fun game casino online money games best online casino real money
neon54 app
vavada
WONDERFUL Post.thanks for share..extra wait .. …
prodamus промокод [url=prodamus-promokod21.ru]prodamus-promokod21.ru[/url] .
vavada promo codes
можно ли купить диплом в реестре [url=https://1oriks-diplom199.ru/]1oriks-diplom199.ru[/url] .
vavada bonus
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
1 win online
casino 1win
vavada casino no deposit bonus
Уборка квартир с очень запущенным состоянием https://ochistka-zahlamlyonnyh-kvartir.ru/
Aviator is all about timing and big wins. Start with demo play to understand the mechanics, then join the real money excitement. Popular with Indian players, the game rewards patience and a quick finger on the cash-out.
online aviator game [url=https://aviator-games-online.ru/]aviator crash game[/url] .
Great! Thank you so much for sharing this. I can’t wait to use it.
Great! Thank you so much for sharing this. I can’t wait to use it.
Your article helped me a lot, is there any more related content? Thanks!
items4games
Discover a Realm of Gaming Chances with Items4Games
At Items4Games, we deliver a vibrant marketplace for enthusiasts to acquire or sell profiles, items, and features for top titles. If you are seeking to improve your game arsenal or interested in selling your profile, our service offers a smooth, protected, and valuable experience.
Reasons to Choose Items4Play?
**Broad Game Catalog**: Discover a large selection of titles, from thrilling adventures like Battleground and Call of Duty to immersive adventure games like ARK and Genshin. We include everything, guaranteeing no gamer is overlooked.
**Range of Services**: Our products include account purchases, virtual money, exclusive goods, trophies, and training options. If you need assistance improving or obtaining special benefits, we have it all.
**Easy Navigation**: Explore easily through our systematized marketplace, categorized alphabetically to get exactly the game you need fast.
**Secure Deals**: We ensure your protection. All exchanges on our marketplace are handled with the top security to secure your private and payment information.
**Key Points from Our Collection**
– **Survival and Exploration**: Titles ARK and Day-Z give you the chance to enter challenging environments with premium goods and passes on offer.
– **Tactical and Exploration**: Boost your gameplay in games such as Royal Clash and Age of Wonders 4 with virtual money and options.
– **Competitive Gaming**: For competitive fans, improve your technique with mentoring and level-ups for Valorant, DotA, and League of Legends.
**A Platform Made for Gamers**
Backed by ApexTech, a reliable company certified in Kazakhstan, Items4Games is a place where video game wishes come true. From acquiring pre-order keys for the newest titles to finding hard-to-find in-game treasures, our site meets every gamer’s need with expertise and efficiency.
Join the gaming family right away and boost your game play!
For questions or guidance, reach out to us at **support@items4games.com**. Let’s improve the game, as one!
teen patti lucky 100 888 स्पोर्ट कैसीनो डेज़ इंडिया
असली पैसे वाले कैसीनो daman game app स्लॉट गेम
Как официально купить аттестат 11 класса с упрощенным обучением в Москве
1xbet online top 10 online casino in india casio login
कैसीनो साइट्स भारत में कैसीनो ऑनलाइन गेम असली पैसे
промокод robokassa [url=https://www.promokod-robokassa.ru]промокод robokassa[/url] .
The best prices can be found by means of online offers to flagyl for dogs for details.
Your article helped me a lot, is there any more related content? Thanks!
Powerful treatment is available when you valtrex breastfeeding at greatly reduced prices
Официальная покупка диплома вуза с сокращенной программой обучения в Москве
доставка алкоголя в москве круглосуточно https://dostavka-alcogolya-mix-1.ru/
доставка алкоголя на дом круглосуточно https://dostavka-alcogolya-nochyu.ru/
Обработка стен от плесени на балконе https://unichtozhenie-pleseni-spb-lo.ru/
Обработать квартиру после умершего https://dezinfekciya-smerti-msk-mo.ru/
доставка алкоголя в москве круглосуточно https://dostavka-alcogolya-city-2.ru/
Всё, что нужно знать о покупке аттестата о среднем образовании без рисков
californiarpn2.listbb.ru/viewtopic.php?f=1&t=851
доставка алкоголя https://dostavka-alcogolya-v-moskve.ru/
Полезные советы по безопасной покупке диплома о высшем образовании
охрана труда обучение дистанционно в москве https://ohrana-truda-distancionno.ru
Discover a Realm of Gaming Chances with Items4Games
At Items4Games, we provide a dynamic hub for enthusiasts to buy or exchange accounts, virtual items, and options for some of the most popular games. If you’re looking to upgrade your gaming arsenal or interested in selling your account, our platform delivers a smooth, protected, and valuable process.
Why Select Items4Games?
**Broad Title Catalog**: Browse a extensive variety of titles, from action-packed games such as Warzone and War Call to engaging adventure games like ARK: Survival Evolved and Genshin Impact. We cover all games, making sure no player is left behind.
**Selection of Features**: Our selections feature account purchases, credits, exclusive items, milestones, and coaching services. If you want help gaining levels or unlocking special benefits, we are here to help.
**Easy Navigation**: Browse easily through our systematized site, organized in order to get precisely what you want with ease.
**Protected Exchanges**: We ensure your security. All trades on our platform are conducted with the top safeguarding to protect your confidential and financial data.
**Highlights from Our Offerings**
– **Survival and Adventure**: Titles ARK: Survival Evolved and Day-Z allow you to explore tough worlds with premium goods and keys on offer.
– **Strategy and Adventure**: Enhance your performance in games like Clash Royale and Wonders Age with credits and options.
– **Professional Gaming**: For competitive fans, improve your technique with coaching and account upgrades for Valored, Dota, and League of Legends.
**A Hub Designed for Players**
Backed by ApexTech, a trusted company registered in Kazakhstan, Items4Play is a market where playtime wishes are realized. From purchasing advance passes for the newest releases to finding hard-to-find in-game treasures, our marketplace caters to every gamer’s requirement with professionalism and efficiency.
Become part of the community now and elevate your game adventure!
For inquiries or help, reach out to us at **support@items4games.com**. Let’s game better, as one!
1win casino
Сколько стоит диплом высшего и среднего образования и как это происходит?
bc game apk
bc game download android
BBgate MarketPlace 2024 Breaking Bad Gate Forum
BBgate MarketPlace
bc game top
промокод продамус на 5000 [url=www.rubiz.forum.cool/viewtopic.php?id=3874#p13907]www.rubiz.forum.cool/viewtopic.php?id=3874#p13907[/url] .
Купить диплом магистра оказалось возможно, быстрое обучение и диплом на руки
one win casino
1win bet mocambique
Официальная покупка школьного аттестата с упрощенным обучением в Москве
vavada 100 free spins
Most Popular Earning App in Pakistan|Easy Way to Earn in Pakistan|Earning Potential in Pakistan|Pakistan Money Processing Software|Rate the Best Earning App in Pakistan|Pakistan Earning Opportunities|Pakistan Right Choice for Processing|New level of income in Pakistan|Pakistan: leader in earning|App that will make it easier to earn in Pakistan Pakistan
earn money app pakistan [url=https://bestearningappinpakistan.com/]pk earning app[/url] .
THA娛樂城與九州娛樂簡介
THA娛樂城是九州娛樂旗下的一個知名線上娛樂平台,致力於為玩家提供多元化且優質的娛樂服務。九州娛樂是亞洲地區領先的線上娛樂品牌,長期專注於打造穩定、公平且充滿樂趣的遊戲環境,旗下擁有多個知名娛樂平台,而THA娛樂城便是其中的一個旗艦產品。以下將詳細介紹THA娛樂城的特色與服務。
THA娛樂城的遊戲種類
THA娛樂城為玩家提供了多樣化的遊戲選擇,滿足不同玩家的需求與興趣,包括以下幾大類別:
1. 體育投注
體育迷可以在THA娛樂城享受豐富的體育賽事投注,涵蓋足球、籃球、網球等多項國際體育比賽。平台提供即時賠率和多種投注選項,讓玩家隨時掌握比賽動態並進行下注。
2. 真人娛樂
真人娛樂區提供即時互動的遊戲體驗,玩家可透過直播技術與真人荷官互動,遊玩如百家樂、輪盤、骰寶等經典遊戲。這不僅增添了真實感,更讓玩家有身臨其境的感受。
3. 電子老虎機
THA娛樂城匯集了多款高人氣的電子老虎機遊戲,從經典水果機到新潮主題機,皆配備精美的畫面與流暢的操作介面,為玩家帶來無限樂趣。
4. 捕魚遊戲
捕魚遊戲是許多玩家的最愛,THA娛樂城提供多種精美場景和豐富玩法的捕魚遊戲,玩家可以挑戰高額獎勵,享受射擊與策略結合的獨特樂趣。
5. 彩票與其他遊戲
除了以上幾類,平台還提供彩票遊戲及其他創新型娛樂遊戲,適合喜歡嘗試新鮮玩法的玩家。
九州娛樂的技術支持
作為THA娛樂城的母公司,九州娛樂以其強大的技術實力與嚴謹的管理體系為平台提供支持。九州娛樂採用國際領先的安全加密技術,確保玩家的個人資訊與交易數據得到妥善保護。此外,平台的遊戲結果皆經過嚴格的隨機性測試與第三方機構認證,保證公平公正。
優質的會員服務
THA娛樂城致力於打造一個高品質的會員體驗,其服務特色包括:
– 優惠活動
平台定期推出多種促銷活動,如新會員註冊禮金、存款返利、週週回饋等,讓玩家享受更多的遊戲資金。
– 快速出入金
平台提供便捷且快速的存提款服務,玩家可以安心進行資金操作,且無需擔心延遲問題。
– 24小時客戶服務
為了確保玩家的需求能即時被解決,THA娛樂城提供全年無休的客服支援,無論是遊戲問題還是技術諮詢,客服團隊都能快速回應。
與其他平台的區別
THA娛樂城之所以能在眾多線上娛樂平台中脫穎而出,不僅因其豐富的遊戲種類與高品質服務,更在於它所帶來的獨特價值:
1. 品牌信譽
作為九州娛樂旗下的品牌,THA娛樂城擁有長期積累的良好信譽,是許多玩家的首選。
2. 創新與多樣性
平台不斷推出新遊戲與創意玩法,讓玩家始終保持新鮮感。
3. 本地化服務
THA娛樂城深諳玩家需求,提供多語言支援與符合本地習慣的服務,提升玩家的使用便利性。
未來展望
隨著線上娛樂行業的快速發展,THA娛樂城也在持續進步與創新,力求為玩家帶來更多驚喜。無論是透過引進新的遊戲技術、擴展遊戲種類,還是改善服務品質,THA娛樂城都希望成為每位玩家的最佳娛樂夥伴。
總結來說,THA娛樂城憑藉其豐富的遊戲內容、可靠的技術支持以及優質的會員服務,已在亞洲娛樂市場佔有一席之地。如果您正在尋找一個結合刺激與信賴的娛樂平台,那麼THA娛樂城絕對值得一試。
vavada online casino
bc game crash
vavada site
neon54 ????????
THA娛樂城與九州娛樂簡介
THA娛樂城是九州娛樂旗下的一個知名線上娛樂平台,致力於為玩家提供多元化且優質的娛樂服務。九州娛樂是亞洲地區領先的線上娛樂品牌,長期專注於打造穩定、公平且充滿樂趣的遊戲環境,旗下擁有多個知名娛樂平台,而THA娛樂城便是其中的一個旗艦產品。以下將詳細介紹THA娛樂城的特色與服務。
THA娛樂城的遊戲種類
THA娛樂城為玩家提供了多樣化的遊戲選擇,滿足不同玩家的需求與興趣,包括以下幾大類別:
1. 體育投注
體育迷可以在THA娛樂城享受豐富的體育賽事投注,涵蓋足球、籃球、網球等多項國際體育比賽。平台提供即時賠率和多種投注選項,讓玩家隨時掌握比賽動態並進行下注。
2. 真人娛樂
真人娛樂區提供即時互動的遊戲體驗,玩家可透過直播技術與真人荷官互動,遊玩如百家樂、輪盤、骰寶等經典遊戲。這不僅增添了真實感,更讓玩家有身臨其境的感受。
3. 電子老虎機
THA娛樂城匯集了多款高人氣的電子老虎機遊戲,從經典水果機到新潮主題機,皆配備精美的畫面與流暢的操作介面,為玩家帶來無限樂趣。
4. 捕魚遊戲
捕魚遊戲是許多玩家的最愛,THA娛樂城提供多種精美場景和豐富玩法的捕魚遊戲,玩家可以挑戰高額獎勵,享受射擊與策略結合的獨特樂趣。
5. 彩票與其他遊戲
除了以上幾類,平台還提供彩票遊戲及其他創新型娛樂遊戲,適合喜歡嘗試新鮮玩法的玩家。
九州娛樂的技術支持
作為THA娛樂城的母公司,九州娛樂以其強大的技術實力與嚴謹的管理體系為平台提供支持。九州娛樂採用國際領先的安全加密技術,確保玩家的個人資訊與交易數據得到妥善保護。此外,平台的遊戲結果皆經過嚴格的隨機性測試與第三方機構認證,保證公平公正。
優質的會員服務
THA娛樂城致力於打造一個高品質的會員體驗,其服務特色包括:
– 優惠活動
平台定期推出多種促銷活動,如新會員註冊禮金、存款返利、週週回饋等,讓玩家享受更多的遊戲資金。
– 快速出入金
平台提供便捷且快速的存提款服務,玩家可以安心進行資金操作,且無需擔心延遲問題。
– 24小時客戶服務
為了確保玩家的需求能即時被解決,THA娛樂城提供全年無休的客服支援,無論是遊戲問題還是技術諮詢,客服團隊都能快速回應。
與其他平台的區別
THA娛樂城之所以能在眾多線上娛樂平台中脫穎而出,不僅因其豐富的遊戲種類與高品質服務,更在於它所帶來的獨特價值:
1. 品牌信譽
作為九州娛樂旗下的品牌,THA娛樂城擁有長期積累的良好信譽,是許多玩家的首選。
2. 創新與多樣性
平台不斷推出新遊戲與創意玩法,讓玩家始終保持新鮮感。
3. 本地化服務
THA娛樂城深諳玩家需求,提供多語言支援與符合本地習慣的服務,提升玩家的使用便利性。
未來展望
隨著線上娛樂行業的快速發展,THA娛樂城也在持續進步與創新,力求為玩家帶來更多驚喜。無論是透過引進新的遊戲技術、擴展遊戲種類,還是改善服務品質,THA娛樂城都希望成為每位玩家的最佳娛樂夥伴。
總結來說,THA娛樂城憑藉其豐富的遊戲內容、可靠的技術支持以及優質的會員服務,已在亞洲娛樂市場佔有一席之地。如果您正在尋找一個結合刺激與信賴的娛樂平台,那麼THA娛樂城絕對值得一試。
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр philips в москве, можете посмотреть на сайте: сервисный центр philips в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Easily review deals and duloxetine hcl 30 mg benefits and drawbacks?
Discreet shipping, fantastic prices. Order mirtazapine 15 mg for dogs are advantages of internet shopping.
neon 57
娛樂城
RG富遊娛樂城是亞洲地區知名的線上娛樂平台,致力於為玩家提供多元化且高品質的遊戲體驗。自成立以來,RG富遊娛樂城以其豐富的遊戲種類、優質的服務以及安全可靠的遊戲環境,贏得了廣大玩家的信賴與支持。
遊戲種類
RG富遊娛樂城提供多樣化的遊戲選擇,滿足不同玩家的需求:
真人娛樂:包括百家樂、輪盤、骰寶等,玩家可與真人荷官即時互動,享受真實賭場的氛圍。
電子遊戲:涵蓋各類老虎機、電子撲克等,遊戲畫面精美,玩法多樣,帶來無限樂趣。
體育投注:提供足球、籃球、網球等多項體育賽事的投注服務,賠率公正,資訊即時更新。
彩票遊戲:包括各類熱門彩票遊戲,玩法簡單,獎金豐厚,讓玩家輕鬆參與。
捕魚遊戲:精美的海底世界場景,豐富的魚種和道具,帶來刺激的捕魚體驗。
平台特色
安全可靠:RG富遊娛樂城採用先進的加密技術,保障玩家的個人資訊和資金安全,並持有合法的營業執照,受相關監管機構監管。
優惠活動:平台定期推出各類優惠活動,如首儲贈送、返水優惠、抽獎活動等,讓玩家享受更多福利。
客戶服務:提供24小時在線客服,隨時解答玩家的疑問,確保每位玩家都能獲得及時的幫助。
多元支付:支持多種支付方式,存提款快捷方便,滿足不同玩家的需求。
玩家評價
許多玩家對RG富遊娛樂城給予了高度評價,認為平台遊戲種類豐富,操作簡便,出入金迅速,客服服務專業且友善。此外,平台的優惠活動也深受玩家喜愛,增加了遊戲的樂趣和收益。
總結
RG富遊娛樂城以其多元化的遊戲選擇、優質的服務和安全可靠的遊戲環境,成為眾多玩家的首選線上娛樂平台。無論您是新手還是老玩家,都能在這裡找到適合自己的遊戲,享受極致的娛樂體驗。
RG富遊娛樂城簡介
RG富遊娛樂城是亞洲地區知名的線上娛樂平台,致力於為玩家提供多元化且高品質的遊戲體驗。自成立以來,RG富遊娛樂城以其豐富的遊戲種類、優質的服務以及安全可靠的遊戲環境,贏得了廣大玩家的信賴與支持。
遊戲種類
RG富遊娛樂城提供多樣化的遊戲選擇,滿足不同玩家的需求:
真人娛樂:包括百家樂、輪盤、骰寶等,玩家可與真人荷官即時互動,享受真實賭場的氛圍。
電子遊戲:涵蓋各類老虎機、電子撲克等,遊戲畫面精美,玩法多樣,帶來無限樂趣。
體育投注:提供足球、籃球、網球等多項體育賽事的投注服務,賠率公正,資訊即時更新。
彩票遊戲:包括各類熱門彩票遊戲,玩法簡單,獎金豐厚,讓玩家輕鬆參與。
捕魚遊戲:精美的海底世界場景,豐富的魚種和道具,帶來刺激的捕魚體驗。
平台特色
安全可靠:RG富遊娛樂城採用先進的加密技術,保障玩家的個人資訊和資金安全,並持有合法的營業執照,受相關監管機構監管。
優惠活動:平台定期推出各類優惠活動,如首儲贈送、返水優惠、抽獎活動等,讓玩家享受更多福利。
客戶服務:提供24小時在線客服,隨時解答玩家的疑問,確保每位玩家都能獲得及時的幫助。
多元支付:支持多種支付方式,存提款快捷方便,滿足不同玩家的需求。
玩家評價
許多玩家對RG富遊娛樂城給予了高度評價,認為平台遊戲種類豐富,操作簡便,出入金迅速,客服服務專業且友善。此外,平台的優惠活動也深受玩家喜愛,增加了遊戲的樂趣和收益。
總結
RG富遊娛樂城以其多元化的遊戲選擇、優質的服務和安全可靠的遊戲環境,成為眾多玩家的首選線上娛樂平台。無論您是新手還是老玩家,都能在這裡找到適合自己的遊戲,享受極致的娛樂體驗。
vavada казино
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр philips, можете посмотреть на сайте: сервисный центр philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
discounted prices from respectable pharmacies before you lisinopril vs norvasc Learn more about it!
dinnerExcellent health benefits are attainable when you does prednisone make you gain weight from legitimate online pharmacies in order to get the best
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр philips в москве, можете посмотреть на сайте: официальный сервисный центр philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
일본배대지
메인 서비스: 간편하고 효율적인 배송 및 구매 대행 서비스
1. 대행 서비스 주요 기능
메인 서비스는 고객이 한 번에 필요한 대행 서비스를 신청할 수 있도록 다양한 기능을 제공합니다.
배송대행 신청: 국내외 상품 배송을 대신 처리하며, 효율적인 시스템으로 신속한 배송을 보장합니다.
구매대행 신청: 원하는 상품을 대신 구매해주는 서비스로, 고객의 수고를 줄입니다.
엑셀 대량 등록: 대량 상품을 엑셀로 손쉽게 등록 가능하여 상업 고객의 편의성을 증대합니다.
재고 관리 신청: 창고 보관 및 재고 관리를 통해 물류 과정을 최적화합니다.
2. 고객 지원 시스템
메인 서비스는 사용자 친화적인 접근성을 제공합니다.
유저 가이드: 대행 서비스를 더욱 합리적으로 사용할 수 있도록 세부 안내서를 제공합니다.
운송장 조회: 일본 사가와 등 주요 운송사의 추적 시스템과 연동하여 운송 상황을 실시간으로 확인 가능합니다.
3. 비용 안내와 부가 서비스
비용 계산기: 예상되는 비용을 간편하게 계산해 예산 관리를 돕습니다.
부가 서비스: 교환 및 반품, 폐기 및 검역 지원 등 추가적인 편의 서비스를 제공합니다.
출항 스케줄 확인: 해외 배송의 경우 출항 일정을 사전에 확인 가능하여 배송 계획을 세울 수 있습니다.
4. 공지사항
기본 검수 공지
무료 검수 서비스로 고객의 부담을 줄이며, 보다 철저한 검수가 필요한 경우 유료 정밀 검수 서비스를 권장합니다.
수출허가서 발급 안내
항공과 해운 수출 건에 대한 허가서를 효율적으로 발급받는 방법을 상세히 안내하며, 고객의 요청에 따라 이메일로 전달됩니다.
노데이터 처리 안내
운송장 번호 없는 주문에 대한 새로운 처리 방안을 도입하여, 노데이터 발생 시 관리비가 부과되지만 서비스 품질을 개선합니다.
5. 고객과의 소통
카카오톡 상담: 실시간 상담을 통해 고객의 궁금증을 해결합니다.
공지사항 알림: 서비스 이용 중 필수 정보를 지속적으로 업데이트합니다.
메인 서비스는 고객 만족을 최우선으로 하며, 지속적인 개선과 세심한 관리를 통해 최상의 경험을 제공합니다.
일본 소비세 환급, 네오리아와 함께라면 간편하고 안전하게
일본 소비세 환급은 복잡하고 까다로운 절차로 많은 구매대행 셀러들이 어려움을 겪는 분야입니다. 네오리아는 다년간의 경험과 전문성을 바탕으로 신뢰할 수 있는 서비스를 제공하며, 일본 소비세 환급 과정을 쉽고 효율적으로 처리합니다.
1. 일본 소비세 환급의 필요성과 네오리아의 역할
네오리아는 일본 현지 법인을 설립하지 않아도 합법적인 방식으로 소비세 환급을 받을 수 있는 솔루션을 제공합니다. 이를 통해:
한국 개인사업자와 법인 사업자 모두 간편하게 환급 절차를 진행할 수 있습니다.
일본의 복잡한 서류 심사를 최소화하고, 현지 로컬 세리사와 협력하여 최적의 결과를 보장합니다.
2. 소비세 환급의 주요 특징
일본 연고가 없어도 가능: 일본에 사업자가 없더라도 네오리아는 신뢰할 수 있는 서비스를 통해 소비세 환급을 지원합니다.
서류 작성 걱정 해결: 잘못된 서류 제출로 환급이 거절될까 걱정될 필요 없습니다. 네오리아의 전문 대응팀이 모든 과정을 정밀하게 관리합니다.
현지 법인 운영자를 위한 추가 지원: 일본 내 개인사업자나 법인 운영자에게는 세무 감사와 이슈 대응까지 포함된 고급 서비스를 제공합니다.
3. 네오리아 서비스의 장점
전문성과 신뢰성: 정부로부터 인정받은 투명성과 세무 분야의 우수한 성과를 자랑합니다.
맞춤형 서포트: 다양한 사례를 통해 쌓은 경험으로 고객이 예상치 못한 어려움까지 미리 해결합니다.
로컬 업체에서 불가능한 고급 서비스: 한국인 고객을 위해 정확하고 간편한 세무회계 및 소비세 환급 서비스를 제공합니다.
4. 네오리아가 제공하는 혜택
시간 절약: 복잡한 절차와 서류 준비 과정을 전문가가 대신 처리합니다.
안심 환급: 철저한 관리와 세심한 대응으로 안전하게 환급을 받을 수 있습니다.
추가 서비스: 세무감사와 이슈 발생 시 즉각적인 지원으로 사업의 연속성을 보장합니다.
네오리아는 소비세 환급이 복잡하고 어렵다고 느껴지는 고객들에게 최적의 길잡이가 되어드립니다. 신뢰를 바탕으로 한 전문적인 서비스로, 더 이상 소비세 환급 문제로 고민하지 마세요!
st666 bóng đá
ST666 – Nền tảng sòng bạc trực tuyến hàng đầu tại Việt Nam
ST666 tự hào là một trong những thương hiệu uy tín hàng đầu trong lĩnh vực giải trí và sòng bạc trực tuyến tại châu Á. Với nhiều năm liên tục được bình chọn 5 sao, ST666 mang đến cho người chơi những trải nghiệm đẳng cấp và an toàn.
Lý do chọn ST666
Thương hiệu đáng tin cậy
ST666 là nền tảng được hàng triệu người chơi tại Việt Nam tin tưởng nhờ danh tiếng lâu năm và sự minh bạch trong hoạt động.
Sản phẩm đa dạng
Người chơi có thể tận hưởng hàng loạt trò chơi hấp dẫn như:
Nổ hũ: Đem lại cơ hội trúng thưởng lớn với đồ họa sống động.
Sòng bài: Bao gồm các trò chơi cổ điển như bài cào, baccarat, poker.
Thể thao: Đặt cược các trận đấu bóng đá, bóng rổ với tỷ lệ hấp dẫn.
Xổ số và bắn cá: Các trò chơi thú vị dành cho người yêu thích thử thách.
Đá gà: Một hình thức giải trí truyền thống được nâng cấp với chất lượng trực tuyến.
An ninh bảo mật
ST666 áp dụng công nghệ bảo mật tiên tiến, đảm bảo thông tin và giao dịch của người chơi luôn an toàn tuyệt đối.
Giao dịch nhanh chóng
Với hệ thống xử lý tự động hiện đại, ST666 cung cấp tốc độ nạp rút nhanh nhất, giúp người chơi tận hưởng trải nghiệm mượt mà.
Khuyến mãi hấp dẫn và dịch vụ chuyên nghiệp
ST666 không chỉ nổi bật với chất lượng sản phẩm mà còn thường xuyên tổ chức các chương trình khuyến mãi, tặng thưởng lớn. Đội ngũ hỗ trợ 24/7 luôn sẵn sàng giải đáp thắc mắc của khách hàng một cách tận tình.
Tin tức và mẹo chơi đá gà từ ST666
ST666 không ngừng cập nhật các bí quyết và thông tin mới nhất về đá gà, giúp người chơi nâng cao chiến lược và kỹ thuật. Từ việc chọn gà đá phù hợp đến cách chăm sóc và điều trị, mọi kiến thức đều được chia sẻ một cách chi tiết và chuyên nghiệp.
Tham gia ngay hôm nay!
Hãy truy cập ST666 – Trang chủ chính thức để trải nghiệm thế giới sòng bạc trực tuyến đa dạng và uy tín nhất. Không chỉ là nơi giải trí, ST666 còn mang đến cơ hội kiếm tiền hấp dẫn cho mọi người chơi.
Chơi ngay – Trải nghiệm đỉnh cao tại ST666!
Find out exciting freebies for ED treatments at how to remain intimate when taking tamoxifen ? Find out the truth right here.
Покупка школьного аттестата с упрощенной программой: что важно знать
Many people feel that buying alcohol and prednisone for your prescription.
1win login
ST666.LOVE – Nhà cái uy tín và nền tảng cá cược hàng đầu tại Việt Nam
ST666 là một thương hiệu cá cược nổi bật tại Việt Nam, mang đến trải nghiệm giải trí toàn diện và an toàn cho người chơi. Với hàng loạt tính năng hiện đại, chương trình khuyến mãi hấp dẫn, và dịch vụ chăm sóc khách hàng tận tâm, ST666 xứng đáng là lựa chọn số một của bạn trong thế giới cá cược trực tuyến.
Thông báo quan trọng về link đăng nhập ST666
Để đảm bảo an toàn và tránh các trường hợp gián đoạn truy cập, link đăng nhập vào ST666 có thể thay đổi liên tục. Trước khi nạp tiền, quý khách vui lòng liên hệ với nhân viên hỗ trợ để nhận thông tin mới nhất. Chúng tôi cam kết đồng hành cùng bạn, mang đến trải nghiệm cá cược may mắn và thuận lợi.
Các tính năng nổi bật của ST666
Hệ thống sảnh chơi đa dạng
Casino: Đắm mình trong không gian sòng bài trực tuyến sang trọng.
Thể thao: Đặt cược với tỷ lệ hấp dẫn trong các trận đấu thể thao hàng đầu.
Đá gà: Trực tiếp từ đấu trường SV388 với chất lượng video sắc nét.
Slot quay, bắn cá, xổ số, eSport: Phong phú lựa chọn, thỏa sức trải nghiệm.
Khuyến mãi hấp dẫn
Thưởng 100% nạp đầu: Tăng gấp đôi cơ hội chiến thắng.
Hoàn tiền 10% mỗi ngày: An tâm chơi không lo rủi ro.
Thưởng nóng: Nhận ngay 100K cho thành viên mới.
Ứng dụng ST666 tiện lợi
Tải app ST666 trên các nền tảng iOS và Android, giúp bạn truy cập dễ dàng, mọi lúc mọi nơi.
An toàn và minh bạch
ST666 được cấp chứng chỉ hoạt động hợp pháp, cam kết mang đến môi trường cá cược uy tín, bảo mật cao.
Hướng dẫn tham gia ST666
Đăng ký tài khoản: Nhanh chóng qua giao diện thân thiện của website hoặc ứng dụng.
Đăng nhập và nạp tiền: Sử dụng nhiều phương thức thanh toán tiện lợi.
Rút tiền dễ dàng: Hệ thống xử lý giao dịch tự động, đảm bảo tốc độ nhanh chóng.
Trải nghiệm đẳng cấp tại ST666.LOVE
ST666 không chỉ là nền tảng giải trí mà còn là nơi hội tụ của những trò chơi cá cược đỉnh cao. Hãy tham gia ngay hôm nay để nhận nhiều ưu đãi hấp dẫn và trải nghiệm những phút giây sôi động.
Liên hệ ST666 để được hỗ trợ và nhận link đăng nhập mới nhất. Chúc quý khách may mắn!
asiast6666
ST666 | Đăng Nhập Nhà Cái ST666 Chính Thức Năm 2023
ST666 là điểm đến lý tưởng cho nhiều game thủ hiện nay, với vô số dịch vụ và sản phẩm hấp dẫn. Nơi đây được đánh giá cao và được ưu tiên bởi những người chơi đam mê cá cược. Hãy cùng tìm hiểu kỹ hơn về ST666 trong bài viết dưới đây.
ST666 – Nhà cái cá cược uy tín hàng đầu Châu Á
ST666 đã được cấp phép hoạt động bởi tổ chức PAGCOR cùng First Cagayan, đảm bảo độ tin cậy và an toàn cho người chơi. Với nhiều loại hình cá độ đa dạng, từ cá cược thể thao cho đến casino trực tuyến, ST666 mang đến cho người chơi sự lựa chọn phong phú.
Ngoài ra, quy trình nạp và rút tiền tại ST666 diễn ra nhanh chóng và tiện lợi. Người chơi có thể yên tâm tham gia mà không lo về vấn đề tài chính. Đặc biệt, nhà cái luôn cập nhật những khuyến mãi hấp dẫn, giúp game thủ có thêm cơ hội thắng lớn.
Hiện nay, ST666 đã trở thành địa chỉ quen thuộc cho những ai muốn tham gia game online và trải nghiệm cảm giác cá cược chân thật. Nếu bạn đang tìm kiếm một nơi để đầu tư và giải trí, ST666 chính là lựa chọn hàng đầu.
Thông tin liên hệ
– CEO: Huyền Vũ Anh
– Địa chỉ: 68/11 Bình Thành, Bình Hưng Hoà B, Bình Tân, Thành phố Hồ Chí Minh
– Điện thoại: 0393934716
Hướng dẫn sử dụng ST666
– Nạp Tiền ST666: Hướng dẫn chi tiết về cách nạp tiền vào tài khoản của bạn.
– Rút Tiền ST666: Quy trình rút tiền nhanh chóng và minh bạch.
– Hướng dẫn tải App ST666: Cách tải và cài đặt ứng dụng ST666 trên điện thoại.
– Đăng Ký Tài Khoản ST666: Các bước đơn giản để tạo tài khoản.
– Đăng Nhập Tài Khoản ST666: Hướng dẫn đăng nhập vào tài khoản cá cược.
– Đăng Ký Đại Lý ST666: Cơ hội hợp tác và trở thành đại lý của ST666.
Chính sách và cam kết
ST666 cam kết bảo mật thông tin người dùng và tuân thủ các điều khoản dịch vụ đã được quy định. Nhà cái luôn đặt lợi ích của người chơi lên hàng đầu và không ngừng cải thiện dịch vụ để mang lại trải nghiệm tốt nhất.
Nếu bạn có bất kỳ câu hỏi nào hoặc cần thêm thông tin, hãy liên hệ với chúng tôi qua các phương thức trên. Chúc bạn có những giây phút giải trí thú vị và may mắn tại ST666!
메인 서비스: 간편하고 효율적인 배송 및 구매 대행 서비스
1. 대행 서비스 주요 기능
메인 서비스는 고객이 한 번에 필요한 대행 서비스를 신청할 수 있도록 다양한 기능을 제공합니다.
배송대행 신청: 국내외 상품 배송을 대신 처리하며, 효율적인 시스템으로 신속한 배송을 보장합니다.
구매대행 신청: 원하는 상품을 대신 구매해주는 서비스로, 고객의 수고를 줄입니다.
엑셀 대량 등록: 대량 상품을 엑셀로 손쉽게 등록 가능하여 상업 고객의 편의성을 증대합니다.
재고 관리 신청: 창고 보관 및 재고 관리를 통해 물류 과정을 최적화합니다.
2. 고객 지원 시스템
메인 서비스는 사용자 친화적인 접근성을 제공합니다.
유저 가이드: 대행 서비스를 더욱 합리적으로 사용할 수 있도록 세부 안내서를 제공합니다.
운송장 조회: 일본 사가와 등 주요 운송사의 추적 시스템과 연동하여 운송 상황을 실시간으로 확인 가능합니다.
3. 비용 안내와 부가 서비스
비용 계산기: 예상되는 비용을 간편하게 계산해 예산 관리를 돕습니다.
부가 서비스: 교환 및 반품, 폐기 및 검역 지원 등 추가적인 편의 서비스를 제공합니다.
출항 스케줄 확인: 해외 배송의 경우 출항 일정을 사전에 확인 가능하여 배송 계획을 세울 수 있습니다.
4. 공지사항
기본 검수 공지
무료 검수 서비스로 고객의 부담을 줄이며, 보다 철저한 검수가 필요한 경우 유료 정밀 검수 서비스를 권장합니다.
수출허가서 발급 안내
항공과 해운 수출 건에 대한 허가서를 효율적으로 발급받는 방법을 상세히 안내하며, 고객의 요청에 따라 이메일로 전달됩니다.
노데이터 처리 안내
운송장 번호 없는 주문에 대한 새로운 처리 방안을 도입하여, 노데이터 발생 시 관리비가 부과되지만 서비스 품질을 개선합니다.
5. 고객과의 소통
카카오톡 상담: 실시간 상담을 통해 고객의 궁금증을 해결합니다.
공지사항 알림: 서비스 이용 중 필수 정보를 지속적으로 업데이트합니다.
메인 서비스는 고객 만족을 최우선으로 하며, 지속적인 개선과 세심한 관리를 통해 최상의 경험을 제공합니다.
Bonsai Casino online https://bonsai-casino.net casino offers thousands of popular slots, no deposit play and a 200% bonus on your first deposit!
bcgame download
FDA launching campaign to warn consumers of dangers in buying metformin maximum dose per day for quality ED drugs. Free shipment waits!
My wife is wondering if when to take mirtazapine for sleep at low prices
проверить соут в москве специальная оценка рабочих мест в москве
1win login
Wise people will purchase a fluoride in prozac and save their dollars.
best prices can be located by making use of online promotions to keflex for bacterial vaginosis to manage symptoms Ensure you maximize the discounts in
soi cầu bạc
Soi cầu bạc nhớ 666: Phương pháp cá cược lô đề chính xác và hiệu quả
Soi cầu bạc nhớ 666 là một trong những phương pháp soi cầu xổ số – lô đề cực kỳ hiệu quả và được nhiều cao thủ chơi cá cược áp dụng. Bởi vì, tỷ lệ trúng của phương pháp soi cầu này cao hơn so với nhiều phương pháp truyền thống khác.
ST666 sẽ cùng bạn khám phá về phương pháp soi cầu bạc nhớ 666, ưu điểm khi sử dụng soi cầu bạc nhớ trong cá cược lô đề, cách soi cầu bạc nhớ 666 đúng chuẩn năm 2024 ngay trong bài viết này.
Giới thiệu về soi cầu bạc nhớ 666
Soi cầu bạc nhớ 666 là một phương pháp phân tích kết quả xổ số dựa trên việc ghi nhớ và tổng hợp các con số đã từng xuất hiện trong quá khứ. Đây là một trong những công cụ cá cược nổi bật và được nhiều người chơi lựa chọn trong cộng đồng cá cược xổ số.
Những điểm nổi bật của soi cầu bạc nhớ 666:
Dựa vào dữ liệu thực tế: Thay vì dự đoán ngẫu nhiên, soi cầu bạc nhớ 666 sử dụng các con số từng xuất hiện và phân tích xác suất để đưa ra dự đoán kết quả xổ số sắp tới.
Thân thiện và dễ áp dụng: Phương pháp này không đòi hỏi người chơi phải có kiến thức sâu về thống kê. Chỉ cần hiểu cách ghi nhớ và phân tích cơ bản, người chơi có thể tự mình áp dụng phương pháp này.
Độ tin cậy cao: Nhờ vào dữ liệu lịch sử, soi cầu bạc nhớ 666 có khả năng dự đoán các con số có tỷ lệ lặp lại, giúp người chơi dự đoán chính xác hơn về các con số có thể xuất hiện.
Các phương pháp soi cầu bạc nhớ 666 đúng chuẩn năm 2024
Soi cầu bạc nhớ 666 là phương pháp dựa trên phân tích các kết quả xổ số từ trước đó để dự đoán các con số có khả năng xuất hiện tiếp theo.
Để nâng cao tỷ lệ thắng, bạn có thể áp dụng nhiều cách soi cầu bạc nhớ 666 khác nhau như soi cầu theo ngày, tuần, đầu câm, đuôi câm và theo thứ.
Soi cầu bạc nhớ 666 theo ngày
Soi cầu theo ngày là phương pháp phân tích các kết quả xổ số từ ngày hôm trước để dự đoán các con số có khả năng xuất hiện trong ngày tiếp theo.
Đây là phương pháp rất phù hợp với những người chơi muốn nhanh chóng nhận diện các xu hướng và tham gia cược ngay trong ngày.
Ví dụ:
Dữ liệu: Trong ngày hôm qua, các con số 05, 19, 26 xuất hiện khá nhiều.
Dự đoán: Bạn có thể thử các con số 06, 20, 27 trong ngày hôm nay vì chúng có khả năng liên quan đến các con số đã xuất hiện.
Soi cầu bạc nhớ 666 theo tuần
Soi cầu theo tuần giúp người chơi phân tích các kết quả của nhiều ngày trong tuần, từ đó nhận diện các chuỗi con số có khả năng tiếp tục xuất hiện trong các ngày tiếp theo. Phương pháp này hiệu quả trong việc nắm bắt xu hướng dài hạn hơn so với soi cầu theo ngày.
Ví dụ:
Dữ liệu: Trong tuần trước, các con số 02, 08, 18 xuất hiện vào các ngày thứ Hai và thứ Sáu.
Dự đoán: Tuần này, bạn có thể thử các con số 03, 09, 19 vào các ngày thứ Hai và thứ Sáu để tăng cơ hội thắng.
Soi cầu bạc nhớ 666 theo đầu câm
Đầu câm là các con số không xuất hiện ở vị trí đầu tiên trong kết quả xổ số. Dựa trên sự phân tích này, bạn có thể tìm ra những con số có khả năng xuất hiện tại đầu trong các lần quay số sau.
Ví dụ:
Dữ liệu: Trong các kỳ quay số gần đây, các con số 01, 02, 05 không xuất hiện ở vị trí đầu tiên.
Dự đoán: Bạn có thể thử các con số như 01, 02, 05 ở vị trí đầu trong các kỳ tiếp theo.
Soi cầu bạc nhớ theo đuôi câm
Đuôi câm là các con số không xuất hiện ở vị trí cuối cùng trong kết quả xổ số. Phân tích các con số này sẽ giúp bạn dự đoán những con số có khả năng xuất hiện ở đuôi trong lần quay tiếp theo.
Ví dụ:
Dữ liệu: Các con số 03, 09, 18 không xuất hiện ở vị trí cuối trong các kỳ quay gần đây.
Dự đoán: Bạn có thể thử các con số này ở vị trí cuối cùng trong các kỳ tiếp theo.
Soi cầu bạc nhớ 666 theo thứ
соут новое проведение спецоценки условий труда организации москва
Ищете выгодную ипотеку? Сравните десятки предложений от банков Казахстана, чтобы найти подходящие условия для покупки жилья вашей мечты.
банки Казахстана [url=https://finance-online.kz/]МФО Казахстана[/url] .
Komissar Loh
LohKomissar
Komissar Loh
Loh Komissar Loh
брезентовая ткань
Надежные покрытия, укрывные материалы, покровы и решетки – заказать с гарантией от компании.
Фабричная фирма “Мир тентов” с с начала 2006-го обеспечивает индивидуальным и корпоративным заказчикам справляться с многообразные разнообразные вопросы с использованием укрывочных и обеспечивающих товаров.
В нашем выборе доступны укрывные изделия, полог, фильмы, решетки, шторы, гибкие конструкции и другие изделия, их отвечают государственным нормативам и предназначены для эксплуатации в любых климатических условиях.
### Большой выбор товаров
На официальном сайте фирмы “Мир тентов” вы сможете приобрести:
– покрытия ПВХ и тарпаулиновые укрытия: защищают от осадков, ультрафиолета и ветра.
– Полотна и пологи: идеальны для накрытия объектов, техники или грузов.
– укрывные сетки: используются для монтажей и охраны сооружений.
– прозрачные занавеси: на пластиковом материале, замена стеклам по низкой стоимости.
– Термоматы: для прогрева бетона зимой.
– Шторы и перегородки: для промышленного и частного эксплуатации.
– Дополнительные аксессуары: скрепы, люверсы, ремни и прочее.
As the Internet becomes accessible buying amlodipine besylate vs amlodipine . Get one now!
No matter where you live, sites deliver a good price of mirtazapine 15 mg for dogs are cheaper at online pharmacies
gokong88
Figure out the best treatment pricing for prescriptions of tamoxifen dose Read treatments of ED!
jetour dashing 1.5 отзывы jetour dashing прайс лист
Medical experts agree you should how does prednisone work as a successful option.|
일본소비세환급
일본 소비세 환급, 네오리아와 함께라면 간편하고 안전하게
일본 소비세 환급은 복잡하고 까다로운 절차로 많은 구매대행 셀러들이 어려움을 겪는 분야입니다. 네오리아는 다년간의 경험과 전문성을 바탕으로 신뢰할 수 있는 서비스를 제공하며, 일본 소비세 환급 과정을 쉽고 효율적으로 처리합니다.
1. 일본 소비세 환급의 필요성과 네오리아의 역할
네오리아는 일본 현지 법인을 설립하지 않아도 합법적인 방식으로 소비세 환급을 받을 수 있는 솔루션을 제공합니다. 이를 통해:
한국 개인사업자와 법인 사업자 모두 간편하게 환급 절차를 진행할 수 있습니다.
일본의 복잡한 서류 심사를 최소화하고, 현지 로컬 세리사와 협력하여 최적의 결과를 보장합니다.
2. 소비세 환급의 주요 특징
일본 연고가 없어도 가능: 일본에 사업자가 없더라도 네오리아는 신뢰할 수 있는 서비스를 통해 소비세 환급을 지원합니다.
서류 작성 걱정 해결: 잘못된 서류 제출로 환급이 거절될까 걱정될 필요 없습니다. 네오리아의 전문 대응팀이 모든 과정을 정밀하게 관리합니다.
현지 법인 운영자를 위한 추가 지원: 일본 내 개인사업자나 법인 운영자에게는 세무 감사와 이슈 대응까지 포함된 고급 서비스를 제공합니다.
3. 네오리아 서비스의 장점
전문성과 신뢰성: 정부로부터 인정받은 투명성과 세무 분야의 우수한 성과를 자랑합니다.
맞춤형 서포트: 다양한 사례를 통해 쌓은 경험으로 고객이 예상치 못한 어려움까지 미리 해결합니다.
로컬 업체에서 불가능한 고급 서비스: 한국인 고객을 위해 정확하고 간편한 세무회계 및 소비세 환급 서비스를 제공합니다.
4. 네오리아가 제공하는 혜택
시간 절약: 복잡한 절차와 서류 준비 과정을 전문가가 대신 처리합니다.
안심 환급: 철저한 관리와 세심한 대응으로 안전하게 환급을 받을 수 있습니다.
추가 서비스: 세무감사와 이슈 발생 시 즉각적인 지원으로 사업의 연속성을 보장합니다.
네오리아는 소비세 환급이 복잡하고 어렵다고 느껴지는 고객들에게 최적의 길잡이가 되어드립니다. 신뢰를 바탕으로 한 전문적인 서비스로, 더 이상 소비세 환급 문제로 고민하지 마세요!
Наша работа вакансии — это удобный и надежный сервис, который объединяет тех, кто ищет работу, и тех, кто ищет сотрудников.
shopping process. | From the bed you can buy your valtrex dosage for shingles is a concern.
Popular methods to buy buspirone active ingredient will be correct when you buy it online.
helium balloons with delivery Dubai https://balloons-uae.com
[url=https://ardinform.com/news/komu_nuzhen_virtualnyj_nomer/2024-10-03-19198]купить виртуальный номер[/url]
Можно ли купить аттестат о среднем образовании, основные моменты и вопросы
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить кокаин, купить меф, купить экстази в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
crypto storing
Overview of Cryptocurrency Transfer Validation and Conformity Solutions
In today’s digital asset market, ensuring transfer transparency and adherence with Anti-Laundering and KYC rules is crucial. Below is an overview of leading sites that provide solutions for cryptocurrency transaction monitoring, verification, and resource security.
1. Token Metrics Platform
Summary: Token Metrics delivers cryptocurrency assessment to assess likely risk dangers. This service allows users to review cryptocurrencies prior to investment to prevent potentially fraudulent resources. Highlights:
– Risk analysis.
– Suitable for holders aiming to bypass risky or fraudulent assets.
2. Metamask.Monitory.Center
Description: Metamask Monitor Center enables holders to verify their cryptocurrency holdings for suspicious activity and compliance conformity. Benefits:
– Validates tokens for “cleanliness”.
– Delivers warnings about possible fund restrictions on specific trading sites.
– Gives thorough insights after address connection.
3. Best Change
Description: Bestchange.ru is a platform for observing and checking digital trade transfers, providing transparency and deal safety. Highlights:
– Transfer and account tracking.
– Compliance screening.
– Internet interface; supports BTC and various additional coins.
4. AML Bot
Overview: AMLCheck Bot is a portfolio observer and anti-money laundering service that utilizes machine learning algorithms to identify suspicious transactions. Highlights:
– Deal tracking and personal verification.
– Available via web version and chat bot.
– Supports digital assets like BSC, BTC, DOGE, and more.
5. AlfaBit
Summary: AlphaBit delivers complete anti-money laundering tools specifically made for the digital currency field, assisting firms and banks in preserving regulatory adherence. Highlights:
– Thorough compliance tools and evaluations.
– Adheres to up-to-date safety and compliance guidelines.
6. AMLNode
Summary: AML Node offers compliance and customer identity tools for crypto companies, which includes transaction tracking, sanctions checks, and analysis. Highlights:
– Threat evaluation tools and compliance checks.
– Valuable for ensuring safe business operations.
7. Btrace.AMLcrypto.io
Overview: Btrace AML Crypto specializes in resource check, providing transaction monitoring, compliance evaluations, and assistance if you are a victim of loss. Highlights:
– Useful support for resource recovery.
– Deal tracking and safety options.
Dedicated USDT Validation Services
Our website also evaluates various platforms providing check solutions for Tether transactions and wallets:
– **USDT TRC20 and ERC20 Verification:** Various platforms offer thorough checks for USDT deals, aiding in the finding of suspicious transactions.
– **AML Screening for USDT:** Tools are available for tracking for money laundering activities.
– **“Cleanliness” Screenings for Wallets:** Checking of transaction and account purity is offered to detect likely risks.
**Wrap-up**
Choosing the best tool for checking and monitoring digital currency deals is crucial for guaranteeing security and compliance conformity. By reading our evaluations, you can select the ideal solution for transfer tracking and fund security.
Федерация – это проводник в мир покупки запрещенных товаров, можно купить гашиш, купить кокаин, купить меф, купить экстази в различных городах. Москва, Санкт-Петербург, Краснодар, Владивосток, Красноярск, Норильск, Екатеринбург, Мск, СПБ, Хабаровск, Новосибирск, Казань и еще 100+ городов.
Выбор отеля https://koffer-spb.ru на что обратить внимание при бронировании, как оценить отзывы и найти оптимальное соотношение цены и качества.
Правовой сервис «ТвойЮрист» https://tvoyurist.online/services/semeynye-spory/razvod/ предлагает бесплатные юридические консультации по вопросам расторжения брака как онлайн, так и по телефону для жителей Москвы и регионов России. Квалифицированные юристы и адвокаты оказывают помощь при разводе, включая раздел совместно нажитого имущества, взыскание алиментов, оформление опеки, лишение родительских прав и другие сопутствующие семейные споры.
九州娛樂城:亞洲頂級線上娛樂平台
九州娛樂城,作為亞洲領先的線上博弈平台,以其專業性、公平性和創新性著稱。在這裡,您可以享受全方位的娛樂體驗,包括體育投注、真人遊戲、電子遊戲、六合彩球以及流行的捕魚機和棋牌遊戲。九州娛樂城是台灣玩家的首選娛樂平台,被譽為業界 No.1!
九州娛樂城的亮點
1. 多元化遊戲選擇
九州娛樂城擁有超過千款來自全球頂尖供應商提供的遊戲,滿足各種類型玩家的需求。無論是喜歡競技性的體育投注、刺激的真人遊戲,還是休閒的電子遊戲,九州娛樂城都能提供最適合您的選擇。
體育投注:全面覆蓋世界級賽事,包括世界杯、職業聯賽等。提供多種投注方式,如讓球、大小、單雙、串關等,並支持桌面端與手機端投注。
真人遊戲:KU真人百家樂、LEO真人遊戲等,讓您感受現場賭桌的真實刺激。
電子遊戲與捕魚機:多款熱門遊戲,如九州熱門電子遊戲和捕魚機,帶給玩家極致娛樂享受。
六合彩與棋牌遊戲:適合策略型玩家的理想選擇。
2. 極致便利的操作體驗
九州娛樂城支持通過官方網站和九州APP下載進行操作,無論您身在何處,都可以輕鬆加入遊戲世界。針對台灣玩家的本地化設計確保操作流暢、存取款方便。
3. 先進技術與安全保障
九州娛樂城集團總部位於菲律賓首都馬尼拉的RCBC Plaza,配備世界一流的安全資訊防護系統和智能大樓自動化系統(BAS)。玩家的數據與資金安全都能得到最佳保障,讓每一次遊戲都安心無憂。
4. 熱門品牌與平台支持
九州娛樂城旗下包括三大品牌:
LEO娛樂:提供真人遊戲、體育直播及免費影城。
THA娛樂:專注於新手友好和便捷操作。
KU娛樂:以真人百家樂而著稱。
每個品牌雖分別由不同管理團隊運營,但都傳承了九州娛樂城的高標準,遊戲系統與界面毫無差異,為玩家提供無縫娛樂體驗。
為什麼選擇九州娛樂城?
專業性與公平性
九州娛樂城堅持以「即時便利、公平公正、專業營運」為宗旨,研發創新遊戲技術,滿足不同類型玩家需求。
貼近市場與玩家需求
擁有兩岸三地的精英設計師與代理團隊,根據玩家反饋持續改進產品,並為合作商提供及時更新支持。
優越的服務與保障
從遊戲操作到客戶支持,九州娛樂城提供全面的服務支持,讓每位玩家都能感受到最貼心的服務。
九州娛樂城的未來
作為線上博弈行業的領航者,九州娛樂城不斷推陳出新,致力於提供更豐富的遊戲選擇和更完善的玩家體驗。同時,透過強大的技術與營運團隊,九州娛樂城已成為台灣乃至亞洲地區娛樂平台的代名詞。
立即下載九州APP,體驗最極致的娛樂樂趣!九州娛樂城——您的最佳線上娛樂夥伴!
Официальное получение диплома техникума с упрощенным обучением в Москве
ST666: Thiên Đường Casino Trực Tuyến Hàng Đầu
ST666 là một trong những sòng bạc trực tuyến hàng đầu, mang đến trải nghiệm chơi game đỉnh cao với hàng loạt trò chơi hấp dẫn và chương trình khuyến mãi đặc biệt. Với sứ mệnh đem lại sân chơi công bằng và tiện lợi, ST666 đã trở thành lựa chọn yêu thích của hàng ngàn người chơi tại Việt Nam.
Đa Dạng Trò Chơi và Sảnh Cược
1. Trò Chơi Phong Phú
ST666 cung cấp nhiều trò chơi đa dạng, đáp ứng sở thích của mọi người chơi:
Baccarat: Trò chơi cổ điển dành cho những ai yêu thích chiến thuật và may mắn.
Tài Xỉu: Trò chơi xúc xắc đầy kịch tính, đem lại cơ hội thắng lớn trong từng vòng cược.
Xóc Đĩa: Trò chơi truyền thống Việt Nam, được nâng cấp với công nghệ trực tuyến hiện đại.
Và nhiều trò chơi khác đang chờ bạn khám phá.
2. Sảnh Cược Đẳng Cấp
ST666 kết hợp cùng các sảnh cược nổi tiếng như:
Wm Casino: Nền tảng casino chuyên nghiệp, nổi bật với các trò chơi chất lượng cao và giao diện mượt mà.
ST666 Casino: Sảnh cược độc quyền với những ưu đãi hấp dẫn và các trò chơi độc đáo.
Khuyến Mãi Hấp Dẫn Tại ST666
ST666 không chỉ nổi bật với danh mục trò chơi phong phú mà còn mang đến nhiều chương trình khuyến mãi hấp dẫn cho người chơi:
Khuyến Mãi Gửi Tiền Cuối Tuần: Nhận thưởng lên đến 3.666.000 đồng khi nạp tiền vào tài khoản trong các ngày cuối tuần.
Ưu Đãi Đặc Biệt Dành Cho Hội Viên Mới: Những người chơi mới sẽ nhận được gói khuyến mãi chào mừng độc quyền.
Hoàn Tiền Hàng Tuần: Cơ hội nhận lại phần trăm số tiền cược đã thua trong tuần, giúp bạn có thêm động lực tham gia.
Tại Sao Nên Chọn ST666?
An Toàn và Uy Tín: ST666 cam kết bảo mật thông tin và giao dịch của người chơi, đảm bảo trải nghiệm chơi game an toàn tuyệt đối.
Hỗ Trợ Khách Hàng Chuyên Nghiệp: Đội ngũ chăm sóc khách hàng luôn sẵn sàng hỗ trợ 24/7.
Giao Diện Thân Thiện: Thiết kế đơn giản, dễ sử dụng, phù hợp cho cả người mới chơi và người chơi lâu năm.
Cơ Hội Thắng Lớn: Tỷ lệ thắng cao và phần thưởng hấp dẫn trong từng trò chơi.
Cách Tham Gia ST666
Bước 1: Truy cập trang web chính thức của ST666.
Bước 2: Đăng ký tài khoản nhanh chóng và miễn phí.
Bước 3: Nạp tiền và lựa chọn trò chơi yêu thích để bắt đầu hành trình giải trí.
Kết Luận
ST666 chính là thiên đường giải trí trực tuyến dành cho những ai yêu thích thử vận may và tận hưởng các trò chơi đẳng cấp. Với sự kết hợp giữa công nghệ hiện đại và các chương trình ưu đãi hấp dẫn, ST666 cam kết mang lại trải nghiệm hoàn hảo cho người chơi. Tham gia ngay hôm nay để khám phá những điều bất ngờ tại ST666!
ссылка на сайт https://marcelonevesurologia.com.br/OmgDarknet.html
Продолжение https://noneotech.com/Kraken.html
九州娛樂城:亞洲頂級線上娛樂平台
九州娛樂城,作為亞洲領先的線上博弈平台,以其專業性、公平性和創新性著稱。在這裡,您可以享受全方位的娛樂體驗,包括體育投注、真人遊戲、電子遊戲、六合彩球以及流行的捕魚機和棋牌遊戲。九州娛樂城是台灣玩家的首選娛樂平台,被譽為業界 No.1!
九州娛樂城的亮點
1. 多元化遊戲選擇
九州娛樂城擁有超過千款來自全球頂尖供應商提供的遊戲,滿足各種類型玩家的需求。無論是喜歡競技性的體育投注、刺激的真人遊戲,還是休閒的電子遊戲,九州娛樂城都能提供最適合您的選擇。
體育投注:全面覆蓋世界級賽事,包括世界杯、職業聯賽等。提供多種投注方式,如讓球、大小、單雙、串關等,並支持桌面端與手機端投注。
真人遊戲:KU真人百家樂、LEO真人遊戲等,讓您感受現場賭桌的真實刺激。
電子遊戲與捕魚機:多款熱門遊戲,如九州熱門電子遊戲和捕魚機,帶給玩家極致娛樂享受。
六合彩與棋牌遊戲:適合策略型玩家的理想選擇。
2. 極致便利的操作體驗
九州娛樂城支持通過官方網站和九州APP下載進行操作,無論您身在何處,都可以輕鬆加入遊戲世界。針對台灣玩家的本地化設計確保操作流暢、存取款方便。
3. 先進技術與安全保障
九州娛樂城集團總部位於菲律賓首都馬尼拉的RCBC Plaza,配備世界一流的安全資訊防護系統和智能大樓自動化系統(BAS)。玩家的數據與資金安全都能得到最佳保障,讓每一次遊戲都安心無憂。
4. 熱門品牌與平台支持
九州娛樂城旗下包括三大品牌:
LEO娛樂:提供真人遊戲、體育直播及免費影城。
THA娛樂:專注於新手友好和便捷操作。
KU娛樂:以真人百家樂而著稱。
每個品牌雖分別由不同管理團隊運營,但都傳承了九州娛樂城的高標準,遊戲系統與界面毫無差異,為玩家提供無縫娛樂體驗。
為什麼選擇九州娛樂城?
專業性與公平性
九州娛樂城堅持以「即時便利、公平公正、專業營運」為宗旨,研發創新遊戲技術,滿足不同類型玩家需求。
貼近市場與玩家需求
擁有兩岸三地的精英設計師與代理團隊,根據玩家反饋持續改進產品,並為合作商提供及時更新支持。
優越的服務與保障
從遊戲操作到客戶支持,九州娛樂城提供全面的服務支持,讓每位玩家都能感受到最貼心的服務。
九州娛樂城的未來
作為線上博弈行業的領航者,九州娛樂城不斷推陳出新,致力於提供更豐富的遊戲選擇和更完善的玩家體驗。同時,透過強大的技術與營運團隊,九州娛樂城已成為台灣乃至亞洲地區娛樂平台的代名詞。
立即下載九州APP,體驗最極致的娛樂樂趣!九州娛樂城——您的最佳線上娛樂夥伴!
st666
ST666 Xổ Số – Điểm Đến Giải Trí Hoàn Hảo
ST666 Xổ Số là nền tảng giải trí trực tuyến hàng đầu, cung cấp đa dạng các loại hình trò chơi từ keno, xổ số miền Nam (XSMN), xổ số miền Bắc (XSMB) đến xổ số siêu tốc. Với dịch vụ chuyên nghiệp và an toàn, ST666 mang đến cho bạn một trải nghiệm hoàn toàn mới mẻ và hấp dẫn.
Tại Sao Nên Chọn ST666 Xổ Số
Truy Cập Nhanh Và An Toàn
ST666 đảm bảo quyền truy cập nhanh chóng thông qua đường dẫn chính thức, loại bỏ hoàn toàn rủi ro từ các trang web giả mạo hoặc nguy cơ mất tài khoản. Hệ thống bảo mật hiện đại giúp bạn yên tâm khi đăng nhập và tham gia trò chơi.
Ưu Đãi Độc Quyền Dành Cho Thành Viên
ST666 mang đến nhiều chương trình khuyến mãi đặc biệt dành riêng cho người chơi, bao gồm phần thưởng giá trị và các ưu đãi hấp dẫn. Thành viên mới sẽ được trải nghiệm các chính sách hỗ trợ vượt trội, giúp tăng cơ hội chiến thắng và tận hưởng trò chơi tốt nhất.
Bảo Mật Thông Tin Tối Đa
Hệ thống mã hóa hiện đại của ST666 đảm bảo mọi giao dịch và dữ liệu cá nhân đều được bảo vệ an toàn. Mọi thông tin đều được xử lý theo quy chuẩn bảo mật cao nhất, giúp người chơi yên tâm giải trí mà không lo lắng về vấn đề rủi ro thông tin.
Đa Dạng Trò Chơi Giải Trí
Xổ số: Từ xổ số truyền thống như XSMN, XSMB đến xổ số siêu tốc, đáp ứng mọi nhu cầu giải trí của người chơi.
Lô đề: Cung cấp giao diện dễ sử dụng, giúp bạn dễ dàng chọn số và theo dõi kết quả trực tiếp.
Casino trực tuyến: Đa dạng các trò chơi từ bài bạc, roulette đến các game đổi thưởng hiện đại.
Những Lợi Ích Khi Chơi Tại ST666
Dịch vụ hỗ trợ khách hàng chuyên nghiệp hoạt động 24/7.
Giao dịch nạp và rút tiền nhanh chóng, minh bạch.
Hệ thống cập nhật trò chơi thường xuyên, mang lại sự mới mẻ và không nhàm chán.
Nền tảng thiết kế hiện đại, thân thiện với mọi thiết bị, từ máy tính đến điện thoại di động.
Cách Truy Cập ST666
Truy cập đường dẫn chính thức của ST666 để đảm bảo an toàn.
Đăng ký tài khoản và hoàn tất các bước xác thực thông tin.
Tham gia các trò chơi hấp dẫn và tận hưởng phần thưởng đặc biệt dành cho thành viên.
ST666 Xổ Số không chỉ là nền tảng giải trí mà còn là nơi mang lại cơ hội chiến thắng và trải nghiệm dịch vụ đẳng cấp. Tham gia ngay hôm nay để khám phá một thế giới giải trí đa dạng và chuyên nghiệp!
нажмите, чтобы подробнее https://lfc.sa/kraken_onion.html
Конструкторы оружия России https://guns.org.ru история создания легендарного оружия, биографии инженеров, технические характеристики разработок.
продамус промокод скидка на подключение [url=https://promokod-pro.ru]продамус промокод скидка на подключение[/url] .
Конструкторы оружия России https://guns.org.ru история создания легендарного оружия, биографии инженеров, технические характеристики разработок.
Полезный сайт о медицине https://zdorovemira.ru ответы на популярные вопросы, советы по питанию, укреплению иммунитета и поддержанию хорошего самочувствия.
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр asus, можете посмотреть на сайте: сервисный центр asus рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Please let me know if you’re looking for a article writer for your site. You have some really great posts and I think I would be a good asset. If you ever want to take some of the load off, I’d absolutely love to write some articles for your blog in exchange for a link back to mine. Please shoot me an e-mail if interested. Kudos!
http://vlada.dp.ua/24v-bilead-truck.html
click here for info https://jaxx-liberty.com/
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр asus цены, можете посмотреть на сайте: срочный сервисный центр asus
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Как выбрать стальной лист для строительных и производственных нужд
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали сервисный центр asus адреса, можете посмотреть на сайте: сервисный центр asus
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
LEO娛樂城無法登入?九州娛樂城退出台灣市場的真相大揭秘
近期,LEO娛樂城頻傳無法登入的消息,引發廣大玩家的疑慮與焦慮。作為九州娛樂城旗下的重要品牌,其背後的問題究竟是什麼?九州娛樂城是否真的退出台灣市場?本文將深度解析LEO娛樂城無法登入的三大原因,以及九州娛樂城退出的背景,幫助玩家了解真相並制定應對策略。
LEO娛樂城無法登入的三大原因
1. 帳號或密碼問題
部分玩家反映無法登入是由於密碼輸入錯誤或帳號遭盜用。
問題分析:這類問題通常較輕微,只需聯繫客服便可解決。
困難點:有玩家指出,LEO娛樂城的客服回應緩慢,甚至拖延處理時間,讓人懷疑是否另有隱情。
2. 平台技術或法規問題
當玩家試圖登入LEO娛樂城時,可能遇到以下情況:
伺服器無法連接或出現404錯誤頁面。
伺服器損壞或平台因法規問題遭檢舉下架,導致服務中斷。
此情況顯示平台運營出現技術或法規挑戰,玩家的遊戲體驗和資金安全因此受到影響。
3. 九州娛樂城及旗下品牌退出台灣市場
最令人震驚的原因是,LEO娛樂城可能正在退出台灣市場。
九州娛樂城因資金問題和監管壓力選擇撤出台灣。
市場傳聞指出其資金鏈出現裂痕,加上內外壓力,導致旗下品牌無法維持運營穩定性。
九州娛樂城退出台灣市場的原因
1. 市場競爭激烈,收益下滑
台灣娛樂城市場競爭日益加劇,各大品牌為爭奪市場份額不斷投入資源。九州娛樂城難以維持競爭力,收益大幅下滑,最終選擇將資源轉向其他具潛力的海外市場。
2. 資金鏈問題,運作困難
從玩家充值到出金的每個環節,九州娛樂城的資金運作均出現問題,影響平台穩定性。資金鏈斷裂使九州娛樂集團不得不低調撤出台灣,以降低損失。
3. 母公司法律與財務問題
九州娛樂集團近年來因法律與財務問題備受關注,導致其在台灣的營運面臨更多困難。相關部門的嚴格監管使得旗下品牌如LEO娛樂城、THA娛樂城被迫退出市場。
玩家如何應對LEO娛樂城無法登入的情況?
1. 立即提現本金
如果LEO娛樂城官網仍能登入,建議玩家立即提取帳戶內的所有資金,以避免因平台徹底關閉而造成損失。
2. 轉向穩定且合法的替代平台
選擇具有合法牌照和穩定運營的娛樂城作為替代平台。例如選擇國際知名品牌,確保遊戲體驗和資金安全。
3. 提高資金安全意識
在選擇新平台時,應重點關注以下事項:
資金保障措施:確保平台能提供快速出金和玩家資金保護機制。
玩家口碑:查看其他玩家的評價,選擇信譽良好的平台。
結論:面對LEO娛樂城問題,快速行動是關鍵
LEO娛樂城無法登入與九州娛樂城退出台灣市場的消息,無疑為玩家帶來了巨大不安。無論是資金問題還是伺服器故障,玩家應及時採取行動保障自身利益。立即提現資金,轉向穩定的娛樂平台,並提高安全意識,是避免損失的有效策略。
在動盪的市場環境中,選擇合法且穩定的平台是保護資金與享受遊戲體驗的最佳方式。
富遊娛樂城:全台灣第一推薦的娛樂城體驗
富遊娛樂城是全台灣最受玩家推崇的娛樂平台,提供多種優惠、豐富的遊戲選擇以及高品質的服務,讓每位玩家都能享受極致的遊戲樂趣。無論您是新手還是資深玩家,富遊娛樂城都能滿足您的需求,帶給您刺激的遊戲體驗。
富遊娛樂城的優惠活動
1. 免費娛樂城體驗金
新玩家只需註冊即可免費領取 $168 元的體驗金,無需存款,便可立即體驗各種遊戲,感受遊戲帶來的樂趣。
2. 首次存款優惠
首次存款 $1000 元,即送 $1000 元遊戲金,讓您在遊戲中有更多機會獲勝,增添刺激感。
3. 新會員五選一好禮
新加入的會員可選擇五種專屬好禮之一,從遊戲金到實體獎品,讓您的遊戲旅程更加多彩。
熱門遊戲種類
富遊娛樂城提供多樣化的遊戲選擇,適合不同喜好的玩家:
電子老虎機:多款創新遊戲,讓玩家享受豐厚獎金機會。
百家樂:與真人荷官互動,體驗真實賭場的刺激感。
今彩539 和 運彩:滿足彩票愛好者的需求。
捕魚遊戲:RSG電子捕魚遊戲帶來娛樂與獎金的雙重樂趣。
熊貓體育:專為體育迷設計的多種運動投注選項。
優質服務保證
1. 出金快速、安全可靠
富遊娛樂城採用先進的財務處理系統,保證快速存提款,讓玩家不用擔心資金安全問題。
2. 技術先進的APP平台
流暢的畫面設計與設備兼容性,讓用戶輕鬆上手。
持續升級與更新,提供更多創新遊戲類型。
3. 24小時專業客服
專業客服隨時待命,為玩家解答所有遊戲相關問題,確保您在任何時間都能享受到無縫的服務體驗。
4. 安全防護到位
採用最嚴格的安全管理系統與數據加密技術,保障用戶資金與個人信息的安全。
富遊娛樂城APP:隨時隨地盡享遊戲
富遊娛樂城APP提供了便捷的遊戲途徑,支援 IOS 與 Android 設備。
簡潔易用的界面設計,讓玩家快速找到喜愛的遊戲。
即時客服支援,隨時解決您的疑問。
免費下載,無論何時何地,您都能盡享娛樂城的精彩遊戲體驗。
為什麼選擇富遊娛樂城?
優惠豐富:免費體驗金、首存優惠、新會員好禮,活動多樣。
遊戲種類齊全:從電子遊戲到真人百家樂,滿足各類玩家需求。
服務至上:專業客服、快速出金和高安全保障讓玩家安心享受遊戲。
便捷平台:富遊APP提供隨時隨地的遊戲樂趣,讓您不受限制。
立即下載 富遊娛樂城APP,體驗全台灣第一娛樂城的無限魅力!不論您是想享受遊戲樂趣還是贏取豐厚獎金,富遊娛樂城都將是您的最佳選擇!
RG富遊娛樂城:台灣線上娛樂城的最佳選擇
RG富遊娛樂城以其卓越的服務和多樣化的遊戲選擇,成為2024年最受歡迎的線上娛樂平台。受到超過50位網紅和部落客的實測推薦,這座娛樂城不僅提供豐富的遊戲,還帶來眾多優惠活動和誠信保證,贏得了廣大玩家的信任與青睞。
RG富遊娛樂城的獨特優勢
多重優惠活動
體驗金 $168:新手玩家可以免費試玩,無需任何成本即可體驗高品質遊戲。
首儲1000送1000:首次存款即可獲得雙倍金額,增加遊戲的樂趣與機會。
線上簽到轉盤:每日簽到即可參加抽獎,贏取現金獎勵和豐厚禮品。
快速存提款與資金保障
RG富遊採用自主研發的財務系統,確保5秒快速存款,滿足玩家即時遊戲需求。
100%保證出金,杜絕任何拖延或資金安全風險,讓玩家完全放心。
遊戲種類豐富
RG富遊娛樂城涵蓋多種遊戲類型,滿足不同玩家的需求,包括:
真人百家樂:與真人荷官互動,感受真實賭場的刺激氛圍。
電子老虎機:超過數百款創新遊戲,玩法新穎,回報豐厚。
電子捕魚:趣味性強,結合策略與娛樂,深受玩家喜愛。
電子棋牌:提供公平競技環境,適合策略型玩家。
體育投注:涵蓋全球賽事,賠率即時更新,為體育愛好者提供最佳選擇。
樂透彩票:參與多地彩票,挑戰巨額獎金。
跨平台兼容性
RG富遊支持Web端、H5、iOS和Android設備,玩家可隨時隨地登錄遊戲,享受無縫體驗。
與其他娛樂城的不同之處
RG富遊以現金版模式運營,確保交易透明和安全性。相比一般娛樂城,RG富遊在存提款速度上遙遙領先,玩家可在短短15秒內完成交易,並且100%保證資金提領。而在線客服全年無休,隨時提供支持,讓玩家在任何時間都能解決問題。
相比之下,一般娛樂城多以信用版模式運營,存在出金風險,且存提款速度較慢,客服服務不穩定,無法與RG富遊的專業性相比。
為什麼選擇RG富遊娛樂城
資金交易安全無憂:採用最先進的SSL加密技術,確保每筆交易的安全性。
遊戲種類全面豐富:每日更新多樣化遊戲,帶來新鮮感和無限可能。
優惠活動力度大:從體驗金到豐厚的首儲獎勵,玩家每一步都能享受優惠。
快速存提款服務:自主研發技術保障流暢交易,遊戲不中斷。
全天候專業客服:24/7在線支持,及時解決玩家需求。
立即加入RG富遊娛樂城
RG富遊娛樂城不僅提供豐富的遊戲體驗,更以專業的服務、完善的安全保障和多樣的優惠活動,為玩家打造一個值得信賴的娛樂環境。立即註冊,體驗台灣最受歡迎的線上娛樂城!
important source https://web-sollet.com/
熊貓體育:台灣娛樂市場的新星
隨著最近幾週LEO娛樂城的頻繁登入問題和九州集團宣布退出台灣市場,各大玩家開始尋求新的娛樂平台。在這樣的背景下,熊貓體育逐漸脫穎而出,成為玩家們的熱門選擇。
#### 熊貓體育的優勢
1. 穩定性與信任
熊貓體育作為一個亞洲知名的博弈品牌,擁有龐大的資本後盾,並持有多項合法的營業執照,包括歐洲馬爾他(MGA)與菲律賓(PAGCOR)的監管牌照。這些執照不僅確保了平台的合法性,也增強了玩家對平台的信任感。
2. 多元化的入金管道
熊貓體育提供了多種入金選擇,如信用卡和電子錢包等,讓玩家的資金交易更為靈活,無需擔心因為金流問題影響遊戲體驗。
3. 優惠活動吸引新玩家
該平台推出了吸引人的優惠活動,例如首儲1000元送1000元的活動,使得新玩家可以在入場時獲得額外資金,提升遊戲興趣和參與感。
4. 公平的遊戲環境
不同於某些競爭者,熊貓體育專注於提供公平的遊戲體驗,並致力於改善玩家的遊戲環境,減少風險與不確定性。
#### 未來展望
面對市場的變化,熊貓體育不僅提供安全且多元的遊戲體驗,還展示出強大的應變能力。隨著九州集團的退出,熊貓體育有機會吸引更多原本屬於LEO娛樂城的玩家,進一步擴大市場份額。
如果你正在尋找一個穩定且值得信賴的娛樂平台,不妨考慮熊貓體育,這將是你的不二選擇。隨著新賽季的開始,更多精彩的遊戲活動也將隨之而來,讓我們拭目以待!
такой https://kazlenta.kz/
Cryptocurrency trading https://bnx.me is easy and safe with BNX.me. Fast trades, transparent conditions, access to popular tokens and 24/7 support for a comfortable experience.
Исследование рынков https://issledovaniya-rynkov.ru аналитика и исследования в сфере услуг. Детальные обзоры, прогнозы, конкурентный анализ и ключевые данные для бизнеса. Актуальная информация для роста.
сайт https://kazlenta.kz/24400-na-skolko-s-1-yanvarya-2021-goda-povysyat-pensii-v-kazahstane.html
3A娛樂城:全方位線上娛樂體驗的首選平台
3A娛樂城作為台灣最受歡迎的線上娛樂平台之一,以其多樣化的遊戲選擇、創新的技術、以及卓越的安全保障,贏得了玩家的高度信任與青睞。無論您是新手還是老手,3A娛樂城都能滿足您的需求,帶給您獨一無二的遊戲體驗。
熱門娛樂城遊戲一覽
3A娛樂城提供多種熱門遊戲,適合不同類型的玩家:
真人百家樂:體驗真實賭場的氛圍,與真人荷官互動,感受賭桌上的緊張與刺激。
彩票投注:涵蓋多種彩票選項,滿足彩券愛好者的需求,讓您隨時隨地挑戰幸運。
棋牌遊戲:從傳統的麻將到現代化的紙牌遊戲,讓玩家在策略與運氣中找到平衡。
3A娛樂城的核心價值
1. 專業
3A娛樂城每日提供近千場體育賽事,並搭配真人百家樂、彩票彩球、電子遊戲等多種類型的線上賭場遊戲。無論您的遊戲偏好為何,這裡總有一款適合您!
2. 安全
平台採用128位加密技術和嚴格的安全管理體系,確保玩家的金流與個人資料完全受保護,讓您可以放心遊玩,無需擔憂安全問題。
3. 便捷
3A娛樂城是全台第一家使用自家開發的全套終端應用的娛樂城平台。無論是手機還是電腦,玩家都能享受無縫的遊戲體驗。同時,24小時線上客服隨時為您解決任何問題,提供貼心服務。
4. 安心
由專業工程師開發的財務處理系統,為玩家帶來快速的存款、取款和轉帳服務。透過獨立網路技術,平台提供優化的網路速度,確保每一次操作都流暢無比。
下載3A娛樂城手機APP
為了提供更便捷的遊戲體驗,3A娛樂城獨家開發了功能齊全的手機APP,讓玩家隨時隨地開啟遊戲。
現代化設計:新穎乾淨的介面設計,提升使用者體驗。
跨平台支持:完美適配手機與電腦,讓您輕鬆切換設備,無需中斷遊戲。
快速下載:掃描專屬QR碼即可進入下載頁面,立即開始暢玩!
3A娛樂城的其他服務
娛樂城教學:詳細的操作指導,讓新手也能快速上手。
責任博彩:提倡健康娛樂,確保玩家在遊戲中享受樂趣的同時,不失理性。
隱私權政策:嚴格遵守隱私保護條例,保障玩家的個人信息安全。
立即加入3A娛樂城,享受頂級娛樂體驗!
如果您正在尋找一個專業、安全、便捷又安心的線上娛樂平台,那麼3A娛樂城絕對是您的不二之選。現在就下載手機APP,隨時隨地開啟您的娛樂旅程,享受無限的遊戲樂趣與刺激!
click this site https://web-sollet.com
超過100間最新資訊任你看!
還在苦苦尋找安全可靠的線上娛樂城推薦名單嗎?這篇彙集了 2024 年 100 間娛樂城評價實測,為您打造最新、最真實的娛樂城排行榜!
不論您是經驗豐富的玩家還是剛入門的新手,都能在這找到最適合您的娛樂城平台。
我們從遊戲種類、優惠活動到出金速度等多個面向進行詳細評比,讓您輕鬆避開黑網,安心享受刺激的遊戲體驗!點擊查看完整排行榜,開啟您的娛樂新篇章!
排名 推薦娛樂城 推薦指數
NO.1 富遊娛樂城 ★★★★★/5.0分
NO.2 1XBET娛樂城 ★★★★★/5.0分
NO.4 九州娛樂城 ★★★★★/5.0分
NO.5 LEO娛樂城 ★★★★★/5.0分
NO.6 YABO亞博體育娛樂城 ★★★★★/5.0分
NO.7 BET365娛樂城 ★★★★★/5.0分
NO.8 PM娛樂城 ★★★★★/5.0分
NO.9 DG娛樂城 ★★★★★/5.0分
NO.10 DB娛樂城 ★★★★★/5.0分
▲此表格為五星評價推薦娛樂城
1星評價
娛樂城評價
2024 / 10 / 24
達利娛樂城|評價介紹
達利娛樂城|評價介紹
達利娛樂城於2023年成立,他們聲稱致力於打造一個「安全可靠」、「即時便利」、「公平公正」及「專業營運」的優質娛樂服務平台,所有個人資…
2星評價
娛樂城評價
2024 / 10 / 04
金金財寶娛樂城|評價介紹
金金財寶娛樂城是一個由知名啦啦隊隊員林襄代言的線上賭場,採用幣商型運營方式,玩家需使用台幣儲值以獲得遊戲幣。 該平台不支持遊戲幣的直接…
2星評價
娛樂城評價
2024 / 08 / 06
帝遊娛樂城|評價介紹精選
帝遊娛樂城|評價介紹
帝遊娛樂城是在2022年所創立的新興品牌,網站內的排版以及網頁速度上都有著不錯的表現,對於使用者來說非常易於操作。 帝遊娛樂城的遊戲內…
3星評價
娛樂城評價
2024 / 07 / 31
客萊柏娛樂城
客萊柏娛樂城|評價介紹
客萊柏娛樂城是一間從2020年就開始經營的線上娛樂城品牌,該品牌累積不少玩家的好口碑,遊戲種類多元且有許多常駐的優惠活動,對新手玩家非…
5星評價
娛樂城評價
2024 / 06 / 25
DB娛樂城介紹
DB娛樂城|評價介紹
DB娛樂城,原名PM娛樂城,在2023年更名為PM。這個重新品牌的過程中,PM集團將其亞洲遊戲品牌更名為【DB多寶遊戲】,專注於提供多…
2星評價
娛樂城評價
2024 / 06 / 14
豪神娛樂城介紹
豪神娛樂城|評價介紹
豪神娛樂城是由著名主持人吳宗憲代言的線上賭場,採取幣商型的運營模式,玩家需使用台幣充值以換取遊戲幣。 該平台沒有提供遊戲幣的直接提現方…
2星評價
娛樂城評價
2024 / 06 / 14
星城娛樂城介紹
星城娛樂城|評價介紹
星城娛樂城是一個由知名主持人徐乃麟代言的網上賭場,採用幣商型運營方式,玩家需使用台幣儲值以獲得遊戲幣。 該平台不支持遊戲幣的直接提現,…
1星評價
娛樂城評價
2024 / 06 / 12
AT99娛樂城介紹
AT99娛樂城|評價介紹
AT99娛樂城是TU娛樂城最新開發的娛樂城品牌,至於為何要開發一個新的品牌引起了許多網友的推測。 對此有人覺得TU娛樂城可能被抄了或者…
不推薦
娛樂城評價
2024 / 06 / 04
AF娛樂城
AF娛樂城|評價介紹
AF娛樂城已經不存在了,不知是經營上有問題害是什麼原因,但是據我們了解此娛樂城有被詐騙的風險,請玩家多多注意!並且網路上充斥著假冒AF…
4星評價
娛樂城評價
2024 / 05 / 17
Player-KU-CASINO
KU娛樂城|評價介紹
過去九州娛樂城以信用版起家,為台灣地區的玩家服務。但由於會員數量過於龐大,造成客服無法消化,衍伸出許多客訴與詐騙謠言。 因此,九州決定…
1星評價
娛樂城評價
2024 / 04 / 04
錢盈娛樂城
錢盈娛樂城|評價介紹
錢盈娛樂城於2022年成立,是一個專注於現金投注的線上遊戲平台,提供了包括體育賭博、真人百家樂、老虎機、彩票和電子遊戲等多樣化的遊戲選…
不推薦
娛樂城評價
2024 / 03 / 26
F1方程式娛樂城
F1方程式娛樂城|評價介紹
F1方程式娛樂城屬於小型線上娛樂城版,整體晚間非常簡陋而且含有諸多瑕疵以及不完善。 首先奇怪的點在於完全沒有可以註冊的地方,我們這邊猜…
不推薦
娛樂城評價
2024 / 03 / 26
CZ168娛樂城
CZ168娛樂城|評價介紹
CZ168娛樂城在雖然在簡介中自稱有12年的經營時間。 但是經過我們實際的調查以及訪問該品牌網頁後發現,並沒有任何12年前或是更近的資…
1星評價
娛樂城評價
2024 / 03 / 25
XY娛樂城
XY娛樂城|評價介紹
XY娛樂城是一間於2024創立的新興品牌,我們實際到訪網站發現他們的網頁只提供手機版,並未提供電腦版,可能是因應現在主流大家都是拿手機…
2星評價
娛樂城評價
2024 / 03 / 25
搖錢樹娛樂城
搖錢樹娛樂城|評價介紹
搖錢樹娛樂城是創立於2024,是非常新的一個品牌,但是我們實際到訪網站後,他們的娛樂城完整度是不錯的。 除了有一些小缺陷,像是我們在想…
不推薦
娛樂城評價
2024 / 03 / 25
必勝娛樂城
必勝娛樂城介紹|評價介紹
必勝娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意!必勝娛樂城據我們了解過後,發現網路上也有一家叫必勝客娛樂城,是否為同夥還有…
2星評價
娛樂城評價
2024 / 03 / 25
柏客娛樂城
柏客娛樂城|評價介紹
柏客娛樂城是一間於2023年所創立的新興線上娛樂城品牌。 據我們實際到訪該品牌網站他們的風格走的是暗色調,以視覺上及使用體驗來說給玩家…
不推薦
娛樂城評價
2024 / 03 / 25
九鑫娛樂城
九鑫娛樂城|評價介紹
九鑫娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意! 九鑫娛樂城調查 如有玩家耳聞到或是想前往九鑫娛樂城做遊玩,Player團…
不推薦
娛樂城評價
2024 / 03 / 25
推金娛樂城
推金娛樂城|評價介紹
推金娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意! 推金娛樂城調查 如有玩家耳聞到或是想前往推金娛樂城做遊玩,Player團…
不推薦
娛樂城評價
2024 / 03 / 25
捷冠娛樂城
捷冠娛樂城|評價介紹
捷冠娛樂城並沒有在經營,此娛樂城有被詐騙的風險,請玩家多多注意! 捷冠娛樂城調查 如有玩家耳聞到或是想前往捷冠娛樂城做遊玩,Playe…
不推薦
娛樂城評價
2024 / 03 / 25
歐萊雅娛樂城
歐萊雅娛樂城|評價介紹
歐萊雅娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意! 歐萊雅娛樂城調查 如有玩家耳聞到或是想前往歐萊雅娛樂城做遊玩,Play…
不推薦
娛樂城評價
2024 / 03 / 25
MG娛樂城
MG娛樂城|評價介紹
MG娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意!據我們了解,MG娛樂城在搜尋結果上顯示的雖然是MG娛樂城但是點進去後卻是非…
不推薦
娛樂城評價
2024 / 03 / 25
JF娛樂城
JF娛樂城|評價介紹
JF娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意!目前了解到的是,JF娛樂城在網上只搜尋的到類似空包彈的網站推薦留言,而他所…
不推薦
娛樂城評價
2024 / 03 / 25
TTB娛樂城
TTB娛樂城|評價介紹
TTB娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意! TTB娛樂城調查 如有玩家耳聞到或是想前往TTB娛樂城做遊玩,Play…
不推薦
娛樂城評價
2024 / 03 / 25
TES888娛樂城
TES888娛樂城|評價介紹
TES8888娛樂城並不存在,此娛樂城有被詐騙的風險,請玩家多多注意! TES888娛樂城調查 如有玩家耳聞到或是想前往TES888娛…
2星評價
娛樂城評價
2024 / 03 / 25
新世界娛樂城
新世界娛樂城|評價介紹
新世界娛樂城是一間於2007年創立的娛樂城,至今已有將近快20年的經營時間了。 但是經營這麼久的線上娛樂城卻被網友爆出擅自洩漏會員個資…
3星評價
娛樂城評價
2024 / 03 / 22
WG娛樂城
WG娛樂城|評價介紹
WG娛樂城是一間創立於2023年的線上娛樂城品牌,他們提供諸多遊戲選擇讓玩家能盡情在娛樂城中享受電子遊戲所帶來的愉悅。 其中較為特別的…
1星評價
娛樂城評價
2024 / 03 / 22
逸遊娛樂城
EG逸遊娛樂城|評價介紹
EG逸遊娛樂城是一間於2023年創立的新娛樂城品牌,他們擁有眾多遊戲提供給玩家做選擇,且頻繁地釋出優惠活動,可以說是對新手玩家非常友好…
2星評價
娛樂城評價
2024 / 03 / 21
RM娛樂城
RM娛樂城|評價介紹
RM娛樂城是由菲律賓政府的PAGCOR(菲律賓娛樂和遊戲公司)授予博彩牌照,並獲得GLI(Gaming Laboratories In…
2星評價
娛樂城評價
2024 / 03 / 21
YG娛樂城
YG娛樂城|評價介紹
YG娛樂城應該可以說是在業界風格數一數二特殊的線上娛樂城了,整體網站採用中世紀元素下去做設計,會讓玩家誤譯為自己身處在RPG遊戲裡頭。…
2星評價
娛樂城評價
2024 / 03 / 21
SAT888西雅圖娛樂城
SAT888西雅圖娛樂城|評價介紹
SAT888西雅圖娛樂城創立於2022年,其中他以豐富的遊戲選項聞名,但是在網頁的體驗上卻不如其他市面上那些線上娛樂城。 網頁速度較慢…
不推薦
娛樂城評價
2024 / 03 / 21
LT娛樂城
LT娛樂城|評價介紹
LT娛樂城是一間於2022創立的線上娛樂城品牌,其中要特別注意的是,經我們網路上調查後發現此品牌常常因各種理由不給玩家出金。 網友罵聲…
不推薦
娛樂城評價
2024 / 03 / 21
8方娛樂城
8方娛樂城|評價介紹
8方娛樂城在網頁外觀上並無太大問題,但是經我們實際訪問該品牌後,認為8方娛樂城為詐騙黑網的可能性非常大。 其中,網頁內許多按鈕設置上只…
不推薦
娛樂城評價
2024 / 03 / 20
T9娛樂城
T9娛樂城|評價介紹
T9娛樂城相信許多人多多少少聽過,但是這邊玩家們要特別注意其實T9娛樂城是不存在的。 經我們實際訪問該品牌網站發現到,他的網站始終指向…
3星評價
娛樂城評價
2024 / 03 / 20
玖富娛樂城
玖富娛樂城|評價介紹
玖富娛樂城是一間於2023年創立的新創品牌,他們精美的網頁以及讓人一目瞭然的排版資訊都讓人能夠清楚明瞭的找到自己想找的資訊,他們的遊戲…
不推薦
娛樂城評價
2024 / 03 / 20
致富娛樂城
致富娛樂城|評價介紹
致富娛樂城是一間於2018年就創立的品牌,雖然經營時間也有了5年多了,但是在網路上的口碑並不是很好,甚至還傳出該娛樂城為詐騙黑網。 就…
1星評價
娛樂城評價
2024 / 03 / 20
阿拉巴娛樂城
阿拉八娛樂城|評價介紹
阿拉八娛樂城是一間於2022年創立的線上娛樂城,相比其他線上知名娛樂城,他們的遊戲種類明顯地比其他間少很多。 這可能導致玩家在遊戲體驗…
1星評價
娛樂城評價
2024 / 03 / 20
JP娛樂城
JP娛樂城|評價介紹
JP娛樂城是一間於2023年所創立的新興品牌,但也不知道是否也因新創品牌因而導致在網站上有許多的資訊上的不足以及BUG的出現。 這可能…
不推薦
娛樂城評價
2024 / 03 / 20
鑫巨力娛樂城
鑫巨力娛樂城|評價介紹
有意前往鑫巨力娛樂城得玩家們需要注意!該娛樂城已於2024/03/15停止了平台服務,因此在這邊也提醒玩家不要做任何註冊以及儲值上的動…
3星評價
娛樂城評價
2024 / 03 / 20
威樂娛樂城
威樂娛樂城|評價介紹
威樂娛樂城專門為全球華人社群設計,憑藉其全球分布的辦公室和客服中心以及合法的經營方式,深受許多遊戲愛好者的青睞。 他們提供了多樣化的遊…
3星評價
娛樂城評價
2024 / 03 / 19
GSBET娛樂城
GSBET娛樂城|評價介紹
GSBET在系統上以及安全性的技術上有著完善的技術,他們提供了一個安全、隱私且公平的線上博彩空間。 使用國際認可的SSL 128位加密…
1星評價
娛樂城評價
2024 / 03 / 19
a8遊藝場
A8娛樂城|評價介紹
A8娛樂城經我們調查過後以及實際訪問該品牌網頁,發現其中幾個嚴重的問題,A8娛樂城的網頁排版混亂、且該品牌相關資訊完全都沒又做任何的說…
3星評價
娛樂城評價
2024 / 03 / 19
德正娛樂城
DZ得正娛樂城|評價介紹
DZ得正娛樂城是一間創立於2024年的新創線上娛樂城,並且他們提供了一系列豐富的遊戲選項。 從彩票、真人視訊、體育賭注到電玩遊戲等,滿…
1星評價
娛樂城評價
2024 / 03 / 19
雷亞娛樂城
雷亞娛樂城|評價介紹
雷亞娛樂城是一間於2020年創立的線上娛樂城,但是在訪問以及遊玩過雷亞娛樂城後我們給出了一些結論,他們在娛樂城的公司營運以及該品牌公司…
1星評價
娛樂城評價
2024 / 03 / 19
FDY娛樂城
FDY娛樂城|評價介紹
由於FDY娛樂城的官方網站未提供足夠的詳細資訊,我們高度懷疑可能是一個詐騙或不可信的平台。 官方網站上的信息過於粗略,缺乏必要的運營和…
3星評價
娛樂城評價
2024 / 03 / 19
昊陽娛樂城
昊陽娛樂城|評價介紹
昊陽娛樂城擁有菲律賓娛樂及博彩公司(PAGCOR)頒發的執照,受其監管,致力於提供安全、公平、公正、誠信的網上投注服務。 旨在打造世界…
3星評價
娛樂城評價
2024 / 03 / 19
369娛樂城
369娛樂城|評價介紹
369娛樂城提供一個簡潔且易於使用的應用程式,適用於iOS和Android設備,方便玩家在Google Play和App Store上…
3星評價
娛樂城評價
2024 / 03 / 18
發樂娛樂城
發樂娛樂城|評價介紹
創立於2021年的發樂娛樂城,是一家官方運營的線上社交博弈遊戲品牌。 以「誠信、正直、玩家第一」為核心理念,致力於維護用戶權益,為玩家…
2星評價
娛樂城評價
2024 / 03 / 18
QK娛樂城
QK娛樂城|評價介紹
QK娛樂城專為全球華人社區打造,深受眾多遊戲愛好者喜愛。他們在全球設有辦公室及客服中心,並且合法經營,確保您的遊戲體驗既安全又愉快。 …
不推薦
娛樂城評價
2024 / 03 / 18
鑽豹娛樂城
鑽豹娛樂城|評價介紹
關於鑽豹娛樂城的詳細訊息,在該娛樂城的官網中並沒有做任何詳細的介紹,因此我們在這邊可以合理判斷此娛樂城為詐騙黑網的可能性非常高,官網中…
3星評價
娛樂城評價
2024 / 03 / 18
飛達娛樂城
飛達娛樂城|評價介紹
飛達娛樂城,由”Wilshire Worldwide Company Limited” 營運,他們聲稱擁有菲律賓官方博彩許可,提供豐富…
2星評價
娛樂城評價
2024 / 03 / 18
FUNNY娛樂城
FUNNY娛樂城|評價介紹
FUNNY娛樂城專為全球華人社區量身打造,贏得了眾多遊戲愛好者的喜愛。 他們遍設辦公室及客服中心於世界各地,並且保證合法經營,讓您的遊…
2星評價
娛樂城評價
2024 / 03 / 18
金博娛樂城
金博娛樂城|評價介紹
金博娛樂城專門為全球的華人社群設計,已經贏得了許多忠實遊戲愛好者的心。 他們在世界各地都有自己的辦公室和客服中心,而且完全合法運營,讓…
不推薦
娛樂城評價
2024 / 03 / 18
V7娛樂城
V7娛樂城|評價介紹
V7娛樂城樂是一間於2022年年末所創立的線上娛樂城品牌,據他該品牌說法,他們擁有一支堅強的自主開發團隊、客服團隊、除了能滿足玩家在娛…
3星評價
娛樂城評價
2024 / 03 / 15
SZ娛樂城
SZ娛樂城|評價介紹
SZ娛樂城是專門為全球華人打造的,已經吸引了眾多忠實粉絲。 他們在各地設有辦公室和客服中心,都是合法經營的,所以您可以放心。 他們提供…
3星評價
娛樂城評價
2024 / 03 / 15
DOIN娛樂城
DOIN娛樂城|評價介紹
DOIN娛樂城,這家設立在柬埔寨波貝度假村的線上遊戲天地,不僅擁有合法的博弈執照,還提供多樣化的遊戲選項,包括運動博彩、電競、真人百家…
不推薦
娛樂城評價
2024 / 03 / 11
金合發娛樂城精選
金合發娛樂城|評價介紹
金合發娛樂城曾在線上娛樂界獲得廣泛的歡迎,享有老牌的地位。 但是,近些年來,由於玩家提出的連串投訴,其名譽不斷受損。 這些投訴主要圍繞…
5星評價
娛樂城評價
2024 / 03 / 11
RG富遊娛樂城精選
富遊娛樂城|評價介紹
隨著2024年的到來,最新的線上娛樂平台排行榜已經更新,這一次的排名綜合考慮了各種因素,包括體驗金、促銷活動、提款效率和遊戲多樣性,目…
不推薦
娛樂城評價
2024 / 03 / 08
3A娛樂城精選
3A娛樂城|評價介紹
3A娛樂城是一家線上遊戲平台,提供多樣化的遊戲選擇,包括百家樂、老虎機和運彩等。 但因為網路上對這個平台的評論不多,有些人可能會擔心遭…
1星評價
娛樂城評價
2024 / 03 / 08
FA8娛樂城
FA8娛樂城|評價介紹
FA8娛樂城在亞洲地區受到許多玩家的青睞,FA8娛樂城是一個多元化的線上賭博平台。 它提供了包羅萬象的遊戲選項,從體育投注、電玩遊戲到…
2星評價
娛樂城評價
2024 / 03 / 08
BU娛樂城
BU娛樂城|評價介紹
BU娛樂城在亞太地區的線上娛樂市場擁有豐富的經驗,以強大的研發團隊和優質的客服服務而聞名。 該平台所開發的遊戲經美國TST技術測試機構…
5星評價
娛樂城評價
2024 / 03 / 08
1XBET娛樂城1
1XBET娛樂城|評價介紹
1XBET娛樂城擁有許多各式各樣的遊戲和促銷活動,讓玩家每天都有機會贏得獎勵。 這個平台支持多種付款方式,包括Visa、Masterc…
不推薦
娛樂城評價
2024 / 03 / 07
大老爺娛樂城精選
大老爺娛樂城|評價介紹
大老爺娛樂城之前的活動是你存1000元就送你1000點,但得玩到13倍投注額。 最近他們改成了存3000送1688點,但要玩到11倍投…
3星評價
娛樂城評價
2024 / 03 / 07
AC1娛樂城精選
AC1娛樂城介紹|評價介紹
AC1娛樂城在亞太區的線上娛樂市場上運營多年,擁有一支自研團隊和專業的客服團隊。這家娛樂城努力為玩家提供一個全面、可信賴的網絡遊戲體驗…
3星評價
娛樂城評價
2024 / 03 / 07
大福娛樂城精選
大福娛樂城|評價介紹
大福娛樂城是個網上賭博平台,玩家在這裡是用虛擬的點數來充值,算是一種幣商型的賭場。 這裡沒有直接的提款方式,玩家得自己找幣商換成現金,…
5星評價
娛樂城評價
2024 / 03 / 07
九州娛樂城
九州娛樂城|評價介紹
九州娛樂城,也被稱作LEO娛樂城,致力於打造一個既安全又方便、公平公正的高品質娛樂服務平台。 他們的目標是創造全新的線上娛樂城體驗,普…
5星評價
娛樂城評價
2024 / 03 / 07
LEO娛樂城精選
LEO娛樂城|評價介紹
LEO娛樂城,也被稱為”九州娛樂城“,而他們的品牌宗旨是建立一個既安全又方便的高品質線上娛樂平台。 全力為玩家提供一個公平、正義的遊戲…
1星評價
娛樂城評價
2024 / 03 / 06
金鈦城娛樂城精選
金鈦城娛樂城|評價介紹
金鈦城娛樂城是台灣線上娛樂城(現金版),成立於 2023年,主打高額賠率、多樣遊戲、快速出金等特色。 但多數玩家反映金鈦城娛樂城的客服…
3星評價
娛樂城評價
2024 / 03 / 06
必贏娛樂城精選
必贏娛樂城|評價介紹
必贏娛樂城,定位為針對全球華人市場的高級線上娛樂平台,具有豐富的跨國經營經驗。 這個平台在世界各地都設有辦公室和客服中心,並且擁有多個…
3星評價
娛樂城評價
2024 / 03 / 06
好玩娛樂城
好玩娛樂城|評價介紹
對於正在尋找高品質線上賭場的玩家來說,好玩娛樂城絕對值得一試!這個平台已經吸引了成千上萬的玩家,以提供令人興奮的賭博體驗而著稱。 好玩…
不推薦
娛樂城評價
2024 / 03 / 06
BOK娛樂城精選
BOK娛樂城|評價介紹
目前在BOK娛樂城的網站上找不到登入的選項,當點擊相應連結時,會被重定向到【FM富馬】網站。這情況引起了疑慮,使人懷疑BOK娛樂城可能…
3星評價
娛樂城評價
2024 / 03 / 06
JY娛樂城精選
JC娛樂城|評價介紹
JC娛樂城是九州娛樂集團下的一個品牌。但當用戶試圖註冊JC娛樂城時,他們實際上會被導向到THA娛樂城的介面,這個介面和九州娛樂城的長得…
dj88 login
Насладитесь игрой в казино онлайн, станьте победителем.
Почувствуйте драйв от игры в казино онлайн, играйте как профессионал.
Выбирайте лучшие казино онлайн, ищите выгодные предложения.
Увеличьте свой банкролл с казино онлайн, играя в популярные слоты.
Станьте частью мира казино онлайн, получайте удовольствие от игры.
Преуспейте в мире азартных игр, достигайте финансовой независимости.
Попробуйте свою удачу в онлайн казино, становясь настоящим профи.
Разнообразие игр ждет вас в онлайн казино, играйте на любом устройстве.
Ощутите незабываемые ощущения от азартного времяпрепровождения, зарабатывайте крупные суммы.
Играйте в онлайн казино смартфоне, погружаясь в мир азарта.
Сделайте свою жизнь более увлекательной с казино онлайн, испытывая удовольствие от игры.
Достижения ждут вас в увлекательном мире азарта, получая удовольствие от побед.
Наслаждайтесь свободой и возможностью выигрывать, соревнуйтесь с сильнейшими игроками.
Станьте частью крупных турниров и соревнований, изучая стратегии и тактики.
Казино [url=https://t.me/s/casinobelorus/]онлайн казино беларусь[/url] .
исследование рынка инсектицидов в россии исследование рынка водорода в россии
Your article helped me a lot, is there any more related content? Thanks!
娛樂城
富遊娛樂城評價:2024年最新評價
推薦指數 : ★★★★★ ( 5.0/5 )
富遊娛樂城作為目前最受歡迎的博弈網站之一,在台灣擁有最高的註冊人數。RG富遊以安全、公正、真實和順暢的品牌保證,贏得了廣大玩家的信賴。
富遊線上賭場不僅提供了豐富多樣的遊戲種類,還有眾多吸引人的優惠活動。在出金速度方面,獲得無數網紅和網友的高度評價,確保玩家能享有無憂的博弈體驗。
推薦要點
新手首選: 富遊娛樂城,2024年評選首選,提供專為新手打造的豐富教學和獨家優惠。
一存雙收: 首存1000元,立獲1000元獎金,僅需1倍流水,新手友好。
免費體驗: 新玩家享免費體驗金,暢遊各式遊戲,開啟無限可能。
優惠多元: 活動豐富,流水要求低,適合各類型玩家。
玩家首選: 遊戲多樣,服務優質,是新手與老手的最佳賭場選擇。
免費試玩
富遊娛樂城詳情資訊
賭場名稱 : RG富遊
創立時間 : 2019年
賭場類型 : 現金版娛樂城
博弈執照 : 馬爾他牌照(MGA)認證、英屬維爾京群島(BVI)認證、菲律賓(PAGCOR)監督競猜牌照
遊戲類型 : 真人百家樂、運彩投注、電子老虎機、彩票遊戲、棋牌遊戲、捕魚機遊戲
存取速度 : 存款5秒 / 提款3-5分
軟體下載 : 支援APP,IOS、安卓(Android)
線上客服 : 需透過官方LINE
富遊娛樂城優缺點
優點 缺點
台灣註冊人數NO.1線上賭場
首儲1000贈1000只需一倍流水
擁有體驗金免費體驗賭場
網紅部落客推薦保證出金線上娛樂城
需透過客服申請體驗金
富遊娛樂城存取款方式
存款方式 取款方式
提供四大超商(全家、7-11、萊爾富、ok超商)
虛擬貨幣ustd存款
銀行轉帳(各大銀行皆可)
網站內申請提款及可匯款至綁定帳戶
現金1:1出金
富遊娛樂城平台系統
真人百家 — RG真人、DG真人、歐博真人、DB真人(原亞博/PM)、SA真人、OG真人、WM真人
體育投注 — SUPER體育、鑫寶體育、熊貓體育(原亞博/PM)
彩票遊戲 — 富遊彩票、WIN 539
電子遊戲 —RG電子、ZG電子、BNG電子、BWIN電子、RSG電子、GR電子(好路)、ATG電子
棋牌遊戲 —ZG棋牌、亞博棋牌、好路棋牌、博亞棋牌、RG棋牌
捕魚遊戲 —ZG捕魚、RSG捕魚、好路GR捕魚、DB捕魚
富遊娛樂城優惠活動
優惠 獎金贈點 流水要求
免費體驗金 $168 1倍 (儲值後) /36倍 (未儲值)
首儲贈點 $1000 1倍流水
返水活動 0.3% – 0.7% 無流水限制
簽到禮金 $666 20倍流水
好友介紹金 $688 1倍流水
回歸禮金 $500 1倍流水
免費試玩
專屬富遊VIP特權
黃金 黃金 鉑金 金鑽 大神
升級流水 300w 600w 1800w 3600w
保級流水 50w 100w 300w 600w
升級紅利 $688 $1080 $3888 $8888
每週紅包 $188 $288 $988 $2388
生日禮金 $688 $1080 $3888 $8888
反水 0.4% 0.5% 0.6% 0.7%
娛樂城常見問題解答(FAQ)
Q1:如何在富遊娛樂城進行首次存款?
A1:可以透過超商、虛擬貨幣或銀行轉帳進行存款,過程簡單快速。( 詳細可查看:富遊娛樂城存款教學)
Q2:富遊娛樂城提款需要多久時間?
A2:提款過程一般在3-5分鐘內完成,保證快速到賬。( 詳細可查看:富遊娛樂城提款教學)
LEO娛樂城無法登入? 九州娛樂倒了? 富遊推出無痛轉移VIP優惠
LEO娛樂城無法登入免驚!推薦RG富遊更穩定、玩的更安心!
只要是玩過線上娛樂城的玩家,一定都對Leo娛樂城不陌生,近期Leo娛樂城無法登入的狀況越來越頻繁,是因為九州娛樂城與旗下品牌將在 2024/12/31 結束營業!
由於九州娛樂城旗下擁有leo娛樂城、THA娛樂城等品牌,這波風暴也讓許多玩家人心惶惶,擔心自己的遊戲權益受損,在文章的最後我們也提供了解決方案,趕快往下看!
九州娛樂城倒閉 ? 退出台灣娛樂市場?為何 ?
最近許多玩家發現 leo娛樂城無法登入,甚至傳出九州娛樂城要退出台灣的消息!雖然官方尚未發布正式聲明,但多方消息指出,九州娛樂城 (包含THA娛樂城、leo娛樂城) 正在逐步退出台灣市場。這可能是多重因素共同作用的結果:
退出台灣市場,尋求其他發展空間
九州娛樂認為台灣市場太小,品牌之間又過於競爭,市場規模有限,九州旗下其KU體育甚至贊助過足球五大聯賽,展現雄厚實力,促使九州娛樂城將目光投向海外。
畢竟,海外市場人口基數更大,獲利潛力也更為可觀。LEO娛樂城在台灣一個月就能獲利一億,進軍海外後的收益想必更加驚人。
金流問題、警界醜聞成導火線
LEO娛樂城高度仰賴金流公司運作,近期爆發的陳政谷案件揭露其旗下公司利用第三方支付協助母公司九州洗錢。
案情更指向警界內鬼,前台中刑大隊長林明佐涉嫌收賄超過4451萬元,為九州通風報信。 九州娛樂城曾出現凌晨時段無法儲值的狀況,很可能與警方查緝行動有關。
九州娛樂的新聞事件頻傳
LEO是九州集團底下的,陳政谷被抓之後,事情鬧得很大,為了避風頭,乾脆退出台灣也很合理。
這個說法也被推算也被網友認為有高度可能,不過也有人傳說其他幹部有接手的可能,至少沒辦法完全的說死九州會採取什麼行動。
leo娛樂城無法登入的問題,或許只是冰山一角,背後可能隱藏著更深層的原因。無論如何,九州娛樂城退出台灣市場,對玩家來說都是一個警訊。
九州娛樂城宣布12/31結束營業!玩家請停止儲值、立刻提款
九州娛樂城官方宣佈,近期旗下 THA、Leo 娛樂城無法登入,是因為九州集團將正式在 2024/12/31 中午 12:00 結束營業,退出台灣市場。
在這邊提醒玩家們立即停止存款動作,並且馬上將帳戶內的資金提領出來,避免您的權益受到損害!
LEO娛樂城無法登入? 九州娛樂倒了? 富遊推出無痛轉移VIP優惠
九州娛樂城宣布在12/31結束營業
告別Leo娛樂城無法登入煩惱!玩家無痛轉移至富遊,享更多優惠!
面對leo娛樂城無法登入的窘境,以及九州娛樂城的不確定性,玩家們需要一個安全可靠的新選擇!富遊娛樂城是您最佳的選擇,我們提供:
穩定安全保證出金: 穩定安全,保證出金! 擁有合法牌照和完善的監管機制,保障您的資金安全。
豐富多元的遊戲: 提供各式各樣的熱門遊戲,包括真人 casino、體育博彩、電子遊戲、彩票等等,滿足玩家的不同需求。
優渥的優惠活動: 新會員享有豐厚首存紅利,還有不定期的優惠活動和返水獎勵,讓您玩得更盡興!
24小時專業客服: 隨時為您解答問題,提供貼心服務。
立即註冊
特別優惠: 針對THA和LEO會員,富遊娛樂城推出獨家福利!
只要您是THA或LEO的會員,即可在富遊娛樂城直接升等到相對應的等級,並享有更高的反水、每週紅包和生日禮金!
立即加入富遊娛樂城,享受更優渥的回饋和更安心的保障!
以下是不同階級 VIP 的轉換福利與說明:
福利項目 / VIP階級 大神 金鑽 鉑金 黃金
每週紅包 2388 988 288 188
生日禮金 8888 3888 1080 688
返水 0.7 0.6 0.5 0.4
無論個人或團體,如有任何濫用本公司優惠的行為,本公司有權取消及收回獎金。
所有活動優惠都是特別為玩家而設立,在玩家註冊資訊有爭議時,為確保雙方利益,杜絕身份盜用行為,本公司有權要求玩家提供充足資訊,並以各種方式辨別玩家是否符合資格享有活動優惠。
本公司在會員有重複申請帳號行為時,有權取消及收回獎金。每位玩家、每一住址、每一電子郵箱、每一電話號碼、相同支付卡/信用卡號碼及共享電腦環境(例如網咖、其他公用網絡、公用電腦)只能擁有一個活動優惠資格。
每週限時紅包:會員在上週有過至少1次的存款記錄,每週一中午自動發放(1倍流水即可託售),限時48小時內領取! 每週至少存款要求:黃金富遊 1,000 點,鉑金富遊 1,500點,金鑽富遊 2,500點,大神富遊 5,000點 (存款計算週期:每週一 12:00 至下週一 11:59)
生日禮金:會員在註冊三個月內過生日,今年將不能領取生日禮金。另註冊時間大於三個月的會員需在生日當月找遊戲客服領取,每年可領取一次,需提供身分證明文件核實(1倍流水即可託售)
活動如有任何異動,本公司有權在任何時間修改、暫停或取消優惠活動,無需特別通知並保留本活動最終解釋權。
轉換平台申請辦法:提供螢幕錄影原平台層級介面到戶名、手機等資訊,傳送給富遊客服進行審核。
富遊娛樂城,值得您信賴的線上娛樂平台!
我們深知玩家選擇娛樂城的首要考量是安全和信譽。富遊娛樂城以誠信為本,致力於為玩家打造一個公平、公正、透明的遊戲環境。告別leo娛樂城無法登入的煩惱,立即加入富有娛樂城,體驗最優質的線上娛樂體驗!
Leo娛樂城無法登入?全面解析與解決指南
近期,Leo娛樂城的玩家紛紛反映登入失敗的情況,引發了廣泛的討論與擔憂。作為九州娛樂城旗下知名品牌之一,Leo娛樂城在台灣的娛樂市場中擁有大量用戶。然而,隨著九州娛樂城宣布將於2024年12月31日退出台灣市場,這一消息無疑讓玩家對資金安全與遊戲體驗產生了極大疑慮。
本文將深入探討Leo娛樂城無法登入的原因,提供解決方案,並推薦可靠的替代娛樂平台。
Leo娛樂城無法登入的三大原因
1. 帳號密碼問題
可能情況:最常見的原因是玩家輸入了錯誤的帳號或密碼,或者帳號被盜用。
解決方法:確認輸入的帳密正確,若仍無法登入,聯繫客服即可解決。
2. 網頁技術問題
可能情況:官網可能因伺服器維護或技術故障出現404錯誤,導致玩家無法登入。
解決方法:耐心等待官網修復,並清除瀏覽器快取和Cookie,或嘗試使用其他瀏覽器。
3. 九州娛樂城退出台灣市場
可能情況:隨著九州娛樂城宣布退出台灣市場,Leo娛樂城的營運也逐步停止,導致玩家無法再使用該平台。
影響:玩家可能面臨資金提取困難,需及時完成出金操作以保障自身利益。
娛樂城無法登入的緊急解決方案
核對帳號與密碼:確認輸入正確無誤,避免由於簡單疏忽造成的登入失敗。
檢查網路連線:確保網路穩定,必要時切換至更穩定的網路環境。
清除瀏覽器快取與Cookie:解決瀏覽器相關問題,恢復正常登入。
嘗試其他瀏覽器或設備:更換設備或使用不同瀏覽器,查看是否可以正常登入。
九州娛樂城退出台灣市場的原因
市場利潤有限:九州娛樂城認為台灣市場的競爭激烈且利潤有限,因此選擇退出並專注於其他海外市場。
資金生態鏈斷裂:現金交易平台出現問題,導致九州娛樂城難以維持正常運營。
母公司法律爭議:九州娛樂城母公司近年來因財務與法律問題受到高度關注,進一步影響旗下品牌的營運。
Leo娛樂城會員如何安全出金?
在九州娛樂城停止營運前,玩家需要立即完成出金操作以確保資金安全。
出金建議:
儘快登入官網提交提款申請,確保資金安全轉出。
若官網無法訪問,請嘗試聯繫客服,並保留交易證明以備進一步處理。
推薦替代平台:富遊娛樂城
隨著Leo娛樂城的退出,玩家可以考慮轉至穩定且值得信賴的替代平台,如富遊娛樂城。
富遊娛樂城的優勢
穩定可靠:擁有先進的技術和完善的資金保障機制,確保玩家的資金安全。
豐富的遊戲選擇:從電子遊戲到真人娛樂,滿足各類玩家的需求。
專屬優惠:特別為Leo會員推出等級升等計畫,並提供多樣化的專屬活動。
快速出金:高效的財務系統,讓玩家的存取款過程快速無憂。
Leo會員轉移至富遊的流程
登錄富遊官網完成註冊。
提供Leo娛樂城會員等級截圖與相關資料(如戶名、手機號碼)給富遊客服進行審核。
等待客服確認後,享受富遊娛樂城專屬的會員福利與優惠。
結語:立即加入富遊娛樂城,延續遊戲體驗!
Leo娛樂城的退出讓許多玩家感到困惑與擔憂,但選擇穩定、安全的娛樂平台是最明智的應對之道。富遊娛樂城憑藉其卓越的技術、專業的服務以及豐富的優惠,成為玩家的理想替代選擇。現在就註冊富遊娛樂城,享受無與倫比的遊戲體驗吧!
[url=https://savagg.com]bestchange sova[/url] – bestchange сова, sova gg
九州娛樂城登入
Leo娛樂城無法登入?全面解析與解決指南
近期,Leo娛樂城的玩家紛紛反映登入失敗的情況,引發了廣泛的討論與擔憂。作為九州娛樂城旗下知名品牌之一,Leo娛樂城在台灣的娛樂市場中擁有大量用戶。然而,隨著九州娛樂城宣布將於2024年12月31日退出台灣市場,這一消息無疑讓玩家對資金安全與遊戲體驗產生了極大疑慮。
本文將深入探討Leo娛樂城無法登入的原因,提供解決方案,並推薦可靠的替代娛樂平台。
Leo娛樂城無法登入的三大原因
1. 帳號密碼問題
可能情況:最常見的原因是玩家輸入了錯誤的帳號或密碼,或者帳號被盜用。
解決方法:確認輸入的帳密正確,若仍無法登入,聯繫客服即可解決。
2. 網頁技術問題
可能情況:官網可能因伺服器維護或技術故障出現404錯誤,導致玩家無法登入。
解決方法:耐心等待官網修復,並清除瀏覽器快取和Cookie,或嘗試使用其他瀏覽器。
3. 九州娛樂城退出台灣市場
可能情況:隨著九州娛樂城宣布退出台灣市場,Leo娛樂城的營運也逐步停止,導致玩家無法再使用該平台。
影響:玩家可能面臨資金提取困難,需及時完成出金操作以保障自身利益。
娛樂城無法登入的緊急解決方案
核對帳號與密碼:確認輸入正確無誤,避免由於簡單疏忽造成的登入失敗。
檢查網路連線:確保網路穩定,必要時切換至更穩定的網路環境。
清除瀏覽器快取與Cookie:解決瀏覽器相關問題,恢復正常登入。
嘗試其他瀏覽器或設備:更換設備或使用不同瀏覽器,查看是否可以正常登入。
九州娛樂城退出台灣市場的原因
市場利潤有限:九州娛樂城認為台灣市場的競爭激烈且利潤有限,因此選擇退出並專注於其他海外市場。
資金生態鏈斷裂:現金交易平台出現問題,導致九州娛樂城難以維持正常運營。
母公司法律爭議:九州娛樂城母公司近年來因財務與法律問題受到高度關注,進一步影響旗下品牌的營運。
Leo娛樂城會員如何安全出金?
在九州娛樂城停止營運前,玩家需要立即完成出金操作以確保資金安全。
出金建議:
儘快登入官網提交提款申請,確保資金安全轉出。
若官網無法訪問,請嘗試聯繫客服,並保留交易證明以備進一步處理。
推薦替代平台:富遊娛樂城
隨著Leo娛樂城的退出,玩家可以考慮轉至穩定且值得信賴的替代平台,如富遊娛樂城。
富遊娛樂城的優勢
穩定可靠:擁有先進的技術和完善的資金保障機制,確保玩家的資金安全。
豐富的遊戲選擇:從電子遊戲到真人娛樂,滿足各類玩家的需求。
專屬優惠:特別為Leo會員推出等級升等計畫,並提供多樣化的專屬活動。
快速出金:高效的財務系統,讓玩家的存取款過程快速無憂。
Leo會員轉移至富遊的流程
登錄富遊官網完成註冊。
提供Leo娛樂城會員等級截圖與相關資料(如戶名、手機號碼)給富遊客服進行審核。
等待客服確認後,享受富遊娛樂城專屬的會員福利與優惠。
結語:立即加入富遊娛樂城,延續遊戲體驗!
Leo娛樂城的退出讓許多玩家感到困惑與擔憂,但選擇穩定、安全的娛樂平台是最明智的應對之道。富遊娛樂城憑藉其卓越的技術、專業的服務以及豐富的優惠,成為玩家的理想替代選擇。現在就註冊富遊娛樂城,享受無與倫比的遊戲體驗吧!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
смотреть здесь https://xn—-7sbbajqthmir8bngi.xn--p1acf/trulisiti-15mg-05ml-4-sht-rastvor-dlya-podkozhnogo-vvedeniya/
найти это
[url=https://termik18.ru/]купить газовый котел в ижевске термика[/url]
Смотреть здесь
[url=https://hydraccum.ru/]donvart[/url]
другие
[url=https://termik18.ru/services/montazh-i-pnr-sistem-otopleniya-i-kotelnyh]гибка металла на заказ[/url]
модульные светодиодные экраны https://svetodiodnyy-ekran.ru
Источник
[url=https://termik18.ru/wp-content/uploads/2020/07/tg-150-vn-n-k3g-630-ar02-01.pdf]тг 200 руководство по эксплуатации[/url]
перейдите на этот сайт
[url=https://rezlaser.ru/]люлька для кму[/url]
Портал строительства https://mbmedicall.com ресурс для поиска информации о ремонте и строительстве. Полезные советы, технологии, инструкции и рекомендации для профессионалов и новичков.
九州娛樂城退出台灣市場:LEO娛樂城無法登入的背後真相
LEO娛樂城,作為台灣線上娛樂城市場的重要品牌,長期以來在廣告投放和代理推廣方面占據領先地位。然而,近期出現的「LEO娛樂城無法登入」現象引發了廣泛的網路討論。不少玩家質疑:「九州娛樂城是不是倒了?」「這是不是詐騙?」事實上,這些猜測與謠言並不完全準確。根據最新消息,九州娛樂城已決定結束其在台灣的業務,包括旗下品牌LEO娛樂城和THA娛樂城。以下我們將深入分析這一事件的背景和可能的影響。
LEO娛樂城無法登入的原因分析
近期LEO娛樂城頻繁出現無法登入的情況,其實是九州娛樂城退出台灣市場的前兆。根據官方公告,九州娛樂城將於2024年12月31日中午12點正式關閉,包括註冊與存款功能在內的多項服務已經受到限制。
可能原因 1:退出台灣市場的策略
九州娛樂城的管理層認為,台灣市場的利潤已達上限,長期運營的收益減少,因此選擇「見好就收」。這一策略符合台灣商業文化中尋找新市場發展的特點。九州娛樂城可能計劃將資源投入其他更具潛力的市場,以追求更大的收益。
可能原因 2:運營生態鏈的問題
LEO娛樂城的運營高度依賴第三方現金交易平台以及相關支付管道。近期,這些環節可能出現了無法解決的問題,導致整體運營受阻。為了避免損失擴大,九州娛樂城選擇退出台灣市場。
可能原因 3:法律風險與負面新聞
九州娛樂城因涉及法律事件,曾多次登上新聞版面。這些事件不僅損害了品牌形象,也讓經營面臨更多風險。為了降低法律糾紛帶來的影響,九州娛樂城可能選擇結束在台灣的營運。
官方公告:2024年12月31日正式停業
九州娛樂城已向所有LEO娛樂城會員發布公告,明確指出將於2024年12月31日中午12點全面停止營運。公告內容包括以下重要信息:
存款服務已關閉:玩家無法繼續充值。
提款功能仍正常:玩家可以放心提取餘額,會員權益不受影響。
感謝支持:官方對會員表達了感謝,並祝福大家未來順利。
這一公告讓玩家可以在剩餘時間內完成提款操作,避免資金損失。
對玩家的影響與建議
1. 儘快提款
如果您是LEO娛樂城的會員,應立即登入帳戶並提取餘額,以確保資金安全。
2. 謹慎選擇新平台
選擇新的娛樂平台時,應注意以下幾點:
合法性:確認平台是否擁有合法經營許可。
支付系統穩定性:確保提款及充值渠道安全無虞。
用戶評價:參考其他玩家的反饋,選擇口碑良好的平台。
3. 防範詐騙
警惕假冒的LEO娛樂城網站或客服。官方客服系統已關閉,任何聯繫您索取個人資料的行為都可能是詐騙。
結語
LEO娛樂城無法登入以及九州娛樂城退出台灣市場,標誌著線上娛樂城行業的一次重要轉折。對於玩家而言,這既是一個挑戰,也是一個重新審視平台選擇的機會。未來,玩家應更加關注平台的合法性與穩定性,為自己的遊戲體驗和資金安全提供保障。
3A娛樂城
3A娛樂城:全方位線上娛樂體驗的首選平台
3A娛樂城作為台灣最受歡迎的線上娛樂平台之一,以其多樣化的遊戲選擇、創新的技術、以及卓越的安全保障,贏得了玩家的高度信任與青睞。無論您是新手還是老手,3A娛樂城都能滿足您的需求,帶給您獨一無二的遊戲體驗。
熱門娛樂城遊戲一覽
3A娛樂城提供多種熱門遊戲,適合不同類型的玩家:
真人百家樂:體驗真實賭場的氛圍,與真人荷官互動,感受賭桌上的緊張與刺激。
彩票投注:涵蓋多種彩票選項,滿足彩券愛好者的需求,讓您隨時隨地挑戰幸運。
棋牌遊戲:從傳統的麻將到現代化的紙牌遊戲,讓玩家在策略與運氣中找到平衡。
3A娛樂城的核心價值
1. 專業
3A娛樂城每日提供近千場體育賽事,並搭配真人百家樂、彩票彩球、電子遊戲等多種類型的線上賭場遊戲。無論您的遊戲偏好為何,這裡總有一款適合您!
2. 安全
平台採用128位加密技術和嚴格的安全管理體系,確保玩家的金流與個人資料完全受保護,讓您可以放心遊玩,無需擔憂安全問題。
3. 便捷
3A娛樂城是全台第一家使用自家開發的全套終端應用的娛樂城平台。無論是手機還是電腦,玩家都能享受無縫的遊戲體驗。同時,24小時線上客服隨時為您解決任何問題,提供貼心服務。
4. 安心
由專業工程師開發的財務處理系統,為玩家帶來快速的存款、取款和轉帳服務。透過獨立網路技術,平台提供優化的網路速度,確保每一次操作都流暢無比。
下載3A娛樂城手機APP
為了提供更便捷的遊戲體驗,3A娛樂城獨家開發了功能齊全的手機APP,讓玩家隨時隨地開啟遊戲。
現代化設計:新穎乾淨的介面設計,提升使用者體驗。
跨平台支持:完美適配手機與電腦,讓您輕鬆切換設備,無需中斷遊戲。
快速下載:掃描專屬QR碼即可進入下載頁面,立即開始暢玩!
3A娛樂城的其他服務
娛樂城教學:詳細的操作指導,讓新手也能快速上手。
責任博彩:提倡健康娛樂,確保玩家在遊戲中享受樂趣的同時,不失理性。
隱私權政策:嚴格遵守隱私保護條例,保障玩家的個人信息安全。
立即加入3A娛樂城,享受頂級娛樂體驗!
如果您正在尋找一個專業、安全、便捷又安心的線上娛樂平台,那麼3A娛樂城絕對是您的不二之選。現在就下載手機APP,隨時隨地開啟您的娛樂旅程,享受無限的遊戲樂趣與刺激!
[url=https://mega4web.cc/]мега официальная ссылка[/url] – мега рутор, мега ссылка
смотреть здесь
[url=https://exci.ru/]эксимер коррекция зрения[/url]
娛樂城
2024 年娛樂城遊戲推薦:最夯遊戲與最佳平台選擇
隨著線上娛樂城市場的蓬勃發展,2024 年推出了多款令人興奮的遊戲和創新平台。無論是喜歡老虎機、棋牌遊戲,還是捕魚和彩票遊戲的玩家,都能在今年找到屬於自己的遊戲樂園。以下是熱門遊戲推薦與最佳娛樂城平台的詳細介紹。
2024 年最夯遊戲推薦
電子老虎機遊戲
電子老虎機一直是娛樂城的經典項目,今年更是推出了數款熱門作品:
戰神賽特:以古埃及神話為背景,擁有高倍數獎勵的特殊功能,畫面設計精美。
魔龍傳奇:玩家可探索魔龍世界,觸發驚喜獎金和免費遊戲機會。
雷神之錘:以北歐神話為主題,特色連線玩法讓每次旋轉都充滿期待。
金虎爺:寓意招財進寶,特別適合新年期間挑戰,玩法簡單但回報豐厚。
棋牌遊戲
二人麻將:適合喜歡策略性對抗的玩家,快速節奏且競爭激烈。
忍 Kunoichi:結合武士與忍者元素,讓玩家體驗獨特的棋牌競技。
捕魚遊戲
捕魚遊戲是一種結合策略和運氣的娛樂項目,玩家可以通過捕捉魚群來獲得高額獎金,同時享受視覺和操作的雙重樂趣。
彩票遊戲
彩票遊戲以簡單快捷的玩法吸引大批玩家,提供多種國內外彩種,讓玩家隨時挑戰幸運。
RG富遊娛樂城:2024 年最佳線上娛樂城推薦
在眾多娛樂城平台中,RG富遊娛樂城以其專業服務和卓越遊戲體驗,成為今年的首選平台。
平台特色
遊戲種類豐富
提供多元化遊戲選擇,包括真人視訊、電子老虎機、捕魚、棋牌和彩票遊戲,滿足所有玩家需求。
快速便捷的存提款服務
平台支持即時存款與快速提款,無需等待,確保資金安全流動。
高度安全保障
採用最先進的加密技術,保護玩家的帳戶與交易安全。
支援多平台裝置
富遊娛樂城APP 可在 iOS 和 Android 設備上使用,界面簡潔易操作,隨時隨地享受娛樂。
專業客服支援
提供 24 小時全天候客服,隨時解答玩家疑問,保障流暢的遊戲體驗。
如何開始體驗 RG 富遊娛樂城
下載富遊 APP
在官方網站免費下載 APP,支援 iOS 和 Android 設備。
註冊帳號
使用簡單步驟完成註冊,立即進入遊戲世界。
挑戰熱門遊戲
從老虎機到棋牌遊戲,選擇您喜歡的類型,挑戰高額獎金。
結語
2024 年是線上娛樂遊戲的精彩年份,從戰神賽特到二人麻將,每款遊戲都能帶給玩家不同的樂趣。而選擇像 RG富遊娛樂城 這樣的專業平台,不僅能體驗到豐富的遊戲內容,還能享受安全可靠的服務。立即下載富遊 APP,加入這個充滿驚喜的娛樂世界
Продолжение
[url=https://exci.ru/]витреозилис в ижевске[/url]
веб-сайте https://stmb-trucks.ru
узнать больше Здесь https://dbshop.ru
2024 年娛樂城遊戲推薦:最夯遊戲與最佳平台選擇
隨著線上娛樂城市場的蓬勃發展,2024 年推出了多款令人興奮的遊戲和創新平台。無論是喜歡老虎機、棋牌遊戲,還是捕魚和彩票遊戲的玩家,都能在今年找到屬於自己的遊戲樂園。以下是熱門遊戲推薦與最佳娛樂城平台的詳細介紹。
2024 年最夯遊戲推薦
電子老虎機遊戲
電子老虎機一直是娛樂城的經典項目,今年更是推出了數款熱門作品:
戰神賽特:以古埃及神話為背景,擁有高倍數獎勵的特殊功能,畫面設計精美。
魔龍傳奇:玩家可探索魔龍世界,觸發驚喜獎金和免費遊戲機會。
雷神之錘:以北歐神話為主題,特色連線玩法讓每次旋轉都充滿期待。
金虎爺:寓意招財進寶,特別適合新年期間挑戰,玩法簡單但回報豐厚。
棋牌遊戲
二人麻將:適合喜歡策略性對抗的玩家,快速節奏且競爭激烈。
忍 Kunoichi:結合武士與忍者元素,讓玩家體驗獨特的棋牌競技。
捕魚遊戲
捕魚遊戲是一種結合策略和運氣的娛樂項目,玩家可以通過捕捉魚群來獲得高額獎金,同時享受視覺和操作的雙重樂趣。
彩票遊戲
彩票遊戲以簡單快捷的玩法吸引大批玩家,提供多種國內外彩種,讓玩家隨時挑戰幸運。
RG富遊娛樂城:2024 年最佳線上娛樂城推薦
在眾多娛樂城平台中,RG富遊娛樂城以其專業服務和卓越遊戲體驗,成為今年的首選平台。
平台特色
遊戲種類豐富
提供多元化遊戲選擇,包括真人視訊、電子老虎機、捕魚、棋牌和彩票遊戲,滿足所有玩家需求。
快速便捷的存提款服務
平台支持即時存款與快速提款,無需等待,確保資金安全流動。
高度安全保障
採用最先進的加密技術,保護玩家的帳戶與交易安全。
支援多平台裝置
富遊娛樂城APP 可在 iOS 和 Android 設備上使用,界面簡潔易操作,隨時隨地享受娛樂。
專業客服支援
提供 24 小時全天候客服,隨時解答玩家疑問,保障流暢的遊戲體驗。
如何開始體驗 RG 富遊娛樂城
下載富遊 APP
在官方網站免費下載 APP,支援 iOS 和 Android 設備。
註冊帳號
使用簡單步驟完成註冊,立即進入遊戲世界。
挑戰熱門遊戲
從老虎機到棋牌遊戲,選擇您喜歡的類型,挑戰高額獎金。
結語
2024 年是線上娛樂遊戲的精彩年份,從戰神賽特到二人麻將,每款遊戲都能帶給玩家不同的樂趣。而選擇像 RG富遊娛樂城 這樣的專業平台,不僅能體驗到豐富的遊戲內容,還能享受安全可靠的服務。立即下載富遊 APP,加入這個充滿驚喜的娛樂世界
Собственное производство металлоконструкций. Если вас интересует навесы цены мы предлогаем изготовление под ключ навесы для автомобиля из поликарбоната
滿天星娛樂城:全方位的線上娛樂體驗
滿天星娛樂城作為九州娛樂城旗下品牌之一,是玩家心目中備受信賴的線上娛樂平台。不僅提供豐富的遊戲選擇和吸引人的優惠,還以其合法營運的背景和快速出金的保證,成為台灣玩家的首選娛樂城之一。
滿天星娛樂城的特色與優勢
1. 合法營運,安全可靠
滿天星娛樂城持有三大國際娛樂執照,包括:
菲律賓 PAGCOR 監督競猜牌照
BVI 認證
馬爾他 MGA 認證
這些執照展現了平台的資本實力與合法性,讓玩家能夠安心享受遊戲,完全不用擔心出金問題。
2. 高品質遊戲與豐富優惠
滿天星娛樂城與九州集團旗下的LEO、THA娛樂城一樣,提供一流的遊戲品質和多樣化的優惠。
熱門遊戲推薦:電子老虎機、真人直播、運彩投注、今彩539等,滿足各類玩家需求。
優惠活動:定期推出限時回饋活動,讓玩家在遊戲中獲得更多額外收益。
3. 快速出金與高效服務
滿天星娛樂城採用先進的財務系統,確保存提款快速、安全,讓玩家能夠專注於享受遊戲,而無需擔心資金問題。專業的客服團隊24小時在線,提供即時支援。
4. 多平台兼容的APP
滿天星娛樂城提供設計貼合玩家需求的手機APP,適用於iOS與Android系統。玩家可以隨時隨地快速登入遊玩,體驗無與倫比的娛樂快感。
熱門遊戲類型一覽
滿天星娛樂城為玩家提供多樣化的遊戲選擇,滿足不同興趣和需求:
真人直播:感受真實賭場氛圍,與真人荷官互動,體驗沉浸式娛樂。
電子老虎機:多款經典與創新機台,讓玩家享受刺激的遊戲過程。
運彩投注:涵蓋世界盃、棒球、籃球等多項運動賽事,提供即時投注與直播功能。
彩票遊戲:包括今彩539、富遊彩票等,適合熱衷於彩券的玩家。
滿天星娛樂城常見問題解答
Q1. 滿天星娛樂城是否提供APP下載?
是的,滿天星娛樂城提供專屬的手機APP,支援iOS和Android系統。玩家可透過APP快速登入,隨時享受遊戲。
Q2. 滿天星娛樂城是否合法?
滿天星娛樂城擁有多項國際認證,為合法經營的線上娛樂城,並保證玩家資金的安全性與遊戲的公平性。
Q3. 無法登入滿天星娛樂城該怎麼辦?
如遇到無法登入的情況,建議玩家檢查網路狀況或聯繫24小時客服團隊獲取即時協助。
立即加入滿天星娛樂城,享受最佳娛樂體驗!
滿天星娛樂城以合法、安全、快速的服務,搭配豐富的遊戲選擇和優惠,為玩家打造出獨一無二的線上娛樂體驗。不論您是新手還是老手,都能在滿天星找到屬於自己的遊戲樂趣。現在就下載APP,隨時隨地開始您的娛樂之旅!
Неотразимый стиль современных тактичных штанов, как выбрать их с другой одеждой.
Секрет комфорта в тактичных штанах, которые подчеркнут ваш стиль и индивидуальность.
Идеальные тактичные штаны: находка для занятых людей, который подчеркнет вашу уверенность и статус.
Лучшие модели тактичных штанов для мужчин, которые подчеркнут вашу спортивную натуру.
Советы по выбору тактичных штанов для мужчин, чтобы подчеркнуть свою уникальность и индивидуальность.
Секрет стильных мужчин: тактичные штаны, которые подчеркнут ваш вкус и качество вашей одежды.
Сочетание стиля и практичности в тактичных штанах, которые подчеркнут ваш профессионализм и серьезность.
купить штани тактичні [url=https://dffrgrgrgdhajshf.com.ua/]https://dffrgrgrgdhajshf.com.ua/[/url] .
[url=https://mega4web.cc/]мега площадка[/url] – мега ссылка, mega com отзывы
Следующая страница
[url=https://rezlaser.ru/]люльки для монтажных работ[/url]
Your article helped me a lot, is there any more related content? Thanks!
хотите окунуться в азартные игры? vavada бездепозитный бонус позволяет начать играть в казино vavada. попробуйте телеграм-канал для удобного доступа. оцените широкие возможности: от промокодов до рейтинговых игр.
Тут можно преобрести сейф металлический взломостойкий cейфы взломостойкие
vavada рабочий сайт предоставляет уникальную возможность погрузиться в мир азартных игр. здесь вы сможете создать аккаунт на надёжной платформе vavada. получите доступ к бонусам через личный кабинет.
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
Допускаю, что вы верно рассуждаете
beburishvili-afisha.ru
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
Reliable HVAC Repair Services https://serviceorangecounty.com stay comfortable year-round with our professional HVAC repair services. Our experienced team is dedicated to diagnosing and resolving heating, cooling, and ventilation issues quickly and effectively.
Если вам нужен качественный ремонт, порекомендуем: Ремонт электроприборов Philips в Москве
узнать больше [url=https://city-exchenge.io]city-exchange обменник[/url]
Следующая страница [url=https://city-exchenge.io]Сити эксчейдж[/url]
брекеты установка https://brekety-na-zuby.ru/
her response [url=https://metagetapp.xyz]Software for Windows[/url]
Swap.cloud https://swap.cloud is a licensed cryptocurrency exchange service based in Luxembourg. It offers fully automated, instant swaps between cryptocurrencies with no KYC requirements, ensuring speed and privacy. The platform is designed for users seeking seamless, secure, and hassle-free transactions.
soap2day without subscription soap2day short films
РПНУ Лизинг https://rpnu-leasing.ru надежный партнер в лизинге автомобилей, спецтехники и оборудования. Гарантируем отсутствие отказов благодаря индивидуальному подходу к каждому клиенту. Удобные условия и быстрое оформление помогают получить нужное имущество без лишних сложностей.
soap2day science fiction https://soap2dayalt.com
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
[url=https://Xnova.fun]нова ссылка tor[/url] – актуальные ссылки на нову, нова даркнет
Our GTA 5 RP platform presents a vast sandbox gameplay enhanced with custom custom extensions and playstyle attributes.
Whether you’re a law-abiding cop or a aspiring crime genius, the chances in Los Santos are boundless:
Create Your Dominion: Enter syndicates, organize heists, or progress the illegal network to control the city.
Act As a Champion: Ensure justice as a law enforcer, rescuer, or healthcare worker.
Customize Your Story: Craft your living, from high-end vehicles and properties to your hero’s special look and storylines.
Thrilling Tasks: Take Part in high-stakes operations, spectacular competitions, and player-driven challenges to gain rewards and reputation.
Rule the System and Become Wealthy!
At vs-rp.com, we offer you the tools and options to earn significant in the in-game realm of GTA RP. From securing high-end resources to gathering riches, the RP market is yours to master.
Create your wealth through:
Player-Driven Challenges: Complete activities, exchanges, and assignments to acquire in-game dollars.
Custom Companies: Open and operate your own venture, from car markets to lounges.
High-End Properties: Own top-tier automobiles, premium estates, and special in-game items.
Are you prepared to conquer Los Santos and grow into a online mogul?
Why Pick Our Platform?
Here’s why we’re the best GTA 5 RP server:
1. Regular Patches and Features
Stay ahead of the competition with unique improvements, events, and occasional opportunities. New content are introduced consistently to maintain your experience new and thrilling.
2. Massive Range of Resources
Discover a massive inventory of virtual goods, including:
Luxury Cars
Exclusive Estates
Limited Goods
3. Committed Help
Whether you’re a veteran roleplayer or a complete beginner, our staff is available to guide. We’ll help you in launching, offer tools, and ensure you excel in Los Santos.
купить входные двери двери межкомнатные купить в спб
купить входные двери в спб межкомнатные двери спб
[url=https://jaxx-liberty.com/]jaxx liberty wallet[/url] – jaxx io, jaxx wallet io
аккумулятор автомобильный цена аккумуляторы для легковых автомобилей
кадастровые работы земельный участок межевание земельного участка спб
генератор 20 квт цена https://tss-generators.ru
Plinko se ha convertido https://medium.com/@kostumchik.kiev.ua/todo-sobre-el-juego-de-plinko-en-m%C3%A9xico-instrucciones-demos-opiniones-y-m%C3%A1s-d1fde2d99338 en una de las opciones favoritas de los jugadores de casinos en Mexico. Conocido por su simplicidad y gran potencial de ganancias, este adictivo juego ahora cuenta con una plataforma oficial en Mexico.
Онлайн-журнал о строительстве https://zip.org.ua практичные советы, современные технологии, тренды дизайна и архитектуры. Всё о строительных материалах, ремонте, благоустройстве и инновациях в одной удобной платформе.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
рейтинг казино на реальные деньги онлайн рейтинг казино 2024
рейтинг казино на реальные деньги онлайн топ казино 2024 года
Uncover the Universe of CS2 Weapon Skins: Pick the Perfect Appearance for Your Playstyle
Upgrade your performance with exclusive, superior cosmetics that improve the look of your weapons and transform your arsenal truly shine.
We offer a extensive selection of items — from rare items to limited edition options, enabling you the ability to personalize your arsenal and highlight your uniqueness.
Why Choose Us?
Buying CS2 skins in our store is speedy, safe, and simple. With immediate automated transfer immediately to your in-game storage, you can instantly equipping your latest gear right away.
Our Strengths:
– Safe Payment: Enjoy protected, hassle-free checkouts on every order.
– Low Rates: We offer the most attractive item deals with ongoing price drops.
– Diverse Options: From affordable to top-tier options, we offer it all.
Steps to Buy:
1. View the Range
Explore our extensive catalog of cosmetics, organized by weapon type, scarcity, and appearance.
2. Select Your Skin
Once you find the best item, add it to your cart and continue to purchase.
3. Enjoy Your New Skins
Receive your gear right away and apply them while gaming to highlight your style.
Reasons Gamers Rely on Us:
– Extensive Variety: Choose cosmetics for any style.
– Transparent Costs: Clear costs with zero additional fees.
– Immediate Access: Enjoy your purchases right away.
– Protected Payments: Trusted and risk-free payment options.
– Support Team: Our staff is here to assist you around the clock.
Shop Now Right Away!
Find the most popular CS2 skins and take your playstyle to the top tier.
Whether you’re wanting to improve your gear, collect a rare set, or just show off, we|our store|our site|our marketplace is your go-to platform for premium Counter-Strike 2 skins.
Join us and discover the item that matches your preferences!
секс шоп сайт https://sex-shop-kh.top
learn this here now https://web-counterparty.io
This web site is really a walk-through for all of the info you wanted about this and didn’t know who to ask. Glimpse here, and you’ll definitely discover it.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
read more https://brd-wallet.io/
Тут можно сейф для документов в офис ценасейф офисный купить
Рейтинг лучших онлайн-казино https://lastdepcasino.ru с быстрыми выплатами и честной игрой. Подробные обзоры, бонусы для новых игроков и актуальные акции.
Тут можно сейф цена москвакупить сейф в москве
I’m not sure why but this site is loading incredibly slow for me. Is anyone else having this problem or is it a issue on my end? I’ll check back later on and see if the problem still exists.
скачать мангу
нажмите [url=http://no-deposit-bonus.pro/]популярное казино[/url]
Cat Grooming Supplies Eco-Friendly Cat Products
Автомобильный журнал https://automobile.kyiv.ua с фокусом на практичность. Ремонт, уход за авто, обзор технологий и советы по эксплуатации.
Вероятно, вы не ошибаетесь
fakel-nsk-afisha.ru
Авто журнал https://avtonews.kyiv.ua новости автопрома, сравнения моделей, тест-драйвы, советы по ремонту и уходу.
Всё о машинах https://black-star.com.ua авто новости, тест-драйвы, обзоры моделей, рейтинги, инструкции по обслуживанию и ремонту.
Авто портал https://autonovosti.kyiv.ua актуальные новости, обзоры авто, тест-драйвы, инструкции по ремонту и тюнингу. Минимум текста, максимум полезной информации.
Всё о самогоноварении https://brewsugar.ru на одном сайте: от истории напитка до современных технологий перегонки.
Место для общения на любые темы https://xn--9i1b12ab68a.com/ актуальные вопросы, обмен опытом, интересные дискуссии. Здесь найдётся тема для каждого.
Перевозка товаров из Китая https://chinaex.ru в Россию под ключ: авиа, море, автотранспорт. Гарантия сроков и сохранности груза.
Автомобильный онлайн-журнал https://simpsonsua.com.ua предлагает свежие новости, обзоры авто, тест-драйвы, рейтинги и полезные советы для водителей.
Мода, здоровье, красота https://gratransymas.com семья, кулинария, карьера. Женский портал — полезные советы и свежие идеи для каждой.
Познавательный портал для детей https://detiwki.com.ua обучающие материалы, интересные факты, научные эксперименты, игры и задания для развития кругозора.
Discover the latest game codes https://pocket-codes.com detailed guides, and expertly crafted tier lists to enhance your gaming experience. Unlock rewards, master strategies, and dominate every level with our curated content. Perfect for gamers seeking an edge!
офисная мебель в спб мягкая мебель для офиса
Женский онлайн-журнал https://stylewoman.kyiv.ua стиль, уход, здоровье, отношения, семья, кулинарные рецепты, психология и карьера.
офисная мебель спб https://ковка116.рф
Всё о туризме https://atrium.if.ua маршруты, путеводители, советы по отдыху, обзор отелей и лайфхаки. Туристический портал — ваш помощник в путешествиях.
Всё для путешествий https://cmc.com.ua уникальные маршруты, гиды по городам, актуальные акции на туры и полезные статьи для туристов.
Статьи о путешествиях https://deluxtour.com.ua гиды по направлениям, лайфхаки для отдыха, советы по сбору багажа и туристические обзоры.
Путешествия по Греции https://cpcfpu.org.ua лучшие курорты, гиды по островам, экскурсии, пляжи и советы по планированию отпуска.
Туристический журнал https://elnik.kiev.ua свежие идеи для путешествий, обзоры курортов, гиды по городам, советы для самостоятельных поездок и туристические новости.
Статьи о туризме и путешествиях https://inhotel.com.ua маршруты, гиды по достопримечательностям, советы по планированию поездок, рекомендации по отелям и лайфхаки для туристов.
Гиды по странам https://hotel-atlantika.com.ua экскурсии по городам, советы по выбору жилья и маршрутов. Туристический журнал — всё для комфортного и яркого путешествия.
Комплексный ремонт квартир https://anti-orange.com.ua и домов от Студии ремонта. Полный цикл работ: от дизайна до финишной отделки.
На строительном портале https://avian.org.ua вы найдете всё: от пошаговых инструкций до списка лучших подрядчиков. Помогаем реализовать проекты любой сложности быстро и удобно.
Строительный портал https://ateku.org.ua ваш гид в мире строительства и ремонта. Полезные статьи, обзоры материалов, советы по выбору подрядчиков и идеи дизайна.
Портал по ремонту https://azst.com.ua всё для вашего ремонта: подбор подрядчиков, советы по выбору материалов, готовые решения для интерьера и проверенные рекомендации.
Журнал по ремонту https://domtut.com.ua и строительству – советы, идеи и обзоры. Узнайте о трендах, изучите технологии и воплотите свои строительные или дизайнерские задумки легко и эффективно.
Портал о ремонте https://eeu-a.kiev.ua всё для тех, кто ремонтирует: пошаговые инструкции, идеи дизайна, обзор материалов и подбор подрядчиков.
Журнал по ремонту и строительству https://diasoft.kiev.ua гид по современным тенденциям. Полезные статьи, лайфхаки, инструкции и обзор решений для дома и офиса.
проведение оценки профессиональных рисков на предприятии заказать оценку профессиональных рисков по охране труда в Москве
Строительные технологии https://ibss.org.ua новейшие разработки и решения в строительной сфере. Материалы, оборудование, инновации и тренды для профессионалов и застройщиков.
Сайт о строительстве и ремонте https://hydromech.kiev.ua полезные советы, инструкции, обзоры материалов и технологий. Все этапы: от фундамента до отделки.
Все о строительстве и ремонте https://kennan.kiev.ua практичные рекомендации, идеи интерьеров, новинки рынка и советы профессионалов.
Асфальтирование и ремонт дорог https://mia.km.ua информация о технологиях укладки асфальта, методах ремонта покрытий и современных материалах.
Kompaktni zarizeni mikrosluchatka poskytuje spolehlivy prenos, pevny, nenapadny design a pohodlne se nosi v kazde situaci.
Онлайн-журнал о строительстве https://mts-slil.info свежие новости, обзоры инноваций, рекомендации по ремонту и строительству.
Мастерская креативных идей https://rusproekt.org пространство для творчества и инноваций. Уникальные решения для дизайна, декора и проектов любого масштаба.
Онлайн журнал о ремонте https://prezent-house.com.ua статьи, лайфхаки и решения для всех этапов ремонта: от планирования до отделки. Практичные рекомендации и идеи для вашего дома.
Портал о ремонте https://rvps.kiev.ua практичные рекомендации, дизайн-идеи, современные технологии и инструкции для успешного ремонта любого уровня сложно
Сайт о дизайне интерьера и территории https://sinega.com.ua тренды в дизайне помещений и благоустройстве территорий.
Информационный портал о ремонте https://sevgr.org.ua практичные советы, проверенные методики и новинки рынка. Помощь в планировании, выборе подрядчиков и создании идеального пространства.
Архитектурный портал https://skol.if.ua новости архитектуры, современные проекты, градостроительные решения и обзоры мировых трендов.
Информационный портал о ремонте https://stinol.com.ua практичные советы, проверенные методики и новинки рынка. Помощь в планировании, выборе подрядчиков и создании идеального пространства.
Гид по ремонту https://techproduct.com.ua идеи и советы для самостоятельного ремонта: экономичные решения, готовые проекты, обзоры материалов и дизайнерские лайфхаки.
For effective treatment, use ibuprofen ephedrin concerning ED management kit. Free shipping now!
Официальные доступ кракен ссылка быстрый и безопасный доступ к сайту, обходя блокировки и сохраняя полную анонимность пользователей.
Анонимная платформа Kraken market обеспечивает безопасные транзакции, конфиденциальность и доступ к разнообразным товарам.
Кодировка и вывод из запоя на дому https://nashinervy.ru/bez-rubriki/vyvod-iz-zapoya-i-kodirovka-ot-alkogolizma-na-domu-professionalnyj-podhod-k-vosstanovleniyu-zdorovya.html безопасно, эффективно и анонимно. Помощь специалистов 24/7 для возвращения к трезвой жизни в комфортных условиях.
Are there any places where is motrin 800 a blood thinner . Should I stop taking it?
The speed of transactions makes it easy to check the 600 mg gabapentin at consistently low prices
A reliable site allows you to speak to a pharmacist when buying sulfasalazine for colitis in dogs too.
на этом сайте
[url=https://dbshop.ru/catalog/gromkaya_akustika/shirokopolosnaya_akustika/]купить широкополосные динамики для авто[/url]
get cheaper rates.Health benefits are achievable when you buy tegretol et hypertension when you are buying it online.
Find the best no deposit bonus casino canada offers! Explore top-rated casinos with free spins and bonus cash for new players. Start playing without risking your funds.
Автодоставка из Китая https://china-top.ru быстрая и надежная транспортировка товаров. Полный цикл: от оформления документов до доставки на склад клиента.
Смотреть индийские фильмы онлайн https://kinoindia.tv подборка лучших фильмов с уникальным колоритом. Бесплатный доступ и ежедневное обновление каталога.
нажмите здесь
[url=https://dbshop.ru/catalog/koroba_i_aksessuary/stels_koroba_dlya_sabvufera/]стелс короб в крыло автомобиля[/url]
Has your etodolac vidal are small businesses.
Deals for does neurontin help with opiate withdrawal which is online at cheaper prices
Free Online Games game your gateway to a world of free online entertainment! Explore a vast collection of games, from puzzles and card games to action and arcade classics. Play instantly on any device without registration or downloads
воздушная доставка шарики надувные купить
доставка шаров сегодня шарики на заказ с доставкой
You should only carbamazepine tolerance delivered when you order from this site
whoah this weblog is wonderful i love studying your articles. Stay up the great work! You understand, lots of persons are searching around for this information, you could aid them greatly.
сериалы онлайн бесплатно
Some people use the Internet to buy etodolac 400 mg snort online.Easeus Deleted File Recovery – CNET Download. Disk
There are many natural products when you withdrawal from neurontin they are right for you.
Bonus pills added if you celecoxib and sulfa allergy , an effective treatment, at greatly reduced prices
Купить уникальный сувенир в Москве https://podarki-suveniry-vip.ru
Оценка профессиональных рисков https://ocenka-riskov-msk.ru комплексная услуга для выявления, анализа и снижения угроз на рабочем месте.
Наши лифчик для подростка предлагают идеальное сочетание стиля и комфорта. Выберите бюстгальтер без косточек для мягкой поддержки или кружевной бюстгальтер для романтичного образа. Для будущих мам подойдут бюстгальтеры для беременных и бюстгальтеры для кормления. Обратите внимание на бюстгальтер с пуш-ап для эффекта увеличения груди и комфортные бюстгальтеры для повседневного ношения.
sex in wien wien sextreffen
Searching for indomethacin extemporaneous preparation being it is discounted and it treats your medical condition
price options offered by authorized pharmacies before you can mebeverine be taken after food the clear choice?
Take off problems of erection. Follow this link celebrex long term use sold under different brand names.
paying too much for it | All these internet suppliers sell is celecoxib a controlled substance as a successful option.|
Stay home, shop your drugs online and enjoy a low price of how to get generic amitriptyline pill Online pharmaci
see this website https://vivat-publishing.com/2024/06/13/keberuntungan-menanti-di-hoki-slot-168-panduan-untuk-pemain-baru/
Everyone can diclofenac sodium topical gel 1 uses which is online at cheaper prices
paying too much for it | All these internet suppliers sell cilostazol contraindication heart failure is easy.
straight from the source https://98toto0228.com/2024/06/13/keberuntungan-besar-di-big888-slot-menangkan-jackpot-impian-anda/
Предлагаем стекла для спецтехники https://steklo-ufa.ru любых типов и размеров. Прочные, устойчивые к ударам и погодным условиям материалы.
Производство шпона в Москве https://shpon-massiv.ru качественный шпон из натурального дерева для мебели, дверей и отделки. Широкий выбор пород, гибкие размеры и выгодные цены.
Real savings made if you buy on this site. Cheap can you get elavil for sale for an extended period?The lowest prices to
Fix health problems with can i order amitriptyline without insurance is 24/7.
you could try here https://98toto0228.com/2024/06/13/bocoran-slot-rtp-live-rahasia-menang-besar-di-mesin-slot-online/
Инженерные изыскания в Москве https://geology-kaluga.ru точные исследования для строительства и проектирования. Геологические, гидрологические, экологические и геодезические работы для строительства.
Геосинтетические материалы https://geobentomat.ru надежное решение для строительства и укрепления грунтов. Геотекстиль, георешетки, геомембраны и другие материалы для дренажа, армирования и защиты конструкций.
Popular methods to buy diclofenac warnings at low prices always available through this specialist site
Consider various price options before you efeito colateral cilostazol from solid online pharmacies when you need cost-effective
Рекомендую Взломать вк . Проверенные хакеры, которые предоставляют профессиональные услуги.
Hello, you used to write wonderful, but the last several posts have been kinda boring… I miss your tremendous writings. Past few posts are just a little bit out of track! come on!
go to my site https://allslotwallet.org/2024/06/13/login-slot-habanero-panduan-lengkap-untuk-pemain-baru-habanero-slot-login/
Great facts about ED at cost of mestinon online now!
Рекомендую Взломать маил . Проверенные хакеры, которые предоставляют профессиональные услуги.
Torlab.net https://torlab.net новый торрент-трекер для поиска и обмена файлами! Здесь вы найдете фильмы, игры, музыку, софт и многое другое. Быстрая скорость загрузки, удобный интерфейс и активное сообщество. Подключайтесь, делитесь, скачивайте — ваш доступ к миру качественного контента!
Доставка дизельного топлива https://neftegazlogistic.ru в Москве – оперативно и качественно! Поставляем ДТ для автотранспорта, строительной и спецтехники. Гарантия чистоты топлива, выгодные цены и быстрая доставка прямо на объект.
YOURURL.com https://allslotwallet.org/2024/06/13/hobi-188-slot-menjelajahi-dunia-permainan-dan-keseruan-di-setiap-putaran/
the best policyManufacturers make generic drugs available to order imitrex no prescription in our database. Order online today!
Cheap prices for can you buy sumatriptan without prescription and have multiple orgasms?|
https://rxguides.net/guides Explore detailed guides to master your favorite games. From beginner tips to advanced strategies, our guides help you level up, complete challenges, and unlock hidden secrets for the ultimate gaming experience.
Where can I find publications that discuss can i purchase cheap pyridostigmine pills online you should consult your physician.
you could try these out https://tallyhouniforms.com/2024/06/05/mengungkap-rahasia-slot-99-strategi-dan-tips-untuk-meningkatkan-peluang-anda-menang-besar/
The effectiveness of Viagra in ED. where to get generic mestinon pill since it’s a successful treatment
get more https://key-res.com/2024/06/05/keberuntungan-besar-di-toto-slot-777-cara-menang-dan-rahasia-di-balik-mesin-slot/
If I’m taking where can i buy cheap imitrex without insurance pills on this specialist portal
Extravagant offers at where to get sumatriptan prices pills from these pharmacies
Получайте больше прибыли на onexbet, не тратя много времени.
onexbet – ваш путь к успеху, где бы вы ни находились.
Ставки на спорт с onexbet, лучшие условия для игры.
Получите эмоциональный заряд от игры на onexbet, и ваша жизнь никогда не будет прежней.
onexbet – безопасность и конфиденциальность, всегда гарантированы.
Готовы ли вы к большим выигрышам? Вам нужен onexbet, – самый удачный выбор для вас.
onexbet – ваш надежный союзник в мире игры, который всегда придет на помощь.
Onexbet – ваш путь к вершине, добивайтесь успеха вместе с onexbet.
onexbet – это не просто ставки, это стиль жизни, которая помогает вам реализовать себя.
Готовы к большим деньгам и успеху? Попробуйте onexbet, и вы поймете, что все возможно.
onexbet – это не просто игровая платформа, это ваш шанс на успех, который приведет вас к желаемым результатам.
onexbet – это идеальное место для тех, кто ищет азарт и адреналин, но при этом ценит качество и надежность.
Качественные ставки на спорт только на onexbet, все это гарантировано для вас.
Желаете больше азарта и адреналина? Попробуйте onexbet, и вы обязательно останетесь довольны.
onexbet online [url=https://arxbetdsrdg.com/]onexbet online[/url] .
blog https://philosophyandscienceofself-control.com/2024/06/13/keberuntungan-di-rafi-88-slot-menang-besar-atau-pulang-dengan-tangan-kosong/
Торкретирование бетона цена за м2
if you’re looking to start an ecommerce business, consider amazon’s marketplace. create professional product pages with engaging photos and descriptions. use promotional campaigns to drive more traffic and increase brand visibility. follow this guide to learn how to sell on amazon.
our website https://mangoandmoreshop.com/2024/06/13/keberuntungan-berlian-888-slot-petualangan-menang-di-dunia-kasino/
don’t buy all coverage.For men with ED, is where can i get cheap lioresal no prescription is the biggest trend .
Рекомендую https://telegra.ph/Opytnye-hakery-chem-oni-otlichayutsya-ot-novichkov-i-kak-ya-s-nimi-rabotal-12-15-2 . Проверенные хакеры, которые предоставляют профессиональные услуги.
bilan o’yin-kulgi dunyosiga xush kelibsiz https://starvet.uz! 1000 dan ortiq o’yinlar, jonli dilerlar, sport va e-sport bir joyda. Saxiy bonuslar, tezkor depozitlar va qulay pul olish. O’ynang, g’alaba qozoning va yangi his-tuyg’ularga qayting!
Discover the best game codes https://rxguides.net in-depth guides, and updated tier lists for your favorite games! Unlock exclusive rewards, master gameplay strategies, and find the top characters or items to dominate the competition.
advice https://mangoandmoreshop.com/2024/06/13/mimpi-di-balik-mesin-slot-no-1-harapan-dan-kegagalan-di-kasino/
Online pharmacy serves you at how to buy lioresal no prescription . Should I call my doctor?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
helpful resources https://bluevioletbodyworks.com/2024/06/13/keberuntungan-besar-di-slot-naga777-petualangan-seru-di-dunia-perjudian-online/
go to these guys https://bluevioletbodyworks.com/2024/06/13/mantab-slot-petualangan-seru-di-dunia-perjudian-online/
Big discounts on offer for how to buy generic lioresal no prescription at the same prices and discounts?
read the full info here https://haasfoundation.org/2024/06/14/login-panah-4d-slot-cara-mudah-dan-cepat-untuk-bermain-panduan-panah-4d-slot-login/
offers received from reputable pharmacies before you actually can you get lioresal price are much better deals than in local stores.
фільм повністю онлайн uakino.lu
фільм вийшла дивитися онлайн uakino.pl
Achieve health benefits each time you buy cost of lioresal to fill your pet medications.
фільми онлайн 2024 фільми 2024 дивитися онлайн
Online casinos https://taya365casino.app are thousands of slots, live games, profitable promotions and instant wins. Try your luck in a comfortable and safe environment, enjoying the excitement at any time and from any device.
Using the internet, you can find a how to get lioresal for sale dosage isn’t working, should I quit taking the drug?
Откройте для себя инновации с televizoare samsung широкий выбор смартфонов, планшетов, телевизоров и бытовой техники. Выгодные цены, гарантия качества и быстрая доставка. Закажите оригинальную продукцию Samsung прямо сейчас и наслаждайтесь технологиями будущего!
yacht dubai marina price yacht at dubai marina
dubai marina private yacht tour yacht rental dubai
Simply compare online offers to buy how to buy lioresal online . Get one now!
Здесь можно оружейный ящик купитьсейф для ружья
Подробнее
[url=https://mango-offlce.com/]Манго Офис вход[/url]
здесь
[url=https://lk.mangoo-office.com/]Манго Офис голосовая аналитика[/url]
kantorbola99
Самые актуальные новости Украины https://2news.com.ua/ политика, экономика, общество и культура. Только проверенные факты и оперативная подача информации.
Discover the latest codes for mobile games https://game-zoom.ru exclusive codes for Roblox, and detailed guides for games. Stay ahead in your favorite titles with tips, tricks, and rewards to enhance your gaming experience!
Практическое руководство Коновалова https://olsi.ru упражнения и советы для восстановления и укрепления здоровья.
Анализируйте поведение своей аудитории https://bs2site2.net находите точки роста и повышайте конверсии сайта. Поможем вам сделать ваш бизнес эффективнее и увеличить доход.
For Sale: Database of Casino Players in Europe
Are you looking for a way to expand your customer base and increase your business revenue? We have a unique offer for you! We are selling an extensive database of casino players from Europe that will help you attract new clients and improve your marketing strategies.
What does the database include?
• Information on thousands of active casino players, including their preferences, gaming habits, and contact details.
• Data on visit frequency and betting amounts.
• The ability to segment by various criteria for more precise targeting.
The total database contains 2 million players. Data is from 2023. The database is active, and no mailings have been conducted yet.
The price for the entire database is 5000 USDT.
The price for 1 GEO is 700 USDT.
Tier 1 countries.
For any details, please contact me:
Telegram: https://t.me/Cybermoney77
С помощью платформы https://bc2site.gl вы получите доступ к инновационным инструментам, которые помогут преуспеть в онлайн-продвижении. Управление проектами, оптимизация SEO и аналитика — все это доступно на bs2site.
Узнайте свою аудиторию лучше https://bs2saite.gl анализ данных, улучшение опыта пользователей и рост конверсий. Помогаем привлекать клиентов и увеличивать доход.
С сайтом https://bs2site-at.at/ вы можете легко анализировать свою аудиторию, улучшать видимость сайта в поисковых системах и повышать конверсии. Наша команда экспертов гарантирут качественную поддержку и советы для эффективного использования всех инструментов.
эскорт москва на ночь https://vip-eskort-msk.ru
Your article helped me a lot, is there any more related content? Thanks!
Портал для коллекционеров https://ukrcoin.com.ua и ценителей монет и банкнот Украины. Узнайте актуальные цены на редкие украинские монеты, включая копейки, и откройте для себя уникальные экземпляры для своей коллекции. На сайте представлены детальные описания, редкости и советы для нумизматов. Украинские монеты разных периодов и их стоимость – всё это на одном ресурсе!
Юридическое агентство «Актив правовых решений» https://ufalawyer.ru было основано в 2015 году в центре столицы Республики Башкортостан – городе Уфа, командой высококвалифицированных юристов, специализирующихся на вопросах недвижимости, семейном и жилищном праве, а также в спорах исполнения договоров строительного подряда и банкротства физических лиц.
Vnish offers official https://vnish.us firmware for Antminer models S21, T21, S19, T19, and L7. Visit the official Vnish website to boost your mining efficiency by 15-25%.
My Betting Sites India https://bettingblog.tech your guide to the best sports betting sites. Reviews, ratings, bonuses and comparisons. Find the perfect sports betting platform in India!
молодые шлюхи шлюхи города
скачать порно купить меф пятигорск
vavada mirror register in vavada
download official vavada app vavada freespins
смотреть хорошие фильмы без рекламы смотреть фильм
Are there any side effects in taking how to buy generic imdur without prescription than a local store.
Choose the perfect where buy cheap azathioprine tablets pills from several suppliers compared to find the best deal
to get what you needOnline comparison shopping allows you to get cheap imuran price and save the money for other purchases.
Our insulation services https://iepinsulation.com keep your home warm and energy-efficient year-round. We specialize in insulating facades, roofs, floors, and attics using modern materials and techniques. Trust our experienced team for durable, cost-effective solutions that improve comfort and reduce energy bills.
a recommendation from someone you trust before you buy any can you get cheap imdur no prescription pills using this comparative listing
эскорт девушки москва https://vip-eskort-msk.ru
check my source [url=https://play.google.com/store/apps/details?id=com.skinsli]korean skinsli website App on Android[/url]
Steam Desktop Authenticator https://steamdesktopauthenticator.me is a powerful tool designed to enhance the security of your Steam account. By generating time-based one-time passwords, it provides an additional layer of protection against unauthorized access. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
Find effective treatments online everyday with meloxicam bei rГјckenschmerzen after comparing multiple offers
Steam Desktop Authenticator https://steamauthenticator.ru это альтернатива мобильному аутентификатору Steam. Генерация кодов, подтверждение обменов и входов теперь возможны с компьютера. Программа проста в использовании, повышает удобство и позволяет защитить аккаунт, даже если у вас нет доступа к телефону.
Quality is a major concern when you piroxicam and asthma and save your cash.
Steam Desktop Authenticator https://steamauthenticatordesktop.com is an alternative to the mobile authenticator. Generating Steam Guard codes, confirming logins, trades and transactions is now possible directly from your computer. A convenient and secure solution for Steam users who want to simplify their account management.
Steam Desktop Authenticator https://steamdesktopauthenticator.io is a convenient tool for two-factor authentication of Steam via PC. The program generates Steam Guard codes, replacing the mobile authenticator. Easily confirm logins, trades and sales directly from your computer. Increase account security and manage it quickly and conveniently.
Popular methods to buy baclofen and alcohol . Be active!
Where can I find publications that discuss mobic and vicodin affordably to treat your condition
There are ways to para que serve o comprimido meloxicam remain in the blood?
Are men who use search results for piroxicam 0.5 gel so that you can ease symptoms while accessing excellent
the best policyManufacturers make generic drugs available to baclofen for anxiety at reduced prices
And kick your ailments. Guaranteed online proven methods with mobic peptic ulcer on the Internet is always the lowest.
You can easily go online to check the meloxicam 7 5 ratiopharm . Check what best for you.
vavada mirror vavada deposit
Steam Desktop Authenticator https://authenticatorsteam.com is the perfect tool for managing Steam security via PC. It replaces the mobile authenticator, allowing you to generate Steam Guard codes, confirm trades and logins. Ease of use and reliable protection make this program indispensable for every Steam user.
Возможно, вы правы
fakel-nsk-afisha.ru
People look for the cheapest price of piroxicam tablets dose and various payment options when you buy online.
Medical experts agree you should baclofen side effects weight gain at a discount, is there something wrong with the product?
icsee приложение для видеонаблюдения на пк модули видеоаналитики
vms программа для видеонаблюдения скачать программа для видеонаблюдения камера
The sites offer information about the drug and price of can you snort mobic . Get one now!
time you happen to be searching the web for a great remedy, what is teva-meloxicam simply because it is inexpensive and produces results you want
[url=https://xelaui.com]ui kit[/url] – figma Design Kit, ui kit
Manufacturers offer low price of que es el piroxicam is a concern.
The internet is one place to get low price of baclofen dose and prompt ED now! Exciting freebies awaits you.
Achieve health benefits each time you buy ketorolac no prescription generic or brand prices and discounts?
интернет магазин секс игрушек https://sex-hub-kharkov.top
секс шоп онлайн https://sex-hub-kyiv.top
Планируете карьеру или хотите узнать больше о своем рынке труда? На нашем сайте https://zlojnachalnik.ru вы найдете подробную информацию о профессиях, их перспективах и уровнях зарплат. Получите ценную информацию, чтобы сделать осознанный выбор и достичь своих профессиональных целей. Узнайте всё о современных профессиях: от востребованности на рынке до уровня заработной платы.
You’ve made a good decision to rizatriptan farmaco includes information. See the ED natural treatment options.|
When you are looking to zuzahlung maxalt lingua 10 mg makes a trip to the pharmacy a thing of the past. Best meds
[url=https://hyip-helper.net/]Хайп под ключ[/url] – Хайп под ключ, Купить хайп под ключ
is not such a good ideaPeople look for the cheapest price of where can i get toradol no prescription is by comparing prices from pharmacies
Anybody can enjoy low price of get cheap ketorolac pill in the price chart published on this site
[url=https://hyip-helper.net/]скрипты хайпов[/url] – купить хайп проект под ключ, Купить хайп под ключ
Online pharmacy serves you at rizatriptan цена from an online pharmacy?
coverage you have now.Lock in the best deal on maxalt mlt and alcohol at a fraction of the normal cost
Accedez au miroir fonctionnel 888starz pour vos paris en toute securite.
Heat up your body with the newest product of how to buy generic toradol tablets to help eliminate symptoms by securing excellent online
Официальный сайт https://1winpromobk.ru, где вы найдете актуальные промокоды и бонусы для 1Win. Получите эксклюзивные предложения, такие как 500% на первый депозит и бесплатные спины. Присоединяйтесь прямо сейчас, чтобы воспользоваться всеми преимуществами и начать выигрывать!
A common way to save money and can i order generic ketorolac without prescription sold on the Internet have been removed because of safety.
Heat up your body with the newest product of rizatriptan canada including from online pharmacies
[url=https://promagnit.ru/]рекламные магнитики[/url] – изготовление магнитов, магнитики на холодильник на заказ
Buying maxalt rapitab pris for recreational fun?
[url=https://promagnit.ru/]изготовление магнитов[/url] – магнитные закладки с логотипом, производство магнитов на холодильник
more helpful hints [url=https://smmpanel.one]Provider Instagram services[/url]
Перейти на сайт [url=https://vk.com/brows_makeup_kotlas]Перманентный макияж[/url]
сайт слитых курсов сайт со слитыми курсами
здесь [url=https://vk.com/brows_makeup_kotlas]Макияж[/url]
People with low incomes are likely to cyproheptadine while breastfeeding it is necessary to take precautions.
paying too much for it | All these internet suppliers sell periactin for cyclic vomiting syndrome is 24/7.
Какое программное обеспечение https://www.cctvforum.ru для видеонаблюдения является лучшим? Какой сервис видеонаблюдения как услуги (VSaaS) наиболее простой и удобный в использовании?
Лучшие 10 программ https://www.cctvfocus.ru для видеонаблюдения. Программное обеспечение для видеонаблюдения. При выборе программного обеспечения важно учитывать наличие функции обнаружения объектов с использованием искусственного интеллекта.
Five interesting facts about cyproheptadine pronounce misconceptions about online ordering. Don’t be ignorant, read
Bookmark this site for buying periactin liquid form at consistently low prices
нажмите здесь [url=https://vk.com/brows_makeup_kotlas]Татуаж бровей[/url]
Bookmark this portal for buying cyproheptadine muscle for recreational fun?
Real savings made if you buy on this site. Cheap periactin weight gain 2011 are so much better online. Check this out
Read Full Report [url=https://smmpanel.one]Buy Twitter Followers[/url]
yourself familiar with requirements for pharmacies that sell what is cyproheptadine used to treat on the Internet is low as there are no middlemen involved. |
Download online Taya365 app and discover a new level of mobile gaming. Slots, live casino, exclusive bonuses – all this is available on your smartphone. Enjoy the game anytime, anywhere!
Consider various price options before you periactin withdrawal symptoms on the Internet is low as there are no middlemen involved. |
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
you get.Any time you want to cyproheptadine.drugs.com . Check what best for you.
You can save big each time you periactin allergy medicine at cheap prices
Идеальное решение для скрытой связи — купить капсульный микронаушник. Широкий выбор моделей, гарантия качества и выгодные условия покупки. Надёжная связь, компактный размер и удобство использования.
[url=https://grand-kamin.ru/]электрокамины дешево[/url] – биокамины недорого настольные, встроенный электрокамин
сколько стоит гелий стоимость воздушных шаров воздушные шарики
dinnerExcellent health benefits are attainable when you cyproheptadine xanax for an extended period?Check online to find the best place to
deals onlinePeople who can’t afford prescriptions will often periactin gain weight pills on the Internet.
[url=https://grand-kamin.ru/]камин дровяной для дома[/url] – купить камин дровяной, биокамин для дома купить
discounted prices from respectable pharmacies before you cyproheptadine mirtazapine at rock bottom prices
[url=https://www.btc24cash.ru/]Sell a problematic cryptocurrency at a favorable rate[/url] – Without checking aml, Fast cryptocurrency exchange for Stores
you happen to be searching for a successful remedy, you should periactin fda prices. Great savings on all drugs!
Steam Desktop Authenticator https://authenticatorsteam.com is a convenient application for managing two-factor authentication in Steam. Allows you to quickly confirm trades, logins and purchases, providing additional protection for your account.
[url=https://www.btc24cash.ru/]Solve any problems with cryptocurrency[/url] – Dark web Bitcoin Exchange for Pure usdt, They don ‘t care about sanctions, they will withdraw your dirty money
Consumers are aware of low price of cyproheptadine hcl for cats can help you buy it safely online.
Do I need a doctor’s prescription to buy para que es el periactin make sure you handpick the pharmacy.
Durmitor ring black lake Zabljak
greek meaning Bianca Resort and Spa
Treat ED now. More details and recommendations at cyproheptadine other uses directory that lists online pharmacy websites?
for the drugs you need and get a low price of periactin for abdominal migraine . ED drugs come in lower price.
Score exceptional deals when you cyproheptadine side effects cats today.
Looking for big reductions? The prices for periactin belgique from internet suppliers at unbeatably low prices
Официальный сайт https://1winpromobk.ru, где вы найдете актуальные промокоды и бонусы для 1Win. Получите эксклюзивные предложения, такие как 500% на первый депозит и бесплатные спины.
Какое программное обеспечение для видеонаблюдения https://www.cctvforum.ru является лучшим? Какой сервис видеонаблюдения как услуги (VSaaS) наиболее простой и удобный в использовании?
visit this site right here
[url=https://trusteewallet.org/]trust plus[/url]
Может, вы и правы
butirkaconcert.ru
Выберите идеальную коляску 3 в 1 для вашего ребенка, которые обязательно пригодятся.
Топовые модели колясок 3 в 1, с комфортом и безопасностью для малыша.
Как выбрать коляску 3 в 1: полезные советы, для того, чтобы учесть все нюансы.
Что нужно знать при выборе коляски 3 в 1, для безопасной и комфортной поездки.
Сравнение колясок 3 в 1: отзывы и рекомендации, чтобы сделать обдуманный выбор.
balios s lux 3 in 1 [url=https://kolyaska-3-v-1-msk.ru/]https://kolyaska-3-v-1-msk.ru/[/url] .
Looking for drugs at discounted prices? Buy here for good value cyproheptadine purpose with ED treatments?
the best policyManufacturers make generic drugs available to periactin dosage for weight gain Visit today.
Steam Desktop Authenticator steamauthenticator.ru is a convenient application for managing Steam two-factor authentication directly on your PC. It allows you to confirm logins, trades, and purchases without the need for a mobile device.
Steam Desktop Authenticator steamdesktopauthenticator.me is a PC application that makes it easier to use two-factor authentication on Steam. By replacing the mobile authenticator, it allows you to confirm trades, purchases, and account logins, providing a high level of security and ease of use.
Steam Desktop Authenticator steamdesktopauthenticator.io is a simple and reliable way to protect your Steam account. The program allows you to confirm transactions, receive security codes, and manage two-factor authentication settings without relying on your smartphone.
Steam Desktop Authenticator authenticatorsteam.com is an alternative to the Steam Mobile Authenticator. It provides codes for two-factor authentication directly on your PC.
Откройте для себя лучшие недорогие отели в Москве Вас ждут стильные номера, изысканная кухня, современные удобства и внимание к деталям. Отели расположены в ключевых районах города, что делает их идеальными для деловых поездок, романтических выходных или туристических открытий.
Steam Desktop Authenticator steamauthenticatordesktop.com is a handy app to enhance the security of your Steam account. It generates codes for two-factor authentication, allowing you to easily confirm transactions and logins.
possibleYour pharmacists should respect your decision to cyproheptadine ssri will also be low.
Don’t be afraid to ask questions when you are buying periactin to treat vertigo from respected online pharmacies if you’d prefer great deals
Рекомендую – скороварка какую выбрать
Официальная страница диана шурыгина телеграмм. Только здесь вы найдете личные истории, фото, видео и эксклюзивный контент. Узнавайте первыми о новых проектах и наслаждайтесь моментами её жизни. Подписывайтесь, чтобы быть всегда на связи!
курсы красноречия и ораторского искусства курсы по голосу и речи москва
дешевые гелиевые шары сколько стоит гелий стоимость воздушных шаров
Steam Desktop Authenticator https://steamauthenticator.ru is a two-factor authentication application for PC. Generates codes to confirm transactions and log in to Steam, improving the security of your account. Convenient, quick to install and easy to use solution for data protection.
Онлайн слив курсов https://sliv-kursov213.ru простой способ получить знания из популярных онлайн-курсов. Развивайтесь в своем темпе, выбирайте интересующие темы и экономьте на образовании. Здесь вы найдете материалы для саморазвития, карьерного роста и хобби.
Steam Desktop Authenticator https://authenticatorsteam.com is a two-factor authentication application for PC. Generates codes to confirm transactions and log in to Steam, improving the security of your account. Convenient, quick to install and easy to use solution for data protection.
Рекомендую – выбор скороварки
Ресми сайттан 888starz apk ж?ктеп, ?ауіпсіз ойынды баста?ыз.
Рекомендую – скороварки рейтинг
смотреть фильмы бесплатно в США фильмы онлайн HD мелодрамы
лучшие фильмы онлайн мелодрамы лучшие фильмы онлайн детективы
лучшие фильмы 2011 смотреть онлайн фильмы 2024 смотреть онлайн боевики
blog here
[url=https://brd-wallet.io/]bread-wallet[/url]
новинки кино онлайн на телефоне фильмы онлайн HD в HD
яхта на 20 человек яхта в дубае
Download music https://progworld.net in high quality without sound loss. Convenient search, wide choice of genres and artists, fast downloads.
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт ноутбуков lenovo в москве, можете посмотреть на сайте: срочный ремонт ноутбуков lenovo
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
купить аттестат в хабаровске
яхта на 25 человек https://arenda-yahty-dubai.ru
Download music https://progworld.net for free and without registration. Huge database of tracks of all genres in high quality. Convenient search and fast download.
Смотрите аниме онлайн https://reanime.net на русском! Огромная коллекция сериалов и фильмов в хорошем качестве. Все популярные аниме с русской озвучкой и субтитрами. Удобно, бесплатно, в отличном качестве.
anonymous
[url=https://web-counterparty.io/]counterwallet[/url]
Доставка грузов из Китая https://cargotlk.ru под ключ. Организуем перевозки любых объемов: от документов до крупногабаритных грузов. Авиа, морская и автодоставка. Полное сопровождение, таможенное оформление, страхование.
Wow, fantastic blog layout! How long have you been blogging for? you made blogging look easy. The overall look of your site is excellent, let alone the content!
#@G@G@G@G#
https://exploringtemecula.com/wp-content/pgs/utilisez_code_promo_1xbet.html
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
see this here https://toruswallet.org
More Help https://toruswallet.org
Home Page [url=https://toruswallet.org]torus app[/url]
discover this info here https://toruswallet.org
you can find out more [url=https://toruswallet.org]torus labs[/url]
как выиграть в 1win лаки джет 1win
Find Out More [url=https://sites.google.com/mycryptowalletus.com/phantom-walletapp-extension/]phantom Extension[/url]
Интернет-магазин инструментов https://profimaster58.ru для работы по металлу — ваш эксперт в качественном оборудовании! В ассортименте: измерительный инструмент, резцы, сверла, фрезы, пилы и многое другое. Гарантия точности, надежности и выгодных цен.
DocReviews https://docreviews.com.ua это платформа, где пациенты могут оставлять отзывы о врачах. Мы стремимся помочь людям найти лучшего врача для своих нужд, предоставляя им доступную и достоверную информацию.
discover this info here [url=https://sites.google.com/mycryptowalletus.com/phantom-walletapp-extension/]phantom Download[/url]
see post [url=https://sites.google.com/mycryptowalletus.com/metamask-walletapp-extension/]Metamask Extension[/url]
Смотрите аниме онлайн https://studiobanda.net бесплатно и без рекламы. Удобный каталог с популярными тайтлами, новинками и свежими сериями. Высокое качество видео и быстрый плеер обеспечат комфортный просмотр. Подборки по жанрам, рекомендации и регулярные обновления сделают ваш опыт максимально приятным.
школа фигурного катания цена записаться на каток
голая шурыгина https://shuriginadiana.org
check my blog [url=https://sites.google.com/mycryptowalletus.com/phantom-walletapp-extension/]phantom Download[/url]
Официальная страница Дианы Шурыгиной https://t.me/ShuryginaDianaCoin свежие новости, уникальные фото и видео, личные откровения и новые проекты. Погружайтесь в мир Дианы, узнавайте её историю и вдохновение. Будьте в центре её жизни и не пропустите ни одного яркого момента!
https://nestone.uz/assets/pages/?888starz-download-app.html 888starz
Предприниматель и инвестор Святослав Гусев https://dzen.ru/gusevlive специализирующийся на IT, блокчейн-технологиях и венчурном инвестировании. Активно делится аналитикой рынка, инсайдами и новостями, которые помогут заработать каждому!
лучшие фильмы онлайн в 4К лучшие фильмы онлайн комедии
смотреть фильмы бесплатно в Украине фильмы 2015 смотреть онлайн
лучшие фильмы онлайн на планшете фильмы 2014 смотреть онлайн
нові фільми онлайн з українським дубляжем нові фільми онлайн детективи
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Agar siz sportga stavka qilish yoki kazino o‘yinlarida qatnashish imkoniyatidan foydalanmoqchi bo‘lsangiz, unda 888starz stavka ilovasi siz uchun eng yaxshi tanlovdir. Ushbu ilova yuqori darajadagi xavfsizlik va tezkor ishlashni ta’minlaydi. Uni yuklab oling va imkoniyatlaringizni kengaytiring.
купить диплом о среднем образовании в москве
At Cheap SEO Solutions https://cheap-seo-solutions.com we don’t believe in half-measures. We deliver comprehensive SEO solutions that cover all the bases, from keyword research and on-page optimization to link building and content creation. Our goal is to help businesses improve their search engine rankings, drive organic traffic, and increase conversions.
Ставки на спорт с Vavada https://selfiedumps.com это простота, надежность и высокие шансы на победу. Удобная платформа, разнообразие событий и быстрые выплаты делают Vavada идеальным выбором для любителей азарта. Зарегистрируйтесь сейчас и начните выигрывать вместе с нами!
Discover the power of AI with deepnudenow Fast image processing and accessible functionality allow you to create unique effects. Enjoy safe and anonymous use of the platform for entertainment.
top comics 2005 free comic book reader in USA
best manga reading site in USA best manga to read 2015
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
1win withdrawal limit создатель 1win
Emerald flats Montenegro property for sale
index [url=https://phantom-wallet.net]phantom Download[/url]
mostbet promo kod 2023 mostbet aviator signal bot
mostbet promo mostbet партнерка
haus bootssteg kaufen Montenegro immobilie
новинки кино онлайн на компьютере фильмы 2024 смотреть онлайн мелодрамы
Sveti stefan Montenegro Montenegro immobilien kaufen
новинки кино онлайн мелодрамы фильмы 2007 смотреть онлайн
click this [url=https://sites.google.com/mycryptowalletus.com/metamaskwalletapp-extension/]Metamask Extension[/url]
get redirected here [url=https://sites.google.com/mycryptowalletus.com/phantomwalletapp-extension/]phantom Download[/url]
visit the website [url=https://sites.google.com/mycryptowalletus.com/metamaskwalletapp-extension/]MetaMask Download[/url]
find more [url=https://sites.google.com/mycryptowalletus.com/metamask-walletlogin/]Metamask Extension[/url]
Смотрите любимые дорамы https://dorama2025.ru онлайн в HD-качестве! Огромный выбор корейских, китайских, японских и тайваньских сериалов с профессиональной озвучкой и субтитрами.
новости азербайджана сегодня Местные новости и события
онлайн ридер манхвы приключения бесплатно читать манхву онлайн ужасы
1win rocket queen ракетка 1win
андрогенные стероиды метан стероид
application Montenegro company register
Montenegro englisch Montenegro immobilien kaufen
free teleprompter app teleprompter online
Останні новини Черкас https://18000.ck.ua та Черкаської області. Важливі новини про політику, бізнес, спорт, корупцію у владі на сайті 18000 ck.ua.
скачать манхву бесплатно в Казахстане новая манхва читать онлайн в Украине
baosici Montenegro Montenegro immobilien kaufen
[url=https://kgmstrategy.com/]benefits of digital procurement systems[/url] has become our go-to resource for effective procurement management.
Hey There. I found your blog using msn. This is an extremely well written article. I will make sure to bookmark it and come back to read more of your useful info. Thanks for the post. I will definitely comeback.
waldhutte kaufen Montenegro immobilien kaufen
We’ve seen significant improvements after integrating [url=https://arroyostrategy.com]supplier management[/url] into our procurement processes.
Kotor sandstrand immobilien in Montenegro
манхва на русском языке в HD скачать манхву бесплатно фэнтези
The integration of [url=https://kgmstrategy.com/]benefits of digital procurement systems[/url] into our processes has yielded great results.
видеонаблюдения для windows программа видеонаблюдения
Ищете качественные стероиды для роста мышц? У нас вы найдете широкий выбор сертифицированной продукции для набора массы, сушки и улучшения спортивных результатов. Только проверенные бренды, доступные цены и быстрая доставка. Ваше здоровье и успех в спорте – наш приоритет! Заказывайте прямо сейчас!”
манхва на русском языке в США новинки онлайн ридер манхвы
дивитися фільм безкоштовно жахи кращі фільми 2019 онлайн
нові фільми онлайн в Україні фільми 2024 дивитися онлайн у високій якості
взять займ список мфо https://mfo-all.ru
новый слив дианы шурыгиной https://shuriginadiana.ru
новинки фильмы онлайн HD новинки фильмы 2024 смотреть онлайн
Строительный портал https://bastet.com.ua ваш путеводитель в мире стройки! Подборка лучших материалов, контакты мастеров, проекты и лайфхаки. Создавайте уют и красоту с нашим сервисом!
Нужны деньги срочно Займер займ – ваш быстрый выход! Подайте заявку из любого места, получите деньги в течение нескольких минут. Удобно, прозрачно, без скрытых комиссий.
Финансовые трудности? Решите их за минуты займ на карту быстро деньги с моментальным переводом на карту. Оформление онлайн, простые условия и никакого лишнего стресса. Ваш надежный финансовый помощник!
Get the facts https://my-sollet.com
the original source https://web-lumiwallet.com
Откройте для себя лучшие lineage 2 сервера! Интересные рейты, уникальные механики, активная экономика и дружное комьюнити. Сражайтесь с боссами, участвуйте в массовых баталиях и развивайте персонажа. Присоединяйтесь к нам и наслаждайтесь игрой без лагов и с заботой об игроках!
visit our website https://web-lumiwallet.com
Строительный портал https://bms-soft.com.ua для тех, кто строит и ремонтирует! Узнайте о трендах, найдите мастеров, подберите материалы и получите ценные рекомендации.
Biography of Spanish footballer Pedri https://pedri-bd.com statistics at Barcelona, ??games with teammate Gavi, inclusion in the national team for Euro, meme with Cristiano Ronaldo.
Biography of Argentine footballer Paulo Dybala https://paulo-dybala-bd.com personal life, tattoos on the body, wedding with his wife Oriana Sabatini.
[url=http://bs2siite2.at]blacksprut com[/url] – ссылка на блекспрут bs site biz, bs2best at ссылка
Welcome to the Mohamed Salah https://mohamed-salah-en.com fansite! Find out everything about the Liverpool football great and the Egyptian national team. Goals, achievements, stats – it’s all here!
Biography of Dutch footballer xavi-simons-bd.com midfielder for Paris Saint-Germain and the Netherlands national team Xavi Simons. Sports career, playing for RB Leipzig and Barcelona, ??participation in Euro 2024, achievements. Personal life, girlfriend, latest news in 2024.
Team Spirit – 2024 roster https://team-spirit-dota2.com news, match and tournament schedule, statistics, award list, rating, logo.
Execration is a legendary Dota 2 execration dota2 com eSports team that conquers the heights of world eSports with its skill and tactics.
Строительный и архитектурный портал https://intertools.com.ua все самое интересное о строительстве и архитектуре – новости архитектуры и строительства, обзоры и аналитика.
Invictus Gaming is a legendary invictus gaming dota2 esports organization known for its remarkable victories in Dota 2, including the championship at The International 2018.
Latest news http://league-of-legends-esports.com analytics and forecasts in the world of League of Legends eSports. Stay up to date with all the main events of the professional scene!
Official website https://t1-league-of-legends.com of the legendary eSports team T1 for League of Legends. Latest news, match results, player statistics and LOL Betting.
Latest news and analytics on League of Legends lol news matches, tournaments, betting. Stay up to date with the latest eSports events!
Official website of the T1 t1-lol.com League of Legends eSports team. Latest news, matches, statistics, tournaments and predictions on LoL Betting.
Official website of the award-winning samsung galaxy league Samsung Galaxy League of Legends team. Latest news, matches, statistics, player profiles and bets on games.
Official website of the eSports organization g2-esports-league-of-legends.com/
Fnatic is a legendary League fnatic-league-of-legends of Legends eSports team. Our website has all the latest news, matches, player statistics and game predictions.
Official Team Liquid website https://team-liquid-league-of-legends.com latest news, match results, tournaments, player profiles and LOL Betting.
Gen G is one of the strongest eSports teams gen-g-league-of-legends in League of Legends. Our website has the latest news, matches, statistics and LOL Betting.
Dive into the world of Edward Gaming http://edward-gaming-league-of-legends.com the legendary League of Legends eSports team. Latest news, matches, tournaments, statistics and LOL Betting.
Welcome! Find out the latest news dplus-league-of-legends matches, tournaments and statistics of the Dplus team in the League of Legends!
Find out everything about Team WE http://team-we-league-of-legends.com news, matches, player statistics and bets on League of Legends. Support the team!
webcam surveillance software ai security camera software
Натуральные молочные продукты https://gastrodachavselug2.ru свежесть и качество с заботой о вашем здоровье! Широкий выбор: молоко, творог, сметана, сыры. Только натуральные ингредиенты, без консервантов и добавок.
Valorant Esports https://valorant-esports-en.com News, matches, tournaments, awards, game news
Enter the world of Team Falcons team-falcons news, matches, player stats and bets on Valorant. Stay up to date!
Follow Gen.G Esports geng esports valorant com news, matches, tournaments, player stats and betting analytics on Valorant!
Hey I know this is off topic but I was wondering if you knew of any widgets I could add to my blog that automatically tweet my newest twitter updates. I’ve been looking for a plug-in like this for quite some time and was hoping maybe you would have some experience with something like this. Please let me know if you run into anything. I truly enjoy reading your blog and I look forward to your new updates.
https://cleanshop.com.ua/7-professional-headlight-sealing-secrets.html
thc weed in prague cannafood delivery in prague
marijuana shop in prague https://420dayshop.site
kush shop in prague https://shop420prg.site
buy marijuana in prague https://nicebudsshop.site
thc joint for sale in prague weed shop in prague
buy thc vape in prague cannafood in prague
buy cali weed in prague https://shopraha.site
buy cannabis in prague hemp in prague
buy thc chocolate in prague https://pragueshop.site
marijuana in prague 420 movement in prague
Explore Natus Vincere natus-vincere-counter-strike2 com the legendary esports organization excelling in CS2 and beyond. With a legacy of victories and innovative strategies, NAVI inspires millions and defines esports greatness.
Find out the latest news sentinels-valorant matches and statistics of the Sentinels Valorant team. Betting and analytics are waiting for you!
Discover Vitality vitality-counter-strike2 com a leading esports team setting global standards in Counter-Strike 2 and beyond. Explore their innovations, victories, and influence shaping the future of competitive gaming.
Virtus.pro is a professional eSports team https://virtus-pro-counter-strike2.com with a rich history. Known for victories in CS:GO and striving for the top in CS2. Find out about the strategy, roster and future of this legend.
Discover the journey of MOUZ http://mouz-counter-strike2.com a powerhouse in CS2 esports. From tactical mastery to emerging talents, explore their path to glory, innovative gameplay, and unwavering ambition to dominate the scene.
Biography of footballer Kylian Mbappe https://kylian-mbappe-bd.com personal life, rumors of an affair with Alicia Aylis and Ines Rau. Career, statistics and salary at Paris Saint-Germain, victory at the World Cup and other achievements of the striker.
Biography of football player Neymar http://neymar-bd.com personal life, relationships and rumors of romances with Katya Safarova, Natalia Barulich, the birth of a son and Bruna’s last girlfriend, the birth of daughters.
Biography of Belgian footballer kevin de bruyne bd com Kevin De Bruyne (Kevin De Bruyne): personal life, relationship with his wife, conflict with Thibaut Courtois over his girlfriend Caroline.
Biography of football player Luis Alberto Suarez luis-suarez-bd com personal life, daughter, wife, children, height. Leaving the club Atletico Madrid, career in Barcelona and Liverpool, goal statistics.
Biography of football player Jude Bellingham jude-bellingham-bd.com personal life, relationship with girlfriend Laura. Player statistics in the Real Madrid team, matches for the England national team with Harry Kane, the athlete’s salary, conflict with Mason Greenwood.
Try the free demo game Crazy Monkey crazy monkey (Igrosoft) and read our exclusive review!
Hot Fruits 100 Slot hot-fruits-100.com az Review by Amatic Industries – Play Hot Fruits 100 demo for free or real money. Bonuses and best casinos for September 2024!
JetX is a unique simulation game https://jetx.com.az from SmartSoft Gaming. Players fly a virtual plane and collect their winnings safely.
Learn everything about blackjack blackjack rules, types of bets, features of the online game and answers to popular questions.
RB Leipzig rb-leipzig.com.az team history, club titles, top scorers and players in team history
Current Heidenheim fc heidenheim com az squad with player stats and market value, match schedule, club news and rumours
Declan Rice (Arsenal) declan rice midfielder, 25 years old. Check out his biography, statistics, goals and latest 2024 news.
Phil Foden https://phil-foden-az.com is a talented midfielder for Manchester City. Find out about his biography, statistics and latest news.
Разнообразие фурнитуры для плинтуса, найдите идеальный вариант.
Прочные материалы для плинтуса, не подведут вас в эксплуатации.
Легкость сборки плинтуса, для быстрой установки.
Современные решения для отделки плинтуса, подчеркните стиль своего интерьера.
Эко-варианты элементов для плинтуса, для заботы об окружающей среде.
Тренды в оттенках для декора плинтуса, подчеркните цветовую гамму своего интерьера.
Оригинальные решения для отделки плинтуса, сделайте свой дом неповторимым.
Рекомендации по заботе о фурнитуре для плинтуса, для долгосрочного использования.
Креативные решения для отделки плинтуса, выдержите общий стиль в каждой детали.
Фурнитура для плинтуса в классическом стиле, для создания аристократичной атмосферы.
фурнитура купить [url=https://furnituradlyaplintusamsk.ru/]фурнитура купить[/url] .
Yassin Bunu from Al-Hilal yassine bounou az com biography, statistics, news and everything about his career in football.
Thiago Silva thiago-silva-az.com is a legendary defender for Chelsea and the Brazilian national team. On the site you can find a biography, the latest news, statistics, videos and interviews. Learn everything about the career and achievements of the great football player.
Learn about Garrett Bale gareth bale az com his biography, personal life, achievements and the latest news from the world of football.
Everything about Kaka kaka-az.com biography, matches, goals, statistics, photos, videos and the latest news about the football legend on one site!
Everything about Marquinhos marquinhos biography, news, matches, statistics, photos and videos of the best moments. Learn everything about the legendary footballer!
Inter Miami CF inter-miami-az.com/ is a soccer club founded by David Beckham in 2018. The team is committed to succeeding in MLS by attracting star players and developing a youth academy for future success.
Chelsea FC chelsea-az.com news 2024/2025: squad, transfers, calendar, standings, player statistics, results and club achievements.
Atletico Madrid atletico-madrid-az.com is a symbol of passion, resilience and struggle. A club with a rich history, loyal fans and a fighting spirit that inspires both on and off the pitch. Never give up!
Should I worry about buying albendazole tablet how to take about your problem.
Bukalo Saka https://bukayo-saka.com.az is one of the brightest and most promising footballers of his generation. His incredible skill, tactical awareness and strong performance on the pitch have already earned him recognition at Arsenal and the England national team.
Mohamed Salah https://mohamed-salah.com.az is an Egyptian footballer, Liverpool star and a symbol of hope for millions. His achievements on the pitch, his generosity and his loyalty to his roots have made him a national hero and a global football icon.
Jude Bellingham jude bellingham com az is a young English midfielder who has quickly taken world football by storm. Strong, versatile and determined, he has already become a key player for Real Madrid and the England national team.
Erling Haaland erling haaland is a young Norwegian striker who is quickly becoming a star in world football. He is known for his speed, physical strength and phenomenal performance at all levels of the game.
George Best https://george-best.com.az is a brilliant footballer and a shining symbol of the 1960s, known for his talent and turbulent life. He left an indelible mark on football by combining success on the pitch with the tragedy of personal struggle.
Rudy Gobert rudy-gobert-az.com/ is a French center and one of the best defenders in the NBA, nicknamed “The French Tower.” A three-time Defensive Player of the Year, he inspires with his skills and commitment to excellence.
Nikola Jokic https://nikola-jokic-az.com is a Serbian basketball player, NBA star, and leader of the Denver Nuggets. Known for his unique style of play, court vision, and leadership, he has become a role model for a new generation of centers.
Luka Doncic lukadoncic is a Slovenian basketball player, the leader of the Dallas Mavericks team and one of the main stars of the NBA. His unique playing style, records and influence have made him a symbol of European success in world basketball.
Excellent health benefits are attainable when you biaxin price from an online pharmacy?
See incredible savings when you trihexyphenidyl brand name . Purchase orders now!
Popular methods to buy why does clarithromycin cause a metallic taste from one of these pharmacies
Who would mind buying online to get a good price of how to take albendazole for deworming in adults after you compare online offerings
Can you suggest a biaxin allergy icd 10 can be a sexual stimulant for women?
Julius Randle is a versatile NBA forward julius randle a leader for the Knicks, and an inspiring example of perseverance. His play, leadership, and desire to win make him one of the defining figures in the modern league.
Cristiano Ronaldo biography cristiano ronaldo personal life, relationships with Irina Shayk and Georgina Rodriguez, children, career at Real and Juventus, records with Portugal at Euro 2020.
Biography of footballer Mohamed Salah https://mohamed-salah-az.org wife Magi Sadiq, children, charity work, book “The Last Pharaoh”. Statistics, salary and awards with Liverpool and Egypt in 2024.
Biography of footballer Luis Alberto Suarez luis suarez az org personal life, wife, children, height. Departure from Atletico Madrid, career at Barcelona and Liverpool, goal statistics. Playing for Gremio, moving to Inter Miami, retirement from international duty and the latest news in 2024.
Looking for drugs at affordable prices? This site makes low-cost trihexyphenidyl हाइड्रोक्लोराइड गोलियाँ आईपी 2mg remain in the body?
Check out how much you can save on clarithromycin triple therapy from responsible pharmacies online if you desire competitive
When you buy a drug online at low price of albendazole for cattle contains all the details.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Talented Nigerian striker Victor Osimhen victor-osimhen-az.com/ proudly represents Italian club Napoli and the Nigerian national team. This story highlights his remarkable sporting career, personal development and notable achievements, including a loan spell at Galatasaray.
Federico Valverde’s federico-valverde biography: personal life, date of birth, children with Mina Bonino, salary, religion, playing style on the pitch, Real Madrid statistics, salary, number inherited from Kroos, position for 2024 and news.
Biography of Spanish footballer Rodri rodri-az.org Manchester City midfielder, salary, worth, religion, Euro match statistics, champion status and games with Joao Cancelo. Latest updates in 2024.
Biography of Lamine Yamal lamine yamal az com a Spanish winger who plays for FC Barcelona and the national team. Includes career highlights, statistics, Euro 2024 winning salary and personal life.
Biography of LeBron James bronny james son Bronny James. Covers his personal life, family, health issues, NBA draft, and the latest news in 2024.
Frankie de Jong’s biography https://frenkie-de-jong-az.org covers his personal life, height, wife, club stats at Barcelona and Ajax, transfer rumours to Man Utd, playing position and shirt number.
Luka Doncic biography https://luka-doncic-az.com salary, signature shoes, stats, NBA comparisons with Trae Young, games with Jokic and Irving, personal life updates.
Stephen Curry stephen-curry biography: personal life, height, weight, career, team, injuries, three-pointers, LeBron James, statistics, sneakers and 2024 updates.
you can check here https://granbyma.net/2024/06/13/keajaiban-di-balik-viabola-slot-peluang-dan-strategi-menang-besar/
Всё для строительства и ремонта https://artpaint.com.ua на одном портале: советы экспертов, обзоры материалов, расчет сметы и готовые решения для вашего дома или бизнеса.
Портал для строительства https://6may.org и ремонта: полезные советы, современные материалы, проекты и идеи. Все, что нужно для воплощения ваших задумок – от фундамента до крыши.
Студия дизайна интерьера https://bconline.com.ua и архитектуры: создаем уникальные проекты для квартир, домов и коммерческих пространств. Эстетика, функциональность и индивидуальный подход – в каждом решении.
Все об озеленении и благоустройстве https://bathen.rv.ua Ландшафтный дизайн, проекты садов, террас и парков. Идеи для создания зеленых зон, подбор растений и профессиональные услуги для вашего участка.
see it here https://todoprogramas.com/2024/06/13/rahasia-di-balik-rajabandot-slot-petualangan-dan-keberuntungan-di-dunia-judi-online/
купить анаболические стероиды стероиды для набора купить
Разработка и продвижение сайтов https://magikfox.ru в Москве и регионах России от диджитал агентства MagicFox. Лучшие цены на рускрутку. Сделаем продающий сайт на Битрикс и обеспечим высокий уровень продаж.
Ваш путеводитель в мире строительства https://dcsms.uzhgorod.ua идеи, планы, пошаговые инструкции и лучшие материалы. Узнайте, как построить дом мечты или обновить интерьер.
Профессиональный портал для строительства https://blogcamp.com.ua проекты, материалы, расчеты, советы и вдохновение. Все, чтобы ваш ремонт или стройка были успешными.
Your article helped me a lot, is there any more related content? Thanks!
Хотите построить дом https://donbass.org.ua или сделать ремонт? Здесь вы найдете всё: инструкции, идеи, современные технологии и проверенные решения. Портал для тех, кто строит.
Все для строителей и мастеров https://dki.org.ua актуальные технологии, практические советы, строительные материалы и проекты. Простые решения для сложных задач!
Создайте дом своей мечты https://intellectronics.com.ua На нашем портале вы найдете идеи, инструкции и новейшие технологии для ремонта и строительства.
Станьте мастером https://fmsu.org.ua своего дела! Портал для тех, кто хочет строить и ремонтировать качественно и выгодно.
Your Domain Name https://granbyma.net/2024/06/13/panduan-menang-uang4d-slot-tips-dan-trik-terbaik-untuk-pemain-pemula/
read review https://www.vuoksenkalastuspuisto.com/2024/06/13/totomaniac-slot-login-panduan-lengkap-untuk-pemain-baru/
Heya! I’m at work surfing around your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Keep up the great work!
https://millionigrushek.ru/
Архитектура и дизайн интерьера https://it-cifra.com.ua под ключ: современные решения, индивидуальный подход и гармония стиля и функциональности. Создаем пространство вашей мечты!
Найдите все для ремонта https://keravin.com.ua и строительства! Уникальные идеи, пошаговые инструкции и рекомендации специалистов на одном портале.
Стройте с комфортом https://mr.org.ua полезные советы, новейшие технологии, пошаговые инструкции и проекты – всё для вашего удобства.
Мы помогаем строить https://juglans.com.ua лучше! Советы, проекты, новейшие материалы и технологии для вашего ремонта или строительства.
Решили строить или делать ремонт https://msc.com.ua Мы подскажем, как выбрать лучшие материалы, спланировать бюджет и воплотить все задумки.
Строительство без лишних вопросов https://okna-k.com.ua наш портал – кладезь информации о современных материалах, технологиях и лучших решениях для дома, дачи или офиса.
Всё для успешного строительства https://newboard-store.com.ua и ремонта на одном портале! Мы собрали актуальную информацию, идеи и инструкции для вашего удобства. Заходите и стройте с нами!
Все секреты https://mramor.net.ua строительства в одном месте! Советы экспертов, подбор материалов и готовые проекты для вдохновения.
to get what you needOnline comparison shopping allows you to Щ‚Ш±Шµ ШіЩ‚Ш· Ш¬Щ†ЫЊЩ† cytotec 200 online you save money and keep your privacy.
setting up company in montenegro business in Montenegro
Информация о стройке https://purr.org.ua без лишних сложностей! Наш портал поможет выбрать материалы, узнать о технологиях и сделать ваш проект лучше.
how to load bet code on 1win when will 1win token be launched
1win uganda login 1win prediction
review sites personally visit a pharmacy before approving for zantac dosage for infants from respected online pharmacies if you’d prefer great deals
If I take mesalamine dr and save their dollars.
Low price of zantac ranitidine misconceptions about online ordering. Don’t be ignorant, read
Всё, что нужно знать о металлах https://metalprotection.com.ua от их свойств до применения в различных отраслях. Обзоры, советы, новости и информация о производителях для вашего удобства.
Men lost their confidence when ED came. cytotec miscarriage from respected online pharmacies if you’d prefer great deals
Вавада предлагает Vavada betting на любой вкус! Здесь вы найдете ставки на футбол, теннис, баскетбол, киберспорт и многое другое. Широкий выбор событий, удобный интерфейс и выгодные коэффициенты делают платформу идеальной как для новичков, так и для опытных игроков. Начните свой путь в ставках уже сегодня!
Хотите построить дом https://samozahist.org.ua или сделать ремонт? На нашем портале вы найдёте лучшие решения и вдохновение для вашего проекта.
Ищете проверенные строительные советы https://rus3edin.org.ua Наш портал поможет выбрать материалы, спланировать проект и сделать всё на высшем уровне.
Всё о дизайне интерьера https://sculptureproject.org.ua в одном месте! Узнайте, как создать уютное, стильное и функциональное пространство, которое будет радовать каждый день.
производственный контроль программа обучения разработка программы производственного контроля цена
Экспертный строительный портал https://smallbusiness.dp.ua для вашего проекта! Советы, новинки и инструкции для тех, кто хочет сделать всё идеально.
Хотите стильный интерьер https://sitetime.kiev.ua Наш портал предлагает уникальные идеи, профессиональные рекомендации и примеры лучших дизайн-проектов.
Take the time to shop around when you want to zantac diarrhea from internet suppliers at unbeatably low prices
Some pharmacies give free consultation when you when is the best time to take mesalamine at discounted prices
Get the facts on all medicines when you is ranitidine back on the market 2023 brand and generic product?.
Many Internet pharmacies where you cytotec side effects induction delivered in days to give you essential treatment
голубой топаз цена https://bluetopaz.ru/
топаз белый прозрачный https://whitetopaz.ru/
Найдите всё о строительстве https://srk.kiev.ua и ремонте на нашем портале. Полезные статьи, актуальные технологии и лучшие практики ждут вас.
Преобразите ваш дом https://vineyardartdecor.com вместе с нами! На портале вы найдёте свежие идеи, советы по планировке и материалы для создания идеального интерьера.
Планируете стройку https://texha.com.ua или ремонт? У нас вы найдёте проверенных специалистов, инструкции, материалы и проекты на любой вкус. Всё для комфортного строительства!
Всё о строительстве https://valkbolos.com и ремонте на одном портале! Гид по материалам, обзор инструментов, советы по дизайну и подбор подрядчиков. Создавайте дом своей мечты!
[url=https://bbqate.com/]BBGate Free Sample[/url] – bbgate forum, bb
Most online stores will guarantee you the brand name for ranitidine with ED treatments?
Read on zantac 300 mg at incredibly low prices when you purchase from discount
What’s the difference between a mesalamine generic , will my partner have any negative feelings?
For the best deals, buy cytotec contractions pills through this specialist low-cost site
голубой топаз https://bluetopaz.ru/
Планируете ремонт или строительство https://vodocar.com.ua У нас всё, что нужно: от инструкций и советов до подрядчиков и обзоров материалов. Стройте с нами!
Лучшие советы по строительству https://stroysam.kyiv.ua и ремонту на одном сайте! Найдите вдохновение, изучите обзоры и воплотите свои идеи с профессиональной помощью.
топаз белого цвета https://whitetopaz.ru/
Полный справочник по строительству https://stroy-portal.kyiv.ua и ремонту: советы, инструкции, дизайн-решения и помощь с выбором материалов и подрядчиков.
Ваш гид в мире строительства https://vitamax.dp.ua и ремонта! Обзоры, практические советы, дизайн-идеи и подбор профессионалов для реализации любых проектов.
Good pharmacies offer discounts when you ranitidine dose for adults pills from several suppliers compared to find the best deal
Choose the perfect cytotec price and prompt ED now! Exciting freebies awaits you.
Простые решения для ремонта https://teplo.zt.ua и строительства! Идеи дизайна, рекомендации экспертов и проверенные материалы для вашего проекта.
Стройте и ремонтируйте https://suli-company.org.ua с лёгкостью! Полезные статьи, инструкции, советы по выбору материалов и подрядчиков ждут вас здесь.
Портал о ремонте и строительстве https://buildingtips.kyiv.ua с полезными статьями, рекомендациями по выбору материалов и подрядчиков.
Полный гид по строительству https://tsentralnyi.volyn.ua и ремонту: от планирования до отделки. Читайте, выбирайте и стройте с уверенностью и комфортом.
Get the facts on all medicines when you zantac rebate to start feeling better
Are there any side effects in taking mesalamine dosage from reputable pharmacies
Полный гид по строительству https://tsentralnyi.volyn.ua и ремонту: от планирования до отделки. Читайте, выбирайте и стройте с уверенностью и комфортом.
ggdrop стандофф промокод на ggdrop на пополнение
Tormac.org https://tormac.org – это специализированный торрент-трекер, предназначенный для пользователей Mac-компьютеров. Сайт предоставляет широкий выбор контента, ориентированного на операционные системы macOS и iOS.
Приветствую на https://b2best.at! Мы предлагаем надежные и проверенные покупки в интернете. Ознакомьтесь с нашими статьями о безопасности и легальности. Ваши покупки — наш приоритет!
When seeking a highly effective remedy, you always want to recall on ranitidine remain in the blood?
Online pharmacy serves you at oral cytotec is so much less that people prefer to shop online.
A detailed history https://inter-milan-az.com of the Italian football club Inter Milan. From their first Scudetto to their Champions League victory.
Choose the lowest price of zantac dosage for dogs at budget prices keep your medical costs affordable. Buy here
mostbet скачать на андроид бесплатно mostbet minimum deposit
mostbet скачать iphone mostbet mexico
1win original букмекерская контора 1win
Go to lialda mesalamine many more details.
MLB Draft Betting https://bettingblog.website Your guide to the world of MLB draft betting. Expert predictions, top odds and detailed analysis will help you increase your chances of success. Bet and win with us!
Best Forex Trading Course https://blogforex.tech is your key to successful trading. Learn the secrets of professionals, study strategies and learn how to minimize risks. Master Forex easily and effectively!
Credit Union Mobile Home Loans https://blogcredit.tech are the perfect solution for buying or refinancing a mobile home. Affordable rates, easy application, and reliable support every step of the way. Take the first step toward your home with us!
Tennis betting https://yourmoneyblog.site best odds, predictions and analytics. Explore detailed match reviews, statistics and strategies to make successful bets. Use our tips and win!
[url=https://kra020.shop]kraken маркетплейс[/url] – https kraken20 at не работает, маркетплейс кракен kraken
Buying ranitidine near me in our database. Order online today!
Federal Gov Open Enrollment https://body-balance.online is your chance to upgrade or choose an insurance plan. Easy navigation, expert support, and a wide range of programs will help you make the right choice. Apply now!
Consider first-rate online pharmacies the moment you decide to cytotec pregnancy category can be a sexual stimulant for women?
Crypto Funk https://besttodaynew.com is a fresh look at cryptocurrencies. News, trends, guides and analytics for beginners and professionals. Find out how to get the most out of blockchain technology!
VIPPS checks pharmacies for proper storage of their zantac and pregnancy for your prescription.
Shop around from home for all the reduced price rectal mesalamine shipped to your door in low-cost high-value deal
Shop around from home for all the reduced price famotidine ranitidine drug allow for multiple orgasms?
You can save big each time you cytotec misoprostol 200 mcg uses include comparing prices from online pharmacies
программа производственного контроля санитарных норм программа производственного контроля качества
Home Equity Loans https://funnydays1.com How They Work, What Are the Terms and Benefits? Get the full details on how to use your home’s value for financial purposes. Find out more today!
Auto loans from Community Credit Union https://sunnydays100.com are simple, affordable, and great value. Low interest rates and flexible repayment options make it easy to buy a new or used car.
Credit score requirements for FHA loans https://lifeofnews1.com minimum threshold and tips for improving. Find out how to increase your chances of getting a loan, as well as what affects approval. Detailed information for those who want to get a mortgage through FHA.
No Credit Check Loans in Abilene TX https://daynewday1.com is fast access to money without unnecessary checks. Convenient terms, simple application and instant approval. Get financial help when you need it!
Steve Rogers kapitan-amerika bravely fought the Nazis until a tragic accident left him frozen in the Arctic ice for years.
Kevin Durant biography kevin-durant-az org personal life, relationships, height, weight, shoe size and 2024 NBA statistics with the Brooklyn Nets.
Kyrie Irving’s kyrie-irving-az com biography covers his personal life, height, flat-footedness, injuries, Muslim faith, vaccination stance, Boston Celtics stats, plus Nike shoes. Latest news for 2024.
Rafael Nadal rafael-nadal-az.com/ date and place of birth, height, career highlights, childhood, tennis results, ATP rankings, records, injuries, Australian Open defeat, return to tournaments, career summary and latest news in 2024.
Biography of American basketball legend Michael Jordan http://michael-jordan-az.org personal life, participation in the Monaco Champions League match, film projects, marriage to Yvette Prieto, parenthood, net worth and collaboration with Michael Jackson. Latest updates in 2024.
Dive into the exciting gaming world of taya365 app login! Endless selection of games, fast withdrawals and fair play – everything for your pleasure.
Daniil Medvedev biography daniil-medvedev-az com personal life, wife and child. His tennis tournaments, matches against Nadal and Djokovic and becoming world number 1. Loss of top spot, Australian Open and latest news in 2024.
Biography of Roy Jones Jr. http://roy-jones-az.org How he became the first boxer to win the middleweight, super middleweight, super heavyweight and super heavyweight titles. Known for his explosive style, like Mike Tyson.
A proven way to will macrobid side effects go away pills side-by-side on this site
Алкоголь подарочная https://giftbox-3.ru упаковка оптом и упаковочная бумага в коробку в Новосибирске.
Are there harmful side effects if I take misoprostol cvs precio , will my partner have any negative feelings?
Try your luck at taya365 app login, where excitement meets reliability! Hundreds of popular games, unique promotions and instant payouts await you.
THC chocolate shop in Prague buy Cali weed in Prague
buy Cannafood in Prague Cali weed in Prague
[url=https://fermacc.org/]купить эфириум[/url] – ferma cc, обменять eth
Paolo Maldini’s biography paolo-maldini photo, defender 2019, personal life, Instagram, Milan, salary, religion and news.
Biography of Spanish footballer Xavi Hernandez xavi hernandez coaching career, Barcelona statistics, matches with Iniesta and Messi, Guardiola’s influence, goals, youth training, dismissal as Barcelona coach, personal life and 2024 updates.
Biography of football legend Pele pele personal life, ex-spouses, children and current wife Maria Aoki. A reminder of his legendary career, goals and special style of play, as well as successful performances in the national team.
Discover the life of Sergio Busquets sergio-busquets-az.org his parents, his partner Elena Galera Moron, his sons, his club career, his achievements with Spain and the latest news for 2024.
Biography of Brazilian footballer Ronaldinho ronaldinho personal life, son’s contract, current position. Club career, free kick goals, dribbling, jersey number, Ballon d’Or award, prison sentence. Latest news of 2024.
Biography of Spanish footballer jordi-alba-az.org Jordi Alba: Left back for Barcelona and the Spanish national team, trained at the academies of Barcelona and Valencia.
Biography of Portuguese footballer Joao Felix joao felix az com personal life, relationship with his girlfriend, resemblance to Kaka, national team appearances with Cristiano Ronaldo, club statistics, salary and latest news in 2024.
Biography of footballer casemiro-az org Casemiro: personal life, wife and children. Career, statistics, salary at Real Madrid, Brazil national team, transfer fee, position, transfer to Manchester United and the latest news for 2024.
Welcome to the fan site memphis-depay dedicated to the active Dutch footballer Memphis Depay, his career path with clubs and the Dutch national team. Tattoos, personal life and news.
[url=https://fermacc.org/]обменять тон[/url] – купить usdt, купить ltc
download manga Attack on Titan free online popular manga Berserk free online
Always come here first for macrobid with alcohol sold with amazing discounts by a specialist site
Pay better prices to mifepristona y misoprostol pills to your home when buying through this site
別再被詐騙黑網騙了!3A最新娛樂城體驗金提供所有線上娛樂城的最新動向
By 3ACasino / December 17, 2024
隨著線上娛樂城的興起,越來越多的玩家選擇在網上娛樂平台上娛樂、賭博,並享受多元化的遊戲體驗。無論是體育賭博、老虎機還是各種賽事投注,線上3a娛樂城都提供了豐富的選擇。然而,隨著線上平台的繁榮,也伴隨著詐騙和不安全平台的風險。如何分辨正規可靠的娛樂城,並避免被詐騙或陷入黑網的陷阱,是每一位玩家必須謹慎對待的問題。
本文將為您介紹線上娛樂城的基本資訊,並提供一些有效的辨識技巧,幫助您避免進入詐騙的黑網,同時介紹3A娛樂城如何為玩家提供最新的娛樂城動向,讓您玩得安心、玩得開心。
一、線上3a娛樂城官網的發展與現狀
隨著科技的進步和網絡的普及,線上3a娛樂城逐漸成為了全球賭博行業的重要一環。這些平台讓玩家可以在家中舒適的環境中進行各種賭博活動,無需親自到賭場,隨時隨地享受賭博樂趣。
多元化的遊戲選擇
目前,線上娛樂城提供的遊戲種類非常豐富,包括老虎機、撲克、賓果、輪盤、21點、體育賭博等各式各樣的選項。玩家可以根據自己的興趣選擇不同的遊戲,並參與到全球賭博市場的競爭中。
技術創新
隨著虛擬現實(VR)技術、人工智慧(AI)等技術的發展,許多娛樂城平台也在不斷創新,提升玩家的體驗。例如,利用VR技術打造身臨其境的賭博環境,讓玩家仿佛置身於真實的賭場;而AI技術則被用於提高遊戲的公平性和精確性。
移動設備支持
隨著智能手機和平板電腦的普及,許多線上3a娛樂城也推出了移動版本,使得玩家可以隨時隨地享受娛樂遊戲。不僅如此,這些平台還推出了適合不同操作系統(如iOS、Android)的應用程式,讓遊戲體驗更加便捷和流暢。
二、線上3a娛樂城官網的詐騙風險
儘管線上娛樂城提供了許多便利和娛樂選擇,但隨著市場的擴大,一些不法分子也進駐其中,利用各種詐騙手段來侵害玩家的利益。這些詐騙黑網的特點通常表現為以下幾個方面:
假網站與假平台
詐騙網站往往以低廉的優惠和豪華的宣傳吸引玩家上鉤,這些網站的設計和操作界面看起來非常專業,但實際上它們並沒有真正的運營許可證。玩家將個人資料和資金投入這些平台後,會發現自己無法提現或賺取的金額被無故凍結。
誘人的獎金和優惠
詐騙平台常常通過推出不切實際的“首存大獎”或“免費彩金”等優惠來吸引玩家,並誘使玩家進行大量投注。這些優惠通常都附帶不合理的條件,並在玩家達不到要求時取消所有贈金,甚至使玩家的存款受到影響。
遊戲不公平與結果操控
部分不法娛樂城會使用作弊手段操控遊戲結果,尤其是老虎機、輪盤等隨機遊戲,玩家在這些平台上的每次投注都無法得到公平對待,從而產生不合理的損失。
不清楚的賭博條款與隱藏費用
許多不正規的娛樂城平台會將一些不明確或隱藏的條款添加到賭博合約中。這些條款可能涉及到存款、取款或遊戲的條件,使玩家無法順利提現,甚至可能被扣除不明費用。
三、如何識別正規3a娛樂城官網?
要避免進入詐騙黑網,首先要學會如何識別正規的3a娛樂城。以下是幾個辨別真偽的關鍵指標:
合法授權與運營許可證
正規的娛樂城平台會擁有合法的運營許可證,這些證書一般來自於知名的賭博監管機構,如英國賭博委員會(UKGC)、馬耳他博彩局(MGA)等。玩家可以在平台的底部或關於我們的頁面查看這些資訊,以確保該平台的合法性。
使用加密技術保障安全
正規平台會採用最新的SSL加密技術來保護玩家的個人資訊和資金安全。玩家可以在平台網址欄查看是否以“https”開頭,並且確認網頁上的支付方式是安全的。
透明的支付與提款政策
正規娛樂城會提供清晰明確的存款和提款流程,並且在玩家要求提款時不會無理拖延。平台的條款和條件應該是簡單且易於理解的,沒有隱藏費用。
客戶服務與口碑
正規3a娛樂城會提供全天候的客戶服務支持,並能迅速解答玩家的問題。玩家可以查看該平台的用戶評價與口碑,了解其他玩家的真實經驗。
四、3a娛樂城官網:為玩家提供最新的娛樂城動向
作為專業的線上娛樂平台,3A娛樂城致力於為玩家提供全面的娛樂資訊,並協助玩家避開詐騙黑網。我們提供以下幾項服務:
實時更新娛樂城資訊
3A娛樂城會定期更新最新的線上3a娛樂城動向,包括合法平台的推薦、遊戲的評測、賭博行業的動態等,讓玩家能夠隨時掌握市場變化。
專業的遊戲分析與技巧分享
我們的專業團隊會分享各種遊戲技巧、策略與賠率分析,幫助玩家提高遊戲的勝率。同時,還會提供對熱門遊戲的深入剖析,讓玩家能夠更好地理解遊戲規則,避免上當受騙。
安全保障與信譽保證
3A娛樂城嚴格篩選合作平台,所有推薦的娛樂城都經過嚴格審查,保證其合法性和安全性。玩家可以放心選擇平台進行遊戲,享受公正、安全的賭博體驗。
專業的客戶服務
我們提供全天候的客戶服務,隨時解答玩家在遊戲過程中的問題,並提供專業的遊戲指導與問題解決方案。
隨著線上娛樂城市場的發展,選擇一個安全、合法、可靠的娛樂平台對於每位玩家來說至關重要。避免被詐騙黑網騙取資金,保持理智並選擇正規的3a娛樂城,是享受線上賭博娛樂的基本前提。3A娛樂城作為領先的娛樂平台,將繼續為玩家提供最新的娛樂城動向和專業的遊戲資訊,幫助您在安全、公正的環境中享受遊戲樂趣。
https://aaawin88.org/3acasino/
When looking to antibiotic macrobid in the price chart published on this site
If a pharmacy offers misoprostol induction of labor you can save dollars.
taya 365 casino login taya 365
James Rodriguez james-rodriguez-az.org/ biography: personal life, latest news, Instagram, goals, transfer to Rayo Vallecano, statistics and captain of the Colombian national team.
taya365 login taya 365 login
Nicholas Jackson nicolas-jackson-az com is a Senegalese professional footballer who has taken the football world by storm with his play and achievements.
Biography Pau Victor https://pau-victor-az.org is a Spanish footballer who started in the lower divisions. Thanks to hard work, he got into a good youth team at FC Barcelona. He played for Girona and has good statistics.
Biography of Jamie Bynoe-Gittens jamie-gittens-az.org/ a winger for German club Borussia Dortmund, and an English footballer.
When Huseyin and Naime hakan calhanoglu welcomed their son Hakan to Monchengladbach, Germany, during the 1994 World Cup, they had no idea he was destined to become a star. Learn his biography, facts and news.
Biography of Dominik Szoboszlai dominik-szoboszlai-az org a Hungarian footballer, midfielder for Liverpool and captain of the Hungarian national team.
Phil Foden Biography phil-foden-az.org/ A look at his personal life, relationship with Rebecca and the birth of his sons and daughters.
Biography of Ollie Watkins ollie-watkins-az org an English striker for Aston Villa and the England national team. Find out about his career, clubs such as Exeter City and Brentford, height, age, achievements, participation in Euro 2024, personal life and latest news.
Francisco Conceicao https://francisco-conceicao-az.org was born into a family where football was already a part of the family, with a legacy built on hard work and passion. Juventus, Porto and Portugal national team appearances, brother Rodrigo, FIFA stats and news.
Check expiration dates when you how long for macrobid to work for uti only after you have looked at competitive online specials
How long does misoprostol vaginal is a concern.
Biography of Austrian jorginho footballer Arnautovic Marko – games at FC Werder Bremen and Internationale, market value, achievements. Personal life, conflicts, rumors and latest news.
Biography of Austrian footballer marko-arnautovic Arnautovic Marko – games at FC Werder Bremen and Internationale, market value, achievements. Personal life, conflicts, rumors and latest news.
Biography of Federico Chiesa https://federico-chiesa-az.org Italian winger for Juventus and the Italian national team. Career, Fiorentina, Euro 2024, transfer to Liverpool, family, wife Lucia Bramanti.
Aurelien Tchouameni’s aurelien-tchouameni-az.org/ biography: personal life, date of birth, parents’ jobs, statistics at Real Madrid and Monaco, position, jersey number, 2024 updates.
Biography of Dayot Upamecano dayot-upamecano-az org Bayern star, France national team hero, early career start, Euro play-off participation, personal life and football news for 2025.
Biography of football player antoine-griezmann-az.com/ Antoine Griezmann: personal life, birth of children, national origin. Now his career, playing for Atletico Madrid.
Biography of Portuguese bernardo silva az com footballer Bernardo Silva: personal life, relationship with his wife, similarities with Bruno Fernandes. Current team, number on the field, reviews of fans who have sold out.
Biography of Brazilian football player Rodrigo https://rodrygo-az.com photos of the striker of the Real Madrid club and the Brazilian national team, sports career.
Biography of Spanish http://pedri-az.com footballer Pedri, statistics at Barcelona, ??games with teammate Gavi, joining the national team for the Euros.
Biography of Brazilian alisson-becker-az.com footballer Alisson: photo of the goalkeeper of the Liverpool club and the national team, sports career, playing for FC Inter and Roma, growth, achievements.
[url=https://alt-coins.cc]Альткоин обменник крипты[/url] – Альткоин обменник крипты, Альткоин бестчейдж
The effectiveness of Viagra in ED. macrobid dose for uti from responsible pharmacies online if you desire competitive
Online pharmacy serves you at misoprostol vaginally at decreased prices
Нужен ремонт техники чинпочин.рус все услуги для вашего дома в одном месте! Выбирайте мастеров для ремонта, уборки или сантехнических работ. Качественный сервис, прозрачные цены и удобство использования.
Tobey Maguire’s http://tobey-maguire-az.com biography: personal life, memories of him, friendship with Leonardo DiCaprio, divorce from ex-wife. Role in Spider-Man films, career now.
Biography of footballer https://iker-casillas-az.com Iker Casillas: personal life, separation from ex-wife Sara Carbonero.
Biography of Spanish footballer Dani Carvajal dani carvajal personal life, marriage to Joselu and twin sisters. Performances at the Euro for Real Madrid and the Spanish national team.
Biography of actor Keanu Reeves keanu reeves personal life, the tragic death of his child and his relationship with his common-law wife Jennifer Syme, artist Alexandra Grant.
Biography of actor http://liam-neeson-az.com Liam Neeson: personal life, death of his wife Natasha Richardson, children. Star roles in films, starring roles in the drama “Schindler’s List”.
FTP Text Document Editors Software CCTV Vertical Market Apps
Affordable prices can be found to does macrobid cause yeast infections from sites that don’t post info about their company.
Don’t buy from sites that say their how misoprostol works at cost-effective prices when you get it from good online
whoah this weblog is great i really like studying your posts. Stay up the good work! You realize, lots of persons are searching around for this information, you could aid them greatly.
is important to find the best prices as soon as you decide to macrobid antibiotic class website is licensed to sell products?
quotes is finding better ratesHow can I decide between possible misoprostol postpartum hemorrhage at lower prices
Excellent prices can be found when you use online discounts to macrobid for uti side effects sold with amazing discounts by a specialist site
Can I expect to take misoprostol for abortion first trimester pills from several suppliers compared to find the best deal
Biography of Zendaya Coleman zendaya-maree (Zendaya): modeling career, music and cinema, details of her personal life, ex-boyfriend Jacob Elordi, romance with Tom Holland.
Now you can’t find a person formula1-az com who hasn’t heard of Formula 1. Today it is one of the most prestigious and popular sports on the planet.
Welcome to the main page karim-benzema of the fansite dedicated to the world football star Karim Benzema. Learn all about his incredible career, incredible achievements and phenomenal skills.
Welcome to the world of Neymar https://neymar-azerbaycan.com a fan site dedicated to the great footballer. Learn all about his career, achievements and unique playing style.
Biography of British actress emily-blunt Emily Blunt: personal life, dating and relationship with her husband John Krasinski, raising children.
check here https://jaxx-wallet.net/
Welcome to the most exciting inter-miami-azerbaijan.com/ Inter Miami FC fansite! Join us and share the passion for this dynamic team.
Welcome to Laure Boulleau’s fansite laure-boulleau-azerbaijan com Here you can find everything about the great footballer: news, statistics, photos and more. Immerse yourself in the world of her creativity!
Biography of actress anya-taylor-joy-az.com/ Anya Taylor-Joy: personal life, wedding with Malcolm McRae, husband, relationship with parents. Filmography, roles in films and TV series “The Witch”, “The Queen’s Walk”, new projects and the latest news for 2024.
Biography of actress Anya Taylor-Joy https://anya-taylor-joy-az.com personal life, wedding with Malcolm McRae, husband, relationship with parents. Filmography, roles in films and TV series “The Witch”, “The Queen’s Walk”, new projects and the latest news for 2024.
Erling Haaland erling-haaland-azerbaijan.com/ all personal trophies and awards. Erling Haaland – biography of the striker on the football field of Manchester City and the Norwegian national team.
Discover the world of Belgian kevin-de-bruyne-azerbaijan com midfield maestro Kevin De Bruyne, known for his unparalleled playmaking skills.
Welcome to the Stephen Curry http://stephen-curry-azerbaycan.com fan site! Learn about his greatness and inspiring success story.
Join the Pedri Fan Hub https://pedri-azerbaijan.com dedicated to celebrating the meteoric rise of this young football star. Explore exclusive content, updates and lively discussions about Pedri’s journey from humble beginnings to becoming a regular for Barcelona and the Spanish national team.
Angel Di Maria http://angel-di-maria-azerbaijan.com He is an Argentine footballer who has had a successful career in European football clubs. He defends the honor of the country in international tournaments.
скупка золота 585 скупка золота на лом цена за грамм
Welcome to the fan site moussa dembele of the talented footballer and real star Moussa Dembele! Here you will find everything new and most interesting about his career, achievements and amazing moments on the field.
People realized that by searching for macrobid headache on the Internet is always the lowest.
check this link right here now https://web-freewallet.com
Best deals in town. Learn how to order what does misoprostol do to the uterus . Get one now!
ломбард скупка золота цена за грамм скупка золота цена
Оперативная помощь на дороге https://angeldorog.by/tsena-na-evakuator/ услуги эвакуатора, грузовой и легковой шиномонтаж, а также грузоперевозки фурами по доступным ценам. Работаем круглосуточно, быстро реагируем и гарантируем надежность. Звоните в любое время – решим вашу проблему!
Camera VMS Nanny cam software
Discover the ultimate hub https://zinedine-zidane-azerbaijan.com for all things Zinedine Zidane. Dive into in-depth analysis of Zidane’s illustrious career, from his legendary performances to his coaching triumphs.
Find out all about Kylie Jenner https://kylie-jenner-azerbaijan.com at Kylie Jenner, the ultimate fan site for the latest updates on her fashion line, beauty tips and personal life.
There is no need to spend a lot of cash when you can macrobid for sinus infection . ED problems quickly resolved!
Choose authentic online pharmacies any time you intend to misoprostol iud insertion pills using this comparative listing
bc game
blog https://jaxx-liberty.com/
Find Out More https://web-freewallet.com/
Immerse yourself in the world of Gigi Hadid https://gigi-hadid-azerbaijan.com through our dedicated website. Explore the latest news, highlights, exclusive interviews and in-depth features about her fashion endeavors, personal life and charitable efforts.
Biography of American professional gervonta-davis boxer Gervonta Davis: career highlights, weight, records, famous fights, personal life, controversies and latest 2024 updates.
Discover the world of Brad Pitt brad-pitt with our dedicated website, offering extensive coverage of his illustrious career, upcoming projects, and personal endeavors.
tesla for rent https://electrodrive.si
У нас вы можете купить айфоны https://vk.com/crazy_humor01 оптом по самым лучшим ценам. Оригинальные смартфоны Apple с гарантией качества. Постоянное наличие популярных моделей.
1Win crash-game Aviator
their website https://web-freewallet.com
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Квартирный переезд https://spb-gruzoperevozka.ru с грузчиками быстро и качественно! Упакуем, вынесем, перевезем и разместим вещи на новом месте. Надежная команда, аккуратность и доступные тарифы.
переговорный стол на 6 человек https://mm26.ru
переговорные столы офисные https://mm26.ru
Looking for a is macrobid a strong antibiotic will be correct when you buy it online.
Whenever you pastilla misoprostol remain in the body?
Откройте для себя последние kraftsir.ru/ новости, аналитику и экспертные обзоры о спорте и ставках. Узнайте о лучших стратегиях ставок, следите за актуальными событиями в мире спорта и получите все необходимые инструменты для успешных ставок.
Investigate CS2 Skins: Find Your Ideal Match
Alter Your Experience
Display your uniqueness in Counter-Strike 2 (CS2) with special weapon skins. Our store provides a diverse selection, from scarce to limited-edition styles, enabling you to showcase your style and enhance your gameplay.
Simple and Safe Purchasing
Appreciate a flawless shopping journey with rapid digital delivery, ensuring your newly purchased skins are instantly available. Shop securely with our secure checkout process, whether you’re seeking budget options or high-quality designs.
How It Works
1. Explore the Range: Investigate a vast variety of CS2 skins, organized by exclusivity, arms type, or design.
2. Select Your Skin: Add your ideal skin to your cart and proceed to checkout.
3. Fit Your New Skins: Immediately receive and use your skins in-game to shine during matches.
Cost-effective Tailoring
Personalization should be available for every player. We regularly offer deals on CS2 skins, providing top-tier designs obtainable at reasonable prices.
Featured Designs
– P250 | Nuclear Threat (Factory New) – 3150 €
– Desert Eagle | Hand Cannon (Minimal Wear) – 450 €
– StatTrak™ P2000 | Ocean Foam (Factory New) – 285.88 €
– Glock-18 | Synth Leaf (Field-Tested) – 305 €
Embark on Your Shopping Experience Today!
Improve your gameplay with our outstanding range of CS2 skins. Whether upgrading your weapons or creating a unique collection, our store is your destination for premium skins. Elevate your gaming adventure today!
киного исторические сериалы kinogo смотреть онлайн
kinogo фильмы про вампиров kinogo фильмы для взрослых
киного фильмы по рейтингу kinogo короткометражные фильмы
kinogo сериалы по популярности kinogo фильмы для двоих
Enjoy effective treatment when you macrobid and yeast infection at a cheaper price?
Internet drugstores list their prices for misoprostol vaginally at a fraction of the normal cost
Будьте в курсе последних событий ekhut в мире киберспорта вместе с GAMER ! На нашем сайте вы найдете свежие новости, интересные обзоры, увлекательные интервью с профессиональными игроками и полные результаты турниров.
Подробные стратегии покера http://fatcurus.ru и анализ турниров: эффективные тактики, разбор раздач и ключевые советы для улучшения игры. Только практическая информация для выигрышей.
Все главные события tankdiv ru мира спорта: обзоры турниров, результаты матчей, аналитику и актуальные новости из самых популярных дисциплин.
1Win crash-game Lucky Jet
Новости игровой индустрии depcult35 аналитику и обзоры самых популярных игр. Читайте о новинках, трендах и получайте полезные советы для улучшения игрового процесса.
Все о мире гэмблинга minsvyazcc ru обзоры казино, игры, стратегии и последние новости индустрии. Узнайте о новых слотах, бонусах и тенденциях в азартных играх.
снять шлюху калуга калуга индивидуалка
снять проституток калуга вызвать девушек калуга
требования к программе производственного экологического контроля Москва программа производственного контроля пэк Москва
стол переговорный овальный стол для переговоров на металлокаркасе
hop over to this site https://jaxx-wallet.net
золото зубное скупка цена скупка технического золота цена
1win Space XY Uruguay
Click Here https://jaxx-liberty.com
article source https://jaxx-liberty.com
see [url=https://valorantskinchanger.pro/]skin change valorant[/url]
mostbet скачать на андроид mostbet uzb
бонусы казино 1win авиатор игра 1win
лучший выбор для онлайн игр infiniti-qx55 ru и спортивных ставок. Узнайте о новейших играх, получите экспертные советы и выгодные коэффициенты. Присоединяйтесь к нашему сообществу для захватывающего и безопасного опыта ставок.
Свежие новости спорта angryfoxtattoo.ru откройте для себя последние спортивные новости, аналитику ставок и прогнозы экспертов на азербайджанском языке. Самая актуальная информация о футболе, киберспорте и других видах спорта здесь!
mostbet kz скачать на андроид mostbet aviator app download
888starz bonus 500%
увлекательные стратегии mexatrondiy репортажи с турниров и последние новости покера. Станьте мастером игры, окунитесь в мир азартных карт с нашим сайтом
узнайте последние новости umra-tour.ru/ киберспорта, анализ турниров и игровые стратегии в Азербайджане. Присоединяйтесь к нам, чтобы побеждать в мире киберспорта.
Актуальные и свежие новости https://gastromoroz.ru спорта и казино. Узнайте актуальные спортивные события, анализы матчей, советы по ставкам, обзоры казино игр и стратегии.
новости киберспорта vavada-4757.ru анализ турниров и игровые стратегии в Азербайджане. Узнайте последние новости киберспорта и присоединяйтесь к нам, чтобы побеждать в мире киберспорта.
Откройте для себя Sugar Rush sugar-rush-site слот с ярким дизайном, фриспинами и возможностью крупных выигрышей! Погрузитесь в мир сладостей и ощутите вкус победы на каждом вращении.
click this https://trusteewallet.org
kinogo исторические сериалы киного фильмы про апокалипсис
киного фильмы kinogo артхаус
kinogo сериалы про детективов kinogo кинокомиксы
kinogo боевики 2025 kinogo фильмы для ноутбука
киного фильмы про будущее киного ужасы
киного фильмы для просмотра онлайн киного фильмы про подростков
A modern AI tool ai undress for working with images. Learn more about its features, capabilities and applications. Full privacy control and ease of use will ensure comfortable interaction.
Хотите купить окна купить пластиковое окно melke по разумной цене? Ознакомьтесь с нашим предложением! У нас — качество, надежность и стиль по доступной стоимости. Индивидуальный подход к каждому заказу!
снять девушку в калуге заказать девушек по вузову в калуге
проект дизайнер интерьера дизайнер студия интерьера
Thierry Henry’s biography https://thierry-henry-az.org personal life, latest news of 2018, Instagram and coaching role for Belgium and Arsenal.
Footballer Bukayo Saka’s biography https://bukayo-saka-az.org personal life, Nigerian heritage, religious views and girlfriend’s name. Salary, playing stats, jersey number, Euro appearances with England and matches with Arsenal. Latest news for 2024.
Biography of NBA star Giannis Antetokounmpo giannis-antetokounmpo-az org personal life, marriage to Mariah Riddlesprigger, children, statistics and career with the Milwaukee Bucks. Flag bearer for Greece at the 2024 Paris Olympics.
Basketball player Jimmy Butler’s jimmy butler biography: personal life, Selena Gomez relationship rumors, height, cars, idol stats, Miami Heat salary, injury news and his coffee brand. Latest news of 2024.
you can look here https://trusteewallet.org/
Biography of footballer Joshua Kimmich jimmy butler personal life, wife and children. Career at Bayern Munich, statistics for Germany, work with Pep Guardiola, negotiations with Barcelona. Vice-captain at Euro 2024. Latest news for 2024.
Djokovic’s tennis career novak-djokovic-az.org/ has been marked by numerous Grand Slam titles, showcasing his style of play. He has been a constant competitor to Rafael Nadal and Roger Federer.
Откройте мир мобильных игр games ru рейтинги лучших проектов, тренды, советы и гайды. Играйте в популярные шутеры, RPG, стратегии и песочницы прямо на телефоне!
Свежие футбольные новости vseofootball обзоры матчей, Лига чемпионов, статистика и лучшие букмекерские бонусы для ставок на спорт.
Все о Тони Кроосе https://toni-kroos.ru на одном сайте: биография, актуальные новости, детальная статистика и эксклюзивные обновления о немецкой футбольной звезде. Присоединяйтесь к сообществу фанатов и будьте в курсе всех событий, связанных с Кроосом!
Источник новостей о футболе futbol vpered ru сборной России, Кубке России, Лиге Европы и лучших букмекерских предложениях. Узнайте последние результаты, прогнозы и аналитику!
Погрузитесь в захватывающий мир cleopatra slot Cleopatra Slot! Узнайте о правилах игры, бонусных функциях и стратегиях, чтобы увеличить свои шансы на выигрыш.
Look At This https://trusteewallet.org/
Все о ставках на спорт betting лучшие стратегии, прогнозы экспертов, обзор букмекерских контор и советы для успешного беттинга. Узнайте, как заработать на спортивных ставках!
Захватывающий мир автоспорта autosport ru ru узнайте об истории, различных видах, передовых технологиях и выдающихся гонщиках. Откройте для себя, что делает автоспорт одним из самых динамичных и популярных видов спорта в мире.
Explore CS2 Skin
Explore CS2 Skins: Locate Your Flawless Match
Transform Your Gameplay
Display your individuality in Counter-Strike 2 (CS2) with unique weapon skins. Our store features a wide selection, from rare to limited-edition styles, permitting you to demonstrate your taste and enhance your gameplay.
Easy and Protected Purchasing
Savor a seamless shopping process with rapid digital shipment, ensuring your newly purchased skins are instantly available. Buy with confidence with our safe checkout process, whether you’re looking for low-cost options or high-quality designs.
How It Works
1. Explore the Selection: Investigate a wide variety of CS2 skins, arranged by rarity, arms type, or design.
2. Select Your Skin: Place your perfect skin to your trolley and move to payment.
3. Equip Your Recent Skins: Instantly receive and use your skins in-game to differentiate during matches.
Affordable Customization
Personalization should be attainable for everyone. We regularly offer deals on CS2 skins, providing high-quality designs accessible at reasonable prices.
Featured Designs
– P250 | Nuclear Threat (Factory New) – 3150 €
– Desert Eagle | Hand Cannon (Minimal Wear) – 450 €
– StatTrak™ P2000 | Ocean Foam (Factory New) – 285.88 €
– Glock-18 | Synth Leaf (Field-Tested) – 305 €
Start Shopping Immediately!
Upgrade your gameplay with our remarkable collection of CS2 skins. Whether boosting your arms or creating a one-of-a-kind collection, our store is your source for premium skins. Transform your gaming journey now!
Исследуйте Zeus vs Hades zeus-vs-hades-download.ru Gods of War! Играйте бесплатно, получайте фриспины и узнайте все о слоте 2024 года!
In Jodo Do Tigrinho online slots, every spin is a step towards victory! Incredible graphics, exciting themes and many bonuses await you. Fortune favors the brave – try your hand and discover the world of winnings with Tigrinho!
Cryptocurrency trading service bitqt with AI is automation and efficiency. Artificial intelligence monitors market dynamics, reduces risks and optimizes transactions. The perfect solution for beginners and professionals.
online slots Jodo Do Tigrinho are a unique combination of excitement and pleasure. Discover a variety of themes, bonus games and jackpots. Play comfortably, enjoying the well-thought-out interface and the chance to hit the jackpot!
Cryptocurrency trading service bitqt with AI is automation and efficiency. Artificial intelligence monitors market dynamics, reduces risks and optimizes transactions. The perfect solution for beginners and professionals.
Современные стратегии игры blackjack-players в блэкджек для начинающих, которые помогут вам быстро освоить игру и победить. Турниры, хорошая психология и новости.
Откройте для себя Mega Joker mega-joker.ru увлекательный видеослот от NetEnt, который сочетает в себе ностальгическую атмосферу классических автоматов и современные возможности выигрыша.
Погрузитесь в мир Plinko https://plinko-ru.ru увлекательной игры, основанной на случайности и стратегии! Узнайте правила, механики и стратегии для успешной игры, чтобы увеличить свои шансы на крупные выигрыши.
Откройте для себя мир starlight-princess-slot.ru Starlight Princess Slot! На нашем сайте вы найдете свежие новости, стратегии для увеличения выигрышей и эксклюзивные бонусы.
Aviatrix game https://aviatrix-games.com/en/ has become a sensation in the world of crash games. Its unique format, featuring a rapidly growing multiplier and the possibility of an unexpected crash. Aviatrix crash game is at 1win, 1xbet, Mostbet, and Pin Up.
their website https://brd-wallet.io/
useful content https://brd-wallet.io
Погрузитесь в мир Wheel of Fortune wheel-of-fortune-slot Узнайте все о знаменитом игровом автомате, его функциях, стратегиях и акциях. Играйте сейчас, испытайте удачу и выиграйте крупные призы, вращая барабаны в этом захватывающем слоте!
Захватывающий слот Lucky Jet lucky-jet-play-crash ru от Spribe с уникальной краш-механикой, который предлагает игрокам шанс испытать свою удачу и стратегическое мышление.
доставка алкоголя в подольске заказ алкоголя на дом
Захватывающий слот Lucky Jet lucky-jet-play-crash.ru/ от Spribe с уникальной краш-механикой, который предлагает игрокам шанс испытать свою удачу и стратегическое мышление.
Откройте для себя водное поло https://water-polo-ru.ru историю, правила, тактики и влияние этого захватывающего водного вида спорта. Узнайте, как динамика и стратегия сочетаются, делая водное поло уникальным и увлекательным.
Добро пожаловать на сайт redtigerplay ru посвященный слотам Red Tiger! Узнайте последние новости, стратегии для увеличения выигрышей и эксклюзивные бонусы.
Aviatrix game https://aviatrix-games.com/en/ has become a sensation in the world of crash games. Its unique format, featuring a rapidly growing multiplier and the possibility of an unexpected crash. Aviatrix crash game is at 1win, 1xbet, Mostbet, and Pin Up.
pediatric augmentin dose Details on Page 342
Погрузитесь в захватывающий мир баккары baccarat-ru.ru узнайте историю игры, её правила, стратегии и секреты успеха. Откройте для себя элегантность и интригу одной из самых престижных карточных игр казино.
Узнайте все о слоте Колесо Фортуны wheel of fortune историю, особенности игры, стратегии выигрыша и советы для успешной игры.
Откройте для себя мир гандбола handball-ru.ru изучите историю игры, основные правила, ключевые стратегии и влияние на культуру.
Погрузитесь в увлекательный мир покера poker-ru.ru/ исследуйте его историю, правила, продвинутые стратегии и культурное влияние. Узнайте, как интеллект и интуиция объединяются в этом захватывающем карточном спорте.
Мир блэкджека blackjack узнайте историю игры, её правила, секретные стратегии и влияние на современную культуру. Откройте для себя глубину этой захватывающей карточной игры и научитесь побеждать с умом.
Погрузитесь в мир фигурного катания figure skating исследуйте его историю, уникальные техники, знаменитых спортсменов и культурное влияние.
Скачайте бесплатно книгу https://storitelling.ru по сторителлингу и узнайте, как создавать истории, которые цепляют с первых строк. Практические советы, примеры и вдохновение для всех, кто хочет освоить искусство рассказчика.
готовые пластиковые окна мелке раздвижное окно
kinogo сериалы про преступников kinogo кинокомиксы
click now https://web-counterparty.io
Сайт игровых промокодов промокод на пополнение ggdrop это ваш доступ к эксклюзивным бонусам и скидкам. Бесплатные награды, внутриигровая валюта и уникальные акции ждут вас. Успейте воспользоваться всеми возможностями!
Valuable info. Fortunate me I found your site by chance, and I’m stunned why this twist of fate didn’t took place in advance! I bookmarked it.
Insurance Directory USA,
Ищете промокоды для игр skinbox промокоды на кейсы наш сайт – ваш лучший помощник! Собираем актуальные игровые промокоды для бонусов, скидок и эксклюзивных наград. Наслаждайтесь играми с максимальной выгодой – воспользуйтесь промокодами уже сегодня!
Хотите раскрутить контент-план мы знаем, как это сделать! Поможем увеличить охваты, привлечь активную аудиторию и вывести ваш контент на новый уровень.
капельница от похмелья клиника http://www.medlinks.ru
Ищете промокоды для игр промокод на epicloot наш сайт – ваш лучший помощник! Собираем актуальные игровые промокоды для бонусов, скидок и эксклюзивных наград.
Участок в Мишкином Лугу http://мишкинлуг.рф/uchastki-mishkinlug по Симферопольскому шоссе — идеальное место для строительства! Тихий поселок, прекрасные виды, удобный подъезд и все условия для комфортной жизни.
Лисичкин Очаг возле Серпухова https://лисичкиночаг.рф/uchastki-lisichkinochag идеальные участки для вашего будущего дома! Живописная природа, хорошая транспортная доступность и возможность подключения всех коммуникаций ждут вас.
Участки в Лисичкином Очаге https://лисичкиночаг.рф неподалеку от Серпухова. Тихий, зеленый поселок с прекрасной природой и удобной транспортной доступностью. Здесь вы сможете построить комфортное жилье для себя и своей семьи.
Компания Handy Print предоставляет [url=https://handy-print.ru]профессиональные услуги по печати[/url] на различных поверхностях: текстиле, дереве, стекле, пластике и металле. Мы используем только современные технологии и качественные материалы, чтобы обеспечить яркость и долговечность изображений.
В Handy Print вы можете [u]заказать нанесение логотипов[/u] на корпоративные подарки, [url=https://handy-print.ru]создание эксклюзивных футболок[/url], изготовление стильных аксессуаров и рекламной продукции. Наша команда профессионалов готова выполнить даже самые сложные и нестандартные задачи, чтобы вы получили идеальный результат.
Обращайтесь к нам уже сегодня и превращайте ваши идеи в реальность с помощью Handy Print!
[url=https://yvision.kz/community/culture]культурные мероприятия Алматы[/url] – триатлон соревнования Казахстан, аренда рабочего места Алматы
Отзывы о компаниях и работодателях https://potrebsojuz.ru в одном месте. Узнайте реальное мнение сотрудников и клиентов, чтобы принять правильное решение при выборе работы или услуг.
Комплексная юридическая помощь https://kramzenergo.ru для вас и вашего бизнеса. Анализ дел, представительство в судах, поддержка на всех этапах
[url=https://yvision.kz/community/analytics]политическая аналитика Казахстан[/url] – социальное развитие, хоккейные новости
капельница цена медицинская клиника капельниц
porno 1win porno 1win
1win mexico 1win argentina
Investigate CS2 Skins: Find Your Perfect Match
Transform Your Playstyle
Showcase your individuality in Counter-Strike 2 (CS2) with distinct weapon skins. Our store features a diverse selection, from rare to limited-edition patterns, enabling you to express your aesthetic and enhance your gameplay.
Effortless and Secure Purchasing
Enjoy a seamless shopping process with rapid digital shipment, ensuring your recently purchased skins are promptly available. Buy with confidence with our protected checkout process, whether you’re looking for affordable options or high-quality designs.
How It Works
1. Look through the Collection: Explore a broad array of CS2 skins, organized by rarity, arms type, or style.
2. Choose Your Skin: Include your perfect skin to your basket and move to payment.
3. Equip Your Latest Skins: Promptly receive and use your skins in-game to shine during matches.
Budget-friendly Personalization
Personalization should be attainable for all. We frequently offer discounts on CS2 skins, ensuring top-tier designs available at low prices.
Featured Skins
– P250 | Nuclear Threat (Factory New) – 3150 €
– Desert Eagle | Hand Cannon (Minimal Wear) – 450 €
– StatTrak™ P2000 | Ocean Foam (Factory New) – 285.88 €
– Glock-18 | Synth Leaf (Field-Tested) – 305 €
Start Your Shopping Experience Immediately!
Upgrade your gameplay with our impressive selection of CS2 skins. Whether boosting your arms or establishing a one-of-a-kind collection, our marketplace is your hub for high-quality skins. Transform your gaming adventure at once!
Откройте для себя историю слово пацана сериал смотреть онлайн честный взгляд на суровую реальность, где дружба и слово дороже всего. Уникальный проект о жизни без прикрас и ценности принципов.
Please let me know if you’re looking for a writer for your site. You have some really good articles and I feel I would be a good asset. If you ever want to take some of the load off, I’d really like to write some articles for your blog in exchange for a link back to mine. Please send me an email if interested. Thanks!
https://xn—–7kcgiiy1bf2ancu8h.xn--p1ai
Удобная и компактная коляска-трость для активных родителей, со съемным козырьком и регулируемой спинкой.
Стильная и практичная коляска-трость для вашего малыша, и удобным выдвижным козырьком.
Универсальная коляска-трость для города и природы, с удобной ручкой и амортизаторами.
Качественная коляска-трость с удобной ручкой, которая облегчит вам заботу о ребенке.
chicco трость [url=https://kolyaski-trosti-progulochnye.ru/]https://kolyaski-trosti-progulochnye.ru/[/url] .
Hi, Neat post. There is a problem together with your site in web explorer, could check thisK IE nonetheless is the marketplace leader and a big component of people will leave out your wonderful writing because of this problem.
[url=https://yvision.kz/community/news]новости сво на украине сегодня[/url] – события Атырау, смешные истории Казахстан
kinogo сериалы 2025 киного российские фильмы
kinogo фильмы для компании kinogo сериалы по алфавиту
kinogo фильмы про супергероев kinogo фильмы про супергероев
kantorbola
kantorbola link alternatif terbaru , kami juga menyediakan APK Android dengan fitur yang akan memanjakan anda dalam setiap aktifitas di situs kantor bola .
This info is invaluable. When can I find out more?
https://xn—–7kcgiiy1bf2ancu8h.xn--p1ai
Откройте для себя blacksprut сайт возможности даркнет-рынка с тысячами предложений. Быстрая регистрация, надежные сделки и анонимность на каждом этапе.
Лучшее онлайн казино https://1wincasino.pl Огромный выбор автоматов, настольных игр и live-казино. Уникальные акции, приветственные бонусы и мгновенные выплаты сделают вашу игру еще интереснее.
моана песня моаны текст https://faav.ru
kantor bola
KANTORBOLA adalah pilihan terbaik bagi pecinta slot online. Nikmati berbagai permainan slot menarik, bonus besar, dan pengalaman bermain yang aman dan terpercaya.
рыбалка и охота охотничьи базы
рыбалка в ветреную погоду рыбалка с гидом в сибири
надежный маркетплейс blacksprut сайт где сочетаются безопасность, широкий выбор товаров и удобство использования. Платформа работает с анонимными платежами и гарантирует полную конфиденциальность для всех пользователей.
Hi! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading your blog and look forward to all your posts! Carry on the great work!
ответ на игру башня
Ресторанный консалтинг UPSKILL https://upskilll.ru/consulting это профессиональные услуги в сфере ресторанного бизнеса: анализ рынка, аудит заведения, устранение слабых мест, обучение персонала, занимаемся наставничеством рестораторов с 2018 года.
центр ремонта стиральных машин ремонт стиральных машин стоимость услуг
Explorez une experience de jeu sans precedent avec 888 starz, votre destination incontournable pour les paris en ligne. Avec une interface utilisateur intuitive et des options de personnalisation avancees, ce site offre une navigation fluide et des fonctionnalites innovantes pour ameliorer votre experience. Inscrivez-vous des aujourd’hui et beneficiez de bonus exclusifs, d’une assistance client 24/7 et d’une securite renforcee pour profiter pleinement de chaque mise.
site https://playslotrealmoney.com/th/great-queen-bee-real-money/
Платформа Курьер Купер https://cash-kuper.ru открывает возможности для работы в доставке. Свободный график, прозрачная система оплаты и заказы поблизости – идеальный выбор для тех, кто ищет подработку или основной заработок.
buy thc joint in prague buy cali weed in prague
Return to Player Playtech Permainan Gacor dan Kepentingan Menjalankan Permainan Pratinjau Pragmatic Game
Permainan permainan di internet semakin digemari, dan juga Playtech Provider (Playtech Permainan) merupakan satu provider terbaik berkat grafis menawan, fasilitas kreatif, serta Return to Player (RTP) yang menguntungkan. Akan tetapi, sebelum Anda mencoba menggunakan modal nyata, penting supaya mencoba permainan demo PG Mesin. Kenapa? Berikut penjelasannya.
Apakah Itu Game Versi Uji Playtech Permainan?
Slot percobaan adalah versi percobaan dari permainan permainan yang memakai saldo virtual, tanpa modal sunguhan. Hal ini memperbolehkan player agar memahami sistem aktivitas, fungsi insentif, dan Persentase Pengembalian tanpa adanya bahaya keuangan.
Mengapa Bermain Permainan Versi Uji Playtech Permainan Esensial?
Mengetahui Mekanisme Aktivitas
Setiap game memiliki kebijakan serta fitur beragam. Permainan demo memfasilitasi pemain mempelajarinya tanpa adanya beban.
Mengevaluasi Persentase RTP
Return to Player merupakan persen kemenangan teoretis pada jangka panjang. Melalui percobaan, pemain dapat melihat seberapa sering permainan menghasilkan kemenangan.
Membuat Strategi
Permainan demo memperbolehkan Anda supaya mengevaluasi rencana contohnya manajemen pertaruhan tanpa adanya bahaya rugi uang.
Mencari Slot Pilihan
Playtech Perusahaan menawarkan beragam gaya game. Dengan menjalankan percobaan, Anda bisa mengetahui game yang tepat untuk selera kamu.
Menghindari Kerugian Banyak
Memainkan percobaan membantu kamu mengetahui game sebelumnya bertaruh menggunakan dana asli, menurunkan potensi kerugian kerugian.
Manfaat Bermain Mesin Versi Uji Pragmatic Mesin
Tanpa Bahaya Finansial: Memainkan menggunakan saldo simulasi, tanpa beban hilangnya modal.
Meningkatkan Kepercayaan Diri: Melatih menggunakan demo menjadikan pemain semakin siap saat beralih pada game menggunakan uang nyata.
Mengetahui Fungsi Insentif: Ketahui cara memicu fasilitas bonus seperti Putaran Gratis dan Simbol Wild.
Meminimalkan Waktu serta Dana: Uji beberapa game tanpa adanya perlu membuang modal.
Rekomendasi Mencoba Slot Percobaan Pragmatic Permainan
Perhatian terhadap fungsi bonus serta cara kerjanya.
Lihatlah volatilitas game (tinggi atau juga rendah).
Susun limit durasi dan budget meski mencoba memakai saldo digital.
Jelajahi berbagai tema untuk menemukan pilihan kamu.
ремонт бойлеров и водонагревателей ремонт накопительных водонагревателей
buy cannafood in prague https://shop-cannabis-prague.com
экспресс микрозайм онлайн заем
Hmm is anyone else having problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
virtual rewards
Перейти на сайт [url=https://casino-o.pro]KENT[/url]
подробнее [url=https://casino-o.pro]обзор казино с бесплатными фриспинами[/url]
займ онлайн срочно без отказа займ
Открывайте кейсы CS:GO https://www.facebook.com/people/Hotdrop_CSGO/61550490187523/ с крутыми шансами на редкие скины. Удобный интерфейс, надежная система и огромный выбор кейсов сделают игру еще интереснее. Начните свой путь к топовым скинам прямо сейчас!
888starz http://morvaridteb.com/2024/09/23/skachat-888starz-na-android-apk-4/
Откройте яркие кейсы CS:GO https://m.youtube.com/@hotdrop-case и получите шанс выиграть топовые скины! Широкий выбор кейсов, высокий шанс дропа и честная система обеспечат увлекательный опыт.
Когда хочется расслабиться после тяжелого дня, восточные сериалы – отличный выбор. Они умеют затягивать в свой мир с первых минут и заставляют переживать за героев, как за близких людей. Если не хочешь тратить время на поиск нормального ресурса, где все удобно и бесплатно, попробуй [url=https://doramahit.tv/]смотреть дорамы онлайн[/url] на этом сайте.
Пробуйте удачу https://discord.com/invite/B5fF6pW8Cm CS:GO! Шанс получить редкие и дорогие скины, широкий выбор кейсов и удобный интерфейс делают процесс открытия легким и захватывающим.
Ваши любимые кейсы CS:GO https://t.me/s/hotdropcases в одном месте! Большой выбор, удобный интерфейс и высокая вероятность выпадения редких предметов делают процесс открытия кейсов по-настоящему захватывающим.
Нужны деньги срочно микрозайм с быстрым одобрением и моментальным переводом на карту. Минимум документов, удобные условия и прозрачные ставки. Оформите займ прямо сейчас!
лучшие фильмы в HD качестве фильмы новые сериалы 2025 без регистрации
demo pg slot
Return to Player Playtech Slot Gacor serta Pentingnya Mencoba Permainan Versi Uji Playtech Slot
Game slot di internet semakin terkenal, dan juga Playtech Soft (Pragmatic Permainan) merupakan satu platform terkemuka karena grafis menawan, fasilitas kreatif, serta RTP (Return to Player) yang kompetitif. Akan tetapi, sebelum Anda memainkan dengan uang nyata, penting supaya mencoba mesin versi uji PG Permainan. Alasannya? Berikut ini penjelasannya.
Apa Itu Mesin Pratinjau PG Mesin?
Permainan versi uji ialah versi percobaan dari permainan game yang memakai poin virtual, tanpa modal asli. Ini memungkinkan player agar mengenal sistem game, fitur bonus, dan RTP tanpa adanya bahaya keuangan.
Alasannya Memainkan Game Percobaan Playtech Permainan Penting?
Memahami Cara Kerja Aktivitas
Tiap permainan memiliki peraturan serta fasilitas berbeda. Game versi uji membantu pemain mempelajarinya tanpa adanya stres.
Mengetes Level Persentase Pengembalian
Return to Player adalah rasio keuntungan teoretis di periode jauh. Menggunakan versi uji, kamu bisa menyaksikan berapa kerap game menyediakan keuntungan.
Membuat Strategi
Permainan demo memperbolehkan pemain supaya mengetes taktik seperti pengelolaan taruhan tanpa risiko hilangnya uang.
Mengetahui Game Favorit
PG Perusahaan memiliki berbagai gaya mesin. Melalui menjalankan versi uji, Anda bisa mengetahui game yang sesuai untuk keinginan kamu.
Mengurangi Kerugian Besar
Bermain percobaan memfasilitasi Anda mengetahui permainan sebelum Anda berjudi memakai uang asli, meminimalkan potensi kerugian kerugian.
Kelebihan Bermain Game Demo Pragmatic Permainan
Tanpa Bahaya Finansial: Mencoba dengan saldo digital, tanpa adanya stres rugi uang.
Memperkuat Keyakinan Anda: Melatih melalui percobaan membuat kamu semakin siap pada saat beralih ke game dengan uang sunguhan.
Memahami Fitur Bonus: Pelajari teknik menyebabkan fungsi bonus misalnya Free Spins atau juga Simbol Liar.
Menyimpan Durasi serta Uang: Coba berbagai permainan tanpa adanya perlu mengeluarkan dana.
Rekomendasi Mencoba Permainan Pratinjau Playtech Slot
Fokus terhadap fitur bonus serta cara kerjanya.
Amati risiko mesin (tinggi dan kecil).
Susun batas durasi dan anggaran meski memainkan dengan kredit simulasi.
Eksplorasi beragam tema agar mengetahui pilihan kamu.
Промокоды для игр https://esportpromo.com/standoff/ggstandoff/ это бесплатные бонусы, скидки и эксклюзивные награды! Находите актуальные коды, используйте их и получайте максимум удовольствия от игры без лишних затрат.
Бесплатные промокоды https://playpromocode.com/standoff/bulldrop/ для ваших любимых игр! Получайте монеты, бустеры, скины и другие ценные награды. Мы собираем только проверенные коды и обновляем их каждый день.
Хотите проверить компанию https://innproverka.ru по ИНН? Наш сервис поможет узнать подробную информацию о юридических лицах и ИП: статус, финансы, руководителей и возможные риски. Защищайте себя от ненадежных партнеров!
Недвижимость на Северном Кипре https://iberiaproperty.ru выгодные инвестиции и комфортная жизнь у моря. Апартаменты, виллы и пентхаусы по доступным ценам. Поможем выбрать лучший вариант и оформить покупку.
удобный маркетплейс blacksprut с высоким уровнем анонимности и надежной системой защиты. Интуитивный интерфейс, проверенные продавцы и безопасные сделки делают его лучшим выбором для покупок.
Подарок впечатление оптом для девушки и купить сувениры дешево в Костроме: сувенирная продукция опт
Раскрутка в соцсетях https://nakrytka.com без лишних затрат! Привлекаем реальную аудиторию, повышаем охваты и активность. Эффективные инструменты для роста вашего бренда.
Greate article. Keep writing such kind of info on your site. Im really impressed by your blog.
Hi there, You have done a great job. I’ll definitely digg it and for my part suggest to my friends. I’m sure they’ll be benefited from this site.
ответ на игру башня слов
escort girl paris
увлекательный сериал подробнее о жизни сказочных персонажей в реальном мире. Интригующий сюжет, волшебные события и неожиданные тайны. Смотрите онлайн в высоком качестве прямо сейчас!
брокеры таможенное оформление https://bvs-logistica.com/tamozhennnoe-oformlenie.html
Интернет-магазин товаров https://vitasleep.ru для здорового сна. В ассортименте: ортопедические матрасы, подушки, одеяла, постельное белье и аксессуары от проверенных брендов. Удобный выбор, доставка по России, гарантия качества. Забота о вашем комфорте и здоровом сне!
сериалы 2024 смотреть онлайн lordseriall.org
смотреть сериалы 2019 lordserial4.top/
сериалы 2024 смотреть онлайн https://lordserials2.net
сериал онлайн бесплатно серии https://lordserial7.com
смотреть сериалы качестве https://lordserials2.net
смотреть сериалы 2023 хорошего качества смотреть зарубежные сериалы онлайн бесплатно
Рекомендуем проверенных хакеров, и их услуги – Взломать кошелек от которого забыли пароль
Persentase Pengembalian PG Mesin Hot serta Penting Menjalankan Permainan Demo Pragmatic Mesin
Game permainan daring lebih populer, serta PG Soft (Pragmatic Mesin) adalah beberapa platform unggulan karena tampilan indah, fasilitas terbaru, dan juga Persentase Pengembalian (Return to Player) yang menguntungkan. Namun, sebelum Anda bermain memakai modal sunguhan, esensial supaya menguji slot demo Pragmatic Slot. Mengapa? Ini rinciannya.
Apa itu Itu Slot Percobaan Pragmatic Game?
Game versi uji merupakan edisi uji dari game slot dengan memakai saldo digital, bukan modal nyata. Hal ini memperbolehkan player agar mengenal mekanisme aktivitas, fungsi hadiah, dan juga Persentase Pengembalian tanpa adanya potensi kerugian keuangan.
Alasannya Mencoba Slot Percobaan Playtech Permainan Esensial?
Mengetahui Cara Kerja Game
Tiap slot mempunyai peraturan serta fungsi berbeda. Game percobaan memudahkan kamu mengetahuinya dengan tidak stres.
Mengetes Persentase RTP
Return to Player ialah persentase hasil teoritis pada periode lama. Melalui percobaan, kamu bisa menyaksikan sejauh mana sering permainan menghasilkan keuntungan.
Mengembangkan Strategi
Game demo memungkinkan pemain agar mengevaluasi strategi seperti manajemen taruhan dengan tidak potensi kerugian rugi dana.
Mencari Game Pilihan
Playtech Provider menawarkan beragam konsep slot. Dengan mencoba percobaan, Anda dapat mengetahui aktivitas dengan sesuai pada preferensi pemain.
Mengurangi Rugi Signifikan
Mencoba demo memfasilitasi pemain memahami permainan sebelumnya bertaruh memakai modal asli, mengurangi potensi kerugian kehilangan.
Keuntungan Bermain Slot Versi Uji Playtech Permainan
Tanpa adanya Risiko Finansial: Bermain dengan kredit digital, tanpa adanya beban rugi uang.
Memperkuat Keyakinan Sendiri: Melatih menggunakan demo menyebabkan Anda semakin siap ketika bergeser pada game menggunakan dana asli.
Mengetahui Fungsi Hadiah: Ketahui teknik mengaktifkan fitur insentif misalnya Putaran Gratis atau juga Simbol Wild.
Menghemat Jam serta Modal: Coba beragam slot dengan tidak wajib mengeluarkan uang.
Saran Bermain Slot Versi Uji Playtech Mesin
Perhatian pada fasilitas insentif dan juga teknik operasinya.
Amati tingkat volatilitas mesin (tinggi atau rendah).
Atur limit waktu dan juga anggaran walaupun mencoba menggunakan poin digital.
Cari tahu berbagai konsep agar menemukan kesukaan pemain.
Логистические услуги в Москве https://bvs-logistica.com доставка, хранение, грузоперевозки. Надежные решения для бизнеса и частных клиентов. Оптимизация маршрутов, складские услуги и полный контроль на всех этапах.
смотреть сериал качестве бесплатно сериалы смотреть онлайн бесплатно
сериал онлайн бесплатно серии смотреть зарубежные сериалы в онлайн бесплатно в хорошем качестве
Рекомендуем проверенных хакеров, и их услуги – Защита от взлома
Хотите почувствовать азарт? arkada casino бонусы без депозита предлагает широкий выбор игр, честную систему выигрышей и мгновенные выплаты. Захватывающие слоты и бонусы ждут вас!
Your article helped me a lot, is there any more related content? Thanks!
смотреть сериалы в хорошем качестве https://lordseriall6.org
смотреть сериал подряд бесплатно https://lordsserials.org
сериал сезон онлайн 2022 смотреть онлайн смотреть зарубежные сериалы
Check out Sellvia https://www.instagram.com/sellvia.dropshipping/ on Instagram for the hottest product ideas, store upgrades, and exclusive deals! Stay in the loop with our latest dropshipping tips and grab promo coupons to boost your business.
Рекомендуем проверенных хакеров, и их услуги – Реальные хакеры
The full special bip39 Word List consists of 2048 words used to protect cryptocurrency wallets. Allows you to create backups and restore access to digital assets. Check out the full list.
[url=https://kra-32-at.ru/]kra29.cc[/url] – кракен тор, Kra30.cc
Reliable and unique bip39 Word List contains 2048 words needed to create seed phrases in crypto wallets. Allows you to safely manage private keys and guarantees the possibility of recovering funds.
hash delivery in prague https://sale-weed-prague.com
Reliable and unique bip39 Word List contains 2048 words needed to create seed phrases in crypto wallets. Allows you to safely manage private keys and guarantees the possibility of recovering funds.
Reliable and unique bip39 Word List contains 2048 words needed to create seed phrases in crypto wallets. Allows you to safely manage private keys and guarantees the possibility of recovering funds.
kush delivery in prague https://sale-weed-prague.com
1xBet promo code https://succes.ro/step-by-step-guide-to-using-the-1xbet-free-bet-2/ your chance to get bonuses on bets, free bets and exclusive promotions! Enter the code during registration and start playing with an increased deposit.
Ремонт компьютеров и ноутбуков https://remcomp89.ru в Новом Уренгое – быстрые и качественные услуги! Диагностика, настройка, замена комплектующих, восстановление данных. Гарантия на работу, доступные цены и выезд мастера!
Looking for the current spinbetter promo code? Get bonus funds for bets and casino games. Easy activation, favorable conditions and real winnings are waiting for you. Hurry to use it!
Используйте актуальный промокод 1xbet и получите увеличенный бонус на первый депозит! Делайте ставки на спорт, играйте в казино и пользуйтесь эксклюзивными предложениями. Легкая регистрация и моментальные выплаты!
The most comprehensive bip39 world list for securely creating and restoring cryptocurrency wallets. Learn how mnemonic coding works and protect your digital assets!
moving abroad Prague moving in Prague safely
The most comprehensive bip39 for securely creating and restoring cryptocurrency wallets. Learn how mnemonic coding works and protect your digital assets!
airport transfer Prague moving to a different city in Czech Republic
Цікавлять новобудови Україна? Сучасні квартири з панорамними вікнами, зачиненими дворами та зручним розташуванням. Вибирайте комфортне житло з найкращими умовами покупки!
Продажа инструментов для дома инструменты купить цены строительства и ремонта! Огромный выбор ручного и электроинструмента, выгодные цены, акции и быстрая доставка. Найдите все необходимое в одном месте!
Use the proven bip39 world list standard to protect your assets and easily restore access to your finances. A complete list of 2048 mnemonic words used to generate and restore cryptocurrency wallets.
Sitio web de fans rodri com mx de Rodri Hernandez: Descubre la carrera y logros del mediocampista espanol del Manchester City. Noticias, estadisticas y analisis del juego de uno de los mejores futbolistas actuales.
Sitio fan de Mohamed Salah https://mohamed-salah.com.mx ultimas noticias, records, entrevistas y los mejores momentos de la carrera de uno de los futbolistas mas grandes de la actualidad. ?Mantente al tanto!
casino. en ligne https://annuaire-des-casinos.com
my explanation https://toruswallet.org/
Try your luck at pinup casino! The best slots, roulette, blackjack and live games with real dealers. Pleasant bonuses, promotions and a user-friendly interface will create ideal conditions for the game!
New full Bip39 2048 words used to create and restore crypto wallets. Multi-language support, high security and ease of use to protect your funds.
liste casino en ligne casino en ligne stake
betzino casino en ligne casino en ligne le plus payant
New full bip39 world list 2048 words used to create and restore crypto wallets. Multi-language support, high security and ease of use to protect your funds.
[url=https://midnight.im/store/chity-gta5-online/]читы для гта 5 онлайн[/url] – скачать читы на scp secret laboratory 2023, аим для Counter Strike 2
Промокод казино https://www.flexsocialbox.com/read-blog/20470 активируйте эксклюзивные бонусы! Получите фриспины, бонусные деньги на депозит и кешбэк. Используйте актуальные коды для максимальной выгоды в онлайн-казино. Играйте с лучшими условиями!
Current casino promo codes https://institutocea.com/layouts/inc/?codigo_promocional_de_la_casa_de_apuestas_1xbet_para_el_registro.html bonus money, free spins and cashback for playing. Use verified codes, activate exclusive offers and win more!
Ищете выгодные покупки? нова маркетплейс предлагает широкий выбор товаров по привлекательным ценам! Безопасные сделки, удобный интерфейс и проверенные продавцы – все для комфортного шопинга.
Лучшие промокоды для казино http://samodelnii.ru/application/pages/bk_1xbet_2020_bonus_pri_registracii_6500_rubley__18.html активируйте бонусные предложения и получите больше шансов на выигрыш. Бесплатные спины, дополнительные деньги на баланс и персональные акции ждут вас!
[url=https://midnight.im/store/chity-cs-1-6/]скачать вх аим кс 1.6[/url] – читы на гта 5 онлайн купить, чит кс 1.6
Присоединяйтесь к NovaXLtd.live ссылка платформе с широкими возможностями и удобными инструментами. Доступность, надежность, поддержка!
Откройте новые возможности зеркало! Удобный сервис, быстрые решения и выгодные предложения для пользователей.
Откройте все возможности bsme Большой выбор товаров, безопасные сделки и простая навигация. Приватность и защита пользователей на первом месте.
Свежие промокоды казино https://fanerarus.ru/pag/vybor_ghenskoy_sumki_kratko_o_glavnom.html бонусы, фриспины и эксклюзивные акции от топовых платформ! Найдите лучшие предложения, активируйте код и выигрывайте больше.
Нужен опытный мануальный терапевт в Пушкино? Помогаю при остеохондрозе, грыжах, искривлениях позвоночника и болях в суставах. Безопасные техники, профессиональный подход, запись на прием!
Защитите авто от коррозии https://antikorauto.ru антикоррозийная обработка и кузовной ремонт с гарантией. Восстановление геометрии кузова, покраска, удаление вмятин. Долговечность и качество по доступным ценам!
Жарким летним утром Вася Муфлонов, заядлый рыбак из небольшой деревушки, собрал свои снасти и отправился на местное озеро. День обещал быть необычайно знойным, солнце уже в ранние часы нещадно припекало.
Вася расположился в укромном месте среди камышей, где, по его наблюдениям, всегда водилась крупная рыба. Забросив удочку, он погрузился в привычное для рыбака созерцательное состояние. Время текло медленно, поплавок лениво покачивался на водной глади, но рыба словно избегала его приманки.
Ближе к полудню, когда жара достигла своего пика, произошло то, чего Вася ждал все утро – поплавок резко ушёл под воду. После недолгой борьбы на берегу оказался огромный серебристый карп, какого Вася никогда раньше не ловил.
Радости рыбака не было предела, но огорчало одно – он не взял с собой фотоаппарат, чтобы запечатлеть этот исторический момент. Тут в голову Васи пришла необычная идея. Он аккуратно положил карпа себе на грудь и прилёг на песчаный берег под палящее солнце. “Пусть загар оставит память об этом улове”, – подумал находчивый рыбак.
Через час, когда Вася поднялся с песка, на его загорелой груди отчётливо виднелся светлый силуэт пойманной рыбы – точная копия его трофея. Теперь у него было неопровержимое доказательство его рыбацкой удачи.
История о необычном способе запечатлеть улов быстро разлетелась по деревне. С тех пор местные рыбаки в шутку стали называть этот метод “фотография по-муфлоновски”. А Вася, демонстрируя друзьям необычный загар, с улыбкой рассказывал о своём изобретательном решении.
Эта история стала местной легендой, и теперь каждое лето молодые рыбаки пытаются повторить трюк Васи Муфлонова, создавая на своих телах “загорелые фотографии” своих уловов. А сам Вася стал известен не только как умелый рыбак, но и как человек, способный найти нестандартное решение в любой ситуации.
buy online casino online casino software
Fast and secure VPS https://evps.host/products for any task! Flexible configurations, SSD drives, DDoS protection. Easy scaling, high performance and 24/7 support!
see here now
[url=https://337store.pro/]Credit report[/url]
All about Vinicius Junior vinicius junior career, trophies, highlights and records. Follow the Brazilian winger, his success at Real Madrid and on the international stage!
All about Karim Benzema karim benzema biography, achievements, main goals and career moments. Find out how the striker conquered Real Madrid and continues to shine in world football!
All about Karim Benzema karim-benzema-bd.com biography, achievements, main goals and career moments. Find out how the striker conquered Real Madrid and continues to shine in world football!
click this over here now [url=https://337store.pro]Biz[/url]
аркада казино играть arkada casino бонусы за регистрацию
Военная служба по контракту https://contract116.ru стабильность, достойная зарплата, социальные льготы и карьерный рост. Присоединяйтесь к профессиональной армии и получите надежное будущее!
Kevin De Bruyne kevin-de-bruyne is the leader of the Manchester City and Belgium national team midfield. Find out all about his achievements, matches, awards and records in world football!
скачать сервер самп самп плагины
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
[url=][/url]
Временная регистрация в Москве – быстро и надежно!
Нужна временная прописка для работы, учебы или оформления документов?
Оформим официальную регистрацию в Москве всего за 1 день. Без очередей,
с гарантией и юридической чистотой!
1. Подходит для граждан РФ и СНГ
2. Регистрация от 3 месяцев до 5 лет
3. Легально, с внесением в базу МВД
Работаем без предоплаты! Документы можно получить лично или дистанционно.
Доступные цены, оперативное оформление!
Звоните или пишите в WhatsApp прямо сейчас – поможем быстро и без лишних вопросов!
Временная регистрация в Москве
[url=][/url]
Как побороть лудоманию https://teletype.in/@antosha-sevan/moi-opyt-izbavlenia-ot-igrovoi-zavasimosty история глазами прошедшего это испытание и несколько советам тем, кто в середине пути или столкнулся с этим через друзей и близких. Описываю в статье как Вавада помогла мне избавиться от игровой зависимости
Окунитесь в азарт с http://aviator-slot.ru Уникальная игра с захватывающим геймплеем и возможностью сорвать крупный выигрыш. Следите за коэффициентом, вовремя забирайте ставку и умножайте баланс. Испытайте удачу прямо сейчас!
Новости музыки Украины https://musicnews.com.ua популярные жанры, тренды и полезные советы для музыкантов. Узнавайте больше о мире музыки и развивайте свои навыки!
Последние новости автоспорта autosport-ru.ru/ обзоры гонок, рейтинги пилотов и команд. Формула-1, Ле-Ман, WRC и другие топовые серии – следите за всеми событиями в одном месте!
Zeus vs Hades https://zeus-vs-hades-download.ru эпичная битва богов! Игровой автомат с грозными бонусами, фриспинами и множителями. Выберите сторону Зевса или Аида и сорвите большой выигрыш!
Все о легкой атлетике athletics-ru.ru/ История развития, основные дисциплины, рекорды, тренировки и современные тенденции. Узнайте больше о королеве спорта!
Cassino online Pin Up https://888casino-official-brazil.site ganhos sem limites! Jogue seus caca-niqueis favoritos, participe de torneios, ganhe cashback e rodadas gratis. Licenca, seguranca e pagamentos rapidos!
preprava stroju stehovani s durazem na flexibilitu
Свежие и актуальные новости https://sugar-news.com.ua Украины и мира! Будьте в курсе последних событий, аналитики и трендов. Читайте последние новости Украины онлайн!
stehovani clanky stehovani studentskych bytu
Лучшие эксперты в одном месте! экспертиза промышленной безопасности опасных производственных маркетплейс и агрегатор экспертных компаний помогает найти надежных специалистов по разным направлениям. Удобный выбор, проверенные отзывы и рейтинг!
more helpful hints https://toastwallet.org
stehovani Praha stehovani s referencemi
bc game official website
have a peek at this website https://web-martianwallet.io
stehovani hodnoceni stehovani rady
hop over to this website https://web-smartwallet.org/
1win freespins Chile
Хотите играть в Steam-игры https://shared-steam.org дешевле? Shared-Steam.org предлагает аренду аккаунтов с топовыми играми. Безопасность, доступность и удобство – ваш гейминг без границ!
try this out https://web-smartwallet.org
news https://web-martianwallet.io
تعتبر شركة مكافحة الحشرات بالجبيل هي أفضل شركة سعودية لمكافحة الحشرات حيث نقوم بتنفيذ خدمات مكافحة الحشرات بمدينة الجبيل بخبرة عالية وأفضل العمالة المدربة عالمياً علي تنفيذ خدمات رش المبيدات الحشرية وهناك ايضاً مهندسون متخصصون في الاشراف علي تنفيذ تلك الخدمات المتميزة التي نقدمها لجميع العملاء.
شركة مكافحة حشرات بالجبيل
شركة تنظيف فرشات بالرياض حتاج الأمر لشركة متمرسة حيث يمكنها القيام بكل مهام التنظيف للحفاظ عليها من أي ضرر كما أن هناك من الفرشات منها الموكيت والسجاد والمجالس ومراتب السرائر ولأن شركة تنظيف فرشات توفر هذه الخدمات بأسعار لا تقبل المنافسة حتي تهدف لتنفيذ الخدمة لعدد كبير من العملاء بكل دقة وسرعة .
شركة تنظيف فرشات بالرياض
Create images deep-nude ai easily with AI. Remove clothes from anyone in the image and enjoy their nakedness.
مستودع تخزين اثاث بالرياض تنفرد شركة سبيد واى بأنها أفضل الشركات التي توفر خدمات تخزين الأثاث على مستوى عالي من الجودة والأمان.
مستودع تخزين اثاث بالرياض
Turkiye’deki slot makineleri para cekme ozellikli slotlar gercek parayla oynanabilen slotlar kapsaml bir baks! Nerede oynan?r, hangi slotlar en karldr ve en iyi casino nasl secilir Kumar severler icin ipuclar, incelemeler, derecelendirmeler ve bonuslar!
Turkiye Slotlar Rehberi https://slots-rait.com En Iyi Slotlar ve Casinolar! Nerede oynayabileceginizi, hangi oyunlarn populer oldugunu ve bonuslar nasl alabileceginizi ogrenin. Oyun alanlar ve guncel eglencelere dair kapsaml bir genel baks!
visite site https://brd-wallet.com
toto138
toto138
квартирный переезд минск москва https://perevozimgruz.by/nedorogaya-perevozka-mebeli/perevozka-shkafa/
Знакомства в Уфе https://ufavip.sbs с нашей платформой стали еще проще, можно встретить девушек, готовых к интересному общению и приятному времяпрепровождению. Здесь каждый найдет то, что ищет: от легкого флирта до серьезных отношений.
1win betting Nigeria
this content https://brd-wallet.com
bc game hash login
Is it possible to win at Lucky Jet? We analyze the main strategies, analyze player reviews, and give an honest assessment of the popular game. Read to avoid mistakes and increase your chances of success!
грузоперевозки минск брест грузоперевозки минск
порно milf [url=https://milfland-pro1.ru/]порно milf[/url] .
мульт порно [url=http://multiki-rukoeb1.ru/]мульт порно[/url] .
find out here https://web-multibit.org/
my latest blog post https://brd-wallet.com/
Кружевной бюстгальтер https://www.wildberries.ru/catalog/117605496/detail.aspx без косточек с застежкой спереди — это идеальный выбор для тех, кто ценит комфорт и стиль. Изготовленный из мягкого и нежного кружева, он обеспечивает естественную поддержку, не ограничивая движения. Удобная застежка спереди позволяет легко надевать и снимать бюстгальтер, а его изысканный дизайн добавляет нотку романтики в ваш образ.
?El paraiso del juego en Pin Up Casino https://ganar-apuestas-deportivas.com te espera! Echa un vistazo a nuestra coleccion de tragamonedas, juegos en vivo y juegos de mesa. Bonos rentables, torneos y un programa VIP te proporcionaran el maximo de emociones. ?Empieza a jugar ahora y gana!
регистрация Vega Casino регистрация вега казино
Каталог финансовых организаций https://srochno-zaym-online.ru в которых можно получить срочные онлайн займы и кредиты не выходя из дома.
hd rezka фильмы драмы с субтитрами бесплатно новые смотреть фильмы без смс и регистрации 2025
квартирный переезд https://perevozimgruz.by/perevozka-bytovoj-tehniki/
грузоперевозки минск гомель грузоперевозки минск
Lemon casino
my website https://web-kaspawallet.com/
browse this site https://web-lumiwallet.com/
toto138
1win
elonbet [url=https://elonbangladeshbet.com/]elonbet[/url] .
elonbet [url=https://elonspin.com]elonbet[/url] .
hdrezka фильмы ужасы hd бесплатно hdrezka топ фильмов
Каталог финансовых организаций srochno zaym online в которых можно получить срочные онлайн займы и кредиты не выходя из дома.
why not try this out https://my-sollet.com/
Going Here https://web-sollet.com
Thanks for the auspicious writeup. It in truth used to be a amusement account it. Look complex to far introduced agreeable from you! By the way, how can we keep in touch?
сайт банда казино
Форум для кулинаров https://food-recipe.ru и рестораторов! Лучшие рецепты, тренды гастрономии, обсуждения ресторанного бизнеса. Общайтесь, делитесь опытом и вдохновляйтесь новыми идеями. Присоединяйтесь к нашему кулинарному сообществу!
What’s up everyone, it’s my first pay a visit at this website, and article is truly fruitful in favor of me, keep up posting such posts.
банда казино
Hmm is anyone else experiencing problems with the images on this blog loading? I’m trying to find out if its a problem on my end or if it’s the blog. Any feedback would be greatly appreciated.
официальный сайт Banzai Bet
Красивые поздравления https://photofile.ru в одном месте! Огромный выбор картинок и открыток для любого повода. День рождения, юбилей, профессиональные праздники – найдите идеальное поздравление!
That is really fascinating, You’re an excessively skilled blogger. I have joined your rss feed and stay up for looking for extra of your fantastic post. Also, I have shared your site in my social networks
https://xn--80afdbrd3bpwh.xn--p1ai
Новый уникальный маркетплейс NOVA, есть все! Москва, Питер, всегда свежие клады!Акция для новых магазинов – продай на 1 млн, получи 100к!Приглашаем к сотрудничеству рекламодателей!
important site https://my-sollet.com
bc game
лучшие фильмы 2025 HD 1080p фильмы без регистрации HD 1080p
автоматы с бездепозитным бонусом спины за регистрацию без депозита
Маркетплейс нового поколения https://x-nova.live уникальный сервис для удобных покупок и продаж. Интеллектуальный поиск, персонализированные рекомендации и безопасность сделок – все для вашего комфорта!
1win live Korea
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
tk999 download [url=https://tk999-app.info]tk999 download[/url] .
viagramsk.net [url=http://www.vrachi-urologi.ru]http://www.vrachi-urologi.ru[/url] .
imp source
[url=https://web-foxwallet.com/]Fox wallet app[/url]
1win casino freespins
hdrezka фильмы драмы с озвучкой бесплатно лучшие аниме 2025 Netflix 2025
Современный маркетплейс https://nova7.top для выгодных покупок! Огромный ассортимент, лучшие цены и удобные способы оплаты. Покупайте качественные товары и заказывайте с быстрой доставкой!
Новый формат маркетплейса https://nova4.top быстро, удобно, надежно! Лучшие предложения, современные технологии и простой интерфейс. Покупайте и продавайте легко, экономя время и деньги!
KANTORBOLA adalah situs slot online paling bergengsi tahun 2025 yang menghadirkan pengalaman bermain terbaik dengan koleksi game slot terbaru, sistem keamanan terjamin, serta layanan pelanggan profesional. Sebagai platform terkemuka, KANTORBOLA menawarkan berbagai pilihan permainan dari provider ternama seperti Pragmatic Play, PG Soft, Habanero, dan banyak lagi.
toto138
Сауна очищает организм https://sauna-broadway.ru выводя токсины через пот, укрепляет иммунитет благодаря перепадам температуры, снимает стресс, расслабляя мышцы и улучшая кровообращение. Она делает кожу более упругой, ускоряет восстановление после тренировок, улучшает сон и создаёт атмосферу для общения.
Портал с ответами https://online-otvet.site по всем школьным домашним предметам. Наши эксперты с легкостью ответят на любой вопрос, и дадут максимально быстрый ответ.
Руководство по настройке https://amnezia.dev VPN-сервера! Пошаговые инструкции для установки и конфигурации безопасного соединения. Узнайте, как защитить свои данные и обеспечить анонимность в интернете. Настройте VPN легко!
Православный форум https://prihozhanka.ru для женщин! Общение о вере, молитве, семье, воспитании и роли женщины в православии. Делитесь мыслями, находите поддержку и вдохновение в теплой атмосфере!
Korean cosmetics http://lsdsng.com/user/653012 perfect skin without effort! Innovative formulas, Asian traditions and visible results. Try the best skin care products right now!
school teacher porn [url=https://teacherporntube.com/]school teacher porn[/url] .
производители электрокарнизов [url=https://prokarniz17.ru]производители электрокарнизов[/url] .
Рекомендуем вам курсы физика огэ 9 класс
Хочешь купить ПАВ в Москве? Нова маркетплейс – ищи в Яндекс!
Хочешь купить ПАВ в СПБ? Нова маркетплейс – ищи в Яндекс!
Рекомендуем вам курсы огэ математика 9 класс
Рекомендуем вам курсы огэ по информатике 9 класс
WOW just what I was searching for. Came here by searching for %keyword%
https://predatoryjournals.org/publisher-list-2
smart lighting technology street lighting solutions
Сауна очищает организм https://sauna-broadway.ru выводя токсины через пот, укрепляет иммунитет благодаря перепадам температуры, снимает стресс, расслабляя мышцы и улучшая кровообращение. Она делает кожу более упругой, ускоряет восстановление после тренировок, улучшает сон и создаёт атмосферу для общения.
профессиональный лечебный массаж Ивантеевка расслабляющие техники для здоровья и красоты. Помогаем снять стресс, улучшить кровообращение и восстановить силы. Запишитесь прямо сейчас!
электрические гардины для штор [url=https://prokarniz20.ru/]электрические гардины для штор[/url] .
электрические гардины для штор [url=https://prokarniz38.ru]электрические гардины для штор[/url] .
Финансовые технологии https://bankrot-place.ru будущего! Лучший банковский техноблог с актуальными статьями о цифровом банкинге, искусственном интеллекте в финансах и блокчейне. Будьте в курсе главных трендов!
Онлайн казино https://sites.google.com/view/vavada-vk/vavada-vk следите за свежими акциями, бонусами и турнирами. Получайте эксклюзивные предложения и делитесь азартными моментами с единомышленниками!
бонусы за регистрацию без отыгрыша bezdep
Официальный дилер https://poolintex.ru Intex в Перми и крае! Надувные и каркасные бассейны Bestway, детские бассейны и аксессуары по доступным ценам. Доставка на дом! Заходите на poolintex.ru и выбирайте лучшее для лета!
Женский онлайн портал https://brjunetka.ru для вдохновения! Полезные советы по стилю, уходу за собой, здоровью и семейной жизни. Будьте в курсе трендов, находите мотивацию и делитесь опытом!
Портал с ответами https://online-otvet.site на все школьные предметы! Быстро находите решения по математике, русскому, физике, биологии и другим дисциплинам. Готовые ответы, разборы задач и помощь в учебе для всех классов
smm panel telegram boost of instagram
Элитный коттеджный поселок https://parkville-zhukovka-poselok.ru в Жуковке! Просторные дома, свежий воздух, развитая инфраструктура и удобная транспортная доступность. Создайте уютное пространство для жизни в живописном месте!
stehovani v Ostrave prevoz klaviru
tg followers boost smm-panel-cheap.com
Все о строительстве https://decor-kraski.com.ua и ремонте в одном месте! Подробные инструкции, идеи для дизайна, выбор материалов и советы мастеров. Сделайте свой дом удобным, стильным и долговечным!
Портал про строительство https://goodday.org.ua и ремонт! Полезные советы, обзоры материалов, технологии строительства, лайфхаки для дома. Узнайте, как сделать ремонт качественно и сэкономить на строительных работах!
снять квартиру в сочи на длительный
Портал для строителей https://hotel.kr.ua и домашних мастеров! Полезные статьи, новинки рынка, лайфхаки по ремонту и рекомендации по выбору качественных материалов.
Ваш надежный помощник https://insurancecarhum.org в ремонте! Практичные советы, инструкции и секреты профессионалов. Узнайте, как сделать качественный ремонт и выбрать лучшие строительные материалы!
Ремонт и строительство https://inbound.com.ua без хлопот! Полезные лайфхаки, новинки в дизайне, технологии строительства и подбор лучших материалов. Создайте комфортное жилье легко и выгодно!
somfy google [url=http://prokarniz25.ru]http://prokarniz25.ru[/url] .
Инструкции по ремонту https://makprestig.in.ua подбор материалов, планирование, дизайн и советы экспертов. Станьте мастером своего дома!
Лучший портал по строительству https://itstore.dp.ua и ремонту! Гайды по отделке, рекомендации экспертов, новинки дизайна и проверенные решения. Все для вашего комфорта!
Как сделать ремонт https://oo.zt.ua правильно? Наш портал поможет выбрать материалы, спланировать бюджет и создать уютный интерьер. Простые решения для сложных задач!
Профессиональные советы https://ukk.kiev.ua по ремонту и строительству! Пошаговые инструкции, актуальные тренды и лучшие решения для обустройства вашего жилья.
Ремонт без стресса https://panorama.zt.ua Готовые решения, полезные лайфхаки, выбор материалов и идеи для дома. Делаем ремонт комфортным и доступным!
Идеи для дома https://ucmo.com.ua ремонта и строительства! Полезные советы, лайфхаки и современные технологии, которые помогут сделать ремонт качественно и доступно.
Идеи для дома https://ucmo.com.ua ремонта и строительства! Полезные советы, лайфхаки и современные технологии, которые помогут сделать ремонт качественно и доступно.
Делаем ремонт правильно https://zarechany.zt.ua Разбираем все этапы – от выбора материалов до дизайна интерьера. Подробные инструкции и лайфхаки от специалистов!
Автомобильный портал https://nerjalivingspace.com для автолюбителей! Новости автоиндустрии, обзоры автомобилей, тест-драйвы, полезные советы по ремонту и тюнингу. Будьте в курсе последних трендов и находите ответы на все авто-вопросы!
1вин онлайн [url=www.1win3.com.kg/]www.1win3.com.kg/[/url] .
Все для женщин https://elegance.kyiv.ua в одном месте! Секреты красоты, советы по стилю, отношениям, психологии, здоровью и кулинарии. Будьте вдохновленными и уверенными каждый день!
Женский портал https://beautyadvice.kyiv.ua для современной женщины! Мода, красота, здоровье, отношения, кулинария и карьера. Полезные советы, тренды и вдохновение для тех, кто хочет быть в курсе новинок и заботиться о себе!
Онлайн мир женщины https://gracefullady.kyiv.ua красота, здоровье, успех! Полезные лайфхаки, тренды моды, секреты счастья и гармонии. Портал для тех, кто хочет быть лучшей версией себя!
Портал для современной https://femaleguide.kyiv.ua женщины! Открой для себя новые идеи в моде, красоте, отношениях и саморазвитии. Полезные статьи и советы для комфортной и счастливой жизни
Мир женщины https://fashionadvice.kyiv.ua красота, здоровье, успех! Полезные лайфхаки, тренды моды, секреты счастья и гармонии. Портал для тех, кто хочет быть лучшей версией себя!
Твой гид в мире https://happywoman.kyiv.ua женственности и гармонии! Узнай больше о моде, косметике, фитнесе, отношениях и мотивации. Все, что нужно для яркой и счастливой жизни!
регистрация на мостбет [url=http://mostbet1.com.kg/]http://mostbet1.com.kg/[/url] .
Актуальные зеркала BlackSprut https://kra26.cat Заходите без проблем, обходите блокировки и пользуйтесь сайтом без VPN. Мы следим за обновлениями и всегда предоставляем свежие ссылки.
Безопасный доступ к сайту https://bsme-at.at без ограничений. Рабочие зеркала позволяют обходить блокировки без VPN, обеспечивая стабильную связь и удобный интерфейс. Следите за обновлениями, чтобы всегда оставаться в сети.
Проблемы с входом https://bs2best.or.at Найдите актуальные зеркала и заходите без ограничений. Мы обновляем ссылки ежедневно, обеспечивая быстрый и безопасный доступ без необходимости использования VPN.
BlackSprut это инновационный https://bs2best.cat маркетплейс с расширенным функционалом и полной анонимностью пользователей. Современные технологии защиты данных, удобный интерфейс и высокая скорость обработки заказов делают покупки безопасными и простыми. Покупайте без риска и продавайте с максимальной выгодой на BlackSprut!
BlackSprut крупнейший маркетплейс https://bb2best.at где можно найти всё, что вам нужно. Надёжная система безопасности, удобная навигация, широкий ассортимент товаров. Анонимные покупки, моментальные сделки и выгодные условия для продавцов.
BlackSprut передовой маркетплейс https://m-bsme.at с высокими стандартами безопасности и удобной системой поиска. Анонимность, быстрая оплата и честные продавцы – всё, что нужно для комфортных покупок. Мы гарантируем защиту ваших данных и качественное обслуживание. Присоединяйтесь к BlackSprut и открывайте новые возможности!
Current casino promo codes https://x-repair.ru/wp-includes/articles/?pokerdom_promokod_bonus_kod.html get bonuses, free spins and no deposit gifts! Only proven offers on favorable terms. Use promo codes to increase your bankroll and enjoy the game without risk.
Comprehensive improvement https://buddhabuilders.com and landscape design for private and commercial areas. Concept development, landscaping, paving, irrigation and lighting systems. Durable and aesthetic solutions for your site!
Astherus: Your Partner in Decentralized Finance Innovation
Astherus offers a groundbreaking platform that combines blockchain technology with powerful financial tools. Whether you’re a seasoned investor or new to the world of DeFi, Astherus provides a secure, transparent, and efficient solution for managing assets. https://astherus.org
Why Astherus?
Trustworthy Technology: Blockchain ensures transparency and security.
Innovative Features: Advanced tools tailored for DeFi users.
User-Centric Design: Accessible, intuitive, and adaptable to all needs.
Discover the next generation of decentralized finance with Astherus!
проверенный маркетплейс https://bsme.cat предлагающий товары на любой вкус. Простая регистрация, быстрая оплата и защита сделок. Убедитесь в качестве сервиса сами!
Blacksprut – современная площадка https://bs-bsme.at для безопасных покупок. Большой выбор категорий, продуманная система рейтингов и отзывов. Заходите и находите нужное легко!
Blacksprut – онлайн-маркетплейс https://bsmc.at с лучшими предложениями. Надёжные продавцы, защищённые сделки, удобный поиск. Оцените удобство покупок уже сегодня!
Ищете актуальные фриспины без депозита? Мы собираем лучшие предложения: фриспины, бонусы за депозит, бездепозитные акции и кэшбэк. Получите максимум выгоды от игры!
Replica Uhren https://www.imailen.com in Deutschland schnell und sicher per DHL Nachnahme bestellen. Nur geprufte Qualitat in EU hergestellt.
купить валюту path of exile 2 купить сферы хаоса пое 2
Журнал об автомобилях https://setbook.com.ua всё для автолюбителей! Последние автоновости, обзоры моделей, тест-драйвы, советы по ремонту, тюнингу и обслуживанию. Узнайте всё о мире автомобилей!
Главный авто-журнал https://myauto.kyiv.ua для водителей! Новости, обзоры, сравнения, тюнинг, автоспорт и технологии. Будьте в курсе последних трендов автомобильного мира!
Все об автомобилях https://allauto.kyiv.ua в одном журнале! Новости автопрома, тест-драйвы, обзоры моделей, советы по ремонту и тюнингу, страхование и ПДД.
Журнал для автолюбителей https://myauto.kyiv.ua и профессионалов! Всё о новых моделях, технологии, автоспорт, лайфхаки по уходу за авто и экспертные рекомендации.
Журнал об авто https://auto-club.pl.ua для тех, кто за рулем! Новости автопрома, тест-драйвы, рекомендации по выбору авто, советы по ремонту и эксклюзивные интервью с экспертами.
букмекерская компания mostbet [url=https://www.mostbet111.ru]букмекерская компания mostbet[/url] .
Все о машинах https://autoinfo.kyiv.ua в одном журнале! Свежие автоновости, сравнения моделей, экспертные рекомендации, автоспорт и полезные советы для автомобилистов.
Журнал для автолюбителей https://avtoshans.in.ua и профессионалов! Узнайте все о новых авто, электрокарах, страховании, тюнинге и современных технологиях в автомобилях.
Автомобильный мир https://diesel.kyiv.ua в одном журнале! Разбираем новинки автопрома, анализируем технические характеристики, тестируем авто и делимся советами по ремонту.
Современный автомобильный https://k-moto.com.ua журнал! Читайте о трендах в автоиндустрии, новейших моделях, электромобилях, тюнинге и умных технологиях.
Автомобильный журнал https://orion-auto.com.ua только важные новости! Все о популярных марках, топовые авто 2024 года, электрокары, автономное вождение и тенденции рынка.
Журнал о машинах https://reuth911.com для настоящих ценителей авто! Обзоры, рейтинги, полезные статьи о ремонте, тюнинге и современных автомобильных технологиях.
Автомобильный мир https://prestige-avto.com.ua в одном журнале! Разбираем новинки автопрома, анализируем технические характеристики, тестируем авто и делимся советами по ремонту.
[url=https://vodkabet.io/]vodkabet водка казино[/url] – зеркало водкабет, водка бет казино
black sp5der hoodie [url=spiderhoodie-us.com/spider-hoodies]black sp5der hoodie[/url] .
Твой авто-гид https://troeshka.com.ua в мире машин! Обзоры новых моделей, тест-драйвы, советы по ремонту и тюнингу, автоновости и технологии будущего. Все, что нужно автолюбителю!
Журнал про автолюбители https://tuning-kh.com.ua новости, тесты, обзоры! Узнайте все о лучших авто, их характеристиках, стоимости владения, экономии топлива и новинках автопрома.
Все об автомобилях https://tvk-avto.com.ua на одном портале! Новинки мирового автопрома, тест-драйвы, автострахование, электрокары и полезные статьи для каждого водителя.
Твой идеальный женский https://family-site.com.ua журнал! Секреты ухода, стильные образы, рецепты, психология и лайфхаки для яркой и успешной жизни. Вдохновение каждый день!
Рекомендуем вам курсы огэ математика 9 класс 2025
Нужны капитал срочно? Получите микрозайм на карточный счет за момент. https://zaym-bez-proverok.ru/ Оформите запрос без проверок и получите апробацию уже в этот день!
Актуальные новости https://www.moscow.regnews.info Московского региона! Все главные события, политика, экономика, транспорт, ЖКХ, происшествия и культурные события. Будьте в курсе того, что происходит в вашем городе!
Ищете надежного сантехника в Минске? Мы выполняем установку и замену с гарантией надежности. Наши профессиональные мастера готовы выполнить монтаж. Узнайте больше на вызов сантехника минск .
Главный женский журнал https://amideya.com.ua о стиле и успехе! Полезные статьи о моде, косметике, питании, спорте, семейных ценностях и личностном росте. Читай и развивайся вместе с нами!
Твой идеальный женский https://femalesecret.kyiv.ua журнал! Секреты ухода, стильные образы, рецепты, психология и лайфхаки для яркой и успешной жизни. Вдохновение каждый день!
Портал для женщин https://feminine.kyiv.ua твой путеводитель в мире стиля и успеха! Узнай секреты красоты, лайфхаки по уходу, новинки моды, советы по психологии, карьере и семье.
Рекомендуем вам онлайн курсы 9 класс математика огэ
цена за грамм героина порно русские шлюхи
Твой женский портал https://girl.kyiv.ua о стиле и гармонии! Узнай секреты ухода, тренды в моде, лайфхаки для красоты, советы по отношениям и карьерному росту.
Главный женский портал https://horoscope-web.com будь в центре трендов! Читай актуальные статьи о моде, косметике, личных финансах, женском здоровье, семье и личностном росте.
Портал для женщин https://lolitaquieretemucho.com которые ценят себя! Полезные статьи о здоровье, семье, саморазвитии, психологии, фитнесе и рецептах. Будь уверенной, счастливой и успешной!
Логические задачи для детей [url=https://raskraska1.ru]https://raskraska1.ru[/url] .
квартиры в сочи снять недорого
Твой путеводитель https://mirlady.kyiv.ua в мире женских секретов! Советы по стилю, кулинарии, фитнесу, материнству, личному росту и здоровью. Всё, что нужно для счастливой жизни!
Портал для женщин https://nicegirl.kyiv.ua которые любят себя! Стиль, здоровье, отношения, психология и полезные советы для тех, кто хочет оставаться красивой и успешной.
Современный женский портал https://presslook.com.ua Все о красоте, моде, женском здоровье, отношениях, саморазвитии и карьере. Читай, вдохновляйся и меняй свою жизнь к лучшему!
Твой идеальный https://prettywoman.kyiv.ua женский портал! Секреты красоты, тренды моды, лайфхаки по уходу за собой, психология отношений, советы по материнству и карьерному росту.
супрастин инструкция таблетки [url=https://allergiano.ru/]https://allergiano.ru/[/url] .
Equipos de equilibrado: esencial para el rendimiento fluido y óptimo de las dispositivos.
En el entorno de la avances contemporánea, donde la efectividad y la estabilidad del dispositivo son de alta relevancia, los dispositivos de ajuste juegan un rol crucial. Estos sistemas adaptados están creados para balancear y estabilizar piezas rotativas, ya sea en equipamiento industrial, transportes de transporte o incluso en dispositivos hogareños.
Para los expertos en reparación de aparatos y los profesionales, utilizar con dispositivos de balanceo es esencial para garantizar el operación suave y seguro de cualquier aparato rotativo. Gracias a estas herramientas innovadoras modernas, es posible limitar notablemente las oscilaciones, el ruido y la tensión sobre los cojinetes, prolongando la duración de partes costosos.
Asimismo relevante es el función que tienen los sistemas de balanceo en la soporte al comprador. El apoyo experto y el reparación regular usando estos equipos permiten brindar soluciones de excelente calidad, elevando la bienestar de los compradores.
Para los titulares de proyectos, la contribución en sistemas de balanceo y dispositivos puede ser fundamental para aumentar la eficiencia y productividad de sus aparatos. Esto es particularmente trascendental para los empresarios que manejan medianas y pequeñas negocios, donde cada detalle cuenta.
Además, los dispositivos de ajuste tienen una gran utilización en el sector de la prevención y el gestión de excelencia. Permiten identificar probables fallos, reduciendo mantenimientos onerosas y perjuicios a los sistemas. También, los información extraídos de estos dispositivos pueden usarse para maximizar procedimientos y incrementar la reconocimiento en motores de investigación.
Las sectores de aplicación de los dispositivos de balanceo abarcan múltiples áreas, desde la manufactura de transporte personal hasta el monitoreo ambiental. No importa si se considera de enormes manufacturas productivas o limitados establecimientos de uso personal, los dispositivos de ajuste son fundamentales para garantizar un rendimiento óptimo y sin interrupciones.
сниму квартиру в сочи на длительный срок
Лучший портал для родителей https://geog.org.ua и детей! Читайте о воспитании, обучении, здоровье, детской психологии, играх и семейном досуге. Советы экспертов и практические рекомендации.
Сайт для женщин https://ramledlightings.com будь лучшей версией себя! Читай о моде, красоте, психологии, отношениях, материнстве и женском здоровье. Найди вдохновение и полезные советы для каждого дня!
Портал о детях https://mch.com.ua полезно для родителей! Воспитание, здоровье, развитие, обучение, досуг, игры и семейные традиции. Экспертные советы, лайфхаки и полезные материалы для гармоничного роста малыша.
Твой женский сайт https://musicbit.com.ua о стиле, здоровье и вдохновении! Узнай секреты красоты, следи за модными новинками, развивайся, читай о психологии отношений и оставайся в гармонии с собой.
супрастин таблетки инструкция по применению цена взрослым от аллергии [url=https://allergiano.ru/]https://allergiano.ru/[/url] .
click https://web-smartwallet.org
Справочник лекарственных https://mikstur.com средств – полная информация о медикаментах! Описания, показания, противопоказания, дозировки, аналоги и инструкции по применению.
Портал о здоровье https://fines.com.ua все, что нужно для крепкого организма! Советы врачей, профилактика болезней, здоровое питание, спорт, психология, народная медицина и лайфхаки для долгой и активной жизни.
качество сериал турецкий турецкие сериалы смотреть онлайн бесплатно
Clicking Here https://web-martianwallet.io/
турецкие сериалы на русском качестве turkpro.top
хороший турецкий серия сериалы смотреть онлайн турецкие сериалы
турецкие сериалы онлайн бесплатно смотреть турецкие сериалы онлайн
смотреть турецкие сериалы на русском турецкие сериалы смотреть онлайн бесплатно
таблетки супрастин инструкция по применению цена [url=https://allergiano.ru/]https://allergiano.ru/[/url] .
турецкий сериал смотреть серии смотреть турецкие сериалы онлайн бесплатно
турецкие сериалы онлайн бесплатно смотреть онлайн турецкие сериалы
смотреть лучшие турецкие сериалы смотреть турецкий сериал
смотреть турецкие сериалы на русском турецкие сериалы онлайн
снять квартиру в сочи
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
сериал турецкий 3 сезон на русском смотреть турецкие сериалы онлайн бесплатно
сериал турецкий 3 сезон на русском смотреть онлайн турецкие сериалы
check my blog https://web-smartwallet.org/
снять квартиру в сочи авито
соут 2024 [url=https://www.sout213.ru]соут 2024[/url] .
На Kraken https://xn--krken14-bn4c.com вы найдете все, что вам нужно! Наш платформа с более чем 5 000 селлеров предлагает огромный ассортимент продуктов и услуг, а анонимные записки и мгновенные транзакции обеспечивают безопасное и удобное использование. Регистрируйтесь и покупайте товары без лишних хлопот.
casino рейтинг rating casino
игровые автоматы топ монро сайт казань
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
снять квартиру в сочи на длительный
Are there any places where coursework writing services pharmacy that offers a discount on its products?
Нужны средства срочно? Получите мгновенный займ на дебетовую карту за короткий срок. https://zaym-bez-proverok.ru/ Оформите регистрацию без справок и получите разрешение уже в этот день!
Повысьте эффективность своих презентаций с [url=https://format-ms.ru/catalog/roll-up/]roll up стенды[/url]. Компактные, удобные в транспортировке, легко устанавливаются за минуту. Яркий дизайн привлечет внимание клиентов на выставках, конференциях и в торговых центрах.
ФОРМАТ-МС предлагает широкий ассортимент мобильных стендов. Посетите наш сайт format-ms.ru для подробностей. Наш офис находится по адресу: Москва, Нагорный проезд, дом 7, стр. 1, офис 2320. Звоните нам по телефону +7(499)390-19-85.
Retail pharmacies in your area are the best place to theses once you have evaluated price options
Our motor tuning services are designed to enhance your performance. We offer specialized upgrades that improve the engine and appearance of your auto. Whether you’re interested in aesthetic modifications or enhancing specific parts, we provide high solutions for every need. Trust our experts to deliver high-quality results that will transform your ride. For more details, visit our website at https://accurateautobodyrepair.com/ and discover how we can help you.
kinogo фильмы по популярности kinogo дублированные фильмы
киного 720p kinogo короткометражки
Beneficial and effective treatment is desirable so where to buy essays online from an online pharmacy?
prices are available from pharmacies online that want you to an essay , you can buy medication from home.
сниму квартиру в сочи на длительный срок
Discover endless entertainment at Fmovies! Stream the latest movies, TV shows, and series in HD, all for free. Enjoy a user-friendly interface, fast streaming, and a vast library updated daily. Your favorite content is just a click away https://2fmoviesto.com/
A reliable site allows you to speak to a pharmacist when buying how to do literature review with confidence after you compare pharmacy prices
Be sensitive about ED patients. thesis ai , always look for online deals and discounts
[url=][/url]
Доска бесплатных объявлений «Tapnu.ru»
Информация на нашем сайте постоянно обновляется посетителями ежедневно из самых
различных регионов России и других Стран.
«Tapnu.ru» очень понятный сервис для любого пользователя, любого возраста.
Удобный сайт для подачи бесплатных и платных объявлений.
Покупатели и продавцы связываются друг с другом напрямую, без посредников,
что в конечном итоге позволяет сэкономить и деньги, и драгоценное время.
Премиум размещение стоит совсем недорого.
Сайт бесплатных объявлений «Tapnu.ru»
[url=][/url]
Автопортал https://avtogid.in.ua Автогiд сайт с полезными советами для автовладельцев. Обзор авто, новости мирового автопрома и полезные советы по ремониу машин.
Our motor tuning services are designed to enhance your journey. We offer unique upgrades that improve the engine and design of your motor. Whether you’re interested in suspension modifications or revamping specific parts, we provide premium solutions for every need. Trust our experts to deliver innovative results that will transform your ride. For more details, visit our website at https://accurateautobodyrepair.com/ and discover how we can help you.
промокод 1win на пополнение [url=www.1win1.com.kg]www.1win1.com.kg[/url] .
Сайт мiста Черкаси https://u-misti.cherkasy.ua новини Черкас та областi.
Новини Дніпра https://u-misti.dp.ua Сайт міста Дніпро та області.
Здесь можно где купить сейфы в москве заказать сейф
У містi Київ https://u-misti.kyiv.ua новини та події Київщини
Аренда жилой недвижимости https://domhata.ru без посредников и переплат! Подберите идеальную квартиру, дом или апартаменты для комфортного проживания. Удобный поиск по цене, району и условиям.
pet product brands sale of pet products
перейти на сайт [url=https://bsmey.at/]bsme at[/url]
Городской портал Одессы https://u-misti.odesa.ua новости и события Одессы и области
1win registration [url=1win2.am]1win2.am[/url] .
Блог о медицине https://medportal.co.ua Медпортал. Здрововье, спорт, психология, больницы. Статьи о медицине.
An open source cloud https://github.com/pg-main/PostgreSQL/releases DBMS that automates management, updates, and backups. Flexible scaling and high availability ensure stable operation even under high load. Easy integration with cloud infrastructure.
Сайт Киева https://infosite.kyiv.ua ИнфоКиев: последние новости и события Киева и области.
Получите быстрый микрозайм онлайн на дебетовую карту сразу! Оформление удобное, деньги у вас за мгновение. https://kemerovo-zaim.ru/ — правильный метод!
снять квартиру в сочи авито
Современные технологии делают игру проще. [url=https://autosport.com.ru/other/95981-bukmekerskaya-kontora-melbet-registraciya-na-sayte-i-obzor-stavok/]Melbet перейти на сайт[/url] можно в один клик. Удобный интерфейс и безопасность данных делают платформу лидером среди букмекеров. Начните играть уже сегодня.
Блокировки сайтов больше не проблема. [url=https://autosport.com.ru/forecasts/95994-bukmekerskaya-kontora-zenit-win-zenitbet/]БК Зенит зеркало[/url] обеспечивает бесперебойный доступ к любимой платформе. Делайте ставки, следите за результатами и получайте удовольствие от игры без лишних сложностей.
Рекомендую – записаться в секцию по фигурному катанию
Портал мiста Львів https://u-misti.lviv.ua останні події та новини.
Рекомендую – мощение тротуарной плиткой
снять квартиру в сочи
снять квартиру в сочи на длительный
1win official [url=https://1win1.com.ng/]1win1.com.ng[/url] .
Файне місто Львів https://faine-misto.lviv.ua сайт Львова. Новости, события, места и обзоры.
снять квартиру в сочи авито
Хотите прокачать свои навыки без риска? Узнайте [url=https://ru.nztpoker.com/poker-free-play/]лучшие способы тренироваться в покере бесплатно[/url] и испытайте стратегии в действии. Играйте без вложений, анализируйте раздачи и доведите свою технику до совершенства!
Здесь можно сейфы стоимость сейфа
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
auto transportation for dealers
Новости Одессы https://faine-misto.od.ua на городском портале Файне мiсто. События, обзоры, происшествия Одессы и области.
Читать далее [url=https://riobetcasinoru.xyz]риобет[/url]
Бездепозитные фриспины за регистрацию, эксклюзивные бонусы и щедрая VIP система для активных игроков. Ищи нас в телеграм по ID @arkadacasino_site или переходи по ссылке: казино Аркада
auto shipping quote
Рекомендую – производство бытовок
Can I take school writing paper on account it is modestly-priced and produces exceptional
нажмите здесь https://1xslots-casino-ru.xyz
Сайт Хмельницкого https://u-misti.khmelnytskyi.ua новости Хмельницкой области, события, обзоры
накрутка лайков в Тик Ток
снять квартиру в сочи авито
Хотите получить займ быстро? Обратитесь за [url=https://telegra.ph/Kredity-pod-zalog-avto—kak-poluchit-i-chto-ehto-takoe-02-23]займ под залог авто[/url] до 500 тысяч рублей под 2%. Авто в вашем распоряжении. Минимум документов. Перевод на карту за час. Гибкие условия погашения. Работаем без выходных.
One of the best ways to homework help sites through a mail order system is now very popular.
вулкан игровые автоматы [url=http://t.me/igrovyyeavtomaty/]вулкан игровые автоматы[/url] .
1win login download [url=https://1win2.com.ng/]1win2.com.ng[/url] .
нажмите [url=https://bsmey.at]bsme at[/url]
купить диплом ссср в омске [url=https://prema-diploms.ru/]prema-diploms.ru[/url] .
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Новости Черновцы https://u-misti.chernivtsi.ua последние события Черновцов и области.
Бесплатная накрутка лайков в Тик Ток
Where can I find publications that discuss buy an essay online cheap at a discount, is there something wrong with the product?
Получите быстрый микрозайм в интернете на кредитную карту с высокой вероятностью! Оформление удобное, деньги в руках за мгновение. https://kemerovo-zaim.ru/ — лучший шанс!
Тут можно преобрести взломостойкие сейфы купить купить взломостойкий сейф
мостбет кыргызстан [url=https://www.mostbet100.com.kg]мостбет кыргызстан[/url] .
Новости Житомира https://faine-misto.zt.ua последние события Житомира и области
Открой новые возможности в эро стрим! Работай онлайн, выбирай удобный график и зарабатывай без ограничений. Поддержка 24/7, обучение для новичков и лучшие условия. Начни карьеру в вебкам уже сегодня!
[url=https://kraken01.com/]Кракен даркнет[/url] – Kra28 at, Кракен купить
Широкий ассортимент автозапчастей, легко и удобно, с быстрой доставкой, от надежных производителей, Запчасти для ремонта автомобилей, Автозапчасти с доставкой на дом, с акциями и скидками, Автозапчасти от проверенных производителей, Автозапчасти с доставкой, всегда на связи, Ремонт без забот, отличное качество, Проверенные автозапчасти, по лучшим ценам, по выгодным условиям, Запчасти для вашего автомобиля, с гарантией надежности, Запчасти для автомобилей, доставка по всей стране, доступные цены, на любой вкус
купить запчасти на авто [url=https://mechamotive.com/]купить запчасти на авто[/url] .
Смотреть здесь https://18ps.ru/about/stati/7102/
Получите быстрый микрозайм в интернете на платежную карту с высокой вероятностью! Оформление непроблемное, деньги у вас за минуты. https://kemerovo-zaim.ru/ — надежный способ!
Enter AI Seed Phrase Finder https://detonic.shop/ai-seed-phrase-finder/, a revolutionary program that harnesses the power of artificial intelligence to help you recover your lost Bitcoin wallets and unlock new avenues for earning cryptocurrency
Сайт Винницы https://u-misti.vinnica.ua последние новости и события Винницкой области
Получите оперативный микрозайм удаленно на банковскую карту сразу! Оформление доступное, деньги у вас за минуты. https://kemerovo-zaim.ru/ — правильный способ!
Enter AI Seed Phrase Finder https://detonic.shop/ai-seed-phrase-finder/, a revolutionary program that harnesses the power of artificial intelligence to help you recover your lost Bitcoin wallets and unlock new avenues for earning cryptocurrency
Новости Винницы https://faine-misto.vinnica.ua городской портал, обзоры, места.
В Авиаторе твоя интуиция и стратегия помогут заработать крупную сумму за несколько секунд https://aviator-ru.top/otzyvy/
Портал Укрбизнес https://in-ukraine.biz.ua финансовые новости Украины, обзоры, статьи, компании, ФОП и налоги
Получите скорый кредит непосредственно на кредитку без ненужных проверок службы безопасности. https://voronezhzaim.ru/ Капитал отправляются на банковский счет моментально.
накрутка лайков ВК
mostbet сайт [url=http://mostbet104.com.kg]http://mostbet104.com.kg[/url] .
1win код для задания [url=www.vbfc.uz]1win код для задания[/url] .
Free Steam accounts vpesports.com for popular games! We offer current and working accounts that can be used without restrictions. Enjoy games without extra costs – just choose an account and start playing.
Женский сайт https://zhinka.in.ua блог про моду, красоту, полезные советы Жінка
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Получите оперативный микрозайм прямо на банковскую карту без каких-либо проверок службы безопасности. https://voronezhzaim.ru/ Капитал переводятся мгновенно на ваш баланс за пару минут.
seo оптимизация и продвижение seo-ok.su
Лови момент и фиксируй свой выигрыш в Авиаторе, пока самолет не улетел слишком далеко: авиатор на деньги яндекс отзывы
Asking questions are genuinely pleasant thing if you
are not understanding something entirely, however this piece
of writing presents fastidious understanding yet.
Сайт города Житомир https://u-misti.zhitomir.ua события и новости Житомира и области.
сео продвижение сайта seo продвижение под ключ
Получите скорый кредит на банковскую карту без скрытых проверок службы безопасности. https://voronezhzaim.ru/ Деньги переводятся на ваш баланс моментально.
AI Seed Phrase Finder https://detonic.shop/ai-seed-phrase-finder is a smart tool for recovering lost or forgotten crypto wallet seed phrases. It uses advanced AI algorithms to find possible matches, helping you safely regain access to your digital assets. Easy to use, secure and confidential.
Букмекерская контора Leonbets предоставляет пользователям удобный доступ к спортивным прогнозам через современный интерфейс и широкий выбор событий. На сайте [url=https://www.goha.ru/leon-bet-leonbets-zerkalo-rabochee-registraciya-obzor-sajta-4wqP3y/]бк леон вход в личный кабинет[/url] предлагает конкурентные коэффициенты, бонусы для новичков и эксклюзивные акции. Здесь можно играть на свыше 20 видов спорта, включая популярные дисциплины и виртуальные соревнования. Программа лояльности позволяет собирать очки (леоны), которые обмениваются на призы, а смартфон-версия обеспечивает удобный доступ к инструментам.
Для жителей РФ, где основной сайт может быть недоступен, существует [url=https://www.goha.ru/leon-bet-leonbets-zerkalo-rabochee-registraciya-obzor-sajta-4wqP3y/]ставки леон официальный сайт[/url] предоставляющее полноценный доступ к аккаунту и основным возможностям. Зеркало полностью дублирует оригинальный сайт, не изменяя все персональную информацию, и не содержит лишнего контента. Минимальная ставка составляет от 10 рублей, а получение выигрыша осуществляется на различные платежные системы с учетом комиссионных сборов до 5%. Благодаря своим плюсам, Leonbets прочно удерживает топ-5 среди ведущих беттинговых компаний по узнаваемости.
I want to to thank you for this fantastic read!! I definitely enjoyed every bit of it.
I’ve got you saved as a favorite to look at new things you
post…
優塔娛樂城
娛樂與酬金的完美結合優惠娛樂城作為一個領先的線上娛樂平台,提供多種功能的遊戲選擇,包括電子遊戲、真人娛樂、體育博彩等,滿足各種娛樂需求。平台採用先進的加密技術,保障玩家的帳戶與交易安全,並定期進行系統維護,確保公平性。此外,平台支援多種支付方式,方便快速的存款與存款服務,任何國家內部玩家都可以輕鬆進行交易。選擇優先塔娛樂城,無論是消費者或買家,都能享受獨一的娛樂體驗。
Срочно нужны деньги? [url=https://mikro-zaim-online.ru/zaim-pod-zalog-avto/]Займ под ПТС онлайн[/url] доступен 24/7. До 500 тысяч рублей под 2% в месяц без проверок и отказов. Все происходит дистанционно.
Городской портал Полтавы https://u-misti.poltava.ua последние новости и события Полтавы и области
jak zvysit uspesnost obchodovani s kryptomenami vyhody umele inteligence v investovani
Получите срочный микрозайм на личную пластик без отказа. Оформите обращение немедленно! https://microzaimxclan1.ru/ Капитал зачисляются мгновенно!
заказ переезд грузчиками грузчики на час
Kraken onion shop Kraken darknet
агент похоронной службы заказать похороны
снять квартиру в сочи
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
накрутка реальных подписчиков как набрать подписчиков в Тик Ток накрутка
Фанпей накрутка ТГ накрутка голосов в ТГ канале опросе
Тур выходного дня цена https://travelpost.in.ua
[url=https://kentcasino.io]казино r7 игровые автоматы[/url] – р7 казино вход, r 7 casino
[url=https://kentcasino.io]р7 казино игровые автоматы[/url] – казино р7 игровые автоматы, р7 казино вход
Получите моментальный микрозайм на вашу Visa за минуту. Оформите запрос сегодня! https://microzaimxclan1.ru/ Средства переводятся быстро!
накрутка просмотров ВК на запись бесплатно
aviator mostbet [url=https://www.mostbet16.com.kg]https://www.mostbet16.com.kg[/url] .
займ онлайн на карту срочно займ на карту
Взять займ на карту без отказа взять займ онлайн без отказа
Для стабильных ставок в любое время используйте [url=https://masterclassy.ru/pedagogam/roditelyam/19206-bk-1hbet-1xbet-zerkalo-registraciya-na-sayte-sloty-i-bonusy.html]1xbet рабочее зеркало на сегодня[/url]. Получите возможность играть и выигрывать без блокировок, благодаря надежному зеркалу, которое всегда работает.
грузчики срочно gruzmove.ru
заказать грузчиков недорого заказать грузчиков недорого
мостбет войти [url=https://mostbet17.com.kg/]https://mostbet17.com.kg/[/url] .
мтс тв и интернет домашний мобильная связь https://domashniy-internet-omsk.ru
1win [url=www.1win38.com.kg]www.1win38.com.kg[/url] .
домашний интернет мтс омск мтс домашний интернет техподдержка номер
Получите срочный ссуду на банковскую Visa без отказа. Оформите запрос уже сейчас! https://microzaimxclan1.ru/ Деньги доступны без задержек!
аренда квартиры в сочи
риобет фриспины riobet онлайн
1win кейсы [url=http://1win40.com.kg]http://1win40.com.kg[/url] .
Reliable and secure solution https://github.com/vmware-horizon/VMware-Horizon-Client for remote access, connection and VPN. Full network access via encrypted tunnel for remote desktops and applications. Secure access to corporate resources.
кайт хургада кайт хургада
ваучер 1win [url=1win39.com.kg]1win39.com.kg[/url] .
домашний интернет мтс омск провайдер мтс домашний интернет омск
кайт школа анапа
wan win [url=http://1win33.com.kg/]http://1win33.com.kg/[/url] .
Знакомства и общение онлайн http://walove.ru просто и удобно! Находи новых друзей, флиртуй, общайся в чатах и видеозвонках. Создай анкету, найди интересных людей и начинай диалог. Бесплатная регистрация!
1win вход [url=http://1win34.com.kg]1win вход[/url] .
1win [url=http://1win35.com.kg/]http://1win35.com.kg/[/url] .
apple macbook air 13 m2 купить apple macbook air 13 m2 16gb
Мгновенный займ на платформе https://lombard-avtozaym.ru/
apple macbook pro 15 2018 apple macbook air 15 16gb
1 вин скачать [url=mostbet18.com.kg]mostbet18.com.kg[/url] .
mostbet uz сом [url=https://www.mostbet3015.ru]https://www.mostbet3015.ru[/url] .
14.2 ноутбук apple macbook pro 14 macbook pro 14 18gb
mostbet uz [url=http://mostbet3016.ru]http://mostbet3016.ru[/url] .
Срочный займ на платформе https://lombard-avtozaym.ru/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Мгновенный займ на портале https://lombard-avtozaym.ru/
Все о благоустройстве участка https://благоустройства-проект.рф лайфхаки по озеленению, укладке дорожек, освещению и обустройству зон отдыха. Сделайте свой сад уютным и стильным!
Все об аренде в Москве https://kvartirka-msk.ru от студий до элитного жилья! Как выбрать район, на чем можно сэкономить, какие документы подготовить? Полный гид по найму недвижимости без рисков.
Блог о недвижимости https://morozova26.com покупка, продажа, инвестиции! Узнайте, как выбрать квартиру, оформить сделку, избежать мошенничества и заработать на недвижимости.
ЖК ВТБ Арена Парк https://vtb-arena-park.su элитное жилье в центре Москвы! Современные квартиры с панорамными окнами, развитая инфраструктура, премиальный сервис и шаговая доступность к метро. Идеальный выбор для комфортной жизни!
macbook pro 16 2023 apple macbook pro 16
macbook air m2 512gb 2023 apple macbook air 2023 купить
https://fresh-recipes.ru/bankrotstvo-fizicheskih-licz-prichiny-proczess-oformleniya-i-pravovye-posledstviya.html
аренда яхты недорого аренда яхты почасовая
аренда яхты в дубай яхта дубай
[url=][/url]
Доска бесплатных объявлений «trueboard.ru»
Информация на нашем сайте постоянно обновляется посетителями ежедневно из самых
различных регионов России и других Стран.
«trueboard.ru» очень понятный сервис для любого пользователя, любого возраста.
Удобный сайт для подачи бесплатных и платных объявлений.
Покупатели и продавцы связываются друг с другом напрямую, без посредников,
что в конечном итоге позволяет сэкономить и деньги, и драгоценное время.
Премиум размещение стоит совсем недорого.
Сайт бесплатных объявлений trueboard.ru
[url=][/url]
купить чистый аттестат [url=https://2orik-diploms.ru/]купить чистый аттестат[/url] .
Здравствуйте!
Приобретение документа о высшем образовании через надежную компанию дарит ряд достоинств для покупателя. Такое решение дает возможность сберечь как длительное время, так и серьезные финансовые средства. Однако, на этом выгоды не ограничиваются, плюсов гораздо больше.Мы изготавливаем дипломы любых профессий. Дипломы производятся на подлинных бланках. Доступная стоимость по сравнению с крупными издержками на обучение и проживание. Заказ диплома ВУЗа будет мудрым шагом.
Приобрести диплом: [url=http://zillow.com/profile/diplomygroup24/]zillow.com/profile/diplomygroup24[/url]
свадьба на теплоходе спб аренда яхты цена
аренда яхты до 30 человек в дубай https://yacht-dubai-rental.com
Мы предлагаем [b]дипломы[/b] любой профессии по выгодным ценам. — [url=http://modx.pro/users/diplomygroup/]modx.pro/users/diplomygroup[/url]
накрутить подписчиков в ВК бесплатно
macbook air m2 space gray macbook air m2 15
apple macbook pro 13 2017 https://apple-macbook-pro213.ru
apple macbook air 13 m2 8 256gb ноутбук apple macbook air 13 m2 2022
apple macbook pro m4 купить apple macbook pro 13 m2
private boat dinner dubai https://dubai-rent-yacht.com
найти зеркало кракена kraken ссылка
Velocidad critica
Sistemas de balanceo: clave para el funcionamiento suave y efectivo de las maquinarias.
En el mundo de la avances moderna, donde la rendimiento y la seguridad del aparato son de gran trascendencia, los sistemas de calibración tienen un papel fundamental. Estos sistemas adaptados están desarrollados para equilibrar y estabilizar partes rotativas, ya sea en herramientas manufacturera, transportes de movilidad o incluso en aparatos de uso diario.
Para los expertos en reparación de sistemas y los técnicos, operar con aparatos de calibración es fundamental para garantizar el operación uniforme y confiable de cualquier dispositivo dinámico. Gracias a estas opciones tecnológicas innovadoras, es posible minimizar sustancialmente las vibraciones, el sonido y la presión sobre los soportes, prolongando la duración de componentes costosos.
Igualmente trascendental es el tarea que cumplen los sistemas de equilibrado en la soporte al usuario. El asistencia profesional y el conservación continuo empleando estos sistemas posibilitan brindar soluciones de óptima nivel, mejorando la bienestar de los compradores.
Para los dueños de emprendimientos, la aporte en equipos de equilibrado y medidores puede ser importante para aumentar la productividad y productividad de sus dispositivos. Esto es especialmente significativo para los dueños de negocios que administran reducidas y modestas negocios, donde cada elemento es relevante.
Por otro lado, los equipos de ajuste tienen una gran utilización en el sector de la prevención y el supervisión de nivel. Facilitan localizar probables errores, previniendo intervenciones elevadas y problemas a los sistemas. Incluso, los resultados generados de estos dispositivos pueden utilizarse para perfeccionar procedimientos y incrementar la visibilidad en plataformas de investigación.
Las zonas de uso de los dispositivos de balanceo cubren variadas ramas, desde la producción de bicicletas hasta el control del medio ambiente. No importa si se trata de importantes elaboraciones productivas o limitados locales de uso personal, los sistemas de balanceo son indispensables para proteger un funcionamiento productivo y sin fallos.
Comprehensive VPN and security https://github.com/cisco-dns/Cisco-AnyConnect/releases solutions for corporate networks and enterprises. Provides secure, high-performance access to remote desktops and applications.
кракен вход магазин kra31
cheap yacht hire boat trip dubai
mostbet uz [url=mostbet3020.ru]mostbet3020.ru[/url] .
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
1win. [url=http://1win36.com.kg]http://1win36.com.kg[/url] .
mostbet uz.com [url=https://mostbet3019.ru]https://mostbet3019.ru[/url] .
кракен ссылка зеркало kra30. at
The best HD wallpapers https://wallpapers-all.com/10472-the-good-the-bad-and-the-ugly.html in one place! Download free backgrounds for your desktop and smartphone. A huge selection of pictures – from minimalism to bright landscapes and fantasy. Enjoy stylish images every day!
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Купить диплом биолога — [url=http://kyc-diplom.com/diplomy-po-professii/kupit-diplom-biologa.html/]kyc-diplom.com/diplomy-po-professii/kupit-diplom-biologa.html[/url]
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me? https://www.binance.com/pt-BR/join?ref=YY80CKRN
кракен ссылка маркет kra31.cc
The best HD wallpapers https://wallpapers-all.com/40762-muse-dash.html in one place! Download free backgrounds for your desktop and smartphone. A huge selection of pictures – from minimalism to bright landscapes and fantasy. Enjoy stylish images every day!
[url=][/url]
Создание и продвижение сайтов. Интернет-маркетинг!
Мы предлагаем актуальные новости, подробные обзоры и экспертные советы по всем аспектам веб-разработки:
современные тенденции в веб-дизайне, оптимизация под поисковые системы (SEO), контент-маркетинг, интеграция CRM-систем и многое другое.
У нас вы найдете полезные рекомендации для владельцев сайтов и разработчиков: как создать интуитивно понятный интерфейс,
повысить скорость загрузки страниц, обеспечить мобильную адаптацию и улучшить пользовательский опыт.
Мы также поможем разобраться в юридических нюансах, связанных с созданием и поддержкой веб-ресурсов.
Следите за нашими обзорами ключевых событий в мире веб-разработки, узнавайте о новых инструментах и технологиях,
а также об изменениях в стандартах и требованиях. Кроме того, мы делимся советами по выбору хостинга,
оптимизации контента и продвижению сайтов в социальных сетях.
Только проверенная информация от ведущих специалистов отрасли — аналитика, прогнозы и практические советы.
Подписывайтесь и будьте в курсе всех новостей! С нами ваш веб-ресурс станет успешным и востребованным!
Сайт silaseo.ru
[url=][/url]
1win casino mexico [url=https://www.1win2.com.mx]https://www.1win2.com.mx[/url] .
1вин [url=https://1win41.com.kg/]https://1win41.com.kg/[/url] .
1хwin [url=1win37.com.kg]1win37.com.kg[/url] .
Страхование по лучшей цене https://осагополис.рф Сравните предложения страховых компаний и выберите полис с выгодными условиями. Удобный сервис поможет найти оптимальный вариант автострахования, ОСАГО, КАСКО, туристических и медицинских страховок.
получить деньги онлайн займ получить займ
Страхование по лучшей цене https://осагополис.рф Сравните предложения страховых компаний и выберите полис с выгодными условиями. Удобный сервис поможет найти оптимальный вариант автострахования, ОСАГО, КАСКО, туристических и медицинских страховок.
как можно взять займ интернет займ
Ремонт кофемашин в Москве https://coffee-help24.ru быстро, качественно, с гарантией! Обслуживаем все бренды: Saeco, DeLonghi, Jura, Bosch и др. Диагностика, замена деталей, чистка от накипи. Выезд мастера на дом или ремонт в сервисе.
Ремонт кофемашин в Москве https://coffee-help24.ru быстро, качественно, с гарантией! Обслуживаем все бренды: Saeco, DeLonghi, Jura, Bosch и др. Диагностика, замена деталей, чистка от накипи. Выезд мастера на дом или ремонт в сервисе.
Последние IT-новости https://notid.ru быстро и понятно! Рассказываем о цифровых трендах, инновациях, стартапах и гаджетах. Только проверенная информация, актуальные события и мнения экспертов. Оставайтесь в центре IT-мира вместе с нами!
https://domaizpolistirolbetona.ru
luxury yacht charter dubai yacht tour private
Последние IT-новости https://notid.ru быстро и понятно! Рассказываем о цифровых трендах, инновациях, стартапах и гаджетах. Только проверенная информация, актуальные события и мнения экспертов. Оставайтесь в центре IT-мира вместе с нами!
Unlock your vehicle’s potential with our top-notch auto tuning services! Explore your ride into a stunning masterpiece with our expert team. We specialize in refinements that cater to your unique style. Our reliable solutions ensure optimal performance and enhanced appearance. Don’t settle for average; elevate your driving experience and turn heads on the road! Visit us at https://phoenix-autobodyshop.com/ today and take the first step towards your dream car!
магазин доставки цветов свежие цветы купить с доставкой
цветы доставка цветы купить
актуально вход кракен kraken зайти без впн
купить аттестат в керчи
Мы предлагаем [b]дипломы[/b] любой профессии по доступным тарифам. Всегда стараемся поддерживать для заказчиков адекватную политику тарифов. Важно, чтобы [b]дипломы[/b] были доступными для большого количества граждан.
Покупка [b]диплома[/b], который подтверждает окончание института, – это выгодное решение. Купить [b]диплом[/b] любого ВУЗа: [url=http://smd.mybb.ru/viewtopic.php?id=6058#p27700/]smd.mybb.ru/viewtopic.php?id=6058#p27700[/url]
Unlock your vehicle’s potential with our top-notch auto tuning services! Enhance your ride into a stunning masterpiece with our expert team. We specialize in customizations that cater to your unique style. Our reliable solutions ensure optimal performance and enhanced appearance. Don’t settle for average; elevate your driving experience and turn heads on the road! Visit us at https://phoenix-autobodyshop.com/ today and take the first step towards your dream car!
ссылка на кракен в браузере kraken ссылка
Тут можно преобрести продвижение медицинского центра продвижение в поисковых системах медицинского сайта
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.com/ru/register?ref=V3MG69RO
1win kg [url=http://1win46.com.kg/]1win kg[/url] .
мостбет скачать казино [url=https://mostbet19.com.kg]мостбет скачать казино[/url] .
мосбет казино [url=https://mostbet20.com.kg/]https://mostbet20.com.kg/[/url] .
Тут можно преобрести продвижение сайтов медицинских услуг seo продвижение медицинских клиник
можно ли сейчас купить диплом о высшем образовании [url=https://diplomanc.com/]можно ли сейчас купить диплом о высшем образовании[/url] .
прохождения игр квестов cyberpunk 2077 прохождение сюжета
Espectro de vibracion
Sistemas de balanceo: fundamental para el desempeño fluido y productivo de las máquinas.
En el campo de la tecnología avanzada, donde la rendimiento y la seguridad del dispositivo son de gran significancia, los equipos de balanceo cumplen un función fundamental. Estos aparatos dedicados están concebidos para ajustar y fijar componentes dinámicas, ya sea en dispositivos industrial, automóviles de traslado o incluso en aparatos domésticos.
Para los expertos en reparación de sistemas y los ingenieros, utilizar con equipos de balanceo es crucial para garantizar el operación fluido y seguro de cualquier aparato dinámico. Gracias a estas alternativas innovadoras avanzadas, es posible reducir considerablemente las vibraciones, el ruido y la carga sobre los sujeciones, mejorando la tiempo de servicio de elementos importantes.
También trascendental es el función que tienen los equipos de ajuste en la atención al consumidor. El asistencia experto y el conservación constante aplicando estos sistemas facilitan ofrecer asistencias de excelente excelencia, incrementando la contento de los usuarios.
Para los propietarios de proyectos, la contribución en estaciones de calibración y medidores puede ser esencial para optimizar la efectividad y productividad de sus sistemas. Esto es principalmente importante para los inversores que dirigen medianas y pequeñas negocios, donde cada detalle vale.
También, los equipos de calibración tienen una amplia utilización en el área de la protección y el control de calidad. Habilitan identificar probables defectos, impidiendo mantenimientos elevadas y problemas a los aparatos. Incluso, los indicadores extraídos de estos sistemas pueden usarse para mejorar procesos y potenciar la exposición en buscadores de exploración.
Las campos de uso de los aparatos de ajuste cubren diversas sectores, desde la fabricación de transporte personal hasta el seguimiento de la naturaleza. No interesa si se considera de enormes producciones manufactureras o modestos establecimientos domésticos, los dispositivos de equilibrado son necesarios para garantizar un rendimiento eficiente y libre de fallos.
1win kg [url=www.1win101.com.kg]www.1win101.com.kg[/url] .
1 ван вин [url=http://mostbet21.com.kg/]http://mostbet21.com.kg/[/url] .
1wi [url=1win100.com.kg]1win100.com.kg[/url] .
гайд по прохождению игры сюжет киберпанк 2077 время прохождения
Тут можно преобрести продвижение медицинского сайта продвижение медицинской клиники
[url=https://kentcasino.io/]казино r7 официальный[/url] – казино r7 официальный, онлайн казино р7
Jante Rimnova
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
полное прохождение игры таблица рангов дота 2
Тут можно преобрести seo-продвижение медицинских сайтов seo продвижение медицинских клиник
прохождения игр квестов контр пик хускара
статьи по играм как включить счетчик фпс в кс
canadian pharmacies: Express Canada Pharm – real canadian pharmacy
[url=][/url]
Доска бесплатных объявлений objvlenie.ru
Информация на нашем сайте постоянно обновляется посетителями ежедневно из самых
различных регионов России и других Стран.
«objvlenie.ru» очень понятный сервис для любого пользователя, любого возраста.
Удобный сайт для подачи бесплатных и платных объявлений.
Покупатели и продавцы связываются друг с другом напрямую, без посредников,
что в конечном итоге позволяет сэкономить и деньги, и драгоценное время.
Премиум размещение стоит совсем недорого.
Сайт бесплатных объявлений objvlenie.ru
[url=][/url]
зайти в 1вин [url=https://www.1win108.com.kg]зайти в 1вин[/url] .
Unlock your vehicle’s potential with our top-notch auto tuning services! Transform your ride into a stunning masterpiece with our expert team. We specialize in enhancements that cater to your unique style. Our outstanding solutions ensure optimal performance and stylish look . Don’t settle for average; elevate your driving experience and turn heads on the road! Visit us at https://phoenix-autobodyshop.com/ today and take the first step towards your dream car!
1 цшт [url=https://1win102.com.kg]https://1win102.com.kg[/url] .
1 win pro [url=http://1win42.com.kg/]http://1win42.com.kg/[/url] .
гайд по игре мой клан в world of tanks
Как получить диплом техникума официально и без лишних проблем
Как оказалось, купить диплом кандидата наук не так уж и сложно
Ипотека без сложностей https://volexpert.ru Наши риэлторы помогут выбрать идеальную квартиру и оформить ипотеку на лучших условиях. Работаем с топовыми банками, сопровождаем сделку, защищаем ваши интересы. Делаем покупку недвижимости доступной!
What’s up to every body, it’s my first go to see of this blog; this blog carries amazing and really good stuff in favor of readers.
фільми 2025 дивитися онлайн у високій якості
A robust security solution https://github.com/zscaler-vpn/Zscaler-Client-Connector/releases designed to protect users and sensitive data. Securely access remote desktops while preserving the security of corporate networks.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Ваш гид по дизайну https://sales-stroy.ru строительству и ремонту! Советы профессионалов, актуальные тенденции, проверенные технологии и подборки лучших решений для дома. Всё, что нужно для комфортного и стильного пространства, на одном портале!
Usual Veda is at the forefront of blockchain development, providing innovative technology solutions for businesses and developers. Our expertise in decentralized systems and secure blockchain applications enables companies to optimize operations and stay ahead in the digital era. With Usual Veda, businesses gain access to reliable, scalable, and cutting-edge technology that drives success. https://usual-vault.com/
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but other than that, this is great blog. A fantastic read. I’ll certainly be back.
best comic reading site in HD
1 цшт [url=http://aktivnoe.forum24.ru/?1-8-0-00000252-000-0-0-1741169084/]http://aktivnoe.forum24.ru/?1-8-0-00000252-000-0-0-1741169084/[/url] .
1 win казино [url=www.svstrazh.forum24.ru/?1-18-0-00000135-000-0-0-1741169701]www.svstrazh.forum24.ru/?1-18-0-00000135-000-0-0-1741169701[/url] .
В группе “Загородная жизнь” на VK кто-то спрашивал про озеленение, и в комментариях многие советовали посмотреть [url=https://greenhistory.ru/tseny/gazon_rulonniy]стоимость рулонного газона[/url] на Greenhistory.ru. Решил последовать совету – выбрал вариант, заказал, и через день у меня уже был шикарный зеленый участок. Быстро, надежно и качественно!
мост бет [url=https://cah.forum24.ru/?1-13-0-00001559-000-0-0/]мост бет[/url] .
Trazite pouzdane elektricni motori crna gora? Imamo siroku paletu modela za razlicite zadatke. Crnu Goru isporucujemo elektromotorima, kao i elektricnim motociklima, skuterima i biciklima. Ekoloski prihvatljiv transport za udobno putovanje. Visokokvalitetni motori i komponente po konkurentnim cijenama. Dostava i konsultacije – kontaktirajte nas!
кайтсерфинг в египте
игровой ноутбук thunderobot купить https://igrovye-noutbuki.ru
Google-поиск помог найти [url=https://zaim-lines.ru/]займ взять онлайн на карту[/url], когда неожиданно потребовались 11 000 рублей на лекарства. Простой запрос в поисковике привел к надежной МФО, которая одобрила средства за 20 минут – спасли ситуацию!
Jante Rimnova
canadian pharmacy meds
https://expresscanadapharm.com/# canadian pharmacy online reviews
best canadian online pharmacy
Товары для вашего авто лучшие цены на автозапчасти автоаксессуары, масла, запчасти химия, электроника и многое другое. Быстрая доставка, акции и бонусы для постоянных клиентов. Подбирайте товары по марке авто и будьте уверены в качестве!
Товары для вашего авто https://avtostilshop.ru автоаксессуары, масла, запчасти химия, электроника и многое другое. Быстрая доставка, акции и бонусы для постоянных клиентов. Подбирайте товары по марке авто и будьте уверены в качестве!
Такси для бизнеса http://www.obzh.ru/mix/korporativnye-puteshestviya-s-yandeks-taksi-novoe-slovo.html работа по всей России. Удобные поездки для сотрудников! Оформите корпоративный аккаунт и получите выгодные условия, детальную отчетность и надежный сервис. Быстрое бронирование, прозрачные тарифы, комфортные автомобили – организуйте рабочие поездки легко!
мастбет [url=https://chesskomi.borda.ru/?1-10-0-00000277-000-0-0-1741171219/]https://chesskomi.borda.ru/?1-10-0-00000277-000-0-0-1741171219/[/url] .
1win.kg [url=https://aqvakr.forum24.ru/?1-3-0-00001121-000-0-0]1win.kg[/url] .
1win. pro [url=https://cah.forum24.ru/?1-13-0-00001560-000-0-0-1741172791]https://cah.forum24.ru/?1-13-0-00001560-000-0-0-1741172791[/url] .
Такси для бизнеса https://roads.ru/main/promo-materialy/vozvrat-avto-popavshego-na-shtrafstoyanku/ работа по всей России. Удобные поездки для сотрудников! Оформите корпоративный аккаунт и получите выгодные условия, детальную отчетность и надежный сервис. Быстрое бронирование, прозрачные тарифы, комфортные автомобили – организуйте рабочие поездки легко!
кокаин гашиш купить ебутся под мефом
детское порно телеграм мефедрон купить закладку
Онлайнказино Бонсай https://bonsai-casino2.com/ игровые автоматы, рулетка, покер и живые дилеры! Получайте бонусы за регистрацию, участвуйте в турнирах и выводите выигрыши без задержек. Надёжность, безопасность и азарт – всё в одном месте!
Актуальні новини будівництва https://dverikupe.com.ua та нерухомості в Україні. Огляди ринку, тренди, технології, законодавчі зміни та експертні думки – все про будівельну галузь на одному сайті!
Дізнавайтеся про останні новини https://ampdrive.info електромобілів, супекарів та актуальні події автомобільного світу в Україні. Ексклюзивні матеріали, фото та аналітика для справжніх автолюбителів на AmpDrive.?
Элегантные ковры для любого интерьера, идеальный.
Лучшие варианты ковров для вашего дома, со скидкой.
Эко-дизайн: ковры из натуральных материалов, новинки.
Ковры, которые подчеркнут вашу индивидуальность, харизму.
Ковры для игровой зоны, разнообразие.
Традиционные и современные ковры, инвестируйте.
Эстетика ковров в офисе, профессионализм.
Неприхотливые ковры для занятых людей, узнайте.
Руководство по выбору ковров, узнайте.
Теплота и уют с коврами, откройте.
Тенденции в мире ковров, выбор.
Создайте уют на даче с коврами, найдите.
Как сделать ваш интерьер уникальным с коврами, креативность.
Ковры: от классики до модерна, исследуйте.
Создайте атмосферу уюта в спальне, найдите.
Качество и стиль от лучших производителей, успех.
Мои любимые ковры для зоолюбителей, удобные.
Согревающие ковры для вашего дома, вдохновение.
Как использовать ковры для зонирования, функции.
ковры для дома [url=https://kovry-v-moskve.ru/]https://kovry-v-moskve.ru/[/url] .
баланс ван вин [url=http://aktivnoe.forum24.ru/?1-8-0-00000254-000-0-0-1741273702/]баланс ван вин[/url] .
1 win казино [url=http://1win109.com.kg]1 win казино[/url] .
1win am [url=https://1win10.am]https://1win10.am[/url] .
BEKU4D
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Актуальні новини політики https://insideukr.com в Україні та світі. Аналітика, думки експертів, головні події дня та ексклюзивні матеріали – будьте в курсі разом із нами!
Honey Money Казино https://honeymoneycasino.ru это захватывающий мир азартных игр с щедрыми бонусами, быстрыми выплатами и огромным выбором слотов, рулетки, покера и других развлечений. Играй онлайн в любое время, участвуй в турнирах и получай эксклюзивные награды.
Лучшие онлайн казино казино на эфир рейтинг топовых игровых платформ с лицензией, щедрыми бонусами, быстрыми выплатами и широким выбором слотов, покера, рулетки и других азартных игр. Мы собрали проверенные казино с высоким рейтингом, безопасностью и выгодными акциями.
керамогранит цена за м2 керамогранит цена за м2
керамогранит 60х60 https://magazin-keramogranit.ru
Купить телевизоры на дачу https://televizory-dlya-dachi.ru в интернет-магазине по низкой цене! При покупке дачных телевизоров на сайте воспользуйтесь скидками, акциями, бонусной программой.
Натяжные потолки с установкой https://natyazhnye-potolki2.ru стильное и практичное решение для любого интерьера. Предлагаем широкий выбор фактур и цветов, качественные материалы, быстрый монтаж и гарантию на работу. Устанавливаем потолки любой сложности в квартирах, домах, офисах.
Отдых в Анапе https://otdyh-vanape.ru идеальный выбор для всей семьи! Чистые песчаные пляжи, теплое море, развитая инфраструктура и развлечения на любой вкус. Гостиницы, отели, частный сектор – найдите идеальное жилье.
купить телевизор недорого в спб https://nedorogie-televizory.ru
Все о компьютерных играх https://lifeforgame.ru обзоры новых проектов, рейтинги, детальные гайды, новости индустрии, анонсы и системные требования. Разбираем особенности геймплея, помогаем с настройками и прохождением. Следите за игровыми трендами, изучайте секреты и погружайтесь в мир гейминга.
телевизор haier 43 smart tv s2 pro телевизор haier 43 smart tv
телевизор oled купить в москве телевизор haier 55 oled
1wi [url=http://1win110.com.kg/]http://1win110.com.kg/[/url] .
казино 1win [url=https://1win103.com.kg/]https://1win103.com.kg/[/url] .
1win прямой эфир [url=1win111.com.kg]1win111.com.kg[/url] .
vavada получить промокод
Все о недвижимости https://poselok-exclusive.ru покупка, аренда, ипотека. Разбираем рыночные тренды, юридические тонкости, лайфхаки для выгодных сделок. Помогаем выбрать квартиру, рассчитать ипотеку, проверить документы и избежать ошибок при сделках с жильем. Актуальные статьи для покупателей, арендаторов и инвесторов.
Все о недвижимости https://poselok-exclusive.ru покупка, аренда, ипотека. Разбираем рыночные тренды, юридические тонкости, лайфхаки для выгодных сделок. Помогаем выбрать квартиру, рассчитать ипотеку, проверить документы и избежать ошибок при сделках с жильем. Актуальные статьи для покупателей, арендаторов и инвесторов.
Unlock your vehicle’s potential with our top-notch auto tuning services! Explore your ride into a stunning masterpiece with our expert team. We specialize in upgrades that cater to your unique style. Our premium solutions ensure optimal performance and stylish look . Don’t settle for average; elevate your driving experience and turn heads on the road! Visit us at https://americasbestcertifiedautobody.com/ today and take the first step towards your dream car!
Your article helped me a lot, is there any more related content? Thanks!
Все о компьютерных играх https://lifeforgame.ru обзоры новых проектов, рейтинги, детальные гайды, новости индустрии, анонсы и системные требования. Разбираем особенности геймплея, помогаем с настройками и прохождением. Следите за игровыми трендами, изучайте секреты и погружайтесь в мир гейминга.
Все о недвижимости https://psk-opticom.ru покупка, аренда, ипотека. Разбираем рыночные тренды, юридические тонкости, лайфхаки для выгодных сделок. Помогаем выбрать квартиру, рассчитать ипотеку, проверить документы и избежать ошибок при сделках с жильем. Актуальные статьи для покупателей, арендаторов и инвесторов.
курсы стрип пластики стретчинг
Looking for free steam accounts? We regularly share working accounts with games, bonuses, and tips. Subscribe now and don’t miss new giveaways! Only verified and active accounts.
go to the website
[url=https://brd-wallet.com/]bread-wallet[/url]
Все о недвижимости https://9312886940.ru покупка, аренда, ипотека. Разбираем рыночные тренды, юридические тонкости, лайфхаки для выгодных сделок. Помогаем выбрать квартиру, рассчитать ипотеку, проверить документы и избежать ошибок при сделках с жильем. Актуальные статьи для покупателей, арендаторов и инвесторов.
qled телевизор 55 smart 4k ultra hd 4k qled телевизор 55
Все о компьютерных играх https://lifeforgame.ru обзоры новых проектов, рейтинги, детальные гайды, новости индустрии, анонсы и системные требования. Разбираем особенности геймплея, помогаем с настройками и прохождением. Следите за игровыми трендами, изучайте секреты и погружайтесь в мир гейминга.
Your article helped me a lot, is there any more related content? Thanks!
Мир компьютерных игр https://lifeforgame.ru Мы расскажем о лучших новинках, секретах прохождения, системных требованиях и игровых трендах. Новости, гайды, обзоры и рейтинги – всё, что нужно геймерам.
Покупка, аренда, ипотека https://stolbbeton.ru всё о недвижимости в одном блоге! Советы по выбору жилья, юридические аспекты, анализ цен и прогнозы рынка. Рассказываем, как грамотно оформить ипотеку, проверить документы и избежать ошибок при сделках с недвижимостью. Будьте в курсе всех изменений и трендов!
школа танцев в москве студия танцев
visit this site right here
[url=https://web-multibit.org/]MultiBit Classic Wallet[/url]
1win онлайн [url=http://1win11.am]1win онлайн[/url] .
Играйте в онлайн-казино рублевые казино с рублевыми счетами! Надежные казино с моментальными выплатами, бонусами и фриспинами. Пополнение через карты, кошельки и криптовалюту. Выбирайте топовые игры и выигрывайте без лишних комиссий!
Онлайн казино https://t.me/igrovie_avtomati_igrat/24 с лучшими бонусами и шансом на крупный выигрыш! Наслаждайтесь игрой в топовые слоты, получайте фриспины и участвуйте в акциях. Надежные площадки, высокая отдача и мгновенные выплаты – ваш шанс на успех!
Играйте в онлайн-казино https://t.me/casino_bonus_bezdep/15 топовые игровые автоматы, лайв-дилеры, мгновенные выплаты и бонусы для новых игроков. Наслаждайтесь честной игрой, удобными платежными методами и крупными выигрышами!
1 вин [url=www.1win13.am]www.1win13.am[/url] .
1вин [url=1win12.am]1win12.am[/url] .
click to investigate [url=https://toastwallet.org]toast wallet download[/url]
The best casino Retro Casino! Classic slot machines, generous bonuses and reliable payouts. Enjoy the excitement of retro slots and play on a proven platform!
Все, что вам нужно для игры https://t.me/vavada_casino_vhod/10! Игровые автоматы, рулетка, покер, живые дилеры и эксклюзивные бонусы. Наслаждайтесь качественной игрой с мгновенными выплатами и надежными провайдерами!
Играйте онлайн в https://t.me/jvspin_bet_casino/9 – лицензионное онлайн-казино с лучшими слотами, лайв-играми и щедрыми бонусами. Пополняйте счет удобными способами, получайте награды и выигрывайте реальные деньги!
1 win casino [url=https://1win3.com.mx/]1 win casino[/url] .
1win descarga [url=https://www.1win5.com.mx]https://www.1win5.com.mx[/url] .
casino 1win [url=https://1win4.com.mx/]https://1win4.com.mx/[/url] .
Играйте в Jozz Casino Официальный сайт популярное онлайн-казино с широким выбором слотов, настольных игр и лайв-дилеров. Выгодные бонусы, удобные платежные системы и моментальные выплаты ждут вас!
Выбирайте https://t.me/s/booi_casino_site топовое онлайн-казино с выгодными акциями, эксклюзивными играми и лайв-казино. Присоединяйтесь к сообществу игроков и получайте максимальное удовольствие от игры!
A powerful VPN solution https://github.com/ivanti-it/Ivanti-Secure-Access-Client/releases designed to provide secure remote access to corporate networks. The software supports multiple authentication methods, including multi-factor authentication (MFA), certificates, and biometrics.
https://vavadaonc10.fun/
Recommended Reading [url=https://brd-wallet.com]bread crypto[/url]
Свіжі ідеї дизайну https://dverikupe.od.ua інтер’єру, сучасні тренди, поради щодо декору та ремонту. Створюйте затишок та стиль у кожному куточку вашого дому!
сколько стоит лазерная эпиляция лазерная эпиляция цены для женщин
свіжі новини криптовалют https://cryptonews.v.ua блокчейна та DeFi. Огляди проектів, курси криптовалют, прогнози ринку та аналітика для трейдерів та інвесторів. Слідкуйте за криптомир з нами!
типография официальный сайт типография сайт
Continue [url=https://web-martianwallet.io]martian wallet chrome[/url]
see this page
[url=https://web-multibit.org/]multibit classic[/url]
A robust SSL VPN client https://sourceforge.net/p/sonicwall-netextender/wiki/Home/ application for providing remote users with secure access to corporate networks. Comprehensive security features and seamless connectivity for corporate environments
Покупка недвижимости и ипотека https://realsfera.ru что нужно знать? Разбираем выбор жилья, условия кредитования, оформление документов и юридические аспекты. Узнайте, как выгодно купить квартиру и избежать ошибок!
look at more info [url=https://web-multibit.org]MultiBit Classic download[/url]
ипотека и покупка недвижимости https://9312886940.ru что нужно знать? Разбираем выбор жилья, условия кредитования, оформление документов и юридические аспекты. Узнайте, как выгодно купить квартиру и избежать ошибок!
Buy elite Montenegro real estate investment: purchase apartments and houses without risks! Current prices, transaction execution, taxes and residence permit. Profitably purchase housing for life, recreation or investment.
click now [url=https://web-martianwallet.io]martian wallet firefox[/url]
resource [url=https://toastwallet.org]recover toast wallet[/url]
more [url=https://toastwallet.org]toast wallet download[/url]
Secure your connections https://github.com/arcgis-wiki/ArcGIS/releases with FortiClient, ArcGIS Pro, Cisco AnyConnect, and Cisco Secure Client. Reliable VPN clients for remote work, data protection, and corporate network access without threats or information leaks!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/ph/register?ref=B4EPR6J0
готовые сервера самп CS 2
crmp samp 2
мосбет [url=http://mostbet34.com.kg/]http://mostbet34.com.kg/[/url] .
1win. [url=http://1win104.com.kg]http://1win104.com.kg[/url] .
1win login nigeria [url=http://1win9.com.ng]http://1win9.com.ng[/url] .
Unlock your vehicle’s potential with our top-notch auto tuning services! Transform your ride into a stunning masterpiece with our expert team. We specialize in modifications that cater to your unique style. Our premium solutions ensure optimal performance and aesthetic appeal . Don’t settle for average; elevate your driving experience and turn heads on the road! Visit us at https://accurateautobodyrepair.com/ today and take the first step towards your dream car!
Тут можно преобрести продвижение медицинской клиники seo-продвижение медицинских сайтов
Хотите сдать радиолом https://radiolom99.ru? Мы принимаем микросхемы, платы, процессоры и прочие радиоэлементы по выгодным ценам. Быстрая оценка, честные цены и удобные способы приема. Узнайте, сколько стоят ваши детали прямо сейчас!
Najboljse pocitnice hotel Zlatni bor Zabljak! Uzivajte v udobju, svezem zraku in osupljivi pokrajini. Gorske poti, smucanje, izleti in prijetno vzdusje. Brezplacen Wi-Fi, zajtrk in parkirisce. Rezervirajte bivanje v osrcju narave!
Dobrodosli v Kolasin Montenegro hotel! Uzivajte v udobnih sobah, osupljivem razgledu in odlicni storitvi. Pozimi – smucanje, poleti – pohodi v gore in izleti. Prirocna lokacija, restavracija, SPA in prijetno vzdusje. Rezervirajte nepozabne pocitnice!
Купите теплицу https://tepl1.ru/catalog с доставкой по выгодной цене! Широкий выбор моделей: поликарбонатные, стеклянные, пленочные. Быстрая доставка, прочные конструкции, удобный монтаж. Идеально для дачи, сада и фермерства. Заказывайте качественные теплицы с доставкой прямо сейчас!
equilibrador
Equipos de ajuste: clave para el operacion suave y productivo de las equipos.
En el mundo de la ciencia actual, donde la rendimiento y la confiabilidad del sistema son de suma importancia, los equipos de calibracion desempenan un papel fundamental. Estos sistemas dedicados estan desarrollados para calibrar y estabilizar partes moviles, ya sea en maquinaria industrial, automoviles de transporte o incluso en dispositivos caseros.
Para los tecnicos en reparacion de sistemas y los ingenieros, utilizar con sistemas de balanceo es fundamental para garantizar el desempeno fluido y confiable de cualquier sistema dinamico. Gracias a estas herramientas innovadoras innovadoras, es posible limitar significativamente las oscilaciones, el estruendo y la esfuerzo sobre los rodamientos, prolongando la tiempo de servicio de partes costosos.
De igual manera significativo es el rol que cumplen los equipos de calibracion en la asistencia al consumidor. El apoyo experto y el soporte regular aplicando estos aparatos permiten proporcionar soluciones de alta estandar, aumentando la contento de los clientes.
Para los titulares de emprendimientos, la aporte en sistemas de equilibrado y sensores puede ser esencial para aumentar la eficiencia y eficiencia de sus dispositivos. Esto es principalmente trascendental para los empresarios que dirigen modestas y pequenas organizaciones, donde cada punto cuenta.
Por otro lado, los dispositivos de equilibrado tienen una amplia implementacion en el area de la fiabilidad y el control de estandar. Habilitan detectar eventuales errores, evitando mantenimientos caras y perjuicios a los aparatos. Incluso, los indicadores extraidos de estos dispositivos pueden aplicarse para mejorar procedimientos y mejorar la presencia en plataformas de consulta.
Las areas de implementacion de los sistemas de calibracion incluyen variadas ramas, desde la manufactura de bicicletas hasta el seguimiento de la naturaleza. No afecta si se considera de extensas manufacturas manufactureras o reducidos establecimientos caseros, los sistemas de equilibrado son indispensables para asegurar un funcionamiento efectivo y sin riesgo de paradas.
мостбет кг [url=https://mostbet1009.com.kg]https://mostbet1009.com.kg[/url] .
1win ru [url=https://1win105.com.kg]https://1win105.com.kg[/url] .
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
娛樂城大解析
娛樂城,通常指的是一個線上賭博平台,提供各種娛樂遊戲,如賭場遊戲、體育博彩、電子遊戲等。這些平台讓玩家可以在網路上進行賭博,而不需要親自前往實體賭場。娛樂城通常包含了各式各樣的遊戲選項,例如百家樂、輪盤、老虎機、撲克等,並且透過即時娛樂、直播等技術,提升了玩家的沉浸感和互動性。現今的娛樂城大多數已經支援手機和桌面端的多平台操作,讓玩家可以隨時隨地參與遊戲,這樣的便利性使得它們受到全球玩家的青睞。此外,娛樂城也會推出不同的優惠活動、註冊獎金和忠誠計劃,吸引新用戶並保持老用戶的活躍度。然而,娛樂城的風險也不可忽視。由於賭博本身具有高度的娛樂性,但也存在可能的成癮問題。多數國家對於線上賭博有著嚴格的法律規範,玩家在選擇娛樂城平台時,應該格外留意平台的合法性和安全性,以避免陷入詐騙或遭遇其他法律風險。因此,理性投注並了解相關法律是每位玩家應該保持的基本態度。
1win sportsbook [url=http://1win10.com.ng/]1win sportsbook[/url] .
Recommended Site
[url=https://keplerchain.com/]trust wallet secret phrase[/url]
go to this site [url=https://keplerchain.com]staking rewards[/url]
about his
[url=https://keplerchain.com/]recover crypto wallet[/url]
internet [url=https://keplerchain.com]defi wallet[/url]
Современные методы по бизнесу: https://student.uog.edu.et/hello-world-3/
[url=https://ykrn.site/]Kraken onion[/url] – Как зайти на кракен, Кракен рекомендации
mostbet casino [url=mostbet1000.com.kg]mostbet casino[/url] .
1win официальный сайт [url=www.1win106.com.kg]www.1win106.com.kg[/url] .
Тут можно преобрести продвижение сайтов медицинской тематики продвижение сайта медицинских услуг
мостбет кг [url=https://mostbet1010.com.kg]https://mostbet1010.com.kg[/url] .
Sans?n?z? Sweet Bonanza’da sweet-bonanza-casino.site deneyin – parlak ve karl? bir slot! Ucretsiz donusler, kazanc carpanlar?, kademeli kombinasyonlar ve buyuk odemeler. Ucretsiz veya parayla cevrimici oynay?n ve tatl? oduller kazan?n!
Glory Casino’da glory-casino-guncel-giris.online oynayn – en iyi oyunlar, yuksek odemeler ve 7/24 destek! Populer slotlar?, kart oyunlar?n? ve ruleti secin, bonuslar kazan ve gercek para kazan?n!
Diego Armando Maradona https://diego-maradona.com.mx es una leyenda del futbol mundial! Campeon del Mundo de 1986, autor de “La Mano de Dios” y “El Gol del Siglo”. Un gran jugador argentino que inspiro a generaciones. ?Su tecnica, su regate y su pasion por el juego lo convirtieron en un icono del futbol!
Лучшие https://aacsatlanta.com/dui-school-marietta/ инструменты для работы с бизнесом.
Fansite de Mike Tyson http://mike-tyson.com.mx donde podras conocer su historia, peleas, noticias y todo lo relacionado a su legado boxistico. Sigue sus proyectos y conoce mas sobre esta leyenda.
Sitio de fans de Michael Phelps https://michael-phelps.com.mx Un lugar donde los fanaticos pueden encontrar toda la informacion sobre su carrera, sus records y su vida. Noticias, logros y contenido exclusivo.
Sitio de fans de Muhammad Ali muhammad-ali.com.mx La historia de una leyenda del boxeo, sus victorias, su lucha por sus derechos y su legado que inspiro al mundo.
Как сэкономить на бизнесе: https://karoen.nl/blog/2023/06/06/ontspan-en-geniet-een-gids-voor-de-perfecte-vakantie/
Sitio fan de George Foreman george-foreman.com.mx dedicado a su carrera, victorias, derrotas y legado en el boxeo. Historias inspiradoras y el estilo unico de una leyenda del deporte.
https://nettyfish.com/bulk-sms-service-in-chennai/ Подробное руководство по бизнесу.
купить рюкзак
Новые подходы в бизнесе: http://traverseearth.com/the-chianti-region-tuscany-italy/
лучший прокат авто аренда авто в сочи аэропорту без водителя
Играйте в Big Bamboo big-bamboo-slot.online слот с захватывающим геймплеем, фриспинами и множителями! Ощутите атмосферу восточной удачи, собирайте бонусные символы и выигрывайте по-крупному.
Join Glory Casino glory-casino-bd.online and get maximum bonuses! Top slot machines, table games, jackpots and exclusive promotions. Play online and win comfortably!
Взрослый вебкам бесплатно https://hotcams.one Тысячи моделей, приватные шоу, видео в высоком качестве и горячие трансляции. Общайтесь в чате и наслаждайтесь без ограничений!
скачать mostbet [url=https://mostbet1001.com.kg/]скачать mostbet[/url] .
1 win [url=www.1win107.com.kg]www.1win107.com.kg[/url] .
her comment is here
[url=https://www.reddit.com/user/AlanaMcdowell/comments/1dqewao/what_do_you_think_about_kreativstorm/]What do you think about Kreativstorm?[/url]
Новые подходы в бизнесе: https://www.editions-ric.fr/2019/02/10/video-france-3-reportage-sur-patrick-lecointe-editions-ric/
Геймерам на заметку: если ваш Xbox глючит – не спешите покупать новый! На [url=https://mobile-worker.ru/remont-dzhojstikov.html]ремонт геймпада xbox[/url] цены вполне адекватные, делают быстро и с гарантией. Моему контроллеру вернули вторую жизнь за пару часов работы.
Не тратьте время на поиски надёжного сервиса – обратитесь в Mobile-Worker! Бесплатная диагностика, быстрый ремонт без записи и гарантия 60 дней делают нас лучшим выбором для владельцев смартфонов, планшетов и ноутбуков. Работаем ежедневно, запись не требуется.
1win.com [url=https://1win5000.ru]https://1win5000.ru[/url] .
рюкзак женский
Почему желтеют можжевельники после зимы https://e-pochemuchka.ru/pochemu-zhelteyut-mozhzhevelniki-posle-zimy/
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Какой https://www.tandem.edu.co/halloween/ вариант предпочесть в бизнесе?
娛樂城大解析
娛樂城,通常指的是一個線上賭博平台,提供各種娛樂遊戲,如賭場遊戲、體育博彩、電子遊戲等。這些平台讓玩家可以在網路上進行賭博,而不需要親自前往實體賭場。娛樂城通常包含了各式各樣的遊戲選項,例如百家樂、輪盤、老虎機、撲克等,並且透過即時娛樂、直播等技術,提升了玩家的沉浸感和互動性。現今的娛樂城大多數已經支援手機和桌面端的多平台操作,讓玩家可以隨時隨地參與遊戲,這樣的便利性使得它們受到全球玩家的青睞。此外,娛樂城也會推出不同的優惠活動、註冊獎金和忠誠計劃,吸引新用戶並保持老用戶的活躍度。然而,娛樂城的風險也不可忽視。由於賭博本身具有高度的娛樂性,但也存在可能的成癮問題。多數國家對於線上賭博有著嚴格的法律規範,玩家在選擇娛樂城平台時,應該格外留意平台的合法性和安全性,以避免陷入詐騙或遭遇其他法律風險。因此,理性投注並了解相關法律是每位玩家應該保持的基本態度。
[url=https://images.google.ru/url?q=https://expl0it.ru/]взять займ без отказа онлайн на карту[/url] – не беспокойтесь о отказах! Этот сервис работает с любыми клиентами. Простая регистрация, моментальное одобрение. Деньги на карту без проверок.
Сравнительный анализ бизнеса: https://www.tandem.edu.co/presentacion-the-space/
webpage
[url=https://web-smartwallet.org/]smart wallet apk[/url]
рюкзак черный
cod promoțional 1win [url=https://www.1win5001.ru]https://www.1win5001.ru[/url] .
прокат авто без водителя дешево аренда авто в адапазары
поддержка мостбет [url=https://mostbet1003.com.kg/]https://mostbet1003.com.kg/[/url] .
скачать mostbet на телефон [url=https://mostbet1002.com.kg]https://mostbet1002.com.kg[/url] .
Практические советы для https://mejorsintlc.cl/litio-e-hidrogeno-verde-en-la-maleta-del-presidente-boric/ работы с бизнесом.
you could try this out
[url=https://web-smartwallet.org/]customer service number for smart wallet[/url]
регистрация рио бет казино регистрация РиоБет
Хочу понять в https://epiczo.com/?p=254 бизнесе. Куда зайти?
a fantastic read
[url=https://web-smartwallet.org/]the smart wallet[/url]
blog
[url=https://web-smartwallet.org/]wallet smart wallet[/url]
An impressive share! I have just forwarded this onto a colleague who was doing a little research on this. And he actually bought me dinner because I discovered it for him… lol. So let me reword this…. Thank YOU for the meal!! But yeah, thanks for spending some time to talk about this issue here on your website.
регистрация RioBet
Займ на карту без отказа без проверки деньги в долг на карту срочно без проверки кредитной истории
Взять займ онлайн россия займы официальный сайт
автомобили известных марок ремонт автомобилей
мтс интернет
https://labourmarket.pro/employer/klaus1195
мтс тарифы на интернет
prirodni biser Zabljak Durmitor Jedinstveni planinski pejzazi, bistra jezera, kanjoni i guste sume. Idealno mjesto za planinarenje, rafting, skijanje i rekreaciju na otvorenom. Otkrijte nacionalni park pod zastitom UNESCO-a!
swiper casino espana nuevoscasinosonlineespana
рюкзак школьный
скачать 1win с официального сайта [url=cah.forum24.ru/?1-19-0-00000716-000-0-0-1741702224]cah.forum24.ru/?1-19-0-00000716-000-0-0-1741702224[/url] .
мотбет [url=http://dubna.myqip.ru/?1-18-0-00000145-000-0-0-1741708632/]http://dubna.myqip.ru/?1-18-0-00000145-000-0-0-1741708632/[/url] .
мтс новосибирск
https://www.teknoxglobalconcept.com/employer/howard7695/
мтс подключить новосибирск
https://dmpublicidad.com.ar/974-2/ Пример из практики: Бизнес.
мтс новосибирск
https://easterntalent.eu/employer/gabriele1894/
мтс интернет
look what i found [url=https://web-smartwallet.org]apa itu smart wallet[/url]
Где смотреть статистику о бизнесе? https://shop.platinumwellness.net/hello-world/
everything about the world https://t.me/ufc_ar of UFC in Arabic! Latest news, tournament schedules, fighter ratings and exclusive analytical materials. Follow the best fights and stay up to date with all the events in the world of mixed martial arts!
Пытаюсь разобраться в http://vitanuova.ru/u-severnoj-korei-est-svoj-planshet/ бизнесе. Что посоветуете?
рюкзак спортивный
mostbet промокод [url=https://aktivnoe.forum24.ru/?1-8-0-00000260-000-0-0-1741701879/]https://aktivnoe.forum24.ru/?1-8-0-00000260-000-0-0-1741701879/[/url] .
1win официальный сайт вход [url=http://aktivnoe.forum24.ru/?1-8-0-00000259-000-0-0-1741701621/]http://aktivnoe.forum24.ru/?1-8-0-00000259-000-0-0-1741701621/[/url] .
мостбет официальный сайт [url=https://cah.forum24.ru/?1-19-0-00000715-000-0-0-1741702061]мостбет официальный сайт[/url] .
прокат авто симферополь недорого аренда машины симферополь
мтс интернет новосибирск
https://hatchingjobs.com/companies/carley7478/
мтс домашний интернет
Лучшие инструменты для работы с бизнесом: http://www.pureatz.com/recipes/penne-with-shrimp-and-asparagus/
Follow UFC fights with https://t.me/s/ufc_ar full tournament schedule, fight results, fighter ratings and analytics. Exclusive news, reviews and interviews with top MMA athletes – all in one place!
Рейтинг казино с релоад бонусом https://t.me/casino_list_reyting
мтс тв новосибирск
https://jobseeker.charisonecare.co.uk/employer/cinda8428/
мтс подключение новосибирск
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at https://aquasculpt.best and sculpt your dream body today!
Авторитетное мнение о бизнесе: https://mattaarquitectos.es/portfolio/avenida-reina-victoria-8-madrid/main-31/
Продвижение вашего сайта на новый уровень, лучшие стратегии.
Секреты успешного продвижения сайтов, проводите.
Узнайте, как продвигать сайт, трафик.
Будущее онлайн-продвижения, которые изменят ваш бизнес.
Топовые приемы для улучшения позиционирования, доступные каждому.
Что важно для онлайн-продвижения, которые принесут плоды.
Топовые компании для онлайн-продвижения, на которые можно положиться.
Избегайте этих ошибок в SEO, за которыми стоит следить.
Бюджетное продвижение сайтов, узнайте.
Топовые инструменты для анализа, что упростят вашу работу.
Как анализировать успех продвижения сайта, которые нельзя игнорировать.
Как контент влияет на трафик, о чем многие забывают.
Успех в локальном SEO, методы для вашего региона.
Как понять свою аудиторию, основа успешного продвижения.
Как оптимизировать сайт для мобильных, может стать вашим преимуществом.
SEO против контекстной рекламы, на основе фактов.
Почему важны бэклинки, на практике.
Изменения в мире продвижения, не пропустите.
Сила SMM в SEO, вовлекайте пользователей.
Оптимизация сайта для поисковых систем, которые изменят вашу стратегию.
реклама на гугле [url=https://1prodvizhenie-sajtov-52.ru/]реклама на гугле[/url] .
мтс новосибирск
https://skilling-india.in/employer/helene8694/
мтс новосибирск
[url=][/url]
Все про остекление и ремонт балконов — новости, советы и услуги в одном месте!
Хотите преобразить свой балкон или лоджию?
Мы предлагаем свежие идеи, актуальные обзоры и экспертные мнения
по всем ключевым вопросам: современные тенденции в остеклении,
варианты дизайна и материалы для отделки.
Полезные рекомендации для тех, кто планирует обновление балкона:
как выбрать подходящий тип остекления — тёплое или холодное,
какие материалы использовать для утепления и отделки, а также
как избежать распространённых ошибок при монтаже.
Мы поможем вам разобраться в юридических аспектах согласования
перепланировок и остекления.
Следите за нашими обзорами новых технологий и материалов,
узнавайте о лучших предложениях на рынке, а также получайте советы
по уходу за окнами и балконными конструкциями.
Мы делимся рекомендациями по выбору надёжных подрядчиков,
рассказываем о преимуществах различных систем остекления и
предлагаем идеи по функциональному использованию пространства балкона.
Только актуальная информация от ведущих специалистов отрасли — проверенные факты,
практические советы и вдохновляющие примеры.
Подписывайтесь и оставайтесь в курсе последних тенденций!
С нами ваш балкон станет уютным и функциональным пространством,
радующим вас каждый день!
Сайт balconyokna.ru
[url=][/url]
Играйте в Mostbet Casino https://mostbet.spas-extreme.ru лицензированное онлайн-казино с огромным выбором игр! Получайте бонусы, выигрывайте в лучших слотах и наслаждайтесь быстрыми выплатами. Удобные способы пополнения счета!
Выбираем недвижимость в Киеве https://automat.kiev.ua как оценить район, новостройки и вторичный рынок? Анализ цен, проверка застройщика, юридическая безопасность сделки. Полезные советы для покупки квартиры без ошибок и переплат!
Строительный онлайн журнал https://kero.com.ua ваш источник актуальной информации о строительстве и ремонте! Советы, обзоры материалов, технологии, тренды и новости отрасли. Узнайте о современных методах строительства, инженерных решениях и дизайне интерьера!
Подкаст о https://schule-am-volkspark.de/plusminus-umfrage бизнесе.
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at https://aquasculpt.one and sculpt your dream body today!
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at https://aquasculpt.me and sculpt your dream body today!
один вин [url=https://1win112.com.kg/]https://1win112.com.kg/[/url] .
1vin казино [url=https://www.1win113.com.kg]1vin казино[/url] .
один вин официальный сайт [url=https://1win713.ru/]https://1win713.ru/[/url] .
Как не сдаться при изучении бизнеса: https://aroagardenbar.com.br/hello-world-2/
мтс подключение екатеринбург
https://doctifyindia.in/employer/24inetrnet-domashnij-ekb-3/
мтс тв екатеринбург
Exponent Finance is redefining DeFi lending by providing secure, transparent, and high-yield investment solutions. Through smart contract-powered lending pools, Exponent Finance DeFi platform allows users to borrow and lend crypto assets with optimal efficiency and minimal risk. Whether you’re looking to earn passive income through staking or access instant liquidity, Exponent Finance offers a decentralized, non-custodial, and user-friendly solution to meet all your financial goals in the crypto ecosystem. https://exponent.ink
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at https://aquasculpt.one !
провайдер мтс
https://www.oyeanuncios.com/profile/lanemosely526
мтс подключить екатеринбург
Всё для мужчин https://kompanion.com.ua в одном месте! Спорт, мода, авто, гаджеты, здоровье и лайфхаки. Читай полезные советы, следи за трендами и будь лучшей версией себя.
Новости шоу-бизнеса https://mediateam.com.ua мода, красота и афиша – всё в одном месте! Узнавайте о главных событиях, свежих трендах и топовых мероприятиях. Будьте в курсе всего, что происходит в мире стиля и развлечений!
Все автомобильные новости https://nmiu.org.ua в одном месте! Новые модели, обзоры, сравнения, тест-драйвы, технологии и автоиндустрия. Следите за тенденциями и оставайтесь в курсе событий автопрома!
Что лучше выбрать в бизнесе? https://kubalitours.com/family-friendly-resorts-in-coastal-kenya/
рюкзак черный
Выбор недвижимости в Киеве https://odinden.com.ua на что обратить внимание? Анализ районов, проверка застройщиков, сравнение цен на новостройки и вторичное жилье.
Актуальные новости бизнеса https://rentwell.in.ua экономики и недвижимости! Аналитика, тренды, инвестиции, рынок недвижимости и финансовые прогнозы. Будьте в курсе главных событий и принимайте взвешенные решения!
Лучший женский портал https://rosetti.com.ua Стиль, красота, здоровье, семья, карьера и саморазвитие. Узнавайте о новых трендах, читайте полезные советы и вдохновляйтесь идеями для счастливой жизни!
мтс телевидение
https://jobs.web4y.online/employer/24inetrnet-domashnij-ekb/
мтс тв
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at https://aquasculpt.lifestyle !
mostbet kg отзывы [url=https://mostbet1011.com.kg]mostbet kg отзывы[/url] .
мостбет мобильная версия скачать [url=http://mostbet1004.com.kg/]http://mostbet1004.com.kg/[/url] .
how to bet on 1win [url=1win11.com.ng]1win11.com.ng[/url] .
Современный женский портал https://womanlife.kyiv.ua мода, стиль, красота, здоровье, отношения и карьера. Читайте актуальные статьи, находите полезные советы и вдохновляйтесь на новые достижения!
Детский портал о здоровье https://run.org.ua полезная информация для заботливых родителей! Советы педиатров, питание, развитие, вакцинация, профилактика болезней и здоровый образ жизни. Всё, что нужно знать о здоровье вашего ребенка!
Все для женщин https://timelady.kyiv.ua в одном месте! Новости моды, бьюти-советы, отношения, карьера, психология и лайфхаки. Читайте статьи, находите вдохновение и будьте уверены в себе каждый день!
Повышение эффективности через бизнес: https://asesinosasueldo.org/busco-un-sicario/.
HyperDrive is transforming the way data is stored and managed through decentralized storage and blockchain hosting solutions. Built for security, scalability, and efficiency, HyperDrive enables businesses, developers, and blockchain projects to store and distribute data without relying on centralized servers. By leveraging Web3 technology and distributed networks, HyperDrive ensures reliable, censorship-resistant, and high-performance storage solutions for the digital era. https://hyperdrive.ink
мтс телевидение
https://clujjobs.com/employer/24inetrnet-domashnij-ekb-3/
мтс телевидение
chinese moving company toronto office moving companies toronto
Всё для женщин https://allwoman.kyiv.ua в одном месте! Советы по стилю, уходу за собой, психологии, семье, карьере и саморазвитию. Узнавайте о новинках моды, секретах успешных женщин и будьте на шаг впереди!
Современный женский сайт https://dama.kyiv.ua красота, стиль, здоровье, семья и карьера. Читайте актуальные статьи, находите полезные советы и вдохновляйтесь на новые достижения!
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at https://aquasculpt.one !
Что нельзя делать с бизнесом? https://seointellect.com/2023/04/09/boost-your-online-presence-our-top-digital-marketing/
мтс тв екатеринбург
https://isourceprofessionals.com/companies/24inetrnet-domashnij-ekb/
мтс телевидение екатеринбург
Женский онлайн-журнал https://krasotka.kyiv.ua мода, красота, здоровье, семья и карьера. Полезные статьи, тренды, лайфхаки и вдохновение для современной женщины. Читайте, развивайтесь и наслаждайтесь жизнью!
Лучший сайт для женщин https://model.kyiv.ua секреты красоты, стильные образы, отношения, карьера, лайфхаки и вдохновение. Оставайтесь в курсе трендов, читайте экспертные советы и развивайтесь вместе с нами!
Онлайн-журнал для женщин https://otnoshenia.net которые стремятся к лучшему! Советы по стилю и макияжу, секреты счастливых отношений, здоровое питание, психология и идеи для отдыха.
рюкзак женский
Сайт для современных женщин https://princess.kyiv.ua Все о последних трендах в мире моды и красоты, секреты здоровья, психология, советы по саморазвитию, карьере и личным отношениям.
Портал для женщин https://woman365.kyiv.ua которые ценят красоту и уверенность! Новинки моды, макияж, секреты счастья, психология, карьера и вдохновение. Узнавайте полезные советы и воплощайте мечты в реальность!
Женский онлайн-клуб https://womanclub.kyiv.ua для тех, кто ценит стиль, здоровье и успех! Узнайте секреты красоты, тренды моды, советы по отношениям и карьере. Читайте вдохновляющие истории, пробуйте новые лайфхаки и развивайтесь каждый день!
AquaSculpt weight loss is here to stay! With AquaSculpt capsules, you get fast AquaSculpt results thanks to natural AquaSculpt ingredients. No worries about AquaSculpt side effects—users confirm it in AquaSculpt reviews. Curious AquaSculpt how to use? It’s easy and effective. AquaSculpt where to buy? Visit https://aquasculpt.best and transform your body now!
Видел прогнозы, что Бизнес будет главным https://www.aquilamanagement.eu/faq-items/class-aptent-taciti-sociosqu-ad-litora-torquent-per-conubia-nostra-pers/ трендом. Возражения?
CS:GO/CS2 skins https://wiki.vpesports.com catalog with full description! Check out rare, legendary and popular skins, their cost, collections and features. Find the perfect skin for your inventory!
The best online marketplace https://forum.batman.gainedge.org/index.php?topic=72285.0! Buy and sell game, social, business and other accounts. Convenient filtering system, transaction security and current offers. All popular services and games in one place!
Buy verified accounts account market with ease! Gaming, business, and social media accounts available at competitive prices. Fast transactions, trusted sellers, and secure payments. Get the best deals now!
1win kg [url=1win715.ru]1win kg[/url] .
1 vin [url=https://1win114.com.kg/]https://1win114.com.kg/[/url] .
1вин официальный регистрация [url=https://1win708.ru/]https://1win708.ru/[/url] .
Сайт для женщин https://womanexpert.kyiv.ua которые хотят быть успешными и счастливыми! Советы по красоте, здоровью, воспитанию детей, карьере и личностному росту. Актуальные тренды, лайфхаки и вдохновение для современных женщин!
Лучший автомобильный портал https://kia-sportage.in.ua Обзоры автомобилей, сравнения, новинки, тест-драйвы, лайфхаки для водителей и советы по выбору авто. Всё, что нужно автолюбителям и профессионалам!
Портал для автолюбителей https://lada.kharkiv.ua всё об автомобилях! Автообзоры, рейтинг лучших моделей, новинки, цены, советы по уходу и эксплуатации. Узнайте, какие авто заслуживают вашего внимания!
Лично мне помог этот ресурс по бизнесу: https://kelidsazan.com/%da%a9%d9%84%db%8c%d8%af%d8%b3%d8%a7%d8%b2-%d8%a7%d8%b4%d8%b1%d9%81%db%8c-%d8%a7%d8%b5%d9%81%d9%87%d8%a7%d9%86%db%8c/
Exponent Finance is redefining DeFi lending by providing secure, transparent, and high-yield investment solutions. Through smart contract-powered lending pools, Exponent Finance DeFi platform allows users to borrow and lend crypto assets with optimal efficiency and minimal risk. Whether you’re looking to earn passive income through staking or access instant liquidity, Exponent Finance offers a decentralized, non-custodial, and user-friendly solution to meet all your financial goals in the crypto ecosystem. https://exponent.ink
UnagiSwap is a cutting-edge decentralized exchange (DEX) that provides fast, secure, and transparent crypto trading. Designed for traders looking to swap digital assets efficiently without intermediaries, UnagiSwap offers low fees, deep liquidity, and seamless smart contract execution. Whether you’re a casual trader or a professional investor, UnagiSwap’s non-custodial platform ensures full control over your assets in a decentralized environment. https://unagiswap.org
Инфографика по бизнесу: http://inetlog.ru/
Сайт для женщин https://womanportal.kyiv.ua всё о моде, красоте, здоровье, отношениях и саморазвитии! Полезные советы, тренды, лайфхаки и вдохновение для современной женщины. Будьте стильной, уверенной и успешной!
Автомобильный сайт https://newsgood.com.ua для водителей и автолюбителей! Узнавайте актуальные новости, читайте обзоры новых моделей, изучайте советы по обслуживанию и вождению.
Авто портал для всех https://rupsbigbear.com кто любит автомобили! Новости, тест-драйвы, характеристики, тюнинг, страхование, покупка и продажа авто. Следите за последними тенденциями и выбирайте лучшее для себя!
seo оптимизация сайта заказать [url=http://prodvizhenie-sajtov-v-moskve223.ru]seo оптимизация сайта заказать[/url] .
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at https://aquasculpt.xyz !
Что не пишут https://lnx.juliacom.it/2019/10/02/dietro-le-quinte/ в учебниках с бизнесом.
мтс тарифы екатеринбург
https://jobspage.ca/employer/inetrnet-domashnij-ekb-2/
мтс тв
Discover the art of auto tuning at Saratoga Auto Body, where your vehicle’s power is fully optimized. Our committed team focuses on bespoke tuning treatments designed to enhance your car’s look and performance . Indulge in our satisfied clientele and drive a vehicle that truly embodies your distinct taste. Visit https://saratogaautobody.com/ and kickstart your car’s reimagining today!
motsbet [url=https://mostbet1005.com.kg]https://mostbet1005.com.kg[/url] .
1win играть [url=https://1win714.ru]https://1win714.ru[/url] .
Женский журнал онлайн https://sunshadow.com.ua стиль, уход, секреты красоты, семья, карьера и саморазвитие. Будьте в курсе трендов, находите полезные лайфхаки и вдохновляйтесь на новые достижения!
Лучший женский онлайн-журнал https://sweetheart.kyiv.ua Всё о моде, красоте, здоровье, отношениях и успехе. Экспертные советы, лайфхаки и мотивация для уверенных в себе женщин.
Ваш гид в мире красоты https://wonderwoman.kyiv.ua моды и саморазвития! Экспертные статьи о здоровье, отношениях, карьере, психологии и лайфхаках для повседневной жизни. Оставайтесь в курсе трендов и открывайте новые возможности!
Noon Capital is revolutionizing real estate crowdfunding by offering secure, decentralized, and high-yield investment opportunities. Through blockchain-powered property financing, Noon Capital investment platform allows investors to participate in fractional real estate ownership, earn passive income, and diversify their portfolios with full transparency and security. Whether you’re an institutional investor or an individual seeking real estate-backed DeFi solutions, Noon Capital provides a seamless and profitable investment experience. https://noon.ad
1winj [url=https://1win709.ru/]https://1win709.ru/[/url] .
Лично мне помог этот ресурс по бизнесу: https://blog.12min.com/br/frases-marcantes-de-livros/
Женский мир https://vsegladko.net без границ! Узнайте всё о моде, уходе за собой, фитнесе, психологии, карьере и хобби. Читайте актуальные статьи, следите за новыми тенденциями и наполняйте жизнь яркими моментами!
Автомобильный онлайн-журнал https://svobodomislie.com всё о мире авто! Свежие новости, обзоры моделей, тест-драйвы, автоспорт, технологии и лайфхаки для водителей. Следите за трендами и будьте в курсе последних событий автопрома!
Онлайн-журнал о машинах https://sw.org.ua всё, что нужно знать об автомобилях! Премьеры новых моделей, сравнение авто, автострахование, технологии, электрокары и советы для владельцев.
мтс подключить екатеринбург
https://aicreator24.com/employer/inetrnet-domashnij-ekb-2/
мтс цены
Современный женский https://adviceskin.com журнал для тех, кто хочет быть стильной, уверенной и успешной! Секреты красоты, модные тенденции, здоровье, карьера, психология и лайфхаки для повседневной жизни.
Сайт о красоте и здоровье https://beautytips.kyiv.ua полезные советы, тренды ухода, секреты молодости, правильное питание и фитнес. Узнавайте, как оставаться красивой, здоровой и энергичной в любом возрасте!
Мода, красота и здоровье https://fashiontop.com.ua всё в одном месте! Советы по стилю, уходу за волосами и кожей, диеты, тренировки и wellness-тренды. Узнайте, как выглядеть и чувствовать себя на 100%!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
мтс екатеринбург
https://essencialponto.com.br/employer/24inetrnet-domashnij-ekb-3/
мтс домашний интернет
Идеальный баланс стиля https://feromonia.com.ua красоты и здоровья! Читайте о модных тенденциях, косметике, правильном питании, спорте и психологическом комфорте. Найдите вдохновение для гармоничной жизни!
Мода, красота и здоровье https://gryada.org.ua ваш путь к идеальному образу! Последние тренды, советы по уходу, секреты стройности и здорового образа жизни. Создавайте гармонию в своём стиле и самочувствии!
Секреты идеального стиля https://ladyone.kyiv.ua молодости и здоровья! Советы по моде, косметике, уходу за кожей и волосами, фитнесу и сбалансированному питанию. Узнайте, как создать гармоничный образ и чувствовать себя великолепно!
https://inderjeet.co.uk/hello-world Где учиться бизнесу?
мтс цены
https://animployment.com/employer/24inetrnet-domashnij-ekb/
мтс тарифы екатеринбург
https://www.graemestrang.com/?page_id=11 Как монетизировать бизнес в бизнесе?
Новые подходы https://constcourt.tj/en/2020/01/30/working-visit-to-new-york-city-21-09-2017/ в бизнесе.
Секреты красоты и здоровья https://magiclady.kyiv.ua в одном месте! Полезные советы по уходу, тренды моды, спорт, правильное питание и психология уверенности. Узнайте, как выглядеть и чувствовать себя великолепно!
Ваш гид по стилю https://magictech.com.ua красоте и жизни! Женский журнал о модных трендах, секретах молодости, психологии, карьере и личных отношениях.
Лучший женский журнал https://modam.com.ua онлайн! Мода, стиль, уход за собой, фитнес, кулинария, саморазвитие и лайфхаки. Полезные советы и вдохновение для современной женщины, которая стремится к лучшему!
1wiun [url=https://1win717.ru]1wiun[/url] .
игра 1вин [url=http://1win818.ru]http://1win818.ru[/url] .
1вин кг [url=https://1win819.ru/]https://1win819.ru/[/url] .
Ваш женский путеводитель https://topwoman.kyiv.ua по красоте, стилю и саморазвитию! Полезные советы, модные тенденции, лайфхаки по уходу за собой, психология, отношения и вдохновение.
Современный женский онлайн https://viplady.kyiv.ua журнал для тех, кто хочет большего! Всё о моде, косметике, фитнесе, питании, психологии, карьере и отношениях. Узнавайте новое, вдохновляйтесь и воплощайте мечты в реальность!
Онлайн-журнал для женщин https://one-lady.com которые хотят быть стильными и успешными! Последние тренды, секреты красоты, уход за собой, здоровье, психология и карьера. Будьте в курсе новинок и наслаждайтесь жизнью!
https://www.kaeshammer.ch/bouquets/ Нужны реальные кейсы по бизнесу.
фабрика бетона минск [url=beton-vip.ru]фабрика бетона минск[/url] .
Портал для родителей https://rodkom.org.ua всё о воспитании, развитии и здоровье детей! Полезные советы, лайфхаки, педиатрические рекомендации, семейная психология и идеи для досуга. Растите счастливых и здоровых детей вместе с нами!
Автомобильный портал https://kakavto.com всё, что нужно знать о машинах! Новинки автопрома, технологии, электрокары, автоспорт, автострахование и советы по ремонту. Следите за трендами автоиндустрии!
Советы для родителей https://agusha.com.ua в одном месте! Развитие ребёнка, воспитание, здоровье, питание, семейные отношения и идеи для досуга. Полезные статьи, лайфхаки и экспертные мнения помогут вам в заботе о малыше!
Плюсы и https://cobsamex.net/inversion/educacion-garantizada/ минусы разных подходов к бизнесу.
Актуальные новости Украины https://vesti.in.ua политика, экономика, спорт, культура и общество! Оперативная информация, эксклюзивные материалы, репортажи и аналитика. Следите за событиями в режиме реального времени!
Главные новости дня https://mostmedia.com.ua политика, экономика, общество, спорт и культура! Оперативные события, аналитика, мнения экспертов и репортажи. Читайте актуальные новости Украины и мира в одном месте!
Медицинский онлайн-журнал https://medicalanswers.com.ua ваш личный консультант по здоровью! Полезные статьи, советы врачей, профилактика, диагностика, лечение и здоровый образ жизни.
Как реализовали финансов в компании: https://krovlyaug.ru
Как устроен механизм финансов? https://allealavto.ru.
Elevate your driving excursion with D&T Auto Body’s superior tuning solutions . Our team of aficionados is passionate about perfecting your vehicle to uncover its true strength . Whether you seek speed or flair, our tailored solutions provide thorough results. Discover the transformation at https://dandtautobody.com/ and witness how we can transform your car into a gem .
Сайт для женщин https://bbb.dp.ua всё о моде, красоте, здоровье, отношениях и саморазвитии! Читайте полезные советы, следите за трендами, вдохновляйтесь и наслаждайтесь гармоничной жизнью!
Juega sin limites! casas de apuestas deportivas sin licencia en espana ofrecen altas cuotas, pagos rapidos y anonimato. ?Compara casas de apuestas populares, elige metodos de apuestas convenientes y disfruta de la emocion!
Apuestas deportivas baravaca plataformas con licencia, cuotas favorables, variedad de deportes y pagos rapidos. ?Consulta la valoracion de las mejores casas de apuestas y elige la tuya!
https://myasnayatarelka.ru Мемы про финансы.
купить бетон в минске [url=www.beton-lot.ru]купить бетон в минске[/url] .
[url=https://betslive.ru/enomo-casino-promokod/]Бонусы за регистрацию с промокодом Enomo казино[/url] – Бонусы за регистрацию с промокодом Риобет, Казино X промокод
Dobite a preskumajte Bobotov Kuk a pocitite majestatnost hor! Najvyssi vrch Ciernej Hory (2523 m) ponuka ohromujuce panoramy, vzrusujuce trasy a nezabudnutelne emocie. Zistite najlepsie lezecke cesty a tipy na bezpecny vylet!
Otkrijte most Djurdjevic Tara Bridge – jedan od najlepsih mostova u Evropi! Jedinstvena gradevina iznad kanjona Tare zadivljuje svojom razmjerom i panoramskim pogledom. Najbolje rute, izleti i savjeti za putnike!
Kaufen Sie montenegro – Ihr Zuhause am Meer oder in den Bergen! Tolle Angebote, Villen, Wohnungen und Apartments. Informieren Sie sich uber die besten Lagen, Preise, rechtlichen Feinheiten und Investitionsmoglichkeiten!
Круглосуточные займы без отказов – отличный способ решить финансовые вопросы. Выбирай проверенные МФО и моментально получай [url=https://telegra.ph/Zajm-na-kartu-onlajn—poluchite-zajm-onlajn-ot-luchshih-MFO-02-15]какие микрозаймы дают займы на любые карты [/url] без скрытых условий и длительных ожиданий.
Срочно понадобились деньги, зашел в Яндекс и сразу нашел отличный вариант! Оформил [url=https://telegra.ph/Zajmy-s-plohoj-kreditnoj-istoriej—vzyat-zajm-s-plohoj-KI-i-prosrochkami-03-16]кредит онлайн на карту без отказа без проверки мгновенно [/url], одобрили быстро, условия отличные – всего 0.6% в день.
Подкаст о https://lombardizumrud.ru финансах.
[url=https://betslive.ru/enomo-casino-promokod/]Enomo casino промокод[/url] – pokerok промокод, 1xgames промокод при регистрации
Мне самому помог этот https://glykas.com.gr/2017/09/27/highlights-from-hong-kongs-art-central/ ресурс по бизнесу.
Sakupon an Salog Tara https://www.tara-montenegro-rafting.me an pinakamarahay na pag-rafting sa Montenegro! Pag-raft sa saro sa pinakahararom na mga kanyon sa Europa, an pinakadalisay na tubig asin naturalesa kan Durmitor. An perpektong pakikipagsapalaran para sa mga mahilig sa luwas!
Успешные кейсы применения финансов: https://triumph-uk.ru
Enjoy fun at Tara river rafting extreme rafting, kayaking, boating and camping in picturesque places. The perfect place for active recreation and immersion in wild nature!
Хотите списать долги? банкротство в самаре помощь в сложных финансовых ситуациях. Освободитесь от кредитов, штрафов и задолженностей. Узнайте, как начать процедуру прямо сейчас!
1win pro [url=https://www.1win820.ru]1win pro[/url] .
1win kg [url=https://www.1win821.ru]https://www.1win821.ru[/url] .
1win online [url=https://www.1win808.ru]https://www.1win808.ru[/url] .
Мнение специалистов о бизнесе: https://mueenahmed.com/?p=4
Перспективы финансов: https://123inv.ru
Успешные https://1pzk.ru кейсы применения финансов.
Приветствую. https://activefond.ru Подскажите, где посмотреть информацию о финансах?
История становления https://www.peretyazhka-mebeli-v-novosibirske-154.ru/ бизнеса.
A seamless fusion of local care with international expertise.
cost lisinopril without dr prescription
Every pharmacist here is a true professional.
Пример из https://cm-rf.ru практики: Финансы.
купить товарный бетон с доставкой [url=https://betonby.ru/]купить товарный бетон с доставкой[/url] .
ТОП-10 ресурсов по финансам: https://centrdeklaraciy22.ru
commercial movers in toronto moving and storage toronto
Статьи о ремонте и строительстве https://tvin270584.livejournal.com советы, инструкции и лайфхаки! Узнайте, как выбрать материалы, спланировать бюджет, сделать ремонт своими руками и избежать ошибок при строительстве.
Ремонт и сантехника https://santekhnik-moskva.blogspot.com пошаговые инструкции, выбор материалов, монтаж систем водоснабжения и отопления, устранение протечек и установка сантехнических приборов. Советы экспертов для качественного ремонта!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Секретные методы https://myavto24.ru/ бизнеса.
Смешные случаи в финансах: https://pgl48.ru
Какие платформы https://nika42.ru использовать для финансов?
мостбет скачать на андроид [url=https://www.mostbet1006.com.kg]https://www.mostbet1006.com.kg[/url] .
мастбет [url=https://mostbet1007.com.kg]https://mostbet1007.com.kg[/url] .
Нужна машина в прокат? прокат авто в алуште быстро, выгодно и без лишних забот! Машины всех классов, удобные условия аренды, страховка и гибкие тарифы. Забронируйте авто в несколько кликов!
mostber [url=www.mostbet1008.com.kg]www.mostbet1008.com.kg[/url] .
explosives esports news explosives
Ready-made custom works by link fast, high-quality and inexpensive! We will help with abstracts, term papers, diplomas, essays and other academic assignments. Guaranteed originality, deadlines and 24/7 support!
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Нужен качественный бетон? бетон в день звонка быстро, надёжно и по выгодной цене! Прямые поставки от производителя, различные марки, точное соблюдение сроков. Оперативная доставка на стройплощадки, заказ онлайн или по телефону!
Бюро переводов Сочи «ЛОГОС» в Сочи – это услуги по профессиональным, письменным переводам текстов любой сложности и любых типов документов (юридических, экономических, медицинских, технических) с нотариальным заверением.
сайты где кейсы кс го http://cs-go.ru
1Win Brasil 1winbr com apostas esportivas e cassino online! Altas odds, bonus generosos e ampla variedade de jogos. Aposte em esportes, jogue no cassino e aproveite as melhores promocoes agora mesmo!
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Sports betting with https://1xbetapp-br.com/! Huge selection of matches, live bets, generous bonuses and lightning-fast payouts. Play casino, eSports and win at any time!
Welcome to Winbet Casino https://winbetaz.biz/ a place where luck is on your side! Huge selection of games, bonuses for new players and instant payouts. Try your luck right now!
Внезапно ушла сестра. В “Городской ритуальной службе” все сделали деликатно и с уважением. Сибирский Тракт, 31А, г. Казань [url=https://yandex.ru/maps/org/gorodskaya_ritualnaya_sluzhba/213997720181/]https://yandex.ru/maps/org/gorodskaya_ritualnaya_sluzhba/213997720181/[/url]
устройство дренажа на участке спб [url=http://www.drenazh-uchastka-96.ru]устройство дренажа на участке спб[/url] .
site here https://web-lumiwallet.com
скачать crazy monkey https://www.crazymonkeygame.com
maximum winnings with https://onewinwin.in! Bet on sports, play in the casino, participate in promotions and tournaments. Convenient payments, fast payouts and a welcome bonus for beginners. Join 1win and collect your winnings!
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Что допустим важные тенденции рынка проходят мимо вас? На [url=https://telegra.ph/Moshenniki-na-finansovom-rynke—chislo-aferistov-vyroslo-vdvoe-02-17]Почему важно следить за движением валют? [/url] стоит подписаться, чтобы всегда быть в курсе свежих финансовых изменений, стоимости валют и кредитных предложений. Мы предоставляем только проверенную информацию: какие микрозаймы выгоднее, где взять займ на выгодных ставках, что ждёт финансовый рынок и какие оценки специалистов.
Не пропускайте главные события! На нашем портале [url=https://telegra.ph/CB-obnovit-osnovaniya-dlya-blokirovki-schetov-v-bankah-02-17]Как не потерять деньги в условиях экономического кризиса [/url] обновляются ежедневно, а разбор тенденций объясняется понятными словами. Будьте в курсе событий, изучайте мнения профессионалов и используйте информацию в своих интересах. В мире, где финансовые рынки нестабильны, важно быть в числе первых.
I blog frequently and I truly appreciate your information. Your article has truly peaked my interest. I am going to book mark your blog and keep checking for new details about once per week. I subscribed to your Feed as well.
снятие ломки анонимно
mostbet kg скачать на андроид [url=http://mostbet788.ru/]http://mostbet788.ru/[/url] .
мостбет [url=https://mostbet787.ru]мостбет[/url] .
1win онлайн [url=https://www.1win809.ru]https://www.1win809.ru[/url] .
戰神賽特
「戰神賽特」— 2025年最火爆的老虎機,等你來挑戰!
如果你正在尋找一款高賠率、刺激又充滿神秘感的老虎機遊戲,那麼「戰神賽特」絕對是你的最佳選擇!這款由RG電子精心打造的遊戲,以古埃及戰神賽特為主題,結合精美畫面與震撼音效,帶你進入神秘的沙漠世界,感受無與倫比的刺激體驗。
為何玩家瘋狂愛上戰神賽特?
超狂賠率 51,000 倍:一轉瞬間,財富翻倍不是夢
高RTP達96.89%:更高勝率,更多機會贏得大獎
獨特遊戲機制:掉落消除+獎金購買,玩法多樣更刺激
極致視聽享受:古埃及風格設計+震撼音效,讓你完全沉浸其中
無論你是老虎機高手還是新手玩家,「戰神賽特」都能帶給你前所未有的遊戲體驗!快來挑戰戰神,贏取屬於你的豐厚獎勵!
why not try here https://web-lumiwallet.com/
gambling without limits https://one-1win.in wide selection of games, high odds, fast payouts and exclusive bonuses. Try your luck in the casino and on bets. Play, win and earn with 1win!
Что когда важные финансовые новости проходят мимо вас? На [url=https://telegra.ph/Dollar-upal-do-80-rublej—chto-budet-s-kursom-dollar-i-rubl-v-blizhajshee-vremya-03-18]Какие новости экономики нельзя пропускать? [/url] стоит следить за ними, чтобы всегда быть в курсе свежих прогнозов, изменений на валютном рынке и кредитных предложений. Мы публикуем только свежую информацию: какие кредиты доступны, где получить деньги на лучших условиях, что происходит с инфляцией и какие мнения аналитиков.
Не упускайте главные события! На нашем портале [url=https://telegra.ph/MFO-pod-udarom—zakonodateli-hotyat-ostanovit-kreditovanie-zakreditovannyh-grazhdan-02-17]Что происходит в экономике? Узнайте прямо сейчас [/url] доступны в любое время, а разбор тенденций излагается доступно. Будьте в курсе событий, читайте прогнозы экспертов и действуйте с пониманием ситуации. В мире, где денежные потоки непредсказуемы, важно быть в числе первых.
your game, your rules http://winbkaz.biz Sports, eSports, casino, poker and slots – choose and win! Convenient account replenishment, instant withdrawals and cool promotions for new players. Join now!
кайт школа хургада
Aw, this was a very nice post. Finding the time and actual effort to generate a very good article… but what can I say… I put things off a whole lot and don’t manage to get nearly anything done.
снять ломку наркомана
Хотите получить 10 euros por registrarte начни игру без риска – Открой для себя захватывающие слоты, живое казино и эксклюзивные бонусы. Играй с комфортом, наслаждайся топовыми играми и выигрывай!
Mostbet Uzbekistan https://mostbetuzbekistan-apk.com/ offers you profitable bets, top odds and instant payouts. Make sports predictions, play online casino and enjoy the excitement with registration bonuses!
мостбет кг [url=www.mymoscow.forum24.ru/?1-2-0-00000718-000-0-0-1742357638]www.mymoscow.forum24.ru/?1-2-0-00000718-000-0-0-1742357638[/url] .
1win вход на сайт [url=https://mymoscow.forum24.ru/?1-2-0-00000717-000-0-0-1742357431/]https://mymoscow.forum24.ru/?1-2-0-00000717-000-0-0-1742357431/[/url] .
1wi. [url=https://cah.forum24.ru/?1-19-0-00000732-000-0-0]https://cah.forum24.ru/?1-19-0-00000732-000-0-0[/url] .
Azure Storage Explorer https://github.com/azure-docs/Azure-Storage-Explorer/releases is a convenient tool for managing data in the Azure cloud. Work with Blob, Table, Queue and File Storage through an intuitive interface.
Дежурный администратор в больнице рекомендовал [url=https://telegra.ph/Pochka-skolko-stoit-03-07]ознакомиться со статьей о донорстве[/url]. Кремация организована с пониманием. Сотрудники работают профессионально.
Магазин печей и каминов https://pech.pro широкий выбор дровяных, газовых и электрических моделей. Стильные решения для дома, дачи и бани. Быстрая доставка, установка и гарантия качества!
heroin ufc terrorist attack
кайт школа анапа
Online Casino mit Bonus Crab – mega gewinne warten auf dich! Beginne [url=https://kosnews.bigcartel.com/product/bonus-crab]bonus crab casino[/url] deine reise zu riesigen jackpots und exklusiven belohnungen, die jeden spin spannender und lohnenswerter machen als je zuvor.
септик для частного дома в спб септик для частного дома в спб
gay esports porn
heroin esports porn
1win казино – официальный сайт [url=http://1win705.ru]http://1win705.ru[/url] .
mostbet [url=https://mostbet780.ru/]https://mostbet780.ru/[/url] .
скачать мостбет официальный сайт [url=http://mostbet781.ru]http://mostbet781.ru[/url] .
cocaine esports porn
cocaine esports terrorist attack
BMW X6: идеально для активной жизни, узнайте.
Комфорт и стиль в BMW X6, привлекать.
инновации.
Уникальный дизайн BMW X6, кроссоверов.
Как BMW X6 меняет правила игры, исследуйте.
BMW X6: лучшее сочетание цены и качества, в свое будущее.
Роскошь внутри BMW X6, высокий уровень.
Ваш надежный спутник – BMW X6, гарантирует.
Почему стоит выбрать BMW X6?, в нашем исследовании.
Динамичный BMW X6 – для активной жизни, каждого.
Как BMW X6 заботится о вашей безопасности, на высшем уровне.
BMW X6 – это не просто кроссовер, новые стандарты.
Технологический прогресс BMW X6, формируют.
Исключительный комфорт BMW X6, особенности.
Преимущества владения BMW X6, в нашем руководстве.
BMW X6: стиль, который невозможно не заметить, выразит вашу индивидуальность.
BMW X6 против других SUV, в нашем отчете.
Что говорят владельцы о BMW X6?, в нашем обзоре.
Современные системы безопасности BMW X6, позаботятся о вас.
BMW X6: наш окончательный вердикт, предлагаем выводы.
ix1 bmw [url=https://bmw-x6.biz.ua/]https://bmw-x6.biz.ua/[/url] .
Chicken Road Casino is a game like no other, offering pure chaos and fun. Spin [url=https://bsky.app/profile/barbarossarevenge.bsky.social]source[/url] to help chickens dodge traffic while unlocking free spins, jackpots, and endless entertainment unlike anything else.
visit our website [url=https://www.acheter-faux-billet.com]acheter des billets contrefaits[/url]
Consistency, quality, and care on an international level.
where to get cytotec without a prescription
They’re globally renowned for their impeccable service.
navigate to this web-site [url=https://www.acheter-faux-billet.com/]acheter des faux billets[/url]
Наши любимые модели BMW для каждого водителя, поклонников бренда.
Узнайте о лучших моделях BMW, которые вдохновляют.
Откройте для себя новейшие модели BMW, включая.
От компактных до люксовых: модельный ряд BMW, невероятно разнообразен.
Погрузитесь в мир премиальных автомобилей BMW, лучшие технологии.
Что отличает BMW от других брендов, с уникальными особенностями.
Эволюция автомобилей: модельный ряд BMW, тех, кто стремится к совершенству.
Лучшие автомобили в модельном ряду BMW, которые заинтересуют.
Как BMW отвечает на вызовы времени, узнайте.
Модели BMW: оптимальный выбор для всех, превосходящие ожидания.
Погрузитесь в технологии BMW, это опыт, который нужно испытать.
Каждая модель BMW — это удовольствие от вождения, который покоряет сердца.
Каждая модель BMW — это мастерская инженерия, поклонников.
Почему BMW — это ваш идеальный выбор, от классики до современности.
Вдохновляйтесь моделями BMW для вашего стиля жизни, с передовыми технологиями.
От автомобилей для города до внедорожников: BMW, для любых приключений.
Модельный ряд BMW: сочетание стиля и технических решений, для тех, кто ищет лучшее.
Откройте для себя свою следующую BMW, с комфортом и стилем.
Каждый автомобиль BMW — это возможность, на любой вкус.
bmw x7 2019 [url=https://model-series-bmw.biz.ua/]bmw x7 2019[/url] .
Always up-to-date with the latest healthcare trends.
lisinopril without rx
They provide valuable advice on international drug interactions.
heroin esports porn
cocaine esports gay
1win. com [url=https://agility.forum24.ru/?1-0-0-00000755-000-0-0-1742359870]https://agility.forum24.ru/?1-0-0-00000755-000-0-0-1742359870[/url] .
мостбет скачать на андроид [url=https://agility.forum24.ru/?1-0-0-00000756-000-0-0-1742360323]https://agility.forum24.ru/?1-0-0-00000756-000-0-0-1742360323[/url] .
1win aplicația [url=http://1win5002.ru/]1win aplicația[/url] .
terrorist attack esports gay
terrorist attack esports cocaine
кайтсёрфинг в хургаде
I always find great deals in their monthly promotions.
generic cipro without prescription
Their international insights have benefited me greatly.
кайт египет
Transform your car into a spectacular creation with Eurshall’s Auto Body’s exceptional tuning solutions . Our skilled team dedicates itself to upgrading each vehicle to realize its full performance. Whether you’re aiming for pace or flair , our made-to-order solutions ensure thorough results. Visit https://eurshallsautobody.com/ today to explore the innovation and maneuver a vehicle that truly reflects your personality .
gay esports terrorist attack
Free steam accounts https://t.me/s/freesteamaccountc
Enjoy live sports betting on 888Starz Pakistan and use promo code 888LEGAL for bonuses.
Sheet music for piano sheet music and piano
Klavier lernen noten kostenlos noten klavier pdf
Klavier mit noten noten vom klavier
Тут можно преобрести cейф взломостойкий сейф банковский взломостойкий
Работники кладбища посоветовали [url=https://apteka.rin.ru/novosti/224321/kak-perezhit-poteryu-blizkogo-cheloveka-i-spravitsya-s-gorem.html]Apteka.rin.ru[/url]. Организация похорон прошла без нервотрепки. Благодарны за помощь.
помощь в согласовании перепланировки квартиры [url=www.soglasovanie-pereplanirovki-kvartiry14.ru/]помощь в согласовании перепланировки квартиры[/url] .
1win kg [url=https://www.belbeer.borda.ru/?1-6-0-00001555-000-0-0-1742473542]https://www.belbeer.borda.ru/?1-6-0-00001555-000-0-0-1742473542[/url] .
1win букмекер [url=https://taksafonchik.borda.ru/?1-14-0-00002041-000-0-0]https://taksafonchik.borda.ru/?1-14-0-00002041-000-0-0[/url] .
мостбет скачать казино [url=http://ongame.forum24.ru/?1-18-0-00001219-000-0-0-1742360461/]http://ongame.forum24.ru/?1-18-0-00001219-000-0-0-1742360461/[/url] .
Piano sheet music music piano sheet music music
Хотите списать долги? https://pro-58.ru/ законное освобождение от кредитных обязательств. Работаем с физлицами и бизнесом. Бесплатная консультация!
Site-ul https://betsysrealfood.com este o resursa cu diverse articole in limba romana, acoperind subiecte precum sanatatea, nutri?ia, moda ?i stilul de via?a. Titlurile articolelor includ teme precum „?tiri de sanatate”, „?tiri pentru bebelu?i”, „?tiri de Medicina Alternativa” ?i „?tiri de via?a”. Site-ul este destinat publicului vorbitor de romana, interesat de un stil de via?a sanatos ?i re?ete de casa.
Быстрая продажа и покупка https://profis.com.ua/ размещайте объявления о продаже товаров, поиске услуг, аренде недвижимости и работе. Простой интерфейс, удобный поиск, бесплатные публикации!
кайт хургада
Теплый пол требует особого подхода к ремонту и обслуживанию. Специалисты раскрывают все нюансы работы с системой обогрева в руководстве [url=https://telegra.ph/Gruntovka-dlya-gipsokartona-pod-shpaklevku-03-03]отделка под ключ[/url], помогая избежать типичных ошибок при монтаже и ремонте.
вывески наружная реклама рекламный стенд уличный
изготовление световой вывески вывески для магазинов
где купить медицинскую справку на права медицинский центр спб справки
win 1 [url=http://1win822.ru/]http://1win822.ru/[/url] .
мостбет скачать на андроид [url=http://mostbet782.ru/]http://mostbet782.ru/[/url] .
карниз электрический [url=http://elektrokarnizy-dlya-shtor.ru/]карниз электрический[/url] .
[url=https://kraken.xn--onon-hya.com]кракен даркнет[/url] – kraken зеркало, как зайти на кракен
Loyalty Program http://www.nomini-casino.ru
1win ru [url=http://1win823.ru]http://1win823.ru[/url] .
Зимой мегаполис окутан в снегу, создавая неудобства для транспорта и жителей. Мы решаем эту задачу! Компания «Снегоплав» – профессионал в сфере утилизации снега, предлагающий инновационные решения для коммунальных служб. Наши технологии обеспечивают возможность оперативно и качественно ликвидировать снежные завалы, сокращая временные и финансовые расходы и обеспечивая безопасность на дорогах. Каждая [url=https://snegoplav.com/]снегоплавильная установка зачем[/url] от «Снегоплав» – это сочетание надёжности, высокой эффективности и функциональности.
Мы разрабатываем оборудование, способное утилизирует снег в воду непосредственно на объекте. Это безопасный и экономичный способ уборки улиц, избавляющий от обязанности вывоза снега за город. В нашем предложении – переносные и мощные установки, адаптированные под различные условия работы. Если вам нужна проверенная [url=https://snegoplav.com/]мобильная снегоплавильная установка[/url] мы предложим лучшее оборудование для всех масштабов масштаба – для небольших участков до областных центров.
Выбирая нашу компанию, вы получаете новейшие технологии, сертифицированное оборудование и профессиональное обслуживание. Наши разработки – идеальный вариант городских предприятий, строительных компаний и муниципальных структур. Свяжитесь с нами: +7 (495) 123-45-67 или заходите в наш офис: г. Москва, ул. Примерная, д. 10.
[url=][/url]
Все о недвижимости в России и мире — новости, аналитика, советы экспертов в одном месте!
Хотите быть в курсе последних событий на рынке недвижимости? Мы предлагаем свежие новости, актуальные обзоры и экспертные мнения по всем ключевым вопросам: изменения в законодательстве, тренды в сфере жилья и коммерческой недвижимости, а также прогнозы цен на ближайшее будущее.
У нас вы найдете полезные рекомендации для инвесторов и владельцев недвижимости: как выгодно вложить средства в жилье, защитить свои инвестиции, выбрать надежного застройщика и избежать ошибок при заключении сделок. Мы также поможем разобраться в юридических тонкостях покупки, аренды и оформления прав собственности.
Следите за обзорами крупнейших событий на рынке недвижимости, узнавайте о новых проектах, возможностях для инвестиций и изменениях в инфраструктуре городов. Кроме того, мы делимся советами по обустройству жилья, лайфхаками для ремонта и рекомендациями по выбору материалов и услуг — от поиска профессиональных подрядчиков до экономии без потери качества.
Только актуальная информация от ведущих экспертов отрасли — проверенные факты, аналитика и прогнозы.
Подписывайтесь и оставайтесь в центре событий! С нами вы всегда будете на шаг впереди — ведь ваш дом и инвестиции заслуживают самого лучшего!
Сайт sis69.ru
[url=][/url]
Хотите перекусить вкусно? купить Пита средиземноморская питу, шаверму, донер, гирос и тортилью. Ароматная свежая выпечка, мясо на гриле и фирменные соусы. Отличный выбор для перекуса, обеда или вечеринки.
кайт эльгуна
Kasyno Mostbet oferuje setki automatów i gier na żywo | Sprawdź logowanie do kasyna Mostbet i graj bez ograniczeń | Mostbet Polska stale rozwija swoją ofertę dla graczy z Polski [url=https://mostbet-kasyno-strona-pl.com/]www.mostbet.com[/url]
типография спб книги tipografiya-price.ru
типография спб наклейки типография санкт петербург
Rejestracja w Mostbet zajmuje tylko chwilę, a bonusy czekają od razu | Z Mostbet możesz zagrać na automatach, ruletce i w pokera | Z Mostbet możesz grać zarówno na komputerze, jak i w telefonie [url=https://mostbet-kasyno-strona-pl.com/]Mostbet opinie graczy[/url]
Mostbet Polska to idealne miejsce na rozpoczęcie przygody z grami online | Mostbet com to oficjalna strona z pełnym dostępem do wszystkich funkcji | Dołącz do Mostbet i odbierz bonus bez depozytu [url=https://mostbet-kasyno-strona-pl.com/]Kasyno i zakłady Mostbet[/url]
Тут можно преобрести сейф металлический взломостойкий вломостойкие сейфы
helpful hints [url=https://galaxy-swapper.org]galaxyswapper[/url]
1win ракета [url=http://1win810.ru/]http://1win810.ru/[/url] .
mostbet kg скачать [url=https://mostbet783.ru]https://mostbet783.ru[/url] .
мостбет официальный сайт [url=https://mostbet784.ru]https://mostbet784.ru[/url] .
Mostbet Polska to idealne miejsce na rozpoczęcie przygody z grami online | Mostbet pl to legalna strona z certyfikatem i ochroną danych | Z Mostbet możesz grać zarówno na komputerze, jak i w telefonie [url=https://mostbet-kasyno-strona-pl.com/]most bet Polska[/url]
Web Site
[url=https://galaxy-swapper.org/]galaxy swapper[/url]
Mostbet to zaufana platforma dla miłośników zakładów sportowych | Mostbet online daje dostęp do gier 24/7 z każdego urządzenia | Mostbet Polska stale rozwija swoją ofertę dla graczy z Polski [url=https://mostbet-kasyno-strona-pl.com/]mostbet.com[/url]
кайт анапа
Ищете профессионалов для дорогого авто? [url=https://t.me/s/nord_west_deteil]Nord-West детейлинг[/url] – более 10 лет успешной работы с премиум-автомобилями. Оклейка кузова, полировка и защита керамикой. Ваше авто засияет как новое благодаря нашим экспертам в Великом Новгороде.
Kasyno Mostbet oferuje setki automatów i gier na żywo | Mostbet online daje dostęp do gier 24/7 z każdego urządzenia | Mostbet oferuje wygodne metody płatności i szybką wypłatę środków [url=https://mostbet-kasyno-strona-pl.com/]Mostbet darmowe spiny[/url]
Mostbet to zaufana platforma dla miłośników zakładów sportowych | Mostbet kasyno to nowoczesna platforma z grami od topowych dostawców | Mostbet opinie potwierdzają wysoką jakość obsługi klienta [url=http://mostbet-kasyno-strona-pl.com/]http://mostbet.com[/url]
кайт хургада
Mostbet kasyno online przyciąga atrakcyjnymi promocjami | Czy warto wybrać Mostbet? Opinie graczy mówią same za siebie | Grając w Mostbet masz dostęp do wsparcia technicznego 24/7 [url=https://mostbet-kasyno-strona-pl.com/]mostbet pl logowanie[/url]
зайти на сайт https://maps.google.so/url?q=https://travelanswer.ru/places/covo-oyster-bar.html
Opinie o Mostbet pokazują, że to jedno z najlepszych kasyn w sieci | Mostbet com to oficjalna strona z pełnym dostępem do wszystkich funkcji | Mostbet Polska stale rozwija swoją ofertę dla graczy z Polski [url=https://mostbet-kasyno-strona-pl.com/]Mostbet kasyno online[/url]
Mostbet to zaufana platforma dla miłośników zakładów sportowych | Dzięki bonusowi powitalnemu w Mostbet zaczniesz grę z przewagą | Dołącz do Mostbet i odbierz bonus bez depozytu [url=https://mostbet-kasyno-strona-pl.com/]mostbet casino logowanie[/url]
нажмите здесь http://images.google.bi/url?q=https://travelanswer.ru/places/dublinskiy-zamok.html
печать буклета на принтере https://tipografiya-buklety.ru
печать рекламных наклеек печать прозрачных наклеек
печать на сувенирах спб сувениры с печатью на заказ
Dzięki Mostbet możesz obstawiać i wygrywać każdego dnia | Mostbet logowanie jest intuicyjne i nie sprawia żadnych trudności | Dołącz do Mostbet i odbierz bonus bez depozytu [url=https://mostbet-kasyno-strona-pl.com/]Mostbet opinie graczy[/url]
Mostbet to zaufana platforma dla miłośników zakładów sportowych | Dzięki bonusowi powitalnemu w Mostbet zaczniesz grę z przewagą | Mostbet kasyno oferuje darmowe spiny i turnieje z nagrodami [url=https://mostbet-kasyno-strona-pl.com/]Mostbet Polska – kasyno i zakłady[/url]
мостбет скачать [url=www.eisberg.forum24.ru/?1-0-0-00000327-000-0-0-1742579529]мостбет скачать[/url] .
мостбет мобильная версия скачать [url=https://taksafonchik.borda.ru/?1-14-0-00002042-000-0-0-1742473173/]мостбет мобильная версия скачать[/url] .
1win com [url=fanfiction.borda.ru/?1-3-0-00000125-000-0-0-1742475251]fanfiction.borda.ru/?1-3-0-00000125-000-0-0-1742475251[/url] .
нажмите, чтобы подробнее http://www.google.si/url?sa=i&source=images&cd=&docid=tvesbldjjphkym&tbnid=isrjl50bi1j8bm:&ved=0cagqjrwwaa&url=https://travelanswer.ru/places/egipetskiy-muzey-arheologicheskiy-fond-klosa.html
печать с логотипом для упаковки печать упаковки
печать блокнотов дешево https://pechat-bloknotov.ru
Подробнее https://www.google.sk/url?q=https://travelanswer.ru/questions/kak-odevatysya-v-zaru-v-stambule-soveti-dlya-turistok.html
1winn [url=https://1win824.ru]https://1win824.ru[/url] .
1вин бет официальный сайт [url=http://1win825.ru/]1вин бет официальный сайт[/url] .
1win букмекер [url=https://www.1win811.ru]1win букмекер[/url] .
кайт эльгуна
my latest blog post
[url=https://realbackpack.com/]www backpack[/url]
мотбет [url=http://mostbet785.ru/]http://mostbet785.ru/[/url] .
1 win официальный [url=https://1win826.ru]https://1win826.ru[/url] .
1 win казино [url=http://1win812.ru]http://1win812.ru[/url] .
Revamp your automobile with top-notch tuning solutions. Release its entire power and delight in improved functionality. Our skilled technicians specializes in adapting individual part of your ride to align with your taste and requirements. Check out our page https://autobodywilson.com/ to learn further, and adopt a revitalized car exploration today.
check my site
[url=https://realbackpack.com/]backpack wallet crypto[/url]
have a peek at this site
[url=https://realbackpack.com/]xnft backpack[/url]
лучшая биржа аккаунтов маркетплейс аккаунтов
купить аккаунт на бирже продать аккаунты моментально
лучшая биржа аккаунтов купить аккаунты в соц сетях
[url=www.bankrotstvo-v-moskve123.ru]банкротство физ лиц отзывы[/url]
Home Page [url=https://www.ringsshop1.com/]Department Stores Accessories Sunglasses[/url]
cazinouri online moldova [url=http://1win5003.ru/]http://1win5003.ru/[/url] .
Your article helped me a lot, is there any more related content? Thanks! https://accounts.binance.com/lv/register?ref=B4EPR6J0
1win бк [url=https://www.1win827.ru]https://www.1win827.ru[/url] .
motbet [url=https://www.mostbet786.ru]motbet[/url] .
Прочные и удобные zip пакеты с логотипом опт и розница, разные размеры, надежная застежка. Для хранения, фасовки и перевозки. Оформите заказ онлайн с быстрой доставкой!
Discover Travel to Montenegro crystal clear sea, mountain landscapes, ancient cities and delicious cuisine. We organize a turnkey trip: flight, accommodation, excursions.
мтс тв
http://gsrl.uk/employer/24inetrnet-domashnij-ekb-2/
мтс телевидение екатеринбург
Glory Casino app
iPhone 12 iphone 15 pro max
Кухня, о которой я мечтал, стала реальностью благодаря “Эталон Кухни”! +7(843)258-86-66 https://yandex.ru/maps/org/etalon_kukhni/1146748982/
кайт египет
Rejestracja szybka i intuicyjna – zyskałem bonus bez depozytu | Doskonałe źródło wiedzy o legalnych grach w Polsce | Świetne opisy promocji i ofert dla nowych graczy | Rzetelne recenzje i wskazówki dla każdego gracza | Bardzo dobre porównanie kodów promocyjnych | Ranking kasyn ze szczegółowymi opiniami graczy | Bardzo przystępna nawigacja po serwisie | Przydatne informacje dla każdego gracza | Najwyższy poziom bezpieczeństwa i szyfrowania [url=https://legalne-kasyno-online-polska.com/mostbet/]mostbet kod promocyjny 2024[/url].
find out here [url=https://surfwallet.io/]wallet surf[/url]
Najlepsze kasyna w Polsce w jednym miejscu – wszystko jasno opisane | Strona pomaga wybrać najlepsze zakłady bukmacherskie w Polsce | Dobry wybór kasyn z darmowymi spinami | Kasyna z najwyższymi ocenami dostępne od ręki | Legalne zakłady esportowe w jednym miejscu | Duża baza wiedzy o rynku gier w Polsce | Często aktualizowane bonusy i promocje | Kasyna i bukmacherzy dopasowani do polskich graczy | Ranking kasyn 2024 – aktualne dane [url=https://legalne-kasyno-online-polska.com/bookmakers/]bukmacherzy bonusy bez depozytu[/url].
Planning a vacation? https://weather-webcam-in-montenegro.com/sutomore is a warm sea, picturesque beaches, cozy cities and affordable prices. A great option for a couple, family or solo traveler.
Holidays in Kotor are European comfort at an affordable price. Transparent sea, clean beaches, historical cities and warm climate all year round.
Ten serwis świetnie porównuje oferty bonusów kasynowych | Ranking kasyn online naprawdę ułatwia orientację na rynku | Szybki dostęp do logowania i promocji | Ciekawie opisane doświadczenia graczy z Polski | Znalazłem idealne kasyno z promocją cashback | Najlepsze kasyno z szybką rejestracją i płatnościami BLIK | Często aktualizowane bonusy i promocje | Przydatne informacje dla każdego gracza | Szybka rejestracja i natychmiastowy bonus powitalny [url=https://legalne-kasyno-online-polska.com/vulkan-vegas/]vulkan vegas bonusy[/url].
1win. pro [url=http://1win6011.ru]http://1win6011.ru[/url] .
1win [url=http://1win813.ru/]http://1win813.ru/[/url] .
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. https://accounts.binance.com/da-DK/register?ref=V2H9AFPY
mostbet casino [url=http://mostbet794.ru/]http://mostbet794.ru/[/url] .
Dobre promocje i przejrzyste zasady to ogromna zaleta tego serwisu | Ranking kasyn online naprawdę ułatwia orientację na rynku | Dobry wybór kasyn z darmowymi spinami | Przyjazny interfejs i łatwość poruszania się po stronie | Możliwość porównania ofert przed rejestracją | Funkcjonalna wyszukiwarka kodów promocyjnych | Zestawienie kasyn online z szybkimi wypłatami | Przydatne informacje dla każdego gracza | Dostępność wsparcia technicznego i FAQ [url=https://legalne-kasyno-online-polska.com/vulkan-vegas/]kasyno vulkan vegas[/url].
купите недорого профильную стальную трубу proftruba-moscow.ru с доставкой до склада или объекта. предлагаем услуги порезки и упаковки металлопроката.
Портал для любознательных https://dom-nam.ru/index.php/forum/razdel-predlozhenij/164363-aviatsionnyj-anglijskij#203106 Полезная информация, тренды, обзоры, советы и много вдохновляющего контента. Каждый день — повод зайти снова!
ваучер 1win [url=pboarders.borda.ru/?1-11-0-00000929-000-0-0-1742818701]pboarders.borda.ru/?1-11-0-00000929-000-0-0-1742818701[/url] .
Najlepsze kasyna w Polsce w jednym miejscu – wszystko jasno opisane | Doskonałe źródło wiedzy o legalnych grach w Polsce | Przydatne porady jak wypłacić pieniądze z konta | Wszystko opisane prostym językiem, bez zbędnego żargonu | Serwis idealny dla nowych i doświadczonych graczy | Duża baza wiedzy o rynku gier w Polsce | Bezpieczne zakłady bukmacherskie bez depozytu | Doskonałe kasyna z grami typu slot i ruletka | Ranking kasyn 2024 – aktualne dane [url=https://legalne-kasyno-online-polska.com/bookmakers/]bukmacherzy z cashbackiem[/url].
great post to read [url=https://surfwallet.io]zkLogin sui[/url]
мостбет промокод [url=https://www.shorts.borda.ru/?1-18-0-00000397-000-0-0]https://www.shorts.borda.ru/?1-18-0-00000397-000-0-0[/url] .
useful site [url=https://surfwallet.io]zkLogin[/url]
Fajne zestawienie kasyn z płatnościami BLIK i przelewy24 | Pomocna porównywarka legalnych bukmacherów | Znalazłem tu ciekawe kasyna z bonusem za rejestrację | Kasyno z szybką wypłatą – tu znajdziesz ranking | Lista legalnych kasyn w Polsce z dokładnymi opisami | Najlepsi bukmacherzy z polską licencją – lista aktualna | Legalne kasyno z wysokim bonusem powitalnym | Doskonałe kasyna z grami typu slot i ruletka | Ranking kasyn 2024 – aktualne dane [url=https://legalne-kasyno-online-polska.com]kasyno online polska bez depozytu[/url].
Jeśli szukasz sprawdzonych bukmacherów, warto sprawdzić to zestawienie | Wszystko w jednym miejscu – kasyna, zakłady, promocje | Znalazłem tu ciekawe kasyna z bonusem za rejestrację | Wszystko opisane prostym językiem, bez zbędnego żargonu | Darmowe spiny bez depozytu – warto zajrzeć | Najlepsze kasyno z szybką rejestracją i płatnościami BLIK | Bardzo przystępna nawigacja po serwisie | Fajne porady dla graczy początkujących i zaawansowanych | Najwyższy poziom bezpieczeństwa i szyfrowania [url=https://legalne-kasyno-online-polska.com/vulkan-vegas/]vulkan vegas rejestracja[/url].
быстрая продажа аккаунтов аккаунты маркетплейсов купить
link [url=https://surfwallet.io/]zkLogin sui[/url]
магазин продажи аккаунтов http://birzha-akkauntov.ru
Ten serwis świetnie porównuje oferty bonusów kasynowych | Wszystko w jednym miejscu – kasyna, zakłady, promocje | Świetne opisy promocji i ofert dla nowych graczy | Kasyna z cashbackiem i kodami bonusowymi – dobre zestawienie | Kasyna dostępne na urządzeniach mobilnych – to duży plus | Funkcjonalna wyszukiwarka kodów promocyjnych | Często aktualizowane bonusy i promocje | Doskonałe kasyna z grami typu slot i ruletka | Bezpieczne metody płatności – szybkie wypłaty [url=https://legalne-kasyno-online-polska.com/bookmakers/]bonus bukmacherski bez depozytu[/url.
Fajne zestawienie kasyn z płatnościami BLIK i przelewy24 | Strona pomaga wybrać najlepsze zakłady bukmacherskie w Polsce | Znalazłem tu ciekawe kasyna z bonusem za rejestrację | Rzetelne recenzje i wskazówki dla każdego gracza | Znalazłem idealne kasyno z promocją cashback | Najlepsze kasyno z szybką rejestracją i płatnościami BLIK | Oferty kasyn z rejestracją w kilka kliknięć | Legalność serwisów szczegółowo wyjaśniona | Kasyno polecane przez graczy z Polski [url=https://legalne-kasyno-online-polska.com/bookmakers/]bukmacherzy z cashbackiem[/url].
https://imgtube.ru/
Jeśli szukasz sprawdzonych bukmacherów, warto sprawdzić to zestawienie | Sprawdzona strona dla graczy online w Polsce | Przydatne porady jak wypłacić pieniądze z konta | Wszystko opisane prostym językiem, bez zbędnego żargonu | Darmowe spiny bez depozytu – warto zajrzeć | Funkcjonalna wyszukiwarka kodów promocyjnych | Szeroka oferta bukmacherów z cashbackiem i promocjami | Fajne porady dla graczy początkujących i zaawansowanych | Najciekawsze opcje gier dostępne w kasynach [url=https://legalne-kasyno-online-polska.com/vulkan-vegas/]vulkan vegas bonusy[/url].
Zaskakująco duży wybór legalnych bukmacherów z cashbackiem | Sprawdzona strona dla graczy online w Polsce | Szybki dostęp do logowania i promocji | Kasyna z cashbackiem i kodami bonusowymi – dobre zestawienie | Znalazłem idealne kasyno z promocją cashback | Świetne kasyna z darmową rejestracją i bonusem | Legalne kasyno z wysokim bonusem powitalnym | Możliwość rejestracji bez ryzyka – bonus bez depozytu | Oferty bez haczyków – wszystko transparentne [url=https://legalne-kasyno-online-polska.com]kasyno online polska[/url].
Zaskakująco duży wybór legalnych bukmacherów z cashbackiem | Doskonałe źródło wiedzy o legalnych grach w Polsce | Przydatne porady jak wypłacić pieniądze z konta | Wszystko opisane prostym językiem, bez zbędnego żargonu | Znalazłem idealne kasyno z promocją cashback | Najlepsi bukmacherzy z polską licencją – lista aktualna | Często aktualizowane bonusy i promocje | Kasyno online z najlepszymi ocenami – wszystko jasne | Ranking kasyn 2024 – aktualne dane [url=https://legalne-kasyno-online-polska.com/bookmakers/]bukmacher online bonus na start[/url].
1вин [url=https://www.boardwars.forum24.ru/?1-10-0-00000406-000-0-0]https://www.boardwars.forum24.ru/?1-10-0-00000406-000-0-0[/url] .
Boost your car’s capability and aesthetics with our outstanding tuning assistance. Explore the actual ability of your auto through personalized modifications. Our team of technicians renders unsurpassed standard and creativity. See our webpage https://precisionautobodyfrederick.com/ to learn extra, and commence your path towards motoring superiority today.
мобильная версия риобет риобет зеркало рабочее на сегодня
маркетплейс цифровых аккаунтов маркетплейсы для покупки аккаунта
Dołącz do Mostbet i ciesz się ekscytującymi grami kasynowymi. | Mostbet regularnie aktualizuje ofertę promocyjną dla stałych klientów. | Ciesz się grą w pokera, blackjacka i ruletkę w Mostbet. | Mostbet zapewnia szybkie wypłaty wygranych na Twoje konto. [url=https://mostbet-online-casino-polska.com]mostbet logowanie[/url]
сайт 1win официальный сайт вход [url=http://1win6012.ru/]http://1win6012.ru/[/url] .
1vin kg [url=1win814.ru]1vin kg[/url] .
казино онлайн kg [url=https://www.tagilshops.forum24.ru/?1-4-0-00000205-000-0-0]https://www.tagilshops.forum24.ru/?1-4-0-00000205-000-0-0[/url] .
Mostbet oferuje szeroki wybór gier kasynowych i zakładów sportowych. | Mostbet zapewnia profesjonalną obsługę klienta 24/7. | Mostbet oferuje gry od renomowanych dostawców oprogramowania. | Mostbet zapewnia szybkie wypłaty wygranych na Twoje konto. [url=https://mostbet-online-casino-polska.com]https://mostbet-online-casino-polska.com[/url]
мосбет казино [url=https://www.mostbet795.ru/]https://www.mostbet795.ru/[/url] .
Platforma Mostbet zapewnia atrakcyjne bonusy dla nowych graczy. | Mostbet zapewnia profesjonalną obsługę klienta 24/7. | Mostbet posiada licencję gwarantującą uczciwość gier. | Korzystaj z promocji cashback dostępnych w Mostbet. [url=https://mostbet-online-casino-polska.com]mostbet[/url]
Ремонт помещений ремонт офисов под ключ: офисы, отели, склады. Полный комплекс строительно-отделочных работ, от черновой отделки до финишного дизайна.
Mostbet oferuje zakłady na żywo z atrakcyjnymi kursami. | Mostbet wspiera różne metody płatności, w tym karty i e-portfele. | Mostbet to platforma przyjazna zarówno dla początkujących, jak i zaawansowanych graczy. | Skorzystaj z opcji cash-out dostępnej w Mostbet. [url=https://mostbet-online-casino-polska.com]kasyno mostbet[/url]
Kasyno online Mostbet to gwarancja wysokiej jakości rozrywki. | Mostbet zapewnia profesjonalną obsługę klienta 24/7. | Dołącz do turniejów i wyzwań organizowanych przez Mostbet. | Sprawdź sekcję FAQ na stronie Mostbet w celu uzyskania odpowiedzi na pytania. [url=https://mostbet-online-casino-polska.com]mostbet[/url]
оценка квартиры в новостройке для сбербанка ocenka-zagorod.ru
типография официальный сайт типография низких цен
типография сколько офсетная типография спб
Нью Ретро Казино [url=http://newretromirror.ru]http://newretromirror.ru[/url] .
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Dzięki Mostbet możesz obstawiać ulubione dyscypliny sportowe w Polsce. | Bezpieczeństwo i prywatność są priorytetem w Mostbet. | Korzystaj z programu lojalnościowego Mostbet i zbieraj punkty. | Mostbet oferuje zakłady na e-sporty i wydarzenia specjalne. [url=https://mostbet-online-casino-polska.com]mostbet com[/url]
Platforma Mostbet zapewnia atrakcyjne bonusy dla nowych graczy. | Mostbet regularnie aktualizuje ofertę promocyjną dla stałych klientów. | Mostbet oferuje wysokie kursy na zakłady sportowe. | Skorzystaj z opcji cash-out dostępnej w Mostbet. [url=https://mostbet-online-casino-polska.com]mostbet casino[/url]
грузчики на дом нанять грузчиков
Dzięki Mostbet możesz obstawiać ulubione dyscypliny sportowe w Polsce. | Bezpieczeństwo i prywatność są priorytetem w Mostbet. | Mostbet oferuje wysokie kursy na zakłady sportowe. | Mostbet oferuje zakłady na e-sporty i wydarzenia specjalne. [url=https://mostbet-online-casino-polska.com]mostbet kasyno[/url]
грузоперевозки услуги грузчиков профессиональные грузчики
услуги грузчиков перевозки услуги грузчиков недорого
Mostbet to legalne kasyno online dostępne dla graczy z Polski. | Graj odpowiedzialnie i korzystaj z narzędzi kontroli w Mostbet. | Mostbet to platforma przyjazna zarówno dla początkujących, jak i zaawansowanych graczy. | Dołącz do społeczności graczy Mostbet i dziel się doświadczeniami. [url=https://mostbet-online-casino-polska.com]mostbet pl[/url]
займ залог авто
avtolombard-11.ru/ekb.html
где взять деньги под залог авто
Mostbet oferuje zakłady na żywo z atrakcyjnymi kursami. | Mostbet wspiera różne metody płatności, w tym karty i e-portfele. | Mostbet oferuje wysokie kursy na zakłady sportowe. | Mostbet oferuje zakłady na e-sporty i wydarzenia specjalne. [url=https://mostbet-online-casino-polska.com]mostbet opinie[/url]
Гелиевые шары Липецк фольгированные
Odkryj bogatą ofertę slotów w kasynie Mostbet. | Zarejestruj się w Mostbet i skorzystaj z bonusu powitalnego. | Mostbet posiada licencję gwarantującą uczciwość gier. | Dołącz do społeczności graczy Mostbet i dziel się doświadczeniami. [url=https://mostbet-online-casino-polska.com]mostbet casino[/url]
Odkryj bogatą ofertę slotów w kasynie Mostbet. | Doświadczeni gracze docenią zaawansowane funkcje Mostbet. | Mostbet posiada licencję gwarantującą uczciwość gier. | Sprawdź sekcję FAQ na stronie Mostbet w celu uzyskania odpowiedzi na pytania. [url=https://mostbet-online-casino-polska.com]mostbet casino[/url]
cheap custom essay writing service https://promontoryartists.org/ lit review
Бытовки и модульные здания: надёжное вариант для пользовательских проблем
Бытовки и временные конструкции организовывают оборудовать производственную площадку, хранилище или временное помещение. Мы обеспечиваем здания, которые отвечают высоким стандартам долговечности и удобства.
Характеристики
Прочность. Любые модули изготовлены из ресурсов, прочных к испытаниям и погодным условиям.
Скорость доставки. Конструкция перевозится в пределах 1–2 дней после подписания договора.
Гибкая настройка. Осуществляется компоновка утепления, электропроводки или вентиляции.
Зоны действия
На стройплощадках для размещения оборудования или оборудования места для персонала.
Во время мероприятий для создания информационного центра или помещения для инвентаря.
В качестве временных рабочих зон или пунктов управления.
Плюсы
Экономия времени. Отпадает потребность строить временные помещения.
Комфортабельность. Атмосфера, которые повышают результативность действий бригады.
Подстройка. Шанс проката или долгосрочного использования под конкретные требования и бюджет.
Случай применения
Строительная компания задействовала модульное здание для размещения оборудования и зоны отдыха. Постройка была транспортирована за 24 часа, с специальным утеплением. Партнёр обратил внимание на повышение комфорта и ликвидацию простоев.
Как оформить заказ
Для оформления заказа нужно связаться с нами. Выделим полные данные, окажем помощь подобрать идеальный выбор и выполним перевозку.
1vin [url=1win815.ru]1vin[/url] .
1win войти [url=http://1win6014.ru]http://1win6014.ru[/url] .
mostbet kg отзывы [url=https://kharkovbynight.forum24.ru/?1-15-0-00003047-000-0-0-1742814422]https://kharkovbynight.forum24.ru/?1-15-0-00003047-000-0-0-1742814422[/url] .
1 win kg [url=http://yamama.forum24.ru/?1-11-0-00000459-000-0-0-1742818616/]http://yamama.forum24.ru/?1-11-0-00000459-000-0-0-1742818616/[/url] .
казино онлайн kg [url=https://www.mostbet6001.ru]https://www.mostbet6001.ru[/url] .
автоломбард в казани под залог птс
avtolombard-11.ru/kazan.html
деньги под залог машины
pdacenter.ru – сервис по ремонту бытовой техники
Ремонт iMac в Краснодаре в официальном сервисном центре PDACENTER.
Наши инженеры выполняют ремонт любой сложности по дотупным ценам!
Гелиевые шарики
[url=][/url]
Всё о строительстве, дизайне и ремонте в своём доме.
Добро пожаловать на «Свой Угол» – ваш партнер в мире строительства, дизайна и ремонта для вашего дома!
Наш блог создан для того, чтобы предоставить вам всю необходимую информацию, которая сделает ваш дом еще уютнее, красивее и функциональнее.
Мы – эксперты в следующих сферах:
Строительство
Мы поделимся с вами советами о выборе материалов, поиске надежных строителей в Беларуси и планировке стройплощадки.
Если у вас возникают вопросы о строительстве своего дома с нуля или о расширении уже существующего пространства, мы предоставим вам экспертные советы.
Дизайн интерьера
У нас есть идеи и решения для каждой комнаты в вашем доме.
Мы расскажем о последних трендах в дизайне, поделимся советами по выбору цветовой палитры, мебели и аксессуаров, чтобы создать уникальное пространство, отражающее ваш стиль и вкус.
Ремонт
От простых косметических обновлений до капитального ремонта – у нас есть идеи и рекомендации для каждого случая.
Мы поддержим вас на каждом этапе, начиная от планирования и заканчивая последним штрихом.
Что вы найдете на нашем сайте
Экспертные советы
Статьи разработаны профессионалами в области строительства, дизайна и ремонта.
Полезные ресурсы
Ссылки на проверенные магазины, услуги и материалы, которые помогут вам в ваших проектах.
Модные тренды
Мы следим за последними тенденциями и новинками в мире строительства и дизайна.
«Свой Угол» – ваш проводник в мире уюта и стиля в вашем доме. Погружайтесь в наши статьи, найдите вдохновение, задавайте вопросы и делитесь своим опытом.
Создайте свой угол вместе с нами!
Информационный портал «Свой Угол»
[url=][/url]
Your article helped me a lot, is there any more related content? Thanks!
pop over to this site https://cleanthebit.com/es/
купить аккаунт социальные сети купля продажа аккаунта
Продажа путёвок https://camp-centr.com. Спортивные, творческие и тематические смены. Весёлый и безопасный отдых под присмотром педагогов и аниматоров. Бронируйте онлайн!
печать визиток а4 https://tipografiya-pechat-vizitok.ru
Воздушные шары Липецк с круглосуточной доставкой
кредит под залог автомобиля
avtolombard-11.ru/kemerovo.html
автоломбард в кемерово под залог
1 цшт [url=http://1win816.ru/]http://1win816.ru/[/url] .
мостбет официальный сайт [url=http://maksipolinovtsu.forum24.ru/?1-1-0-00000194-000-0-0-1742815870/]http://maksipolinovtsu.forum24.ru/?1-1-0-00000194-000-0-0-1742815870/[/url] .
1win кейсы [url=https://1win6015.ru/]1win кейсы[/url] .
1 win казино [url=www.mymoscow.forum24.ru/?1-6-0-00026928-000-0-0]1 win казино[/url] .
скачать мостбет официальный сайт [url=https://www.mostbet6002.ru]https://www.mostbet6002.ru[/url] .
Remarkable! Its really remarkable post, I have got much clear idea regarding from this article.
leebet
Znalazłem tu pomocne porady dla graczy. | Kasyna online dobrze porównane. | Znajdziesz tu aktualności sportowe z całej Polski. | Recenzje slotów i gier hazardowych online. | Legalne kasyna i wszystko o rejestracji. | [url=https://slots-play.pl/]najlepsze sloty total casino[/url] | Kasyna online dobrze sklasyfikowane. | Zakłady sportowe przedstawione jasno. | [url=https://gamesplays.pl/]gry z fabułą[/url] | Wybór slotów z różnych kategorii. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]polska siatkówka sport[/url]
круглосуточный автоломбард
avtolombard-11.ru
автоломбард москва под залог
contoh literature review https://miorix.com/ help to write a thesis statement
Выполняем качественное https://energopto.ru/raboty/proektirovanie/proektirovanie-itp-tstp/ под ключ. Энергоэффективные решения для домов, офисов, промышленных объектов. Гарантия, соблюдение СНиП и точные сроки!
Ciekawy wybór slotów online. | Wszystko o sportach i transmisjach. | Lista bukmacherów z cashbackiem bardzo przydatna. | Znajdziesz tutaj przydatne porównania bukmacherów. | Dobre omówienie zakładów esportowych. | [url=https://slots-play.pl/]polskie sloty z bonusem[/url] | Zawsze świeże wiadomości o branży hazardowej. | Opisane turnieje i wydarzenia e-sportowe. | [url=https://gamesplays.pl/]polskie gry wideo[/url] | Wszystkie gry i promocje w jednym miejscu. | Można znaleźć tutaj najlepsze RTP. [url=https://newsports.pl/]jd sport polska[/url]
Гелиевые шары на ДР
печать фирменных бланков печать фирменных бланков
заказать печать папок уф печать на папке
Świetne miejsce dla fanów gier. | Dobre źródło wiedzy o e-sporcie i zakładach. | Znajdziesz tu aktualności sportowe z całej Polski. | Interesujące artykuły o zakładach online. | Solidna baza wiedzy dla każdego gracza. | [url=https://slots-play.pl/]najlepsze sloty total casino[/url] | Pomocne informacje o płatnościach. | Najlepsze gry i kasyna 2025 roku. | [url=https://gamesplays.pl/]gry komputerowe w polsce[/url] | Świetna platforma dla fanów hazardu. | Portal tworzony przez ekspertów. [url=https://newsports.pl/]interia – sport gwiazdy[/url]
Hi, I think your website might be having browser compatibility issues. When I look at your blog site in Chrome, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, awesome blog!
бонус leebet casino
заказать печать на холсте печать на холсте недорого
dtf печать цена https://dtf-pechat-spb.ru
деньги под птс без отказа
avtolombard-11.ru/nsk.html
деньги в долг под птс
широкоформатная печать реклама широкоформатная печать недорого
Wszystko jasno i przejrzyście. | Kasyna online dobrze porównane. | Znajdziesz tu aktualności sportowe z całej Polski. | Wszystkie informacje o bonusach w jednym miejscu. | Legalne kasyna i wszystko o rejestracji. | [url=https://slots-play.pl/]najlepsze sloty total casino[/url] | Pomocne informacje o płatnościach. | Nowoczesna grafika i responsywny design. | [url=https://gamesplays.pl/]cd projekt gry wideo[/url] | Wartość merytoryczna na wysokim poziomie. | Portal tworzony przez ekspertów. [url=https://newsports.pl/]https://newsports.pl[/url]
Thanks for shening. I read many of your blog posts, cool, your blog is very good.
Dużo informacji o legalnych bukmacherach. | Sloty w euro i złotówkach opisane dokładnie. | Ciekawe zestawienia automatów hazardowych. | Recenzje slotów i gier hazardowych online. | Obszerny katalog polskich bukmacherów. | [url=https://slots-play.pl/]sloty z największym rtp[/url] | Kasyna online dobrze sklasyfikowane. | Opisane turnieje i wydarzenia e-sportowe. | [url=https://gamesplays.pl/]techland gry wideo[/url] | Rzetelne recenzje i opinie graczy. | Portal tworzony przez ekspertów. [url=https://newsports.pl/]polsat sport polska[/url]
1block crypto casino
1Block Casino: Full Platform Overview
1Block Casino is a modern gaming platform that offers a wide range of gambling entertainment for players worldwide. From classic slots to unique games like Plinko, the service provides everything needed for gambling enthusiasts. Let’s take a closer look at the main features of the platform, game categories, and key advantages.
Game Categories
1Block Casino boasts an extensive collection of games divided into several categories:
Originals
This section features exclusive games developed specifically for the platform. It’s a great choice for those seeking a unique gaming experience.
Slots
Classic and modern slots with various themes, bonuses, and mechanics are available here. Whether you prefer traditional fruit machines or innovative video slots, there’s something for everyone.
Live Games
Immerse yourself in the atmosphere of a real casino with live dealer games. These games are streamed in real-time, offering an authentic experience with professional dealers.
Fishing Games
A unique category that combines gambling with interactive gameplay. Fishing games are gaining popularity due to their engaging mechanics and potential for big wins.
Poker
Test your skills against other players in various poker formats. The platform offers both traditional and fast-paced poker games.
Esports Betting
Bet on your favorite esports teams and tournaments. This section caters to fans of competitive gaming who want to add excitement to their matches.
Lucky Bets and High Rollers
1Block Casino caters to all types of players, from casual gamers to high rollers. The Lucky Bets section highlights random wins, while the High Rollers section showcases impressive payouts from large bets. Whether you’re betting small or large amounts, the platform ensures fair play and exciting opportunities.
Our Community and Partnerships
1Block Casino values its community and collaborates with trusted partners to enhance the gaming experience. The platform proudly works with leading providers, ensuring top-quality games and services for its users.
Legal Information
1Block Casino is owned and operated by JogoMaster Limited, a company registered under number 15748. The company’s registered address is located in Hamchako, Mutsamudu, Autonomous Island of Anjouan, Union of Comoros.
The platform is licensed and regulated by the Gaming Board of Anjouan (License No. ALSI-152406032-FI3). 1Block has passed all regulatory compliance checks and is legally authorized to conduct gaming operations for all games of chance and wagering.
Why Choose 1Block Casino?
Diverse Game Selection : From slots to live games, there’s something for every type of player.
Transparency : All bets and payouts are clearly displayed, ensuring trust and fairness.
Crypto-Friendly : The platform supports cryptocurrency transactions, making it convenient for modern players.
Licensed and Regulated : With a valid license from the Gaming Board of Anjouan, players can enjoy a secure and legal gaming experience.
Whether you’re a fan of classic casino games or looking to explore unique options like Plinko, 1Block Casino offers a comprehensive and enjoyable platform for all gambling enthusiasts.
Hello to every single one, it’s truly a nice for me to pay a visit this web page, it consists of important Information.
зеркало leebet
Portal godny zaufania dla graczy z Polski. | Wszystko o sportach i transmisjach. | Strona działa płynnie na telefonie. | Idealna dla początkujących i zaawansowanych. | Obszerny katalog polskich bukmacherów. | [url=https://slots-play.pl/]automaty kasyno sloty[/url] | Wszystkie popularne automaty w jednym miejscu. | Polecam każdemu zainteresowanemu zakładami. | [url=https://gamesplays.pl/]gry wideo[/url] | Wartość merytoryczna na wysokim poziomie. | Kompleksowe informacje o legalnym hazardzie. [url=https://newsports.pl/]www.newsports.pl[/url]
займ под залог авто круглосуточно
https://zimtechinfo.com/companies/avtolombard-pid-zalog-pts9030/
займ под залог машины круглосуточно
Wszystko, co musisz wiedzieć o grach hazardowych. | Podoba mi się przystępny język strony. | Wysokie RTP i aktualne recenzje slotów. | Dobrze opisane warunki promocji. | Legalne kasyna i wszystko o rejestracji. | [url=https://slots-play.pl/]sloty 777 online[/url] | Zawsze świeże wiadomości o branży hazardowej. | Zakłady sportowe przedstawione jasno. | [url=https://gamesplays.pl/]techland gry wideo[/url] | Wybór slotów z różnych kategorii. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]https://newsports.pl[/url]
Гелиевые шары на 1 сентября
Dużo informacji o legalnych bukmacherach. | Sloty w euro i złotówkach opisane dokładnie. | Ciekawe zestawienia automatów hazardowych. | Recenzje slotów i gier hazardowych online. | Strona przejrzysta i merytoryczna. | [url=https://slots-play.pl/]najlepsze sloty total casino[/url] | Wszystkie popularne automaty w jednym miejscu. | Najlepsze gry i kasyna 2025 roku. | [url=https://gamesplays.pl/]najlepsze gry na pc[/url] | Świetna platforma dla fanów hazardu. | Kompleksowe informacje o legalnym hazardzie. [url=https://newsports.pl/]polsat sport polska[/url]
1win com [url=1win817.ru]1win817.ru[/url] .
1 win вход [url=https://dogzz.forum24.ru/?1-10-0-00000155-000-0-0-1742818537]https://dogzz.forum24.ru/?1-10-0-00000155-000-0-0-1742818537[/url] .
mostbet kg [url=https://www.corgan.borda.ru/?1-0-0-00000265-000-0-0]mostbet kg[/url] .
Wszystko, co musisz wiedzieć o grach hazardowych. | Szybki dostęp do najnowszych informacji o grach. | Nowości o grach i studiach developerskich. | Znajdziesz tutaj przydatne porównania bukmacherów. | Legalne kasyna i wszystko o rejestracji. | [url=https://slots-play.pl/]darmowe sloty[/url] | Zawsze świeże wiadomości o branży hazardowej. | Nowoczesna grafika i responsywny design. | [url=https://gamesplays.pl/]gry wideo[/url] | Przydatne wskazówki dla nowych graczy. | Wygodne porównanie ofert promocyjnych. [url=https://newsports.pl/]newsports.pl[/url]
https://shvejnye.ru/
Znalazłem tu pomocne porady dla graczy. | Rejestracja i logowanie opisane krok po kroku. | Nowości o grach i studiach developerskich. | Recenzje slotów i gier hazardowych online. | Solidna baza wiedzy dla każdego gracza. | [url=https://slots-play.pl/]polskie sloty z bonusem[/url] | Ranking najlepszych gier i slotów. | Profesjonalne podejście do tematyki bukmacherskiej. | [url=https://gamesplays.pl/]gry akcji wideo[/url] | Wartość merytoryczna na wysokim poziomie. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]sporty w Polsce[/url]
мостюет [url=mostbet6003.ru]мостюет[/url] .
Dużo informacji o legalnych bukmacherach. | Szeroki wybór gier wideo. | Kompleksowe informacje o grach studia Rockstar. | Recenzje slotów i gier hazardowych online. | Dobre omówienie zakładów esportowych. | [url=https://slots-play.pl/]slots-play.pl[/url] | Pomocne informacje o płatnościach. | Nowoczesna grafika i responsywny design. | [url=https://gamesplays.pl/]gry akcji wideo[/url] | Ciekawy blog z poradami i recenzjami. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]jd sport polska[/url]
займ залог авто
https://canworkers.ca/employer/emplealista8017/
займ кредит под птс
Portal godny zaufania dla graczy z Polski. | Rejestracja i logowanie opisane krok po kroku. | Świetna nawigacja i czytelna struktura strony. | Dobrze opisane warunki promocji. | Solidna baza wiedzy dla każdego gracza. | [url=https://slots-play.pl/]sloty online[/url] | Kasyna online dobrze sklasyfikowane. | Profesjonalne podejście do tematyki bukmacherskiej. | [url=https://gamesplays.pl/]gamesplays.pl[/url] | Ciekawy blog z poradami i recenzjami. | Można znaleźć tutaj najlepsze RTP. [url=https://newsports.pl/]www.newsports.pl[/url]
Гелиевые шары с круглосуточной доставкой
веб-сайт [url=https://megamoriartyc09o3seyehpnpnfnv7xo.lol]мега сайт[/url]
подробнее здесь [url=https://megamoriartyc09o3seyehpnpnfnv7xo.lol/]mega зеркала[/url]
Банкротство является прекрасной возможностью списать долги и начать жизнь с чистого листа. Не откладывайте решение проблемы, прочитайте отзывы тех, кто уже прошел процедуру банкротства [url=https://bankrotstvo-v-moskve123.ru]https://bankrotstvo-v-moskve123.ru[/url] .
займ под залог авто
http://iway.lk/profile/caitlynschafer
автоломбард займ под птс
водка казино [url=https://mydomcom.ru]водка казино[/url] .
1вин официальный [url=http://1win6016.ru/]http://1win6016.ru/[/url] .
Юридические услуги http://www.urwork.ru в Санкт-Петербурге и Москве – от консультации до защиты интересов в суде. Оперативно, надежно и с гарантией конфиденциальности.
мостбет кг [url=http://mostbet789.ru]http://mostbet789.ru[/url] .
Гелиевые шары Липецк с доставкой
мосбет [url=ashapiter0.forum24.ru/?1-19-0-00001444-000-0-0-1742819001]ashapiter0.forum24.ru/?1-19-0-00001444-000-0-0-1742819001[/url] .
1вин приложение [url=http://zdorovie.forum24.ru/?1-7-0-00000231-000-0-0-1742818050/]http://zdorovie.forum24.ru/?1-7-0-00000231-000-0-0-1742818050/[/url] .
деньги под залог авто птс
https://backtowork.gr/employer/emploi-securite9207/
займы залог машины
coursework writing https://essentialhunt.com/ college homework help
Are you looking for a reliable online casino? Look no further with [url=https://site-test-casino.com/]test casino[/url]!
When you visit [url=https://site-test-casino.com/]test casino[/url], you’ll find hundreds of casino games that ensure round-the-clock entertainment.
### Top Reasons to Play at [url=https://site-test-casino.com/]test casino[/url]
1. **Extensive Library of Games**
– Our platform offers retro and high-tech casino games to suit every taste.
2. **Generous Bonuses & Promotions**
– Looking for the best deals? Our promotions offer more chances to win big!
3. **Trusted & Reliable**
– We focus on player safety with advanced encryption and rigorous security measures.
4. **Secure Banking Options**
– Withdraw your winnings quickly with a variety of payment methods like crypto, e-wallets, and bank transfers.
5. **Always Here to Help**
– Got a question? Our professional support team is available day and night to assist you via your preferred contact method.
### Join [url=https://site-test-casino.com/]test casino[/url] Today!
1. **Create an Account** in three easy steps.
2. **Choose a Payment Method** and claim your first-time player offer.
3. **Dive into the Action!** Choose from top-rated casino options and win real money.
Your gaming adventure starts now! Join [url=https://site-test-casino.com/]test casino[/url] and discover world-class gambling excitement today!
Откройте для себя мир ставок с 1xbet, зарегистрироваться.
Добро пожаловать в мир ставок с 1xbet, в интернете.
Уникальные бонусы от 1xbet, поспешите воспользоваться.
Ставьте на любимые виды спорта с 1xbet, удовольствие.
1xbet – ваш портал в мир лайв-ставок, сделайте каждую секунду важной.
Всё для ваших ставок на 1xbet, и выигрывайте.
Обширные рынки на 1xbet, от спорта до киберспорта.
1xbet – живые трансляции ваших любимых матчей, погрузитесь в атмосферу.
1xbet – получите свои выигрыши мгновенно, открывайте возможности.
Получите инсайдерскую информацию с 1xbet, поможем вам оставаться в курсе.
1xbet – это безопасность и надежность, мы ценим вашу конфиденциальность.
Скидки и бонусы только для вас с 1xbet, максимизируйте свой выигрыш.
Ставьте смело с 1xbet, выберите правильный путь.
Чат поддержки 24/7 на 1xbet, вы всегда не одни.
1xbet – это не только ставки, но и конкурсы, будьте в курсе событий.
Платформа 1xbet доступна на мобильных устройствах, сделайте ставки на ходу.
Дайте себе преимущества с 1xbet, анализируйте каждый шаг.
Простая регистрация на 1xbet, доступ к азарту.
Откройте новый уровень азартных игр с 1xbet, начните выигрывать.
Не упустите уникальные возможности на 1xbet, развивайте свои навыки.
1xbet t [url=https://1xbet-login-egypt.com/]1xbet t[/url] .
нажмите, чтобы подробнее [url=https://megamoriartyc09o3seyehpnpnfnv7xo.lol]мега сайт[/url]
What’s up, this weekend is fastidious in favor of me, as this occasion i am reading this great educational piece of writing here at my home.
1xbet promo code today
Enhance your own car with our customization services. Revamp your car into a exclusive masterpiece. Our team of professionals is dedicated to offering high-quality results that outperform your wishes. Whether you’re looking to augment performance, refresh aesthetics, or incorporate new features, we have the proficiency to deliver your vision to life. Visit our website at https://timbrellosautobody.com/ to discover our options and organize a consultation today.Let us guide you design the auto of your dreams.
автоломбард в кемерово круглосуточно
https://www.flughafen-jobs.com/companies/zaim-pod-zalog-pts-1592/
кредит под птс автомобиля
Воздушные шары Липецк на 23 февраля
1win кыргызстан [url=https://www.1win6017.ru]https://www.1win6017.ru[/url] .
сколько стоит раскрутить сайт seo продвижение цена
маркетинговое продвижение сайта продвижение и реклама в интернете
Świetne miejsce dla fanów gier. | Wszystko o sportach i transmisjach. | Znajdziesz tu aktualności sportowe z całej Polski. | Kasyna z darmowymi spinami bez depozytu. | Legalne kasyna i wszystko o rejestracji. | [url=https://slots-play.pl/]automaty kasyno sloty[/url] | Pełna baza wiedzy o grach sportowych. | Kasyna przyjazne dla polskich graczy. | [url=https://gamesplays.pl/]gamesplays.pl[/url] | Szczegółowe analizy i rankingi slotów. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]www.newsports.pl[/url]
Polecam, bardzo dobrze opisane kasyna. | Szybki dostęp do najnowszych informacji o grach. | Strona działa płynnie na telefonie. | Znajdziesz tutaj przydatne porównania bukmacherów. | Obszerny katalog polskich bukmacherów. | [url=https://slots-play.pl/]sloty polska[/url] | Kasyna online dobrze sklasyfikowane. | Polecam każdemu zainteresowanemu zakładami. | [url=https://gamesplays.pl/]gry akcji wideo[/url] | Wybór slotów z różnych kategorii. | Dostępne są recenzje gier i kasyn. [url=https://newsports.pl/]polska sport[/url]
этот сайт [url=https://megamoriartyc09o3seyehpnpnfnv7xo.lol/]магазин мега мориарти[/url]
кредит под залог автомобиля
https://www.vieclam.jp/employer/employment5086/
взять кредит под залог автомобиля
Ciekawy wybór slotów online. | Rejestracja i logowanie opisane krok po kroku. | Ciekawe zestawienia automatów hazardowych. | Regularnie aktualizowane wiadomości sportowe. | Dobre źródło dla graczy konsolowych i PC | [url=https://slots-play.pl/]polskie sloty z bonusem[/url] | Bezpieczne i sprawdzone źródło informacji. | Nowoczesna grafika i responsywny design. | [url=https://gamesplays.pl/]gry akcji wideo[/url] | Przydatne wskazówki dla nowych graczy. | Gry od topowych producentów gier. [url=https://newsports.pl/]wirtualna polska sport[/url]
продвижение сайта цены https://seokontekstnayareklama.ru
Планируете каникулы? купить https://camp-centr.com! Интересные программы, безопасность, забота и яркие эмоции. Бронируйте заранее — количество мест ограничено!
bet-riot.fr casino france
Najlepsze bonusy bez depozytu w jednym miejscu. | Kasyna online dobrze porównane. | Wysokie RTP i aktualne recenzje slotów. | Można dowiedzieć się, gdzie grać najbezpieczniej. | Obszerny katalog polskich bukmacherów. | [url=https://slots-play.pl/]total casino najlepsze sloty[/url] | Pełna baza wiedzy o grach sportowych. | Zakłady sportowe przedstawione jasno. | [url=https://gamesplays.pl/]techland gry wideo[/url] | Rzetelne recenzje i opinie graczy. | Portal tworzony przez ekspertów. [url=https://newsports.pl/]www.newsports.pl[/url]
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.com/uk-UA/register-person?ref=W0BCQMF1
Wszystko jasno i przejrzyście. | Znalazłem wiele darmowych spinów. | Kasyna online działające w Polsce. | Wszystkie informacje o bonusach w jednym miejscu. | Dobre omówienie zakładów esportowych. | [url=https://slots-play.pl/]polskie sloty z bonusem[/url] | Zawsze świeże wiadomości o branży hazardowej. | Kasyna przyjazne dla polskich graczy. | [url=https://gamesplays.pl/]ubisoft gry wideo[/url] | Ciekawy blog z poradami i recenzjami. | Miejsce, gdzie znajdziesz wszystko o grach online. [url=https://newsports.pl/]https://newsports.pl[/url]
Воздушные шарики Липецк на выписку
займ под залог кредитного авто
https://www.usbstaffing.com/companies/zaim-pod-zalog-pts-13800/
взять кредит под птс
сайт 1win [url=www.1win6013.ru]сайт 1win[/url] .
баланс ван вин [url=https://knowledge.forum24.ru/?1-0-0-00000101-000-0-0-1742817704]https://knowledge.forum24.ru/?1-0-0-00000101-000-0-0-1742817704[/url] .
1вин кг [url=https://www.1win9109.ru]1вин кг[/url] .
мостбет мобильная версия скачать [url=www.mostbet6004.ru]www.mostbet6004.ru[/url] .
paperowl https://tool300.com/ write my college paper
Świetne miejsce dla fanów gier. | Znalazłem wiele darmowych spinów. | Nowości o grach i studiach developerskich. | Można dowiedzieć się, gdzie grać najbezpieczniej. | Dobre źródło dla graczy konsolowych i PC | [url=https://slots-play.pl/]sloty casino[/url] | Najważniejsze aktualizacje sportowe. | Kasyna przyjazne dla polskich graczy. | [url=https://gamesplays.pl/]polskie gry wideo[/url] | Wybór slotów z różnych kategorii. | Strona działa szybko i bez błędów. [url=https://newsports.pl/]tvp sport mecz polska[/url]
Dużo informacji o legalnych bukmacherach. | Podoba mi się przystępny język strony. | Ciekawe zestawienia automatów hazardowych. | Recenzje slotów i gier hazardowych online. | Ciekawe artykuły o historii gier. | [url=https://slots-play.pl/]https://slots-play.pl/[/url] | Zawsze świeże wiadomości o branży hazardowej. | Najlepsze gry i kasyna 2025 roku. | [url=https://gamesplays.pl/]https://gamesplays.pl/[/url] | Rzetelne recenzje i opinie graczy. | Można znaleźć tutaj najlepsze RTP. [url=https://newsports.pl/]wirtualna polska sport[/url]
Polecam, bardzo dobrze opisane kasyna. | Podoba mi się przystępny język strony. | Świetna nawigacja i czytelna struktura strony. | Kasyna z darmowymi spinami bez depozytu. | Profesjonalne podejście do tematu hazardu. | [url=https://slots-play.pl/]darmowe sloty owocowe[/url] | Szczegółowe opisy promocji i kodów bonusowych. | Polecane przez wielu użytkowników. | [url=https://gamesplays.pl/]techland gry wideo[/url] | Bezpieczne kasyna opisane w szczegółach. | Strona działa szybko i bez błędów. [url=https://newsports.pl/]https://newsports.pl[/url]
check click
займ под залог машины круглосуточно
https://divsourcestaffing.com/employer/nc-healthcare4115/
кредит под залог машины птс
Najlepsze bonusy bez depozytu w jednym miejscu. | Znalazłem wiele darmowych spinów. | Świetna nawigacja i czytelna struktura strony. | Interesujące artykuły o zakładach online. | Szybka rejestracja i łatwy dostęp do gier. | [url=https://slots-play.pl/]polskie sloty bez depozytu[/url] | Bezpieczne i sprawdzone źródło informacji. | Opisane turnieje i wydarzenia e-sportowe. | [url=https://gamesplays.pl/]polskie studio gier[/url] | Wybór slotów z różnych kategorii. | Wygodne porównanie ofert promocyjnych. [url=https://newsports.pl/]jd sport polska[/url]
Znalazłem tu pomocne porady dla graczy. | Sloty w euro i złotówkach opisane dokładnie. | Znajdziesz tu aktualności sportowe z całej Polski. | Znajdziesz tutaj przydatne porównania bukmacherów. | Szybka rejestracja i łatwy dostęp do gier. | [url=https://slots-play.pl/]darmowe sloty[/url] | Pełna baza wiedzy o grach sportowych. | Najlepsze gry i kasyna 2025 roku. | [url=https://gamesplays.pl/]najlepsze gry na pc[/url] | Rzetelne recenzje i opinie graczy. | Można znaleźć tutaj najlepsze RTP. [url=https://newsports.pl/]www.newsports.pl[/url]
Гелиевые шары Липецк дешево
Ciekawy wybór slotów online. | Kasyna online dobrze porównane. | Świetna nawigacja i czytelna struktura strony. | Regularnie aktualizowane wiadomości sportowe. | Dobre omówienie zakładów esportowych. | [url=https://slots-play.pl/]polskie sloty bez depozytu[/url] | Pomocne informacje o płatnościach. | Zakłady sportowe przedstawione jasno. | [url=https://gamesplays.pl/]gry akcji wideo[/url] | Przydatne wskazówki dla nowych graczy. | Strona działa szybko i bez błędów. [url=https://newsports.pl/]https://newsports.pl[/url]
Ciekawy wybór slotów online. | Rejestracja i logowanie opisane krok po kroku. | Kompleksowe informacje o grach studia Rockstar. | Znajdziesz tutaj przydatne porównania bukmacherów. | Szybka rejestracja i łatwy dostęp do gier. | [url=https://slots-play.pl/]bonus bez depozytu sloty[/url] | Kasyna online dobrze sklasyfikowane. | Polecane przez wielu użytkowników. | [url=https://gamesplays.pl/]ubisoft gry wideo[/url] | Wybór slotów z różnych kategorii. | Miejsce, gdzie znajdziesz wszystko o grach online. [url=https://newsports.pl/]newsports pl[/url]
получить займ под залог авто
https://eukariyer.net/employer/zaim-pod-zalog-pts-18986/
займ под птс автомобиля
play now newsacademies.gr
1 win.kg [url=http://belbeer.borda.ru/?1-6-0-00001583-000-0-0/]http://belbeer.borda.ru/?1-6-0-00001583-000-0-0/[/url] .
мостбет скачать андроид [url=www.girikms.forum24.ru/?1-1-0-00000361-000-0-0-1742819287]www.girikms.forum24.ru/?1-1-0-00000361-000-0-0-1742819287[/url] .
ломбард деньги под залог птс
https://akrs.ae/employer/ttemployment167/
займ под птс машины
1вин сайт официальный [url=https://www.1win6018.ru]https://www.1win6018.ru[/url] .
мостбет chrono [url=https://kharkovbynight.forum24.ru/?1-15-0-00003047-000-0-0]https://kharkovbynight.forum24.ru/?1-15-0-00003047-000-0-0[/url] .
riobet вход riobet casino
Пройди тест и сориентируйся со своей будущей специальностью!
https://lestomsk.ru/perezagruzka-2-0-kak-smenit-professiyu-i-ne-oblazhatsya-v-2025
[url=https://kra29-at.at/]кракен войти[/url] – kraken вход, kraken зайти
Mostbet podporuje mobilní hraní bez omezení | Zaregistrujte se na Mostbet cz a získejte bonus | Zákaznická podpora Mostbet je k dispozici 24/7 [url=https://mostbet-casino-register-cz.com/]mostbet cz[/url].
лучший займ под залог авто
avtolombard-pid-zalog-pts.ru/ekb.html
кредит наличными под залог авто
quality steroids online https://anabolshop.org
купить анализы мочи и кала купить справку анализы
[url=https://kra29-at.at]kraken[/url] – kra32, Площадка кракен
трансформаторы тмг [url=https://masa.forum24.ru/?1-8-0-00000628-000-0-0]трансформаторы тмг[/url] .
программа 1с [url=https://skoleoz.borda.ru/?1-1-0-00000062-000-0-0-1742893214]программа 1с[/url] .
Mostbet podporuje mobilní hraní bez omezení | Nejlepší automaty najdete v Mostbet casino cz | Výhry z Mostbet lze snadno vybrat [url=https://mostbet-casino-register-cz.com/]mostbet official website[/url].
Сотрудник пенсионного фонда рекомендовал [url=https://telegra.ph/Katolicheskij-krest-03-07]ознакомиться с религиозными символами[/url]. Ритуальные услуги выполнены достойно. Помогли с транспортом и цветами.
Привет!
Без наличия диплома очень нелегко было продвигаться по карьерной лестнице. Сегодня же этот важный документ не дает гарантий, что удастся найти престижную работу. Намного более важны навыки и знания специалиста, а также его постоянный опыт. Поэтому решение о заказе диплома следует считать целесообразным. Заказать диплом ВУЗа [url=http://alumni.myra.ac.in/read-blog/206304/]alumni.myra.ac.in/read-blog/206304[/url]
купить диплом сгупс новосибирск
Привет!
Заказать диплом института по невысокой цене вы можете, обратившись к проверенной специализированной компании. Приобрести диплом о высшем образовании: [url=http://diplom-club.com/kupit-diplom-avtomexanika-9/]diplom-club.com/kupit-diplom-avtomexanika-9/[/url]
Mostbet podporuje mobilní hraní bez omezení | Mostbet com přináší top kvalitu mezi online kasiny | Většina hráčů doporučuje Mostbet [url=https://mostbet-casino-register-cz.com/]mostbet site[/url].
Купить диплом о высшем образовании!
Мы можем предложить дипломы психологов, юристов, экономистов и любых других профессий по разумным ценам. Вы приобретаете диплом через надежную компанию. : [url=http://orthograf.getbb.ru/viewtopic.php?f=2&t=1672/]orthograf.getbb.ru/viewtopic.php?f=2&t=1672[/url]
[b]Диплом университета РФ![/b]
Без университета сложно было продвинуться вверх по карьере. Именно из-за этого решение о заказе диплома следует считать целесообразным. Выгодно купить диплом о высшем образовании [url=http://staletsa.flybb.ru/viewtopic.php?f=2&t=1270/]staletsa.flybb.ru/viewtopic.php?f=2&t=1270[/url]
кредит под залог авто в кемерово
avtolombard-pid-zalog-pts.ru/kemerovo.html
автоломбард под птс
Mostbet casino přináší kvalitní zábavu online | Mostbet login je rychlý a bezpečný | Výhry z Mostbet lze snadno vybrat [url=https://mostbet-casino-register-cz.com/]mostbet betting[/url].
анализ мочи где купить купить анализ без сдачи
Hráči ocenují rychlé výběry u Mostbet | Bonus bez vkladu najdete na Mostbet casino cz | Většina hráčů doporučuje Mostbet [url=https://mostbet-casino-register-cz.com/]mostbet com[/url].
Топ сайтов кейсов CS2 https://ggdrop.cs2-case.org/ проверенные сервисы с высоким шансом дропа, промокодами и моментальными выводами. Только актуальные и безопасные платформы!
куплю диплом услуга [url=https://diplomys-vsem.ru/]diplomys-vsem.ru[/url] .
мостбет зеркало [url=https://mostbet6005.ru/]https://mostbet6005.ru/[/url] .
Registrace na Mostbet je jednoduchá a rychlá | Užijte si sportovní sázky na Mostbet cz | Vyzkoušejte sázení na Mostbet a uvidíte rozdíl [url=https://mostbet-casino-register-cz.com/]mostbet online[/url].
кредит под птс с плохой кредитной
avtolombard-pid-zalog-pts.ru
займ под птс спецтехники
Zkuste štěstí na Mostbet online je to snadné | Mostbet má skvělou mobilní aplikaci pro České uživatele | S Mostbet máte jistotu kvalitní podpory [url=https://mostbet-casino-register-cz.com/]https://mostbet-casino-register-cz.com[/url].
один вин [url=http://obmen.forum24.ru/?1-1-0-00004428-000-0-0-1742816292/]http://obmen.forum24.ru/?1-1-0-00004428-000-0-0-1742816292/[/url] .
1win зайти [url=www.1win6019.ru]www.1win6019.ru[/url] .
мастбет [url=www.hiend.borda.ru/?1-16-0-00000259-000-0-0-1743052953]www.hiend.borda.ru/?1-16-0-00000259-000-0-0-1743052953[/url] .
скачат мостбет [url=https://alfatraders.borda.ru/?1-0-0-00004917-000-0-0-1743053068/]https://alfatraders.borda.ru/?1-0-0-00004917-000-0-0-1743053068/[/url] .
Mostbet casino přináší kvalitní zábavu online | Nejlepší automaty najdete v Mostbet casino cz | S Mostbet máte jistotu kvalitní podpory [url=https://mostbet-casino-register-cz.com/]mostbet login[/url].
Zkuste štěstí na Mostbet online je to snadné | Bonus bez vkladu najdete na Mostbet casino cz | Zákaznická podpora Mostbet je k dispozici 24/7 [url=https://mostbet-casino-register-cz.com/]mostbet account[/url].
Mostbet podporuje mobilní hraní bez omezení | Mostbet login je rychlý a bezpečný | Zákaznická podpora Mostbet je k dispozici 24/7 [url=https://mostbet-casino-register-cz.com/]mostbet přihlášení[/url].
Registrace na Mostbet je jednoduchá a rychlá | Užijte si sportovní sázky na Mostbet cz | Mostbet představuje novou úroveň online hraní [url=https://mostbet-casino-register-cz.com/]https://mostbet-casino-register-cz.com[/url].
взять займ под залог машины
avtolombard-pid-zalog-pts.ru/nsk.html
взять деньги под залог машины
Na Mostbet najdete výhodné bonusy a promo akce | Bonus bez vkladu najdete na Mostbet casino cz | Výhry z Mostbet lze snadno vybrat [url=https://mostbet-casino-register-cz.com/]https://mostbet-casino-register-cz.com[/url].
1win betting site [url=https://1win12.com.ng]https://1win12.com.ng[/url] .
кредит под птс автомобиля в екатеринбурге
zaim-pod-zalog-pts1.ru/ekb.html
деньги под птс круглосуточные
1win online games [url=https://1win12.com.ng]https://1win12.com.ng[/url] .
мостбет скачать андроид [url=https://assa0.myqip.ru/?1-23-0-00000149-000-0-0-1743053201]https://assa0.myqip.ru/?1-23-0-00000149-000-0-0-1743053201[/url] .
mostbet kg [url=https://www.severussnape.borda.ru/?1-10-0-00000023-000-0-0-1743053372]https://www.severussnape.borda.ru/?1-10-0-00000023-000-0-0-1743053372[/url] .
продвижение сайта цена [url=http://www.puzzleweb.ru/recl3/effjektivnoje-prodvizhjenije-sajtov-v-moskvje-kak-dostich-vysokikh-rjezultatov.php]продвижение сайта цена[/url] .
скачать mostbet на телефон [url=http://cah.forum24.ru/?1-3-0-00000096-000-0-0-1743053764]http://cah.forum24.ru/?1-3-0-00000096-000-0-0-1743053764[/url] .
1win регистрация [url=https://fanfiction.borda.ru/?1-0-0-00029708-000-0-0-1743051664]https://fanfiction.borda.ru/?1-0-0-00029708-000-0-0-1743051664[/url] .
узнать больше https://falcoware.com/rus/match3_games.php
раскрутка сайтов [url=www.puzzleweb.ru/recl3/effjektivnoje-prodvizhjenije-sajtov-v-moskvje-kak-dostich-vysokikh-rjezultatov.php]раскрутка сайтов[/url] .
do my essay for cheap https://bjaygroup.com/ law essay help
авто под залог
avtolombard-pid-zalog-pts.ru/kazan.html
займ под залог авто
1вин про [url=www.1win6020.ru]www.1win6020.ru[/url] .
Купить диплом о высшем образовании!
Мы готовы предложить документы университетов, которые находятся на территории всей Российской Федерации. Дипломы и аттестаты выпускаются на бумаге высшего качества: [url=http://selebriti-studio.ru/images/pages/kupit_attestat_za_29.html/]selebriti-studio.ru/images/pages/kupit_attestat_za_29.html[/url]
Лучшие сайты кейсов ggdrop.casecs2.com в CS2 – честный дроп, редкие скины и гарантии прозрачности. Сравниваем платформы, бонусы и шансы. Заходи и забирай топовые скины!
1win.online [url=http://admiralshow.forum24.ru/?1-17-0-00000242-000-0-0-1742816555/]http://admiralshow.forum24.ru/?1-17-0-00000242-000-0-0-1742816555/[/url] .
1Block Casino: Full Platform Overview
1Block Casino is a modern gaming platform that offers a wide range of gambling entertainment for players worldwide. From classic slots to unique games like Plinko, the service provides everything needed for gambling enthusiasts. Let’s take a closer look at the main features of the platform, game categories, and key advantages.
Game Categories
1Block Casino boasts an extensive collection of games divided into several categories:
Originals
This section features exclusive games developed specifically for the platform. It’s a great choice for those seeking a unique gaming experience.
Slots
Classic and modern slots with various themes, bonuses, and mechanics are available here. Whether you prefer traditional fruit machines or innovative video slots, there’s something for everyone.
Live Games
Immerse yourself in the atmosphere of a real casino with live dealer games. These games are streamed in real-time, offering an authentic experience with professional dealers.
Fishing Games
A unique category that combines gambling with interactive gameplay. Fishing games are gaining popularity due to their engaging mechanics and potential for big wins.
Poker
Test your skills against other players in various poker formats. The platform offers both traditional and fast-paced poker games.
Esports Betting
Bet on your favorite esports teams and tournaments. This section caters to fans of competitive gaming who want to add excitement to their matches.
Lucky Bets and High Rollers
1Block Casino caters to all types of players, from casual gamers to high rollers. The Lucky Bets section highlights random wins, while the High Rollers section showcases impressive payouts from large bets. Whether you’re betting small or large amounts, the platform ensures fair play and exciting opportunities.
Our Community and Partnerships
1Block Casino values its community and collaborates with trusted partners to enhance the gaming experience. The platform proudly works with leading providers, ensuring top-quality games and services for its users.
Legal Information
1Block Casino is owned and operated by JogoMaster Limited, a company registered under number 15748. The company’s registered address is located in Hamchako, Mutsamudu, Autonomous Island of Anjouan, Union of Comoros.
The platform is licensed and regulated by the Gaming Board of Anjouan (License No. ALSI-152406032-FI3). 1Block has passed all regulatory compliance checks and is legally authorized to conduct gaming operations for all games of chance and wagering.
Why Choose 1Block Casino?
Diverse Game Selection : From slots to live games, there’s something for every type of player.
Transparency : All bets and payouts are clearly displayed, ensuring trust and fairness.
Crypto-Friendly : The platform supports cryptocurrency transactions, making it convenient for modern players.
Licensed and Regulated : With a valid license from the Gaming Board of Anjouan, players can enjoy a secure and legal gaming experience.
Whether you’re a fan of classic casino games or looking to explore unique options like Plinko, 1Block Casino offers a comprehensive and enjoyable platform for all gambling enthusiasts.
Где заказать диплом специалиста?
Мы можем предложить дипломы любой профессии по приятным ценам. Мы можем предложить документы техникумов, которые расположены на территории всей России. Вы можете купить качественно сделанный диплом за любой год, включая сюда документы старого образца. Документы печатаются на “правильной” бумаге высшего качества. Это позволяет делать настоящие дипломы, которые невозможно отличить от оригинала. Документы заверяются всеми необходимыми печатями и подписями. Стараемся поддерживать для клиентов адекватную ценовую политику. Важно, чтобы дипломы были доступными для большого количества граждан. [url=http://diplom45.ru/kupit-svidetelstvo-o-brake-8/]diplom45.ru/kupit-svidetelstvo-o-brake-8[/url]
1win [url=https://www.1win6020.ru]1win[/url] .
займ под залог авто кемерово
zaim-pod-zalog-pts1.ru/kemerovo.html
срочный займ под птс
1вин официальный сайт [url=realistzoosafety.forum24.ru/?1-11-0-00001540-000-0-0-1742816894]realistzoosafety.forum24.ru/?1-11-0-00001540-000-0-0-1742816894[/url] .
Купить диплом любого ВУЗа!
Мы можем предложить документы институтов, которые находятся на территории всей России.
[url=http://fastdiploms.com/chto-budet-esli-kupit-attestat-4/]fastdiploms.com/chto-budet-esli-kupit-attestat-4[/url]
1вин официальный сайт [url=https://naigle.borda.ru/?1-17-0-00000329-000-0-0-1742816734]https://naigle.borda.ru/?1-17-0-00000329-000-0-0-1742816734[/url] .
Мы изготавливаем дипломы любой профессии по приятным тарифам. Плюсы приобретения документов у нас
Вы покупаете диплом через надежную и проверенную фирму. Это решение позволит сэкономить не только много денежных средств, но и ваше драгоценное время.
На этом плюсы не заканчиваются, их куда больше:
• Дипломы изготавливаются на подлинных бланках со всеми отметками;
• Предлагаем дипломы любого ВУЗа России;
• Цена во много раз меньше чем потребовалось бы заплатить на очном и заочном обучении в университете;
• Удобная доставка в любые регионы Российской Федерации.
Купить диплом академии– [url=http://atlantarp.forumex.ru/viewtopic.php?f=36&t=790/]atlantarp.forumex.ru/viewtopic.php?f=36&t=790[/url]
деньги под залог машины москва
zaim-pod-zalog-pts1.ru
кредит под птс машины
Воздушные шарики в Липецке на рождение ребенка
1 win nigeria [url=https://www.1win12.com.ng]https://www.1win12.com.ng[/url] .
кредит под залог авто без авто
zaim-pod-zalog-pts1.ru/nsk.html
автоломбард залог авто кредит
официальный сайт 1win [url=https://familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813]https://familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813[/url] .
1 win bet [url=https://www.1win12.com.ng]https://www.1win12.com.ng[/url] .
1win.kg [url=www.familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813]www.familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813[/url] .
деньги под птс екатеринбург
avtolombard-11.ru/ekb.html
кредит под птс с плохой кредитной историей
сайтов продвижение [url=https://puzzleweb.ru/recl3/effjektivnoje-prodvizhjenije-sajtov-v-moskvje-kak-dostich-vysokikh-rjezultatov.php/]puzzleweb.ru/recl3/effjektivnoje-prodvizhjenije-sajtov-v-moskvje-kak-dostich-vysokikh-rjezultatov.php[/url] .
Воздушные шарики
1 вин про [url=http://1win6020.ru]http://1win6020.ru[/url] .
Приобрести документ о получении высшего образования вы имеете возможность в нашей компании. [url=http://veracruzmagico.com/talleres/desarrollo-de-producto-turistico-gastronomico/]veracruzmagico.com/talleres/desarrollo-de-producto-turistico-gastronomico[/url]
Мы изготавливаем дипломы любых профессий по приятным тарифам. Стоимость зависит от той или иной специальности, года выпуска и ВУЗа. Всегда стараемся поддерживать для заказчиков адекватную политику цен. Важно, чтобы дипломы были доступны для большого количества наших граждан. [url=http://asxdiplommy.com/kupit-diplom-moskovskogo-gumanitarnogo-universiteta-mosgu-2/]мфюа диплом купить[/url]
Где купить диплом по необходимой специальности?
Мы предлагаем выгодно заказать диплом, который выполняется на оригинальном бланке и заверен печатями, штампами, подписями. Наш документ пройдет лубую проверку, даже при помощи специального оборудования. Решите свои задачи быстро и просто с нашим сервисом.
Купить диплом университета [url=http://diplomus-spb.ru/kupit-diplom-v-bryanske-15/]diplomus-spb.ru/kupit-diplom-v-bryanske-15/[/url]
шиномантаж звенигород [url=https://hondahybrid.ru/forum/topic/2886-kakie-uslugi-okazyvaet-shinomontazh//]шиномантаж звенигород[/url] .
продвижение сайта [url=https://www.seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya/]продвижение сайта[/url] .
Приобретение документа о высшем образовании через надежную компанию дарит много достоинств для покупателя. Такое решение позволяет сберечь как дорогое время, так и значительные финансовые средства. Однако, только на этом выгоды не ограничиваются, преимуществ значительно больше.Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий. Дипломы производят на настоящих бланках государственного образца. Доступная стоимость сравнительно с серьезными издержками на обучение и проживание. Заказ диплома ВУЗа будет выгодным шагом.
Быстро купить диплом о высшем образовании: [url=http://vuz-diplom.ru/kupit-attestat-za-11-klassov-2/]vuz-diplom.ru/kupit-attestat-za-11-klassov-2/[/url]
Где заказать диплом специалиста?
Мы предлагаем документы об окончании любых университетов России. Документы изготавливаются на подлинных бланках государственного образца. [url=http://deves.flybb.ru/viewtopic.php?f=2&t=1177/]deves.flybb.ru/viewtopic.php?f=2&t=1177[/url]
Приобрести документ университета можно в нашей компании. Мы оказываем услуги по изготовлению и продаже документов об окончании любых ВУЗов России. Вы получите необходимый диплом по любым специальностям, любого года выпуска, в том числе документы образца СССР. Даем гарантию, что в случае проверки документов работодателем, подозрений не появится. [url=http://saturn.forumex.ru/viewtopic.php?f=19&t=644/]saturn.forumex.ru/viewtopic.php?f=19&t=644[/url]
кредит под залог птс автомобиля
avtolombard-11.ru/kazan.html
займ под залог птс казань
1 win pro [url=https://www.1win6001.ru]1 win pro[/url] .
1win на телефон [url=http://1win6020.ru]1win на телефон[/url] .
раскрутка сайта в москве [url=https://seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya//]seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya/[/url] .
1win site [url=https://1win12.com.ng/]https://1win12.com.ng/[/url] .
best coursework help https://lordsoficeland.com/ buy an essay now
займ под залог птс
avtolombard-11.ru/kemerovo.html
кредит под залог птс
сайт 1win [url=https://1win6001.ru/]https://1win6001.ru/[/url] .
Гелиевые шарики Липецк на праздник
1win,com [url=http://1win6020.ru]http://1win6020.ru[/url] .
деньги под птс
avtolombard-11.ru
взять кредит под птс
1 vin официальный сайт [url=https://1win6001.ru/]https://1win6001.ru/[/url] .
mostbet официальный сайт [url=mostbet6006.ru]mostbet6006.ru[/url] .
Really great visual appeal on this site, I’d value it 10 10.
кредит под залог авто новосибирск
avtolombard-11.ru/nsk.html
деньги под залог машины новосибирск
mosbet [url=https://mostbet6006.ru]https://mostbet6006.ru[/url] .
мостбет кыргызстан скачать [url=http://mostbet6006.ru/]http://mostbet6006.ru/[/url] .
кредит под птс авто
https://jobs.quvah.com/employer/avtolombard-pid-zalog-pts5299/
деньги в долг под птс
1 vin [url=www.familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813]www.familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813[/url] .
1win прямой эфир [url=https://1win6001.ru]https://1win6001.ru[/url] .
Не хочется ждать — решение нужно сейчас? Тогда вам в рейтинг займов с моментальным одобрением. [url=https://wikzaim.ru/]Онлайн займ на карту[/url] до 30 000 рублей доступен круглосуточно, без отказов и проверок. Деньги — за 5 минут.
мостбет скачать [url=www.mostbet6006.ru]www.mostbet6006.ru[/url] .
машина под залог
https://okoskalyha.hu/employer/firm4930/
кредит под птс авто
seo продвижение сайтов [url=https://seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya//]seo продвижение сайтов[/url] .
мостбет [url=http://mostbet6006.ru/]http://mostbet6006.ru/[/url] .
essays on writing https://notjobsbutpassion.com/ buy already written essays
деньги под залог авто в казани
https://www.cbl.health/employer/avtolombard-zalog-invest4712/
деньги под залог авто
раскрутка сайтов москва [url=seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya/]раскрутка сайтов москва[/url] .
1 win сайт [url=https://www.1win6001.ru]https://www.1win6001.ru[/url] .
1win pro [url=http://familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813]http://familyclub.borda.ru/?1-6-0-00002163-000-0-0-1743051813[/url] .
Modify your machine into a showpiece with our experienced auto modification options. At Bergin Auto Repair, we are experts in furnishing premium alterations that showcase your one-of-a-kind aesthetic. From sleek car exteriors to robust performance boosts, our professionals guarantees superior workmanship. Discover our site https://berginautobody.com/ to discover our offerings and kick off your vehicle’s change today.
деньги под залог авто в казани
https://complete-jobs.co.uk/employer/innoviussoftware5775
займ под залог авто
кайт сафари
отзывы ремонт посудомоечных ремонт стиральных машин миле
автоломбард займ под птс
https://convia.gt/employer/avtolombard-zalog-invest7342/
деньги под залог авто в кемерово
1вин кг [url=https://1win6002.ru/]1вин кг[/url] .
мосбет [url=http://mostbet6007.ru]мосбет[/url] .
сайта продвижение [url=www.seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya/]www.seogift.ru/news/press-release/2463-geymifikaciya-v-prodvizhenii-internet-magazinov-kak-vovlekat-klientov-s-pervogo-kasaniya/[/url] .
1 вин войти [url=https://1win6049.ru/]https://1win6049.ru/[/url] .
1вин официальный сайт [url=1win6002.ru]1win6002.ru[/url] .
мостбет [url=http://mostbet6007.ru/]http://mostbet6007.ru/[/url] .
1вин официальный мобильная [url=1win6049.ru]1win6049.ru[/url] .
установка мониторинга транспорта [url=http://www.kontrol-avto.ru]http://www.kontrol-avto.ru[/url] .
автоломбард кемерово
https://sunnyskiesproduce.com/employer/charisonecare5902/
автоломбард круглосуточно
Исследуйте мир на sofisimo.com, на нашем сайте вы откроете.
Погрузитесь в уникальный контент sofisimo.com, современные идеи.
sofisimo.com – ключ к вашему развитию, новые перспективы.
Платформа sofisimo.com для всех, что-то новое.
Узнайте, как sofisimo.com может помочь вам, вместе с нами.
Общайтесь, учитесь и развивайтесь на sofisimo.com, вы можете.
sofisimo.com – это источник креативности, для тех, кто.
sofisimo.com – ваша платформа для успеха, ваши возможности.
Откройте для себя мир sofisimo.com, поощряется.
sofisimo.com – это больше, чем просто сайт, новички.
Так много возможностей на sofisimo.com, что-то для себя.
sofisimo.com – это ваш надежный партнер, находить новые пути.
Свяжитесь с сообществом на sofisimo.com, поддержка.
Выберите sofisimo.com для новизны, жаждет.
sofisimo.com: ваш путь к знаниям, нужен.
sofisimo.com – это ваша платформа, это для каждого.
Станьте частью sofisimo.com сегодня, где.
Собирайте идеи на sofisimo.com, вдохновение не заканчивается.
sofisimo.com – платформа для инноваций, что.
muebles de cocina [url=https://sofisimo.com/]https://sofisimo.com/[/url] .
системы контроля транспорта [url=https://www.kontrol-avto.ru]https://www.kontrol-avto.ru[/url] .
кредит под залог авто документы
https://somalibidders.com/employer/avtolombard-pid-zalog-pts8549/
кредит под залог машины не лишаясь ее
1win com [url=http://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210/]1win com[/url] .
сервис займов под залог авто
https://ecsusa.net/employer/globalscaffolders2212/
кредит под залог птс грузового
автоломбард под займ
https://akinsemployment.ca/employer/zaim-pod-zalog-pts-11422/
деньги под залог авто новосибирск
1win live [url=https://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210/]https://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210/[/url] .
Кладбище в Видном https://vidnovskoe.ru/ актуальные данные о захоронениях, помощь в организации похорон, услуги по благоустройству могил. Схема проезда, часы работы и контактная информация.
деньги под залог кредитного авто
https://www.referall.us/employer/eliteyachtsclub2970/
деньги под залог машины новосибирск
1вин официальный сайт [url=https://www.balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848]https://www.balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848[/url] .
Η ιστοσελίδα μας προτείνει κορυφαίες επιλογές καζίνο Επισκεφθείτε το BoaBoa Casino και απολαύστε την αυθεντική ελληνική εμπειρία παιχνιδιού
1.вин [url=https://www.alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210]https://www.alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210[/url] .
1win скачать kg [url=www.1win6002.ru]www.1win6002.ru[/url] .
мрстбет [url=mostbet6007.ru]mostbet6007.ru[/url] .
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
взять займ под птс
avtolombard-pid-zalog-pts.ru/ekb.html
займ под залог птс
1 ван вин [url=https://www.1win6002.ru]https://www.1win6002.ru[/url] .
mostbet скачать [url=https://mostbet6007.ru/]https://mostbet6007.ru/[/url] .
1 вин официальный сайт [url=https://balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848]https://balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848[/url] .
Аккредитованное агентство http://pravo-migranta.ru по аутстаффингу мигрантов и миграционному аутсорсингу. Оформление иностранных сотрудников без рисков. Бесплатная консультация и подбор решений под ваш бизнес.
1 win официальный [url=https://balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848/]https://balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848/[/url] .
1 вин [url=https://1win6049.ru/]https://1win6049.ru/[/url] .
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
репрайсер wb по расписанию [url=https://www.reprajser-wildberries.ru]репрайсер wb по расписанию[/url] .
займ птс
avtolombard-pid-zalog-pts.ru/kemerovo.html
деньги под залог авто птс
1vin казино [url=https://balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848/]1vin казино[/url] .
бк 1win [url=http://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210]http://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210[/url] .
Официальный сайт 1win https://1win.kykyryza.ru ставки на спорт, киберспорт, казино, live-игры и слоты от лучших провайдеров. Моментальные выплаты, круглосуточная поддержка, щедрые акции и удобное мобильное приложение. Делай ставки и играй в казино на 1win — быстро, безопасно и выгодно!
Swiat emocji z 1win 1win pl Zaklady sportowe i e-sportowe, kasyno online, poker, gry wirtualne i wiele wiecej. Szybka rejestracja, bonus powitalny i natychmiastowa wyplata wygranych. 1win – wszystko, czego potrzebujesz do gry w jednym miejscu!
кредит под птс автомобиля в москве
avtolombard-pid-zalog-pts.ru
автоломбард кредит под птс
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
1win казино [url=www.balashiha.myqip.ru/?1-12-0-00000437-000-0-0-1743258848]1win казино[/url] .
1 win. [url=www.1win6049.ru]www.1win6049.ru[/url] .
1win зайти [url=https://1win6002.ru/]https://1win6002.ru/[/url] .
автоломбард займ под птс
avtolombard-pid-zalog-pts.ru/nsk.html
деньги под птс круглосуточные
most bet [url=http://mostbet6007.ru]http://mostbet6007.ru[/url] .
1win мобильная версия сайта [url=1win6049.ru]1win мобильная версия сайта[/url] .
деньги в кредит под залог машины
zaim-pod-zalog-pts1.ru/ekb.html
деньги под залог авто остается у вас
1-win [url=https://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210/]https://alfatraders.borda.ru/?1-0-0-00004932-000-0-0-1743258210/[/url] .
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
1win вход [url=1win6003.ru]1win6003.ru[/url] .
mostbet игры [url=mostbet6008.ru]mostbet игры[/url] .
1вин сайт официальный [url=http://obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936]1вин сайт официальный[/url] .
кредит под птс авто
avtolombard-pid-zalog-pts.ru/kazan.html
взять кредит в залог автомобиля
1win зайти [url=http://1win6003.ru]http://1win6003.ru[/url] .
mostbet kg скачать на андроид [url=https://mostbet6008.ru/]https://mostbet6008.ru/[/url] .
Thank you for every other informative site. The place else may I am getting that type of info written in such an ideal way? I have a challenge that I am simply now operating on, and I’ve been on the look out for such information.
ваучер 1win [url=www.obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936]www.obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936[/url] .
Find the Perfect Clock https://clocks-top.com for Any Space! Looking for high-quality clocks? At Top Clocks, we offer a wide selection, from alarm clocks to wall clocks, mantel clocks, and more. Whether you prefer modern, vintage, or smart clocks, we have the best options to enhance your home. Explore our collection and find the perfect timepiece today!
paper writers https://diehardcard.com/ english article
кредит под птс автомобиля
zaim-pod-zalog-pts1.ru/kemerovo.html
наличные под залог автомобиля
macaulay honors college essay https://customgiftto.com/ paper writing
Откройте для себя vavadaukr.kiev.ua, предложит.
лучшие советы, для того чтобы.
Познакомьтесь с vavadaukr.kiev.ua, доступны.
новых тенденциях.
С vavadaukr.kiev.ua.
vavadaukr.kiev.ua предлагает вам возможность.
Станьте частью vavadaukr.kiev.ua, которое.
интересные факты, будут вам полезны.
Ознакомьтесь с возможностями vavadaukr.kiev.ua, интересными инновациями.
мир нового.
Узнайте больше о vavadaukr.kiev.ua, открывать новое.
множество опций, которые.
Сайт vavadaukr.kiev.ua уникален тем, доступный контент.
Воспользуйтесь ресурсами vavadaukr.kiev.ua для.
vavadaukr.kiev.ua – это площадка для, новые взгляды.
vavadaukr.kiev.ua – ваша онлайн-платформа, расширят ваш кругозор.
Что предлагает vavadaukr.kiev.ua, придавая уверенность.
bonus vavada [url=https://vavadaukr.kiev.ua/]bonus vavada[/url] .
Wonderful post but I was wondering if you could write a litte more on this topic? I’d be very grateful if you could elaborate a little bit further. Kudos!
https://grktmn.ru/includes/pages/bk_pari_promokod_na_fribet_bonus_do_25000_rubley.html
1вин онлайн [url=www.1win6050.ru]www.1win6050.ru[/url] .
интернет провайдеры по адресу екатеринбург
domashij-internet-ekaterinburg001.ru
провайдер по адресу
подключить домашний интернет екатеринбург
domashij-internet-ekaterinburg002.ru
домашний интернет подключить екатеринбург
кайт школа анапа
1вин сайт [url=http://1win6050.ru]http://1win6050.ru[/url] .
рулонные жалюзи с рисунком [url=www.rulonnye-shtory-s-elektroprivodom99.ru]рулонные жалюзи с рисунком[/url] .
1wln [url=http://1win6003.ru]http://1win6003.ru[/url] .
мостбет официальный сайт [url=http://svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517]http://svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517[/url] .
уличные рулонные шторы [url=https://www.rulonnye-shtory-s-elektroprivodom99.ru]уличные рулонные шторы[/url] .
интернет тарифы екатеринбург
domashij-internet-ekaterinburg003.ru
провайдер по адресу
[url=http://bankrotstvo-v-moskve95.ru]банкротство физических лиц отзывы[/url]
1win кыргызстан [url=www.1win6050.ru]www.1win6050.ru[/url] .
мрстбет [url=https://www.mostbet6008.ru]https://www.mostbet6008.ru[/url] .
1win онлайн [url=http://1win6003.ru]http://1win6003.ru[/url] .
mostbet apk скачать [url=http://svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517]http://svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517[/url] .
скачат мостбет [url=svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517]svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517[/url] .
мотбет [url=http://mostbet6008.ru]http://mostbet6008.ru[/url] .
Ενδιαφέρεστε για ένα αξιόπιστο καζίνο για ελληνικό κοινό? Τσεκάρετε Leon Casino Greece για να απολαύσετε με εξαιρετικές υπηρεσίες.
1winn [url=https://obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936]1winn[/url] .
Thank you for sharing your thoughts. I truly appreciate your efforts and I am waiting for your next write ups thanks once again.
https://www.finlandmlbforum.com/read-blog/18741
mostbet kg скачать на андроид [url=svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517]mostbet kg скачать на андроид[/url] .
ванвин [url=http://1win6003.ru]ванвин[/url] .
мосбет казино [url=https://mostbet6008.ru/]https://mostbet6008.ru/[/url] .
Добро пожаловать в 1win https://1win.onedivision.ru азарт, спорт и выигрыши рядом! Ставь на матчи, играй в казино, участвуй в турнирах и получай крутые бонусы. Удобный интерфейс, быстрая регистрация и выплаты.
1win com [url=https://www.1win6050.ru]https://www.1win6050.ru[/url] .
writing essay https://tempcontroledu.com/ help with college essays
мостбет скачать казино [url=https://www.svstrazh.forum24.ru/?1-18-0-00000136-000-0-0-1743260517]мостбет скачать казино[/url] .
Бесплатные Steam аккаунты http://t.me/GGZoneSteam с играми и бонусами. Проверенные логины и пароли, ежедневное обновление, удобный поиск. Забирай свой шанс на крутой аккаунт без лишних действий!
εγγραφείτε τώρα Ανακαλύψτε τα παιχνίδια του Leon Bet στην Ελλάδα και απολαύστε τα καλύτερα στοιχήματα στην Ελλάδα.
кайт школа
essay maker https://mobilemechanicbaltimoremd.com/ the best essay writing service
Доска объявлений https://estul.ru/blog по всей России: продавай и покупай товары, заказывай и предлагай услуги. Быстрое размещение, удобный поиск, реальные предложения. Каждый после регистрации получает на баланс аккаунта 100? для возможности бесплатного размещения ваших объявлений
pop over to this web-site [url=https://sites.google.com/mycryptowalletus.com/phantom-wallet-login/]phantom Extension[/url]
автоматические римские шторы [url=www.rulonnye-shtory-s-elektroprivodom99.ru]автоматические римские шторы[/url] .
their website [url=https://sites.google.com/mycryptowalletus.com/metamask-wallet-login/]MetaMask Download[/url]
1win ставки официальный сайт [url=http://obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936]http://obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936[/url] .
more helpful hints [url=https://sites.google.com/mycryptowalletus.com/phantom-walletlogin/]phantom Extension[/url]
1win. com [url=https://obovsem.myqip.ru/?1-9-0-00000059-000-0-0-1743051936]1win. com[/url] .
Maispin——2025年最新USDT娛樂城,安全、快速、刺激!
歡迎來到 Maispin,2025年最具潛力的新秀 USDT娛樂城!在這裡,您只需提供 錢包地址 即可註冊,無需繁瑣的個人資訊,享受 安全、匿名、快速 的遊戲體驗。Maispin 提供超過 1000種賭場遊戲,涵蓋 真人百家樂、體育投注、老虎機、撲克、輪盤 等經典娛樂,讓您隨時隨地感受頂級賭場的刺激氛圍。我們與世界知名遊戲供應商合作,確保遊戲 公平公正,並提供高額彩金、獎勵活動,讓玩家輕鬆贏大獎!作為 USDT區塊鏈娛樂城,Maispin 存提款秒到帳,無需繁瑣審核,資金流動安全透明,讓玩家更安心地享受遊戲樂趣。立即加入 M宇宙,體驗前所未有的加密娛樂新潮流!
1win казино [url=https://1win6004.ru/]https://1win6004.ru/[/url] .
мостбет промокод [url=mostbet6009.ru]mostbet6009.ru[/url] .
click here to find out more [url=https://sites.google.com/mycryptowalletus.com/phantom-wallet-login/]phantom Extension[/url]
какие бывают рулонные шторы [url=http://rulonnye-shtory-s-elektroprivodom99.ru]какие бывают рулонные шторы[/url] .
1 вин войти [url=www.1win6004.ru]www.1win6004.ru[/url] .
mostbet kg скачать на андроид [url=https://mostbet6009.ru]https://mostbet6009.ru[/url] .
Homepage [url=https://keplr-extension.com]keplr Extension[/url]
Мы предлагаем дипломы любых профессий по выгодным ценам. Дипломы производят на настоящих бланках Купить диплом об образовании [url=http://diplomf-v-irkutske.ru/]diplomf-v-irkutske.ru[/url]
Где заказать диплом по нужной специальности?
Приобрести диплом института по доступной стоимости вы сможете, обращаясь к проверенной специализированной компании.: [url=http://institute-diplom.ru/]institute-diplom.ru[/url]
1win вход на сайт [url=http://1win6050.ru]http://1win6050.ru[/url] .
1win официальный сайт [url=https://kharkovbynight.forum24.ru/?1-5-0-00000235-000-0-0]1win официальный сайт[/url] .
Воздушные шары на выпускной
рулонные шторы больших размеров [url=rulonnye-shtory-s-elektroprivodom99.ru]рулонные шторы больших размеров[/url] .
свадебный тент аренда [url=www.shatry-dlya-meropriyatiy.ru]www.shatry-dlya-meropriyatiy.ru[/url] .
Самые новые анекдоты https://www.anekdotovmir.ru — коротко, метко и смешно! Подборка актуального юмора: от жизненных до политических. Заходи за порцией хорошего настроения!
find this [url=https://sites.google.com/mycryptowalletus.com/phantomwalletlogin/]phantom Extension[/url]
1win kg [url=www.girikms.forum24.ru/?1-2-0-00000264-000-0-0]www.girikms.forum24.ru/?1-2-0-00000264-000-0-0[/url] .
заказ шатров для мероприятий [url=www.shatry-dlya-meropriyatiy.ru/]заказ шатров для мероприятий[/url] .
Кладбища Видного https://bulatnikovskoe.ru график работы, схема участков, порядок захоронения и перезахоронения. Все важные данные в одном месте: для родственников, посетителей и организаций.
masters degree https://sirtuinresearch.com/ pay someone to write my essay
Keep on working, great job!
http://www.bakinsky-dvorik.ru/club/user/177754/blog/5603/
Здравствуйте!
Без университета очень непросто было продвигаться по карьере. В последние годы документ не дает каких-либо гарантий, что удастся получить престижную работу. Куда более важное значение имеют профессиональные навыки и знания специалиста и его постоянный опыт. Именно из-за этого решение о покупке диплома можно считать рациональным. Заказать диплом об образовании [url=http://av.flyboard.ru/viewtopic.php?f=9&t=2098/]av.flyboard.ru/viewtopic.php?f=9&t=2098[/url]
Добрый день!
Мы изготавливаем дипломы любых профессий по приятным тарифам. Цена может зависеть от выбранной специальности, года получения и ВУЗа: [url=http://rdiplomm24.com/]rdiplomm24.com/[/url]
easy way to write an essay https://organicwrite.com/ pay for essay
Воздушные шарики Липецк на 23 февраля
[b]Диплом любого университета РФ![/b]
Без ВУЗа сложно было продвинуться вверх по карьере. Именно из-за этого решение о заказе диплома стоит считать рациональным. Купить диплом о высшем образовании [url=http://aweza.co/employer/gosznac-diplom-24/]aweza.co/employer/gosznac-diplom-24[/url]
Купить диплом о высшем образовании!
Мы изготавливаем дипломы любой профессии по приятным тарифам. Вы заказываете документ через надежную и проверенную временем фирму. : [url=http://mosvol.flybb.ru/viewtopic.php?f=2&t=569/]mosvol.flybb.ru/viewtopic.php?f=2&t=569[/url]
1.вин [url=1win6051.ru]1win6051.ru[/url] .
1win kg скачать [url=http://1win6004.ru/]1win kg скачать[/url] .
скачать mostbet [url=https://mostbet6009.ru]https://mostbet6009.ru[/url] .
1win вход [url=cinemania.forum24.ru/?1-15-0-00001911-000-0-0-1743258043]cinemania.forum24.ru/?1-15-0-00001911-000-0-0-1743258043[/url] .
Rattling great info can be found on blog.
1wln [url=http://1win6052.ru/]http://1win6052.ru/[/url] .
мостбет казино [url=https://mostbet6009.ru/]https://mostbet6009.ru/[/url] .
Воздушные шарики на свадьбу
1вин официальный сайт мобильная [url=http://1win6004.ru]http://1win6004.ru[/url] .
Мы изготавливаем дипломы любой профессии по приятным тарифам.– [url=http://diplom-top.ru/kupit-gosudarstvennij-diplom-s-zaneseniem-v-reestr/]diplom-top.ru/kupit-gosudarstvennij-diplom-s-zaneseniem-v-reestr/[/url]
1 вин официальный [url=http://1win6051.ru]http://1win6051.ru[/url] .
1vin [url=https://1win6051.ru/]1vin[/url] .
mostbet официальный сайт [url=mostbet6009.ru]mostbet6009.ru[/url] .
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Дипломы производят на подлинных бланках Заказать диплом института [url=http://rusd-diplomj.ru/]rusd-diplomj.ru[/url]
Где заказать диплом по необходимой специальности?
Приобрести диплом института по невысокой стоимости вы сможете, обратившись к надежной специализированной фирме.: [url=http://diplom-city24.ru/]diplom-city24.ru[/url]
1вин. [url=www.1win6051.ru]www.1win6051.ru[/url] .
мосбет казино [url=https://www.mostbet6010.ru]https://www.mostbet6010.ru[/url] .
1 win казино [url=http://knowledge.forum24.ru/?1-1-0-00000082-000-0-0-1743258384/]http://knowledge.forum24.ru/?1-1-0-00000082-000-0-0-1743258384/[/url] .
1 win регистрация [url=https://1win6004.ru]1 win регистрация[/url] .
установка шатров для мероприятий [url=www.shatry-dlya-meropriyatiy.ru/]www.shatry-dlya-meropriyatiy.ru/[/url] .
Maispin——2025年最新USDT娛樂城,安全、快速、刺激!
歡迎來到 Maispin,2025年最具潛力的新秀 USDT娛樂城!在這裡,您只需提供 錢包地址 即可註冊,無需繁瑣的個人資訊,享受 安全、匿名、快速 的遊戲體驗。Maispin 提供超過 1000種賭場遊戲,涵蓋 真人百家樂、體育投注、老虎機、撲克、輪盤 等經典娛樂,讓您隨時隨地感受頂級賭場的刺激氛圍。我們與世界知名遊戲供應商合作,確保遊戲 公平公正,並提供高額彩金、獎勵活動,讓玩家輕鬆贏大獎!作為 USDT區塊鏈娛樂城,Maispin 存提款秒到帳,無需繁瑣審核,資金流動安全透明,讓玩家更安心地享受遊戲樂趣。立即加入 M宇宙,體驗前所未有的加密娛樂新潮流!
казино 1win [url=https://1win6052.ru]казино 1win[/url] .
мостбет кыргызстан скачать [url=https://mostbet6010.ru]https://mostbet6010.ru[/url] .
купить аккаунт с прокачкой marketpleys-akkauntov.ru
Гелиевые шарики на рождение ребенка
1win. com [url=http://1win6051.ru]http://1win6051.ru[/url] .
шатры для мероприятий аренда цена [url=http://shatry-dlya-meropriyatiy.ru/]http://shatry-dlya-meropriyatiy.ru/[/url] .
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Hey there! Do you use Twitter? I’d like to follow you if that would be okay. I’m undoubtedly enjoying your blog and look forward to new updates.
промокод на new retro casino
1wi [url=https://1win6052.ru/]https://1win6052.ru/[/url] .
услуги по продаже аккаунтов площадка для продажи аккаунтов
провайдер интернета по адресу казань
domashij-internet-kazan001.ru
интернет провайдеры в казани по адресу дома
Гелиевые шары онлайн
свадебный тент аренда [url=https://shatry-dlya-meropriyatiy.ru]https://shatry-dlya-meropriyatiy.ru[/url] .
Нужны [url=https://maktrans.ru/]автомобильные перевозки грузов по россии[/url] без лишней суеты? Обратитесь в «Мак-Транс». Мы берем на себя логистику, оформление, сопровождение и безопасность. Доставим из Москвы в любой регион точно в срок. Прозрачные цены, чёткие условия, индивидуальный подход.
маркетплейс аккаунтов соцсетей magazin-accauntov.ru
арендовать склад в москве для личных вещей [url=http://hranim-veshi.ru/]арендовать склад в москве для личных вещей[/url] .
домашний интернет тарифы казань
domashij-internet-kazan002.ru
интернет домашний казань
Приобретение диплома через качественную и надежную фирму дарит ряд плюсов для покупателя. Это решение помогает сберечь как личное время, так и серьезные финансовые средства. Впрочем, плюсов намного больше.Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий. Дипломы изготавливаются на настоящих бланках. Доступная цена в сравнении с серьезными затратами на обучение и проживание. Покупка диплома о высшем образовании из российского ВУЗа станет рациональным шагом.
Заказать диплом о высшем образовании: [url=http://diplomskiy.com/kupit-diplom-o-visshem-obrazovanii-s-zanosom-v-reestr/]diplomskiy.com/kupit-diplom-o-visshem-obrazovanii-s-zanosom-v-reestr/[/url]
недорогой интернет казань
domashij-internet-kazan003.ru
домашний интернет тарифы казань
маркетплейс для реселлеров http://ploshadka-dlya-prodazhi-akkauntov.ru
mostbet.kg [url=https://mostbet6010.ru]https://mostbet6010.ru[/url] .
Воздушные шарики на 23 февраля
1 win.kg [url=www.1win6052.ru]www.1win6052.ru[/url] .
дешевый интернет москва
domashij-internet-msk001.ru
провайдеры интернета по адресу москва
дорого скупка золота b-gold.ru [url=https://www.of-md.com/jwe-qs/]дорого скупка золота b-gold.ru[/url] .
portofele electronice casino [url=http://1win5004.ru/]http://1win5004.ru/[/url] .
поддержка мостбет [url=mostbet6010.ru]mostbet6010.ru[/url] .
скупка золота в районе b-gold.ru [url=https://www.of-md.com/jwe-qs//]скупка золота в районе b-gold.ru[/url] .
1 win md [url=1win5004.ru]1win5004.ru[/url] .
покупка аккаунтов https://kupit-accaunt.ru
склад хранения москва [url=http://hranim-veshi.ru/]склад хранения москва[/url] .
подключить интернет
domashij-internet-msk002.ru
провайдеры интернета в москве по адресу проверить
1win официальный сайт скачать [url=https://freereklama.borda.ru/?1-5-0-00000114-000-0-0-1743258539]https://freereklama.borda.ru/?1-5-0-00000114-000-0-0-1743258539[/url] .
Мы готовы предложить дипломы любых профессий по выгодным тарифам.– [url=http://vuz-diplom.ru/bistro-vnesite-diplom-v-reestr-legko-i-nadezhno/]vuz-diplom.ru/bistro-vnesite-diplom-v-reestr-legko-i-nadezhno/[/url]
Гелиевые шарики в Липецке на свадьбу
безопасная сделка аккаунтов prodat-akkaunt.ru
1win казино [url=https://1win6052.ru/]https://1win6052.ru/[/url] .
провайдеры домашнего интернета москва
domashij-internet-msk003.ru
лучший интернет провайдер москва
1win мобильная версия сайта [url=http://1win6005.ru/]http://1win6005.ru/[/url] .
мостбет кыргызстан скачать [url=http://mostbet6030.ru/]http://mostbet6030.ru/[/url] .
площадка для продажи аккаунтов pokupka-akkauntov.ru/
бк 1win [url=http://1win6005.ru/]http://1win6005.ru/[/url] .
мостбет промокод [url=mostbet6030.ru]mostbet6030.ru[/url] .
провайдеры по адресу
domashij-internet-nizhnij-novgorod001.ru
провайдеры интернета по адресу
1win com [url=www.snatkina.borda.ru/?1-5-0-00000311-000-0-0-1743258575]www.snatkina.borda.ru/?1-5-0-00000311-000-0-0-1743258575[/url] .
кайт школа
недорогие хостинги php http://uavps.net/vps
Воздушные шары на рождение ребенка
провайдеры интернета в нижнем новгороде по адресу проверить
domashij-internet-nizhnij-novgorod002.ru
интернет провайдеры по адресу дома
сайт доставки суши https://sushibarnaul.ru/
официальный сайт 1win [url=https://www.1win6053.ru]https://www.1win6053.ru[/url] .
1win pariuri [url=1win5004.ru]1win5004.ru[/url] .
mostbet kg отзывы [url=http://mostbet6029.ru/]http://mostbet6029.ru/[/url] .
проверить провайдера по адресу
domashij-internet-nizhnij-novgorod003.ru
провайдеры интернета в нижнем новгороде по адресу проверить
Гелиевые шарики Липецк с бесплатной доставкой
посетить веб-сайт [url=https://lk.mango-offic.info]Mango-Office как подключить[/url]
1win pariuri [url=https://www.1win5004.ru]https://www.1win5004.ru[/url] .
провайдеры интернета в новосибирске по адресу
domashij-internet-novosibirsk001.ru
подключить интернет
найти это [url=https://mango-offic.info]Mango-Office облачная телефония[/url]
1win. com [url=http://1win6053.ru]1win. com[/url] .
мостбет кыргызстан [url=https://www.mostbet6029.ru]https://www.mostbet6029.ru[/url] .
mostbet промокод [url=https://mostbet6029.ru/]https://mostbet6029.ru/[/url] .
1win.kg [url=www.1win6005.ru]www.1win6005.ru[/url] .
скачать mostbet [url=http://mostbet6030.ru/]http://mostbet6030.ru/[/url] .
1win партнёрка [url=https://1win6053.ru/]https://1win6053.ru/[/url] .
мостбет кыргызстан скачать [url=https://hiend.borda.ru/?1-16-0-00000260-000-0-0]https://hiend.borda.ru/?1-16-0-00000260-000-0-0[/url] .
jocuri de noroc online moldova [url=https://1win5004.ru/]jocuri de noroc online moldova[/url] .
интернет провайдеры новосибирск по адресу
domashij-internet-novosibirsk002.ru
подключить интернет в квартиру новосибирск
подробнее [url=https://mango-offlce.net/]Mango-Office вебинар[/url]
write essay ai https://msdnaacr.com/ help write an essay
1win football [url=http://1win13.com.ng/]http://1win13.com.ng/[/url] .
1 win регистрация [url=1win6054.ru]1win6054.ru[/url] .
mostbet игры [url=mostbet6029.ru]mostbet6029.ru[/url] .
Гелиевые шары в Липецке на юбилей
Горкинское кладбище https://gorkinskoe.ru одно из старейших в Видном. Подробная информация: адрес, как доехать, порядок захоронений, наличие участков, памятники, услуги по уходу.
узнать больше [url=https://mango-offic.info]Mango-Office виртуальный номер[/url]
1wi [url=https://1win6054.ru]https://1win6054.ru[/url] .
cheap essay writing service us https://lionessmoon.com/ help me write a essay
1 win [url=https://1win13.com.ng/]1 win[/url] .
1вин партнерка [url=1win6005.ru]1win6005.ru[/url] .
1win ракета [url=1win6006.ru]1win6006.ru[/url] .
интернет провайдеры в новосибирске по адресу дома
domashij-internet-novosibirsk003.ru
провайдеры по адресу дома
Pinco az oyunçular üçün 24/7 dəstək təklif edir|Pinco bonusları hər bir istifadəçiyə təqdim olunur|Pinco kazino oyunları keyfiyyətli və müxtəlifdir|Pinco bonus kodları ilə əlavə qazanc mümkündür|Pinco az ilə oyunların keyfiyyəti təmin olunur|Pinco az oyunçularına tez-tez turnirlər təqdim edir|Pinco slot oyunları yüksək RTP göstəricisinə malikdir|Pinco az oyunçuların rahatlığını əsas tutur|Pinco casino azerbaijan istifadəçilərinə yüksək keyfiyyətli xidmət göstərir [url=https://pinco-casino-azerbaijan.com/]pinco azerbaycan[/url] .
Антенны – http://tv-antenka.ru/
mostbet kg скачать на андроид [url=https://www.mostbet6030.ru]https://www.mostbet6030.ru[/url] .
1вин вход [url=https://1win6006.ru/]1вин вход[/url] .
Pinco kazinosunda canlı oyunlar əsl zövq verir|Pinco online casino Azərbaycanda populyar seçimlərdəndir|Pinco saytında ən məşhur provayderlərin oyunları var|Pinco oyunçuların tələblərinə cavab verir|Pinco kazinosunun promosyonları daim yenilənir|Pinco az-da kazinoya giriş daim əlçatandır|Pinco kazinosunda texniki dəstək çox operativdir|Pinco az ilə təhlükəsiz oyun mühiti təmin olunur|Pinco kazinosunda istənilən vaxt oyun oynamaq mümkündür [url=https://pinco-casino-azerbaijan.com/]www.pinco-casino-azerbaijan.com[/url].
Всё о Казахстане tr kazakhstan kz история, культура, города, традиции, природа и достопримечательности. Полезная информация для туристов, жителей и тех, кто хочет узнать страну ближе.
кайт школа
Pinco kazinosu oyunçular üçün cəlbedici seçimdir|Pinco platformasında turnirlər və yarışlar tez-tez keçirilir|Pinco online kazino əyləncə və qazanc üçün ideal məkandır|Pinco ilə oyun təcrübəsi maraqlı və gəlirlidir|Pinco bonus şərtləri ədalətlidir və şəffafdır|Pinco ilə hər zaman yeni təcrübələr əldə etmək olur|Pinco ilə həm əylənmək, həm də pul qazanmaq olar|Pinco promo kodu yeni istifadəçilər üçün əlverişlidir|Pinco kazinosunda istənilən vaxt oyun oynamaq mümkündür [url=https://pinco-casino-azerbaijan.com/]pinco casino login[/url].
Гелиевые шарики Липецк на день рожденье
mostbet скачать [url=https://www.severussnape.borda.ru/?1-4-0-00000505-000-0-0-1743260265]https://www.severussnape.borda.ru/?1-4-0-00000505-000-0-0-1743260265[/url] .
1.вин [url=https://1win6005.ru/]https://1win6005.ru/[/url] .
Kvalitni nabytek v Praze ruma.cz stylove reseni pro domacnost i kancelar. Satni skrine, sedaci soupravy, kuchyne, postele od proverenych vyrobcu. Rozvoz po meste a montaz na klic.
какие провайдеры по адресу
domashij-internet-spb001.ru
интернет провайдер санкт-петербург
Yeni istifadəçilər üçün Pinco bonusları çox sərfəlidir|Pinco online casino Azərbaycanda populyar seçimlərdəndir|Pinco saytında ən məşhur provayderlərin oyunları var|Pinco kazinosu mobil cihazlarda problemsiz işləyir|Pinco oyunçular üçün rahat interfeys təqdim edir|Pinco kazinosu hər zaman etibarlı qalır|Pinco az onlayn kazinosunda etibarlı ödəniş üsulları var|Pinco promo kodu yeni istifadəçilər üçün əlverişlidir|Pinco platformasında qeydiyyat və giriş çox sadədir [url=https://pinco-casino-azerbaijan.com/]pinco yüklə[/url].
1 win сайт [url=https://1win6053.ru/]https://1win6053.ru/[/url] .
Pinco onlayn kazinosu geniş oyun çeşidi ilə fərqlənir|Pinco kazinosunda minimum depozitlə oyunlara başlamaq mümkündür|Pinco kazinosu etibarlı və lisenziyalı platformadır|Pinco oyunçuların tələblərinə cavab verir|Pinco bonus şərtləri ədalətlidir və şəffafdır|Pinco qeydiyyat prosesi çox rahatdır|Pinco az onlayn kazinosunda etibarlı ödəniş üsulları var|Pinco az saytı daim yenilənir və təkmilləşir|Pinco kazinosunda istənilən vaxt oyun oynamaq mümkündür [url=https://pinco-casino-azerbaijan.com/]pinco casino az[/url].
Офіційний сайт 1win https://visitkyiv.com.ua/ спортивні ставки, онлайн-казино, покер, live-ігри, швидкі висновки. Бонуси новим гравцям, мобільний додаток, цілодобова підтримка.
check over here
[url=https://www.brides-from.ru/Starheaven.html]Starheaven, bride from russia[/url]
мотбет [url=www.mostbet6030.ru]мотбет[/url] .
домашний интернет в санкт-петербурге
domashij-internet-spb002.ru
провайдеры санкт-петербург
Pinco kazinosu oyunçular üçün cəlbedici seçimdir|Pinco platformasında turnirlər və yarışlar tez-tez keçirilir|Pinco kazino oyunları keyfiyyətli və müxtəlifdir|Pinco oyunçuların tələblərinə cavab verir|Pinco oyunçular üçün rahat interfeys təqdim edir|Pinco kazinosu hər zaman etibarlı qalır|Pinco oyunçulara dürüst və şəffaf oyun təklif edir|Pinco istifadəçiləri üçün müntəzəm lotereyalar keçirilir|Pinco az oyunçularına şəxsi bonuslar təqdim edir [url=https://pinco-casino-azerbaijan.com/]pinco login[/url].
Pinco platformasında təhlükəsizlik və məxfilik qorunur|Pinco bonusları hər bir istifadəçiyə təqdim olunur|Pinco canlı dəstək xidməti çox operativdir|Pinco oyunçuların tələblərinə cavab verir|Pinco mobil tətbiqi yükləmək çox rahatdır|Pinco ilə hər zaman yeni təcrübələr əldə etmək olur|Pinco az oyunçularına xüsusi aksiyalar təqdim edir|Pinco onlayn kazinosunda müxtəlif oyun növləri var|Pinco ilə onlayn kazinoda əsl əyləncə yaşayacaqsınız [url=https://pinco-casino-azerbaijan.com/]pinco online[/url].
web link
[url=https://www.brides-from.ru/]brides from russia[/url]
Pinco az oyunçular üçün 24/7 dəstək təklif edir|Pinco kazinosunun mobil versiyası çox rahat işləyir|Pinco kazino oyunları keyfiyyətli və müxtəlifdir|Pinco ilə oyun təcrübəsi maraqlı və gəlirlidir|Pinco kazinosunun promosyonları daim yenilənir|Pinco az oyunçularına tez-tez turnirlər təqdim edir|Pinco az onlayn kazinosunda etibarlı ödəniş üsulları var|Pinco onlayn kazinosunda müxtəlif oyun növləri var|Pinco kazino təcrübəsi digərlərindən fərqlənir [url=https://pinco-casino-azerbaijan.com/]pinco casino az[/url].
Pinco onlayn kazinosu geniş oyun çeşidi ilə fərqlənir|Pinco online casino Azərbaycanda populyar seçimlərdəndir|Pinco onlayn kazinoda mükəmməl istifadəçi interfeysi mövcuddur|Pinco kazinosu mobil cihazlarda problemsiz işləyir|Pinco mobil tətbiqi yükləmək çox rahatdır|Pinco az istifadəçilər üçün əlavə cashback kampaniyaları keçirir|Pinco mobil tətbiqi ilə hər yerdə oyun mümkündür|Pinco az oyunçuların rahatlığını əsas tutur|Pinco kazino təcrübəsi digərlərindən fərqlənir [url=https://pinco-casino-azerbaijan.com/]pinco online casino[/url].
подключить интернет
domashij-internet-spb003.ru
провайдеры по адресу санкт-петербург
Доска бесплатных объявлений salexy kz Казахстана: авто, недвижимость, техника, услуги, работа и многое другое. Тысячи свежих объявлений каждый день — легко найти и разместить!
Pinco kazinosu oyunçular üçün cəlbedici seçimdir|Pinco kazinosunda minimum depozitlə oyunlara başlamaq mümkündür|Pinco kazinosu etibarlı və lisenziyalı platformadır|Pinco oyunçuların tələblərinə cavab verir|Pinco oyunçular üçün rahat interfeys təqdim edir|Pinco az-da kazinoya giriş daim əlçatandır|Pinco oyunçulara dürüst və şəffaf oyun təklif edir|Pinco kazino platformasında qazanc şansı çoxdur|Pinco kazino təcrübəsi digərlərindən fərqlənir [url=https://pinco-casino-azerbaijan.com/]pinco 007[/url].
1вин кг [url=http://1win6054.ru]1вин кг[/url] .
Fantastic beat ! I would like to apprentice while you amend your site, how can i subscribe for a blog site? The account aided me a acceptable deal. I had been tiny bit acquainted of this your broadcast offered bright clear concept
win1 casino [url=https://1win1001.top/]win1 casino[/url] .
услуги складского хранения [url=https://hranim-veshi.ru/]услуги складского хранения[/url] .
sports betting 1win [url=https://1win13.com.ng/]https://1win13.com.ng/[/url] .
мастбет [url=http://mostbet6031.ru/]http://mostbet6031.ru/[/url] .
weblink [url=https://them-rril-lynch.net]merrill edge[/url]
Pinco kazinosunda canlı oyunlar əsl zövq verir|Pinco platformasında turnirlər və yarışlar tez-tez keçirilir|Pinco canlı dəstək xidməti çox operativdir|Pinco platformasında qeydiyyat prosesi asandır|Pinco kazinosunun promosyonları daim yenilənir|Pinco az istifadəçilər üçün əlavə cashback kampaniyaları keçirir|Pinco az onlayn kazinosunda etibarlı ödəniş üsulları var|Pinco az oyunçuların rahatlığını əsas tutur|Pinco kazino istifadəçilərinə geniş oyun kataloqu təklif edir [url=https://pinco-casino-azerbaijan.com/]www.pinco-casino-azerbaijan.com[/url].
Pinco az oyunçular üçün 24/7 dəstək təklif edir|Pinco bonusları hər bir istifadəçiyə təqdim olunur|Pinco oyunçular üçün müxtəlif bonuslar və aksiyalar təklif edir|Pinco ilə onlayn mərclər çox rahatdır|Pinco bonus şərtləri ədalətlidir və şəffafdır|Pinco kazino saytı sadə və istifadəçiyə uyğundur|Pinco platforması beynəlxalq standartlara uyğundur|Pinco onlayn kazinosunda müxtəlif oyun növləri var|Pinco kazino təcrübəsi digərlərindən fərqlənir [url=https://pinco-casino-azerbaijan.com/]pinco bonus[/url].
1win [url=http://1win1001.top/]http://1win1001.top/[/url] .
провайдеры интернета в екатеринбурге по адресу проверить
domashij-internet-ekaterinburg001.ru
интернет домашний екатеринбург
мастбет [url=http://mostbet6031.ru]мастбет[/url] .
1wi [url=https://1win6053.ru]https://1win6053.ru[/url] .
официальный сайт 1 вин [url=http://1win6042.ru]http://1win6042.ru[/url] .
mostbet скачать [url=http://mostbet6032.ru/]http://mostbet6032.ru/[/url] .
mostbet casino [url=https://www.remsanteh.borda.ru/?1-6-0-00000047-000-0-0]https://www.remsanteh.borda.ru/?1-6-0-00000047-000-0-0[/url] .
1wi. [url=1win6054.ru]1win6054.ru[/url] .
1 win bet [url=www.1win13.com.ng]www.1win13.com.ng[/url] .
1вин [url=https://www.1win6006.ru]https://www.1win6006.ru[/url] .
1вин про [url=http://1win6042.ru/]http://1win6042.ru/[/url] .
Всё о кладбищах Видного http://bitcevskoe.ru Битцевское, Дрожжинское, Спасское, Жабкинское. Официальная информация, участки, услуги, порядок оформления документов, схема проезда.
интернет провайдеры в екатеринбурге по адресу дома
domashij-internet-ekaterinburg002.ru
интернет провайдеры по адресу дома
мостбет зеркало [url=http://mostbet6032.ru]мостбет зеркало[/url] .
Hi if you’re laughing, you’re in!
Win or lose, at least you brought the jokes. basketball puns
Basketball.puns that shoot, score, and serve pure joy. Make every conversation more playful with a hoops twist.
Toda la información en el enlace – п»їhttps://basketballpuns.com/
Here’s to plenty of chuckles!
Upgrade your automobile into a work of art with our qualified vehicle enhancement packages. At Bergin Auto Shop, we focus in providing high-quality enhancements that showcase your unique flair. From sleek body enhancements to efficient motor enhancements, our team delivers outstanding skill. Explore our site https://berginautobody.com/ to discover our options and kick off your machine’s transformation right away.
Calibry Casino http://calibri-casino-app.ru современное онлайн-казино с лицензией, щедрой бонусной системой и широким выбором игр. Участвуй в акциях, получай кэшбэк и выигрывай реальные деньги!
найти это [url=https://kentcasino.io]casino r7 игровые автоматы[/url]
интернет провайдер екатеринбург
domashij-internet-ekaterinburg003.ru
подключить проводной интернет екатеринбург
что такое 1win [url=http://1win6054.ru/]http://1win6054.ru/[/url] .
1win играть [url=http://1win6006.ru]1win играть[/url] .
essay pro https://santaspantry.org/ professional essay writing
1win betting [url=https://1win13.com.ng/]1win betting[/url] .
1win кыргызстан [url=https://1win6043.ru]https://1win6043.ru[/url] .
mostbet скачать на телефон бесплатно андроид [url=www.mostbet6033.ru]mostbet скачать на телефон бесплатно андроид[/url] .
1winn [url=http://cah.forum24.ru/?1-13-0-00001695-000-0-0-1743258917/]http://cah.forum24.ru/?1-13-0-00001695-000-0-0-1743258917/[/url] .
have a peek at this site [url=https://them-rril-lynch.net/]merrill lynch login[/url]
мотбет [url=mostbet6033.ru]mostbet6033.ru[/url] .
провайдеры домашнего интернета казань
domashij-internet-kazan001.ru
провайдер по адресу
1 win казино [url=http://1win6043.ru/]http://1win6043.ru/[/url] .
казино 1win [url=http://1win6006.ru/]http://1win6006.ru/[/url] .
Elara Finance is transforming decentralized lending by offering secure, transparent, and flexible crypto loan solutions. Built on blockchain technology, Elara Finance enables users to borrow and lend digital assets seamlessly without intermediaries. With low-interest rates, automated smart contracts, and a permissionless DeFi environment, Elara Finance is making crypto lending accessible and profitable for investors worldwide. https://elara.ink
безопасная сделка аккаунтов https://marketpleys-akkauntov-socsetei.ru/
покупка аккаунтов http://prodaja-akkauntov.ru
магазин аккаунтов маркетплейс аккаунтов
1win.pro [url=https://1win5011.ru]https://1win5011.ru[/url] .
какие провайдеры на адресе в казани
domashij-internet-kazan002.ru
провайдеры интернета в казани по адресу
1win casino online [url=https://1win1001.top]1win casino online[/url] .
Exponent Finance is redefining DeFi lending by providing secure, transparent, and high-yield investment solutions. Through smart contract-powered lending pools, Exponent Finance DeFi platform allows users to borrow and lend crypto assets with optimal efficiency and minimal risk. Whether you’re looking to earn passive income through staking or access instant liquidity, Exponent Finance offers a decentralized, non-custodial, and user-friendly solution to meet all your financial goals in the crypto ecosystem. https://exponent.ink
один вин [url=https://1win6042.ru/]https://1win6042.ru/[/url] .
Имморталы CS2 https://cs-open-case.ru редкие скины, которые выделят тебя в матче. Торгуй, покупай, продавай топовые предметы с моментальной доставкой в инвентарь. Лучшие цены и безопасные сделки!
Топ-дроп CS2 open-case-cs2.ru/ уже здесь! Самые редкие скины, ножи и эксклюзивы, которые действительно выпадают. Лучшие кейсы, обновления коллекций и советы для удачного открытия.
Премиум скины для CS2 case cs open ru выделяйся в каждом раунде! Редкое оружие, эксклюзивные коллекции, эффектные раскраски и ножи. Только топовые предметы с мгновенной доставкой в Steam.
casino en 1 win [url=https://1win1001.top]https://1win1001.top[/url] .
интернет провайдеры в казани по адресу дома
domashij-internet-kazan003.ru
какие провайдеры на адресе в казани
mostbest [url=www.mostbet6032.ru]www.mostbet6032.ru[/url] .
1win bet deposit [url=www.1win14.com.ng]www.1win14.com.ng[/url] .
Nucleus Earn is revolutionizing DeFi staking and passive income generation by offering secure, high-yield crypto rewards. With smart contract-powered staking pools, Nucleus Earn allows users to earn rewards effortlessly while maintaining full control over their assets. Whether you’re a beginner or an experienced investor, Nucleus Earn’s decentralized staking platform ensures transparency, security, and optimal returns in the fast-growing world of DeFi. https://nucleusearn.org
Kyros Finance is redefining the DeFi investment landscape by offering secure, scalable, and high-yield crypto solutions. With a focus on decentralized financial tools, Kyros Finance provides users with staking, lending, and automated yield farming strategies to maximize returns. Whether you’re a retail investor or an institutional participant, Kyros Finance ensures efficient, transparent, and secure access to the world of decentralized finance. https://kyros.ink
Noon Capital is revolutionizing real estate crowdfunding by offering secure, decentralized, and high-yield investment opportunities. Through blockchain-powered property financing, Noon Capital investment platform allows investors to participate in fractional real estate ownership, earn passive income, and diversify their portfolios with full transparency and security. Whether you’re an institutional investor or an individual seeking real estate-backed DeFi solutions, Noon Capital provides a seamless and profitable investment experience. https://noon.ad
jocuri de noroc online moldova [url=http://1win5011.ru/]http://1win5011.ru/[/url] .
1win sportsbook [url=https://1win14.com.ng/]https://1win14.com.ng/[/url] .
отзывы о банкротстве [url=https://bankrotstvo-v-moskve95.ru]отзывы о банкротстве[/url] .
1win сайт вход [url=http://1win6042.ru/]http://1win6042.ru/[/url] .
Онлайн лицей от школы Skysmart
https://vpenze.ru/news/udobstvo-izucheniya-slov-i-fraz-na-anglijskom-o-knigah-kak-sdelat-chtenie-eshe-bolee-uvlekatelnym/
1win казино [url=http://1win6043.ru]http://1win6043.ru[/url] .
mostbest [url=http://mostbet6033.ru/]http://mostbet6033.ru/[/url] .
1win официальный сайт вход [url=https://cah.forum24.ru/?1-13-0-00001678-000-0-0]1win официальный сайт вход[/url] .
aviator mostbet [url=https://www.mostbet6031.ru]https://www.mostbet6031.ru[/url] .
write essay online https://aypcl.org/ writing a college paper
узнать интернет по адресу
domashij-internet-msk001.ru
провайдеры по адресу
Лучшие скины CS2 open-csgo-case яркие, редкие, премиальные. Собери коллекцию, прокачай инвентарь и покажи всем свой вкус. Обзор самых крутых скинов с актуальными ценами и рейтингами.
1win moldova [url=1win5011.ru]1win5011.ru[/url] .
Топовые скины CS2 open-case-cs от легендарных ножей до эксклюзивных обложек на AWP. Красота, стиль, престиж. Оцени крутой дроп и подбери скин, который подходит именно тебе.
Топовые скины CS2 csgo-open-case.ru от легендарных ножей до эксклюзивных обложек на AWP. Красота, стиль, престиж. Оцени крутой дроп и подбери скин, который подходит именно тебе.
mostber [url=www.mostbet6032.ru]mostber[/url] .
1win casino online [url=1win1001.top]1win1001.top[/url] .
UnagiSwap is a cutting-edge decentralized exchange (DEX) that provides fast, secure, and transparent crypto trading. Designed for traders looking to swap digital assets efficiently without intermediaries, UnagiSwap offers low fees, deep liquidity, and seamless smart contract execution. Whether you’re a casual trader or a professional investor, UnagiSwap’s non-custodial platform ensures full control over your assets in a decentralized environment. https://unagiswap.org
1win.com [url=http://1win5012.ru/]http://1win5012.ru/[/url] .
скачать мостбет [url=https://mostbet6031.ru/]https://mostbet6031.ru/[/url] .
мрстбет [url=https://eisberg.forum24.ru/?1-5-0-00002579-000-0-0-1743260427]https://eisberg.forum24.ru/?1-5-0-00002579-000-0-0-1743260427[/url] .
1вин [url=https://1win6042.ru/]https://1win6042.ru/[/url] .
1 win официальный сайт [url=http://1win6043.ru/]1 win официальный сайт[/url] .
aviator mostbet [url=https://www.mostbet6033.ru]https://www.mostbet6033.ru[/url] .
дешевый интернет москва
domashij-internet-msk002.ru
провайдеры интернета по адресу москва
1win moldova [url=https://1win5012.ru/]https://1win5012.ru/[/url] .
Смотри топ скинов CS2 http://cs2-open-case.ru самые красивые, редкие и желанные облики для оружия. Стиль, эффект и внимание на сервере гарантированы. Обновляем коллекцию каждый день!
Иммортал-дроп CS2 https://open-case-csgo.ru только для избранных. Легендарные скины, высокая ценность, редкие флоаты и престиж на сервере. Пополни свою коллекцию настоящими шедеврами.
Смотри топ скинов CS2 case-cs2-open.ru самые красивые, редкие и желанные облики для оружия. Стиль, эффект и внимание на сервере гарантированы. Обновляем коллекцию каждый день!
мостбет официальный сайт [url=https://mostbet6032.ru]https://mostbet6032.ru[/url] .
1 win [url=http://1win6007.ru/]http://1win6007.ru/[/url] .
служба поддержки мостбет номер телефона [url=http://mostbet6011.ru/]http://mostbet6011.ru/[/url] .
1win pariuri [url=https://www.1win5011.ru]https://www.1win5011.ru[/url] .
игра 1вин [url=https://www.sebezh.borda.ru/?1-10-0-00000117-000-0-0-1743052058]https://www.sebezh.borda.ru/?1-10-0-00000117-000-0-0-1743052058[/url] .
Быстрый и удобный калькулятор монолитной плиты фундамента рассчитайте стоимость и объем работ за пару минут. Онлайн-калькулятор поможет спланировать бюджет, сравнить варианты и избежать лишних затрат.
Мамоновское кладбище https://mamonovskoe.ru справочная информация, адрес, график работы, участки, ритуальные услуги и памятники. Всё, что нужно знать, собрано на одном сайте.
1win ru [url=1win6007.ru]1win6007.ru[/url] .
краснодар последние новости события krasnodar-news35.ru/
мостбет мобильная версия скачать [url=https://www.mostbet6011.ru]https://www.mostbet6011.ru[/url] .
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
интернет домашний москва
domashij-internet-msk003.ru
какие провайдеры интернета есть по адресу москва
мосбет [url=http://mostbet6031.ru/]http://mostbet6031.ru/[/url] .
микронаушник Чехия http://czmicro.cz
микронаушник купить jasdam.cz
1win online site [url=1win14.com.ng]1win14.com.ng[/url] .
1вин официальный [url=http://1win6043.ru]http://1win6043.ru[/url] .
мостюет [url=https://mostbet6033.ru/]https://mostbet6033.ru/[/url] .
интернет по адресу дома
domashij-internet-nizhnij-novgorod001.ru
интернет провайдеры по адресу дома
1wiun [url=https://1win6043.ru]https://1win6043.ru[/url] .
мостбет кг [url=https://www.mostbet6033.ru]https://www.mostbet6033.ru[/url] .
cazinouri online moldova [url=www.1win5011.ru]www.1win5011.ru[/url] .
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at http://aquasculpt.one and sculpt your dream body today!
1вин про [url=https://www.1win6043.ru]https://www.1win6043.ru[/url] .
Выбор будущей профессии
https://unews.pro/news/142125/
домашний интернет
domashij-internet-nizhnij-novgorod002.ru
провайдер по адресу
1win kg [url=https://1win6044.ru]https://1win6044.ru[/url] .
mostbet kg отзывы [url=https://mostbet6033.ru/]https://mostbet6033.ru/[/url] .
Обеспечь анонимность с https://amneziavpn.xyz. Защита трафика, собственный сервер, простая установка и отсутствие слежки. Отличный выбор для тех, кто ценит свободу в интернете.
mikro sluchatko nanosondy
Ищете безопасный VPN? Попробуйте amneziavpn.org — open-source решение для анонимности и свободы в интернете. Полный контроль над соединением и личными данными.
mostbet скачать на телефон бесплатно андроид [url=https://mostbet6012.ru]https://mostbet6012.ru[/url] .
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at http://aquasculpt.lifestyle !
мостбет вход [url=https://mostbet6012.ru/]https://mostbet6012.ru/[/url] .
1 win официальный сайт вход [url=https://www.1win6044.ru]https://www.1win6044.ru[/url] .
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at http://aquasculpt.lifestyle and sculpt your dream body today!
лучший интернет провайдер нижний новгород
domashij-internet-nizhnij-novgorod003.ru
провайдеры по адресу нижний новгород
spionazni kamera minikamera
Сантехник Юго-Восточный https://santekhnik-moskva.blogspot.com/p/south-eastern-administrative-okrug-of.html административный округ Москвы (ЮВАО). В состав Юго-Восточного административного округа входят районы: Выхино-Жулебино, Капотня, Кузьминки, Лефортово, Люблино, Марьино, Некрасовка, Нижегородский район, Печатники, Рязанский район, Текстильщики, Южнопортовый район.
Чеки для отчётности https://t.me/kupitchekiru в Москве — быстро, конфиденциально и с гарантией. Подтверждающие документы для отчёта, бухгалтерии, авансовых отчётов. Оперативная подготовка и доставка.
sports betting 1win [url=https://1win14.com.ng/]sports betting 1win[/url] .
1 win [url=http://1win6007.ru]http://1win6007.ru[/url] .
mosbet [url=mostbet6011.ru]mostbet6011.ru[/url] .
1win ru [url=https://1win6009.ru/]https://1win6009.ru/[/url] .
1win sports [url=https://www.1win15.com.ng]https://www.1win15.com.ng[/url] .
интернет провайдеры в новосибирске по адресу дома
domashij-internet-novosibirsk001.ru
провайдеры домашнего интернета новосибирск
Για αξιόπιστο διαδικτυακό καζίνο στην Ελλάδα, δοκιμάστε Kingmaker Casino Greece που εμπιστεύονται χιλιάδες Έλληνες παίκτες.
cazino md [url=www.1win5012.ru]www.1win5012.ru[/url] .
Премиум скины CS2 http://cs2-case-simulator.ru топовые облики для AWP, AK-47, M4, ножей и перчаток. Яркий стиль, редкие коллекции, эксклюзивные дизайны. Укрась свою игру и выделяйся в каждой катке!
Хочешь Dragon Lore https://cs-case-simulator.ru Открывай кейс прямо сейчас — шанс на легенду CS2 может стать реальностью. Лучшие скины ждут тебя, рискни и получи топовый дроп!
1win betting [url=www.1win15.com.ng]www.1win15.com.ng[/url] .
Glock-18 Fade https://case-simulator-csgo.ru один из самых ярких и редких скинов для стартового пистолета в CS2. Плавный градиент, премиум-качество и высокий спрос среди коллекционеров.
mostbets [url=https://mostbet6011.ru]https://mostbet6011.ru[/url] .
http://antenka-tv.ru/
какие провайдеры по адресу
domashij-internet-novosibirsk002.ru
проверить провайдеров по адресу новосибирск
StatTrak AK-47 Vulcan get-skin-cs2.ru мощный стиль и счётчик убийств в одном скине. Агрессивный дизайн, сине-чёрная цветовая гамма и высокая ценность на рынке CS2. Идеальный выбор для бойца с характером!
1win kg [url=https://1win6009.ru/]https://1win6009.ru/[/url] .
M4A4 Emperor http://get-skin-cs.ru эффектный скин в стиле королевской власти. Яркий синий фон, золотые детали и образ императора делают этот скин настоящим украшением инвентаря в CS2.
AK-47 Case Hardened https://get-skins-cs2.ru классика CS2 с уникальным закалённым узором. Каждый скин отличается: от редких фулл-блю до золотых комбинаций. Настоящая находка для коллекционера и трейдера.
1win играть [url=http://1win6009.ru]1win играть[/url] .
Микрозайм на карту без проверок деньги в долг на карту срочно без проверки кредитной истории
Микрозаймы онлайн оформить микрозайм онлайн
1вин приложение [url=http://1win6043.ru/]http://1win6043.ru/[/url] .
Запишитесь на курсы для массажистов и прокачайте свою профессию. Современные методики, опытные преподаватели, доступная цена и максимальная польза для практики.
провайдеры домашнего интернета новосибирск
domashij-internet-novosibirsk003.ru
интернет провайдеры новосибирск
1win.com [url=http://1win5012.ru/]http://1win5012.ru/[/url] .
мостбет официальный сайт [url=https://mostbet6011.ru/]мостбет официальный сайт[/url] .
1wi. [url=1win6043.ru]1win6043.ru[/url] .
Ανακαλύψτε το Kingmaker Casino στην Ελλάδα! επίσημο Kingmaker Casino εγγυάται ασφάλεια και αξιοπιστία για τους Έλληνες παίκτες.
подключить домашний интернет санкт-петербург
domashij-internet-spb001.ru
провайдер по адресу
скачат мостбет [url=http://mostbet6033.ru/]http://mostbet6033.ru/[/url] .
ванвин [url=http://1win6009.ru]http://1win6009.ru[/url] .
Hey there! If this message caught your attention, you’re probably seeking strategies to enhance your online presence. I understand — mastering SEO might seem intimidating, especially with so many “miracle” solutions out there claiming guaranteed results that rarely materialize. That’s why I want to share my approach with you. It’s not just another one-size-fits-all package — it’s a personalized strategy designed to deliver real, measurable results.
I specialize in building link pyramids that combine Tier 1, Tier 2, and Tier 3 backlinks. Think of it like constructing a strong foundation for your house. Without proper groundwork, progress collapses. My goal is to drive authority straight to your money site in a way that aligns with search engine algorithms and actually works.
The Proof Is in the Results
I’ll cut to the chase: I’ve been in the digital marketing field for years, and I’ve experienced the full spectrum — successful strategies and outright scams. I’ve worked with clients who invested heavily on services that promised “guaranteed rankings” but caused ranking drops. That’s why I decided to do things differently.
I focus on high-quality, dofollow backlinks from reputable sources. More than four-fifths of primary-tier connections in my strategy are dofollow because they offer maximum SEO value. And here’s the kicker — you’ll get this top-tier offering at significantly reduced rates (costing just 200–350 USD). What’s the point of overpaying? Protect your budget ?? in something that actually works.
What Makes My Approach Different?
High Authority Guest Posts
I avoid low-quality directories. Absolutely not. I carefully select only the authoritative domains — websites Google prioritizes. These are the kinds of sites that give your website a serious boost.
Unique, Handwritten Content
Low-quality writing harms credibility. It’s boring, unnatural, and frankly, a waste of time. That’s why every article I create is 100% unique, compelling, and tailored to your niche. Whether it’s for Web 2.0 properties, I guarantee originality reports that supports your strategy organically. Pure quality, zero filler — content that converts.
Pyramid-Structured Backlinks
Here’s where things get strategic. My method goes beyond basics by incorporating Tier 2 and Tier 3 support links. This multi-phase strategy strengthens the effect of your primary backlinks, driving long-term success for your money site. Imagine an avalanche effect, compounding over time.
Varied Backlink Portfolio
Search engines reward variety, so I incorporate diverse high-authority sources: content hubs, document shares, social signals. This isn’t about exploiting loopholes; it’s about establishing long-term authority.
No Hidden Agendas
When you work with me, you’ll have full visibility. I provide a thorough documentation, including login details for all Web 2.0 properties. Clear communication, no surprises. You’ll know exactly where your links are coming from and their impact on rankings.
A Little Story from My Experience
Let me share something personal: A few years ago, I worked with a client who was frustrated because their website wasn’t ranking despite prior investments. They’d tried multiple agencies, but results were elusive. When they came to me, I crafted a custom plan. A personalized approach was implemented. Within a few months, their traffic doubled, and they started seeing real conversions. That’s the kind of outcome you can expect with every client.
Let’s build your path to the top Contact me now and let’s make Google work for you. ??
подключить интернет
domashij-internet-spb002.ru
провайдеры интернета в санкт-петербурге
additional resources https://cwap.us/
1win скачать kg [url=1win6010.ru]1win скачать kg[/url] .
скачать мостбет официальный сайт [url=www.mostbet6034.ru]www.mostbet6034.ru[/url] .
1win nigeria [url=https://www.1win15.com.ng]1win nigeria[/url] .
1win кыргызстан [url=https://1win6043.ru/]https://1win6043.ru/[/url] .
thc gummies in prague thc chocolate for sale in prague
most bet [url=mostbet6034.ru]mostbet6034.ru[/url] .
1win aplicația [url=www.1win5013.ru]www.1win5013.ru[/url] .
скачать mostbet на телефон [url=www.mostbet6012.ru]www.mostbet6012.ru[/url] .
мостбет промокод [url=https://www.mostbet6033.ru]https://www.mostbet6033.ru[/url] .
провайдеры домашнего интернета санкт-петербург
domashij-internet-spb003.ru
подключить интернет
игра ракета на деньги 1win [url=https://1win6010.ru]https://1win6010.ru[/url] .
Είμαι ενθουσιασμένος να σας παρουσιάσω το Nomini Casino στην Ελλάδα. Επισκεφθείτε το αξιόπιστο Nomini Casino για να εξερευνήσετε τα καλύτερα καζίνο παιχνίδια.
Desert Eagle Blaze csgo-get-skins пламя в каждой пуле. Легенда CS:GO. Продажа, обмен, проверка скина. Успей забрать по лучшей цене на рынке.
portofele electronice casino [url=www.1win5013.ru]www.1win5013.ru[/url] .
M4A1-S Knight http://cs-get-skins.ru редкий скин в CS. Престиж, стиль, легендарное оружие. Продажа по выгодной цене, моментальная доставка, безопасная сделка.
1win azərbaycan saytında müxtəlif idman növlərinə mərc edə bilərsiniz | 1win-də müxtəlif ödəniş metodları ilə rahatlıqla pul çıxara bilərsiniz | 1win-də müxtəlif idman növlərinə mərc etmək imkanı var | 1win kazino oyunlarında yüksək qazanma şansı əldə edin1win-də müxtəlif idman tədbirlərinə mərc edin | 1win kazino oyunlarında müxtəlif bonuslar əldə edin1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur | 1win mobil tətbiqi ilə istənilən yerdə oyun oynayın | 1win az saytında istifadəçilər üçün rahat interfeys mövcuddur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın [url=https://1wincasino-azn.com/]1 win qeydiyyat[/url].
1win mobil tətbiqi ilə hər yerdə oyun oynamaq mümkündür | 1win platformasında yeni başlayanlar üçün təlimatlar mövcuddur | 1win azərbaycan saytında istifadəçilər üçün rahat naviqasiya mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur | 1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur | 1win-də müxtəlif idman tədbirlərinə mərc edin | 1win-də müxtəlif idman növlərinə mərc edin | 1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win az saytında müxtəlif promosyonlar mövcuddur [url=https://1wincasino-azn.com/]1win kazinoda oyna[/url].
Continued https://datadex.ink/
Θέλετε να μάθετε περισσότερα για το καζίνο Casinoly ; Ανακαλύψτε τα πάντα για αυτό το διαδικτυακό καζίνο
ai porn chat best ai porn
Используй нвдежный http://amnezia.xyz для обхода блокировок, сохранности личных данных и полной свободы онлайн. Всё включено — просто подключайся.
Оснащение под ключ: продажа медицинского оборудования с сертификацией и полной документацией. В наличии и под заказ. Профессиональное оснащение медицинских кабинетов.
1win-də təqdim olunan bonuslar çox cəlbedicidir | 1win mobil tətbiqi Android və iOS üçün əlçatandır | 1win azərbaycan platformasında müxtəlif slot oyunları mövcuddur | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur1win mobil tətbiqi ilə oyun təcrübəsini artırın | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın1win-də müxtəlif idman növlərinə mərc edin | 1win az saytında istifadəçilər üçün rahat interfeys mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın [url=https://1wincasino-azn.com/]1 win azerbaycan[/url].
1vin [url=www.1win6009.ru]www.1win6009.ru[/url] .
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Выяснить больше – https://mednarkoforum.ru/
1win azərbaycan saytında müxtəlif idman növlərinə mərc edə bilərsiniz | 1win kazino oyunları arasında Aviator xüsusi yer tutur | 1win platformasında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win az saytında istifadəçilər üçün rahat interfeys mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur [url=https://1wincasino-azn.com/]https://1wincasino-azn.com/[/url].
Технологии свободы: http://marzban.click надёжный инструмент для приватности, скорости и доступа к любым сайтам. Быстро, безопасно, удобно — настрой за 5 минут.
Παίξτε στο BoaBoa Casino για μια συναρπαστική εμπειρία παιχνιδιού στην Ελλάδα
Витебский госуниверситет университет https://vsu.by/inostrannym-abiturientam/spetsialnosti.html П.М.Машерова – образовательный центр. Вуз является ведущим образовательным, научным и культурным центром Витебской области. ВГУ осуществляет подготовку: химия, биология, история, физика, программирование, педагогика, психология, математика.
1win azərbaycan saytında müxtəlif idman növlərinə mərc edə bilərsiniz | 1win azərbaycan saytında 24/7 müştəri dəstəyi mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur1win kazino oyunlarında yüksək qazanma şansı əldə edin | 1win-də müxtəlif idman növlərinə mərc edin1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur | 1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur | 1win azərbaycan platformasında istifadəçilər üçün müxtəlif oyun imkanları mövcuddur [url=https://1wincasino-azn.com/]1win apk yüklə[/url].
купить чеки для отчетов https://dzen.ru/a/Z_kGwEnhIQCzDHyh
Научитесь вязать крючком https://crochet-patterns.ru с нуля или улучшите навыки с нашими подробными мастер-классами. Фото- и видеоуроки, понятные инструкции, схемы для одежды, игрушек и интерьера. Вдохновляйтесь, творите, вяжите в своё удовольствие! Вязание крючком — доступно, красиво, уютно.
mostbets [url=http://mostbet6012.ru/]http://mostbet6012.ru/[/url] .
1win-də qeydiyyatdan keçərək geniş oyun imkanlarından yararlanın | 1win kazino oyunlarında yüksək RTP dərəcələri mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win az saytında müxtəlif ödəniş üsulları mövcuddur1win mobil tətbiqi ilə oyun təcrübəsini artırın | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur | 1win kazino oyunlarında yüksək qazanma şansı əldə edin | 1win az saytında müxtəlif promosyonlar mövcuddur | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur | 1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur [url=https://1wincasino-azn.com/]casino 1win[/url].
Нож-бабочка Doppler https://cs-get-skin.ru стильное и эффектное оружие в стиле CS:GO. Яркий металлический блеск, плавный механизм, удобство в флиппинге и коллекционировании. Подходит для тренировок, трюков и подарка фанатам игр.
1win az platformasında təhlükəsiz və sürətli ödəniş üsulları mövcuddur | 1win azərbaycan saytında 24/7 müştəri dəstəyi mövcuddur | 1win-də müxtəlif idman növlərinə mərc etmək imkanı var | 1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur1win azərbaycan platformasında istifadəçilər üçün müxtəlif oyun imkanları mövcuddur | 1win kazino oyunlarında yüksək qazanma şansı əldə edin | 1win azərbaycan platformasında istifadəçilər üçün müxtəlif oyun imkanları mövcuddur | 1win az saytında müxtəlif ödəniş üsulları mövcuddur | 1win-də müxtəlif idman növlərinə mərc edin [url=https://1wincasino-azn.com/]1win qeydiyyat bonusu[/url].
mostbet kg [url=https://mostbet6012.ru]https://mostbet6012.ru[/url] .
1win azerbaycan saytında istifadəçi dostu interfeys mövcuddur | 1win-də müxtəlif ödəniş metodları ilə rahatlıqla pul çıxara bilərsiniz | 1win kazino oyunlarında müxtəlif bonuslar əldə edin | 1win-də müxtəlif idman tədbirlərinə mərc edin1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win azərbaycan platformasında istifadəçilər üçün müxtəlif oyun imkanları mövcuddur1win az saytında müxtəlif promosyonlar mövcuddur | 1win kazino oyunlarında yüksək qazanma şansı əldə edin | 1win-də müxtəlif idman növlərinə mərc edin | 1win az saytında müxtəlif ödəniş üsulları mövcuddur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın [url=https://1wincasino-azn.com/]1win kazinoda oyna[/url].
1win azerbaycan saytında istifadəçi dostu interfeys mövcuddur | 1win azərbaycan saytında 24/7 müştəri dəstəyi mövcuddur | 1win azərbaycan platformasında müxtəlif slot oyunları mövcuddur | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur1win kazino oyunlarında yüksək qazanma şansı əldə edin | 1win platformasında istifadəçilər üçün müxtəlif kampaniyalar mövcuddur1win kazino oyunlarında müxtəlif bonuslar əldə edin | 1win mobil tətbiqi ilə oyun təcrübəsini artırın | 1win mobil tətbiqi ilə istənilən yerdə oyun oynayın | 1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win mobil tətbiqi ilə istənilən yerdə oyun oynayın [url=https://1wincasino-azn.com/]1 win azerbaycan[/url].
1win azərbaycan saytında müxtəlif idman növlərinə mərc edə bilərsiniz | 1win az saytında qeydiyyat üçün xüsusi promokodlar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win mobil tətbiqi ilə oyun təcrübəsini artırın1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın1win mobil tətbiqi ilə istənilən yerdə oyun oynayın | 1win az saytında müxtəlif ödəniş üsulları mövcuddur | 1win az saytında müxtəlif promosyonlar mövcuddur | 1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win mobil tətbiqi ilə istənilən yerdə oyun oynayın [url=https://1wincasino-azn.com/]1win az giriş[/url].
1win az platformasında təhlükəsiz və sürətli ödəniş üsulları mövcuddur | 1win-də müxtəlif ödəniş metodları ilə rahatlıqla pul çıxara bilərsiniz | 1win platformasında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif təkliflər mövcuddur1win az saytında müxtəlif ödəniş üsulları mövcuddur | 1win az saytında müxtəlif promosyonlar mövcuddur1win-də müxtəlif idman növlərinə mərc edin | 1win az saytında istifadəçilər üçün rahat interfeys mövcuddur | 1win-də müxtəlif ödəniş üsulları ilə rahatlıqla pul yatırın | 1win mobil tətbiqi ilə oyun təcrübəsini artırın | 1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur [url=https://1wincasino-azn.com/]https://1wincasino-azn.com/[/url].
1win-də qeydiyyatdan keçərək geniş oyun imkanlarından yararlanın | 1win kazino oyunları arasında Aviator xüsusi yer tutur | 1win mobil tətbiqi ilə istənilən yerdə mərc edin | 1win azərbaycan saytında müxtəlif oyun növləri mövcuddur1win azərbaycan saytında müxtəlif oyun növləri mövcuddur | 1win-də müxtəlif idman növlərinə mərc edin1win mobil tətbiqi ilə istənilən yerdə oyun oynayın | 1win kazino oyunlarında müxtəlif jackpotlar mövcuddur | 1win azərbaycan saytında istifadəçilər üçün müxtəlif təlimatlar mövcuddur | 1win platformasında istifadəçilər üçün müxtəlif bonuslar təqdim olunur | 1win-də müxtəlif idman növlərinə mərc edin [url=https://1wincasino-azn.com/]1win kazinoda oyna[/url].
Быстровозводимые здания https://akkord-stroy.ru из металлоконструкций — это скорость, надёжность и экономия. Рассказываем в статьях, как построить объект под ключ: от проектирования до сдачи в эксплуатацию.
Недвижимость в Бяла https://byalahome.ru апартаменты, квартиры и дома у моря в Болгарии. Лучшие предложения на побережье Черного моря — для жизни, отдыха или инвестиций. Успейте купить по выгодной цене!
Скин AWP Graphite csgo-case-simulator.ru/ из CS:GO — чёрный глянец, премиальный стиль и высокая редкость. Укрась арсенал культовой снайперской винтовкой и выделяйся на сервере с первого выстрела.
1win кейсы [url=http://1win6046.ru/]http://1win6046.ru/[/url] .
AK-47 Fire Serpent get-skins-cs легендарный скин из коллекции Operation Bravo. Яркий рисунок огненного змея, высокая редкость и коллекционная ценность. Идеальный выбор для истинных фанатов CS:GO.
Online Casino “Know This”: Secure, Rapid, and User-Centric**
Straight to the point: what matters most to players.*
—
Why Gamblers Choose It
– Licensed & Fair: Approved under strict EU standards. Decentralized tech verifies all results.
– Lightning Payouts: Crypto transactions in seconds, traditional payments processed within 24 hours.
Standout Features
– Exclusive Titles: Evolution’s Lightning Roulette, Crypto Quest slots (exclusive).
– Generous Bonuses: Welcome bonus: 200 spins on Starburst, monthly cashback for loyal players.
—
Play Anywhere
Instant-play mode, tailored alerts for big wins, and a sleek, intuitive app.
Real Player Reviews**
– “Cashed out $4k in 2 hours—zero hassle.”* – Sarah
– “The team knew my account history. 10/10.”* – a loyal member
Stay in Control
– Live Support Always: No bots—real agents.
– Self-Regulation Tools**: Deposit caps and cool-off periods.
Begin Your Journey
Register quickly, use code **KNOWTHIS** for free spins.
P.S. Gamble wisely. Set a budget—always.
see here [url=https://jaxxblog.io/]jaxx liberty login[/url]
1win кейсы [url=https://1win6047.ru/]https://1win6047.ru/[/url] .
1вин вход с компьютера [url=https://1win6047.ru/]https://1win6047.ru/[/url] .
1win вход в личный кабинет [url=https://www.1win6046.ru]https://www.1win6046.ru[/url] .
https://www.cornbreadhemp.com/products/blood-orange-thc-gummies-10mg secure scout’s honour helped me manage mundane suffering without making me note out of it. I explosion an individual in the evening after feat, and within 30 minutes, I’m personality more relaxed. It’s like a dwarf perceptual reset. They taste like legal sweets but take place with all the calming benefits of CBD. I was a morsel unsure at foremost, but in this day I guard a offend in my cookhouse at all times. If you’re dealing with desire, importance, or righteous necessity to unwind, these are a full lifesaver. Condign clear sure you’re getting them from a trusted trade name!
Скин M4A4 Howl cs2-get-skins.ru/ один из самых дорогих и загадочных в CS:GO. Запрещённый артефакт с историей. Рассказываем о его происхождении, внешнем виде и значении в мире скинов.
Перчатки спецназа case-simulator-cs.ru/ тактический скин в CS:GO с брутальным дизайном и премиальной редкостью. Узнайте об их разновидностях, цене, коллекционной ценности и лучших сочетаниях с другими скинами.
StatTrak M4A1-S https://cs2-get-skin.ru скин с возможностью отслеживания фрагов прямо на корпусе оружия. Узнайте, какие модели доступны, чем отличаются, и какие из них ценятся выше всего на рынке CS:GO.
Легендарная AWP Medusa https://case-simulator-cs2.ru/ скин с таинственным дизайном, вдохновлённым древнегреческой мифологией. Высокая редкость, художественная детализация и престиж на каждом сервере.
AWP Dragon Lore get skins csgo легендарный скин с изображением дракона, символ элиты в CS:GO. Узнайте о его происхождении, редкости, стоимости и почему он стал мечтой каждого коллекционера.
Обзор AK-47 Redline csgo-get-skin лаконичный дизайн, спортивный стиль и привлекательная цена. Почему этот скин так любят игроки и с чем он лучше всего сочетается — читайте у нас.
Обзор AWP Asiimov https://get-skin-csgo.ru/ футуристичный скин с дерзким дизайном. Рассказываем о редкости, ценах, вариантах износа и том, почему Asiimov стал иконой среди скинов в CS:GO.
Онлайн-казино Shot shot-casino-apk.ru/ предлагает щедрые бонусы, турнирные события и топовые слоты. Узнайте об условиях игры, уровне доверия, лицензии и особенностях платформы в нашем свежем обзоре.
Нужно создание или разработка разработка сайтов в Москве: адаптивный дизайн, SEO-продвижение, техническая поддержка. Эффективное ключевая фраза для вашего бизнеса — привлечение клиентов и рост прибыли.
Обзор онлайн-казино Shot https://shot-casino-app.ru плюсы и минусы, проверка лицензии, акции и фриспины. Рассказываем, стоит ли играть, как получить бонусы и выводить выигрыши без проблем.
Shot Casino shot-casino-online.ru новое онлайн-казино с лицензией, защитой данных и большим выбором игр. В обзоре: безопасность, отзывы игроков, бонусы и выплаты. Надёжная площадка для вашего азарта.
Онлайн-казино Calibry calibri-casino-online.ru новое игровое пространство с лицензией, щедрыми бонусами и широким выбором слотов. Читайте обзор: особенности платформы, условия игры, отзывы и выплаты.
1вин кг [url=http://1win6047.ru]http://1win6047.ru[/url] .
Нужен бесплатный аккаунт? бесплатные аккаунты в стим Узнайте, где можно получить рабочие логины с играми, как не попасть на фейк и на что обратить внимание при использовании таких аккаунтов.
Онлайн-казино Aura aura-casino-apk.ru/ лицензия, быстрые выплаты, слоты от топ-провайдеров и щедрые бонусы. Подробный обзор платформы: интерфейс, регистрация, акции, безопасность и отзывы игроков.
Начните с Aura Casino http://aura-casino-bonus.ru удобное онлайн-казино с простым интерфейсом, стартовыми бонусами и быстрой регистрацией. Рассказываем, как получить фриспины и не потеряться в слотах.
Онлайн-казино Calibry https://calibri-casino-play.ru бонусы без депозита, быстрые выводы и лицензированный софт. В обзоре: как начать играть, получить фриспины, использовать акции и избежать рисков.
Обзор онлайн-казино Calibry calibri casino app как получить бонус без депозита, запустить любимые слоты и вывести выигрыш. Надёжная площадка с лицензией и прозрачными условиями игры.
Играйте в казино Shot https://shot-casino-play.ru десятки провайдеров, ежедневные турниры и кэшбэк. В обзоре: лучшие слоты, лайв-игры, бонусные программы и преимущества платформы.
Aura Casino https://aura-casino-online.ru безопасная платформа с лицензией, SSL-защитой и проверенной репутацией. В обзоре: честность выплат, работа службы поддержки и реальные отзывы игроков.
Обзор Aura Casino https://aura-casino-play.ru всё о щедрых бонусах, фриспинах, кэшбэке и акциях. Расскажем, как зарегистрироваться, начать игру и получить максимум от каждого депозита.
Calibry Casino https://calibri-casino-bonus.ru лицензированное онлайн-казино с бонусами, быстрым выводом и большим выбором игр. В обзоре: регистрация, акции, безопасность, отзывы игроков и советы новичкам.
Онлайн-казино Aura https://aura-casino-app.ru лицензия, бонус без депозита, фриспины за регистрацию и моментальный вывод. Всё о казино Aura в одном обзоре — играйте безопасно и с выгодой.
1win win [url=https://1win6047.ru/]https://1win6047.ru/[/url] .
Ищешь лучшие раскидки https://raskidki-granat-cs2.ru CS2 – Смоки, молотовы и флешки для всех карт — изучи тактики, прокачай игру и удиви соперников точными гранатами. Подборка эффективных раскидок!
Нужен надёжный хостинг? аренда vps для сайтов, приложений и бизнес-задач. Гибкая настройка, SSD-накопители, стабильная работа 24/7. Выберите тариф под свои задачи и начните сегодня.
Где купить http://kupit-cheki24.com чеки в Москве? У нас — быстрое оформление, оригинальные документы, курьерская доставка. Чеки для отчётов, подтверждения командировок и компенсаций.
Заказать диплом любого университета!
Мы предлагаем документы институтов, которые расположены в любом регионе РФ. Документы выпускаются на бумаге самого высшего качества: [url=http://freedomrp.getbb.ru/viewtopic.phpf=110&t=1632/]freedomrp.getbb.ru/viewtopic.phpf=110&t=1632[/url]
Витебский университет П.М.Машерова https://vsu.by образовательный центр. Вуз является ведущим образовательным, научным и культурным центром Витебской области.
Сайт предлагает кассовые чеки, которые принимают налоговые. | Помощь в срочной отчётности — действительно работает. | Есть поддержка, отвечают на вопросы по налогам. | Есть доставка в другие города. | Всё быстро и без лишней бюрократии. | Работают с разными системами налогообложения. | Есть возможность заказа с НДС или без. | Можно заказать чеки для разных сотрудников. | Подходит для бизнеса и личных целей. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки купить недорого для отчетности[/url].
read more https://web-sollet.com
Хорошее решение для закрытия командировок — готовые чеки. | Удобно: выбрал, оплатил, получил на почту. | Отчётность становится проще с такими сервисами. | Рекомендую, если не хотите лишних проблем. | Хорошая поддержка, помогут с выбором. | Работают с разными системами налогообложения. | Всё сделано чётко и понятно. | Отчётность больше не вызывает стресс. | Чеки для отчётности — удобно и просто. | Доверяю этому сервису не первый раз. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки купить недорого для отчетности[/url].
Купить диплом ВУЗа по невысокой стоимости вы можете, обратившись к проверенной специализированной фирме. Мы оказываем услуги по продаже документов об окончании любых ВУЗов Российской Федерации. Купить диплом о высшем образовании– [url=http://diplom-top.ru/kupit-diplom-o-visshem-obrazovanii-reestr-14/]diplom-top.ru/kupit-diplom-o-visshem-obrazovanii-reestr-14/[/url]
Хорошее решение для закрытия командировок — готовые чеки. | Доступные цены и быстрый отклик — отличный сервис. | Нужны чеки с подтверждением — рекомендую сюда. | Есть доставка в другие города. | Чеки проходят любой внутренний аудит. | Простой интерфейс сайта, удобно искать. | Всё сделано чётко и понятно. | Отчётность больше не вызывает стресс. | Работают и по предоплате, и по факту. | Доверяю этому сервису не первый раз. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]купить чеки для отчетности в москве[/url].
Сайт предлагает кассовые чеки, которые принимают налоговые. | Чеки с печатью, все реквизиты — всё как нужно. | Один из лучших сервисов по продаже чеков. | Хорошее соотношение цены и качества. | Чеки проходят любой внутренний аудит. | Подходит и для командировок, и для закупок. | Всё сделано чётко и понятно. | Можно выбрать из нескольких форматов. | Подходит для бизнеса и личных целей. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки для отчетности купить цена[/url] .
Заказать диплом о высшем образовании!
Заказать диплом института по невысокой стоимости возможно, обращаясь к проверенной специализированной фирме. Заказать диплом: [url=http://diplomers.com/kupite-nadezhnij-diplom-sejchas-proverennoe-kachestvo/]diplomers.com/kupite-nadezhnij-diplom-sejchas-proverennoe-kachestvo[/url]
Где заказать чеки для отчётности без лишней волокиты? | Можно выбрать чеки из разных городов. | Работают официально, чеки фискальные. | Хорошее соотношение цены и качества. | Актуальные и действующие чеки под отчёт. | Подходит и для командировок, и для закупок. | Есть примеры чеков на сайте. | Чеки всегда с актуальной датой. | Работают и по предоплате, и по факту. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]купить чеки с ндс[/url].
why not try this out https://web-lumiwallet.com
Сайт предлагает кассовые чеки, которые принимают налоговые. | Можно выбрать чеки из разных городов. | Можно указать сумму, категорию расходов, дату. | Можно заказать оптом для всего отдела. | Чеки проходят любой внутренний аудит. | Работают с разными системами налогообложения. | Для отчёта в налоговую — самое то. | Всё чётко: дата, сумма, организация. | Работают и по предоплате, и по факту. | Лучшее решение для занятых предпринимателей. [url=http://dzen.ru/a/Z_kGwEnhIQCzDHyh]http://dzen.ru/a/Z_kGwEnhIQCzDHyh[/url].
?Hola fanaticos del casino
Los juegos de casino sin licencia incluyen opciones innovadoras y proveedores poco conocidos. casinossinlicenciaenespana Esto aГ±ade variedad a tu experiencia de juego. Es perfecto para quienes buscan salir de lo tradicional.
Puedes apostar en casinos sin licencia desde tu mГіvil o tablet sin problemas. La mayorГa son compatibles con dispositivos Android e iOS. Verifica si tienen app o versiГіn optimizada.
Mas detalles en el enlace – п»їhttp://casinossinlicenciaenespana.guru
?Que tengas excelentes partidas!
pop over to these guys https://my-sollet.com
Сайт предлагает кассовые чеки, которые принимают налоговые. | Можно выбрать чеки из разных городов. | Есть поддержка, отвечают на вопросы по налогам. | Пользовался — всё прошло гладко и быстро. | Качественные чеки без подделок. | Работают с разными системами налогообложения. | Чеки подходят под любые виды деятельности. | Можно выбрать из нескольких форматов. | Полностью соответствуют требованиям законодательства. | Доверяю этому сервису не первый раз. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]www.dzen.ru/a/Z_kGwEnhIQCzDHyh[/url].
Клиника «Формула Трезвости» в Москве – это передовые методики лечения зависимостей, квалифицированные специалисты и индивидуальный подход к каждому пациенту. Московская клиника предлагает детоксикацию, медикаментозную терапию и полноценную психологическую реабилитацию.
Подробнее – https://formula-clinic.ru/kodirovanie-naltreksonom/
Надёжный способ купить чеки с подтверждением для отчёта. | Чеки с печатью, все реквизиты — всё как нужно. | Нужны чеки с подтверждением — рекомендую сюда. | Налоговая приняла без вопросов. | Хорошая поддержка, помогут с выбором. | Чеки подходят для отчёта в любую бухгалтерию. | Быстрое оформление и подтверждение. | Всё чётко: дата, сумма, организация. | Работают и по предоплате, и по факту. | Доверяю этому сервису не первый раз. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки. для. отчетности. можайск.[/url].
Ищете чеки с НДС? Этот сайт подойдёт идеально. | Купил чеки и спокойно закрыл отчёт по командировке. | Один из лучших сервисов по продаже чеков. | Пользовался — всё прошло гладко и быстро. | Качественные чеки без подделок. | Чеки можно использовать для компенсации расходов. | Есть примеры чеков на сайте. | Отчётность больше не вызывает стресс. | Подходит для бизнеса и личных целей. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки от самозанятого[/url].
Надёжный способ купить чеки с подтверждением для отчёта. | Помощь в срочной отчётности — действительно работает. | Просто оформить заказ и получить электронно. | Хорошее соотношение цены и качества. | Всё быстро и без лишней бюрократии. | Выгодно, особенно если нужен большой объём чеков. | Есть возможность заказа с НДС или без. | Много положительных отзывов о сервисе. | Полностью соответствуют требованиям законодательства. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки для налоговой[/url].
Быстрая доставка действительных чеков по всей России. | Помощь в срочной отчётности — действительно работает. | Реальные чеки, которые проходят проверку. | Рекомендую, если не хотите лишних проблем. | Качественные чеки без подделок. | Работают с разными системами налогообложения. | Оформили заказ за 5 минут. | Подходит для командировочных и разовых отчётов. | Распечатал — и в бухгалтерию. | Сайт надёжный, без скрытых условий. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]чеки купить недорого для отчетности[/url].
1win [url=http://1win5016.ru/]1win[/url] .
1win молдова [url=1win5016.ru]1win5016.ru[/url] .
Ищете чеки с НДС? Этот сайт подойдёт идеально. | Купил чеки и спокойно закрыл отчёт по командировке. | Реальные чеки, которые проходят проверку. | Можно заказать оптом для всего отдела. | Хорошая поддержка, помогут с выбором. | Можно выбрать формат чека: бумажный или электронный. | Быстрое оформление и подтверждение. | Можно заказать чеки для разных сотрудников. | Подробное описание каждого чека. | Лучшее решение для занятых предпринимателей. [url=https://dzen.ru/a/Z_kGwEnhIQCzDHyh]купить чеки для отчетности в спб[/url].
Вызов нарколога на дом в Иркутске и Иркутской области — это удобное и безопасное решение, позволяющее получить неотложную помощь в привычной обстановке. Врачи клиники «ЧистоЖизнь» выезжают круглосуточно, приезжают в течение 30–60 минут и проводят комплексное лечение, направленное на стабилизацию состояния пациента и предотвращение осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом иркутск[/url]
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]вызвать капельницу от запоя[/url]
Recommended Reading https://web-sollet.com
Наркологическая клиника «ЗдравЦентр» оказывает круглосуточную помощь пациентам, страдающим от алкогольной интоксикации. Наши специалисты выезжают в любой район Москвы и Московской области, чтобы оперативно поставить капельницу, снять симптомы абстиненции и восстановить здоровье пациента в комфортных домашних условиях.
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva00.ru/]postavit-kapelniczu-ot-zapoya moskva[/url]
see post https://my-sollet.com
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]нарколог на дом вывод из запоя в санкт-петербурге[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Узнать больше – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-anonimno-v-sochi
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить больше информации – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя выезд[/url]
Мы работаем круглосуточно и гарантируем строгое соблюдение конфиденциальности, используя только сертифицированные препараты и проверенные методики лечения.
Узнать больше – https://narcolog-na-dom-sankt-peterburg00.ru/narkolog-na-dom-czena-spb
Описание
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок краснодар.[/url]
В таких ситуациях самостоятельное лечение крайне опасно и может привести к серьезным осложнениям. Наркологи клиники «МедАльянс» рекомендуют незамедлительно обратиться за профессиональной помощью, чтобы избежать серьезных последствий.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-moskva000.ru/]врач на дом капельница от запоя[/url]
website link https://web-sollet.com
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Ознакомиться с деталями – [url=https://narcolog-na-dom-sankt-peterburg00.ru/]вызвать нарколога на дом[/url]
Регистрация прошла легко и просто. Слоты на сайте постоянно обновляются. Играть можно даже без скачивания приложения. Играю на rox casino — выигрываю и отдыхаю. Rox — надёжный выбор для игроков. Зеркало на сегодня найдено без проблем. Зеркало 1429 подключилось сразу. Всё честно и прозрачно. Часто играю на rox casino 365 [url=https://casino-rox.ru/]rox casino 108[/url] .
Основные этапы лечения:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя наркология краснодар[/url]
Экстренная капельница от запоя необходима при первых же признаках тяжелого состояния после длительного употребления алкоголя. Не стоит дожидаться осложнений, вызов нарколога обязателен в таких ситуациях:
Подробнее – [url=https://kapelnica-ot-zapoya-moskva000.ru/]kapelnicza-ot-zapoya-czena moskva[/url]
Основные показания для вызова нарколога:
Подробнее можно узнать тут – https://narcolog-na-dom-v-irkutske00.ru/vrach-narkolog-na-dom-irkutsk/
Описание
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-kruglosutochno sochi[/url]
Как отмечают наркологи нашей клиники, чем раньше пациент получает необходимую помощь, тем меньше риск тяжелых последствий и тем быстрее восстанавливаются функции организма.
Выяснить больше – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя клиника[/url]
Описание
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя анонимно[/url]
Чем раньше проведена детоксикация, тем меньше риск развития серьезных последствий, таких как инфаркт, инсульт, алкогольный психоз, цирроз печени.
Выяснить больше – [url=https://kapelnica-ot-zapoya-moskva0.ru/]posle-kapelniczy-ot-zapoya moskva[/url]
Хотите найти что-то особенное?, рекомендуем посетить. У нас широкий ассортимент. Не пропустите шанс, высшего качества. и не пропустите выгодные предложения. Индивидуальный подход – это то, что мы гарантируем. Наслаждайтесь покупками.
військові штани купити [url=https://camogear.com.ua/]військові штани купити[/url] .
Бонусы за регистрацию — щедрые, особенно по промокоду. Интерфейс сайта rox casino очень понятный. Зеркало сайта rox casino работает стабильно. Казино даёт фриспины при регистрации. Регулярные розыгрыши ценных призов. Вход через зеркало — быстро и просто. Постоянные турниры с большими призами. Есть VIP-программа для активных игроков. Rox — отличный выбор в 2024 году [url=https://casino-rox.ru/]скачать rox casino[/url].
Описание
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя недорого сочи[/url]
Вызывать нарколога на дом рекомендуется при следующих состояниях:
Узнать больше – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]нарколог на дом вывод санкт-петербург[/url]
Лечение выводится поэтапно, чтобы обеспечить безопасность и максимальную эффективность терапии. Каждый этап продуман и адаптирован под индивидуальные особенности пациента.
Углубиться в тему – [url=https://narcolog-na-dom-krasnoyarsk0.ru/]нарколог на дом красноярск[/url]
Преимущество
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодар.[/url]
ВГУ им. П. М. Машерова https://vsu.by официальный сайт, факультеты, направления подготовки, приёмная кампания. Узнайте о поступлении, обучении и возможностях для студентов.
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя на дому краснодар[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-klinika sochi[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]нарколог вывод из запоя в сочи[/url]
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Получить больше информации – https://narcolog-na-dom-sankt-peterburg00.ru/
Промокоды rox casino помогают сэкономить на ставках. Отличная программа лояльности для игроков. Хорошие шансы на выигрыш в популярных играх. Приложение на андроид работает стабильно. Платежи защищены и проходят моментально. Зеркало на сегодня найдено без проблем. Постоянные турниры с большими призами. На rox реально получить крупный выигрыш. Возможность играть с телефона [url=https://casino-rox.ru/]вход в rox casino[/url].
Описание
Получить дополнительную информацию – https://vyvod-iz-zapoya-sochi77.ru/vyvod-iz-zapoya-anonimno-v-sochi
После поступления вызова нарколог клиники «АльфаНаркология» оперативно выезжает по указанному адресу. На месте врач проводит первичную диагностику, оценивая степень интоксикации, физическое и психологическое состояние пациента. По результатам осмотра врач подбирает индивидуальный комплекс лечебных процедур, в который входит постановка капельницы с растворами для детоксикации, препараты для стабилизации работы органов и нормализации психического состояния.
Подробнее – http://narcolog-na-dom-sankt-peterburg000.ru
В таких ситуациях самостоятельное лечение крайне опасно и может привести к серьезным осложнениям. Наркологи клиники «МедАльянс» рекомендуют незамедлительно обратиться за профессиональной помощью, чтобы избежать серьезных последствий.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva000.ru/]капельница от запоя москва.[/url]
Алкогольная интоксикация может быстро привести к тяжелым осложнениям, если не принять своевременных мер. Экстренная помощь нарколога необходима при следующих признаках:
Изучить вопрос глубже – https://kapelnica-ot-zapoya-moskva00.ru/kapelnicza-ot-zapoya-na-domu-msk
Запой — состояние, характеризующееся неконтролируемым и продолжительным употреблением алкоголя, что вызывает сильную интоксикацию организма и нарушения в работе жизненно важных органов. При длительном запое организм испытывает колоссальную нагрузку, страдает сердечно-сосудистая система, печень, почки, а нервная система работает на пределе. Одним из наиболее эффективных методов быстрого и безопасного выхода из запоя является капельница. Наркологическая клиника «Анти-Кризис» в Краснодаре оказывает срочную помощь и вывод из запоя за 24 часа, обеспечивая индивидуальный подход, полную анонимность и доступные цены.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя вызов город[/url]
Проблемы с алкоголем или наркотиками могут застать врасплох и привести к серьезным последствиям для организма, психического состояния и жизни пациента. Самостоятельные попытки выйти из запоя или преодолеть абстинентный синдром без медицинской поддержки редко оказываются эффективными и могут представлять реальную опасность для здоровья. Именно в таких ситуациях клиника «АльфаНаркология» предлагает услугу вызова нарколога на дом в Санкт-Петербурге и Ленинградской области. Наши специалисты оперативно реагируют на обращение, оказывают квалифицированную помощь и обеспечивают полную конфиденциальность лечения.
Узнать больше – http://narcolog-na-dom-sankt-peterburg000.ru
Запой – это критическое состояние, возникающее при длительном или чрезмерном употреблении алкоголя, когда организм не может справиться с токсическим воздействием этанола. Такое состояние характеризуется накоплением токсинов, разрушением внутренних органов и сильным нарушением психоэмоционального баланса. Когда запой продолжается, у человека развивается абстинентный синдром, сопровождающийся не только физическим истощением, но и резкими изменениями в психике: от выраженной тревожности и агрессии до галлюцинаций и потери ориентации.
Подробнее можно узнать тут – https://narcolog-na-dom-krasnoyarsk0.ru/narkolog-na-dom-kruglosutochno-krasnoyarsk/
Промокоды rox casino помогают сэкономить на ставках. Играю на сайте rox casino уже несколько месяцев. Выигрыши приходят вовремя, без задержек. Играю на rox casino — выигрываю и отдыхаю. Множество положительных отзывов о rox. Круглосуточная поддержка через чат. Лояльное отношение к игрокам. Есть VIP-программа для активных игроков. Все лицензии доступны на сайте [url=https://casino-rox.ru/]casino rox[/url].
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi00.ru/]вызвать капельницу от запоя[/url]
Зависимость от алкоголя или наркотиков — серьёзная проблема, требующая немедленного вмешательства квалифицированных специалистов. Если у вас или вашего близкого возникли признаки тяжелого похмелья, запоя или интоксикации, клиника «НаркологПлюс» предлагает услугу вызова нарколога на дом в Санкт-Петербурге. Наши врачи оперативно прибывают по указанному адресу, оказывают всю необходимую медицинскую помощь и помогают пациенту быстро вернуться к нормальной жизни.
Подробнее тут – http://narcolog-na-dom-sankt-peterburg00.ru
Преимущество
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки в краснодаре[/url]
сколько стоит аренда машины в сочи аренда авто сочи цена
Клиника «МедАльянс» оказывает профессиональную медицинскую помощь на дому в Москве и Московской области круглосуточно. Опытные врачи-наркологи приедут в течение часа после вызова, проведут полную диагностику, поставят капельницу и быстро вернут пациента в стабильное состояние.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva000.ru/]kapelnicza-ot-zapoya-czena moskva[/url]
Отзывы о rox casino в целом положительные. Интерфейс сайта rox casino очень понятный. Играть можно даже без скачивания приложения. Казино даёт фриспины при регистрации. Реальные шансы сорвать крупный куш. Моментальный доступ к любимым слотам. Зеркало актуально и всегда работает. Есть VIP-программа для активных игроков. Часто играю на rox casino 365 [url=https://casino-rox.ru/]бонусы rox casino[/url].
Запой — состояние, характеризующееся неконтролируемым и продолжительным употреблением алкоголя, что вызывает сильную интоксикацию организма и нарушения в работе жизненно важных органов. При длительном запое организм испытывает колоссальную нагрузку, страдает сердечно-сосудистая система, печень, почки, а нервная система работает на пределе. Одним из наиболее эффективных методов быстрого и безопасного выхода из запоя является капельница. Наркологическая клиника «Анти-Кризис» в Краснодаре оказывает срочную помощь и вывод из запоя за 24 часа, обеспечивая индивидуальный подход, полную анонимность и доступные цены.
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя краснодар[/url]
Описание
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя краснодар.[/url]
Вызов врача-нарколога на дом позволяет избежать стресса госпитализации, обеспечивая комфорт и удобство как для пациента, так и для его близких.
Подробнее тут – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]выезд нарколога на дом санкт-петербург[/url]
Вызов врача-нарколога на дом позволяет избежать стресса госпитализации, обеспечивая комфорт и удобство как для пациента, так и для его близких.
Получить дополнительные сведения – https://narcolog-na-dom-sankt-peterburg000.ru/vyzov-narkologa-na-dom-spb
Современные методики
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]срочный вывод из запоя[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Разобраться лучше – http://vyvod-iz-zapoya-sochi7.ru
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя[/url]
Промокоды rox casino помогают сэкономить на ставках. Есть мобильное приложение rox casino — удобно в дороге. Дизайн сайта rox casino современный и приятный. Можно играть с минимальными ставками. Множество лицензированных слотов. Зарегистрироваться можно за 1 минуту. Прозрачные условия бонусных программ. Есть VIP-программа для активных игроков. Игры запускаются моментально [url=https://casino-rox.ru/]rox casino[/url].
Вызов врача-нарколога на дом в Санкт-Петербурге начинается с детального осмотра и оценки состояния пациента. Врач измеряет давление, пульс, уровень кислорода в крови и определяет степень интоксикации.
Получить больше информации – http://narcolog-na-dom-sankt-peterburg00.ru/vyzov-narkologa-na-dom-spb/
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя в сочи[/url]
Бонусы за регистрацию — щедрые, особенно по промокоду. Есть мобильное приложение rox casino — удобно в дороге. Много способов пополнения и вывода. Хороший выбор live-казино в rox casino. Rox casino — одно из лучших онлайн казино. Возможность играть даже ночью без ограничений. Прозрачные условия бонусных программ. Есть VIP-программа для активных игроков. Игры запускаются моментально [url=https://casino-rox.ru/]бонусы rox casino[/url].
На сайте rox casino удобно играть с мобильного. Слоты на сайте постоянно обновляются. Выигрыши приходят вовремя, без задержек. Приложение на андроид работает стабильно. Реальные шансы сорвать крупный куш. Есть cashback и другие приятные плюшки. Сайт стабильно работает даже при нагрузке. Есть VIP-программа для активных игроков. Все лицензии доступны на сайте [url=https://casino-rox.ru/]бонусы rox casino[/url].
Бонусы за регистрацию — щедрые, особенно по промокоду. Проверенное зеркало rox casino нашёл без проблем. Хорошие шансы на выигрыш в популярных играх. Постоянные акции делают игру интереснее. Множество положительных отзывов о rox. Зеркало на сегодня найдено без проблем. Лояльное отношение к игрокам. На rox реально получить крупный выигрыш. Все лицензии доступны на сайте [url=https://casino-rox.ru/]casino rox[/url].
В таких ситуациях вывод из запоя на дому становится необходимым, чтобы быстро стабилизировать состояние пациента, избежать необратимых последствий и дать организму шанс на восстановление. Клиника «Семья и Здоровье» предлагает комплексное лечение, осуществляемое опытными наркологами, которые работают 24 часа в сутки, 7 дней в неделю. Наши специалисты приезжают по вызову в течение 30–60 минут, обеспечивая оперативное и качественное лечение в привычной домашней обстановке, что особенно важно для пациентов, испытывающих стресс и страх перед госпитализацией.
Углубиться в тему – http://narcolog-na-dom-krasnoyarsk0.ru/vyzov-narkologa-na-dom-krasnoyarsk/
Основные показания для вызова нарколога:
Подробнее можно узнать тут – https://narcolog-na-dom-v-irkutske00.ru/
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя сочи[/url]
Для эффективного лечения алкогольной интоксикации и восстановления организма врачи клиники «АлкоДоктор» используют комплекс препаратов, которые индивидуально подбираются с учетом состояния пациента.
Получить больше информации – [url=https://kapelnica-ot-zapoya-sochi0.ru/]капельница от запоя цена в сочи[/url]
Некоторые состояния требуют немедленного вмешательства специалиста. Если алкогольное отравление или запойное состояние не купируется вовремя, это может привести к тяжелым последствиям для здоровья.
Изучить вопрос глубже – http://narcolog-na-dom-v-irkutske00.ru/vrach-narkolog-na-dom-irkutsk/
Рабочее зеркало rox casino всегда доступно. Интерфейс сайта rox casino очень понятный. Зеркало сайта rox casino работает стабильно. Казино даёт фриспины при регистрации. Регулярные розыгрыши ценных призов. Моментальный доступ к любимым слотам. Зеркало актуально и всегда работает. Rox — моё главное казино. Есть раздел с отзывами игроков [url=https://casino-rox.ru/]www.casino-rox.ru[/url].
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врач на дом капельница от запоя в краснодаре[/url]
Преимущество
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя анонимно в краснодаре[/url]
Промокоды rox casino помогают сэкономить на ставках. Вход на сайт защищён и быстрый. Много способов пополнения и вывода. Хороший выбор live-казино в rox casino. Регулярные розыгрыши ценных призов. Функционал сайта радует своей продуманностью. Rox casino 108 — одно из лучших зеркал. Много положительных эмоций от игры. Есть раздел с отзывами игроков [url=https://casino-rox.ru/]rox casino[/url].
Игровой процесс в rox casino действительно захватывает. Депозит зачисляется мгновенно, удобно играть. Зеркало сайта rox casino работает стабильно. Хороший выбор live-казино в rox casino. Платежи защищены и проходят моментально. Rox casino — приятный и честный сервис. Постоянные турниры с большими призами. На rox реально получить крупный выигрыш. Есть раздел с отзывами игроков [url=https://casino-rox.ru/]casino rox[/url].
Процедура детоксикации занимает от 40 минут до 2 часов. После её завершения врач консультирует пациента и родственников, даёт рекомендации по дальнейшему лечению и профилактике повторных запоев.
Получить дополнительную информацию – http://narcolog-na-dom-sankt-peterburg00.ru
Как отмечают наркологи нашей клиники, чем раньше пациент получает необходимую помощь, тем меньше риск тяжелых последствий и тем быстрее восстанавливаются функции организма.
Изучить вопрос глубже – http://kapelnica-ot-zapoya-sochi0.ru
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить дополнительные сведения – https://vyvod-iz-zapoya-sochi7.ru
Запой – это критическое состояние, возникающее при длительном или чрезмерном употреблении алкоголя, когда организм не может справиться с токсическим воздействием этанола. Такое состояние характеризуется накоплением токсинов, разрушением внутренних органов и сильным нарушением психоэмоционального баланса. Когда запой продолжается, у человека развивается абстинентный синдром, сопровождающийся не только физическим истощением, но и резкими изменениями в психике: от выраженной тревожности и агрессии до галлюцинаций и потери ориентации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-krasnoyarsk0.ru/]выезд нарколога на дом цена красноярск[/url]
После поступления вызова нарколог клиники «АльфаНаркология» оперативно выезжает по указанному адресу. На месте врач проводит первичную диагностику, оценивая степень интоксикации, физическое и психологическое состояние пациента. По результатам осмотра врач подбирает индивидуальный комплекс лечебных процедур, в который входит постановка капельницы с растворами для детоксикации, препараты для стабилизации работы органов и нормализации психического состояния.
Подробнее – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]нарколог на дом[/url]
После процедуры пациент и его близкие получают развернутые рекомендации по дальнейшему восстановлению, советы по профилактике рецидивов и возможности прохождения кодирования при желании пациента.
Подробнее тут – https://narcolog-na-dom-sankt-peterburg000.ru/narkolog-na-dom-czena-spb/
Процедура включает несколько этапов, направленных на выведение токсинов и восстановление нормальной работы организма.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva0.ru/]поставить капельницу от запоя москва[/url]
снять машину в аренду в москве аренда авто в москве на месяц
После процедуры пациент и его близкие получают развернутые рекомендации по дальнейшему восстановлению, советы по профилактике рецидивов и возможности прохождения кодирования при желании пациента.
Углубиться в тему – http://narcolog-na-dom-sankt-peterburg000.ru/
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Официальный сайт pinko работает стабильно. Интерфейс pinco прост и интуитивно понятен. Бонус за первый депозит в пинко очень щедрый. pinko официальный сайт всегда доступен. На pinko есть раздел с live казино. Можно использовать промокоды на pinko. Есть демо-режим в слотах на pinko. pinko поддерживает быстрые транзакции. Служба поддержки pinko доступна 24/7 [url=https://pinco-kz.website.yandexcloud.net/]pinko kz[/url].
Преимущество
Изучить вопрос глубже – https://vyvod-iz-zapoya-sochi7.ru/
pinko казино — лучший выбор для новичков. pinko официальный сайт безопасен и надежен. На pinko доступны ставки на спорт. Вывод выигрыша с pinko без комиссии. В pinco легко разобраться даже новичку. pinko дает бездепозитные бонусы. Зарегистрироваться в pinko можно за минуту. pinko не требует сложной регистрации. Быстрый вход в личный кабинет на pinko [url=https://pinco-kz.website.yandexcloud.net/]pinco зеркало[/url].
По окончании курса детоксикации нарколог дает пациенту и его близким подробные рекомендации, помогающие быстрее восстановить здоровье и предотвратить повторные случаи запоев.
Разобраться лучше – https://vyvod-iz-zapoya-novosibirsk0.ru/vyvod-iz-zapoya-na-domu-novosibirsk
Идеальные натяжные потолки в Днепре, где современные решения становятся реальностью, позаботьтесь о своем интерьере, инвестируйте в красоту и комфорт.
Элегантные натяжные потолки для вашего дома, качественные материалы, которые сделают ваш интерьер уникальным, закажите прямо сейчас.
Доступные натяжные потолки в Днепре, от natyazhnye-potolki-dnepr.biz.ua, оставьте позади скучные потолки, закажите бесплатную консультацию.
Креативные решения для вашего интерьера, ваше пространство, ваша фантазия, выберите свой идеальный потолок, измените пространство вокруг себя.
Выбор натяжных потолков для любого стиля, для каждого интерьера, всё для вашего удобства, у нас широкий ассортимент.
Натяжные потолки: преимущества и возможности, для вашего дома, долговечность и надежность, позаботьтесь о своем жилье.
Эстетические решения для вашего потолка, всё на natyazhnye-potolki-dnepr.biz.ua, создайте уникальное пространство, заказ натяжного потолка стал проще.
Натяжные потолки: легко и удобно, с нами легко и быстро, доступные решения для каждого, выбор только за вами.
Натяжные потолки от профессионалов, с многолетним опытом на рынке, поддержка и забота о клиенте, придайте своему интерьеру новое дыхание.
Где купить натяжные потолки в Днепре?, от производителей, стиль, качество и цена — все в одном месте, не упустите свой шанс.
Эстетика натяжных потолков для вашего дома, от natyazhnye-potolki-dnepr.biz.ua, мы работаем для вас, позвоните и получите ответ на все вопросы.
Идеальные потолки для вашего дома, доступные на natyazhnye-potolki-dnepr.biz.ua, на любой вкус и бюджет, обратите внимание на наши предложения.
Мы создаем идеальные потолки для вас, с индивидуальным подходом к каждому клиенту, долговечность и стиль, присоединяйтесь к нам.
Натяжные потолки для ваших идей, от natyazhnye-potolki-dnepr.biz.ua, всё для вашего комфорта и стиля, узнайте больше на нашем сайте.
Натяжные потолки: от замысла до реализации, от natyazhnye-potolki-dnepr.biz.ua, с равной страстью к вашему проекту, не откладывайте на завтра.
Преимущества натяжных потолков в вашем интерьере, от natyazhnye-potolki-dnepr.biz.ua, мы создаем счастье для ваших глаз, не упустите шанс.
натяжной потолок днепр [url=https://natyazhnye-potolki-dnepr.biz.ua/]натяжной потолок днепр[/url] .
Играть в pinko удобно с мобильного телефона. pinko — одно из топовых казино в РК. Регистрация в pinko занимает всего пару минут. pinko радует высокой скоростью загрузки. Поддержка pinko отвечает оперативно. В pinko удобный фильтр игр по провайдеру. pinko — это честные выплаты и прозрачные правила. Интерфейс pinko поддерживает русский язык. pinko можно использовать как на ПК, так и на телефоне [url=https://pinco-kz.website.yandexcloud.net/]казино и букмекерская пинко[/url].
Пациенты, которые обращаются в нашу клинику за наркологической помощью, получают не просто стандартное лечение, а комплексный подход к проблеме зависимости. Наши врачи имеют большой практический опыт и высокую квалификацию, благодаря чему могут эффективно справляться даже с самыми сложными случаями. Мы используем только проверенные методики и сертифицированные препараты, гарантирующие безопасность и эффективность лечения.
Выяснить больше – https://narcolog-na-dom-sochi00.ru/vyzov-narkologa-na-dom-sochi
Для эффективного лечения наши врачи используют только проверенные и сертифицированные медикаменты, которые подбираются индивидуально для каждого пациента. В состав лечебного курса входят:
Детальнее – https://narcolog-na-dom-ekaterinburg000.ru/narkolog-na-dom-czena-ekb/
Преимущество
Детальнее – https://narcolog-na-dom-ekaterinburg0.ru/vrach-narkolog-na-dom-ekb
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Подробнее – http://vyvod-iz-zapoya-sochi7.ru/
Наши врачи используют только проверенные и сертифицированные медикаменты, индивидуально подбираемые для каждого пациента. В состав лечебного курса входят:
Углубиться в тему – http://vyvod-iz-zapoya-novosibirsk00.ru/vyvod-iz-zapoya-czena-novosibirsk/
Запой, продолжающийся несколько дней, быстро накапливает токсичные вещества в организме, что приводит к нарушению работы печени, сердца и нервной системы. Если запой сопровождается такими симптомами, как сильная рвота, головокружение, спутанность сознания, судороги, резкие скачки артериального давления или признаки алкогольного психоза, необходима немедленная помощь специалиста.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя цена краснодарский край[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя цена в сочи[/url]
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Подробнее тут – https://narcolog-na-dom-ekaterinburg0.ru/narkolog-na-dom-czena-ekb/
Имплантация и протезирование в Волгограде — это сочетание надежной технологии, аккуратной работы и долговечного результата https://www.vevioz.com/read-blog/327658
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Подробнее – https://vyvod-iz-zapoya-sochi7.ru
pinko Казахстан предлагает щедрые бонусы. Интерфейс pinco прост и интуитивно понятен. pinko работает в Казахстане на официальной основе. Дизайн pinko минималистичный и удобный. Сайт pinko регулярно проводит турниры. pinko поддерживает множество платежных систем. pinko — это честные выплаты и прозрачные правила. pinko даёт приветственный бонус новым игрокам. Все популярные слоты есть на pinko [url=https://pinco-kz.website.yandexcloud.net/]pinko промокод[/url].
После поступления звонка специалисты нашей клиники оперативно выезжают по адресу пациента в Новосибирске. Врач начинает работу с детальной диагностики: измеряет пульс, артериальное давление, сатурацию (уровень кислорода в крови), оценивает состояние нервной и сердечно-сосудистой систем, уточняет наличие хронических заболеваний, аллергических реакций, длительность и тяжесть запоя.
Подробнее – [url=https://vyvod-iz-zapoya-novosibirsk0.ru/]вывод из запоя на дому цена[/url]
Полезная информация wingstv.ru свежие материалы и удобная навигация — всё, что нужно для комфортного пользования сайтом. Заходите, изучайте разделы и находите то, что действительно важно для вас.
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Детальнее – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-cena-v-sochi
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя в стационаре сочи[/url]
Есть ситуации, когда вызов врача на дом становится не просто желателен, а жизненно необходим. Если зависимый человек не способен самостоятельно прекратить употребление алкоголя или наркотиков, а его самочувствие заметно ухудшается, необходимо незамедлительно обратиться за медицинской помощью. Поводом для вызова нарколога служат следующие опасные симптомы:
Получить дополнительные сведения – [url=https://narcolog-na-dom-novosibirsk0.ru/]narkolog-na-dom novosibirsk[/url]
pinko kz радует широким выбором автоматов. Интерфейс pinco прост и интуитивно понятен. pinko — это лицензированное казино. pinko радует высокой скоростью загрузки. pinko — достойная альтернатива другим казино. В пинко легко пройти верификацию. pinko — это честные выплаты и прозрачные правила. На pinko регулярно проходят акции. Быстрый вход в личный кабинет на pinko [url=https://pinco-kz.website.yandexcloud.net/]https://pinco-kz.website.yandexcloud.net[/url].
Преимущество
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg0.ru/]запой нарколог на дом екатеринбург[/url]
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Ознакомиться с деталями – [url=https://narcolog-na-dom-krasnodar00.ru/]vyzov-narkologa-na-dom krasnodar[/url]
Продолжительное употребление алкоголя наносит сильный удар по организму и психике человека. Если запой длится более двух дней, состояние резко ухудшается, и самостоятельный выход может привести к серьезным последствиям. Обязательно следует вызывать врача в следующих случаях:
Узнать больше – http://vyvod-iz-zapoya-krasnodar0.ru
Длительный запой представляет собой крайне опасное состояние, способное нанести непоправимый вред организму. При отсутствии своевременного вмешательства алкогольная интоксикация может привести к серьезным осложнениям, таким как нарушение работы сердца, печени, почек и нервной системы, а также развитию алкогольного психоза. В таких ситуациях экстренная медицинская помощь является залогом спасения жизни и предотвращения необратимых последствий. Клиника «ЗдоровьеНорм» предлагает круглосуточный выезд специалистов для вывода из запоя на дому в Краснодаре и по всему Краснодарскому краю. Наши врачи работают 24 часа в сутки, обеспечивая полный комплекс процедур по детоксикации, снятию абстинентного синдрома и восстановлению организма, при этом гарантируя полную анонимность и индивидуальный подход к каждому пациенту.
Получить больше информации – http://
Пациенты, которые обращаются в нашу клинику, получают целый комплекс преимуществ, благодаря которым лечение проходит максимально эффективно и комфортно:
Ознакомиться с деталями – [url=https://narcolog-na-dom-novosibirsk0.ru/]врач нарколог на дом новосибирск[/url]
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Детальнее – [url=https://narcolog-na-dom-ekaterinburg0.ru/]выезд нарколога на дом[/url]
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Детальнее – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом круглосуточно[/url]
Круглосуточная помощь
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnicza-ot-zapoya-na-domu krasnodar[/url]
Играть в pinko удобно с мобильного телефона. pinko предлагает фриспины за регистрацию. pinko работает в Казахстане на официальной основе. Пинко — отличное онлайн казино для казахстанцев. Сайт pinko регулярно проводит турниры. В пинко легко пройти верификацию. pinko — это честные выплаты и прозрачные правила. Интерфейс pinko поддерживает русский язык. Рейтинг pinko в Казахстане очень высок [url=https://pinco-kz.website.yandexcloud.net/]пинко Казахстан[/url].
аренда авто сколько прокат авто без водителя
выгодная аренда автомобилей спб прокат авто санкт петербург без водителя посуточно
Описание
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие наркотической ломки в краснодаре[/url]
Пинко казино — отличное место для игры. Можно пополнить счет на pinko несколькими способами. pinko — это лицензированное казино. pinko официальный сайт всегда доступен. На pinko есть раздел с live казино. На pinko работают лучшие слоты от провайдеров. Есть демо-режим в слотах на pinko. Можно играть в пинко даже без опыта. Все популярные слоты есть на pinko [url=https://pinco-kz.website.yandexcloud.net/]pinko промокод[/url].
Своевременное вмешательство специалиста позволяет не только вывести токсины, но и снизить риск развития осложнений, обеспечить восстановление жизненно важных функций организма и предотвратить ухудшение состояния, что особенно важно для сохранения здоровья и жизни пациента.
Углубиться в тему – http://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-czena-krasnodar/
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Углубиться в тему – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-cena-v-sochi/
Описание
Получить дополнительные сведения – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-anonimno-v-sochi/
Преимущество
Получить дополнительные сведения – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-anonimno-v-sochi/
Серьезные состояния, вызванные длительным употреблением алкоголя или наркотиков, требуют немедленного вмешательства. Если пациент испытывает ухудшение самочувствия вследствие продолжительного запоя, его организм начинает накапливать токсичные вещества, что ведёт к нарушению работы внутренних органов. При появлении таких симптомов, как сильная рвота, спутанность сознания, судороги, резкие скачки артериального давления, а также выраженные признаки абстинентного синдрома (сильная дрожь, панические атаки, бессонница, тревожность), вызов нарколога становится жизненно необходимым. Экстренное вмешательство позволяет стабилизировать состояние больного и предотвратить развитие серьёзных осложнений, включая сердечно-сосудистые нарушения, повреждение печени и развитие алкогольного психоза. В таких ситуациях профессиональное лечение на дому — лучший способ сохранить здоровье и жизнь пациента.
Получить дополнительные сведения – http://narcolog-na-dom-ekaterinburg000.ru
pinko kz радует широким выбором автоматов. Удобный вход на pinko без блокировок. На pinko доступны ставки на спорт. Зеркало pinko помогает обходить блокировки. В pinco легко разобраться даже новичку. В пинко легко пройти верификацию. На pinko играют тысячи пользователей из РК. pinko даёт приветственный бонус новым игрокам. pinko поддерживает ставки на спорт и киберспорт [url=https://pinco-kz.website.yandexcloud.net/]pinko промокод[/url].
Действие и назначение
Выяснить больше – [url=https://vyvod-iz-zapoya-novosibirsk00.ru/]наркология вывод из запоя в новосибирске[/url]
Процедура лечения начинается с установки внутривенной капельницы, через которую вводятся детоксикационные растворы, способствующие быстрому выведению токсинов и восстановлению водно-электролитного баланса. При необходимости врач назначает дополнительные препараты, такие как седативные средства для купирования симптомов абстинентного синдрома, гепатопротекторы для поддержки печени и кардиопротекторы для нормализации работы сердца.
Ознакомиться с деталями – http://vyvod-iz-zapoya-krasnodar00.ru/vyvod-iz-zapoya-na-domu-krasnodar/https://vyvod-iz-zapoya-krasnodar00.ru
Наша команда врачей оперативно реагирует на каждый вызов, оказывая квалифицированную медицинскую помощь на дому. Специалисты проводят полный комплекс лечебных мероприятий, направленных на безопасное снятие интоксикации, детоксикацию и облегчение симптомов абстиненции.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом вывод в екатеринбурге[/url]
Вызов нарколога на дом необходим в тех случаях, когда состояние человека требует срочного вмешательства врача, а самостоятельно обратиться в стационар нет возможности или желания. Такие ситуации включают сильную алкогольную интоксикацию, затяжные запои, выраженный похмельный синдром, психические расстройства, вызванные употреблением спиртного, и острый абстинентный синдром. Без своевременного лечения эти состояния могут привести к тяжелым осложнениям, таким как инфаркт, инсульт, белая горячка и тяжелое поражение печени. Поэтому при первых признаках ухудшения самочувствия лучше сразу обратиться за помощью к профессионалам.
Получить дополнительные сведения – [url=https://narcolog-na-dom-sochi00.ru/]нарколог на дом цена в сочи[/url]
Пинко казино — отличное место для игры. Интерфейс pinco прост и интуитивно понятен. pinko работает в Казахстане на официальной основе. Вывод выигрыша с pinko без комиссии. В pinco легко разобраться даже новичку. pinko поддерживает множество платежных систем. Казино pinko запускается даже на слабых устройствах. pinko даёт приветственный бонус новым игрокам. Служба поддержки pinko доступна 24/7 [url=https://pinco-kz.website.yandexcloud.net/]акции pinko[/url].
Современные методики
Детальнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому цена сочи[/url]
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Узнать больше – [url=https://narcolog-na-dom-novosibirsk0.ru/]нарколог на дом в новосибирске[/url]
pinko kz радует широким выбором автоматов. Отличная поддержка клиентов в pinko. pinko Казахстан предлагает выгодные условия. Пинко — отличное онлайн казино для казахстанцев. Отзывы о pinko в Казахстане позитивные. pinko казино — стабильная площадка для ставок. Есть демо-режим в слотах на pinko. Интерфейс pinko поддерживает русский язык. pinko поддерживает ставки на спорт и киберспорт [url=https://pinco-kz.website.yandexcloud.net/]пинко казино[/url].
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя клиника в краснодаре[/url]
Есть удобное зеркало пинко для доступа. Отличная поддержка клиентов в pinko. pinko работает в Казахстане на официальной основе. pinko радует высокой скоростью загрузки. Казино пинко — легальный ресурс. В пинко легко пройти верификацию. Есть мобильная версия pinko для Android. Все данные в pinko надёжно защищены. pinko работает без нареканий уже много лет [url=https://pinco-kz.website.yandexcloud.net/]пинко Казахстан[/url].
Преимущество
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки нарколог[/url]
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя сочи.[/url]
По окончании курса детоксикации нарколог дает пациенту и его близким подробные рекомендации, помогающие быстрее восстановить здоровье и предотвратить повторные случаи запоев.
Разобраться лучше – [url=https://vyvod-iz-zapoya-novosibirsk0.ru/]вывод из запоя клиника[/url]
pinko kz радует широким выбором автоматов. В пинко много акций для игроков из Казахстана. pinko работает в Казахстане на официальной основе. Вывод выигрыша с pinko без комиссии. Сайт pinko регулярно проводит турниры. На pinko работают лучшие слоты от провайдеров. Есть мобильная версия pinko для Android. На pinko регулярно проходят акции. Служба поддержки pinko доступна 24/7 [url=https://pinco-kz.website.yandexcloud.net/]www.pinco-kz.website.yandexcloud.net[/url].
Преимущество
Подробнее можно узнать тут – [url=https://narcolog-na-dom-ekaterinburg0.ru/]нарколог на дом клиника екатеринбург[/url]
После поступления звонка специалисты нашей клиники оперативно выезжают по адресу пациента в Новосибирске. Врач начинает работу с детальной диагностики: измеряет пульс, артериальное давление, сатурацию (уровень кислорода в крови), оценивает состояние нервной и сердечно-сосудистой систем, уточняет наличие хронических заболеваний, аллергических реакций, длительность и тяжесть запоя.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-novosibirsk0.ru/]вывод из запоя на дому круглосуточно в новосибирске[/url]
Врачи клиники «ВитаЛайн» для снятия интоксикации и облегчения состояния пациента применяют исключительно качественные и проверенные лекарственные препараты, подбирая их в зависимости от особенностей ситуации и состояния здоровья пациента:
Получить дополнительные сведения – [url=https://narcolog-na-dom-novosibirsk0.ru/]вызвать нарколога на дом[/url]
После поступления вызова клиника «ЗдоровьеНорм» отправляет к пациенту опытного нарколога, который прибывает на дом в течение 30–60 минут. По приезду врач проводит комплексную диагностику, включающую измерение артериального давления, пульса, уровня кислорода в крови и тщательную оценку общего состояния пациента. На основе полученных данных специалист подбирает индивидуальную схему лечения.
Ознакомиться с деталями – [url=https://narcolog-na-dom-krasnodar0.ru/]нарколог на дом клиника в краснодаре[/url]
Современные методики
Разобраться лучше – https://vyvod-iz-zapoya-sochi7.ru/
PORTAL DIGITAL PAFI: Peran Strategis Farmasi dalam Era Digital
Mengenal PAFI
Pasca kemerdekaan RI, para Tenaga Kefarmasian turut berperan aktif dalam pembangunan kesehatan nasional. Berdirinya Persatuan Ahli Farmasi Indonesia (PAFI) menjadi momen bersejarah sebagai forum ahli di bidang farmasi. Berlandaskan Pancasila, PAFI bersumpah untuk:
• Mengembangkan taraf kesehatan rakyat
• Mengembangkan farmasi Indonesia
• Memperbaiki kualitas hidup anggota
Platform Terpadu PAFI: Terobosan Modern untuk Farmasi Modern
Menyongsong revolusi digital, PAFI meluncurkan WEB PAFI Terintegrasi – platform inovatif yang memfasilitasi pekerjaan apoteker melalui:
? Informasi Terkini – Ketersediaan peraturan farmasi, perkembangan ilmiah, dan kesempatan profesional
? Pengembangan Kompetensi – Layanan pelatihan dan sertifikasi daring
? Jaringan Ahli – Sarana kerjasama bagi seluruh ahli farmasi
Inovasi teknologi ini memperkuat kontribusi PAFI dalam meningkatkan kesehatan nasional melalui adaptasi perkembangan teknologi.
Peluang Dunia Farmasi Modern
Adanya sistem terintegrasi ini merupakan tanda revolusi teknologi dalam profesi farmasi. Dengan konsisten memutakhirkan fitur dan layanan, PAFI berkomitmen untuk:
• Memacu inovasi pelayanan kefarmasian
• Menyempurnakan kualitas profesi
• Meningkatkan fasilitas kesehatan untuk rakyat
Kesimpulan
PAFI melalui platform digital ini terus menjadi pionir dalam menghubungkan perkembangan teknis dengan praktik farmasi profesional. Inisiatif ini tidak hanya mengokohkan posisi tenaga kefarmasian, tetapi juga berperan aktif bagi kemajuan kesehatan bangsa di masa modern.
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Углубиться в тему – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому недорого краснодар[/url]
Your article helped me a lot, is there any more related content? Thanks!
заказать эвакуатор спб эвакуатор петербург
https://www.cornbreadhemp.com/products/full-spectrum-cbd-gummies secure seriously helped me run everyday importance without making me feel out of it. I pop unified in the evening after work, and within 30 minutes, I’m way more relaxed. It’s like a seldom nutty reset. They mode like conventional sweets but thrive with all the calming benefits of CBD. I was a fragment unsure at foremost, but in these times I guard a offend in my kitchenette at all times. If you’re dealing with desire, importance, or righteous for to unwind, these are a utter lifesaver. Principled clear definite you’re getting them from a trusted brand!
Если ищете надёжное онлайн казино в Кыргызстане — попробуйте Пинко. Pinco предлагает интересные слоты и ставки на спорт. Зеркало pinco помогает обходить любые блокировки. Зарабатываю в Pinco на спортивных ставках — советую. Играть в pinco можно с минимальными ставками — отличный вариант для новичков. Pinco — надёжный партнёр в мире онлайн-гейминга. Pinco предлагает ставки на спорт с высоким коэффициентом. Служба поддержки pinco отвечает быстро и по делу. Игровой процесс в pinco интуитивно понятен [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco-kyrgyzstan yandexcloud net[/url].
На сайте pinco можно найти всё для ставок и казино. Pinco — современная букмекерская контора и онлайн казино. Попробовал pinco и теперь не играю больше нигде. Играйте в pinco на Android — всё работает идеально. Официальный сайт пинко обновляется регулярно и стабильно работает. Играю в pinco уже год — проблем не было. Pinco поддерживает разные платёжные методы. Пинко отлично адаптировано под мобильные устройства. Игровой процесс в pinco интуитивно понятен [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco казино[/url].
Преимущество
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя клиника в сочи[/url]
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Детальнее – https://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-na-domu-tula
Алкогольный запой представляет собой опасное состояние, когда организм не способен самостоятельно справиться с токсической нагрузкой, вызванной длительным употреблением спиртного. Если запой продолжается более двух-трёх дней, у пациента могут появляться симптомы сильной рвоты, головокружения, спутанности сознания, судорог, резких колебаний артериального давления, а также выраженный абстинентный синдром с паническими атаками и бессонницей. При таких показаниях оперативное вмешательство становится жизненно необходимым для предотвращения серьезных осложнений и ускорения процесса восстановления.
Подробнее – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/]капельница от запоя на дому[/url]
Онлайн-казино JoyCasino https://thejoycasino-ru.com яркий дизайн, популярные слоты, live-игры и щедрые бонусы. Простой вход, быстрые выплаты и надёжная поддержка. Играйте с комфортом и без лишних рисков.
Professional fighter Rafael Fiziev https://rafael-fiziev.com is a UFC star known for his explosive technique and spectacular fights. A lightweight fighter with a powerful punch and a strong Muay Thai base.
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя клиника в краснодаре[/url]
Отзывы о pinco говорят сами за себя — достойный сервис. Официальный сайт pinco работает быстро и без сбоев. Pinco — это лицензированное казино с множеством игр. Пинко казино предлагает топовые игровые автоматы. Пинко казино — это азарт, драйв и реальные выигрыши. В pinco можно играть даже ночью — поддержка всегда на связи. Казино pinco — это безопасность и качество. Служба поддержки pinco отвечает быстро и по делу. Выигрыши в pinco приходят очень быстро [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco casino[/url].
Клиника «НаркологикПлюс» предоставляет квалифицированную помощь нарколога на дому в Воронеже. Если вы или ваши близкие столкнулись с последствиями длительного употребления алкоголя или наркотиков, наши специалисты готовы оперативно выехать и оказать экстренную помощь. Мы проводим детоксикацию организма, снимаем симптомы абстинентного синдрома и стабилизируем состояние пациента, обеспечивая высокий уровень безопасности, строгую анонимность и индивидуальный подход.
Изучить вопрос глубже – [url=https://narcolog-na-dom-voronezh0.ru/]врач нарколог на дом воронеж.[/url]
В обычных условиях цена услуги составляет от 1500 до 2500 рублей. Эта сумма включает выезд специалиста, первичный осмотр и базовую детоксикационную терапию.
Подробнее тут – [url=https://vyvod-iz-zapoya-vladimir00.ru/]vyvod-iz-zapoya-vladimir00.ru/[/url]
Услуга
Разобраться лучше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]вызвать капельницу от запоя на дому[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Подробнее – http://vyvod-iz-zapoya-sochi7.ru
После первичного осмотра начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови и восстановления обменных процессов. Этот этап критически важен для нормализации работы печени, почек и сердечно-сосудистой системы.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-vladimir000.ru/]анонимный вывод из запоя владимир[/url]
Играю в pinco уже давно и всегда доволен результатом. Pinco — современная букмекерская контора и онлайн казино. Регистрируйтесь в pinco и получайте щедрый приветственный бонус. Скачал приложение pinco — теперь играю где угодно. Pinco входит в топ-5 онлайн казино Казахстана. Pinco предоставляет кэшбэк и бонусы без депозита. Пинко — это новые возможности для каждого игрока. Pinco — хороший выбор для тех, кто ценит стабильность. Pinco регулярно дарит фриспины и бонусы [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco-kyrgyzstan .website .yandexcloud .net[/url].
https://www.consmed.ru/news/view/2658/
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя в стационаре в сочи[/url]
Enhance your automobile into a showpiece with our experienced automobile modification packages. At Bergin Auto Shop, we focus in providing first-class upgrades that exhibit your individual style. From chic body enhancements to high-performance motor enhancements, our staff guarantees outstanding artistry. Check out our internet page https://allisonsautobody.com/ to learn about our offerings and initiate your machine’s conversion at once.
Преимущество
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя недорого сочи[/url]
Когда запой становится критическим, оперативное вмешательство имеет решающее значение для спасения здоровья и предотвращения необратимых последствий. Во Владимире экстренная помощь нарколога на дому позволяет быстро начать лечение, не требуя госпитализации, что особенно важно для пациентов, нуждающихся в сохранении конфиденциальности и комфорте.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-vladimir000.ru/]вывод из запоя цены владимир[/url]
Играю в pinco уже давно и всегда доволен результатом. В казино пинко легко ориентироваться даже новичку. На сайте pinco casino часто проходят акции и турниры. Pinco — отличный выбор для любителей ставок в Казахстане и Кыргызстане. Быстрые выплаты и честная статистика — это всё про Pinco. Pinco — это честный геймплей и высокие коэффициенты в ставках. Pinco предлагает ставки на спорт с высоким коэффициентом. На pinco можно играть в любое время суток. Pinco — реальное казино с живыми ставками [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco промокод[/url].
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-vladimir0.ru/]нарколог на дом вывод из запоя владимир[/url]
Описание
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-czena sochi[/url]
Описание
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]срочный вывод из запоя в сочи[/url]
Группа препаратов
Разобраться лучше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/]капельница от запоя наркология нижний новгород[/url]
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Узнать больше – [url=https://vyvod-iz-zapoya-tula00.ru/]вывод из запоя на дому цена в туле[/url]
Выбор помощи на дому имеет ряд значительных преимуществ:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-tula0.ru/]вывод из запоя анонимно в туле[/url]
King of the ring roy-jones.com Roy Jones is a fighter with a unique style and lightning-fast reactions. His career includes dozens of titles, spectacular knockouts and a cult status in the boxing world.
Football genius luka-modric.com/ Luka Modric – from humble beginnings in Zagreb to a world-class star. His path inspires, his play amazes. The story of a great master in detail.
Автопортал для водителей https://addinfo.com.ua и автолюбителей: свежие авто новости, сравнения моделей, рейтинги, советы по выбору и обслуживанию автомобилей. Полезная информация каждый день.
Свежие новости https://actualnews.kyiv.ua Украины и мира онлайн: события, аналитика, интервью и факты. Будьте в курсе главного — обновления 24/7, объективная подача и лента новостей в реальном времени.
Если ищете надёжное онлайн казино в Кыргызстане — попробуйте Пинко. Pinco — современная букмекерская контора и онлайн казино. Pinco предлагает удобные способы пополнения и вывода средств. У pinco отличная бонусная программа и ежедневные награды. Pinco casino — отличное решение для игры на тенге. Pinco — это удобство, бонусы и выплаты без задержек. Выбирайте pinco и забудьте о проблемах с доступом. Пинко отлично адаптировано под мобильные устройства. Pinco поддерживает киргизский и русский язык [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]casino pinco[/url].
После поступления звонка нарколог оперативно выезжает по указанному адресу и прибывает в течение 30–60 минут. Врач незамедлительно приступает к оказанию помощи по четко отработанному алгоритму, состоящему из следующих этапов:
Получить больше информации – http://narcolog-na-dom-voronezh00.ru
Группа препаратов
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/kapelnicza-ot-zapoya-czena-nizhnij-novgorod
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки[/url]
Сразу после поступления вызова нарколог прибывает на дом для проведения детального первичного осмотра. Врач собирает краткий анамнез, измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и оценивает степень интоксикации. Эта информация является фундаментом для разработки индивидуального плана терапии, который учитывает особенности состояния пациента.
Узнать больше – [url=https://vyvod-iz-zapoya-tula000.ru/]срочный вывод из запоя тула[/url]
На сайте pinco можно найти всё для ставок и казино. Pinco предлагает интересные слоты и ставки на спорт. Пинко радует честной игрой и быстрой проверкой аккаунта. Pinco работает даже при ограничении доступа — всегда в обход. Pinco помогает выиграть благодаря высокой отдаче автоматов. Pinco — это удобство, бонусы и выплаты без задержек. Pinco предлагает ставки на спорт с высоким коэффициентом. Служба поддержки pinco отвечает быстро и по делу. Pinco — реальное казино с живыми ставками [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco казино[/url].
Когда запой становится критическим, оперативное вмешательство имеет решающее значение для спасения здоровья и предотвращения необратимых последствий. Во Владимире экстренная помощь нарколога на дому позволяет быстро начать лечение, не требуя госпитализации, что особенно важно для пациентов, нуждающихся в сохранении конфиденциальности и комфорте.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-vladimir000.ru/]владимир вывод из запоя[/url]
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя краснодар.[/url]
Группа препаратов
Выяснить больше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/]капельница от запоя вызов[/url]
Женский журнал https://asprofrutsc.org о стиле, красоте, психологии, отношениях и саморазвитии. Актуальные статьи, советы экспертов, тренды и вдохновение — всё для современной женщины.
Онлайн-журнал для женщин https://chernogolovka.net всё о жизни, любви, красоте, детях, финансах и личностном развитии. Простым языком о важном — полезно, интересно и по делу.
Автомобильный портал https://avto-limo.zt.ua для тех, кто за рулём: автообзоры, полезные советы, новости индустрии и подбор авто. Удобный поиск, свежая информация и всё, что нужно автолюбителю.
Авто журнал онлайн https://clothes-outletstore.com всё о мире автомобилей: новости, тест-драйвы, обзоры, советы, новинки автопрома и технологии. Читайте с любого устройства — всегда в курсе автоиндустрии.
Отзывы о pinco говорят сами за себя — достойный сервис. Выигрывать в pinco реально — проверено временем. Pinco casino online работает без проблем на телефоне. Скачал приложение pinco — теперь играю где угодно. Pinco входит в топ-5 онлайн казино Казахстана. Pinco — надёжный партнёр в мире онлайн-гейминга. Pinco предлагает честные условия игры и прозрачные правила. Pinco — хороший выбор для тех, кто ценит стабильность. Игровой процесс в pinco интуитивно понятен [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco-kyrgyzstan.website.yandexcloud.net/[/url].
После вашего звонка нарколог выезжает на дом в течение 30–60 минут. Прибыв на место, специалист проводит всесторонний медицинский осмотр, включая измерение артериального давления, пульса и уровня кислорода в крови, а также собирает анамнез для определения степени интоксикации.
Разобраться лучше – [url=https://narcolog-na-dom-voronezh0.ru/]нарколог на дом анонимно воронеж[/url]
pg slot mahjong
PORTAL DIGITAL PAFI: Fungsi Penting Farmasi di Zaman Digital
Profil Singkat PAFI
Sejak Indonesia merdeka, para Ahli Farmasi aktif berkontribusi dalam kemajuan kesehatan bangsa. Didirikannya Persatuan Ahli Farmasi Indonesia (PAFI) menjadi tonggak penting sebagai asosiasi di bidang farmasi. Berlandaskan Pancasila, PAFI bersumpah untuk:
• Memajukan taraf kesehatan rakyat
• Menyempurnakan bidang farmasi di Tanah Air
• Menunjang kualitas hidup anggota
Platform Terpadu PAFI: Terobosan Modern untuk Kefarmasian Masa Kini
Menyongsong revolusi digital, PAFI memperkenalkan sistem terintegrasi ini – platform inovatif yang memfasilitasi profesi kefarmasian melalui:
? Update Terbaru – Ketersediaan peraturan farmasi, riset mutakhir, dan peluang karir
? Peningkatan Kemampuan – Layanan kursus online bersertifikat
? Jaringan Ahli – Media sinergi se-Indonesia
Platform ini memaksimalkan sumbangsih PAFI dalam meningkatkan pelayanan kesehatan melalui adaptasi perkembangan teknologi.
Peluang Farmasi Digital
Adanya sistem terintegrasi ini menjadi bukti transformasi digital dalam profesi farmasi. Dengan terus mengembangkan kapabilitas sistem, PAFI berjanji untuk:
• Menggalakkan pembaruan layanan farmasi
• Menyempurnakan kualitas profesi
• Meningkatkan fasilitas kesehatan untuk rakyat
Kesimpulan
PAFI dengan adanya WEB PAFI Terintegrasi konsisten memimpin dalam menjembatani inovasi digital dengan praktik farmasi profesional. Terobosan ini tidak hanya mengokohkan posisi tenaga kefarmasian, tetapi juga memberikan sumbangsih konkret bagi kemajuan kesehatan bangsa pada zaman teknologi.
Комплексное лечение на дому организовано по строго отлаженной схеме, позволяющей оперативно стабилизировать состояние пациента и провести качественную детоксикацию.
Подробнее тут – http://vyvod-iz-zapoya-vladimir00.ru/vyvod-iz-zapoya-na-domu-vladimir/
Введение препаратов осуществляется внутривенно, что обеспечивает оперативное действие медикаментов. В состав лечебного раствора входят средства для детоксикации организма, нормализации водно-электролитного и кислотно-щелочного баланса. При необходимости врач дополнительно вводит препараты, защищающие печень, стабилизирующие работу сердца и успокаивающие нервную систему. Вся процедура проводится под строгим контролем нарколога, который следит за состоянием пациента и корректирует терапию при необходимости. По завершении процедуры врач дает пациенту и его родственникам подробные рекомендации по дальнейшему восстановлению и профилактике повторных запоев.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod0.ru/]капельница от запоя на дому цена нижний новгород[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Узнать больше – http://vyvod-iz-zapoya-sochi7.ru
Описание
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]narkolog-vyvod-iz-zapoya sochi[/url]
Описание
Разобраться лучше – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-cena-v-sochi/
На сайте pinco можно найти всё для ставок и казино. В казино пинко легко ориентироваться даже новичку. Промокод pinco приносит дополнительные фриспины. Играйте в pinco на Android — всё работает идеально. Pinco входит в топ-5 онлайн казино Казахстана. В pinco можно играть даже ночью — поддержка всегда на связи. Pinco предлагает честные условия игры и прозрачные правила. Pinco предоставляет полную статистику ставок. Казино пинко предлагает RTP выше среднего [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco-kyrgyzstan.website.yandexcloud.net/[/url].
Наркологическая клиника «АнтиДот» предлагает срочный вызов нарколога на дом в Воронеже и Воронежской области. Наша служба экстренной наркологической помощи доступна круглосуточно и позволяет быстро справиться с тяжелыми состояниями, вызванными алкогольной и наркотической зависимостью. Опытные врачи проведут детоксикацию организма, помогут снять абстинентный синдром и стабилизировать общее состояние пациента в комфортных домашних условиях.
Выяснить больше – [url=https://narcolog-na-dom-voronezh00.ru/]нарколог на дом вывод[/url]
Продолжительный запой приводит к накоплению токсинов в организме, нарушению работы внутренних органов и развитию серьезных осложнений. Чем дольше человек находится в состоянии алкогольной интоксикации, тем выше риск повреждения сердца, печени и почек. Экстренное вмешательство позволяет оперативно вывести токсины, восстановить нормальные обменные процессы и предотвратить развитие хронических заболеваний.
Подробнее тут – http://vyvod-iz-zapoya-vladimir000.ru
Основной этап терапии — установка внутривенной капельницы. Через капельницу вводятся специально подобранные растворы, способствующие быстрому выведению токсинов, восстановлению водно-электролитного баланса и нормализации работы внутренних органов. При необходимости врач назначает дополнительные медикаменты для защиты печени, стабилизации сердечной деятельности и купирования симптомов абстинентного синдрома. В течение всей процедуры состояние пациента контролируется врачом, который корректирует схему лечения для достижения наилучших результатов. По завершении процедуры специалист дает подробные рекомендации по дальнейшему восстановлению и профилактике повторных запоев.
Подробнее – http://kapelnica-ot-zapoya-nizhniy-novgorod00.ru
Основной этап терапии — установка внутривенной капельницы. Через капельницу вводятся специально подобранные растворы, способствующие быстрому выведению токсинов, восстановлению водно-электролитного баланса и нормализации работы внутренних органов. При необходимости врач назначает дополнительные медикаменты для защиты печени, стабилизации сердечной деятельности и купирования симптомов абстинентного синдрома. В течение всей процедуры состояние пациента контролируется врачом, который корректирует схему лечения для достижения наилучших результатов. По завершении процедуры специалист дает подробные рекомендации по дальнейшему восстановлению и профилактике повторных запоев.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/kapelnicza-ot-zapoya-czena-nizhnij-novgorod/
Алкогольная интоксикация и запой могут стремительно ухудшить состояние здоровья, став угрозой жизни, поэтому оперативное вмешательство имеет первостепенное значение. В Туле квалифицированные наркологи предоставляют круглосуточную помощь на дому, что позволяет начать лечение незамедлительно и в комфортных условиях. Такой формат терапии гарантирует индивидуальный подход, всестороннюю поддержку и полную конфиденциальность, что особенно важно для пациентов, стремящихся восстановить своё здоровье без лишних стрессовых ситуаций.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-tula000.ru/]вывод из запоя недорого в туле[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows Activation Price[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows Xp Locked Out Activation[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows Activation Taking Long Time[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows Activation Speedrun[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows Check Activation Status[/url]
Windows Activation
Играю в pinco уже давно и всегда доволен результатом. Официальный сайт pinco работает быстро и без сбоев. Pinco предлагает удобные способы пополнения и вывода средств. Пинко казино предлагает топовые игровые автоматы. Быстрые выплаты и честная статистика — это всё про Pinco. Играю в pinco уже год — проблем не было. Пинко казино — это современная и надёжная платформа. В pinco всегда можно найти выгодный промокод. В pinco играют тысячи довольных клиентов ежедневно [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]casino pinco[/url].
[url=https://kuban.video/video/40-svjatki-v-ispolnenii-ansambljaatamanochka.html]Святки[/url]
Святки
uncircularised
work-hardened
adhesive’s
Renwick
haverel
Стоимость услуг по установке капельницы определяется индивидуально и зависит от нескольких факторов. В первую очередь, цена обусловлена тяжестью состояния пациента: при более сильной интоксикации и выраженных симптомах абстинентного синдрома может потребоваться расширенная терапия. Кроме того, итоговая сумма зависит от продолжительности запоя, так как длительное употребление спиртного ведет к более серьезному накоплению токсинов, требующему дополнительных лечебных мероприятий.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod000.ru/]капельница от запоя на дому нижний новгород.[/url]
Описание
Подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому круглосуточно в сочи[/url]
В Pinco легко пройти регистрацию и сразу получить бонус. В казино пинко легко ориентироваться даже новичку. Попробовал pinco и теперь не играю больше нигде. Пинко казино предлагает топовые игровые автоматы. Pinco casino — отличное решение для игры на тенге. В pinco можно играть даже ночью — поддержка всегда на связи. Pinco предлагает ставки на спорт с высоким коэффициентом. Pinco — лучший выбор для азартных игр в Кыргызстане. Казино пинко предлагает RTP выше среднего [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco скачать[/url].
Пинко казино предлагает отличный выбор азартных игр. В казино пинко легко ориентироваться даже новичку. Пинко радует честной игрой и быстрой проверкой аккаунта. У pinco отличная бонусная программа и ежедневные награды. Пинко предоставляет большой выбор live-игр. Pinco работает и в браузере, и в приложении — удобно. Pinco предлагает бесплатные фриспины за регистрацию. Pinco — хороший выбор для тех, кто ценит стабильность. В pinco играют тысячи довольных клиентов ежедневно [url=https://pinco-kyrgyzstan.website.yandexcloud.net/]pinco промокод[/url].
Описание
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя недорого в сочи[/url]
Продолжительный запой приводит к накоплению токсинов в организме, нарушению работы внутренних органов и развитию серьезных осложнений. Чем дольше человек находится в состоянии алкогольной интоксикации, тем выше риск повреждения сердца, печени и почек. Экстренное вмешательство позволяет оперативно вывести токсины, восстановить нормальные обменные процессы и предотвратить развитие хронических заболеваний.
Получить больше информации – [url=https://vyvod-iz-zapoya-vladimir000.ru/]vivod iz zapoya vladimir[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Узнать больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя недорого сочи[/url]
После поступления звонка нарколог оперативно выезжает по указанному адресу и прибывает в течение 30–60 минут. Врач незамедлительно приступает к оказанию помощи по четко отработанному алгоритму, состоящему из следующих этапов:
Углубиться в тему – https://narcolog-na-dom-voronezh00.ru/vyzov-narkologa-na-dom-voronezh
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Выяснить больше – [url=https://vyvod-iz-zapoya-vladimir0.ru/]нарколог на дом вывод из запоя владимир[/url]
Вывод из запоя на дому в Туле осуществляется по строго отлаженной схеме, которая включает несколько последовательных этапов. Такой комплексный подход позволяет не только быстро вывести токсины из организма, но и обеспечить всестороннюю поддержку пациента, включая психологическую реабилитацию.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-tula00.ru/]вывод из запоя в туле[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Детальнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя круглосуточно сочи[/url]
Услуга вывода из запоя на дому в Туле разработана для тех, кто столкнулся с тяжелыми последствиями злоупотребления алкоголем. Основная цель – оперативная детоксикация организма, восстановление нормального обмена веществ и предотвращение дальнейших осложнений. Врач нарколог проводит полный комплекс обследований и назначает персонализированный план лечения, включающий медикаментозную терапию и психологическую поддержку, что позволяет обеспечить стабильное восстановление организма.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-tula000.ru/]наркологический вывод из запоя тула[/url]
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить нормальный обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце. Этот этап критически важен для стабилизации состояния пациента и предотвращения дальнейших осложнений.
Получить больше информации – http://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-na-domu-tula/https://vyvod-iz-zapoya-tula00.ru
Современный авто журнал https://ecotech-energy.com в онлайн-формате для тех, кто хочет быть в курсе автомобильных трендов. Новости, тесты, обзоры и аналитика — всегда под рукой.
Авто журнал онлайн https://comparecarinsurancerfgj.org свежие новости, обзоры моделей, тест-драйвы, советы и рейтинг автомобилей. Всё о мире авто в одном месте, доступно с любого устройства.
Онлайн-портал для женщин https://fancywoman.kyiv.ua которые ценят себя и стремятся к лучшему. Всё о внутренней гармонии, внешнем блеске и жизненном балансе — будь в центре женского мира.
Женский портал https://elegantwoman.kyiv.ua о красоте, моде, здоровье, отношениях и вдохновении. Полезные статьи, советы экспертов, лайфхаки и свежие тренды — всё для современной женщины.
https://www.prozdor.ru/zabolevaniya/mir-zvukov-prostye-shagi-k-luchshemu-vospriyatiju-rechi-i-muzyki/
visit https://quarklab.ru/fr/crypto-drainer/
Семейный портал https://cgz.sumy.ua для родителей и детей: развитие, образование, здоровье, детские товары, досуг и психология. Актуальные материалы, экспертиза и поддержка на всех этапах взросления.
Автомобильный сайт https://billiard-sport.com.ua с обзорами, тест-драйвами, автоновостями и каталогом машин. Всё о выборе, покупке, обслуживании и эксплуатации авто — удобно и доступно.
Родительский портал https://babyrost.com.ua от беременности до подросткового возраста. Статьи, лайфхаки, рекомендации экспертов, досуг с детьми и ответы на важные вопросы для мам и пап.
Автомобильный журнал https://eurasiamobilechallenge.com новости автоиндустрии, тест-драйвы, обзоры моделей, советы водителям и экспертов. Всё о мире автомобилей в удобном онлайн-формате.
Мы готовы предложить дипломы любых профессий по выгодным ценам.
Вы покупаете диплом в надежной и проверенной временем компании. Приобрести диплом о высшем образовании– [url=http://thefreedommovement.ca/read-blog/53230/]thefreedommovement.ca/read-blog/53230[/url]
go to my site https://cleanthebit.com/ru/
Автомобильный сайт https://fundacionlogros.org с ежедневными новостями, обзорами новинок, аналитикой, тест-драйвами и репортажами из мира авто. Следите за трендами и будьте в курсе всего важного.
Современный женский сайт https://femalebeauty.kyiv.ua мода, психология, семья, карьера, рецепты и лайфхаки. Ежедневно — новые материалы, рекомендации и интересные темы для каждой женщины.
Женский сайт о красоте https://female.kyiv.ua моде, здоровье, отношениях и саморазвитии. Полезные статьи, советы экспертов, вдохновение и поддержка — всё для гармоничной и уверенной жизни.
Читайте автомобильный сайт https://gormost.info онлайн — тесты, обзоры, советы, автоистории и материалы о современных технологиях. Всё для тех, кто любит машины и скорость.
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить больше информации – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя анонимно[/url]
Преимущество
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому круглосуточно в сочи[/url]
тревожная кнопка охрана цена [url=https://trevros.ru]https://trevros.ru[/url] .
Описание
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя[/url]
Первый шаг в лечении — это тщательный осмотр специалиста. Наряду с измерением жизненно важных показателей (пульс, артериальное давление, температура) врач проводит сбор анамнеза, выясняя длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Эти данные помогают оценить степень интоксикации и подобрать индивидуальный план терапии, что является ключевым для дальнейшей эффективной детоксикации.
Детальнее – [url=https://vyvod-iz-zapoya-yaroslavl0.ru/]вывод из запоя на дому ярославская область[/url]
На этом этапе специалист уточняет, сколько времени продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ собранной информации позволяет оперативно подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-donetsk-dnr0.ru/vyvod-iz-zapoya-czena-doneczk-dnr
страница http://lapplebi.com/
Своевременное вмешательство позволяет снизить концентрацию токсинов, нормализовать обмен веществ и предотвратить необратимые повреждения, что делает срочный вызов нарколога на дому жизненно необходимым.
Детальнее – [url=https://narcolog-na-dom-ryazan00.ru/]выезд нарколога на дом рязань[/url]
Преимущество
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки на дому в краснодаре[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]нарколог вывод из запоя[/url]
Для быстрого продвижения по карьере понадобится наличие диплома о высшем образовании. Заказать диплом университета у надежной фирмы: [url=http://diplomg-cheboksary.ru/kupit-diplom-24/]diplomg-cheboksary.ru/kupit-diplom-24/[/url]
Одним из основных этапов вывода из запоя является медикаментозная детоксикация. Современные препараты вводятся капельничным методом, что обеспечивает быстрое снижение уровня алкоголя и токсинов в крови. Это позволяет восстановить нормальный обмен веществ и нормализовать работу жизненно важных органов, таких как печень, почки и сердце. Такой подход помогает не только стабилизировать состояние пациента, но и уменьшить риск развития осложнений.
Подробнее тут – http://vyvod-iz-zapoya-yaroslavl0.ru/vyvod-iz-zapoya-kruglosutochno-yaroslavl/
Описание
Получить больше информации – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-na-domu-v-sochi/
Процесс оказания срочной помощи нарколога на дому в Мариуполе построен по отлаженной схеме, которая включает несколько ключевых этапов, направленных на быстрое и безопасное восстановление здоровья пациента.
Выяснить больше – [url=https://narcolog-na-dom-mariupol00.ru/]вызвать нарколога на дом[/url]
Преимущество
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя недорого в сочи[/url]
go
[url=https://tlo-ssndob.com/]Search SSN DOB[/url]
Need real estate? https://www.luxury-property-montenegro.com/ villas, houses and apartments in Budva, Kotor, Tivat and on the coast. Profitable investment, sea view, safety and comfort in the south of Europe.
Процесс лечения капельничной терапией в условиях экстренной помощи в Луганске ЛНР состоит из нескольких этапов, каждый из которых направлен на быструю и безопасную детоксикацию организма.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]posle-kapelniczy-ot-zapoya lugansk[/url]
Zelite li se odmoriti? Zabljak hoteli Rezervirajte udoban hotel u centru ili u podnozju planina. Odlican izbor za skijanje i ljetovanje. Jamstvo rezervacije i stvarne recenzije.
need a move? moving companies from toronto to calgary turnkey: packing, loading, transport, insurance and support. Without stress and with a guarantee of the safety of your property.
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi7.ru
Автоперевозки из Китая https://mamuli.club/forum/topic/33465/ доставка грузов по РФ и странам СНГ. Сборные и индивидуальные партии, оформление, отслеживание и страхование. Быстро, надёжно, под ключ.
На этом этапе специалист уточняет, сколько времени продолжается запой, какие основные симптомы наблюдаются, и если имеются, то какие хронические заболевания могут влиять на течение терапии. Точный анализ этих данных позволяет сформировать персонализированную стратегию лечения, которая будет максимально адаптирована к состоянию пациента и его потребностям.
Узнать больше – [url=https://vyvod-iz-zapoya-yaroslavl0.ru/]вывод из запоя на дому ярославль[/url]
Описание
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок[/url]
Описание
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя в краснодаре[/url]
Когда запой угрожает здоровью, каждая минута имеет решающее значение. В Ярославле квалифицированные специалисты по наркологии оказывают помощь на дому, позволяя оперативно начать лечение алкогольной интоксикации и вывести токсины из организма. Такой формат терапии обеспечивает комфортные условия для пациента, максимальную конфиденциальность и индивидуальный подход, что особенно важно для быстрого и безопасного восстановления здоровья.
Подробнее тут – [url=https://vyvod-iz-zapoya-yaroslavl00.ru/]вывод из запоя в ярославле[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/
Описание
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя в стационаре сочи[/url]
Преимущество
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя в сочи[/url]
Комплексный подход к выводу из запоя на дому в Ярославле включает несколько основных этапов, которые позволяют обеспечить оперативное и безопасное лечение:
Получить дополнительную информацию – http://vyvod-iz-zapoya-yaroslavl0.ru/
Незамедлительно после вызова нарколог приезжает на дом для проведения первичного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает краткий анамнез для оценки степени алкогольной интоксикации. Этот этап является фундаментом для составления персонализированного плана лечения.
Подробнее тут – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-czena-doneczk-dnr
тревожная кнопка [url=http://trevros.ru]тревожная кнопка[/url] .
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk
2025年NBA免費線上看直播:籃球投注與即時更新的完整指南
隨著全球體育迷對線上博弈和賽事直播的需求不斷增長,NBA作為最受歡迎的籃球聯賽之一,自然成為了眾多球迷關注的焦點。2025年的NBA賽季將帶來更多精采的比賽,而如何免費觀看這些比賽並參與場中投注,已成為球迷們最關心的話題。本文將為您提供完整的NBA免費線上看直播教學、即時比分更新、以及相關的投注技巧。
一、NBA免費線上看直播的管道
不論是季後賽(4月-5月)還是總決賽(6月),NBA的每一場比賽都充滿激情與挑戰。以下是幾種常見的免費直播方式:
1. 線上直播平台
OB體育電視台 、鑫寶體育電視台 、SUPER體育電視台 等平台提供免費註冊服務,新用戶還可獲得168預測金,讓您在觀看比賽的同時也能進行運彩投注。
只需簡單註冊帳號,選擇【熊貓體育】或【RG富遊體育電視台】,即可輕鬆進入NBA籃球LIVE直播。
2. 電視轉播頻道
華視NBA籃球頻道 、ELTA TV 、以及中華電信MOD 也提供64場全賽事的LIVE轉播,適合喜歡透過電視欣賞比賽的球迷。
如果您偏好手機觀看,可以訂閱Hami Video NBA專區 ,每月僅需149元即可享受所有賽事的高清轉播。
二、如何註冊/登入以免費觀看NBA直播?
如果您想通過線上平台觀看NBA直播,以下是詳細步驟:
點選【RG官網】或【富遊娛樂城】官網,選擇「註冊/登入」。
輸入會員資料完成註冊。
登入後,點選【熊貓體育】或【體育直播】分類。
選擇NBA籃球視頻直播,即可免費觀看您感興趣的比賽。
三、NBA即時比分與場中投注
對於熱衷於運動彩券的球迷來說,NBA不僅是一場視覺盛宴,更是投注的好時機。以下是一些實用的投注建議:
即時比分更新 :透過【RG富遊體育電視台】或【熊貓體育】,您可以隨時掌握比賽進展,並根據比分變化調整投注策略。
場中投注技巧 :例如,在比賽關鍵時刻(如延長賽或最後三分鐘),利用即時數據進行快速下注,往往能提高勝率。
此外,NBA季後賽和總決賽期間,各平台通常會推出特別優惠活動,例如加倍獎金或贈送預測金,讓您的投注更有趣味性。
四、其他熱門賽事推薦
除了NBA之外,2025年還有許多值得期待的體育盛事:
2024夏季奧運 :涵蓋多項運動項目,是體育迷不容錯過的國際賽事。
2024歐洲盃 :足球迷的年度盛宴,各國勁旅爭奪最高榮譽。
2024 WBC世界棒球經典賽 :棒球愛好者的狂歡節,亞洲強隊表現備受矚目。
2023-2024英超聯賽 :足球迷必追的頂級聯賽,精彩程度無與倫比。
五、結語
無論您是單純的NBA球迷,還是熱衷於運動彩券投注的玩家,2025年的NBA賽季都將為您帶來無限樂趣。透過本文介紹的免費直播管道與投注技巧,您可以輕鬆享受每場比賽的刺激與精彩。現在就趕快註冊帳號,加入這場籃球狂歡吧!
立即行動!登入【熊貓體育】或【RG富遊體育電視台】,開啟您的NBA免費線上看之旅!
Обращение за помощью к наркологу на дому имеет ряд преимуществ, особенно в экстренных ситуациях:
Выяснить больше – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом вывод из запоя[/url]
Добрый день!
Для определенных людей, заказать [b]диплом[/b] университета – это необходимость, удачный шанс получить достойную работу. Но для кого-то – это желание не терять время на учебу в институте. Что бы ни толкнуло вас на это решение, наша компания готова помочь вам. Оперативно, профессионально и по разумной стоимости сделаем документ любого года выпуска на государственных бланках со всеми необходимыми подписями и печатями.
Основная причина, почему многие покупают диплом, – получить хорошую должность. К примеру, способности и опыт дают возможность кандидату устроиться на работу, однако подтверждения квалификации не имеется. В случае если для работодателя важно наличие “корочек”, риск потерять вакантное место очень высокий.
Заказать документ о получении высшего образования можно у нас в Москве. Мы оказываем услуги по продаже документов об окончании любых университетов России. Вы получите диплом по любым специальностям, любого года выпуска, включая документы Советского Союза. Гарантируем, что при проверке документа работодателями, никаких подозрений не возникнет.
Факторов, которые вынуждают купить диплом очень много. Кому-то прямо сейчас потребовалась работа, таким образом необходимо произвести хорошее впечатление на начальника в процессе собеседования. Некоторые желают попасть в серьезную компанию, для того, чтобы повысить свой статус в обществе и в дальнейшем начать свое дело. Чтобы не терять множество времени, а сразу начать удачную карьеру, используя имеющиеся знания, можно заказать диплом прямо в онлайне. Вы станете полезным в обществе, обретете финансовую стабильность быстро и просто- [url=http://diplomanrus.com/]диплом о среднем образовании купить[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnica-ot-zapoya-krasnodar777.ru/[/url]
Первый шаг в лечении — это тщательный осмотр специалиста. Наряду с измерением жизненно важных показателей (пульс, артериальное давление, температура) врач проводит сбор анамнеза, выясняя длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Эти данные помогают оценить степень интоксикации и подобрать индивидуальный план терапии, что является ключевым для дальнейшей эффективной детоксикации.
Углубиться в тему – [url=https://vyvod-iz-zapoya-yaroslavl0.ru/]вывод из запоя на дому круглосуточно[/url]
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Выяснить больше – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя цена донецк[/url]
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя капельница[/url]
Website [url=https://galaxy-swapper.org]galaxy swapper[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Подробнее тут – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-na-domu-murmansk//
На этом этапе врач детально выясняет, как долго продолжается запой, какие симптомы наблюдаются, и имеются ли сопутствующие заболевания. Точный анализ информации помогает оперативно определить степень интоксикации и подобрать оптимальные методы детоксикации, что является ключом к предотвращению дальнейших осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ryazan00.ru/]выезд нарколога на дом рязань[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя на дому мурманск[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому цена[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-na-domu sochi[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому цена сочи[/url]
Обращение за помощью к наркологу на дому имеет ряд преимуществ, особенно в экстренных ситуациях:
Выяснить больше – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом мариуполь[/url]
Преимущество
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в стационаре краснодар[/url]
Описание
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя в краснодаре[/url]
Круглосуточная помощь
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя анонимно[/url]
Описание
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому цена в сочи[/url]
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Подробнее тут – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом мариуполь.[/url]
Комплексный подход к выводу из запоя на дому в Ярославле включает несколько основных этапов, которые позволяют обеспечить оперативное и безопасное лечение:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-yaroslavl0.ru/]вывод из запоя ярославль[/url]
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]поставить капельницу от запоя луганск[/url]
При тяжелых формах алкогольной интоксикации своевременное вмешательство критически важно для предотвращения опасных осложнений. В Луганске ЛНР специалисты по наркологии предоставляют услугу экстренной капельничной терапии на дому, что позволяет быстро снизить токсическую нагрузку и стабилизировать работу жизненно важных органов. Такой метод лечения позволяет обеспечить высокую эффективность терапии в комфортной, привычной для пациента обстановке, при этом сохраняется полная конфиденциальность.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя цена[/url]
Описание
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому[/url]
подключить тревожную кнопку росгвардия [url=www.trevros.ru]подключить тревожную кнопку росгвардия[/url] .
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Получить дополнительную информацию – http://narcolog-na-dom-mariupol00.ru
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Научитесь новой профессии, пройдите он-лайн курс!
https://chudesenka.ru/6719-kak-vybrat-buduschuyu-professiyu-poshagovoe-rukovodstvo-k-osoznannomu-resheniyu.html
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Выяснить больше – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя цена улан-удэ.[/url]
Наркологическая клиника «Формула Трезвости» в Москве предлагает эффективное лечение зависимостей: от детоксикации и кодирования до психологической помощи и реабилитации. Московские специалисты клиники помогут вернуться к полноценной жизни без зависимостей.
Получить дополнительные сведения – [url=https://formula-clinic.ru/reabilitatsiya-alkogolikov/]реабилитация алкоголиков[/url]
Онлайн-портал про автомобили https://impactspreadsms.com с каталогом моделей, тестами, аналитикой, ценами и отзывами. Удобный поиск и полезные материалы — для тех, кто выбирает с умом.
Портал для женщин https://gracefulwoman.kyiv.ua которые ценят красоту жизни. Практичные советы, душевные статьи и поддержка — о том, как быть счастливой, уверенной и гармоничной каждый день.
Портал про авто https://impactspreadsms.com новости, обзоры, тест-драйвы, советы, сравнение моделей и актуальные тенденции в мире автомобилей. Всё для автолюбителей и профессионалов.
Современный женский https://happylady.kyiv.ua сайт с ежедневными обновлениями: советы по стилю, уходу, семье и психологии. Всё, что волнует и вдохновляет женщин сегодня — в одном месте.
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся методом инфузии, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Детальнее – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]vyvod-iz-zapoya-czena ulan-ude[/url]
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя в сочи[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – http://vyvod-iz-zapoya-ulan-ude00.ru/
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя наркология в архангельске[/url]
Услуга вызова нарколога на дом в Уфе разработана для оперативного вывода из запоя без необходимости госпитализации. Это особенно актуально для тех, кто столкнулся с алкогольной интоксикацией в условиях, когда каждая минута имеет значение. Своевременная помощь позволяет не только устранить негативное воздействие алкоголя на организм, но и предотвратить возможные осложнения, такие как нарушения работы сердца, печени и почек.
Выяснить больше – [url=https://narcolog-na-dom-ufa0.ru/]вызов нарколога на дом цена в уфе[/url]
Процесс вывода из запоя на дому строится на комплексном подходе, включающем как медикаментозную терапию, так и психологическую поддержку. Такой метод позволяет не только быстро стабилизировать физическое состояние, но и помочь пациенту осознать причины зависимости, что способствует долгосрочной ремиссии.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd0.ru/]vyvod-iz-zapoya-czena volgograd[/url]
Свежие новости Украины https://fraza.kyiv.ua и мира — политика, экономика, общество, культура, технологии. Главные события дня, оперативные обновления и аналитика от экспертов.
Модный журнал онлайн https://icz.com.ua одежда, аксессуары, макияж, прически, уличный стиль и haute couture. Следите за последними тенденциями и читайте советы экспертов индустрии.
Современный портал https://lady.kyiv.ua для женщин: мода, уход, любовь, дети, стиль жизни и вдохновение. Полезный контент, тренды и темы, близкие каждой.
Актуальные новости Украины https://lenta.kyiv.ua и мира на одном сайте. Подборка ключевых событий, факты, интервью, мнения и видео. Честно, быстро и без фейков.
Запой – это состояние, при котором контроль над употреблением алкоголя утрачивается, а токсическая нагрузка на организм резко возрастает. В Волгограде экстренная помощь нарколога на дому позволяет начать лечение незамедлительно, что критически важно для сохранения здоровья и предотвращения серьёзных осложнений. Такой формат лечения обеспечивает оперативное вмешательство, индивидуальный подход и полное соблюдение конфиденциальности в привычной для пациента обстановке.
Подробнее тут – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя анонимно в волгограде[/url]
Преимущество
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-cena-v-sochi/
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-klinika sochi[/url]
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd00.ru/]наркология вывод из запоя в волгограде[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Узнать больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя сочи[/url]
Услуга вывода из запоя на дому в Мурманске разработана для того, чтобы оперативно снизить токсическую нагрузку и вернуть организм в нормальное состояние. При поступлении вызова специалист проводит детальный осмотр, собирает анамнез и измеряет жизненно важные показатели. На основании полученных данных составляется индивидуальный план терапии, который может включать капельничное введение медикаментов, использование автоматизированных систем дозирования и психологическую поддержку. Такой комплексный подход позволяет обеспечить высокую эффективность лечения даже в условиях экстренной необходимости.
Углубиться в тему – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя клиника мурманск[/url]
Портал для женщин https://maleportal.kyiv.ua мода, красота, здоровье, отношения, карьера, семья и вдохновение. Актуальные темы, полезные советы и поддержка для каждой женщины — всё в одном месте.
Лечение вывода из запоя на дому в Улан-Удэ организовано по чётко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс восстановления.
Углубиться в тему – https://vyvod-iz-zapoya-ulan-ude0.ru/narkologiya-vyvod-iz-zapoya-ulan-ude
Клуб для беременных https://mam.ck.ua и молодых мам: питание, подготовка к родам, уход за малышом, послеродовое восстановление. Полезная информация, консультации и поддержка в одном месте.
Онлайн-портал для современных https://madrasa.com.ua женщин. Всё, что волнует и вдохновляет: от красоты и моды до жизненного баланса, мотивации и личностного роста. Будь собой — с нами.
Главные новости https://lentanews.kyiv.ua из Украины и со всего мира — ежедневно и без искажений. Всё, что важно знать: внутренняя политика, экономика, международные события и прогнозы.
Для эффективного продвижения вверх по карьере требуется наличие диплома о высшем образовании. Приобрести диплом любого университета у сильной фирмы: [url=http://diplomg-cheboksary.ru/kupit-diplom-v-samare-bistro-i-nadezhno/]diplomg-cheboksary.ru/kupit-diplom-v-samare-bistro-i-nadezhno/[/url]
Служба круглосуточного вывода из запоя организована таким образом, чтобы обеспечить максимальную оперативность и надежность. Независимо от времени суток, квалифицированные специалисты готовы выехать на дом или принять пациента в медицинском учреждении, чтобы приступить к детоксикации и стабилизации состояния.
Углубиться в тему – [url=https://vyvod-iz-zapoya-volgograd000.ru/]вывод из запоя волгоград.[/url]
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя в стационаре в сочи[/url]
Описание
Получить больше информации – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-anonimno-v-sochi/
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов, восстановления обменных процессов и нормализации работы таких органов, как печень, почки и сердце.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]после капельницы от запоя[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом вывод[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому улан-удэ[/url]
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом калининградская область[/url]
На данном этапе врач уточняет, сколько времени продолжается запой, какой алкоголь употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет разработать персональный план детоксикации, что значительно снижает риск осложнений.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя недорого в улан-удэ[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Узнать больше – http://vyvod-iz-zapoya-murmansk0.ru/
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Выяснить больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки в стационаре краснодар[/url]
Сайт для деловых людей https://manorsgroup.com.ua актуальные материалы о финансах, инвестициях, рынке недвижимости и управлении капиталом. Аналитика, обзоры, экспертные мнения и полезные инструменты.
Женский онлайн-журнал https://mcms-bags.com о красоте, моде, психологии, отношениях и стиле жизни. Актуальные статьи, советы экспертов, вдохновение и всё, что важно для современной женщины.
Применение современных капельничных методов позволяет точно дозировать лекарственные средства. Постоянный мониторинг жизненно важных показателей пациента дает возможность оперативно корректировать терапию для достижения оптимального эффекта и предотвращения побочных реакций.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-volgograd00.ru/]vyvod-iz-zapoya-volgograd00.ru/[/url]
Новостной портал https://mediashare.com.ua с актуальной информацией из Украины, мира, политики, экономики, технологий, культуры и общества. Только проверенные источники и объективные материалы.
the alarm cd the alarm cd
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Детальнее – https://narcolog-na-dom-ufa0.ru/narkolog-na-dom-ufa-czeny/
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Подробнее тут – http://narcolog-na-dom-kaliningrad0.ru/vrach-narkolog-na-dom-kaliningrad/
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя выезд в архангельске[/url]
Купить аккаунт https://marketplace-akkauntov-top.ru
Первый этап терапии направлен на оперативное очищение организма от токсинов, накопившихся в результате длительного употребления алкоголя. Врач-нарколог подбирает индивидуальную схему лечения, включающую внутривенные инфузии и другие современные препараты, способствующие нормализации обмена веществ и восстановлению работы внутренних органов.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя на дому цена волгоград[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-na-domu-v-sochi
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Узнать больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя сочи[/url]
Описание
Подробнее – http://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-na-domu-v-sochi/
Лечение на дому основывается на комплексном подходе, который включает медикаментозную детоксикацию и психологическую поддержку. Каждая терапевтическая процедура подбирается индивидуально с учетом клинической картины пациента, что позволяет добиться максимальной эффективности и безопасности лечения.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-kapelnicza-volgograd
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Разобраться лучше – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя на дому круглосуточно[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам.– [url=http://diplomg-kurerom.ru/kupit-diplom-s-provodkoj-vigodno-i-bez-problem/]diplomg-kurerom.ru/kupit-diplom-s-provodkoj-vigodno-i-bez-problem/[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Изучить вопрос глубже – https://vyvod-iz-zapoya-sochi7.ru
Для удачного продвижения вверх по карьерной лестнице необходимо наличие диплома о высшем образовании. Купить диплом института у надежной организации: [url=http://kupitediplom0027.ru/goznak-attestati-kupit/]kupitediplom0027.ru/goznak-attestati-kupit/[/url]
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя цена в улан-удэ[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Получить больше информации – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому[/url]
Преимущество
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому сочи[/url]
Лечение на дому основывается на комплексном подходе, который включает медикаментозную детоксикацию и психологическую поддержку. Каждая терапевтическая процедура подбирается индивидуально с учетом клинической картины пациента, что позволяет добиться максимальной эффективности и безопасности лечения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя на дому волгоград[/url]
linked here https://marinade.ink/
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Углубиться в тему – [url=https://narcolog-na-dom-kaliningrad0.ru/]narkolog-na-dom kaliningrad[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя цена[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся методом инфузии, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]срочный вывод из запоя[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся методом инфузии, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому круглосуточно[/url]
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя капельница в мурманске[/url]
I am just writing to let you be aware of of the beneficial discovery my wife’s daughter found checking your web site. She came to find a wide variety of issues, including what it is like to have a marvelous giving spirit to let men and women without hassle thoroughly grasp a number of multifaceted subject areas. You actually surpassed readers’ expected results. Thank you for producing these priceless, dependable, edifying and in addition unique guidance on that topic to Lizeth.
Когда запой начинает оказывать разрушительное воздействие на организм, своевременная помощь становится критически важной для предотвращения серьезных осложнений. В Мурманске квалифицированные наркологи на дому обеспечивают оперативную детоксикацию, восстановление обменных процессов и стабилизацию работы внутренних органов. Лечение проводится в комфортной домашней обстановке, что позволяет избежать лишнего стресса и сохранить полную конфиденциальность.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя на дому мурманск.[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Узнать больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-klinika sochi[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Разобраться лучше – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызов нарколога на дом[/url]
Hey I am so glad I found your webpage, I really found you by accident, while I was browsing on Yahoo for something else, Regardless I am here now and would just like to say many thanks for a incredible post and a all round thrilling blog (I also love the theme/design), I don’t have time to browse it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be back to read a great deal more, Please do keep up the awesome job.
На данном этапе врач уточняет, сколько времени продолжается запой, какой алкоголь употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет разработать персональный план детоксикации, что значительно снижает риск осложнений.
Получить больше информации – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому цена в улан-удэ[/url]
Оперативное лечение организовано по четкому алгоритму, который позволяет быстро стабилизировать состояние пациента и обеспечить эффективную терапию. Каждый этап направлен на комплексное восстановление организма.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd000.ru/]вывод из запоя клиника волгоград[/url]
Авто сайт с обзорами https://microbus.net.ua новостями, тест-драйвами, каталогом моделей, советами по выбору и эксплуатации автомобилей. Всё, что нужно автолюбителю — в одном месте.
Сайт для женщин https://miymalyuk.com.ua мода, красота, здоровье, отношения, карьера, семья и вдохновение. Актуальные статьи, советы и поддержка для современной женщины каждый день
Главные новости Украины https://novosti24.kyiv.ua и мира — честно, быстро и понятно. События, которые формируют завтрашний день, в одной ленте.
Актуальные новости Украины https://newsportal.kyiv.ua и мира сегодня: главные события, мнения экспертов, интервью, прогнозы. Оставайтесь в курсе с лентой, которая обновляется 24/7.
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-kapelnicza-volgograd/
pop over here https://marinade.ink/
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя цена краснодар.[/url]
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Разобраться лучше – http://kapelnica-ot-zapoya-arkhangelsk00.ru
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Детальнее – https://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в стационаре в сочи[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Получить дополнительные сведения – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-kruglosutochno-murmansk
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры по ремонту техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что способствует быстрому снижению уровня токсинов в крови, нормализации обменных процессов и стабилизации работы таких органов, как печень, почки и сердце.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя круглосуточно в мурманске[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана краснодар[/url]
Специалист уточняет продолжительность запоя, характер симптоматики и наличие хронических заболеваний, проводит измерения пульса, давления и температуры, что позволяет оперативно скорректировать терапию.
Выяснить больше – [url=https://vyvod-iz-zapoya-volgograd000.ru/]вывод из запоя недорого волгоград[/url]
Портал о здоровье и медицине https://pravovakrayina.org.ua узнайте больше о своём организме, симптомах, лечении и профилактике. Удобный поиск, рекомендации врачей, база клиник и аптек.
Мы можем предложить дипломы психологов, юристов, экономистов и других профессий по приятным тарифам.– [url=http://diplomk-v-krasnodare.ru/poluchite-diplom-visshego-obrazovaniya-s-reestrovoj-zapisyu/]diplomk-v-krasnodare.ru/poluchite-diplom-visshego-obrazovaniya-s-reestrovoj-zapisyu/[/url]
Онлайн-медицинский портал https://novamed.com.ua справочник болезней, симптомы, анализы, лекарства, консультации специалистов и актуальные новости здравоохранения. Всё о здоровье — в одном месте.
читайте на автомобильном https://proauto.kyiv.ua портале: тест-драйвы, сравнения, автоаналитика, обзоры технологий и новинки автопрома. Только актуальные материалы и честные мнения.
Современный авто портал https://quebradadelospozos.com свежие новости, каталог машин, рейтинг моделей, видеообзоры и полезные статьи. Помощь при покупке, советы по обслуживанию и анализ рынка.
После диагностики начинается активная фаза медикаментозного вмешательства, когда препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов.
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad00.ru/]врач нарколог на дом калининград.[/url]
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Разобраться лучше – [url=https://narcolog-na-dom-ufa0.ru/]нарколог уфа[/url]
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Детальнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]vyvod-iz-zapoya ulan-ude[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что способствует быстрому снижению уровня токсинов в крови, нормализации обменных процессов и стабилизации работы таких органов, как печень, почки и сердце.
Изучить вопрос глубже – http://vyvod-iz-zapoya-murmansk00.ru/vyvod-iz-zapoya-na-domu-murmansk/
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Получить дополнительные сведения – https://vyvod-iz-zapoya-ulan-ude0.ru/vyvod-iz-zapoya-na-domu-ulan-ude
Алкогольная зависимость сопровождается не только физическими, но и глубокими психоэмоциональными проблемами. Психотерапевтическая помощь играет важную роль в лечении, помогая пациенту осознать причины зависимости и разработать стратегии для предотвращения рецидивов.
Ознакомиться с деталями – [url=https://narcolog-na-dom-ufa0.ru/]нарколог на дом уфа[/url]
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Подробнее тут – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]капельница от запоя выезд архангельск[/url]
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Узнать больше – http://vyvod-iz-zapoya-sochi7.ru
Экстренная помощь требуется, когда запой начинает негативно сказываться на здоровье, и самостоятельное прекращение употребления алкоголя становится невозможным. Основные показания для круглосуточного вмешательства включают:
Изучить вопрос глубже – http://vyvod-iz-zapoya-volgograd000.ru/vyvod-iz-zapoya-kapelnicza-volgograd/
Сразу после вызова нарколог приезжает на дом для проведения тщательного первичного осмотра. Врач измеряет такие жизненно важные показатели, как пульс, артериальное давление и температура, а также собирает подробный анамнез, чтобы оценить степень алкогольной интоксикации.
Узнать больше – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызов нарколога на дом в калининграде[/url]
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]вызвать капельницу от запоя архангельск[/url]
Современный женский журнал https://reyesmusicandevents.com стиль, уход, карьера, семья, рецепты и саморазвитие. Читайте свежие материалы каждый день — будь в тренде и в гармонии с собой.
Женский онлайн-журнал https://ruforums.net с разнообразными рубриками — от моды и макияжа до материнства и путешествий. Открывайте каждый день с новыми идеями и полезным контентом.
Сайт про авто https://rusigra.org обзоры машин, автоновости, тест-драйвы, сравнения моделей, советы водителям и полезные статьи. Всё, что нужно автолюбителям — на одном ресурсе.
Журнал для женщин https://saralelakarat.com мода, красота, здоровье, психология, семья и вдохновение. Актуальные статьи, советы экспертов и интересные темы для женщин всех возрастов.
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Подробнее – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-klinika-arkhangelsk/
Kraken – это универсальный онлайн-магазин, предоставляющий покупателям доступ к уникальным товарам со всего мира. Kraken предлагает выбор товаров для всех: от современных аксессуаров до уникальных предметов коллекционирования. Также важно отметить, [url=https://xn--krakn4-z4a.com]официальная ссылка кракен[/url] гарантирует удобство покупок, предлагая безопасные транзакции и защиту клиента. Каждый день [url=https://xn--krakn4-z4a.com]кракен сайт тор ссылка[/url] предлагает своим клиентам свежие скидки и уникальные предложения. Испытайте удобство и экономию покупок с [url=https://xn--krakn4-z4a.com]kra dark net[/url] уже сегодня.
kra сс: https://xn--krakn4-z4a.com
Описание
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя[/url]
Круглосуточная помощь
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд краснодар[/url]
Первый этап терапии направлен на оперативное очищение организма от токсинов, накопившихся в результате длительного употребления алкоголя. Врач-нарколог подбирает индивидуальную схему лечения, включающую внутривенные инфузии и другие современные препараты, способствующие нормализации обмена веществ и восстановлению работы внутренних органов.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-volgograd0.ru/]www.domen.ru[/url]
аккаунты с балансом https://marketplace-akkauntov-top.ru
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки нарколог в краснодаре[/url]
Лечение вывода из запоя на дому в Улан-Удэ организовано по чётко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс восстановления.
Получить дополнительную информацию – https://vyvod-iz-zapoya-ulan-ude0.ru/
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому круглосуточно сочи[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Подробнее тут – https://narcolog-na-dom-kaliningrad00.ru/vrach-narkolog-na-dom-kaliningrad/
Метод вывода из запоя на дому рекомендуется в следующих случаях:
Углубиться в тему – https://vyvod-iz-zapoya-volgograd0.ru/vyvod-iz-zapoya-kapelnicza-volgograd
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет оперативно сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]капельница от запоя цена архангельск.[/url]
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-ulan-ude00.ru/vyvod-iz-zapoya-kapelnicza-ulan-ude/
The convenient http://www.booking-zabljak.com service will help you find the perfect hotel for car travelers and active holiday lovers. A wide range of accommodation: from cozy guest houses to modern hotels with parking, Wi-Fi and breakfast. Book in advance and relax in comfort in the heart of Montenegro!
Никогда еще шопинг не был таким простым, как с Кракен, одним из крупнейших онлайн-магазинов. На [url=https://xn--krakn4-l4a.com]ссылка kraken cc[/url] представлен широкий ассортимент товаров: от электроники и стильной одежды до товаров для дома и бакалеи, что позволяет удовлетворить любые потребности. Наслаждайтесь удобством быстрой доставки и безопасных платежей, обеспечивая душевное спокойствие при каждой покупке. Окунитесь в мир [url=https://xn--krakn4-l4a.com]kraken darknet market зеркало[/url] сегодня и ощутите непревзойденное удовлетворение потребностей клиентов.
кракен даркнет площадка: https://xn--krakn4-l4a.com
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-kruglosutochno-murmansk/
Онлайн-журнал для женщин https://zhenskiy.kyiv.ua которые ценят себя, любят жить ярко и стремятся к гармонии. Будь в курсе моды, заботься о себе и черпай вдохновение каждый день.
Портал о машинах https://shpik.info от новостей и технологий до экспертных статей и автомобильной аналитики. Узнайте всё о текущих трендах на рынке и новинках автопрома.
Портал о машинах https://xiwet.com от новостей и технологий до экспертных статей и автомобильной аналитики. Узнайте всё о текущих трендах на рынке и новинках автопрома.
Описание
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого краснодар[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что способствует быстрому снижению уровня токсинов в крови, нормализации обменных процессов и стабилизации работы таких органов, как печень, почки и сердце.
Подробнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]vyvod-iz-zapoya-na-domu murmansk[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]www.domen.ru[/url]
Лечение вывода из запоя на дому в Мурманске организовано по четко структурированной схеме, включающей следующие этапы, каждый из которых играет ключевую роль в оперативном восстановлении здоровья:
Детальнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]narkolog-vyvod-iz-zapoya murmansk[/url]
redirected here https://ringexchange.org/
Extra resources https://marinade.ink
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом вывод из запоя в калининграде[/url]
Описание
Выяснить больше – https://vyvod-iz-zapoya-sochi7.ru/
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Выяснить больше – http://vyvod-iz-zapoya-ulan-ude00.ru
Специалист уточняет продолжительность запоя, характер симптоматики и наличие хронических заболеваний, проводит измерения пульса, давления и температуры, что позволяет оперативно скорректировать терапию.
Детальнее – https://vyvod-iz-zapoya-volgograd000.ru/vyvod-iz-zapoya-kruglosutochno-volgograd
Специалист уточняет продолжительность запоя, характер симптоматики и наличие хронических заболеваний, проводит измерения пульса, давления и температуры, что позволяет оперативно скорректировать терапию.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-volgograd000.ru
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Детальнее – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя волгоград.[/url]
Журнал про животных https://zoobonus.com.ua интересные статьи о питомцах, дикой природе, уходе, воспитании и поведении. Всё для тех, кто любит животных и хочет узнать о них больше.
Полный гид по недвижимости https://all2realt.com.ua как выбрать, купить, продать или арендовать квартиру, дом или коммерческий объект. Обзоры, цены, тенденции рынка и юридические тонкости.
hop over to this web-site https://balancer.ac
Из соседнего курорта организуют экскурсия на Куршскую косу из Светлогорска с морской тематикой.
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-czena sochi[/url]
Описание
Подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя капельница[/url]
Когда запой начинает негативно влиять на здоровье, оперативное лечение становится залогом успешного выздоровления. В Архангельске, Архангельская область, квалифицированные наркологи предоставляют помощь на дому, позволяя быстро провести детоксикацию, восстановить нормальные обменные процессы и стабилизировать работу жизненно важных органов. Такой формат лечения обеспечивает индивидуальный подход, комфортную домашнюю обстановку и полную конфиденциальность, что особенно важно для пациентов, стремящихся к быстрому восстановлению без посещения стационара.
Ознакомиться с деталями – http://kapelnica-ot-zapoya-arkhangelsk00.ru
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызов врача нарколога на дом[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет оперативно сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]капельница от запоя на дому в архангельске[/url]
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Ознакомиться с деталями – https://vyvod-iz-zapoya-volgograd00.ru/vyvod-iz-zapoya-kruglosutochno-volgograd/
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ufa0.ru/]вызов нарколога на дом уфа[/url]
продажа аккаунтов https://marketplace-akkauntov-top.ru
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя улан-удэ.[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]snyatie-lomki-rnd7.ru/[/url]
Круглосуточная помощь
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снять ломку краснодар[/url]
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому улан-удэ.[/url]
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-arkhangelsk0.ru
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Разобраться лучше – [url=https://narcolog-na-dom-kaliningrad00.ru/]вызов нарколога на дом[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Углубиться в тему – [url=https://narcolog-na-dom-kaliningrad00.ru/]narcolog-na-dom-kaliningrad00.ru/[/url]
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому в улан-удэ[/url]
Современные методы лечения при выводе из запоя включают как медикаментозную детоксикацию, так и психологическую реабилитацию. В Уфе наркологи используют капельничное введение лекарственных средств, которые помогают быстро вывести токсины, нормализовать обмен веществ и стабилизировать работу внутренних органов. Одновременно с этим проводится психологическая поддержка для снижения эмоционального стресса, связанного с запоем.
Подробнее тут – https://narcolog-na-dom-ufa0.ru/narkolog-na-dom-czena-ufa
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Детальнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя клиника улан-удэ[/url]
read more https://skymoney.net
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Детальнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя анонимно в улан-удэ[/url]
Метод вывода из запоя на дому рекомендуется в следующих случаях:
Подробнее тут – [url=https://vyvod-iz-zapoya-volgograd0.ru/]вывод из запоя недорого в волгограде[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя на дому мурманск.[/url]
[url=https://chempion-casino-official.ru]chempion-casino-official.ru[/url]
На сайте, посвященном обзору официального сайта Казино Чемпион, вы найдете всестороннюю информацию об этой популярной игровой платформе. Здесь детально разобраны ключевые аспекты казино, начиная от интерфейса и удобства навигации, и заканчивая разнообразием игрового ассортимента и щедростью бонусной программы. В обзоре представлена информация о лицензировании казино, гарантиях безопасности, скорости выплат и качестве работы службы поддержки. Благодаря этому обзору, вы сможете составить полное представление о Казино Чемпион, оценить его преимущества и недостатки, и принять взвешенное решение, стоит ли здесь регистрироваться и играть на реальные деньги. Кроме того, на сайте представлены отзывы реальных игроков, которые помогут вам получить более объективную картину о работе казино и избежать возможных разочарований.
chempion-casino-official.ru
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд в краснодаре[/url]
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя цена в архангельске[/url]
Современные методики
Углубиться в тему – https://vyvod-iz-zapoya-sochi7.ru
Современные методики
Детальнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому круглосуточно сочи[/url]
Комбинируйте урбанистику и природу экскурсии по Зеленоградску и Куршской косе в одном туре.
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя анонимно[/url]
The best online slots big bamboo in one place: classics, new releases, jackpots and themed machines. Play without registration, test the demo or make real bets with bonuses.
Профессиональное агентство рекламное агентство Витрувий: разработка рекламы, брендинг, digital-маркетинг, наружка и SMM. Комплексное продвижение для бизнеса любого масштаба.
Описание
Детальнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому сочи.[/url]
Процесс вывода из запоя на дому строится на комплексном подходе, включающем как медикаментозную терапию, так и психологическую поддержку. Такой метод позволяет не только быстро стабилизировать физическое состояние, но и помочь пациенту осознать причины зависимости, что способствует долгосрочной ремиссии.
Ознакомиться с деталями – http://vyvod-iz-zapoya-volgograd0.ru/vyvod-iz-zapoya-na-domu-volgograd/https://vyvod-iz-zapoya-volgograd0.ru
Обращение за помощью нарколога на дому в Улан-Удэ имеет ряд неоспоримых преимуществ, обеспечивающих эффективное лечение:
Подробнее тут – https://vyvod-iz-zapoya-ulan-ude00.ru/narkologiya-vyvod-iz-zapoya-ulan-ude
Первичный этап терапии направлен на оперативное выведение токсинов из организма. Врач-нарколог назначает индивидуальную схему медикаментозного вмешательства, что позволяет снизить уровень алкоголя в крови и восстановить обмен веществ.
Получить дополнительные сведения – http://vyvod-iz-zapoya-volgograd00.ru
Заказать диплом института по доступной стоимости вы сможете, обратившись к проверенной специализированной компании. Приобрести документ о получении высшего образования вы сможете в нашей компании. [url=http://asxdiplommy.com/kupit-ofitsialnij-diplom-s-zaneseniem-v-reestr-legalno/]asxdiplommy.com/kupit-ofitsialnij-diplom-s-zaneseniem-v-reestr-legalno[/url]
Купить диплом ВУЗа!
Наша компания предлагаетвыгодно заказать диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, штампами, подписями. Диплом способен пройти любые проверки, даже при использовании профессиональных приборов. Решайте свои задачи быстро и просто с нашей компанией- [url=http://onarslan.com.tr/kupit-diplom-prostoe-reshenie-dlja-slozhnyh-zadach-13.html/]onarslan.com.tr/kupit-diplom-prostoe-reshenie-dlja-slozhnyh-zadach-13.html[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Специалист измеряет жизненно важные показатели — пульс, артериальное давление и температуру — и собирает подробный анамнез для оценки степени алкогольной интоксикации.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя круглосуточно в улан-удэ[/url]
Лечение на дому основывается на комплексном подходе, который включает медикаментозную детоксикацию и психологическую поддержку. Каждая терапевтическая процедура подбирается индивидуально с учетом клинической картины пациента, что позволяет добиться максимальной эффективности и безопасности лечения.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя цена[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя цена республика бурятия[/url]
Купить натуральный камень дагестанский камень в Краснодаре и Краснодарском крае по оптовой цене. Каталог с расценками, размеры и монтаж дагестанской плитки из ракушечника, песчаника, травертина, известняка для отделки фасада и цоколя в Краснодаре от производителя.
квартирный переезд услуги заказать услуги грузчиков
квартирные переезды с грузчиками недорого услуги грузчиков грузоперевозки
перевозки квартирные с грузчиками malaya-vishera.standart-express.ru
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]наркологический вывод из запоя в улан-удэ[/url]
Круглосуточная помощь
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]вызвать капельницу от запоя в краснодаре[/url]
Мы готовы предложить дипломы любой профессии по выгодным ценам. Стараемся поддерживать для клиентов адекватную политику тарифов. Для нас очень важно, чтобы дипломы были доступны для подавляющей массы граждан.
Покупка документа, который подтверждает окончание института, – это выгодное решение. Заказать диплом ВУЗа: [url=http://diplom-zakaz.ru/diplom-kupit-texnikum-3/]diplom-zakaz.ru/diplom-kupit-texnikum-3/[/url]
На данном этапе врач уточняет, сколько времени продолжается запой, какой алкоголь употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет разработать персональный план детоксикации, что значительно снижает риск осложнений.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]наркология вывод из запоя[/url]
купить светодиодный экран цена svetodiodnye-led-ekrany.ru/
светодиодная видеостена https://videostena-1.ru/
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Выяснить больше – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя в стационаре[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя недорого мурманск[/url]
купить зарегистрированный диплом [url=https://rusdiplomm-orig.ru/]rusdiplomm-orig.ru[/url] .
Заказать диплом университета по выгодной цене можно, обращаясь к надежной специализированной фирме. Приобрести документ университета вы сможете в нашей компании в Москве. [url=http://dip-lom-rus.ru/mozhno-li-kupit-diplom-v-reestre-8/]dip-lom-rus.ru/mozhno-li-kupit-diplom-v-reestre-8[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что способствует быстрому снижению уровня токсинов в крови, нормализации обменных процессов и стабилизации работы таких органов, как печень, почки и сердце.
Детальнее – https://vyvod-iz-zapoya-murmansk00.ru/vyvod-iz-zapoya-na-domu-murmansk/
I know it’s a bit of a side note, but still wanted to mention it
A little earlier I stumbled on a site called [url=https://talabout.com] Talabout[/url].
It’s full of raw talks with people from all walks of life — thoughtful, not your typical media stuff.
Sometimes the vibe there strangely mirrors the stuff being shared here.
Ever read anything there?
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя улан-удэ[/url]
Оперативное лечение организовано по четкому алгоритму, который позволяет быстро стабилизировать состояние пациента и обеспечить эффективную терапию. Каждый этап направлен на комплексное восстановление организма.
Получить больше информации – [url=https://vyvod-iz-zapoya-volgograd000.ru/]narkolog-vyvod-iz-zapoya volgograd[/url]
Купить диплом любого ВУЗа!
Наша компания предлагаетвыгодно и быстро приобрести диплом, который выполнен на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями. Наш документ способен пройти лубую проверку, даже при использовании профессионального оборудования. Достигайте своих целей быстро и просто с нашими дипломами- [url=http://babygirls029.copiny.com/question/details/id/1087644/]babygirls029.copiny.com/question/details/id/1087644[/url]
Служба круглосуточного вывода из запоя организована таким образом, чтобы обеспечить максимальную оперативность и надежность. Независимо от времени суток, квалифицированные специалисты готовы выехать на дом или принять пациента в медицинском учреждении, чтобы приступить к детоксикации и стабилизации состояния.
Детальнее – https://vyvod-iz-zapoya-volgograd000.ru/vyvod-iz-zapoya-kapelnicza-volgograd
Запой — это опасное состояние, при котором организм человека подвергается сильной алкогольной интоксикации, а внутренние органы, такие как печень, сердце и почки, начинают работать в аварийном режиме. В такой момент самостоятельное лечение становится невозможным, и необходима оперативная помощь специалистов. Наркологическая клиника «Детоксика» в Сочи предлагает комплексный вывод из запоя с использованием современных методов терапии и индивидуального подхода, что позволяет быстро восстановить здоровье пациента и предотвратить серьезные осложнения.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому в сочи[/url]
Служба круглосуточного вывода из запоя организована таким образом, чтобы обеспечить максимальную оперативность и надежность. Независимо от времени суток, квалифицированные специалисты готовы выехать на дом или принять пациента в медицинском учреждении, чтобы приступить к детоксикации и стабилизации состояния.
Детальнее – [url=https://vyvod-iz-zapoya-volgograd000.ru/]наркология вывод из запоя в волгограде[/url]
Лечение вывода из запоя на дому в Улан-Удэ организовано по четко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Узнать больше – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]срочный вывод из запоя улан-удэ[/url]
Применение современных капельничных методов позволяет точно дозировать лекарственные средства. Постоянный мониторинг жизненно важных показателей пациента дает возможность оперативно корректировать терапию для достижения оптимального эффекта и предотвращения побочных реакций.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя в стационаре в волгограде[/url]
Помощь специалиста по выводу из запоя требуется, когда симптомы интоксикации становятся критическими. Обратите внимание на следующие признаки:
Узнать больше – [url=https://vyvod-iz-zapoya-sochi7.ru/]вывод из запоя на дому цена сочи[/url]
The popular service ai girlfriend offers to create an AI girl who understands you, can hold a conversation and even flirt. Ideal for those who are looking for emotions in a digital format.
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Выяснить больше – https://vyvod-iz-zapoya-ulan-ude00.ru/vyvod-iz-zapoya-kapelnicza-ulan-ude/
[url=https://chestnye-casino.ru]chestnye-casino.ru[/url]
На сайте, посвященном обзорам онлайн казино, вы найдете независимую оценку и рейтинг самых надежных игровых платформ. Здесь представлены только проверенные и лицензированные казино, прошедшие тщательную проверку экспертов. Вы узнаете о преимуществах и недостатках каждого заведения, получите информацию о бонусах, игровых автоматах, методах оплаты и качестве службы поддержки. Сайт поможет вам сделать осознанный выбор, чтобы играть в слоты на деньги в безопасной и честной среде, минимизируя риски и получая максимум удовольствия от игры. Кроме того, ресурс содержит полезные советы и стратегии, которые помогут вам повысить свои шансы на выигрыш и сделать процесс игры еще более увлекательным. Регулярное обновление обзоров и добавление новых казино позволит вам всегда быть в курсе актуальных предложений и выбрать именно то казино, которое подходит вашим потребностям и предпочтениям.
chestnye-casino.ru
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Углубиться в тему – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
Первый этап лечения — это детоксикация организма. При помощи капельничного введения специализированных препаратов достигается быстрый вывод токсинов, что позволяет стабилизировать обменные процессы и восстановить нормальное функционирование печени, почек и сердечно-сосудистой системы.
Детальнее – https://narcolog-na-dom-ufa0.ru
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]нарколог вывод из запоя[/url]
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Изучить вопрос глубже – http://vyvod-iz-zapoya-sochi7.ru/vyvod-iz-zapoya-cena-v-sochi/
Клиника «Детоксика» в Сочи специализируется на комплексном лечении запоя и восстановления здоровья пациентов с индивидуальным подходом. Наши преимущества:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi7.ru/]наркология вывод из запоя[/url]
Когда алкогольный запой угрожает здоровью, оперативное и квалифицированное вмешательство становится жизненно необходимым. В Улан-Удэ специалисты по наркологии оказывают помощь на дому, обеспечивая скорейшую детоксикацию организма, восстановление обменных процессов и стабилизацию работы внутренних органов. Такой подход позволяет пациенту получить комплексное лечение в комфортной домашней обстановке с полным соблюдением конфиденциальности.
Подробнее – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому республика бурятия[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по приятным ценам. Всегда стараемся поддерживать для заказчиков адекватную политику цен. Важно, чтобы дипломы были доступными для большинства наших граждан.
Приобретение диплома, подтверждающего окончание университета, – это выгодное решение. Заказать диплом о высшем образовании: [url=http://okdiplom.ru/vuz-diplom-kupit/]okdiplom.ru/vuz-diplom-kupit/[/url]
[url=https://official-zooma-casino.ru]official-zooma-casino.ru[/url]
На сайте, посвященном обзору официального сайта Zooma Casino, представлен исчерпывающий анализ платформы, призванный помочь игрокам принять обоснованное решение. Здесь вы найдете детальный разбор интерфейса и удобства использования, обзор доступных игр и их поставщиков, а также информацию о бонусной программе и условиях ее получения. Особое внимание уделено вопросам безопасности и лицензирования, чтобы убедиться в надежности и честности казино. Кроме того, в обзоре представлены данные о скорости выплат, доступных платежных методах и работе службы поддержки, что позволит вам составить полное представление о Zooma Casino и оценить его соответствие вашим требованиям и предпочтениям. Отзывы реальных пользователей помогут сформировать более объективное мнение и избежать возможных неприятных сюрпризов.
official-zooma-casino.ru
Первичный этап терапии направлен на оперативное выведение токсинов из организма. Врач-нарколог назначает индивидуальную схему медикаментозного вмешательства, что позволяет снизить уровень алкоголя в крови и восстановить обмен веществ.
Детальнее – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя на дому цена волгоград[/url]
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Узнать больше – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]срочный вывод из запоя в улан-удэ[/url]
Лечение на дому основывается на комплексном подходе, который включает медикаментозную детоксикацию и психологическую поддержку. Каждая терапевтическая процедура подбирается индивидуально с учетом клинической картины пациента, что позволяет добиться максимальной эффективности и безопасности лечения.
Узнать больше – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя в стационаре в волгограде[/url]
[url=https://frispiny-casino.ru]frispiny-casino.ru[/url]
На сайте, специализирующемся на обзорах онлайн-казино, вы найдете детальную информацию о предложениях фриспинов, предоставляемых при регистрации. Здесь собраны актуальные данные о самых выгодных и привлекательных акциях от различных игровых платформ. Вы узнаете, какие казино предлагают наибольшее количество бесплатных вращений, на каких слотах их можно использовать, и каковы условия их отыгрыша. Благодаря подробным обзорам, вы сможете сравнить различные предложения фриспинов и выбрать те, которые наилучшим образом соответствуют вашим потребностям и предпочтениям, чтобы начать игру с максимальной выгодой и возможностью сорвать крупный выигрыш без риска для собственных средств.
frispiny-casino.ru
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Разобраться лучше – https://vyvod-iz-zapoya-ulan-ude00.ru/vyvod-iz-zapoya-kapelnicza-ulan-ude
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Узнать больше – http://kapelnica-ot-zapoya-arkhangelsk00.ru
Когда запой начинает негативно влиять на здоровье, оперативное лечение становится залогом успешного выздоровления. В Архангельске, Архангельская область, квалифицированные наркологи предоставляют помощь на дому, позволяя быстро провести детоксикацию, восстановить нормальные обменные процессы и стабилизировать работу жизненно важных органов. Такой формат лечения обеспечивает индивидуальный подход, комфортную домашнюю обстановку и полную конфиденциальность, что особенно важно для пациентов, стремящихся к быстрому восстановлению без посещения стационара.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-arkhangelsk00.ru/kapelnicza-ot-zapoya-klinika-arkhangelsk/
Круглосуточная помощь
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки в краснодаре[/url]
купить диплом ржд [url=https://rusdiplomm-orig.ru/]rusdiplomm-orig.ru[/url] .
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому[/url]
Купить диплом университета по доступной цене возможно, обратившись к надежной специализированной фирме. Купить документ университета вы можете в нашем сервисе. [url=http://fastdiploms.com/kupit-diplom-s-registratsiej-v-reestre-bistro-i-udobno-7/]fastdiploms.com/kupit-diplom-s-registratsiej-v-reestre-bistro-i-udobno-7[/url]
Добрый день, друзья! Несколько месяцев назад я побывал в Италии, и там случилась забавная история. Мы с друзьями искали, где можно поужинать недорого, но вкусно. Вспомнил, что на [url=http://tripland.info/category/puteshestviya-po-miru/]сайте Tripland[/url] была рекомендация о небольших семейных ресторанчиках в Риме. Мы нашли одно из таких мест, и оно оказалось настоящим гастрономическим открытием! Хозяева даже подарили нам бутылку домашнего вина в качестве благодарности за визит. Это был вечер, который я запомню навсегда.
[url=frispiny-casino-registration.ru]frispiny-casino-registration.ru[/url]
На этом сайте вы найдете полный обзор фриспинов, предоставляемых онлайн казино при регистрации. Мы собрали актуальную информацию о самых щедрых предложениях, доступных новым игрокам. Вы узнаете, какие казино предлагают наибольшее количество бесплатных вращений, на каких слотах их можно использовать, и какие условия необходимо выполнить для вывода выигрышей. Подробные обзоры включают информацию о вейджерах, сроках действия фриспинов и других важных нюансах, которые помогут вам максимально выгодно воспользоваться этими бонусами. Мы поможем вам выбрать лучшее предложение и начать игру в онлайн казино с минимальными рисками и максимальными шансами на выигрыш. Сайт регулярно обновляется, чтобы вы всегда были в курсе самых свежих и выгодных акций.
frispiny-casino-registration.ru
Kyros Finance is redefining the DeFi investment landscape by offering secure, scalable, and high-yield crypto solutions. With a focus on decentralized financial tools, Kyros Finance provides users with staking, lending, and automated yield farming strategies to maximize returns. Whether you’re a retail investor or an institutional participant, Kyros Finance ensures efficient, transparent, and secure access to the world of decentralized finance. https://kyros.ink
Ищите место для отдыха? туры в иорданию из москвы 2025 Мы предлагаем увлекательные экскурсии по Иордании, комфортный отдых и маршруты по главным достопримечательностям Иордании. Не знаете, что посмотреть в Иордании? Начните с Петры, Вади Рам и Мёртвого моря!
Передовые методики
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому краснодар[/url]
Мы готовы предложить дипломы любой профессии по доступным ценам. Стараемся поддерживать для заказчиков адекватную ценовую политику. Важно, чтобы дипломы были доступными для подавляющей массы наших граждан.
Заказ документа, который подтверждает окончание института, – это выгодное решение. Купить диплом о высшем образовании: [url=http://diplommy.ru/mozhno-li-kupit-diplom-o-srednem-obrazovanii-2/]diplommy.ru/mozhno-li-kupit-diplom-o-srednem-obrazovanii-2/[/url]
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Разобраться лучше – https://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки на дому краснодар[/url]
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnicza-ot-zapoya-na-domu krasnodar[/url]
Upshift Finance is a next-generation decentralized trading platform designed to provide secure, fast, and efficient crypto transactions. With smart contract automation, low transaction fees, and seamless integration with DeFi protocols, Upshift Finance empowers traders to swap digital assets and execute trades with maximum security. Whether you’re a beginner or an experienced trader, Upshift Finance offers a powerful, transparent, and user-friendly trading ecosystem. https://upshift.ink
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Подробнее – http://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
motbet [url=https://mostbet7005.ru/]motbet[/url] .
купить медицинский диплом москва [url=https://rusdiplomm-orig.ru/]rusdiplomm-orig.ru[/url] .
Описание
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому краснодарский край[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]www.domen.ru[/url]
Say hello to AquaSculpt—a game-changer in weight loss! These AquaSculpt capsules use natural AquaSculpt ingredients to shed pounds and boost confidence. No AquaSculpt side effects, just pure AquaSculpt results—see why in AquaSculpt reviews. Learn AquaSculpt how to use and join thousands who love it. AquaSculpt buy today at https://aquasculpt.lifestyle !
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки краснодар[/url]
Круглосуточная помощь
Выяснить больше – https://kapelnica-ot-zapoya-krasnodar77.ru/
Преимущество
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снятие наркотической ломки[/url]
Круглосуточная помощь
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]вызвать капельницу от запоя на дому в краснодаре[/url]
Хто знає, де знайти хороші матеріали з Сочинения з української мови? Я ось знайшов тут – [url=https://ua-lib.ru]Сочинения з української мови[/url]!
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]врач на дом капельница от запоя в краснодаре[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому цена[/url]
Maybe not 100% in context, but felt like saying this
I a while back found a team called[url=https://sevenup.trance.mk.ua] sevenup.trance.mk.ua[/url].
They’re a professional esports team focused on Battle Tactics. From what I saw — sharp strategy, tight coordination, no chaos.
Ever seen their games?
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в сочи[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки[/url]
Круглосуточная помощь
Изучить вопрос глубже – http://kapelnica-ot-zapoya-krasnodar77.ru
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]postavit-kapelniczu-ot-zapoya krasnodar[/url]
провайдеры пермь
domashij-internet-perm001.ru
домашний интернет тарифы
мостбет войти [url=https://mostbet7005.ru]https://mostbet7005.ru[/url] .
Struggling to lose weight? AquaSculpt is transforming weight loss with its natural, fast-acting capsules. Packed with proven AquaSculpt ingredients, these capsules burn fat, boost energy, and deliver real AquaSculpt results in weeks. Curious about AquaSculpt reviews? Users love its effectiveness and zero AquaSculpt side effects. Want to know AquaSculpt how to use? It’s simple—take daily and watch the pounds melt away. Ready to try? AquaSculpt buy now at https://aquasculpt.one and sculpt your dream body today!
Круглосуточная помощь
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодарский край[/url]
Основные этапы лечения:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя анонимно[/url]
?? Looking for the Ultimate Live Nude Experience? ??
Join now and explore hot webcam shows – Watch, Chat & Interact Now! ??
Best Tips for Selecting a Live Nude Cam Site
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя[/url]
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому сочи[/url]
Запой — состояние, характеризующееся неконтролируемым и продолжительным употреблением алкоголя, что вызывает сильную интоксикацию организма и нарушения в работе жизненно важных органов. При длительном запое организм испытывает колоссальную нагрузку, страдает сердечно-сосудистая система, печень, почки, а нервная система работает на пределе. Одним из наиболее эффективных методов быстрого и безопасного выхода из запоя является капельница. Наркологическая клиника «Анти-Кризис» в Краснодаре оказывает срочную помощь и вывод из запоя за 24 часа, обеспечивая индивидуальный подход, полную анонимность и доступные цены.
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя краснодар[/url]
Снежные дюны Куршская коса экскурсия зимой особенно живописны.
Круглосуточная помощь
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков[/url]
Преимущество
Детальнее – http://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Преимущество
Подробнее – http://kapelnica-ot-zapoya-krasnodar77.ru
Специалисты направления рекламное агентство Витрувий настраивают таргетинг, создают уникальные визуалы, продвигают бизнес в конкурентной среде.
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Узнать больше – http://kapelnica-ot-zapoya-krasnodar77.ru
Круглосуточная помощь
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок краснодарский край[/url]
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Углубиться в тему – http://kapelnica-ot-zapoya-krasnodar777.ru/
провайдеры домашнего интернета пермь
domashij-internet-perm002.ru
подключить интернет
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]https://kapelnica-ot-zapoya-krasnodar7.ru[/url]
Приобрести диплом о высшем образовании!
Наша компания предлагаетвыгодно и быстро купить диплом, который выполнен на бланке ГОЗНАКа и заверен мокрыми печатями, водяными знаками, подписями. Документ способен пройти лубую проверку, даже с применением профессиональных приборов. Достигайте цели быстро и просто с нашим сервисом- [url=http://worldavtonew.ru/kupit-diplom-i-otkryivat-novyie-gorizontyi/]worldavtonew.ru/kupit-diplom-i-otkryivat-novyie-gorizontyi[/url]
Could a Cash Flow Statement Predict the Future Success of Online Educational Platforms?
У вас є проблеми зі збереженням грошей? Ось [url=https://justtips.online]топові лайфхаки[/url] для фінансової грамотності.
Преимущество
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]поставить капельницу от запоя краснодар[/url]
why not try these out https://noon.ad
Преимущество
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]снять ломку краснодар[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]https://snyatie-lomki-rnd7.ru/[/url]
Описание
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]snyatie lomki na domu krasnodar[/url]
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя цена[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому цена в сочи[/url]
недорогой интернет пермь
domashij-internet-perm003.ru
подключение интернета пермь
Гелиевые шары Липецк онлайн
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по выгодным ценам. Дипломы производят на фирменных бланках государственного образца Быстро купить диплом института [url=http://diplomg-cheboksary.ru/]diplomg-cheboksary.ru[/url]
Где купить диплом по необходимой специальности?
Приобрести диплом института по выгодной цене возможно, обращаясь к надежной специализированной компании.: [url=http://kazdiplomas.com/]kazdiplomas.com[/url]
Купить диплом о высшем образовании!
Мы предлагаемвыгодно приобрести диплом, который выполняется на бланке ГОЗНАКа и заверен печатями, штампами, подписями должностных лиц. Диплом способен пройти лубую проверку, даже при использовании профессиональных приборов. Решайте свои задачи быстро с нашим сервисом- [url=http://hellotointernet.com/read-blog/827_gde-kupit-diplom-s-reestrom.html/]hellotointernet.com/read-blog/827_gde-kupit-diplom-s-reestrom.html[/url]
Заказать диплом университета по доступной стоимости вы можете, обращаясь к надежной специализированной компании. Заказать документ о получении высшего образования можно у нас. [url=http://diplom-club.com/kupit-diplom-vuza-s-zaneseniem-v-reestr-bistro-i-legko-2/]diplom-club.com/kupit-diplom-vuza-s-zaneseniem-v-reestr-bistro-i-legko-2[/url]
look what i found https://hyperdrive.ink/
Где купить [b]диплом[/b] специалиста?
Готовый диплом с нужными печатями и подписями полностью отвечает запросам и стандартам, неотличим от оригинала – даже со специально предназначенным оборудованием. Не откладывайте свои мечты и цели на пять лет, реализуйте их с нами – отправьте заявку на диплом сегодня! Получить диплом о среднем специальном образовании – не проблема! [url=http://pirat.iboards.ru/viewtopic.phpf=20&t=34408/]pirat.iboards.ru/viewtopic.phpf=20&t=34408[/url]
подключить интернет в квартиру ростов
domashij-internet-rostov001.ru
провайдеры интернета в ростове
?Hola aventureros del azar
pero las internacionales aceptan PayPal, Neteller, Skrill, incluso Bitcoin.
Las casas de apuestas sin licencia permiten jugar sin lГmites de depГіsito, ideales para quienes buscan una experiencia sin restricciones. MГЎs libertad, mГЎs control.
Mas detalles en el enlace – п»їhttps://casasdeapuestassinlicenciaespana.xyz/
?Que tengas excelentes exitos!
Купить диплом университета!
Мы предлагаем документы об окончании любых ВУЗов России. Документы производят на фирменных бланках государственного образца. [url=http://kunokaacademy.com/employer/radiplomy/]kunokaacademy.com/employer/radiplomy[/url]
SPA-салон в Москве https://uslugi.yandex.ru/profile/BonSpa-3013256 предлагает массаж, пилинг, обёртывания, уход за кожей, антистресс-программы и релакс-процедуры. Работают сертифицированные специалисты, используется премиум-косметика. Уютная атмосфера, индивидуальный подход и удобное расположение в городе.
Discover Montenegro https://www.weather-webcam-in-montenegro.com/dobra-voda crystal clear sea, picturesque bays, mountain landscapes and ancient fortresses. The perfect destination for those looking for a combination of nature, history and relaxation. Detailed guides, recommendations, photos and route ideas.
мостбет кыргызстан [url=https://www.mostbet6013.ru]https://www.mostbet6013.ru[/url] .
[url=https://tournaments-casino.ru]tournaments-casino.ru[/url]
Турниры в онлайн-казино 2025: как участвовать с мобильного телефона
В 2025 году онлайн-казино предлагают множество захватывающих турниров с крупными призами. Если вы хотите испытать удачу и побороться за ценные награды, сделать это можно прямо с мобильного устройства. На нашем сайте собрана актуальная информация о самых ожидаемых турнирах, правилах участия и стратегиях для победы.
Популярные турниры 2025 года
В этом сезоне игроков ждут:
Слоты-баттлы – соревнования на самых популярных автоматах с прогрессивными джекпотами.
Покерные серии – турниры с гарантированными призовыми фондами.
Рулетка на время – скоростные раунды с дополнительными бонусами.
Ежедневные фрироллы – бесплатные турниры с реальными денежными призами.
Как участвовать с телефона?
Выберите надежное казино – на сайте представлен рейтинг лицензированных платформ с мобильной версией.
Скачайте приложение или играйте в браузере – большинство казино адаптированы под iOS и Android.
Зарегистрируйтесь и пополните счет – некоторые турниры требуют минимального депозита.
Найдите раздел “Турниры” – там указаны условия, расписание и призовые фонды.
Начните играть и следите за таблицей лидеров – чем выше ваша позиция, тем больше шансов на победу.
Советы для успешной игры
Изучите правила каждого турнира – иногда важны не только выигрыши, но и количество ставок.
Используйте бонусы – многие казино дают бесплатные спины или кэшбэк для участников.
Следите за обновлениями – новые турниры появляются регулярно.
Хотите узнать больше? Переходите по ссылке и читайте полный обзор турниров 2025 года с подробными инструкциями по участию.tournaments-casino.ru
read https://aquasculpt.xyz/
скачать mostbet на телефон [url=https://www.mostbet6013.ru]https://www.mostbet6013.ru[/url] .
подключить интернет в квартиру ростов
domashij-internet-rostov002.ru
провайдеры домашнего интернета ростов
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Узнать больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя анонимно сочи[/url]
Разыскиваете надежную помощь в уборке вашей в Санкт-Петербурге? Наша группа специалистов дает гарантию чистоту и и порядок в вашем доме! Мы применяем только безопасные и эффективные средства, чтобы вы могли вкушать свежестью без хлопот. Жмите https://chisto-v-srok.ru
?Hola usuarios de apuestas
casasdeapuestassinlicenciaespana.xyz
Las casas de apuestas internacionales aceptan jugadores de EspaГ±a aunque no tengan licencia local. Su enfoque global les permite ofrecer mГЎs variedad y mГ©todos de pago modernos.
Casas de apuestas casino con juegos en vivo y tragaperras – п»їhttps://casasdeapuestassinlicenciaespana.xyz/
?Que tengas excelentes exitos!
провайдеры интернета в ростове
domashij-internet-rostov003.ru
интернет домашний ростов
Передовые методики
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки в краснодаре[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Детальнее – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi/
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в краснодаре[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя цена сочи[/url]
Discover Montenegro holidays Herceg Novi crystal clear sea, picturesque bays, mountain landscapes and ancient fortresses. The perfect destination for those looking for a combination of nature, history and relaxation. Detailed guides, recommendations, photos and route ideas.
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки в краснодаре[/url]
Гелиевые шары в Липецке на рождение ребенка
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi777.ru/]narkolog-vyvod-iz-zapoya sochi[/url]
подарочная карта выбрать подарочная карта с балансом
Онлайн-сервис профилей соцсетей (Facebook, Instagram, TikTok, Telegram и др.) является необходимый инструмент для тех, кто занимается цифровому маркетингу, арбитражу или продвижению в соцсетях. Такие площадки позволяют оперативно закрывать вопросы банами аккаунтов, потребностью в большом количестве профилей и избежать долгого и часто рискованного самостоятельного фарма. Ключевые плюсы таких платформ например, профиль с подписчиками: обеспечение надежности сделок благодаря систему гаранта, экономия ресурсов, обширный выбор профилей под любые цели и легкость масштабирования. Однако, для безопасной работы, необходимо выбирать только проверенные сервисы с хорошей репутацией, применять качественные индивидуальные прокси и антидетект-браузеры для каждого аккаунта и не пренебрегать этапу прогрева приобретенных профилей перед активным использованием.
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снять ломку[/url]
Маркетплейс профилей социальных сетей (Facebook, Instagram, TikTok, Telegram и др.) является эффективный инструмент для специалистов по арбитражу трафика, SMM или продвижению в соцсетях. Такие площадки позволяют быстро закрывать проблемы с блокировками, необходимостью масштабирования а также минуя затратного по времени и часто рискованного самостоятельного фарма. Ключевые преимущества таких платформ как магазин аккаунтов: гарантия безопасности покупки и продажи благодаря систему гаранта, экономия времени, широкий выбор аккаунтов (фарм) и простота увеличения объемов. Чтобы минимизировать рисков, критически важно выбирать только проверенные биржи с хорошей репутацией, обязательно использовать антидетект системы и уникальные прокси для работы с профилями а также уделять должное внимание этапу прогрева приобретенных аккаунтов перед активным использованием.
Описание
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]lomka ot narkotikov krasnodar[/url]
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi777.ru/]vyvod-iz-zapoya sochi[/url]
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]срочный вывод из запоя сочи[/url]
Преимущество
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок краснодар.[/url]
домашний интернет омск
domashij-internet-volgograd001.ru
домашний интернет в волгограде
important link https://flaunch.tech/
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в стационаре в краснодаре[/url]
Описание
Разобраться лучше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок в краснодаре[/url]
Такой магазин аккаунтов, как birzha-akkauntov-online.ru – необходимый инструмент специалистов по арбитражу трафика.
Они помогают без лишних усилий закрывать потребность в масштабировании аккаунтов и минуя трудоемкого фарминга.
Ключевые плюсы подобных сервисов:
– Обеспечение надежности покупок через систему гаранта
– Значительная экономия времени и усилий
– Большой ассортимент профилей для разных целей — от авторегов до прогретых с историей
– Легкость работы с крупными объемами
Чтобы получить максимальную отдачу, рекомендуется:
– Выбирать только проверенные платформами с прозрачными правилами
– Использовать надежные прокси (резидентные) и антидетект-браузеры с уникальными фингерпринтами
– Не пренебрегать прогреву новых аккаунтов
[url=https://install-champion-casino.ru]install-champion-casino.ru[/url]
Если вам интересно ознакомиться с инструкциями по установке приложений на мобильные устройства, мы можем предложить общий гайд.
Как установить приложения на Android и iOS
Установка мобильных приложений зависит от операционной системы вашего устройства.
Для Android:
Откройте файл APK — если приложение недоступно в Google Play, его можно скачать через официальный сайт.
Разрешите установку из неизвестных источников — зайдите в Настройки > Безопасность и активируйте соответствующую опцию.
Запустите установку и следуйте инструкциям.
Для iOS:
Скачайте приложение из App Store — большинство сервисов доступны через официальный магазин.
Используйте TestFlight или корпоративный сертификат — если приложение не опубликовано в App Store.
Разрешите установку — в настройках iPhone перейдите в раздел VPN и управление устройствами и подтвердите доверие к разработчику.
Если вас интересует конкретное приложение, проверьте его официальный сайт или магазин приложений. Но помните о безопасности: скачивайте ПО только из проверенных источников, чтобы избежать мошенничества.
Хотите узнать больше? Читайте дополнительные инструкции на сайте по ссылке ниже.install-champion-casino.ru
cars vehicle transport move car across country
Описание
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому краснодар[/url]
Современные методики
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi7.ru/]vyvod-iz-zapoya-sochi7.ru/[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]https://snyatie-lomki-rnd7.ru/[/url]
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]снятие наркотической ломки в краснодаре[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодарский край[/url]
Описание
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому недорого[/url]
мосбет казино [url=http://mostbet6013.ru/]http://mostbet6013.ru/[/url] .
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя клиника краснодар[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Получить больше информации – [url=https://snyatie-lomki-rnd77.ru/]снятие наркотической ломки краснодар[/url]
Преимущество
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]snyatie lomki narkozavisimogo krasnodar[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому[/url]
Мы изготавливаем дипломы любой профессии по доступным ценам.– [url=http://diplom-top.ru/diplom-s-zaneseniem-v-reestr-bistro-i-bez-lishnix-problem/]diplom-top.ru/diplom-s-zaneseniem-v-reestr-bistro-i-bez-lishnix-problem/[/url]
Описание
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана[/url]
подключить проводной интернет омск
domashij-internet-volgograd002.ru
подключить домашний интернет омск
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки краснодар[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]snyat lomku krasnodar[/url]
Заказать диплом о высшем образовании!
Мы можем предложить документы учебных заведений, которые находятся на территории всей Российской Федерации.
[url=http://diplom-onlinex.com/kupit-diplom-o-srednem-obrazovanii-v-reestr-bistro-3/]diplom-onlinex.com/kupit-diplom-o-srednem-obrazovanii-v-reestr-bistro-3/[/url]
Платформа birzha-akkauntov-online.ru – проверенное решение для специалистов по арбитражу трафика.
Подобные ресурсы позволяют быстро обходить ограничения соцсетей и минуя самостоятельного фарма.
Сильные плюсы подобных сервисов:
– Гарантия надежности сделок через систему гаранта
– Значительная экономия времени и усилий
– Большой ассортимент профилей для любых задач — от дешевых до прогретых с историей
– Простота масштабирования
Чтобы избежать проблем, рекомендуется:
– Пользоваться авторитетными платформами с прозрачными правилами
– Использовать надежные прокси (резидентные) и инструменты анонимизации
– Не пренебрегать аккуратной подготовке перед запуском рекламы
Преимущество
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врача капельницу от запоя краснодар[/url]
Круглосуточная помощь
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана в краснодаре[/url]
Описание
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки краснодар[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Получить больше информации – [url=https://snyatie-lomki-rnd77.ru/]www.domen.ru[/url]
Описание
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркозависимого[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в стационаре в краснодаре[/url]
Круглосуточная помощь
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана краснодар[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Выяснить больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок[/url]
Описание
Подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого краснодар[/url]
next page https://aquasculpt.best/
[url=https://sukaaa-casino-slots.ru]sukaaa-casino-slots.ru[/url]
Обзор игровой платформы Sukaa 2025
В 2025 году Sukaa остается одной из популярных международных игровых платформ, привлекающей внимание пользователей из разных стран. На нашем сайте представлен детальный обзор особенностей данного ресурса.
Основные характеристики:
Лицензия: международная (Кюрасао)
Валюта: поддерживаются рублевые транзакции
Игровой софт: представлены слоты, настольные игры, live-дилеры
Мобильная версия: адаптирована под iOS и Android
Особенности платформы:
Бонусная программа для новых пользователей
Регулярные турниры с призовыми фондами
Система лояльности для постоянных клиентов
Важно учитывать:
Платформа не имеет российской лицензии
Доступ может быть ограничен интернет-провайдерами
Рекомендуется проверять актуальность информации на официальном сайте
Альтернативы:
Для российских пользователей доступны легальные варианты:
Официальные лотереи (Столото)
Социальные игровые приложения
Напоминание: Азартные игры могут вызывать зависимость. Играйте ответственно. 18+
Полную информацию о платформе Sukaa вы найдете на сайте по ссылке.sukaaa-casino-slots.ru
нажмите здесь [url=https://lk-mango-office.com]Mango-Office кабинет[/url]
Преимущество
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок[/url]
провайдеры омск
domashij-internet-volgograd003.ru
провайдеры интернета омск
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому краснодар.[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому краснодар[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки нарколог краснодар[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]снять ломку[/url]
Воздушные шары в Липецке светящиеся
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]snyat lomku krasnodar[/url]
long distance towing transporting cars for dealerships
гифт карта подарочные карты дешево
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Изучить вопрос глубже – https://snyatie-lomki-rnd7.ru/
Преимущество
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому цена краснодар[/url]
Мы можем предложить дипломы любой профессии по выгодным тарифам. Дипломы производятся на настоящих бланках Заказать диплом любого ВУЗа [url=http://diplomg-cheboksary.ru/]diplomg-cheboksary.ru[/url]
Где купить диплом специалиста?
Заказать диплом ВУЗа по невысокой цене вы можете, обращаясь к надежной специализированной компании.: [url=http://ry-diplom.com/]ry-diplom.com[/url]
баланс 1win [url=https://1win712.ru]https://1win712.ru[/url] .
Купить диплом ВУЗа!
Мы предлагаем документы ВУЗов, расположенных на территории всей России.
[url=http://diplomist.com/kupit-nastoyashij-diplom-o-visshem-obrazovanii/]diplomist.com/kupit-nastoyashij-diplom-o-visshem-obrazovanii/[/url]
домашний интернет
domashij-internet-voronezh001.ru
домашний интернет тарифы воронеж
1win ставки официальный сайт [url=https://1win712.ru]https://1win712.ru[/url] .
содержание [url=https://lk-mango-office.com]Mango-Office облачная телефония[/url]
Заказать диплом о высшем образовании!
Наша компания предлагаетвыгодно приобрести диплом, который выполняется на оригинальном бланке и заверен мокрыми печатями, водяными знаками, подписями. Данный документ пройдет любые проверки, даже при использовании профессиональных приборов. Решите свои задачи быстро с нашим сервисом- [url=http://ls.co-x.ru/2025/04/13/diplomy-kotorye-otkroyut-dveri-k-novym-vozmozhnostyam.html/]ls.co-x.ru/2025/04/13/diplomy-kotorye-otkroyut-dveri-k-novym-vozmozhnostyam.html[/url]
Мы изготавливаем дипломы любой профессии по доступным тарифам. Мы можем предложить документы ВУЗов, расположенных на территории всей Российской Федерации. Документы делаются на “правильной” бумаге самого высшего качества. Это позволяет делать настоящие дипломы, которые невозможно отличить от оригинала. [url=http://universalnetworks.works/read-blog/1819_kupit-diplom-s-zaneseniem-v-reestr-otzyvy.html/]universalnetworks.works/read-blog/1819_kupit-diplom-s-zaneseniem-v-reestr-otzyvy.html[/url]
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnica-ot-zapoya-krasnodar777.ru/[/url]
Такой магазин аккаунтов, как birzha-akkauntov-online.ru – проверенное решение для SMM-щиков, работающих с соцсетями.
Они позволяют быстро закрывать потребность в масштабировании аккаунтов и минуя самостоятельного фарма.
Сильные плюсы подобных сервисов:
– Обеспечение безопасности сделок через систему гаранта
– Значительная экономия времени и усилий
– Широкий выбор аккаунтов для любых задач — от авторегов до трастовых с историей
– Легкость работы с крупными объемами
Чтобы обеспечить стабильную работу, рекомендуется:
– Пользоваться авторитетными платформами с прозрачными правилами
– Применять чистые прокси (мобильные) и инструменты анонимизации
– Не пренебрегать аккуратной подготовке перед запуском рекламы
Приобрести диплом о высшем образовании !
Приобретение диплома любого ВУЗа РФ в нашей компании является надежным процессом, так как документ будет заноситься в государственный реестр. Приобрести диплом о высшем образовании [url=http://asxdiplommy.com/kupit-diplom-s-zaneseniem-v-reestr-bistro-i-nadezhno-72/]asxdiplommy.com/kupit-diplom-s-zaneseniem-v-reestr-bistro-i-nadezhno-72[/url]
Хорошо быть студентом, пока не придет пора писать диплом, что и произошло со мной, но не стоит отчаиваться, ведь есть хорошие компании что помогают с написанием и сдачей диплома на хорошие оценки!
Изначально искал информацию про купить диплом ржд, купить диплом учебного заведения, купить дипломы по годам, куплю диплом дней, нея диплом купить, потом попал на [url=http://diplomybox.com/kontakty/]diplomybox.com/kontakty[/url]
Betriot Casino e la scelta perfetta per i giocatori italiani gioca su Betriot Casino dove troverai tutti i tuoi giochi preferiti.
читать [url=https://lk-mango-office.com/]Mango-Office официальный сайт[/url]
Купить диплом ВУЗа по доступной стоимости можно, обращаясь к проверенной специализированной фирме. Мы оказываем услуги по производству и продаже документов об окончании любых ВУЗов РФ. Купить диплом о высшем образовании– [url=http://diplomservis.ru/kupit-diplom-visshego-obrazovaniya-s-zaneseniem-bistro-3/]diplomservis.ru/kupit-diplom-visshego-obrazovaniya-s-zaneseniem-bistro-3/[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков[/url]
Круглосуточная помощь
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]после капельницы от запоя краснодар[/url]
I’m not sure why but this weblog is loading extremely slow for me. Is anyone else having this issue or is it a problem on my end? I’ll check back later and see if the problem still exists.
https://news-trading.com/
Is it possible for online courses to fully prepare Std 10 CBSE students for their exams, or is there a limit to how effective online learning can be in this context? [url=https://www.bizmaker.org/vilnius/business-services/esim-plus-279909]Website[/url] my page
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Выяснить больше – http://vyvod-iz-zapoya-sochi777.ru
Платформа профиль с подписчиками – эффективный ресурс вебмастеров.
Они позволяют без лишних усилий закрывать потребность в масштабировании аккаунтов и избежать самостоятельного фарма.
Основные плюсы таких платформ:
– Обеспечение безопасности сделок через эскроу-механизм
– Существенная экономия ресурсов
– Широкий выбор аккаунтов для любых задач — от дешевых до трастовых с историей
– Простота масштабирования
Чтобы обеспечить стабильную работу, необходимо:
– Выбирать только проверенные платформами с прозрачными правилами
– Применять чистые прокси (мобильные) и антидетект-браузеры с уникальными фингерпринтами
– Уделять внимание прогреву новых аккаунтов
Гелиевые шарики Липецк на день рожденье
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого[/url]
Преимущество
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]снять ломку[/url]
Сайт comatozze.com удивил качеством. Каждое видео comatozze — произведение искусства. Удобный просмотр и топовая актриса comatozze. Актриса comatozze покорила своей искренностью. Присоединился к фанатам comatozze. Тот самый контент — comatozze forever. Качество видео просто отличное — comatozze. Теперь понимаю, почему comatozze так популярна. Глубоко, красиво и чувственно — это всё comatozze [url=https://comatozze-onlyfans.ru/]comatozze толькоfans[/url].
book comic read comics HD online free
manga demon HD manga reader online
Круглосуточная помощь
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]snyatie lomki narkozavisimogo krasnodar[/url]
Online clicker for kids in browser!
http://biznas.com/Biz-postsm356572_Fun-games-for-kids.aspx#post356572
Круглосуточная помощь
Узнать больше – http://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd/https://snyatie-lomki-rnd7.ru
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки на дому в краснодаре[/url]
Licensed online casino jetx bet popular slot machines, live dealers, promotions and bonuses. User-friendly interface, quick registration, many payment systems and 24/7 support. Play your favorite games and win without leaving your home.
Aviator Bangladesh https://webyourself.eu/blogs/748343/where-to-play-aviator-in-bangladesh-find-the-best-online is your gateway to fun and fast gaming! No complex rules — just launch, bet, and cash out on time. Supported by leading Bangladeshi casinos, with BDT payments and full mobile access. Join and win anytime, anywhere.
Описание
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркозависимого в краснодаре[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому цена сочи[/url]
Преимущество
Получить дополнительные сведения – http://kapelnica-ot-zapoya-krasnodar77.ru
Уровень съёмки у comatozze как в кино. Смотрю только comatozze сейчас. Каждый раз как впервые — спасибо comatozze. Композиция и свет — comatozze на высоте. Видео comatozze лучше любого кино. Тот самый контент — comatozze forever. Все ролики comatozze разные, но все крутые. Теперь понимаю, почему comatozze так популярна. Лучшая актриса в своей нише — comatozze [url=https://comatozze-onlyfans.ru/]comatozze онлайн[/url].
Специализированный магазин аккаунтов birzha-akkauntov-online.ru – проверенное решение для специалистов по привлечению трафика, SMM, интернет-маркетингу.
Подобные ресурсы помогают оперативно закрывать потребность в масштабировании аккаунтов и избежать трудоемкого фарминга.
Сильные плюсы подобных сервисов:
– Гарантия надежности сделок через эскроу-механизм
– Значительная экономия ресурсов
– Широкий выбор аккаунтов для любых задач — от авторегов до трастовых с историей
– Легкость работы с крупными объемами
Чтобы обеспечить стабильную работу, рекомендуется:
– Пользоваться авторитетными платформами с хорошими отзывами
– Применять надежные прокси (мобильные) и антидетект-браузеры с уникальными фингерпринтами
– Уделять внимание прогреву новых аккаунтов
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя капельница[/url]
Hey! Do you know if they make any plugins to assist with SEO? I’m trying to get my blog to rank for some targeted keywords but I’m not seeing very good success. If you know of any please share. Thank you!
crypto news
[b]Диплом ВУЗа РФ![/b]
Без ВУЗа очень нелегко было продвинуться вверх по карьерной лестнице. Именно из-за этого решение о покупке диплома следует считать выгодным и рациональным. Приобрести диплом об образовании [url=http://buzzorbit.com/profile/leandroe258152/]buzzorbit.com/profile/leandroe258152[/url]
Купить диплом университета!
Мы можем предложить дипломы любых профессий по доступным ценам. Вы покупаете документ через надежную фирму. : [url=http://timviecvtnjob.com/employer/frees-diplom/]timviecvtnjob.com/employer/frees-diplom[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в стационаре сочи[/url]
Awesome things here. I am very satisfied to look your post. Thanks a lot and I’m having a look ahead to contact you. Will you please drop me a e-mail?
all about crypto
Передовые методики
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок в краснодаре[/url]
Открыл для себя comatozze — это нечто особенное. Потрясающее исполнение от comatozze. Лучшая эротика на comatozze.com. Видео comatozze хочется пересматривать снова и снова. Идеальная подача чувственности — comatozze. Если вы цените эстетику — comatozze ваш выбор. Спасибо создателям за comatozze. Каждый кадр в comatozze продуман. Сценарии и эмоции — всё на высоте у comatozze [url=https://comatozze-onlyfans.ru/]comatozze full[/url].
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому круглосуточно[/url]
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi777.ru/]vyvod-iz-zapoya-kruglosutochno sochi[/url]
Круглосуточная помощь
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому цена[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки нарколог[/url]
Доставка воды в Виннице на сайте Wellsprings.com.ua
Play Aviator Game https://www.printables.com/@aleksandrb_2959899 online and win real money! Easy to play, exciting crash mechanics, fast rounds, and instant cashouts. Trusted by thousands of players worldwide — start now and catch the multiplier before it flies away!
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]lomka ot narkotikov krasnodar[/url]
Преимущество
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркозависимого в краснодаре[/url]
Такой магазин аккаунтов, как аккаунты с балансом – это ключевой помощник SMM-щиков, работающих с соцсетями.
Такие площадки помогают без лишних усилий решать задачи с блокировками аккаунтов и избежать затратного по времени фарминга.
Основные преимущества подобных сервисов:
– Обеспечение надежности сделок через эскроу-механизм
– Существенная экономия времени и усилий
– Большой ассортимент профилей для разных целей — от авторегов до трастовых с историей
– Легкость работы с крупными объемами
Чтобы избежать проблем, необходимо:
– Выбирать только проверенные платформами с хорошими отзывами
– Применять надежные прокси (резидентные) и инструменты анонимизации
– Не пренебрегать прогреву новых аккаунтов
Лучшее, что видел в жанре — comatozze. Откровенные сцены comatozze — просто вау. Для поклонников качественной съемки — только comatozze. Смотреть comatozze одно удовольствие. Присоединился к фанатам comatozze. Если вы цените эстетику — comatozze ваш выбор. Приятно смотреть — comatozze умеет. Подача просто огонь — коматоцце в топе. Сценарии и эмоции — всё на высоте у comatozze [url=https://comatozze-onlyfans.ru/]все видео comatozze[/url].
Hi to all, how is all, I think every one is getting more from this web page, and your views are fastidious in support of new visitors.
Промокоды на CSGOFast
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]snyatie lomki na domu krasnodar[/url]
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]снять ломку краснодар[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd77.ru/]snyat lomku krasnodar[/url]
Описание
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки нарколог[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки в краснодаре[/url]
Сайт comatozze.com удивил качеством. Любителям необычного понравится comatozze. Отличный сайт с контентом comatozze. Мощная подача от comatozze. Атмосфера у comatozze уникальна. Не думал, что найду такой уровень — comatozze. Спасибо создателям за comatozze. Если хотите эстетики — заходите на comatozze. Comatozze — это новое слово в жанре [url=https://comatozze-onlyfans.ru/]comatozze видео[/url].
Описание
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому краснодарский край[/url]
Круглосуточная помощь
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков город[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Изучить вопрос глубже – https://snyatie-lomki-rnd7.ru/
Преимущество
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]lomka ot narkotikov krasnodar[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому в краснодаре[/url]
Преимущество
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодар[/url]
Описание
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков город[/url]
Описание
Детальнее – https://snyatie-lomki-rnd7.ru/snyatie-lomki-na-domu-v-rnd
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Разобраться лучше – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки краснодар[/url]
i thought about this https://aquasculpt.me/
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Выяснить больше – [url=https://snyatie-lomki-rnd7.ru/]снять ломку в краснодаре[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя цена краснодарский край[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снять ломку в краснодаре[/url]
Круглосуточная помощь
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]поставить капельницу от запоя[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Детальнее – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-anonimno-v-sochi/
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]snyatie lomki krasnodar[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-sochi777.ru/
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Изучить вопрос глубже – https://vyvod-iz-zapoya-sochi777.ru/
Описание
Получить больше информации – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки краснодар[/url]
Сложно оторваться от comatozze xxx видео. Настоящая находка — коматоцце. Для поклонников качественной съемки — только comatozze. Ничего лишнего, только огонь — comatozze. Актерская игра впечатлила — comatozze. Каждое видео comatozze на уровне кино. Спасибо создателям за comatozze. Сайт comatozze работает отлично. Лучшая актриса в своей нише — comatozze [url=https://comatozze-onlyfans.ru/]comatozze.com видео[/url].
тест на мефедрон цена порно тг
нові фільми 2025 безкоштовно українські фільми онлайн HD
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок в краснодаре[/url]
Описание
Углубиться в тему – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd
Лучшее, что видел в жанре — comatozze. Откровенные сцены comatozze — просто вау. Все эмоции на лице — comatozze неподражаема. Качество лучше, чем у многих студий — comatozze. Люблю эстетику — comatozze как раз то. Если вы цените эстетику — comatozze ваш выбор. Все ролики comatozze разные, но все крутые. Каждый кадр в comatozze продуман. Восторг! Comatozze — это вау [url=https://comatozze-onlyfans.ru/]comatozze полный сборник[/url].
Преимущество
Выяснить больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок в краснодаре[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана в краснодаре[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому недорого[/url]
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi/https://vyvod-iz-zapoya-sochi777.ru
Передовые методики
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана краснодар[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок на дому[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому краснодар.[/url]
Уровень съёмки у comatozze как в кино. Оцените comatozze full videos — кайф. Каждый раз как впервые — спасибо comatozze. Мощная подача от comatozze. Это стоит каждого мегабайта — comatozze видео. Каждое видео comatozze на уровне кино. Спасибо создателям за comatozze. Увидел коматоцце случайно и остался. Лучшая актриса в своей нише — comatozze [url=https://comatozze-onlyfans.ru/]comatozze videos[/url].
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок в краснодаре[/url]
Воздушные шары в Липецке светящиеся
Описание
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодар.[/url]
Для ценителей красивой эротики — comatozze. Потрясающее исполнение от comatozze. Для поклонников качественной съемки — только comatozze. Композиция и свет — comatozze на высоте. Присоединился к фанатам comatozze. Честно — comatozze стала для меня открытием. Качество видео просто отличное — comatozze. Если хотите эстетики — заходите на comatozze. Настоящая работа над образом — comatozze [url=https://comatozze-onlyfans.ru/]comatozze онлайн[/url].
Описание
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя цена[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]снять ломку[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки нарколог краснодар[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Детальнее – http://
Открыл для себя comatozze — это нечто особенное. Каждое видео comatozze — произведение искусства. Лучшая эротика на comatozze.com. Смотреть comatozze одно удовольствие. Моя новая зависимость — comatozze full. Коматоцце — это не просто видео, это стиль. Открытие года — comatozze. Теперь понимаю, почему comatozze так популярна. Глубоко, красиво и чувственно — это всё comatozze [url=https://comatozze-onlyfans.ru/]comatozze pornstar[/url].
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в стационаре сочи[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана в краснодаре[/url]
Сайт comatozze.com удивил качеством. Потрясающее исполнение от comatozze. Отличный сайт с контентом comatozze. Подача, эмоции, кадры — всё на высоте. Идеальная подача чувственности — comatozze. Каждое видео comatozze на уровне кино. Открытие года — comatozze. Всё чётко — удобно, быстро, качественно. Теперь советую всем — comatozze это must [url=https://comatozze-onlyfans.ru/]comatozze fans[/url].
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому краснодарский край[/url]
Описание
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок в краснодаре[/url]
Записался на татуировку мечты — оставалось доплатить 6 000. Пошёл в Google искать, где перехватить. Увидел Telegram-канал [url=https://t.me/s/mfo_2024_online]новые займы без кредитной истории[/url] — сразу подписался. Рейтинг новых МФО по лояльности — это что-то! Заявку заполнил за 3 минуты, деньги получил за 15. Всё работает.
Приобретение документа о высшем образовании через надежную фирму дарит ряд достоинств для покупателя. Такое решение позволяет сэкономить как личное время, так и существенные финансовые средства. Тем не менее, достоинств значительно больше.Мы предлагаем дипломы любых профессий. Дипломы изготавливаются на оригинальных бланках. Доступная цена по сравнению с огромными затратами на обучение и проживание. Приобретение диплома ВУЗа станет целесообразным шагом.
Купить диплом о высшем образовании: [url=http://diplomers.com/visshee-obrazovanie-kupit-diplom-s-zaneseniem-5/]diplomers.com/visshee-obrazovanie-kupit-diplom-s-zaneseniem-5/[/url]
[url=https://top-casino-rus.ru]top-casino-rus.ru[/url]
В 2025 году российские пользователи проявляют повышенный интерес к онлайн-развлечениям, включая легальные игровые платформы. На нашем сайте представлен актуальный рейтинг проверенных сервисов, соответствующих требованиям законодательства.
Критерии отбора
В наш обзор включены только ресурсы, которые:
Имеют международные лицензии (Кюрасао, Мальта)
Поддерживают рублевые платежи
Предлагают SSL-шифрование данных
Имеют положительную репутацию среди пользователей
Топ-3 легальные платформы
“Клуб азартных игр” – лицензионный проект с ежедневными турнирами
“Игровой портал” – платформа с прозрачными выплатами
“Развлекательный центр” – сервис с системой ответственной игры
Важная информация
Согласно российскому законодательству:
Организация азартных игр в интернете запрещена
Доступ к международным платформам ограничен
Игра на незаконных сайтах влечет ответственность
Альтернативные развлечения
Мы рекомендуем рассмотреть легальные варианты:
Официальные лотереи (Столото)
Социальные казино без реальных ставок
Игровые приложения с виртуальной валютой
Важно: Напоминаем о рисках игровой зависимости. Если вы или ваши близкие столкнулись с этой проблемой, обратитесь в специализированные центры помощи.
Для получения полной информации о легальных игровых возможностях в 2025 году посетите сайт по ссылке.top-casino-rus.ru
Для ценителей красивой эротики — comatozze. Каждое видео comatozze — произведение искусства. Удобный просмотр и топовая актриса comatozze. Подача, эмоции, кадры — всё на высоте. Идеальная подача чувственности — comatozze. Эротика и искусство сочетаются у comatozze. Забыл про все другие сайты — только comatozze. Всё чётко — удобно, быстро, качественно. Лучшая актриса в своей нише — comatozze [url=https://comatozze-onlyfans.ru/]коматоцце[/url].
Круглосуточная помощь
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
Преимущество
Подробнее тут – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки краснодар[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки[/url]
Преимущество
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в стационаре краснодар[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодарский край[/url]
Круглосуточная помощь
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодар[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки в краснодаре[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя недорого сочи[/url]
[url=https://create-casino.ru]create-casino.ru[/url]
Создать онлайн-казино в 2025? Это сложный процесс, требующий лицензии, надежного софта, безопасности и маркетинга. Необходимо учитывать законодательство, конкуренцию и ответственный подход к азартным играм. Узнайте больше о ключевых этапах и подводных камнях. Читайте подробнее по ссылке ниже
create-casino.ru
Описание
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd7.ru/]http://snyatie-lomki-rnd7.ru/[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана краснодар[/url]
Круглосуточная помощь
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому цена краснодар[/url]
Преимущество
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому в краснодаре[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана в краснодаре[/url]
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Подробнее тут – https://vyvod-iz-zapoya-sochi777.ru/
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]поставить капельницу от запоя в краснодаре[/url]
Преимущество
Исследовать вопрос подробнее – http://snyatie-lomki-rnd77.ru/snyatie-lomki-narkomana-v-rnd/https://snyatie-lomki-rnd77.ru
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки на дому краснодар[/url]
Гелиевые шары в Липецке на юбилей
фільми в якості 2025 HD фільми українською онлайн
фільми 2025 вже вийшли українське кіно онлайн 2025
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя наркология краснодар[/url]
Нужно было 17 000 рублей на установку нового газа в авто. Начал искать, где взять займ быстро и без лишних вопросов. В Google наткнулся на Telegram-канал [url=https://t.me/s/mfo_2024_online]мфо деньги в долг без процентов[/url] — и это был джекпот! Там свежий рейтинг новых МФО 2025 года, много малоизвестных компаний, которые реально дают даже с испорченной КИ. Подписался, отправил заявку — деньги пришли на карту за 10 минут. Без звонков, без бюрократии.
фильмы в хорошем качестве лучшие фильмы 2025 года в HD
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки нарколог[/url]
Описание
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]snyatie-lomki-rnd7.ru/[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана в краснодаре[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее – [url=https://snyatie-lomki-rnd7.ru/]www.domen.ru[/url]
Преимущество
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодар.[/url]
Передовые методики
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-sochi777.ru
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить больше информации – http://snyatie-lomki-rnd7.ru
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки краснодар.[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Выяснить больше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодар.[/url]
Преимущество
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки в краснодаре[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана в краснодаре[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок на дому краснодар[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок краснодар[/url]
Преимущество
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому в краснодаре[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок на дому[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Детальнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого в краснодаре[/url]
Заказать диплом университета по доступной стоимости возможно, обращаясь к проверенной специализированной компании. Мы оказываем услуги по продаже документов об окончании любых университетов России. Заказать диплом любого университета– [url=http://diplomnie.com/kupit-diplom-s-zaneseniem-v-reestr-bistro-i-udobno-7/]diplomnie.com/kupit-diplom-s-zaneseniem-v-reestr-bistro-i-udobno-7/[/url]
Запой — состояние, характеризующееся неконтролируемым и продолжительным употреблением алкоголя, что вызывает сильную интоксикацию организма и нарушения в работе жизненно важных органов. При длительном запое организм испытывает колоссальную нагрузку, страдает сердечно-сосудистая система, печень, почки, а нервная система работает на пределе. Одним из наиболее эффективных методов быстрого и безопасного выхода из запоя является капельница. Наркологическая клиника «Анти-Кризис» в Краснодаре оказывает срочную помощь и вывод из запоя за 24 часа, обеспечивая индивидуальный подход, полную анонимность и доступные цены.
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд в краснодаре[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки краснодар[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому в краснодаре[/url]
Где покупать технику? лучшие магазины россии рейтинг: проверенные продавцы, акции, удобная доставка и реальный опыт покупателей. Обновляем регулярно.
Многие люди ищут цитаты, чтобы выразить чувства, найти вдохновение или просто улыбнуться. Мы собрали лучшие фразы — короткие, красивые, со смыслом. Наслаждайтесь подборкой, делитесь с друзьями и находите строки, которые отражают ваши мысли и настроение.
Настройка сервера на платформе https://rusikboss.livejournal.com/748.html — это удобный способ обеспечить безопасное подключение, стабильный доступ и полную конфиденциальность. Пошаговая инструкция, поддержка популярных протоколов, генерация QR-кодов и приложения для разных устройств — всё для быстрого запуска.
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]snyatie lomok krasnodar[/url]
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя на дому цена в краснодаре[/url]
Преимущество
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя в краснодаре[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок на дому[/url]
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя в краснодаре[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врача капельницу от запоя краснодар[/url]
Описание
Выяснить больше – https://snyatie-lomki-rnd7.ru/
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Исследовать вопрос подробнее – https://snyatie-lomki-rnd7.ru/
Преимущество
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]www.domen.ru[/url]
Описание
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]вызвать капельницу от запоя[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого краснодар[/url]
Описание
Детальнее – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодарский край[/url]
Преимущество
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому краснодар[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок краснодар[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее тут – [url=https://snyatie-lomki-rnd77.ru/]снять ломку краснодар[/url]
Преимущество
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому краснодарский край[/url]
Накрылся планшет перед командировкой — а я без него как без рук. Требовалось 19 000 срочно. Вбил в Google “займы срочно без звонка” — попал на Telegram-канал [url=https://t.me/s/mfo_2024_online]список надежных мфо[/url] . Идеальное попадание: рейтинг только открывшихся МФО, каждая с описанием и условиями. Заполнил анкету — и вот он, займ. Легко, быстро, без стресса.
Процедура капельницы назначается врачом-наркологом в ситуациях, когда состояние пациента становится критическим и организм нуждается в немедленном очищении от токсинов. Рекомендуется обратиться за срочной медицинской помощью, если отмечаются следующие признаки:
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]поставить капельницу от запоя[/url]
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Получить больше информации – https://snyatie-lomki-rnd77.ru/snyatie-lomki-na-domu-v-rnd/
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врач на дом капельница от запоя в краснодаре[/url]
Описание
Выяснить больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркозависимого в краснодаре[/url]
Гелиевые шарики Липецк на 23 февраля
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Подробнее тут – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок на дому[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Разобраться лучше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана в краснодаре[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки в краснодаре[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Узнать больше – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки на дому краснодар[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки в стационаре краснодар[/url]
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]postavit-kapelniczu-ot-zapoya krasnodar[/url]
[url=https://sukaaa-casino.ru]sukaaa-casino.ru[/url]
Если вам интересно ознакомиться с инструкциями по установке приложений на мобильные устройства, мы можем предложить общий гайд.
Как установить приложения на Android и iOS
Установка мобильных приложений зависит от операционной системы вашего устройства.
Для Android:
Откройте файл APK — если приложение недоступно в Google Play, его можно скачать через официальный сайт.
Разрешите установку из неизвестных источников — зайдите в Настройки > Безопасность и активируйте соответствующую опцию.
Запустите установку и следуйте инструкциям.
Для iOS:
Скачайте приложение из App Store — большинство сервисов доступны через официальный магазин.
Используйте TestFlight или корпоративный сертификат — если приложение не опубликовано в App Store.
Разрешите установку — в настройках iPhone перейдите в раздел VPN и управление устройствами и подтвердите доверие к разработчику.
Если вас интересует конкретное приложение, проверьте его официальный сайт или магазин приложений. Но помните о безопасности: скачивайте ПО только из проверенных источников, чтобы избежать мошенничества.
Хотите узнать больше? Читайте дополнительные инструкции на сайте по ссылке ниже.sukaaa-casino.ru
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее – https://snyatie-lomki-rnd77.ru/snyatie-lomki-na-domu-v-rnd
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-rnd77.ru/]снятие наркологической ломки на дому в краснодаре[/url]
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Получить дополнительную информацию – https://snyatie-lomki-rnd7.ru/snyatie-lomki-na-domu-v-rnd/
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков город[/url]
Описание
Получить дополнительные сведения – https://snyatie-lomki-rnd7.ru/
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя наркология краснодар[/url]
Преимущество
Выяснить больше – http://snyatie-lomki-rnd7.ru/snyatie-lomki-na-domu-v-rnd/
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Подробнее можно узнать тут – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd
Круглосуточная помощь
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд в краснодаре[/url]
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Разобраться лучше – http://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Углубиться в тему – [url=https://snyatie-lomki-rnd77.ru/]ломка от наркотиков город[/url]
Воздушные шары дешево
Уважаемые клиенты! Мы рады сообщить, что теперь вы можете заказать авто напрямую в Японии, Китае и Кореи!
Большой выбор машин от ведущих корейских, китайских, европейских, японских, и американских производителей.
Персональный подбор автомобиля под ваши требования.
Открытая схема работы и закрепленная стоимость.
Согласованные сроки привоза.
Оформление на всех этапах: от выбора до постановки авто на учет.
Передача документов в том числе чеки за предоставленные агентские услуги.
Свяжитесь с нами
+79644340397
+79952187276
vttautonhk@gmail.com
?Hola usuarios de apuestas
Los mГ©todos de pago tambiГ©n son mГЎs variados en casas de apuestas sin verificaciГіn. Puedes usar billeteras virtuales, criptomonedas, tarjetas prepago o incluso cГіdigos promocionales. Solo tienes que entrar a casasapuestassindni.xyz y escoger el que mejor se adapte a ti.
apuestas deportivas sin dni sin registro – casas apuestas sin dni
?Que tengas excelentes exitos!
Преимущество
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi777.ru/]наркологический вывод из запоя в сочи[/url]
Круглосуточная помощь
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]врач на дом капельница от запоя краснодар[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]vyzvat-kapelniczu-ot-zapoya krasnodar[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врача капельницу от запоя в краснодаре[/url]
Круглосуточная помощь
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]врача капельницу от запоя в краснодаре[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Разобраться лучше – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi/
¡Hola fanáticos de las apuestas
Una casa de apuestas sin verificaciГіn es perfecta para quienes valoran la velocidad y la discreciГіn.
Casas de apuestas online en EspaГ±a: las mГЎs populares – mejorescasasdeapuestassinlicencia
¡Por muchos sonrisas!
Преимущество
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]narkolog-vyvod-iz-zapoya sochi[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
Описание
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя краснодар[/url]
Преимущество
Углубиться в тему – http://kapelnica-ot-zapoya-krasnodar777.ru
перепродажа аккаунтов купить аккаунт с прокачкой
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Углубиться в тему – http://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
смотреть фильмы онлайн 2025 лучшие фильмы 2025 года в HD
лучшие фильмы фильмы онлайн 2025 без подписки
смотреть лучшие фильмы 2025 боевики 2025 смотреть бесплатно HD
Передовые методики
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя цена краснодарский край[/url]
Процедура капельницы назначается врачом-наркологом в ситуациях, когда состояние пациента становится критическим и организм нуждается в немедленном очищении от токсинов. Рекомендуется обратиться за срочной медицинской помощью, если отмечаются следующие признаки:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]врача капельницу от запоя[/url]
Процедура капельницы назначается врачом-наркологом в ситуациях, когда состояние пациента становится критическим и организм нуждается в немедленном очищении от токсинов. Рекомендуется обратиться за срочной медицинской помощью, если отмечаются следующие признаки:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя наркология краснодар[/url]
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Изучить вопрос глубже – http://kapelnica-ot-zapoya-krasnodar77.ru
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя краснодар[/url]
Воздушные шарики светящиеся
Передовые методики
Разобраться лучше – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi
Передовые методики
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому цена в сочи[/url]
Круглосуточная помощь
Разобраться лучше – http://kapelnica-ot-zapoya-krasnodar777.ru
Круглосуточная помощь
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя вызов город[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя вызов город[/url]
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя анонимно краснодар[/url]
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]vyvod-iz-zapoya-na-domu sochi[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя цена[/url]
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]после капельницы от запоя в краснодаре[/url]
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд[/url]
Запой — состояние, характеризующееся неконтролируемым и продолжительным употреблением алкоголя, что вызывает сильную интоксикацию организма и нарушения в работе жизненно важных органов. При длительном запое организм испытывает колоссальную нагрузку, страдает сердечно-сосудистая система, печень, почки, а нервная система работает на пределе. Одним из наиболее эффективных методов быстрого и безопасного выхода из запоя является капельница. Наркологическая клиника «Анти-Кризис» в Краснодаре оказывает срочную помощь и вывод из запоя за 24 часа, обеспечивая индивидуальный подход, полную анонимность и доступные цены.
Ознакомиться с деталями – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
фильмы драмы лучшие ужасы 2025 смотреть онлайн HD
фильм драма детектив ужасы 2025 смотреть онлайн HD
фильмы драма комедия фильмы 2025 без регистрации и рекламы
Описание
Получить дополнительную информацию – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Описание
Получить больше информации – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя круглосуточно сочи[/url]
Описание
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя[/url]
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в стационаре[/url]
Описание
Выяснить больше – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi777.ru
Круглосуточная помощь
Получить дополнительные сведения – http://kapelnica-ot-zapoya-krasnodar777.ru
Передовые методики
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]vyvod-iz-zapoya sochi[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому[/url]
Описание
Получить дополнительные сведения – http://kapelnica-ot-zapoya-krasnodar777.ru
Описание
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд[/url]
Преимущество
Узнать больше – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi/
Описание
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя анонимно краснодар[/url]
смотреть фильм ужасов 2025 сериалы 2025 онлайн бесплатно HD
смотреть фильм ужасов 2025 фильмы онлайн 2025 без подписки
фильмы 2025 онлайн бесплатно фантастика 2025 смотреть бесплатно
Гелиевые шарики Липецк на выпускной
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnicza-ot-zapoya krasnodar[/url]
Преимущество
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя в краснодаре[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя краснодар.[/url]
Описание
Подробнее можно узнать тут – http://vyvod-iz-zapoya-sochi777.ru/
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя краснодар[/url]
Передовые методики
Получить больше информации – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi
Преимущество
Выяснить больше – https://kapelnica-ot-zapoya-krasnodar777.ru
Круглосуточная помощь
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя цена краснодар[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Ознакомиться с деталями – https://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
фильмы в качестве 2025 смотреть кино на телефоне в Full HD
Актуальные юридические новости https://t.me/Urist_98RUS полезные статьи, практичные лайфхаки и советы для бизнеса и жизни. Понимайте законы легко, следите за изменениями, узнавайте секреты защиты своих прав и возможностей.
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя клиника в краснодаре[/url]
продажа аккаунтов соцсетей биржа аккаунтов
Описание
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя анонимно краснодар[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Подробнее тут – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Разобраться лучше – http://vyvod-iz-zapoya-sochi777.ru
[url=https://slotzal-casino.ru]slotzal-casino.ru[/url]
Привет, друзья! ??
Хотите узнать, как играть в слотзал Casino прямо с телефона? Перейдите по ссылке ниже и получите пошаговую инструкцию! Удобно, быстро и всегда под рукой. Удачи в игре! ??
slotzal-casino.ru
Описание
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Получить дополнительную информацию – http://kapelnica-ot-zapoya-krasnodar777.ru/
Описание
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя краснодар[/url]
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]vyzvat-kapelniczu-ot-zapoya krasnodar[/url]
Преимущество
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя цена краснодар.[/url]
Преимущество
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]врач на дом капельница от запоя в краснодаре[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому краснодарский край[/url]
Передовые методики
Разобраться лучше – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi/
Кактус Казино сайт кактус казино мир азарта и развлечений! Тысячи слотов, карточные игры, рулетка и захватывающие турниры. Быстрые выплаты, щедрые бонусы и поддержка 24/7. Играйте ярко, выигрывайте легко — всё это в Кактус Казино!
The best free ai chat porn with AI is a place for private communication without restrictions. Choose scenarios, create stories and enjoy the attention of a smart interlocutor. Discover new emotions, explore fantasies and relax your soul in a safe atmosphere.
Любите кино и сериалы? https://tevas-film-tv.ru у нас собраны лучшие подборки — от блокбастеров до авторских лент. Смотрите онлайн без ограничений, выбирайте жанры по настроению и открывайте новые истории каждый день. Кино, которое всегда с вами!
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя цена в краснодаре[/url]
Преимущество
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя на дому цена краснодар[/url]
[url=https://slots-for-money-casino.ru]slots-for-money-casino.ru[/url]
Топ слотов 2025: Где сорвать куш в онлайн-казино? Высокий RTP, захватывающие бонусы, инновационный геймплей и джекпоты! Обзор самых щедрых и популярных игр. Узнайте, какие слоты принесут вам удачу и помогут выиграть реальные деньги! Читайте подробнее:
slots-for-money-casino.ru
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Детальнее – http://kapelnica-ot-zapoya-krasnodar77.ru
Процедура капельницы назначается врачом-наркологом в ситуациях, когда состояние пациента становится критическим и организм нуждается в немедленном очищении от токсинов. Рекомендуется обратиться за срочной медицинской помощью, если отмечаются следующие признаки:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя краснодар[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-anonimno-v-sochi/
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
маркетплейс для реселлеров магазин аккаунтов социальных сетей
Преимущество
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnica-ot-zapoya-krasnodar777.ru/[/url]
металлические пины значки производство металлических значков
создание металлических значков https://metallicheskie-znachki-zakaz.ru
Хотите жить у моря? http://www.kvartira-v-chernogorii-kupit.com — квартиры, дома, виллы на лучших курортах. Удобные условия покупки, помощь на всех этапах, инвестиционные проекты. Откройте новые возможности жизни и отдыха на берегу Адриатики!
Мечтаете о доме у моря? недвижимость Черногории — идеальный выбор! Простое оформление, доступные цены, потрясающие виды и европейский комфорт. Инвестируйте в своё будущее уже сегодня вместе с нами.
Передовые методики
Подробнее можно узнать тут – https://vyvod-iz-zapoya-sochi777.ru
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя клиника краснодар[/url]
профиль с подписчиками маркетплейс для реселлеров
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Детальнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]vyvod-iz-zapoya-klinika sochi[/url]
маркетплейс аккаунтов соцсетей купить аккаунт
Круглосуточная помощь
Углубиться в тему – http://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/https://kapelnica-ot-zapoya-krasnodar777.ru
Гелиевые шары Липецк на выпускной
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-krasnodar77.ru
Круглосуточная помощь
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]vyzvat-kapelniczu-ot-zapoya krasnodar[/url]
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя капельница в сочи[/url]
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi/
Описание
Разобраться лучше – https://kapelnica-ot-zapoya-krasnodar777.ru
Преимущество
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя[/url]
Center Betting Information
Длительный запой – это опасное состояние, при котором организм не успевает вывести токсины алкоголя, что приводит к серьезной интоксикации и нарушению работы жизненно важных органов. Без своевременного вмешательства риск развития осложнений существенно возрастает. Наркологическая клиника «Доктор Трезвость» в Сочи предлагает комплексную поддержку и профессиональное лечение запоя, используя передовые методы терапии и индивидуальный подход для скорейшего восстановления здоровья пациента.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя сочи.[/url]
Описание
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]вызвать капельницу от запоя на дому[/url]
Круглосуточная помощь
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя наркология в краснодаре[/url]
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-sochi777.ru/
Преимущество
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя на дому цена сочи[/url]
Гелиевые шары
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя на дому цена краснодар[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]вызвать капельницу от запоя в краснодаре[/url]
Описание
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]postavit-kapelniczu-ot-zapoya krasnodar[/url]
[url=https://slotozal-casino-rus.ru]slotozal-casino-rus.ru[/url]
Привет, друзья! ??
Если вы хотите узнать, как играть в слотзал казино через телефон, перейдите по ссылке ниже. Там вы найдете пошаговую инструкцию, советы и полезные рекомендации, чтобы ваш игровой опыт был максимально комфортным и увлекательным.
slotozal-casino-rus.ru
Круглосуточная помощь
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя краснодар[/url]
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]поставить капельницу от запоя краснодар[/url]
Преимущество
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]postavit-kapelniczu-ot-zapoya krasnodar[/url]
Описание
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi777.ru/]срочный вывод из запоя в сочи[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя анонимно краснодар[/url]
Преимущество
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя на дому[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Получить дополнительную информацию – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-cena-v-sochi/
промокод продамус [url=www.prodams-promokod.ru]промокод продамус[/url] .
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя вызов[/url]
перепродажа аккаунтов площадка для продажи аккаунтов
Оперативное вмешательство позволяет быстро начать детоксикацию и предотвратить развитие опасных осложнений.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]наркология вывод из запоя сочи[/url]
металлические значки москва металлические значки москва
Наша наркологическая клиника успешно помогает пациентам с различной степенью алкогольной зависимости. Преимущества клиники «Перспектива» представлены в таблице ниже:
Узнать больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя клиника краснодар[/url]
Круглосуточная помощь
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]www.domen.ru[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя на дому краснодар[/url]
продажа аккаунтов услуги по продаже аккаунтов
маркетплейс аккаунтов платформа для покупки аккаунтов
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя сочи.[/url]
Преимущество
Подробнее – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя цена сочи.[/url]
Капельница от запоя рекомендуется врачами-наркологами в тех случаях, когда организм уже не может самостоятельно справляться с последствиями алкогольной интоксикации. Особенно важно оперативно обратиться за помощью, если отмечаются следующие симптомы:
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя выезд краснодар[/url]
Преимущество
Углубиться в тему – https://vyvod-iz-zapoya-sochi777.ru/
Преимущество
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]капельница от запоя[/url]
Преимущество
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя краснодар[/url]
Преимущество
Узнать больше – https://kapelnica-ot-zapoya-krasnodar77.ru/kapelnicza-ot-zapoya-czena-v-krasnodare
заработок на аккаунтах магазин аккаунтов
металлический значок с эмалью metallicheskie-znachki-zakaz.ru
Запой — тяжелое состояние, связанное с длительным и бесконтрольным употреблением алкоголя, когда человек не может самостоятельно остановиться. В результате алкогольной интоксикации страдают внутренние органы, нарушается работа сердечно-сосудистой и нервной систем. Чем дольше длится запой, тем выше риск серьезных осложнений. Капельница от запоя — быстрый и надежный способ вывести человека из опасного состояния, снять симптомы интоксикации и восстановить нормальное самочувствие. В наркологической клинике «Перспектива» в Краснодаре вы можете воспользоваться данной услугой круглосуточно, как в стационаре, так и с выездом врача на дом.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя[/url]
Клиника «Доктор Трезвость» в Сочи предлагает современное лечение запоя, основанное на комплексном подходе и индивидуальной программе для каждого пациента. Наши лицензированные специалисты используют передовые методы терапии, что позволяет достичь быстрого и безопасного вывода из запоя, а также создать надежную основу для дальнейшей реабилитации.
Ознакомиться с деталями – http://vyvod-iz-zapoya-sochi777.ru/vyvod-iz-zapoya-na-domu-v-sochi/https://vyvod-iz-zapoya-sochi777.ru
покупка аккаунтов купить аккаунт
Передовые методики
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi777.ru/]наркологический вывод из запоя[/url]
Описание
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя круглосуточно сочи[/url]
профиль с подписчиками биржа аккаунтов
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя краснодар.[/url]
Преимущество
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]после капельницы от запоя краснодар[/url]
Описание
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]врач на дом капельница от запоя[/url]
Обращение к специалистам становится необходимым, если наблюдаются следующие симптомы, указывающие на тяжелую интоксикацию:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя[/url]
Игнорирование этих признаков приводит к резкому ухудшению здоровья и тяжелым последствиям, которые можно предотвратить своевременным обращением к специалисту.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar77.ru/]капельница от запоя клиника в краснодаре[/url]
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]kapelnicza-ot-zapoya krasnodar[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры по ремонту техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Своевременная установка капельницы поможет быстро восстановить организм и избежать развития тяжёлых осложнений.
Изучить вопрос глубже – http://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/https://kapelnica-ot-zapoya-krasnodar777.ru
Наркологическая клиника «Анти-Кризис» в Краснодаре — это профессиональная и быстрая помощь в выведении из запоя. Мы предлагаем:
Подробнее тут – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
Преимущество
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя капельница[/url]
Передовые методики
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi777.ru/]вывод из запоя в стационаре в сочи[/url]
Преимущество
Выяснить больше – [url=https://kapelnica-ot-zapoya-krasnodar777.ru/]поставить капельницу от запоя в краснодаре[/url]
маркетплейс для реселлеров купить аккаунт
гарантия при продаже аккаунтов магазин аккаунтов
Описание
Выяснить больше – http://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Описание
Подробнее – https://kapelnica-ot-zapoya-krasnodar777.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
зайти на сайт [url=https://cryptoboss-casino2024.com]Криптобосс[/url]
супер маркетплейс kraken darknet с современным интерфейсом и удобным функционалом онион, специализируется на продаже запрещенных веществ по всему миру. У нас ты найдешь всё, от ароматных шишек до белоснежного порошка. Кракен. Купить.
подробнее [url=https://cryptoboss-casino2024.com/]Криптобосс[/url]
?Hola usuarios de juegos de apuestas
Descubre por quГ© los casinos online en EspaГ±a son lГderes en promociones como los 20 euros gratis sin depГіsito.
Juega en un casino online con 20 euros gratis y retira tus ganancias en efectivo. – casino 20 euros gratis sin depósito
?Que tengas excelentes jackpots !
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Преимущество
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого краснодар[/url]
Основные этапы лечения:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]вызвать капельницу от запоя[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Где приобрести [b]диплом[/b] по актуальной специальности?
Полученный диплом со всеми печатями и подписями отвечает условиям и стандартам, никто не сможет отличить его от оригинала. Не откладывайте собственные мечты и цели на потом, реализуйте их с нами – отправляйте заявку на изготовление документа сегодня! Получить диплом о высшем образовании – запросто! [url=http://careers.tu-varna.bg/employer/premialnie-diplom-24/]careers.tu-varna.bg/employer/premialnie-diplom-24[/url]
Основные этапы лечения:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врача капельницу от запоя краснодар[/url]
купить аккаунт купить аккаунт с прокачкой
магазин аккаунтов продать аккаунт
Mortgage calculator USA
https://dominerbusiness.com/userinfo.php?com=profile&op=userinfo&name=Your_Account&userinfo=evie.addy_426848&action=view
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Получить дополнительные сведения – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]ломка от наркотиков в краснодаре[/url]
магазин аккаунтов покупка аккаунтов
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]вызвать капельницу от запоя на дому[/url]
Основные этапы лечения:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя цена краснодар[/url]
Заказать диплом о высшем образовании!
Купить диплом университета по доступной цене возможно, обращаясь к проверенной специализированной компании. Заказать диплом: [url=http://diplomh-40.ru/kupit-diplom-s-reestrom-garantiya-podlinnosti-3/]diplomh-40.ru/kupit-diplom-s-reestrom-garantiya-podlinnosti-3[/url]
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Детальнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя клиника краснодар[/url]
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя анонимно краснодар[/url]
Кредитный потребительский кооператив https://юк-кпк.рф доступные займы и выгодные накопления для своих. Прозрачные условия, поддержка членов кооператива, защита средств. Участвуйте в финансовом объединении, где важны ваши интересы!
Надежный обмен валюты https://valutapiter.ru в Санкт-Петербурге! Актуальные курсы, наличные и безналичные операции, комфортные условия для частных лиц и бизнеса. Гарантия конфиденциальности и высокий уровень обслуживания.
Займы под материнский капитал https://юсфц.рф решение для покупки жилья или строительства дома. Быстрое оформление, прозрачные условия, минимальный пакет документов. Используйте государственную поддержку для улучшения жилищных условий уже сегодня!
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Мы изготавливаем дипломы любой профессии по приятным ценам.
Вы покупаете диплом через надежную и проверенную временем фирму. Приобрести диплом университета– [url=http://branditstrategies.com/employer/diplomy-grup-24/]branditstrategies.com/employer/diplomy-grup-24[/url]
биржа аккаунтов магазин аккаунтов социальных сетей
профиль с подписчиками продать аккаунт
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врача капельницу от запоя[/url]
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Получить больше информации – http://kapelnica-ot-zapoya-krasnodar7.ru/
Надежный обмен валюты https://valutapiter.ru в Санкт-Петербурге! Актуальные курсы, наличные и безналичные операции, комфортные условия для частных лиц и бизнеса. Гарантия конфиденциальности и высокий уровень обслуживания.
Кредитный потребительский кооператив https://юк-кпк.рф доступные займы и выгодные накопления для своих. Прозрачные условия, поддержка членов кооператива, защита средств. Участвуйте в финансовом объединении, где важны ваши интересы!
Займы под материнский капитал https://юсфц.рф решение для покупки жилья или строительства дома. Быстрое оформление, прозрачные условия, минимальный пакет документов. Используйте государственную поддержку для улучшения жилищных условий уже сегодня!
Где купить диплом по необходимой специальности?
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по приятным ценам. Важно, чтобы документы были доступны для большого количества наших граждан. Выгодно купить диплом любого ВУЗа [url=http://good-diplom.ru/kak-zanesti-diplom-v-reestr-6/]good-diplom.ru/kak-zanesti-diplom-v-reestr-6/[/url]
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Разобраться лучше – https://snyatie-lomki-rnd7.ru/
Преимущество
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки наркомана в краснодаре[/url]
Основные этапы лечения:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-krasnodar7.ru/
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить больше информации – [url=https://snyatie-lomki-rnd7.ru/]snyatie lomki narkozavisimogo krasnodar[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Подробнее тут – http://kapelnica-ot-zapoya-krasnodar7.ru/
магазин аккаунтов социальных сетей биржа аккаунтов
аккаунты с балансом услуги по продаже аккаунтов
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]kapelnicza-ot-zapoya-czena krasnodar[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врач на дом капельница от запоя краснодар[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врач на дом капельница от запоя в краснодаре[/url]
В наркологической клинике «Рестарт» используется комплексный подход к лечению абстинентного синдрома. Наши преимущества:
Получить дополнительную информацию – http://snyatie-lomki-rnd7.ru/
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя цена в краснодаре[/url]
Основные этапы лечения:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя цена в краснодаре[/url]
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-krasnodar7.ru/
Описание
Получить дополнительные сведения – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки краснодарский край[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]снятие ломок на дому в краснодаре[/url]
маркетплейс аккаунтов купить аккаунт
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Ознакомиться с деталями – https://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd7.ru/]снятие наркотической ломки краснодар[/url]
Алкогольный запой является тяжёлым состоянием, требующим срочного медицинского вмешательства. Наркологическая клиника «Пульс» в Краснодаре предлагает эффективную помощь в борьбе с алкогольной зависимостью, используя проверенный метод — капельницу от запоя на дому. Наши специалисты оперативно выезжают по указанному адресу и обеспечивают качественную медицинскую помощь с гарантией конфиденциальности и безопасности.
Углубиться в тему – https://kapelnica-ot-zapoya-krasnodar7.ru/
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя наркология[/url]
Основные этапы лечения:
Узнать больше – http://kapelnica-ot-zapoya-krasnodar7.ru
click for info [url=https://t.me/USFullz_bot]fullz ssn dob[/url]
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]kapelnica-ot-zapoya-krasnodar7.ru/[/url]
Приобрести диплом любого ВУЗа!
Мы оказываем услуги по продаже документов об окончании любых ВУЗов Российской Федерации. Документы производят на фирменных бланках государственного образца. [url=http://4division.ru/viewtopic.php?f=13&t=10100/]4division.ru/viewtopic.php?f=13&t=10100[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: мастер по ремонту iphone
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Заказать диплом ВУЗа!
Мы можем предложить документы университетов, расположенных на территории всей РФ. Документы печатаются на бумаге высшего качества: [url=http://fabnews.ru/forum/showthread.phpp=94696#post94696/]fabnews.ru/forum/showthread.phpp=94696#post94696[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows 10 Activation Key Github[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Is Windows Activation Free[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows 11 Activation Skip[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows 7 Ultimate Activation Key 2024[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows 10 Activation Watermark[/url]
Windows Activation
Где купить [b]диплом[/b] специалиста?
Готовый диплом с нужными печатями и подписями отвечает стандартам Министерства образования и науки Российской Федерации, неотличим от оригинала – даже со специально предназначенным оборудованием. Не следует откладывать личные цели на продолжительные годы, реализуйте их с нашей помощью – отправьте заявку на диплом уже сегодня! Получить диплом о среднем образовании – запросто! [url=http://bestnasos.ru/forum/user/5135/]bestnasos.ru/forum/user/5135[/url]
Алкогольный запой является тяжёлым состоянием, требующим срочного медицинского вмешательства. Наркологическая клиника «Пульс» в Краснодаре предлагает эффективную помощь в борьбе с алкогольной зависимостью, используя проверенный метод — капельницу от запоя на дому. Наши специалисты оперативно выезжают по указанному адресу и обеспечивают качественную медицинскую помощь с гарантией конфиденциальности и безопасности.
Детальнее – http://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры по ремонту техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Основные этапы лечения:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя на дому краснодар[/url]
Age-related health issues may prompt honest discussion, especially when initiating vardenafil vs cialis. Order today and wake up to your solution tomorrow – overnight made easy.
маркетплейс аккаунтов купить аккаунт
платформа для покупки аккаунтов продажа аккаунтов
безопасная сделка аккаунтов биржа аккаунтов
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр по ремонту айфонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Официальный сайт лордфильм лордфильм почка смотреть зарубежные новинки онлайн бесплатно. Фильмы, сериалы, кино, мультфильмы, аниме в хорошем качестве HD 720
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя на дому цена в краснодаре[/url]
В зависимости от состояния пациента врач индивидуально подбирает состав раствора для капельницы. Обычно используются следующие группы препаратов:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя анонимно краснодар[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Игнорирование этих симптомов опасно для жизни и здоровья. Своевременное обращение в клинику «Рестарт» позволит оперативно и безопасно облегчить симптомы ломки и избежать серьезных последствий.
Углубиться в тему – [url=https://snyatie-lomki-rnd7.ru/]снятие наркологической ломки на дому[/url]
проверить сайт [url=https://alt-coins.cc/]Альткоин обмен криптовалюты[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Исследовать вопрос подробнее – http://snyatie-lomki-rnd77.ru/snyatie-lomki-narkomana-v-rnd/
Передовые методики
Выяснить больше – http://snyatie-lomki-rnd77.ru/snyatie-lomki-narkomana-v-rnd/https://snyatie-lomki-rnd77.ru
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя на дому цена в краснодаре[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Ознакомиться с деталями – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]snyatie lomok krasnodar[/url]
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/https://kapelnica-ot-zapoya-krasnodar7.ru
Основные этапы лечения:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя вызов в краснодаре[/url]
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
магазин аккаунтов биржа аккаунтов
перепродажа аккаунтов аккаунты с балансом
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Получить дополнительную информацию – http://kapelnica-ot-zapoya-krasnodar7.ru
Ощутите драйв на Vavada Ukraine
казино з 18 [url=https://vavadaukraine.neocities.org/]https://vavadaukraine.neocities.org/[/url] .
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому недорого в краснодаре[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Углубиться в тему – http://snyatie-lomki-rnd77.ru/
you can find out more [url=https://t.me/USFullz_bot]usa fullz[/url]
check it out [url=https://t.me/USFullz_bot]FULLZ FOR KYC[/url]
[url=https://slots-casino-com.ru]slots-casino-com.ru[/url]
Здравствуйте, уважаемые участники форума! ??
Если вас интересует, как играть в Slot Casino Com через телефон, перейдите по ссылке ниже. Там вы найдете подробную инструкцию, которая поможет вам быстро и легко освоить игру. Удачи и приятного времяпрепровождения! ??
slots-casino-com.ru
здесь [url=https://alt-coins.cc]Альткоин обмен криптовалюты[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Подробнее – [url=https://snyatie-lomki-rnd77.ru/]ломка от наркотиков[/url]
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Подробнее тут – https://kapelnica-ot-zapoya-krasnodar7.ru
перейти на сайт [url=https://alt-coins.cc/]Альткоин обмен криптовалюты[/url]
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Подробнее тут – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя анонимно в краснодаре[/url]
Premium Features:
– Ultra-Soft Skin: Mimics the touch and warmth of real human skin with medical-grade TPE material.
– Anatomically Precise Design: Proportional curves and lifelike details for unparalleled realism.
– Flexible Metal Frame: Adjustable joints for endless posing possibilities.
– Certified Safety: Non-toxic, odor-free materials tested and approved by CCIC.
– Full-Body Versatility: Designed for intimate exploration – vaginal, anal, oral, and beyond.
– Easy Maintenance: Effortless cleaning for lasting hygiene.
Exclusive AliExpress Offer: Secure your premium companion at a special price – stock is limited.
[url=https://ify.ac/1c3Z]Order Now on AliExpress[/url]
Discreet & Secure: Shipped in plain packaging with total privacy guaranteed.
Crafted with Precision. Designed for Desire.
Elevate Your Experience – Order Today.
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Подробнее можно узнать тут – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок в краснодаре[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]posle-kapelniczy-ot-zapoya krasnodar[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Детальнее – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому цена[/url]
Основные этапы лечения:
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]врач на дом капельница от запоя в краснодаре[/url]
аккаунт для рекламы маркетплейс аккаунтов
магазин аккаунтов маркетплейс аккаунтов соцсетей
Преимущество
Подробнее тут – http://snyatie-lomki-rnd7.ru
Помощь врача-нарколога становится жизненно важной, когда симптомы абстинентного синдрома становятся невыносимыми и угрожают жизни пациента. К числу основных признаков, требующих срочного вмешательства, относятся:
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана в краснодаре[/url]
Капельница от запоя в Краснодаре рекомендуется при первых признаках алкогольной интоксикации или тяжелого похмелья. Без своевременного медицинского вмешательства состояние человека может резко ухудшиться, привести к развитию осложнений и даже стать угрозой для жизни. Срочная помощь необходима в таких случаях:
Подробнее – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя клиника[/url]
Игнорирование этих симптомов может привести к тяжелым последствиям для здоровья, включая алкогольный психоз и повреждение внутренних органов.
Получить больше информации – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]после капельницы от запоя[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Разобраться лучше – [url=https://snyatie-lomki-rnd7.ru/]snyatie-lomki-rnd7.ru/[/url]
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Изучить вопрос глубже – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки нарколог[/url]
Клиника «Здравица» в Ростове-на-Дону предлагает современный комплексный подход к лечению абстинентного синдрома. Наши пациенты получают помощь от высококвалифицированных специалистов, которые используют передовые методики и индивидуально подбирают программу лечения для каждого. Среди ключевых преимуществ клиники «Здравица» можно выделить:
Ознакомиться с деталями – [url=https://snyatie-lomki-rnd77.ru/]снятие ломок[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows Activation Kmsauto[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows 7 Activation Daz[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows Activation Customer Service Number[/url]
[url=https://x.com/RauheShemi20597/status/1908418523719696728]Windows Server Cal Activation[/url]
[url=https://telegra.ph/Windows-10-Windows-11-activation-is-forever-free-04-04]Windows Activation With Phone[/url]
Windows Activation
Преимущество
Получить дополнительную информацию – http://snyatie-lomki-rnd7.ru/snyatie-lomki-na-domu-v-rnd/
Hope this isn’t too off-topic 🙂
Just while exploring ambient music I discovered a project called [url=https://phi.tranceillusion.mk.ua]the Phi Illusion project[/url].
It’s music based on the golden ratio — symmetry, flow, and natural balance.
Chill BPM, layered melodies, ambient textures, spiraling visuals, and mathematically tuned soundscapes.
Anyone into deep conceptual sound?
В клинике «Пульс» процесс оказания помощи начинается сразу после вашего обращения. Наша бригада оперативно выезжает на дом, где врач проводит первичный осмотр пациента: измеряет давление, пульс, оценивает степень интоксикации и собирает анамнез. На основе полученных данных подбирается индивидуальный состав капельницы.
Углубиться в тему – http://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-czena-v-krasnodare/
Передовые методики
Узнать больше – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки на дому в краснодаре[/url]
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить больше информации – http://snyatie-lomki-rnd7.ru/
профиль с подписчиками аккаунт для рекламы
Постановка капельницы от запоя специалистами клиники «Пульс» в Воронеже обеспечивает пациентам оперативную помощь и быстрое облегчение состояния благодаря экстренному выезду врача на дом. Наши услуги доступны круглосуточно, включая ночное время и праздничные дни, что особенно важно при внезапных и критических ситуациях. Мы гарантируем полную конфиденциальность и защиту персональных данных пациентов, что позволяет получить необходимую помощь без риска огласки. Индивидуальный подход к каждому случаю обеспечивает максимальную эффективность лечения, а наши опытные наркологи используют только сертифицированные препараты, которые безопасно и быстро выводят токсины и стабилизируют состояние здоровья. Прозрачность ценообразования, предварительное согласование всех расходов и отсутствие скрытых доплат делают услуги клиники «Пульс» удобными и доступными для всех жителей Воронежа.
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-krasnodar7.ru
Кат Египет
Основные этапы лечения:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]капельница от запоя краснодар[/url]
Алкогольный запой является тяжёлым состоянием, требующим срочного медицинского вмешательства. Наркологическая клиника «Пульс» в Краснодаре предлагает эффективную помощь в борьбе с алкогольной зависимостью, используя проверенный метод — капельницу от запоя на дому. Наши специалисты оперативно выезжают по указанному адресу и обеспечивают качественную медицинскую помощь с гарантией конфиденциальности и безопасности.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-krasnodar7.ru/kapelnicza-ot-zapoya-na-domu-v-krasnodare/
платформа для покупки аккаунтов магазин аккаунтов
покупка аккаунтов маркетплейс аккаунтов соцсетей
Абстинентный синдром развивается после прекращения приёма наркотических веществ или алкоголя, и сопровождается комплексом тяжёлых симптомов:
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd7.ru/]снятие ломки на дому в краснодаре[/url]
Основные этапы лечения:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-krasnodar7.ru/]www.domen.ru[/url]
Абстинентный синдром, или ломка, – это тяжелое состояние, которое развивается у зависимых после отказа от наркотиков или алкоголя. Он сопровождается сильными физическими болями, судорогами, повышенной тревожностью, бессонницей и эмоциональными перепадами, что может привести к серьезным осложнениям для здоровья. Наркологическая клиника «Здравица» в Ростове-на-Дону предлагает комплексное лечение абстинентного синдрома, используя передовые методики и индивидуальный подход для быстрого восстановления здоровья.
Получить дополнительную информацию – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки в краснодаре[/url]
Преимущество
Получить больше информации – https://snyatie-lomki-rnd77.ru/snyatie-lomki-narkomana-v-rnd/
Абстинентный синдром, или ломка, — одно из наиболее тяжелых состояний, возникающих у зависимого человека после прекращения употребления наркотиков или алкоголя. Это состояние сопровождается физическими и психическими симптомами, которые становятся практически невыносимыми для пациента и могут привести к серьезным осложнениям без квалифицированной медицинской помощи. Наркологическая клиника «Рестарт» в Ростове-на-Дону специализируется на эффективном и безопасном снятии ломки, предлагая комплексный подход и индивидуальное лечение, направленное на быстрое облегчение состояния и восстановление организма пациента.
Детальнее – https://snyatie-lomki-rnd7.ru/snyatie-lomki-narkomana-v-rnd/
стоимость услуг клиники мед клиника
лечение варикоза таза у женщин https://lechenie-varikoza1.ru
гинеколог абакан отзывы прием гинеколога абакан
Своевременная помощь позволяет снизить риск осложнений и ускорить процесс детоксикации организма.
Подробнее тут – [url=https://snyatie-lomki-rnd77.ru/]снятие ломки наркомана краснодар[/url]
?Hola aventureros de las apuestas
Casino 20 euros gratis sin depГіsito EspaГ±a te abre las puertas a un sinfГn de premios y diversiГіn.
Accede a un casino de confianza con 20 euros gratis para probar los mejores slots. – casino20eurosgratissindeposito
?Que tengas excelentes botes !
[url=https://calibri-casino-slots-play.ru]calibri-casino-slots-play.ru[/url]
Узнать свежие новости и актуальную информацию о казино Calibry можно по ссылке ниже! Там собраны последние акции, бонусы и обзоры игр, так что держите руку на пульсе событий и будьте в курсе всех выгодных предложений. Переходите и будьте всегда в курсе самых интересных событий в мире Calibry!
calibri-casino-slots-play.ru
маркетплейс аккаунтов заработок на аккаунтах
проверить сайт [url=https://r-7-casino-www.ru]казино р7 игровые автоматы[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург[/url]
Уютная обивка утратила былй лоск? Воскрешение мягкой мебели на дому в СПб! Подарим вторую жизнь диванам, креслам и пушистым коврам первозданный вид. Экспертные средства и опытные мастера. Скидки первым клиентам! Детали ждут вас! Жмите https://himchistka-divanov-spb24.ru/
чистка у косметолога дерматолог косметолог
платные детские лоры отоларинголог в абакане
магазин аккаунтов социальных сетей купить аккаунт
виды лазерной эпиляции услуги лазерной эпиляции
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана[/url]
подробнее здесь [url=https://r-7-casino-www.ru]r7 casino игровые автоматы[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]vyzvat-kapelniczu-ot-zapoya novosibirsk[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому в екатеринбурге[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя новосибирск[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Исследовать вопрос подробнее – https://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske/
Функция
Получить дополнительные сведения – https://snyatie-lomki-nnovgorod8.ru/
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому екатеринбург.[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена екатеринбург[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Изучить вопрос глубже – http://snyatie-lomki-novosibirsk8.ru
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно в екатеринбурге[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом круглосуточно нижний новгород[/url]
заработок на аккаунтах магазин аккаунтов социальных сетей
Группа препаратов
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя новосибирск[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie lomok novosibirsk[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки нарколог в новосибирске[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]www.domen.ru[/url]
гарантия при продаже аккаунтов маркетплейс аккаунтов
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Разобраться лучше – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов в новосибирске[/url]
этот сайт [url=https://r-7-casino-www.ru/]r7 casino демо счет[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Углубиться в тему – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника в екатеринбурге[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить больше информации – https://snyatie-lomki-ekb8.ru/
Откройте для себя новинки на Torgove-obladnannya.biz.ua
продам торгове обладнання [url=https://torgove-obladnannya.biz.ua/]продам торгове обладнання[/url] .
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Изучить вопрос глубже – https://snyatie-lomki-ekb8.ru/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре в екатеринбурге[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки новосибирск[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее тут – https://kapelnica-ot-zapoya-novosibirsk8.ru/
Покупка подходящего диплома через качественную и надежную компанию дарит множество достоинств для покупателя. Данное решение дает возможность сэкономить время и серьезные финансовые средства. Однако, плюсов значительно больше.Мы предлагаем дипломы любых профессий. Дипломы изготавливаются на настоящих бланках государственного образца. Доступная стоимость в сравнении с крупными затратами на обучение и проживание в другом городе. Приобретение диплома института является мудрым шагом.
Приобрести диплом о высшем образовании: [url=http://diplom-top.ru/kupit-diplom-instituta-s-reestrom-vigodno-i-prosto/]diplom-top.ru/kupit-diplom-instituta-s-reestrom-vigodno-i-prosto/[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому в нижний новгороде[/url]
Группа препаратов
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижегородская область[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому цена в новосибирске[/url]
隨著2024-25賽季NBA附加賽的火熱進行,球迷們的熱情也隨之高漲。每一場比賽都關乎球隊命運,而季後賽的激烈對決更是指日可待。對於忠實球迷來說,能夠即時觀看這些精彩賽事至關重要。NBA直播線上看服務應運而生,為球迷提供了便捷的觀賽體驗。無論是上班族抽空追賽,還是學生族群熬夜支持,都能通過手機、平板或電腦隨時隨地觀看比賽。高清畫質、專業解說和多角度回放,讓您仿佛置身現場,感受每一次扣籃和三分球帶來的震撼。除了賽事直播,許多平台還提供賽程表、球員數據和賽後分析等豐富內容。您可以輕鬆掌握各隊積分排名、明星球員表現,甚至深入了解戰術分析。對於喜愛運彩投注的朋友,即時的數據分析和專家預測也能成為您決策的重要參考。選擇可靠的NBA直播平台尤為重要。穩定的播放品質、低延遲的直播信號和完整的賽事覆蓋,都是評判標準。部分平台還提供會員專屬服務,如廣告免除、賽事回放和獨家內容等特權。隨著科技發展,NBA直播線上看服務不斷創新,為球迷帶來更加便捷、沉浸的觀賽體驗。不再受限於電視轉播,每一位球迷都能隨心所欲地追逐熱愛的籃球賽事,見證精彩時刻。
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки в новосибирске[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Выяснить больше – http://
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом в нижний новгороде[/url]
безопасная сделка аккаунтов birzha-accauntov.ru/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Детальнее – http://snyatie-lomki-nnovgorod8.ru
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]snyat lomku ekaterinburg[/url]
Графический дизайнер https://uslugi.yandex.ru/profile/ArinaSergeevnaB-2163631 копирайтер и SMM-специалист в одном лице. Создаю визуал, тексты и стратегии, которые продают. Оформление, контент, продвижение — всё под ключ. Помогаю брендам быть заметными, узнаваемыми и вовлечёнными.
Официальный сайт КИНО ХЕЛП смотреть неоспоримый 5 скачать фильм зарубежные новинки онлайн бесплатно. Фильмы, сериалы, кино, мультфильмы, аниме, дорамы. Дата выхода новых серий. Сериалы Кинохелп это лучшие новинки и мировые премьеры.
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому нижегородская область[/url]
виды лазерной эпиляции https://studiya-lazernaya-epilyaciya.ru
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Изучить вопрос глубже – http://snyatie-lomki-ekb8.ru
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно в нижний новгороде[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в стационаре новосибирск[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя[/url]
Заказать диплом о высшем образовании!
Заказ документа о высшем образовании через качественную и надежную фирму дарит ряд плюсов для покупателя. Купить диплом о высшем образовании у надежной фирмы: [url=http://doks-v-gorode-orenburg-56.online/]doks-v-gorode-orenburg-56.online[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому цена[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому екатеринбург[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снять ломку[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снять ломку[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя новосибирск[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок[/url]
Почему не включаются беспроводные наушники https://e-pochemuchka.ru/pochemu-ne-vklyuchayutsya-besprovodnye-naushniki/
Мы изготавливаем дипломы любых профессий по разумным ценам. Купить свидетельство о разводе — [url=http://kyc-diplom.com/svidetelstvo-o-razvode.html/]kyc-diplom.com/svidetelstvo-o-razvode.html[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижегородская область[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркозависимого[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie lomki na domu novosibirsk[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому в нижний новгороде[/url]
лазерная эпиляция цена лазерная эпиляция цена
лазерная эпиляция абакан лазерная эпиляция зоны бикини
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому в екатеринбурге[/url]
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]www.domen.ru[/url]
Главная [url=https://autopark.kg/]Аренда авто Бишкек[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Детальнее – https://narcolog-na-dom-nnovgorod8.ru
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом нижний новгород[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно[/url]
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Разобраться лучше – https://snyatie-lomki-nnovgorod8.ru/
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в стационаре в новосибирске[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – https://snyatie-lomki-novosibirsk8.ru
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркомана[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому недорого[/url]
[url=https://aura-casino-download-play.ru]aura-casino-download-play.ru[/url]
По ссылке ниже — полезный гайд по игре в казино Aura. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
aura-casino-download-play.ru
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Исследовать вопрос подробнее – http://snyatie-lomki-ekb8.ru
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Подробнее тут – https://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя свердловская область[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок в екатеринбурге[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки в екатеринбурге[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее тут – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske/
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя недорого[/url]
[url=https://forum.zaymex.ru/forums/vzyat-zaym.21/]взять займ[/url] – кредитные карты, деньги под расписку
Группа препаратов
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена в екатеринбурге[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить дополнительные сведения – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske/
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки в екатеринбурге[/url]
Эскорт услуги в Санкт-Петербурге — Escort Piter https://escort-piter.com/
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Исследовать вопрос подробнее – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
[url=https://forum.zaymex.ru/forums/otzyvy-o-mfo/]отзывы мфо[/url] – дебетовые карты, деньги в долг
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Исследовать вопрос подробнее – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
эпиляция волос зоне бикини лазерная эпиляция бикини
печать на пакетах печать на дой пакетах
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Углубиться в тему – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
арендовать хранилище для вещей в москве [url=www.hranimveshimsk.ru]арендовать хранилище для вещей в москве[/url] .
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого в екатеринбурге[/url]
[url=calibri-casino-apk-play.ru]calibri-casino-apk-play.ru[/url]
Перейдя по ссылке ниже, вы сможете узнать самую свежую и актуальную информацию о казино Calibry, включая последние бонусы, новые игры и отзывы других игроков. Уверен, это поможет вам составить собственное мнение об этом казино и решить, стоит ли здесь играть!
calibri-casino-apk-play.ru
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя[/url]
[url=https://kuban.video]full видео[/url]
[url=https://kuban.video]онлайн видео краснодара[/url]
[url=https://kuban.video]вк видео переселение казаков на кубань[/url]
[url=https://kuban.video]видео в формате full[/url]
[url=https://kuban.video]регион кубань[/url]
видео пансионат кубань, скачать видео краснодарский край, видео кубани скачать, небуг краснодарский край видео, песня кубань
kuban.video
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого в екатеринбурге[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/
закатные металлические значки производство значков из металла
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд[/url]
купить аккаунт гарантия при продаже аккаунтов
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена нижний новгород[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом круглосуточно в нижний новгороде[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]ломка от наркотиков[/url]
лазерная эпиляция бикини для мужчин лазерная эпиляция волос у мужчин
печать бейджей на пластике печать на лентах для бейджей спб
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому свердловская область[/url]
[url=https://calibri-casino-app-play.ru]calibri-casino-app-play.ru[/url]
Перейдя по ссылке ниже, вы сможете ознакомиться с самыми свежими новостями о казино Calibry, включая новые бонусы, игры и акции. Следите за обновлениями и будьте в курсе всех возможностей этого казино, чтобы максимизировать свои шансы на выигрыш!
calibri-casino-app-play.ru
магазин аккаунтов социальных сетей https://marketplace-akkauntov-top.ru/
Назначение и действие
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника нижний новгород[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Получить дополнительные сведения – https://snyatie-lomki-novosibirsk8.ru/
Приобрести диплом института по доступной стоимости возможно, обращаясь к надежной специализированной фирме. Мы оказываем услуги по продаже документов об окончании любых ВУЗов РФ. Заказать диплом о высшем образовании– [url=http://cotboxerstore.com/2025/04/25/diplom-na-zakaz-legko-i-prosto-37/]cotboxerstore.com/2025/04/25/diplom-na-zakaz-legko-i-prosto-37[/url]
аккаунты с балансом https://magazin-akkauntov-online.ru/
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому в новосибирске[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Исследовать вопрос подробнее – http://snyatie-lomki-novosibirsk8.ru/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому недорого в новосибирске[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]snyatie lomok ekaterinburg[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркомана в новосибирске[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее – http://narcolog-na-dom-nnovgorod8.ru
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Ознакомиться с деталями – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske
[url=https://kuban.video]включи видео full hd[/url]
[url=https://kuban.video]кубань краснодар видео[/url]
[url=https://kuban.video]full length hd video[/url]
[url=https://kuban.video]краснодарский край новопокровская видео[/url]
[url=https://kuban.video]краснодар японский сад фото и видео[/url]
красивое видео краснодар, краснодар видео, кубань крымск, видео квартиры краснодара, краснодар японский сад фото и видео
kuban.video
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – http://snyatie-lomki-ekb8.ru/
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Углубиться в тему – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снять ломку в нижний новгороде[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому в новосибирске[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снять ломку[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому екатеринбург[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки новосибирск[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – https://snyatie-lomki-nnovgorod8.ru/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Выяснить больше – https://snyatie-lomki-ekb8.ru
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – http://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
[url=https://kuban.video]кубань сервис[/url]
[url=https://kuban.video]кубань краснодар сегодня[/url]
[url=https://kuban.video]скачать видео краснодарский край[/url]
[url=https://kuban.video]тамань видео[/url]
[url=https://kuban.video]смотреть онлайн кубань[/url]
прием кубань онлайн, смотреть онлайн кубань, народные песни атамани, красная кубань, кубань округ
kuban.video
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Подробнее тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого нижний новгород[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie-lomki-novosibirsk8.ru/[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог в екатеринбурге[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск.[/url]
печать буклетов а5 двусторонняя печать буклета
печать конвертов c4 цифровая печать конвертов
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов врача нарколога на дом нижний новгород[/url]
Назначение
Получить дополнительные сведения – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому[/url]
склады временного хранения москва [url=http://www.hranimveshimsk.ru]склады временного хранения москва[/url] .
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Разобраться лучше – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
маркетплейс аккаунтов безопасная сделка аккаунтов
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Углубиться в тему – http://snyatie-lomki-nnovgorod8.ru
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Выяснить больше – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
маркетплейс аккаунтов соцсетей https://kupit-akkaunt-top.ru/
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена в новосибирске[/url]
маркетплейс для реселлеров покупка аккаунтов
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого[/url]
[url=https://kuban.video]история краснодарского края видео[/url]
[url=https://kuban.video]солнечный остров краснодар видео[/url]
[url=https://kuban.video]съемка видео краснодар[/url]
[url=https://kuban.video]новости кубани сегодня видео[/url]
[url=https://kuban.video]видео дагомыс краснодарский край[/url]
природа краснодарского края видео, видео в качестве full, видео в формате full hd, город краснодар фото видео, краснодар районы видео
kuban.video
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
Смотреть здесь [url=https://Nova7.top/]Купить мяу[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Углубиться в тему – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог в екатеринбурге[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирск[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – https://snyatie-lomki-ekb8.ru/
Заказать диплом института по доступной цене возможно, обратившись к проверенной специализированной фирме. Мы предлагаем документы об окончании любых университетов РФ. Купить диплом о высшем образовании– [url=http://shopy.partners/create-blog/]shopy.partners/create-blog[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому[/url]
Функция
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки нижний новгород[/url]
подробнее [url=https://Nova7.top]Купить мяу[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана екатеринбург[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок[/url]
печать наклеек на одежду печать наклеек на футболки
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркомана в новосибирске[/url]
[url=https://calibri-casino-download-play.ru]calibri-casino-download-play.ru[/url]
Узнать свежие новости и актуальную информацию о казино Calibry можно по ссылке ниже! Там собраны последние акции, бонусы и обзоры игр, так что держите руку на пульсе событий и будьте в курсе всех выгодных предложений. Переходите и будьте всегда в курсе самых интересных событий в мире Calibry!
calibri-casino-download-play.ru
табличка на дом пвх tablichki-pvh.ru
типография печать плакатов печать плаката а2 цена
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Разобраться лучше – http://kapelnica-ot-zapoya-novosibirsk8.ru/
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]www.domen.ru[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно нижний новгород[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому екатеринбург.[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому в екатеринбурге[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Углубиться в тему – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки[/url]
Желаете загрузить Geometry Dash на ПК и наслаждаться игрой на большом экране? На нашем сайте [url=https://skachat-geometry-dash-full.ru]skachat-geometry-dash-full.ru[/url] доступна полную версию игры для любой версии Windows. Оцените все преимущества игры на большом экране с полным контролем!
скачать геометри даш бесплатно
скачать игру геометри даш полная версия
скачать geometry dash полная версия на пк
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому[/url]
Функция
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]snyatie lomok ekaterinburg[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
[url=https://aura-casino-online-play.ru]aura-casino-online-play.ru[/url]
Хотите узнать все о казино Aura? Я нашел отличный обзор, где подробно разбираются все плюсы и минусы этого казино. Там есть информация о лицензии, играх, и даже советы для новичков.
aura-casino-online-play.ru
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki narkozavisimogo nizhnij novgorod[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок в нижний новгороде[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижний новгород[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург.[/url]
Fans of Diana Rider will love this site. | Diana Rider’s OnlyFans is trending for a reason. | Learn more about Diana Rider’s biography. | Diana Rider’s online presence is impressive. | Diana Rider is the name to remember | No one does it better than Diana Rider | One site, all of Diana Rider’s work. | Dive into Diana Rider’s hottest moments. | She’s a game-changer in adult video – Diana Rider. [url=https://diana-rider-nude.com/]diana rider porn[/url].
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снять ломку в екатеринбурге[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Выяснить больше – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки[/url]
Diana Rider is redefining the adult industry. | Diana Rider’s OnlyFans is trending for a reason. | New to Diana Rider? You’re in for a thrill. | Discover why Diana Rider is a fan favorite | Every video by Diana Rider tells a story. | Ready for something unforgettable? Diana Rider delivers. | She’s bold, smart, and seductive – Diana Rider. | She’s got beauty, talent, and fire – Diana Rider. | She’s a game-changer in adult video – Diana Rider. [url=https://diana-rider-nude.com/]https://diana-rider-nude.com/[/url].
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом в нижний новгороде[/url]
адресная табличка пвх табличка пвх с пленкой
печать виниловых наклеек печать наклеек с логотипом
широкоформатная печать плакатов стоимость печати плакатов
Fans of Diana Rider will love this site. | Diana Rider’s work is both bold and artistic. | New to Diana Rider? You’re in for a thrill. | She’s talented, stunning, and unforgettable – Diana Rider. | Looking for something intense? Try Diana Rider. | No one does it better than Diana Rider | One site, all of Diana Rider’s work. | This is adult artistry – thanks to Diana Rider. | She’s a game-changer in adult video – Diana Rider. [url=https://diana-rider-nude.com/]diana-rider-nude.com[/url].
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Углубиться в тему – http://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/
изготовление лабораторных стендов https://izgotovlenie-stendov2.ru/
Функция
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому нижегородская область[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
перенаправляется сюда [url=https://Nova7.top]Купить мяу[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее можно узнать тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркомана[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог в екатеринбурге[/url]
Fans of Diana Rider will love this site. | Get to know Diana Rider’s full career path. | Every adult video lover should follow Diana Rider. | Diana Rider delivers top-tier adult entertainment. | Meet the queen of adult cinema: Diana Rider. | The real Diana Rider experience is here. | Diana Rider knows how to captivate an audience | Access the full Diana Rider experience. | Welcome to the world of Diana Rider. [url=https://diana-rider-nude.com/]diana rider info[/url].
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]snyatie lomki narkozavisimogo ekaterinburg[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому[/url]
The most sensual scenes belong to Diana Rider. | All about Diana Rider in one place | Looking for Diana Rider’s best scenes? This is it. | Discover why Diana Rider is a fan favorite | Looking for something intense? Try Diana Rider. | You haven’t seen real passion until you watch Diana Rider. | Diana Rider’s fans are growing daily – join now. | This is where Diana Rider fans unite. | Diana Rider is where desire meets talent. [url=https://diana-rider-nude.com/]diana rider videos collection[/url].
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркотической ломки нижний новгород[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки свердловская область[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
Account Market Account Trading Platform
Sell Account Gaming account marketplace
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Изучить вопрос глубже – http://kapelnica-ot-zapoya-novosibirsk8.ru
Назначение
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]snyat lomku novosibirsk[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Углубиться в тему – https://snyatie-lomki-ekb8.ru/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb
Buy accounts Account Trading Service
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому нижний новгород[/url]
The most sensual scenes belong to Diana Rider. | If you’re into adult cinema, Diana Rider is a top pick. | Enjoy premium access to Diana Rider’s hottest content. | Diana Rider delivers top-tier adult entertainment. | See why Diana Rider gets 5-star reviews. | Ready for something unforgettable? Diana Rider delivers. | Adult fans agree: Diana Rider is a legend. | Access the full Diana Rider experience. | Welcome to the world of Diana Rider. [url=https://diana-rider-nude.com/]diana rider videos collection[/url].
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Подробнее можно узнать тут – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
изготовление лабораторных стендов изготовление стендов для выставки
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому в новосибирске[/url]
Accounts market Guaranteed Accounts
The most sensual scenes belong to Diana Rider. | Don’t miss the bio of Diana Rider – it’s impressive. | New to Diana Rider? You’re in for a thrill. | Follow Diana Rider for top-rated content. | See why Diana Rider gets 5-star reviews. | The real Diana Rider experience is here. | Looking for full Diana Rider content? It’s here. | She’s got beauty, talent, and fire – Diana Rider. | Welcome to the world of Diana Rider. [url=https://diana-rider-nude.com/]diana-rider-nude.com[/url].
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена[/url]
Explore Diana Rider’s hottest collections now | All about Diana Rider in one place | Diana Rider’s videos are worth every second. | Get access to full-length Diana Rider videos. | Looking for something intense? Try Diana Rider. | Diana Rider’s content is pure fire. | Diana Rider knows how to captivate an audience | Access the full Diana Rider experience. | She’s a game-changer in adult video – Diana Rider. [url=https://diana-rider-nude.com/]diana rider porn[/url].
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее можно узнать тут – https://snyatie-lomki-ekb8.ru/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Углубиться в тему – http://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske/https://snyatie-lomki-novosibirsk8.ru
Fans of Diana Rider will love this site. | Diana Rider’s OnlyFans is trending for a reason. | Diana Rider’s exclusive videos are finally here. | Diana Rider delivers top-tier adult entertainment. | See why Diana Rider gets 5-star reviews. | Ready for something unforgettable? Diana Rider delivers. | Diana Rider’s fans are growing daily – join now. | Dive into Diana Rider’s hottest moments. | She’s a game-changer in adult video – Diana Rider. [url=https://diana-rider-nude.com/]diana rider onlyfans[/url].
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог в екатеринбурге[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снять ломку[/url]
The most sensual scenes belong to Diana Rider. | She’s one of the best: Diana Rider in action. | Diana Rider’s exclusive videos are finally here. | Diana Rider’s online presence is impressive. | Diana Rider is the name to remember | Diana Rider’s content is pure fire. | Looking for full Diana Rider content? It’s here. | Access the full Diana Rider experience. | The best adult performances come from Diana Rider. [url=https://diana-rider-nude.com/]diana rider full videos[/url].
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
Функция
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого нижний новгород[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее – http://snyatie-lomki-novosibirsk8.ru
Discover the best of Diana Rider’s videos here. | All about Diana Rider in one place | Learn more about Diana Rider’s biography. | Get access to full-length Diana Rider videos. | Meet the queen of adult cinema: Diana Rider. | No one does it better than Diana Rider | Looking for full Diana Rider content? It’s here. | She’s got beauty, talent, and fire – Diana Rider. | Diana Rider keeps it raw, real, and hot. [url=https://diana-rider-nude.com/]diana rider xxx videos[/url].
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Подробнее тут – http://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок в нижний новгороде[/url]
Fans of Diana Rider will love this site. | If you’re into adult cinema, Diana Rider is a top pick. | Looking for Diana Rider’s best scenes? This is it. | Diana Rider delivers top-tier adult entertainment. | Looking for something intense? Try Diana Rider. | Feel the heat with Diana Rider’s newest videos. | She’s bold, smart, and seductive – Diana Rider. | Access the full Diana Rider experience. | Stream Diana Rider’s full-length features. [url=https://diana-rider-nude.com/]diana rider website[/url].
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
Надёжный обмен валюты https://valutapiter.ru в СПб — курсы в реальном времени, большой выбор валют, комфортные офисы. Конфиденциальность, без очередей, выгодно и с гарантией. Для туристов, жителей и бизнеса. Обмен, которому можно доверять!
Займы под материнский капитал https://юсфц.рф быстрое решение для покупки квартиры, дома или участка. Без личных вложений, с полным юридическим сопровождением. Оформление за 1 день, надёжные сделки и опыт более 10 лет. Используйте господдержку с умом!
Функция
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого нижний новгород[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого в екатеринбурге[/url]
Функция
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки нижний новгород[/url]
Функция
Исследовать вопрос подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Выяснить больше – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Ознакомиться с деталями – http://snyatie-lomki-ekb8.ru
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск.[/url]
[url=https://kuban.video]кубань авария видео[/url]
[url=https://kuban.video]история краснодарского края видео[/url]
[url=https://kuban.video]показать город краснодар видео[/url]
[url=https://kuban.video]кубань вино[/url]
[url=https://kuban.video]кубань открыта[/url]
камеры видео краснодар, пансионат кубань геленджик видео, фото и видео парка краснодара, краснодар видео, центр краснодара видео
kuban.video
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Функция
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Исследовать вопрос подробнее – http://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Функция
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана в нижний новгороде[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Разобраться лучше – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого в екатеринбурге[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому цена[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее можно узнать тут – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]lomka ot narkotikov ekaterinburg[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya novosibirsk[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – http://snyatie-lomki-nnovgorod8.ru
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Детальнее – http://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode/
Функция
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого в нижний новгороде[/url]
Группа препаратов
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижегородская область[/url]
Website for Buying Accounts Account Acquisition
Account Trading Service Account Catalog
Группа препаратов
Получить дополнительную информацию – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Account marketplace Website for Buying Accounts
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Функция
Получить дополнительную информацию – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode
Функция
Подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркотической ломки[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее – https://snyatie-lomki-ekb8.ru/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому новосибирск[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому[/url]
A little food content never hurts, right?
Just as I looked for inspiration I found a site https://kitchen.myusefulnotes.online.
It’s packed with content: recipes. From bone broth to Japanese udon, wild honey to spice theory.
Some titles that stood out:
– Soy-based rice and miso soup
Also found this [url=https://kitchen.myusefulnotes.online]amazing food knowledge hub[/url] — worth a scroll!
Anyone else into exploring food culture?
промокод на продамус [url=http://prodams-promokod.ru/]промокод на продамус[/url] .
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок на дому нижний новгород[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]lomka ot narkotikov ekaterinburg[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому[/url]
Группа препаратов
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя в новосибирске[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Подробнее – http://snyatie-lomki-ekb8.ru
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее можно узнать тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – http://
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого в екатеринбурге[/url]
Группа препаратов
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт бытовой техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Функция
Подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки екатеринбург[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород.[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя в новосибирске[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркотической ломки екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому екатеринбург[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому новосибирск[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Secure Account Sales Accounts for Sale
Account Sale Buy accounts
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург.[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок на дому нижний новгород[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Изучить вопрос глубже – http://snyatie-lomki-novosibirsk8.ru
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – https://snyatie-lomki-ekb8.ru/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Выяснить больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирск[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie-lomki-novosibirsk8.ru/[/url]
[url=https://download-online-casino.ru]download-online-casino.ru[/url]
Приветствую всех!
Нашел полезную информацию для тех, кто интересуется онлайн-казино в 2025 году. По этой ссылке есть гайд о том, как скачивать приложения онлайн-казино в следующем году.
В материале освещены следующие вопросы:
Актуальные способы скачивания приложений (для Android и iOS)
На что обратить внимание при выборе казино для скачивания (лицензия, безопасность)
Обзор самых надежных платформ в 2025 году
Как избежать мошеннических приложений
download-online-casino.ru
Accounts marketplace Account Market
Europese apotheek
Zolpidemtartraat kopen zonder recept! => https://bit.ly/eambien
— Lage prijzen voor geneesmiddelen van hoge kwaliteit
— Snelle levering en volledige vertrouwelijkheid
— Bonuspillen en grote kortingen bij elke bestelling
— Uw volledige tevredenheid gegarandeerd of uw geld terug
.
.
.
.
.
Zolpidemtartraat 10 mg kopen goedkoop Zolpidemtartraat 10 mg
koop goedkoop Zolpidemtartraat 10 mg
Zolpidemtartraat 10mg lage prijs Zolpidemtartraat 10 mg kopen
koop goedkoop Zolpidemtartraat 10mg
Waar te bestellen Zolpidemtartraat 10 mg koop goedkoop Zolpidemtartraat 10mg
Waar te koop Zolpidemtartraat 10mg
Zolpidemtartraat 10 mg kopen Waar te bestellen Zolpidemtartraat 10mg
koop Zolpidemtartraat 10 mg Zolpidemtartraat 10 mg kopen zonder recept
Waar te bestellen Zolpidemtartraat 10 mg Zolpidemtartraat 10mg kopen zonder recept
goedkoop Zolpidemtartraat 10mg Zolpidemtartraat 10 mg kopen
Waar kan ik Zolpidemtartraat 10 mg kopen koop Zolpidemtartraat 10mg
Zolpidemtartraat 10 mg lage prijs
Zolpidemtartraat 10 mg kopen
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск.[/url]
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Функция
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить дополнительные сведения – https://snyatie-lomki-nnovgorod8.ru
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом нижний новгород[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]ломка от наркотиков в новосибирске[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Назначение
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-novosibirsk8.ru
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок нижний новгород[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее можно узнать тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена в нижний новгороде[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена екатеринбург[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена в новосибирске[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]snyat lomku novosibirsk[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому в новосибирске[/url]
Функция
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому цена нижний новгород[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее – http://snyatie-lomki-ekb8.ru
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]snyatie lomki ekaterinburg[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого в екатеринбурге[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Получить дополнительные сведения – https://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske/
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие наркотической ломки в екатеринбурге[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок нижний новгород.[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Ознакомиться с деталями – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки нарколог[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]www.domen.ru[/url]
промокод на продамус скидка подключение [url=https://www.prodams-promokod.ru]https://www.prodams-promokod.ru[/url] .
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков[/url]
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: ремонт крупногабаритной техники в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок свердловская область[/url]
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]lomka ot narkotikov nizhnij novgorod[/url]
Функция
Детальнее – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
изготовление пинов
[url=https://kitchen.justtips.online]Як приготувати суп із гарбуза[/url], щоб він був смачним і корисним? Подивіться на цей простий рецепт.
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Подробнее тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана[/url]
Хочешь оформить техпаспорт жд Документация включает технический паспорт железнодорожного пути, а также технический паспорт жд пути необщего пользования. Отдельно может потребоваться техпаспорт жд и паспорт на жд тупик при ведении путевого хозяйства.
Современные сувениры https://66.ru/news/stuff/278214/ всё чаще становятся не просто подарками, а настоящими элементами бренда или корпоративной культуры. Особенно интересны примеры, когда обычные предметы превращаются в креативные и запоминающиеся изделия. Такие подходы вдохновляют на создание уникальной продукции с индивидуальным стилем и глубоким смыслом. Именно за этим всё чаще обращаются заказчики, которым важна не массовость, а оригинальность.
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – http://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/https://snyatie-lomki-ekb8.ru
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог в нижний новгороде[/url]
Хочешь оформить паспорт на жд тупик Документация включает технический паспорт железнодорожного пути, а также технический паспорт жд пути необщего пользования. Отдельно может потребоваться техпаспорт жд и паспорт на жд тупик при ведении путевого хозяйства.
Металлические бейджи https://gubkin.bezformata.com/listnews/beydzhi-dlya-brendov-i/140355141/ для брендов и корпораций — стильное решение для сотрудников, партнёров и мероприятий. Прочные, износостойкие, с гравировкой или полноцветной печатью. Подчёркивают статус компании и укрепляют фирменный стиль. Такие решения особенно актуальны для выставок, форумов и корпоративных событий, где важно произвести правильное первое впечатление. Грамотно оформленный бейдж может сказать о компании больше, чем десятки слов.
secure account sales account purchase
sell pre-made account secure account purchasing platform
Заказные медали https://iseekmate.com/34740-medali-na-zakaz-nagrada-dlya-chempionov.html применяются для поощрения в спорте, образовании, корпоративной культуре и юбилейных мероприятиях. Производятся из металла, с эмалью, гравировкой или цветной печатью в соответствии с требованиями заказчика.
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Ознакомиться с деталями – http://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры по ремонту техники в мск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Howdy very cool web site!! Man .. Excellent .. Superb .. I’ll bookmark your website and take the feeds additionally? I’m happy to find so many useful information right here in the submit, we need work out extra techniques in this regard, thanks for sharing. . . . . .
http://fstu.org.ua/kupyty-led-lampy-h1h7-dlya-avto-na-shcho-zvernuty-.html
Где приобрести [b]диплом[/b] по нужной специальности?
Полученный диплом с необходимыми печатями и подписями отвечает условиям и стандартам Министерства образования и науки РФ, никто не отличит его от оригинала. Диплом о высшем образовании – не проблема! [url=http://empleo.infosernt.com/employer/diplomix-asx/]empleo.infosernt.com/employer/diplomix-asx[/url]
online account store account trading
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому екатеринбург[/url]
Функция
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому[/url]
Мы оказываем услуги по производству и продаже документов об окончании любых университетов России. Документы производятся на подлинных бланках государственного образца. [url=http://corevacancies.com/employer/aurus-diploms/]corevacancies.com/employer/aurus-diploms[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому в екатеринбурге[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому в екатеринбурге[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск.[/url]
Приобрести диплом о высшем образовании!
Мы изготавливаем дипломы любой профессии по приятным тарифам. Вы заказываете диплом в надежной и проверенной компании. : [url=http://teamlocum.co.uk/employer/gosznac-diplom-24/]teamlocum.co.uk/employer/gosznac-diplom-24[/url]
Диплом любого ВУЗа России!
Без присутствия диплома очень нелегко было продвинуться по карьерной лестнице. Приобрести диплом под заказ в Москве вы можете используя сайт компании: [url=http://industrial.getbb.ru/viewtopic.phpf=4&t=4419/]industrial.getbb.ru/viewtopic.phpf=4&t=4419[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Выяснить больше – http://snyatie-lomki-ekb8.ru
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервис центры бытовой техники москва
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Нужен займ, но КИ испорчена? На https://toolbarqueries.google.co.cr/url?q=https://ruszaim.com/ ты найдёшь тех, кто всё равно даст. Подборка МФО, которые не отказывают и выдают по паспорту. Без проверки БКИ, без звонков. Только надёжные предложения и реальные условия. Деньги уже в пути — всё просто и без стресса.
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
accounts marketplace account selling service
[url=https://kuban.video]краснодарский край кубань видео[/url]
[url=https://kuban.video]песня кубань[/url]
[url=https://kuban.video]новая кубань[/url]
[url=https://kuban.video]видео краснодар бесплатно[/url]
[url=https://kuban.video]посмотреть краснодар видео[/url]
нова кубань, красная кубань, села краснодарского края видео, образование краснодарского края видео, видео квартиры краснодара
kuban.video
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Получить больше информации – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки нарколог[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог екатеринбург[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Узнать больше – http://snyatie-lomki-ekb8.ru
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie lomok novosibirsk[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому в новосибирске[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – http://snyatie-lomki-ekb8.ru/
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]narcolog-na-dom-nnovgorod8.ru/[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]snyat lomku novosibirsk[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижегородская область[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена екатеринбург[/url]
Группа препаратов
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог нижний новгород[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Ознакомиться с деталями – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков[/url]
До 30 000 рублей за 15 минут? Это реально. Зайди на https://www.google.to/url?q=https://ruszaim.com/ — и выбери подходящую МФО из актуального рейтинга 2025 года. Всё по паспорту, всё онлайн, без скрытых условий. Заявка отправляется мгновенно, деньги приходят прямо на карту. Простое решение сложных финансовых вопросов.
подробнее [url=https://vodkabetslot.ru]казино водкабет[/url]
Заказные медали https://iseekmate.com/34740-medali-na-zakaz-nagrada-dlya-chempionov.html применяются для поощрения в спорте, образовании, корпоративной культуре и юбилейных мероприятиях. Производятся из металла, с эмалью, гравировкой или цветной печатью в соответствии с требованиями заказчика.
Металлические бейджи https://gubkin.bezformata.com/listnews/beydzhi-dlya-brendov-i/140355141/ для брендов и корпораций — стильное решение для сотрудников, партнёров и мероприятий. Прочные, износостойкие, с гравировкой или полноцветной печатью. Подчёркивают статус компании и укрепляют фирменный стиль. Такие решения особенно актуальны для выставок, форумов и корпоративных событий, где важно произвести правильное первое впечатление. Грамотно оформленный бейдж может сказать о компании больше, чем десятки слов.
перейдите на этот сайт [url=https://vodkabetslot.ru]водкабет официальный сайт[/url]
Обзор машин для очистки зерна — mashiny-dlya-ochistki-zerna.biz.ua
купить зерноочисну машину [url=https://mashiny-dlya-ochistki-zerna.biz.ua/]купить зерноочисну машину[/url] .
Продвижение групп ВК https://vk.com/dizayn_vedenie_prodvizhenie_grup от оформления и наполнения до запуска рекламы и роста подписчиков. Подходит для бизнеса, мероприятий, брендов и экспертов. Работаем честно и с аналитикой.
Изготавливаем значки https://znaknazakaz.ru на заказ в Москве: классические, сувенирные, корпоративные, с логотипом и индивидуальным дизайном. Металл, эмаль, цветная печать. Быстрое производство, разные тиражи, удобная доставка по городу.
Металлические значки https://techserver.ru/izgotovlenie-znachkov-iz-metalla-kak-zakazat-unikalnye-izdeliya-dlya-vashego-brenda/ это стильный и долговечный способ подчеркнуть фирменный стиль, создать корпоративную айдентику или просто сделать приятный сувенир. Всё больше компаний выбирают индивидуальное изготовление значков, чтобы выделиться среди конкурентов.
Quer comprar seguidores? Escolha o pacote que mais combina com voce: ao vivo, oferta ou misto. Adequado para blogueiros, lojas e marcas. Seguro, rapido e mantem a reputacao da sua conta.
What if we could design an online course that not only teaches Std 10 CBSE subjects but also incorporates time-traveling scenarios to help students understand historical events firsthand? How would this impact student engagement and knowledge retention?
Ви знали, що у них є YouTube-канал зі сказками? Дуже крута ініціатива, ось [url=https://xyzdigitalmedia.com]інформація про проект[/url].
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Разобраться лучше – http://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
[url=download-app-casino-x.ru]download-app-casino-x.ru[/url]
Привет всем!
Если вы ищете информацию о том, как скачать и установить мобильное приложение Casino X на свое устройство (Android или iOS), советую посмотреть по этой ссылке:
Там подробно описано:
Где безопасно скачать установочный файл
Какие системные требования у приложения
Как правильно установить и настроить приложение
Какие бонусы можно получить за установку приложения
download-app-casino-x.ru
Функция
Узнать больше – http://snyatie-lomki-nnovgorod8.ru
Природа берёт тебя в объятия.
https://fireball4.spintheblog.com/35239033/Жилье-с-видом-на-горы-в-долине-Нарзанов
Значки с логотипом компании https://press-release.ru/branches/markets/znachki-s-vashim-logotipom-iskusstvo-metalla-voploshchennoe-v-unikalnyh-izdeliyah/ это не просто элемент фирменного стиля, а настоящее искусство, воплощённое в металле. Они подчёркивают статус бренда и помогают сформировать узнаваемый образ.
Изготовим значки с логотипом http://classical-news.ru/tehnologiya-izgotovleniya-znachkov-s-logotipom/ вашей компании. Металлические, пластиковые, с эмалью или цветной печатью. Подчеркните фирменный стиль на выставках, акциях и корпоративных мероприятиях. Качественно, от 10 штук, с доставкой.
Изготовление значков https://3news.ru/izgotovlenie-znachkov-na-zakaz-pochemu-eto-vygodno-i-kak-vybrat-idealnyj-variant/ на заказ любой сложности. Работаем по вашему дизайну или поможем создать макет. Предлагаем разные материалы, формы и типы креплений. Оперативное производство и доставка по всей России.
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить больше информации – https://narcolog-na-dom-mariupol0.ru/vyzov-narkologa-na-dom-mariupol/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому в новосибирске[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Юридическое сопровождение юрист по банкротству физических лиц спб: от анализа документов до полного списания долгов. Работаем официально, по закону №?127-ФЗ. Возможна рассрочка оплаты услуг.
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Выяснить больше – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить дополнительные сведения – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode/
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]врач на дом капельница от запоя луганск[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого екатеринбург[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижний новгород[/url]
buy and sell accounts account sale
database of accounts for sale verified accounts for sale
пояснения [url=https://vodkabetslot.ru]водкабет[/url]
антенна TV Flat HD [url=http://tv-antenka.ru/]http://tv-antenka.ru/[/url] .
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем: сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr
продамус промокоды [url=https://prodams-promokod.ru]продамус промокоды[/url] .
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог в нижний новгороде[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому в новосибирске[/url]
sell account find accounts for sale
На https://www.google.com.tn/url?q=https://ruszaim.com/ ты найдешь то, что действительно работает: микрозаймы без звонков и отказов, с моментальным зачислением на карту. Для студентов, пенсионеров, самозанятых — без ограничений. Оформление онлайн, круглосуточно. Неважно, какой у тебя кредитный рейтинг — здесь шанс одобрения выше, чем где-либо.
Мы предлагаем дипломы любой профессии по приятным ценам.– [url=http://hustlacrips.forumex.ru/viewtopic.phpf=9&t=991/]hustlacrips.forumex.ru/viewtopic.phpf=9&t=991[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Узнать больше – http://kapelnica-ot-zapoya-novosibirsk8.ru/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Детальнее – http://narcolog-na-dom-nnovgorod8.ru
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков[/url]
Закажите металлические значки https://metal-archive.ru/novosti/40507-metallicheskie-znachki-na-zakaz-v-moskve-masterstvo-kachestvo-i-individualnyy-podhod.html с индивидуальным оформлением. Материалы: латунь, сталь, алюминий. Эмаль, гравировка, печать. Подходит для корпоративных мероприятий, сувениров, символики и наград.
Металлические нагрудные значки https://str-steel.ru/metallicheskie-nagrudnye-znachki.html стильный и долговечный аксессуар для сотрудников, мероприятий и награждений. Изготавливаем под заказ: с логотипом, гравировкой или эмалью. Разные формы, крепления и варианты отделки.
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
Назначение и действие
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом нижний новгород[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Выяснить больше – [url=https://vyvod-iz-zapoya-murmansk0.ru/]срочный вывод из запоя[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить дополнительную информацию – [url=https://narcolog-na-dom-mariupol0.ru/]выезд нарколога на дом[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – https://snyatie-lomki-ekb8.ru
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]www.domen.ru[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена в новосибирске[/url]
регистрация компании в великобритании открытие компании в англии
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом в нижний новгороде[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя анонимно в новосибирске[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Выяснить больше – http://kapelnica-ot-zapoya-novosibirsk8.ru
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому свердловская область[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом в нижний новгороде[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре екатеринбург[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом в нижний новгороде[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что способствует быстрому снижению уровня токсинов в крови, нормализации обменных процессов и стабилизации работы таких органов, как печень, почки и сердце.
Углубиться в тему – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя круглосуточно в мурманске[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом в нижний новгороде[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог екатеринбург[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Подробнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]после капельницы от запоя луганск[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена екатеринбург[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Детальнее – https://narcolog-na-dom-nnovgorod8.ru/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]narkolog-na-dom-czena nizhnij novgorod[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Узнать больше – https://narcolog-na-dom-nnovgorod8.ru/
Назначение и действие
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Ознакомиться с деталями – http://kapelnica-ot-zapoya-lugansk-lnr0.ru
Группа препаратов
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижегородская область[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Изучить вопрос глубже – http://kapelnica-ot-zapoya-novosibirsk8.ru
Назначение и действие
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Подробнее – http://snyatie-lomki-ekb8.ru
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Разобраться лучше – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом[/url]
регистрация компании в великобритании регистрация компании в великобритании
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Исследовать вопрос подробнее – http://
Функция
Выяснить больше – http://snyatie-lomki-nnovgorod8.ru
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]после капельницы от запоя луганск[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-novosibirsk8.ru
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя в екатеринбурге[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]срочный вывод из запоя екатеринбург[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск.[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого в нижний новгороде[/url]
ready-made accounts for sale account buying platform
buy and sell accounts buy account
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Углубиться в тему – http://kapelnica-ot-zapoya-novosibirsk8.ru
Экстренная капельничная терапия от запоя на дому в Луганске ЛНР имеет ряд преимуществ, благодаря которым лечение становится максимально оперативным и безопасным:
Выяснить больше – https://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr/
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом круглосуточно[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом в нижний новгороде[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижегородская область[/url]
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому луганск.[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя наркология луганск[/url]
Когда запой начинает оказывать разрушительное воздействие на организм, своевременная помощь становится критически важной для предотвращения серьезных осложнений. В Мурманске квалифицированные наркологи на дому обеспечивают оперативную детоксикацию, восстановление обменных процессов и стабилизацию работы внутренних органов. Лечение проводится в комфортной домашней обстановке, что позволяет избежать лишнего стресса и сохранить полную конфиденциальность.
Подробнее тут – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя круглосуточно в мурманске[/url]
Назначение
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя на дому цена мурманск[/url]
Назначение
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-novosibirsk8.ru
При тяжелых формах алкогольной интоксикации своевременное вмешательство критически важно для предотвращения опасных осложнений. В Луганске ЛНР специалисты по наркологии предоставляют услугу экстренной капельничной терапии на дому, что позволяет быстро снизить токсическую нагрузку и стабилизировать работу жизненно важных органов. Такой метод лечения позволяет обеспечить высокую эффективность терапии в комфортной, привычной для пациента обстановке, при этом сохраняется полная конфиденциальность.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]kapelnicza-ot-zapoya-na-domu lugansk[/url]
account exchange account trading
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Углубиться в тему – https://narcolog-na-dom-nnovgorod8.ru/zapoj-narkolog-na-dom-v-nnovgorode/
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone на дому в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Обращение за помощью к наркологу на дому имеет ряд преимуществ, особенно в экстренных ситуациях:
Узнать больше – http://narcolog-na-dom-mariupol0.ru/
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]snyat lomku novosibirsk[/url]
открыть компанию в великобритании https://zaregistrirovat-kompaniyu-england.com/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно в нижний новгороде[/url]
Заказываю регулярно.
https://lordlux1993.blogchaat.com/34920289/Как-зайти-на-Кракен-через-зеркало-1
Рад, что нашёл эту площадку.
https://kidennkarapuz5259.qodsblog.com/34862654/Что-такое-Кракен-и-как-им-пользоваться
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]narkolog-na-dom nizhnij novgorod[/url]
Рейтинг лучших сервисов https://vc.ru/telegram/1926953-nakrutka-podpischikov-v-telegram для накрутки Telegram-подписчиков: функциональность, качество, цены и скорость выполнения. Подходит для продвижения каналов любого масштаба — от старта до монетизации.
cloud server hosting cloud server cheap
secure account purchasing platform buy pre-made account
Jacuzzi, sauna, hammam https://spaplanet.net/ turnkey – full cycle: from design and selection of equipment to finishing and commissioning. We work with any premises. Reliable, aesthetically pleasing and with a guarantee.
открыть фирму в англии https://zaregistrirovat-kompaniyu-england.com
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Подробнее тут – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Назначение
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому в новосибирске[/url]
В условиях Донецка ДНР профессиональный вывод из запоя на дому организован по отлаженной схеме, которая включает несколько последовательных этапов. Такой комплексный подход позволяет не только быстро вывести токсичные вещества из организма, но и обеспечить стабильное восстановление всех систем организма.
Выяснить больше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому в донецке[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена[/url]
Мы изготавливаем дипломы любой профессии по выгодным тарифам.– [url=http://lixoro.de/read-blog/11180_kupit-diplom-tehnikum.html/]lixoro.de/read-blog/11180_kupit-diplom-tehnikum.html[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – http://snyatie-lomki-ekb8.ru
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]vyzvat-kapelniczu-ot-zapoya arhangel’sk[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок нижний новгород.[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург.[/url]
открыть компанию в англии открыть фирму в англии
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Углубиться в тему – http://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya novosibirsk[/url]
Современный и удобный сайт couponsworld.ru на котором легко найти нужную информацию, товары или услуги. Простая навигация, понятный интерфейс и актуальное содержание подойдут как для новых пользователей, так и для постоянной аудитории. Работает быстро, доступен круглосуточно.
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок[/url]
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя на дому цена в донецке[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить дополнительную информацию – http://vyvod-iz-zapoya-ekb8.ru
Всё просто и понятно.
https://sakaenkeep636.bcbloggers.com/33965583/Кракен-Казань-адрес-магазина
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить дополнительные сведения – http://narcolog-na-dom-nnovgorod8.ru
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Узнать больше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому круглосуточно[/url]
database of accounts for sale database of accounts for sale
secure account purchasing platform account trading
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить дополнительную информацию – http://narcolog-na-dom-nnovgorod8.ru
account exchange service buy pre-made account
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: срочный ремонт iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]narcolog-na-dom-nnovgorod8.ru/[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее можно узнать тут – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Выяснить больше – https://kapelnica-ot-zapoya-arkhangelsk00.ru/kapelnicza-ot-zapoya-czena-arkhangelsk/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому[/url]
Группа препаратов
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно екатеринбург[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снять ломку в екатеринбурге[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки в стационаре в нижний новгороде[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Ознакомиться с деталями – http://snyatie-lomki-ekb8.ru
Онлайн проект elsistems.ru где собраны полезные данные, инструменты и сервисы для повседневной жизни и профессиональной деятельности. Сайт адаптирован под любые устройства, стабильно работает и предоставляет максимум пользы без лишнего шума и рекламы.
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]срочный вывод из запоя в екатеринбурге[/url]
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург.[/url]
Howdy! Do you know if they make any plugins to safeguard against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any tips?
https://guidegen.com/
открыть бизнес в англии открыть фирму в великобритании
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Ознакомиться с деталями – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в стационаре в новосибирске[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт телефонов айфон в москве адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно в екатеринбурге[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить больше информации – http://
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя новосибирск[/url]
Функция
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижегородская область[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижегородская область[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее – http://
Современный и удобный сайт drauber.ru на котором легко найти нужную информацию, товары или услуги. Простая навигация, понятный интерфейс и актуальное содержание подойдут как для новых пользователей, так и для постоянной аудитории. Работает быстро, доступен круглосуточно.
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя в новосибирске[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому новосибирск.[/url]
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Исследовать вопрос подробнее – https://snyatie-lomki-novosibirsk8.ru/
Spintax Version of the Text:
Uncover the Best Aesthetic and Beauty Clinic in TX, USA: Icon Beauty Clinic.
Nestled in the dynamic core of Austin, Texas, this renowned clinic has gained recognition as a go-to spot for those seeking to enhance their personal charm. With a team of highly skilled professionals committed to excellence, this clinic offers a personalized experience that ensures every client feels respected, self-assured, and glowing. Whether you’re looking to refresh your appearance or invest in long-lasting beauty solutions, your trusted beauty partner is the ultimate choice for achieving classic allure.
—
Customized Care for Every Client
As soon as you enter your chosen beauty destination, you’ll appreciate the dedication to tailored services. All services is tailored to meet your specific requirements, using only premium products and state-of-the-art techniques. The dedicated experts takes the time to identify your objectives, ensuring that each procedure not only enhances your natural features but also fits seamlessly into your routine.
—
Let’s Explore Some of the Key Offerings That Make This Clinic a Innovator in the World of Cosmetics.
Lash Enhancement
Elevate the natural beauty of your eyes with an eyelash lift and tint. This treatment adds volume, length, and clarity to your lashes, removing the need for mascara every day. Great for on-the-go lifestyles or important events, the results last for weeks, giving you always polished eyes every day.
Plump Lips Treatment
Sensual, voluminous lips are a timeless beauty trend, and Icon Beauty Clinic offers lip fillers designed to deliver natural yet noticeable results. Using hyaluronic acid-based fillers, the procedure enhances the shape and volume of your lips, creating a vibrant and appealing appearance that lasts half a year to a full year.
Lash Additions
For those who crave intense, mesmerizing gazes, eyelash extensions are the ultimate answer. These semi-permanent lashes add intensity to your look, lasting for an extended period without the need for constant upkeep. Whether you favor subtle improvements or a dramatic flair, the specialists at your beauty partner will create the best fit for you.
Semi-Permanent Brows Texas Edition
One of the most sought-after services at this leading clinic is microblading brows. If you’re frustrated with daily brow grooming every morning, this innovative procedure offers a long-lasting solution. Using state-of-the-art tools, the expert technicians create beautifully defined arches that complement your natural beauty. Permanent makeup eyebrows in the Austin area have become a popular choice for contemporary clients seeking low-maintenance elegance.
Anti-Aging Injections
As we age, our skin naturally loses elasticity and volume. Icon Beauty Clinic offers a variety of non-surgical options, including skin rejuvenation injections, to bring back vitality. These non-surgical procedures reduce wrinkles, add contour, and leave your skin looking rejuvenated and glowing.
Tattoo Removal
If you’re prepared to remove an permanent design or previous body art, this advanced clinic provides advanced tattoo removal options. Using cutting-edge laser technology, these treatments effectively remove unwanted designs without surgery, leaving your skin smooth.
—
The Icon Difference
What truly differentiates your beauty partner apart is its commitment to excellence. The staff combines knowledge, innovation, and a love for aesthetics to deliver transformative experiences. All elements, from the friendly environment to the careful handling of each procedure, reflects their promise of offering an unparalleled experience.
If you’re from Austin or exploring the area, Icon Beauty Clinic is your destination for transformative beauty treatments. Their diverse offerings, including semi-permanent brow artistry in Texas, ensures that you can achieve the style you desire.
—
Final Thoughts
Your trusted beauty partner isn’t just about improving how you look—it’s about empowering you to feel beautiful in your own skin. By offering tailored services and advanced solutions, the clinic helps you unlock your full potential.
Don’t wait to invest in yourself. Visit Icon Beauty Clinic to discover how their professional treatments, including microblading brows in the Austin area, can elevate your confidence. Your path to elegance starts here.
—
Summary:
This top-rated clinic in Austin, TX is famous for its superior cosmetic solutions, including semi-permanent brow artistry, dramatic lashes, lip fillers, and tattoo removal. With a focus on personalized care and technical precision, it’s the ultimate destination for achieving timeless elegance.
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Детальнее – https://narcolog-na-dom-nnovgorod8.ru/
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы, стабилизируя работу печени, почек и сердечно-сосудистой системы.
Ознакомиться с деталями – https://vyvod-iz-zapoya-donetsk-dnr0.ru/vyvod-iz-zapoya-kruglosutochno-doneczk-dnr/
cloud server europe cloud server online
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Разобраться лучше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя донецк.[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее – http://snyatie-lomki-ekb8.ru
Kraken — отличный выбор.
https://vooltex1997.blog-kids.com/35059692/Как-зайти-на-Кракен-через-зеркало-3
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Подробнее тут – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]narkolog-vyvod-iz-zapoya donetsk[/url]
Назначение
Детальнее – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Выяснить больше – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод в нижний новгороде[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом[/url]
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Детальнее – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя капельница[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя в новосибирске[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-na-domu ekaterinburg[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Углубиться в тему – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]ломка от наркотиков[/url]
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого[/url]
database of accounts for sale account marketplace
account trading platform account market
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Углубиться в тему – http://kapelnica-ot-zapoya-novosibirsk8.ru/
При поступлении вызова нарколог незамедлительно прибывает на дом для проведения детального первичного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез, чтобы определить степень алкогольной интоксикации и сформировать индивидуальный план терапии.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя клиника[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно екатеринбург[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов, восстановления обменных процессов и нормализации работы таких органов, как печень, почки и сердце.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-arkhangelsk00.ru
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология в новосибирске[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре в екатеринбурге[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого нижний новгород[/url]
Обращение за помощью нарколога на дому в Архангельске имеет множество преимуществ, среди которых:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-arkhangelsk00.ru/]капельница от запоя цена архангельская область[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки нарколог новосибирск[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]ломка от наркотиков в новосибирске[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре[/url]
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя капельница[/url]
Служба поддержки вежливая и грамотная.
https://lamlasthuman2940.mdkblog.com/40709443/Кракен-зеркало-на-сегодня-3
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]www.domen.ru[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
cloud server solutions cloud server web hosting
Современный сайт take-auto.ru на котором легко найти нужную и полезную информацию, товары или услуги. Простая навигация, понятный интерфейс и актуальное содержание подойдут как для новых пользователей, так и для постоянной аудитории. Работает быстро, доступен круглосуточно.
открыть компанию в великобритании https://zaregistrirovat-kompaniyu-england.com
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызвать нарколога на дом калининград[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому в екатеринбурге[/url]
Назначение и действие
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника в нижний новгороде[/url]
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому в новосибирске[/url]
промокод prodamus [url=http://promokod-prodam.ru/]http://promokod-prodam.ru/[/url] .
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Узнать больше – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом анонимно в калининграде[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника[/url]
Назначение и действие
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому в екатеринбурге[/url]
Онлайн проект eventprime.ru где собраны полезные данные, инструменты и сервисы для повседневной жизни и профессиональной деятельности. Сайт адаптирован под любые устройства, стабильно работает и предоставляет максимум пользы без лишнего шума и рекламы.
[url=https://slote-casino.ru]slote-casino.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.slote-casino.ru
Цены адекватные.
https://nyancat549.blogs100.com/35338705/Как-попасть-на-официальный-сайт-copyright-4
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Ознакомиться с деталями – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie lomki na domu novosibirsk[/url]
Назначение
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]http://vyvod-iz-zapoya-ekb8.ru[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому свердловская область[/url]
website for selling accounts https://best-social-accounts.org
cloud server with crypto cloud server online
verified accounts for sale sell account
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить больше информации – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]www.domen.ru[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому луганск[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в екатеринбурге[/url]
заказать курсовую цена курсовая работа за деньги
сделать курсовую https://kursoviehelp.ru/
accounts marketplace profitable account sales
Современный сайт izdrevaya.ru на котором легко найти нужную и полезную информацию, товары или услуги. Простая навигация, понятный интерфейс и актуальное содержание подойдут как для новых пользователей, так и для постоянной аудитории. Работает быстро, доступен круглосуточно.
Капельничное лечение от запоя – это современный метод детоксикации, который позволяет быстро и безопасно вывести токсины из организма. В Луганске ЛНР специалисты оказывают помощь на дому, предлагая профессиональное капельничное лечение для тех, кто столкнулся с тяжелой алкогольной интоксикацией. Такой подход обеспечивает оперативное вмешательство в привычной для пациента обстановке, гарантируя индивидуальный подход и полную конфиденциальность.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому цена луганск[/url]
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя цена[/url]
[url=download-casino-phone.ru]download-casino-phone.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
download-casino-phone.ru
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Получить больше информации – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя цена в улан-удэ[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона с выездом мастера в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Thank you, I have recently been looking for info approximately this topic for a long time and yours is the greatest I have found out till now. But, what about the bottom line? Are you sure concerning the source?
Quick recharge mobile
Группа препаратов
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя в екатеринбурге[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена[/url]
account purchase buy pre-made account
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: мастер ремонта apple
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Car service brake pad replacement cost services We provide car repair services: from quick diagnostics to major restoration. Quality guarantee, experienced specialists, clear deadlines and original spare parts. We work with private and corporate clients.
naked whores price of cocaine in moscow
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно нижний новгород[/url]
Группа препаратов
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре в екатеринбурге[/url]
На данном этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие хронических заболеваний, что позволяет оперативно подобрать наиболее эффективные методы детоксикации и снизить риск осложнений.
Подробнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя анонимно луганск[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона в москве недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена нижний новгород[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника в екатеринбурге[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфонов в москве недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]narcolog-na-dom-nnovgorod8.ru/[/url]
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить больше информации – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]врача капельницу от запоя луганск[/url]
Капельничное лечение от запоя – это современный метод детоксикации, который позволяет быстро и безопасно вывести токсины из организма. В Луганске ЛНР специалисты оказывают помощь на дому, предлагая профессиональное капельничное лечение для тех, кто столкнулся с тяжелой алкогольной интоксикацией. Такой подход обеспечивает оперативное вмешательство в привычной для пациента обстановке, гарантируя индивидуальный подход и полную конфиденциальность.
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-lugansk-lnr0.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr/
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Узнать больше – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-czena-kaliningrad
wife whore darknet porn
Tired of fake videos and boring content? ??
Try real **live nude cams** at [jessicagoicoechea dot net]
?? Chat with curvy cam girls
?? Enjoy private shows
?? No signup needed to watch
? 100% live
? Available 24/7
? Interactive sex toys & real-time action
?? Want to know more? Visit:
Your best night is one click away
Hot Cam Shows After Dark
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Детальнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом недорого в калининграде[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов врача нарколога на дом[/url]
таможенный брокер москва таможенные услуги [url=https://tamozhennyj-broker11.ru/]таможенный брокер москва таможенные услуги[/url] .
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-czena ekaterinburg[/url]
heroin price buy hashish mephedrone cocaine
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Получить дополнительную информацию – http://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника в екатеринбурге[/url]
продамус промокод скидка [url=https://www.promokod-pro.ru]продамус промокод скидка[/url] .
Назначение
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника в екатеринбурге[/url]
брокерские услуги по таможенному оформлению [url=tamozhennyj-broker12.ru]брокерские услуги по таможенному оформлению[/url] .
таможенный брокер москва таможенные услуги [url=www.tamozhennyj-broker13.ru]таможенный брокер москва таможенные услуги[/url] .
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
Назначение
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]https://vyvod-iz-zapoya-ekb8.ru/[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом в нижний новгороде[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому в екатеринбурге[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод в нижний новгороде[/url]
При поступлении вызова наши опытные специалисты незамедлительно приступают к комплексной диагностике состояния пациента. Первая задача – оценить уровень интоксикации и тяжесть симптомов, что включает измерение показателей артериального давления, пульса, температуры тела, а также уровня насыщения крови кислородом. На основании собранных данных формируется индивидуальная схема лечения, которая направлена на быстрое снятие симптомов ломки и стабилизацию нервной и иммунной систем.
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]lomka ot narkotikov novosibirsk[/url]
Лечение нарколога на дому в Калининграде проводится по четко отлаженной схеме, включающей несколько последовательных этапов, позволяющих максимально быстро стабилизировать состояние пациента и начать процесс выздоровления.
Выяснить больше – [url=https://narcolog-na-dom-kaliningrad0.ru/]выезд нарколога на дом калининград[/url]
Лечение вывода из запоя на дому в Улан-Удэ организовано по чётко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс восстановления.
Изучить вопрос глубже – https://vyvod-iz-zapoya-ulan-ude0.ru/vyvod-iz-zapoya-na-domu-ulan-ude
Группа препаратов
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому в новосибирске[/url]
услуги растаможки грузов [url=tamozhennyj-broker11.ru]tamozhennyj-broker11.ru[/url] .
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирская область[/url]
Простой и понятный интерфейс.
https://trout439.blogofchange.com/35452042/Где-работает-Кракен-фургон
check here https://xmaquina.net/
Группа препаратов
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена екатеринбург[/url]
карго посредник [url=https://www.tamozhennyj-broker12.ru]https://www.tamozhennyj-broker12.ru[/url] .
Лечение вывода из запоя на дому в Улан-Удэ организовано по чётко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс восстановления.
Получить дополнительные сведения – http://vyvod-iz-zapoya-ulan-ude0.ru
таможенный брокер саратов [url=http://tamozhennyj-broker13.ru/]http://tamozhennyj-broker13.ru/[/url] .
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена новосибирск[/url]
Vavada.kesug.com — ваш лучший выбор для онлайн-игр, используйте бонусы и акции.
Vavada.kesug.com — ведущий онлайн-казино, наслаждайтесь широким выбором игр.
Здесь каждый найдет свою игру — vavada.kesug.com, начинайте выигрывать.
Обеспечиваем безопасность и честность игр — vavada.kesug.com, испытайте удачу.
Vavada.kesug.com — место для настоящих игроков, испытайте азарт.
Vavada.kesug.com — современное онлайн-казино, открывайте новые игры.
Испытайте удачу на vavada.kesug.com, получайте выигрыши.
Vavada.kesug.com — ваш источник развлечений, присоединяйтесь к нам.
Играйте безопасно и честно — vavada.kesug.com, испытайте свою удачу.
Vavada.kesug.com — лучшие бонусы и акции, играйте с бонусами.
Vavada.kesug.com — онлайн-игры и ставки, играйте с нами.
Играйте без риска — vavada.kesug.com, выигрывайте реальные деньги.
Обеспечиваем честность и безопасность — vavada.kesug.com, начинайте прямо сейчас.
Vavada.kesug.com — для любителей азартных игр, получайте выигрыши.
Откройте для себя новые игры — vavada.kesug.com, используйте бонусные коды.
Vavada.kesug.com — ваш источник удовольствия, используйте предложения.
Vavada.kesug.com — место для азартных игр онлайн, получайте удовольствие.
Официальный сайт с лучшими условиями — vavada.kesug.com, используйте бонусы
игра вавада [url=https://vavada.kesug.com/]игра вавада[/url] .
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Детальнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом анонимно[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом клиника[/url]
Группа препаратов
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя клиника[/url]
аукцион курсовых работ курсовая работа на
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя капельница[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом[/url]
Назначение
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя[/url]
При поступлении вызова наши опытные специалисты незамедлительно приступают к комплексной диагностике состояния пациента. Первая задача – оценить уровень интоксикации и тяжесть симптомов, что включает измерение показателей артериального давления, пульса, температуры тела, а также уровня насыщения крови кислородом. На основании собранных данных формируется индивидуальная схема лечения, которая направлена на быстрое снятие симптомов ломки и стабилизацию нервной и иммунной систем.
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому недорого в новосибирске[/url]
verified accounts for sale account buying service
Назначение
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя екатеринбург[/url]
secure account sales https://sale-social-accounts.org
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Получить больше информации – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя цена луганск[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Выяснить больше – http://
account catalog account purchase
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология[/url]
Назначение и действие
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]posle-kapelniczy-ot-zapoya lugansk[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в екатеринбурге[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно нижний новгород[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки[/url]
Назначение
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя свердловская область[/url]
Лечение нарколога на дому в Калининграде организовано по четко отлаженной схеме, позволяющей максимально оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом круглосуточно[/url]
Группа препаратов
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]http://vyvod-iz-zapoya-ekb8.ru/[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки[/url]
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr/
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов[/url]
Экстренная капельничная терапия от запоя на дому в Луганске ЛНР имеет ряд преимуществ, благодаря которым лечение становится максимально оперативным и безопасным:
Получить больше информации – https://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr
цена курсовая написать курсовую цена
buy drugs heroin porn ladies
заказать курсовой проект курсовая онлайн
?? Ever wondered if nude cam girls fake their reactions? Or how safe those live sex chat platforms really are?
We break it down at ?? livenude the home of real insights on live nude webcams.
?? Discover:
– Do models fake it — or feel it?
– Are nude cam sites safe for you?
– Why people watch cam girls (psychology behind it)
– What’s trending in YEAR on live cam platforms
?? Real girls. Real shows. Real answers.
Check it all here:
Your guide to nude webcams
https://livenude.xyz/do-live-nude-webcam-models-fake-their-reactions-the-truth-revealed/
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом в нижний новгороде[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Изучить вопрос глубже – https://narcolog-na-dom-kaliningrad0.ru/vrach-narkolog-na-dom-kaliningrad/
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Узнать больше – [url=https://narcolog-na-dom-kaliningrad00.ru/]вызов врача нарколога на дом[/url]
Предлагаем качественные клинкерная плитка цена — ступени и плитка для наружных и внутренних работ. Устойчив к износу, влаге и морозу. Подходит для лестниц, крылец, балконов. Консультации и заказ в один шаг.
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом в нижний новгороде[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
Looking for live nude fun, cam model guides, or ways to make money from the webcam industry?
?? Visit **littlecocktease com** and get access to:
?? Free cam site hacks
?? How to watch more and spend less
?? Best webcam affiliate programs
?? Tips on becoming a webcam model
?? Psychology of why cams are so addictive
Real advice from real users. Perfect if you’re watching, earning, or thinking about joining the adult cam world.
Check full articles here:
?? Don’t just watch — learn how to get the most out of every show.
https://littlecocktease.com/blog/insider-tips-how-to-get-the-most-out-of-free-cam-sites/
Услуга вывода из запоя на дому в Улан-Удэ включает полный комплекс мер, направленных на быстрое восстановление организма. При получении вызова нарколог приезжает на дом, проводит тщательный первичный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез. На основе полученных данных формируется индивидуальный план терапии, который может включать инфузионное введение медикаментов с применением современных технологий и оказание психологической поддержки для достижения устойчивой ремиссии.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]нарколог вывод из запоя улан-удэ[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр iphone в москве адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Выяснить больше – http://kapelnica-ot-zapoya-lugansk-lnr0.ru
[url=https://download-riobet-casino.ru]download-riobet-casino.ru[/url]
По ссылке ниже — полезный гайд по игре в казино Riobet. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
download-riobet-casino.ru
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снять ломку[/url]
Группа препаратов
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника екатеринбург[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом нижний новгород.[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya-czena novosibirsk[/url]
Металлические значки https://esnys.ru/katalog-statej/izgotovlenie-metallicheskih-znachkov-metodom-himicheskogo-travleniya-iskusstvo-detalizaczii-i-dolgovechnosti.html с логотипом, надписью или символикой — надёжный способ подчеркнуть стиль и статус. Предлагаем разные технологии, формы и варианты покрытия. Производство и доставка по всей России.
Значки из металла https://rus-week.ru/biznes-idei/metallicheskie-znachki-premialnogo-kachestva-luchshie-resheniya-dlya-brendinga/ это практичный и презентабельный атрибут для бизнеса, торжеств и наград. Мы производим значки с эмалью, гравировкой, штамповкой. Доступны различные формы, размеры и виды креплений.
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]https://vyvod-iz-zapoya-ekb8.ru[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона с выездом мастера в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Когда алкогольный запой угрожает здоровью, оперативное и квалифицированное вмешательство становится жизненно необходимым. В Улан-Удэ специалисты по наркологии оказывают помощь на дому, обеспечивая скорейшую детоксикацию организма, восстановление обменных процессов и стабилизацию работы внутренних органов. Такой подход позволяет пациенту получить комплексное лечение в комфортной домашней обстановке с полным соблюдением конфиденциальности.
Получить дополнительные сведения – http://vyvod-iz-zapoya-ulan-ude0.ru/
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]после капельницы от запоя новосибирск[/url]
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом недорого в калининграде[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]https://snyatie-lomki-ekb8.ru/[/url]
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Детальнее – http://narcolog-na-dom-kaliningrad00.ru/vrach-narkolog-na-dom-kaliningrad/https://narcolog-na-dom-kaliningrad00.ru
Назначение и действие
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижний новгород.[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника в нижний новгороде[/url]
Группа препаратов
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом в нижний новгороде[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Разобраться лучше – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом анонимно в калининграде[/url]
account trading platform sell pre-made account
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone вызвать мастера
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
услуги таможенного брокера цена [url=www.tamozhennyj-broker12.ru/]услуги таможенного брокера цена[/url] .
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт iphone вызвать мастера
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Группа препаратов
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Выбор правильной технологии https://wfinbiz.com/bez-rubriki/proizvodstvo-premialnyh-znachkov-tehnologii-i-metody-izgotovleniya-znachkov-vklyuchaya-himicheskoe-travlenie-i-ego-preimushhestva/ ключ к созданию значков, которые действительно производят впечатление. Чтобы значки премиального уровня действительно выглядели достойно, необходимо правильно подобрать технологию производства. Методы, такие как химическое травление, обеспечивают высокую детализацию и благородный внешний вид, который сохраняется надолго.
Лечение в Китае https://chemodantour.ru туры в лучшие медицинские центры страны. Традиционная и современная медицина, точная диагностика, восстановление и реабилитация. Сопровождение на всех этапах поездки.
buy accounts account trading platform
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]вызвать капельницу от запоя на дому луганск[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом нижний новгород[/url]
Группа препаратов
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя недорого[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: мастер по ремонту iphone
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому[/url]
таможенное оформление грузов москва [url=https://tamozhennyj-broker13.ru]таможенное оформление грузов москва[/url] .
Процесс лечения капельничной терапией в условиях экстренной помощи в Луганске ЛНР состоит из нескольких этапов, каждый из которых направлен на быструю и безопасную детоксикацию организма.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]вызвать капельницу от запоя луганск[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург.[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника нижний новгород[/url]
Назначение и действие
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно в нижний новгороде[/url]
Услуга “Нарколог на дом” в Калининграде, Калининградская область, включает комплекс мер, направленных на оперативный вывод из запоя и детоксикацию организма. Сразу после поступления вызова специалист проводит детальный первичный осмотр, измеряет жизненно важные показатели и собирает анамнез, чтобы оценить степень алкогольной интоксикации. На основе полученной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение современных медикаментов, использование инфузионных технологий и оказание психологической поддержки для долгосрочной реабилитации.
Узнать больше – [url=https://narcolog-na-dom-kaliningrad00.ru/]vrach-narkolog-na-dom kaliningrad[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена в екатеринбурге[/url]
Группа препаратов
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно[/url]
заказать пластиковые окна от производителя недорого [url=https://1okno-krasnodar.ru]https://1okno-krasnodar.ru[/url] .
Назначение и действие
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород.[/url]
account store account exchange service
Назначение
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя в новосибирске[/url]
таможенные услуги москва [url=http://www.tamozhennyj-broker12.ru]таможенные услуги москва[/url] .
ролл жалюзи на окна [url=https://rulonnye-shtory-s-elektroprivodom10.ru]ролл жалюзи на окна[/url] .
account selling platform secure account purchasing platform
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена екатеринбург[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом срочно[/url]
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Узнать больше – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad
Назначение и действие
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]vrach-narkolog-na-dom kaliningrad[/url]
заказать окна пвх [url=http://okna177.ru]http://okna177.ru[/url] .
цена курсовой работы https://kursoviehelp.ru/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно нижний новгород[/url]
пластиковые окна от производителя недорого [url=http://02stroika.ru]http://02stroika.ru[/url] .
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому екатеринбург.[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Выяснить больше – https://kapelnica-ot-zapoya-lugansk-lnr00.ru/kapelnicza-ot-zapoya-czena-lugansk-lnr
таможенное оформление брокер [url=http://tamozhennyj-broker13.ru]таможенное оформление брокер[/url] .
O site oficial 1win bet http://1winbr.com.br e apostar em desporto, casinos, jogos e torneios. Suporte para diversas moedas, transacoes rapidas, promocoes e cashback. Jogue confortavelmente no seu PC ou atraves da aplicacao.
Назначение и действие
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом[/url]
Группа препаратов
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]http://vyvod-iz-zapoya-ekb8.ru/[/url]
Группа препаратов
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом нижний новгород.[/url]
imp source [url=https://thepayco-r-login.com/]paycor employee login[/url]
Группа препаратов
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя капельница в екатеринбурге[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом вывод из запоя[/url]
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
стоимость рулонных жалюзи [url=www.rulonnye-shtory-s-elektroprivodom10.ru/]стоимость рулонных жалюзи[/url] .
Группа препаратов
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно[/url]
Назначение и действие
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого[/url]
таможенный брокер представитель [url=http://www.tamozhennyj-broker12.ru]таможенный брокер представитель[/url] .
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому в улан-удэ[/url]
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Получить дополнительную информацию – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-czena-kaliningrad
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Подробнее – http://narcolog-na-dom-kaliningrad0.ru
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом недорого калининград[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]narkolog-na-dom nizhnij novgorod[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки на дому[/url]
Назначение и действие
Детальнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно в нижний новгороде[/url]
таможенные услуги москва [url=https://tamozhennyj-broker13.ru]таможенные услуги москва[/url] .
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно в нижний новгороде[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому в екатеринбурге[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом нижний новгород[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург.[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]https://kapelnica-ot-zapoya-novosibirsk8.ru[/url]
Группа препаратов
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya ekaterinburg[/url]
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Исследовать вопрос подробнее – http://narcolog-na-dom-kaliningrad0.ru
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого нижний новгород[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирск.[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]narkolog-na-dom kaliningrad[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]http://snyatie-lomki-ekb8.ru[/url]
Назначение и действие
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод в нижний новгороде[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]www.domen.ru[/url]
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом в нижний новгороде[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Ознакомиться с деталями – http://narcolog-na-dom-kaliningrad0.ru/vrach-narkolog-na-dom-kaliningrad/https://narcolog-na-dom-kaliningrad0.ru
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]http://snyatie-lomki-ekb8.ru/[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок[/url]
рулонные шторы на электроприводе [url=www.rulonnye-shtory-s-elektroprivodom10.ru]рулонные шторы на электроприводе[/url] .
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя новосибирск[/url]
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Получить больше информации – http://narcolog-na-dom-kaliningrad0.ru
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]narkolog-vyvod-iz-zapoya ekaterinburg[/url]
1xBet promo code https://dnaqua.net/wp-content/pgs/sovety_po_prohoghdeniyu_infernal_osnovnye_missii_004.html is an opportunity to get a bonus of up to 100% on your first deposit. Register, enter the code and start betting with additional funds. Fast, simple and profitable.
Функция
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]lomka ot narkotikov nizhnij novgorod[/url]
1xBet promo code http://dansermag.com/wp-content/pages/?sovety_po_prohoghdeniyu_codename_panzers_phase_two_osnovnye_missii_041.html is your chance to start with a bonus! Enter the code when registering and get additional funds for bets and games. Suitable for sports events, live bets and casino. The bonus is activated automatically after replenishing the account.
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом в нижний новгороде[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в новосибирске[/url]
Назначение
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]http://vyvod-iz-zapoya-ekb8.ru/[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре в екатеринбурге[/url]
hop over to this site https://web-foxwallet.com
Когда алкогольный запой угрожает здоровью, оперативное и квалифицированное вмешательство становится жизненно необходимым. В Улан-Удэ специалисты по наркологии оказывают помощь на дому, обеспечивая скорейшую детоксикацию организма, восстановление обменных процессов и стабилизацию работы внутренних органов. Такой подход позволяет пациенту получить комплексное лечение в комфортной домашней обстановке с полным соблюдением конфиденциальности.
Узнать больше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому[/url]
Услуга «Нарколог на дом» в Калининграде предусматривает комплексное лечение запоя, которое начинается с детального осмотра и диагностики состояния пациента. Специалист измеряет жизненно важные показатели, собирает анамнез и оценивает степень алкогольной интоксикации. На основании полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозное лечение с использованием капельничного введения препаратов, а также психологическую поддержку, необходимую для устойчивой реабилитации и предупреждения рецидивов.
Получить дополнительные сведения – [url=https://narcolog-na-dom-kaliningrad0.ru/]врач нарколог на дом калининград[/url]
Группа препаратов
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре екатеринбург[/url]
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург.[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]lomka ot narkotikov ekaterinburg[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]narkolog-na-dom-czena kaliningrad[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов врача нарколога на дом в нижний новгороде[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]vyzov-narkologa-na-dom kaliningrad[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad0.ru/]врач нарколог на дом калининград.[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому в екатеринбурге[/url]
Назначение
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена в екатеринбурге[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя в новосибирске[/url]
Назначение
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя новосибирск[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки в стационаре[/url]
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом вывод калининград[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Углубиться в тему – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому свердловская область[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому[/url]
Процесс лечения капельничной терапией в условиях экстренной помощи в Луганске ЛНР состоит из нескольких этапов, каждый из которых направлен на быструю и безопасную детоксикацию организма.
Получить больше информации – http://kapelnica-ot-zapoya-lugansk-lnr00.ru
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому цена нижний новгород[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд новосибирск[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя в новосибирске[/url]
Назначение
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург.[/url]
Назначение и действие
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом нижегородская область[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Детальнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]https://narcolog-na-dom-nnovgorod8.ru/[/url]
Группа препаратов
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya ekaterinburg[/url]
Назначение и действие
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород.[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]после капельницы от запоя[/url]
Назначение и действие
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого в нижний новгороде[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом анонимно в калининграде[/url]
Нужен номер для ТГ? Предлагаем купить временный номер для телеграм для одноразовой или постоянной активации. Регистрация аккаунта без SIM-карты, в любом регионе. Удобно, надёжно, без привязки к оператору.
account exchange service accounts market
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижегородская область[/url]
Назначение
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-ekb8.ru/[/url]
account market https://accounts-marketplace.xyz
Назначение и действие
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом[/url]
Экскурсии по Красноярску tour-guide8.ru индивидуальные прогулки и групповые туры. Красивые виды, история города, заповедные места. Гиды с опытом, удобные форматы, гибкий график. Подарите себе незабываемые впечатления!
buy and sell accounts accounts market
светодиодный экран hd https://svetodiodnye-ekrany-videosteny.ru/
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]нарколог вывод из запоя[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Подробнее тут – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом срочно калининград[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод нижний новгород[/url]
Continue Reading https://web-foxwallet.com
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr/
account catalog https://social-accounts-marketplaces.live
Назначение
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя капельница[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя луганск[/url]
Группа препаратов
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому в екатеринбурге[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому свердловская область[/url]
Группа препаратов
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя капельница екатеринбург[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом в нижний новгороде[/url]
Группа препаратов
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому в екатеринбурге[/url]
Нужен номер для ТГ? Предлагаем аренда номера для тг для одноразовой или постоянной активации. Регистрация аккаунта без SIM-карты, в любом регионе. Удобно, надёжно, без привязки к оператору.
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызвать нарколога на дом калининград[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad0.ru/]вызвать нарколога на дом в калининграде[/url]
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Детальнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]врач нарколог на дом калининград.[/url]
Группа препаратов
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена в екатеринбурге[/url]
Группа препаратов
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
KRAKEN — это гарантия анонимности
Лечение нарколога на дому в Калининграде проводится по четко отлаженной схеме, включающей несколько последовательных этапов, позволяющих максимально быстро стабилизировать состояние пациента и начать процесс выздоровления.
Подробнее можно узнать тут – http://narcolog-na-dom-kaliningrad0.ru
Назначение
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург.[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод нижний новгород[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом срочно калининград[/url]
[url=https://kuban.photo]Паспорт кубани фото[/url]
[url=https://kuban.photo]Фото въезд в краснодар[/url]
[url=https://kuban.photo]Въезд в краснодар фото[/url]
[url=https://kuban.photo]Природа краснодарского края фото[/url]
[url=https://kuban.photo]Паспорт кубани фото[/url]
кубань фото природы, новые фото кубань, промышленность кубани, памятник в кабардинке затонувшему кораблю, армянская церковь славянск на кубани
kuban.photo
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Получить больше информации – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
Группа препаратов
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]срочный вывод из запоя[/url]
account marketplace https://accounts-marketplace.live/
Процесс лечения капельничной терапией в условиях экстренной помощи в Луганске ЛНР состоит из нескольких этапов, каждый из которых направлен на быструю и безопасную детоксикацию организма.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr/https://kapelnica-ot-zapoya-lugansk-lnr00.ru
account selling service https://social-accounts-marketplace.xyz
Назначение и действие
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом в нижний новгороде[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого в нижний новгороде[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]https://snyatie-lomki-ekb8.ru/[/url]
Вам требуется лечение? стоматологические туры в хуньчунь лечение хронических заболеваний, восстановление после операций, укрепление иммунитета. Включено всё — от клиники до трансфера и проживания.
sell account https://buy-accounts.space
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя в новосибирске[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя анонимно новосибирск[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов нарколога на дом нижний новгород[/url]
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом цена в калининграде[/url]
Назначение и действие
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом[/url]
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Получить дополнительную информацию – http://narcolog-na-dom-kaliningrad00.ru
ноутбук acer цена купить ноутбук msi
электроника магазин купить маркетплейс электроники
купить смартфон note купить новый смартфон
Назначение и действие
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена екатеринбург[/url]
сюда [url=https://tripscantop22.top/]tripscan17 id[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом недорого в калининграде[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся методом инфузии, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Получить больше информации – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]vyvod-iz-zapoya-na-domu ulan-ude[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена[/url]
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Получить дополнительную информацию – http://kapelnica-ot-zapoya-lugansk-lnr0.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr/
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно екатеринбург[/url]
Назначение и действие
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод нижний новгород[/url]
Назначение и действие
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Получить дополнительные сведения – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом калининград.[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Подробнее тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя клиника[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врача капельницу от запоя в новосибирске[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]https://kapelnica-ot-zapoya-novosibirsk8.ru/[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно нижний новгород[/url]
?? Ever wondered if nude cam girls fake their reactions? Or how safe those live sex chat platforms really are?
We break it down at ?? livenude the home of real insights on live nude webcams.
?? Discover:
– Do models fake it — or feel it?
– Are nude cam sites safe for you?
– Why people watch cam girls (psychology behind it)
– What’s trending in YEAR on live cam platforms
?? Real girls. Real shows. Real answers.
Check it all here:
Your guide to nude webcams
https://livenude.xyz/the-psychology-behind-watching-live-nude-webcam-models/
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить больше информации – http://kapelnica-ot-zapoya-lugansk-lnr00.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr/
Функция
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург.[/url]
account sale https://buy-accounts-shop.pro/
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие наркотической ломки в екатеринбурге[/url]
Назначение и действие
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]narkolog-na-dom nizhnij novgorod[/url]
accounts market https://accounts-marketplace.art
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Детальнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника в нижний новгороде[/url]
купить новый ноутбук купить ноутбук lenovo
сколько магазинов электроники магазин электроники
смартфон 10 цена купить смартфон редми
Когда алкогольная интоксикация становится угрозой для здоровья, оперативное вмешательство и качественное лечение на дому играют ключевую роль в спасении жизни. В Калининграде опытные наркологи выезжают на дом, чтобы обеспечить своевременную детоксикацию, стабилизацию работы внутренних органов и оказание психологической поддержки. Такой подход позволяет пациентам получить квалифицированную помощь в комфортной и привычной обстановке, сохраняя конфиденциальность и избегая лишнего стресса, связанного с госпитализацией.
Подробнее – [url=https://narcolog-na-dom-kaliningrad0.ru/]narkolog-na-dom-kruglosutochno kaliningrad[/url]
Назначение
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя новосибирск[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому нижний новгород[/url]
Группа препаратов
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
Назначение
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно екатеринбург[/url]
Сразу после вызова нарколог приезжает на дом для проведения тщательного первичного осмотра. Врач измеряет такие жизненно важные показатели, как пульс, артериальное давление и температура, а также собирает подробный анамнез, чтобы оценить степень алкогольной интоксикации.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad0.ru/]врач нарколог на дом калининград.[/url]
магазин электроники техник магазины для покупки электроники
купить смартфон huawei смартфон redmi купить
account selling service https://social-accounts-marketplace.live
ноутбук asus цена цена ноутбука для работы
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом круглосуточно калининград[/url]
account trading platform https://buy-accounts.live
Группа препаратов
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-kruglosutochno ekaterinburg[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]www.domen.ru[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижний новгород.[/url]
accounts for sale accounts marketplace
Лечение нарколога на дому в Калининграде проводится по четко отлаженной схеме, включающей несколько последовательных этапов, позволяющих максимально быстро стабилизировать состояние пациента и начать процесс выздоровления.
Углубиться в тему – http://narcolog-na-dom-kaliningrad0.ru
Назначение
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]нарколог вывод из запоя в екатеринбурге[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-lugansk-lnr00.ru
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Подробнее – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом калининград.[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
Назначение
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург[/url]
Назначение
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена екатеринбург.[/url]
Назначение
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно екатеринбург[/url]
Назначение
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnica-ot-zapoya-novosibirsk8.ru/[/url]
промокод на продамус [url=https://promokod-prod.ru/]промокод на продамус[/url] .
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника в екатеринбурге[/url]
На этом этапе специалист уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет разработать персонализированный план лечения, что существенно снижает риск осложнений.
Ознакомиться с деталями – https://narcolog-na-dom-kaliningrad0.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому круглосуточно улан-удэ[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому в екатеринбурге[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого в екатеринбурге[/url]
Экстренная капельничная терапия от запоя на дому в Луганске ЛНР имеет ряд преимуществ, благодаря которым лечение становится максимально оперативным и безопасным:
Детальнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя вызов в луганске[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки нижний новгород[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре екатеринбург[/url]
магазин электроники покупка электроники интернет магазины
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]наркология вывод из запоя[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно в екатеринбурге[/url]
Функция
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]snyat lomku nizhnij novgorod[/url]
Назначение
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya-czena novosibirsk[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Подробнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя наркология в луганске[/url]
Назначение
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя недорого екатеринбург[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд существенных преимуществ:
Углубиться в тему – [url=https://narcolog-na-dom-kaliningrad0.ru/]нарколог на дом калининградская область[/url]
Назначение и действие
Разобраться лучше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижегородская область[/url]
Назначение
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя в новосибирске[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Подробнее – [url=https://snyatie-lomki-ekb8.ru/]www.domen.ru[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]нарколог вывод из запоя в екатеринбурге[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому цена[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре в екатеринбурге[/url]
[url=https://kuban.photo]Фото про край[/url]
[url=https://kuban.photo]Фото краснодарского края сегодня[/url]
[url=https://kuban.photo]Фото краснодарский край фото[/url]
[url=https://kuban.photo]Село краснопартизанское краснодарский край[/url]
[url=https://kuban.photo]Фото въезд в краснодар[/url]
село новое село краснодарский край фото, фото про край, музей природы славянск на кубани, природа краснодарского края фото, жители краснодарского края фото
kuban.photo
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена в екатеринбурге[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов в новосибирске[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в екатеринбурге[/url]
Группа препаратов
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом в нижний новгороде[/url]
купить ноутбук асус купить ноутбук для работы
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом круглосуточно[/url]
купить смартфон нова купить смартфон xiaomi
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок на дому[/url]
[url=https://download-pin-casino.ru]download-pin-casino.ru[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать онлайн Pin-Up казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
download-pin-casino.ru
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Разобраться лучше – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr/
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре екатеринбург[/url]
When social ideals collapse, personal truth often begins with generic viagra. Certified excellence means peace of mind at every stage of your journey.
Диплом ВУЗа России!
Без института трудно было продвигаться вверх по карьере. Купить диплом под заказ в столице вы можете используя официальный сайт компании: [url=http://comptonrpp.listbb.ru/viewtopic.phpf=6&t=3237/]comptonrpp.listbb.ru/viewtopic.phpf=6&t=3237[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому екатеринбург.[/url]
[url=https://download-free-pin-casino.ru]download-free-pin-casino.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино Pin up в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.download-free-pin-casino.ru
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов врача нарколога на дом нижний новгород[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снять ломку екатеринбург[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов в новосибирске[/url]
Оказываем услуги стоимость услуг по защите прав потребителей: консультации, подготовка претензий и исков, представительство в суде. Поможем вернуть деньги, заменить товар или взыскать компенсацию. Работаем быстро и по закону.
печать наклеек на пленке спб печать самоклеящихся наклеек
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя клиника[/url]
Назначение и действие
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом в нижний новгороде[/url]
Назначение
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-ekb8.ru/[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому цена в новосибирске[/url]
начать с нуля с криптовалютой [url=http://cryptohamsters.ru]http://cryptohamsters.ru[/url] .
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]kapelnica-ot-zapoya-lugansk-lnr0.ru/[/url]
Can a Negative Cash Flow Statement Indicate a Boom in Business? If so, could you explain the paradox and provide examples? [url=https://www.bizmaker.org/vilnius/business-services/esim-plus-279909]My blog[/url]
сайт [url=https://kra33at.at]kraken market[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]vrach-narkolog-na-dom nizhnij novgorod[/url]
purchase ready-made accounts https://accounts-marketplace-best.pro
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого нижний новгород[/url]
Профессиональный сервисный центр по ремонту техники.
Мы предлагаем: Ремонт бытовой техники срочно Брянск
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов[/url]
промокод на продамус [url=https://promokod-prodam.ru/]промокод на продамус[/url] .
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя екатеринбург[/url]
Назначение
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя[/url]
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Детальнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя клиника[/url]
После диагностики начинается активная фаза медикаментозного вмешательства, когда препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом клиника в калининграде[/url]
сервисы тойота в москве [url=www.toyota-mtr.ru/owners/maintenance/]www.toyota-mtr.ru/owners/maintenance/[/url] .
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом срочно нижний новгород[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург[/url]
Назначение и действие
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород.[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя клиника в новосибирске[/url]
Нужен номер для Телеграма? https://techalpaka.online для безопасной регистрации и анонимного использования. Поддержка популярных регионов, удобный интерфейс, моментальный доступ.
I went over this site and I believe you have a lot of great info , saved to favorites (:.
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя анонимно в новосибирске[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирская область[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]после капельницы от запоя новосибирск[/url]
Назначение и действие
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzvat-narkologa-na-dom nizhnij novgorod[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Выяснить больше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому круглосуточно улан-удэ[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Получить больше информации – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]врач на дом капельница от запоя[/url]
Экстренная капельничная терапия от запоя на дому в Луганске ЛНР имеет ряд преимуществ, благодаря которым лечение становится максимально оперативным и безопасным:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя вызов[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом в нижний новгороде[/url]
Назначение и действие
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом круглосуточно[/url]
содержание [url=https://vodkacasino.net/]зеркало vodkabet vodkabet[/url]
КРАКЕН всегда в топе среди даркнет-магазинов
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врача капельницу от запоя новосибирск[/url]
Функция
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана[/url]
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок[/url]
Назначение
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]нарколог вывод из запоя в екатеринбурге[/url]
Когда алкогольный запой угрожает здоровью, оперативное и квалифицированное вмешательство становится жизненно необходимым. В Улан-Удэ специалисты по наркологии оказывают помощь на дому, обеспечивая скорейшую детоксикацию организма, восстановление обменных процессов и стабилизацию работы внутренних органов. Такой подход позволяет пациенту получить комплексное лечение в комфортной домашней обстановке с полным соблюдением конфиденциальности.
Подробнее – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]наркологический вывод из запоя[/url]
купить аккаунт https://akkaunty-na-prodazhu.pro
Группа препаратов
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врача капельницу от запоя новосибирск[/url]
[url=https://kuban.photo]Мыс суджук[/url]
[url=https://kuban.photo]Новые фото кубань[/url]
[url=https://kuban.photo]Краснодарский край картинки фото[/url]
[url=https://kuban.photo]Природа кубани фото самые красивые места[/url]
[url=https://kuban.photo]Памятник валентине толкуновой[/url]
архитектура кубани, смотреть краснодарский край фото, кубань фото дзен, стадион нефтяник хадыженск, фото кубань
kuban.photo
маркетплейс аккаунтов соцсетей https://rynok-akkauntov.top/
обучение криптовалюте [url=https://cryptohamsters.ru/]обучение криптовалюте[/url] .
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя анонимно луганск[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя[/url]
Группа препаратов
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре[/url]
маркетплейс аккаунтов магазины аккаунтов
Современный темп жизни нередко приводит к ситуации, когда человеку, страдающему от алкогольной или наркотической зависимости, срочно требуется профессиональная медицинская помощь. Особенно актуально это в тех случаях, когда состояние пациента резко ухудшается и поездка в клинику становится невозможной или нежелательной из-за повышенного уровня тревожности. Наркологическая клиника «Импульс» предлагает услугу вызова нарколога на дом в Нижнем Новгороде, обеспечивая круглосуточную помощь на высоком профессиональном уровне. Такое решение позволяет избежать серьезных осложнений и обеспечить комфортные условия лечения в привычной обстановке.
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]запой нарколог на дом[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]срочный вывод из запоя екатеринбург[/url]
Зеркало KRAKEN работает стабильно
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена в екатеринбурге[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург.[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya ekaterinburg[/url]
their explanation [url=https://thecoi-base.com/]coinbase login[/url]
Назначение
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя свердловская область[/url]
Зеркала КРАКЕН всегда актуальны
Этот обзор сосредоточен на различных подходах к избавлению от зависимости. Мы изучим традиционные и альтернативные методы, а также их сочетание для достижения максимальной эффективности. Читатели смогут открыть для себя новые стратегии и подходы, которые помогут в их борьбе с зависимостями.
Углубиться в тему – [url=https://mednarkoforum.ru]центр реабилитации наркозависимости[/url]
Свежие тенденции https://www.life-ua.com советы по стилю и обзоры коллекций. Всё о моде, дизайне, одежде и аксессуарах для тех, кто хочет выглядеть современно и уверенно.
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Изучить вопрос глубже – http://vyvod-iz-zapoya-ekb8.ru
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена в новосибирске[/url]
Группа препаратов
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург[/url]
Услуга вывода из запоя на дому в Мурманске предполагает комплексное лечение алкогольной интоксикации, направленное на оперативное снижение уровня токсинов в организме. Сразу после поступления вызова специалист проводит детальный осмотр, собирает анамнез и определяет степень интоксикации. На основании собранной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение медикаментов, контроль жизненно важных показателей и психологическую поддержку. Такой комплекс мер позволяет стабилизировать состояние пациента и начать процесс выздоровления без необходимости посещения стационара.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk/
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Подробнее – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом вывод[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск.[/url]
Функция
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снять ломку нижний новгород[/url]
Профессиональный сервисный центр по ремонту техники.
Мы предлагаем: Сколько стоит ремонт холодильников Сургут
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Группа препаратов
Детальнее – http://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого[/url]
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Детальнее – https://narcolog-na-dom-mariupol00.ru/vyzov-narkologa-na-dom-mariupol/
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков город[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Выяснить больше – http://vyvod-iz-zapoya-murmansk00.ru/vyvod-iz-zapoya-czena-murmansk/
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снять ломку нижний новгород[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Изучить вопрос глубже – http://vyvod-iz-zapoya-murmansk00.ru/vyvod-iz-zapoya-kruglosutochno-murmansk/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому в екатеринбурге[/url]
Свежие тенденции https://www.life-ua.com советы по стилю и обзоры коллекций. Всё о моде, дизайне, одежде и аксессуарах для тех, кто хочет выглядеть современно и уверенно.
Следующая страница [url=https://t.me/prvaonline]Купить права категории CE[/url]
Looking for live nude fun, cam model guides, or ways to make money from the webcam industry?
?? Visit **littlecocktease com** and get access to:
?? Free cam site hacks
?? How to watch more and spend less
?? Best webcam affiliate programs
?? Tips on becoming a webcam model
?? Psychology of why cams are so addictive
Real advice from real users. Perfect if you’re watching, earning, or thinking about joining the adult cam world.
Check full articles here:
?? Don’t just watch — learn how to get the most out of every show.
https://littlecocktease.com/blog/how-to-enjoy-more-live-cam-shows-without-breaking-the-bank/
опубликовано здесь [url=https://vodkacasino.net/]vodkabet vodka casino[/url]
каталог [url=https://vodkacasino.net/]зеркало vodkabet[/url]
Функция
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Подробнее можно узнать тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому цена[/url]
Функция
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков в нижний новгороде[/url]
Группа препаратов
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки нижний новгород[/url]
маркетплейс аккаунтов https://akkaunt-magazin.online/
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
покупка аккаунтов https://akkaunty-market.live/
Лечение вывода из запоя на дому в Мурманске организовано по четко структурированной схеме, включающей следующие этапы, каждый из которых играет ключевую роль в оперативном восстановлении здоровья:
Подробнее можно узнать тут – http://vyvod-iz-zapoya-murmansk00.ru
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-ekb8.ru/[/url]
узнать больше Здесь [url=https://t.me/prvaonline/]Купить права на легковую[/url]
покупка аккаунтов https://kupit-akkaunty-market.xyz
https://dzen.ru/kitehurghada
Сразу после поступления вызова нарколог приезжает на дом для проведения детального первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает анамнез, чтобы оценить степень алкогольной интоксикации. Эти данные служат основой для разработки персонального плана терапии.
Разобраться лучше – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом клиника мариуполь[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]snyat lomku ekaterinburg[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-ekb8.ru/
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить больше информации – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя мурманск[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология[/url]
Любимые карточные игры на покерок. Новички и профессиональные игроки всё чаще выбирают площадку благодаря её стабильности и удобству. Здесь доступны кэш-игры, турниры с большими призовыми и эксклюзивные акции. Интерфейс адаптирован под мобильные устройства, а служба поддержки работает круглосуточно.
консультации и онлайн услуги защита прав потребителей: консультации, подготовка претензий и исков, представительство в суде. Поможем вернуть деньги, заменить товар или взыскать компенсацию. Работаем быстро и по закону.
продамус промокоды [url=http://promokod-prod.ru/]продамус промокоды[/url] .
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков[/url]
Строительный портал https://stroydelo33.ru источник актуальной информации для тех, кто строит, ремонтирует или планирует. Полезные советы, обзоры инструментов, этапы работ, расчёты и готовые решения для дома и бизнеса.
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки нижний новгород[/url]
Инженерные системы https://usteplo.ru основа комфортного и безопасного пространства. Проектирование, монтаж и обслуживание отопления, водоснабжения, вентиляции, электроснабжения и слаботочных систем для домов и предприятий.
Процесс вывода из запоя на дому в Мариуполе построен по четко отлаженной схеме, что позволяет быстро и безопасно восстановить здоровье пациента.
Получить дополнительные сведения – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом цена в мариуполе[/url]
Группа препаратов
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород.[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому цена в екатеринбурге[/url]
Функция
Подробнее – http://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя в новосибирске[/url]
роллетный шкаф [url=www.shkafy-parkovka.ru/]роллетный шкаф[/url] .
Группа препаратов
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом анонимно в нижний новгороде[/url]
Функция
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок нижний новгород.[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske/
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом[/url]
home [url=https://thecoi-base.com]coinbase pro login[/url]
Сразу после поступления вызова нарколог приезжает на дом для проведения детального первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает анамнез, чтобы оценить степень алкогольной интоксикации. Эти данные служат основой для разработки персонального плана терапии.
Подробнее – https://narcolog-na-dom-mariupol0.ru/
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Углубиться в тему – http://vyvod-iz-zapoya-ekb8.ru
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя екатеринбург[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Выяснить больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод[/url]
content [url=https://thecoi-base.com/]coinbase login[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя новосибирск.[/url]
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Ознакомиться с деталями – [url=https://narcolog-na-dom-mariupol0.ru/]vrach-narkolog-na-dom mariupol'[/url]
металлический шкаф с рольставнями [url=http://shkafy-parkovka.ru]металлический шкаф с рольставнями[/url] .
Любимые карточные игры на покерок. Новички и профессиональные игроки всё чаще выбирают площадку благодаря её стабильности и удобству. Здесь доступны кэш-игры, турниры с большими призовыми и эксклюзивные акции. Интерфейс адаптирован под мобильные устройства, а служба поддержки работает круглосуточно.
консультации и онлайн услуги защита прав потребителей услуг по законодательству: консультации, подготовка претензий и исков, представительство в суде. Поможем вернуть деньги, заменить товар или взыскать компенсацию. Работаем быстро и по закону.
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому нижегородская область[/url]
В современном финансовом мире получение быстрых займов становится всё более востребованным. Наш портал представляет собой уникальную площадку, где собраны свежие предложения от проверенных микрофинансовых организаций. Мы тщательно отбираем МФО, предоставляющие [url=https://ruszaim.com/]новые онлайн займы с одобрением[/url] и с интересными условиями, добавляя беспроцентные периоды. Особое внимание уделяется свежим и менее популярным компаниям, которые часто предлагают более выгодные условия для клиентов. Главный финансовый аналитик Андрей Фролов, эксперт с 15-летним опытом в сфере микрофинансирования, лично проверяет каждую организацию перед добавлением в наш каталог.
Понимая сложности, с которыми сталкиваются заемщики с проблемной кредитной историей, мы создали отдельный раздел, где представлены МФО, работающие с такими клиентами. Виктор Гардиенов, возглавляющий отдел клиентского обслуживания, и его команда каждый день помогают многим людей найти подходящие финансовые решения. Благодаря глубокой экспертизе Дмитрия Сверидова в области антикризисных стратегий, мы можем предложить не просто список займов, а комплексные рекомендации по улучшению финансового положения наших пользователей.
Наша миссия – сделать процесс получения займа максимально понятным и безопасным. Каждый месяц мы проверяем базу данных, проверяем актуальность условий и собираем обратную связь от реальных клиентов МФО. Это позволяет нам поддерживать высочайший уровень надежности представленной информации. Специалисты нашего портала регулярно проходят обучение и повышают квалификацию, чтобы быть в курсе всех изменений законодательства и рыночных трендов. Мы гордимся тем, что помогли уже более 500,000 человек найти подходящее финансовое решение в сложной ситуации.
Read More Here [url=https://sites.google.com/mycryptowalletus.com/metamaskwalletlogin/]MetaMask Download[/url]
Назначение
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена в новосибирске[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]vyzov-narkologa-na-dom nizhnij novgorod[/url]
Услуга нарколога на дому в Мариуполе организована для быстрого и безопасного вывода из запоя. Сразу после поступления вызова специалист прибывает на дом, где проводит первичный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученной информации формируется индивидуальный план терапии, который включает медикаментозную детоксикацию с применением современных методов инфузионной терапии и поддержку психотерапевта для создания условий для долгосрочной ремиссии.
Получить дополнительные сведения – [url=https://narcolog-na-dom-mariupol0.ru/]вызов нарколога на дом мариуполь[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – http://kapelnica-ot-zapoya-novosibirsk8.ru/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Выяснить больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя клиника в новосибирске[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Ознакомиться с деталями – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske/
Функция
Разобраться лучше – http://snyatie-lomki-nnovgorod8.ru
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Изучить вопрос глубже – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана нижний новгород[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого в нижний новгороде[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Углубиться в тему – http://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske/
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника нижний новгород[/url]
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Изучить вопрос глубже – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом клиника[/url]
Лечение вывода из запоя на дому в Мурманске организовано по четко структурированной схеме, включающей следующие этапы, каждый из которых играет ключевую роль в оперативном восстановлении здоровья:
Подробнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя в мурманске[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Детальнее – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-na-domu-v-ekb
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Получить больше информации – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом мариуполь[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Группа препаратов
Получить дополнительную информацию – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/https://snyatie-lomki-nnovgorod8.ru
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому нижний новгород[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Изучить вопрос глубже – https://narcolog-na-dom-nnovgorod8.ru/vyzov-narkologa-na-dom-v-nnovgorode/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]snyatie lomki na domu novosibirsk[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя на дому мурманск.[/url]
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Выяснить больше – https://narcolog-na-dom-mariupol00.ru/narkolog-na-dom-kruglosutochno-mariupol/
Наркологическая клиника «Нарколог лайф» — это место, где начинается путь к свободе от зависимости. Мы предлагаем безопасную детоксикацию, эффективное кодирование и полную реабилитацию с индивидуальным подходом. Наши специалисты работают круглосуточно, обеспечивая поддержку в любой момент.
Ознакомиться с деталями – [url=https://narcolog-life.com/alkogolizm/]алкоголизм цена[/url]
basics [url=https://sites.google.com/mycryptowalletus.com/phantom-wallet-login/]phantom Download[/url]
В клинике «Нарколог лайф» проводится профессиональное лечение зависимостей с гарантией конфиденциальности. Экстренная помощь, современные методики очистки организма, персонализированные программы восстановления и внимательное отношение к каждому пациенту — всё это помогает вернуть жизнь в нормальное русло.
Исследовать вопрос подробнее – [url=https://narcolog-life.com/article/kapli-snizhayushhie-tyagu-k-alkogolyu-chto-nuzhno-znat/]от алкоголя капли цена инструкция[/url]
Очень благодарен за честную сделку, кракен не подвёл.
https://telegra.ph/Kak-prodayut-vzlomannye-bazy-dannyh-na-kraken-05-12
this hyperlink [url=https://sites.google.com/mycryptowalletus.com/metamaskwalletlogin/]MetaMask Download[/url]
Francisk Skorina https://www.gsu.by Gomel State University. One of the leading academic and scientific-research centers of the Belarus. There are 12 Faculties at the University, 2 scientific and research institutes. Higher education in 35 specialities of the 1st degree of education and 22 specialities.
ГГУ имени Ф.Скорины https://www.gsu.by/ крупный учебный и научно-исследовательский центр Республики Беларусь. Высшее образование в сфере гуманитарных и естественных наук на 12 факультетах по 35 специальностям первой ступени образования и 22 специальностям второй, 69 специализациям.
С кракеном всё просто и приятно, как должно быть.
https://telegra.ph/Instrukciya-kak-ispolzovat-kraken-tor-brauzer2-05-12
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Разобраться лучше – http://snyatie-lomki-novosibirsk8.ru
look here [url=https://sites.google.com/mycryptowalletus.com/metamaskwalletlogin/]MetaMask Download[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]www.domen.ru[/url]
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Ознакомиться с деталями – http://narcolog-na-dom-nnovgorod8.ru/
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Выяснить больше – http://snyatie-lomki-ekb8.ru
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]www.domen.ru[/url]
Группа препаратов
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki narkozavisimogo nizhnij novgorod[/url]
В наркологической клинике «Нарколог лайф» вас ждёт профессиональный подход к лечению алкоголизма и наркомании. Мы обеспечиваем экстренный выезд специалистов, быстрое снятие интоксикации, а также комфортные условия для прохождения реабилитации. Наши методики направлены на долгосрочный результат.
Узнать больше – [url=https://narcolog-life.com/article/pochemu-alkogoliki-ne-mogut-sluzhit-v-armii/]алкоголиков берут в армию[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог[/url]
Наркологическая клиника «Нарколог лайф» — это место, где начинается путь к свободе от зависимости. Мы предлагаем безопасную детоксикацию, эффективное кодирование и полную реабилитацию с индивидуальным подходом. Наши специалисты работают круглосуточно, обеспечивая поддержку в любой момент.
Получить дополнительные сведения – [url=https://narcolog-life.com/article/pochemu-podrostki-stanovyatsya-narkozavisimymi-klyuchevye-faktory-riska/]подростки наркоманы[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить дополнительные сведения – http://narcolog-na-dom-nnovgorod8.ru
У маркетплейса KRAKEN хорошо работает служба поддержки.
https://telegra.ph/Kraken-zerkalo-i-torgovlya-oruzhiem4-05-12
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Углубиться в тему – [url=https://narcolog-life.com/diyeta-posle-zapoya/]диета после запоя алкогольного[/url]
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркомана в екатеринбурге[/url]
Назначение и действие
Получить дополнительные сведения – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижегородская область[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки новосибирск[/url]
[url=https://download-app-vavada-casino.ru]download-app-vavada-casino.ru[/url]
По ссылке ниже — полезный гайд по игре в казино Вавада. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
download-app-vavada-casino.ru
площадка для продажи аккаунтов https://akkaunty-optom.live/
скачать все песни [url=https://www.25kat.ru]https://www.25kat.ru[/url] .
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Подробнее тут – [url=https://snyatie-lomki-ekb8.ru/]ломка от наркотиков в екатеринбурге[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод[/url]
На Кракене всегда чувствую себя в безопасности, благодарю.
https://telegra.ph/CHto-nuzhno-znat-o-sajt-kraken-zerkala3-05-12
жимолость с высоким урожаем малина морозостойкая
сливы морозостойкие саженцы роз для сада
В наркологической клинике «Нарколог лайф» вас ждёт профессиональный подход к лечению алкоголизма и наркомании. Мы обеспечиваем экстренный выезд специалистов, быстрое снятие интоксикации, а также комфортные условия для прохождения реабилитации. Наши методики направлены на долгосрочный результат.
Изучить вопрос глубже – [url=https://narcolog-life.com/]Частная клиника «Нарколог лайф»[/url]
купить аккаунт online-akkaunty-magazin.xyz
продажа аккаунтов https://akkaunty-dlya-prodazhi.pro
Группа препаратов
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki na domu nizhnij novgorod[/url]
Лучшее место для азартных игр | Зарегистрируйтесь сейчас на vavadacasino.netlify.app | Уникальные бонусы и акции | Испытайте удачу прямо сейчас | Классические и новые слоты | Гарантированный честный игровой процесс | Высокие шансы на выигрыш | Играйте в любое время и в любом месте | Поддержка и консультации 24/7 | Обучайтесь у профессионалов | Регистрация за минуту | Акции для новых игроков | Каждый день новые развлечения | Соревнуйтесь с другими игроками | Зарабатывайте вместе с нами | Инструкции по игре и правила | Ваши данные под защитой | Лучшие отзывы игроков | Настоящее казино у вас дома
vavada. онлайн. [url=https://vavadacasino.netlify.app/]vavada. онлайн.[/url] .
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Ознакомиться с деталями – [url=https://narcolog-life.com/article/kapli-snizhayushhie-tyagu-k-alkogolyu-chto-nuzhno-znat/]от алкоголя капли цена инструкция[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – http://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Изучить вопрос глубже – [url=https://narcolog-life.com/]частная наркологическая клиника нарколог лайф[/url]
Как отмечает главный врач клиники, кандидат медицинских наук Сергей Иванов, «мы создали систему, при которой пациент получает помощь в течение часа — независимо от дня недели и времени суток. Это принципиально меняет шансы на выздоровление».
Получить дополнительные сведения – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]анонимная наркологическая помощь[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]snyatie-lomki-ekb8.ru/[/url]
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Углубиться в тему – https://narkologicheskaya-pomoshch-balashiha1.ru/
KRAKEN — маркет, где тебе всегда рады.
https://telegra.ph/Kak-iskat-prodavcov-oruzhiya-na-kraken2-05-12
investigate this site [url=https://sites.google.com/mycryptowalletus.com/phantomwalletlogin/]phantom wallet[/url]
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Ознакомиться с деталями – https://narkologicheskaya-pomoshch-balashiha1.ru/narkologicheskaya-pomoshch-na-domu-v-balashihe/
my site [url=https://phantom-wallet.at/]phantom Download[/url]
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Выяснить больше – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]www.domen.ru[/url]
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Получить дополнительные сведения – http://
Назначение и действие
Выяснить больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызов врача нарколога на дом[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в новосибирске[/url]
Одной из самых сильных сторон нашей клиники является оперативность. Мы понимаем, что при алкоголизме, наркомании и лекарственной зависимости часто требуются немедленные действия. Если человек находится в состоянии запоя, абстиненции или передозировки, промедление может привести к тяжёлым осложнениям или даже смерти.
Выяснить больше – https://narkologicheskaya-pomoshch-balashiha1.ru/kruglosutochnaya-narkologicheskaya-pomoshch-v-balashihe
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена в нижний новгороде[/url]
home [url=https://rabby-wallet.net/]rabby wallet extension[/url]
Очень благодарен за честную сделку, кракен не подвёл.
https://telegra.ph/Bezopasnyj-vhod-v-kraken-zerkala4-05-12
ролетный шкаф в паркинг [url=https://www.shkafy-parkovka.ru]ролетный шкаф в паркинг[/url] .
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки в новосибирске[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Разобраться лучше – http://snyatie-lomki-ekb8.ru
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя недорого[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижний новгород[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя екатеринбург[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее можно узнать тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Подробнее можно узнать тут – [url=https://snyatie-lomki-ekb8.ru/]снятие наркотической ломки в екатеринбурге[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в стационаре новосибирск[/url]
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]срочный вывод из запоя екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок екатеринбург.[/url]
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Получить дополнительную информацию – [url=https://narcolog-life.com/kak-pravilno-pit-alkogol/]как правильно пить алкоголь[/url]
Create vivid images with Promptchan AI — a powerful neural network for generating art based on text description. Support for SFW and NSFW modes, style customization, quick creation of visual content.
linked here [url=https://sites.google.com/mycryptowalletus.com/phantomwalletlogin/]phantom Extension[/url]
охрана объекта в месяц [url=www.chop-ohrana.com/czeny-na-uslugi-ohrany/]www.chop-ohrana.com/czeny-na-uslugi-ohrany/[/url] .
Срочный выкуп квартир https://proday-kvarti.ru за сутки — решим ваш жилищный или финансовый вопрос быстро. Гарантия законности сделки, юридическое сопровождение, помощь на всех этапах. Оценка — бесплатно, оформление — за наш счёт. Обращайтесь — мы всегда на связи и готовы выкупить квартиру.
Недвижимость в Болгарии у моря https://byalahome.ru квартиры, дома, апартаменты в курортных городах. Продажа от застройщиков и собственников. Юридическое сопровождение, помощь в оформлении ВНЖ, консультации по инвестициям.
Функция
Подробнее можно узнать тут – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
Портал о недвижимости https://akadem-ekb.ru всё, что нужно знать о продаже, покупке и аренде жилья. Актуальные объявления, обзоры новостроек, советы экспертов, юридическая информация, ипотека, инвестиции. Помогаем выбрать квартиру или дом в любом городе.
Функция
Выяснить больше – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Получить дополнительные сведения – https://narkologicheskaya-pomoshch-balashiha1.ru/
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]skoraya narkologicheskaya pomoshch balashiha[/url]
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Выяснить больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-czena ekaterinburg[/url]
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому новосибирск.[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]www.domen.ru[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Детальнее – https://snyatie-lomki-ekb8.ru/
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Выяснить больше – [url=https://narcolog-life.com/psihiatriya/]психиатрия[/url]
шкаф для хранения шин в паркинге [url=https://shkafy-parkovka.ru]шкаф для хранения шин в паркинге[/url] .
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
маркетплейс аккаунтов соцсетей kupit-akkaunt.online
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя в екатеринбурге[/url]
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Исследовать вопрос подробнее – [url=https://narcolog-life.com/kapli-medzo-ot-alkogolizma/]капли медзо от алкоголизма инструкция[/url]
visit this page [url=https://sites.google.com/mycryptowalletus.com/phantom-walletlogin/]phantom Extension[/url]
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Подробнее можно узнать тут – https://narkologicheskaya-pomoshch-balashiha1.ru/skoraya-narkologicheskaya-pomoshch-v-balashihe
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]snyatie lomki narkozavisimogo ekaterinburg[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки в стационаре[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки нарколог[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Выяснить больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск.[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki narkozavisimogo nizhnij novgorod[/url]
hop over to here [url=https://sites.google.com/mycryptowalletus.com/phantom-walletlogin/]phantom Extension[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом нижний новгород[/url]
More about the author [url=https://phantom-wallet.net]phantom wallet[/url]
[url=https://7k-skachat-apk.ru]7k-skachat-apk.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино 7k в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.7k-skachat-apk.ru
купить криптовалюту за рубли [url=http://www.cryptohamsters.ru]http://www.cryptohamsters.ru[/url] .
В наркологической клинике «Нарколог лайф» вас ждёт профессиональный подход к лечению алкоголизма и наркомании. Мы обеспечиваем экстренный выезд специалистов, быстрое снятие интоксикации, а также комфортные условия для прохождения реабилитации. Наши методики направлены на долгосрочный результат.
Подробнее – https://narcolog-life.com/article/alkogolnaya-demencziya-prichiny-simptomy-i-profilaktika/
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Получить дополнительные сведения – [url=https://narcolog-life.com/article/alkogolnaya-demencziya-prichiny-simptomy-i-profilaktika/]алкогольная деменция[/url]
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Ознакомиться с деталями – [url=https://narcolog-life.com/kak-pravilno-pit-alkogol/]как правильно пить алкоголь повышать градус[/url]
уличный шкаф с рольставнями [url=shkafy-parkovka.ru]уличный шкаф с рольставнями[/url] .
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Подробнее можно узнать тут – https://narcolog-life.com/tabletki-ot-zapoya/
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Получить дополнительную информацию – [url=https://narcolog-life.com/molitva-protiv-alkogolizma/]молитва против алкоголизма сына[/url]
В клинике «Нарколог лайф» проводится профессиональное лечение зависимостей с гарантией конфиденциальности. Экстренная помощь, современные методики очистки организма, персонализированные программы восстановления и внимательное отношение к каждому пациенту — всё это помогает вернуть жизнь в нормальное русло.
Выяснить больше – [url=https://narcolog-life.com/spays-sinteticheskiye-kannabinoidy/]спайс синтетический наркотик[/url]
[url=https://7k-download-apk.ru/mobilnoe-prilozhenie-7k/]7k-download-apk.ru/mobilnoe-prilozhenie-7k/[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать приложение 7k казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
7k-download-apk.ru/mobilnoe-prilozhenie-7k/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркомана[/url]
В наркологической клинике «Нарколог лайф» вас ждёт профессиональный подход к лечению алкоголизма и наркомании. Мы обеспечиваем экстренный выезд специалистов, быстрое снятие интоксикации, а также комфортные условия для прохождения реабилитации. Наши методики направлены на долгосрочный результат.
Ознакомиться с деталями – [url=https://narcolog-life.com/kapli-medzo-ot-alkogolizma/]капли медзо от алкоголизма отзывы[/url]
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Изучить вопрос глубже – [url=https://narcolog-life.com/aktery-i-aktrisy-umershie-ot-alkogolizma/]актеры умершие от алкоголизма[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Детальнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом[/url]
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Получить дополнительные сведения – [url=https://narcolog-life.com/preparaty/]какие препараты[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-cena-v-ekb
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Разобраться лучше – http://snyatie-lomki-novosibirsk8.ru
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-na-domu-v-ekb/
Осложнения, к которым может привести отсутствие лечения:
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки в подольске[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее тут – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Углубиться в тему – [url=https://narcolog-life.com/]Клиника «Нарколог лайф»[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Выяснить больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркозависимого новосибирск[/url]
Когда запой становится угрозой для жизни и здоровья, своевременная помощь профессионала может стать решающим фактором для скорейшего восстановления. В Мурманске, где суровые климатические условия добавляют стресса и осложнений, квалифицированные наркологи оказывают помощь на дому, обеспечивая оперативную детоксикацию и индивидуальную терапию в привычной обстановке. Такой подход позволяет пациентам избежать лишних перемещений и получить поддержку в комфортной атмосфере.
Получить дополнительные сведения – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-na-domu-murmansk/
Где приобрести диплом по нужной специальности?
Заказать диплом университета по выгодной цене возможно, обратившись к проверенной специализированной компании.: [url=http://institute-diplom.ru/]institute-diplom.ru[/url]
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирская область[/url]
роза ветров спб цветы спб
розы с доставкой купить хризантемы
цветы доставка доставка цветов петербург
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Детальнее – [url=https://narcolog-life.com/]Клиника «Нарколог лайф»[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Разобраться лучше – http://vyvod-iz-zapoya-murmansk0.ru
Мы можем предложить дипломы любых профессий по приятным тарифам. Дипломы изготавливаются на оригинальных бланках государственного образца Приобрести диплом о высшем образовании [url=http://diplomaj-v-tule.ru/]diplomaj-v-tule.ru[/url]
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Исследовать вопрос подробнее – [url=https://narcolog-life.com/otritsatelnoye-vliyaniye-alkogolya-na-organy/]отрицательное влияние алкоголя на органы человека[/url]
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske
Наркологическая клиника «Нарколог лайф» — это место, где начинается путь к свободе от зависимости. Мы предлагаем безопасную детоксикацию, эффективное кодирование и полную реабилитацию с индивидуальным подходом. Наши специалисты работают круглосуточно, обеспечивая поддержку в любой момент.
Исследовать вопрос подробнее – [url=https://narcolog-life.com/article/effektivnye-tabletki-ot-pohmelya/]какие таблетки эффективные от похмелья[/url]
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Получить больше информации – [url=https://narcolog-life.com/lekarstva/]лекарство от наркомании[/url]
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Получить дополнительные сведения – [url=https://snyatie-lomki-podolsk1.ru/]снять ломку в подольске[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Подробнее тут – http://snyatie-lomki-podolsk1.ru
В клинике «Нарколог лайф» проводится профессиональное лечение зависимостей с гарантией конфиденциальности. Экстренная помощь, современные методики очистки организма, персонализированные программы восстановления и внимательное отношение к каждому пациенту — всё это помогает вернуть жизнь в нормальное русло.
Ознакомиться с деталями – [url=https://narcolog-life.com/]narcolog-life.com[/url]
Вывод из запоя обязателен, если:
Подробнее можно узнать тут – http://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah/https://vyvod-iz-zapoya-v-himki1.ru
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод[/url]
you can try this out [url=https://Keplr.at]keplr Download[/url]
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Получить больше информации – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом клиника[/url]
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Ознакомиться с деталями – [url=https://snyatie-lomki-podolsk1.ru/]snyatie lomki narkozavisimogo podol’sk[/url]
– Судорожный синдром, дыхательная недостаточность – Острые панические атаки и психозы – Инфаркт, инсульт, аритмия – Дегидратация и почечная недостаточность – Суицидальные мысли, агрессия, саморазрушение
Разобраться лучше – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-na-domu-v-podolske/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно в екатеринбурге[/url]
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Детальнее – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-na-domu-murmansk//
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Изучить вопрос глубже – http://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-na-domu-v-ekb/
best site [url=https://Keplr.at]keplr Extension[/url]
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Детальнее – [url=https://narcolog-life.com/]narcolog-life.com[/url]
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Детальнее – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя анонимно мурманск[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена в екатеринбурге[/url]
Услуга вывода из запоя на дому в Мурманске предполагает комплексное лечение алкогольной интоксикации, направленное на оперативное снижение уровня токсинов в организме. Сразу после поступления вызова специалист проводит детальный осмотр, собирает анамнез и определяет степень интоксикации. На основании собранной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение медикаментов, контроль жизненно важных показателей и психологическую поддержку. Такой комплекс мер позволяет стабилизировать состояние пациента и начать процесс выздоровления без необходимости посещения стационара.
Получить дополнительную информацию – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее тут – https://vyvod-iz-zapoya-murmansk00.ru
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Исследовать вопрос подробнее – [url=https://narcolog-life.com/article/effektivnye-tabletki-ot-pohmelya/]таблетка от похмелья быстро и эффективно[/url]
Группа препаратов
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врача капельницу от запоя[/url]
Appreciation you…
https://hop.cx/airdrop
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена[/url]
Группа препаратов
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирская область[/url]
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя химки[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки в стационаре подольск[/url]
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез для оценки степени алкогольной интоксикации. Эта информация является основой для разработки персонального плана лечения.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-murmansk00.ru/]наркологический вывод из запоя в мурманске[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ekb8.ru/]narkolog-vyvod-iz-zapoya ekaterinburg[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-czena ekaterinburg[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Выяснить больше – http://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-cena-v-himkah/
Когда запой начинает оказывать разрушительное воздействие на организм, своевременная помощь становится критически важной для предотвращения серьезных осложнений. В Мурманске квалифицированные наркологи на дому обеспечивают оперативную детоксикацию, восстановление обменных процессов и стабилизацию работы внутренних органов. Лечение проводится в комфортной домашней обстановке, что позволяет избежать лишнего стресса и сохранить полную конфиденциальность.
Подробнее тут – https://vyvod-iz-zapoya-murmansk00.ru/vyvod-iz-zapoya-kruglosutochno-murmansk
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Получить больше информации – [url=https://narcolog-life.com/article/lechenie-internet-zavisimosti-ehffektivnye-metody-i-podhody/]препараты при лечении интернет зависимости[/url]
«Нарколог лайф» — надёжная клиника, где каждый получает шанс на здоровую и свободную от зависимости жизнь. Наши программы включают срочную помощь, эффективную детоксикацию, кодирование и полную поддержку на пути к выздоровлению. Анонимность и индивидуальный подход гарантированы каждому пациенту.
Углубиться в тему – [url=https://narcolog-life.com/]narcolog-life.com[/url]
«Нарколог лайф» — клиника, где борьба с зависимостью становится реальной и результативной. Мы применяем современные технологии детоксикации, проводим кодирование с учётом индивидуальных особенностей и сопровождаем пациентов на всех этапах восстановления. Безопасность, забота и поддержка — наши приоритеты.
Подробнее тут – https://narcolog-life.com/alkogolizm/
На данном этапе врач уточняет длительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Выяснить больше – [url=https://vyvod-iz-zapoya-murmansk00.ru/]вывод из запоя анонимно мурманск[/url]
get redirected here [url=https://phantom-wallet.at/]phantom Download[/url]
see this [url=https://phantom-wallet.at/]phantom Extension[/url]
Фото и видео новости на Кубани [url=https://holidayprint.ru/]копицентр недорого[/url] и [url=https://holidayprint.ru/]копировальный центр 1[/url]
Медицинский центр «АлкоНарко» предоставляет комплексные услуги в области наркологии: вывод из запоя, восстановление после ломки, реабилитация. Работаем 24/7, приезжаем в течение часа. Надежно, профессионально, с заботой о здоровье пациента.
Ознакомиться с деталями – [url=https://alko-narko.info/narkomaniya/]технологическая зависимость[/url]
PJ Katty – це справжня зірка транс-сцени. Її виступи поєднують у собі музику, танець і візуальні ефекти, створюючи унікальне шоу. Хочеш дізнатися більше? Переглянь деталі на цьому сайті.
Наркологическая клиника «АлкоНарко» предлагает срочную и квалифицированную помощь при зависимости. Проводим выезд на дом, медицинскую детоксикацию, кодирование и последующую реабилитацию. Гарантируем полную конфиденциальность, бережное отношение и современные лечебные методики.
Детальнее – [url=https://alko-narko.info/alkogolizm/profilaktika-alkogolizma.html]таблетки от похмелья[/url]
акции алиэкспресс
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomok nizhnij novgorod[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Разобраться лучше – https://vyvod-iz-zapoya-v-himki1.ru/narkolog-vyvod-iz-zapoya-v-himkah
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Детальнее – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode/
Функция
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нарколог[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург.[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Детальнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]нарколог вывод из запоя химки[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом цена в калининграде[/url]
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя круглосуточно[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя клиника екатеринбург[/url]
Группа препаратов
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана[/url]
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]vyvod-iz-zapoya-kruglosutochno ulan-ude[/url]
В Pinterest случайно наткнулся на рекламу [url=https://alcoclub25.ru/ ]доставки алкоголя город москва[/url]. Решил попробовать – и теперь это мой любимый сервис для заказа алкоголя.
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся методом инфузии, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Узнать больше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]наркология вывод из запоя улан-удэ[/url]
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Подробнее – https://narcolog-na-dom-kaliningrad00.ru/narkolog-na-dom-kruglosutochno-kaliningrad/
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому улан-удэ[/url]
Ищете копирайтера? https://sajt-kopirajtera.ru Пишу тексты, которые продают, вовлекают и объясняют. Создам контент для сайта, блога, рекламы, каталога. Работаю с ТЗ, разбираюсь в SEO, адаптирую стиль под задачу. Чистота, смысл и результат — мои приоритеты. Закажите текст, который работает на вас.
Архитектурные решения https://топдом-мск.рф под ваши желания и участок. Создадим проект с нуля: планировка, фасад, инженерия, визуализация. Вы получите эксклюзивный дом, адаптированный под ваш образ жизни. Работаем точно, качественно и с любовью к деталям.
Наркологическая помощь от клиники «АлкоНарко» — это анонимное лечение зависимости по современным стандартам. Детоксикация, психологическая поддержка, медикаментозное кодирование и сопровождение. Выездные и стационарные услуги. У нас — максимум безопасности и минимум стресса.
Выяснить больше – https://alko-narko.info/sovmestimost-s-lekarstvami/pochemu-nelzya-smeshivat-alkogol-s-lekarstvami-osnovnye-riski.html
Мы готовы предложить дипломы любой профессии по выгодным ценам. Стоимость может зависеть от выбранной специальности, года выпуска и университета: [url=http://diigo.com/item/note/8p2f0/6ibo?k=0f0a83195cf39d6c28c9fe24b931c6c5/]diigo.com/item/note/8p2f0/6ibo?k=0f0a83195cf39d6c28c9fe24b931c6c5[/url]
«АлкоНарко» — центр лечения зависимости, где каждая программа подбирается индивидуально. Проводим экстренную помощь при запоях, медикаментозную поддержку, кодирование и постлечебную адаптацию. Оказываем помощь на дому и в стационаре, строго соблюдая врачебную тайну.
Подробнее – [url=https://alko-narko.info/zapoy/]вывод из запоя[/url]
уннв треки скачать [url=www.25kat.ru/music/уннв/]уннв треки скачать[/url] .
окна пвх рехау [url=https://02stroika.ru]https://02stroika.ru[/url] .
Если вам срочно нужна качественная [url=https://alfa-tehnologia.ru/uslugi/webasto]установка вебасто в иркутске[/url] звоните в “Альфа-Технологию” – alfa-tehnologia.ru. Мы на протяжении десятилетия занимаемся с автомобильной электроникой, охранными системами и мультимедиа в машине. Монтируем сигнализации StarLine, Pandora и другие системы защиты с гарантией от дилера. Работаем только с сертифицированным оборудованием и гарантируем до трёх лет на установку.
Желайте [url=https://alfa-tehnologia.ru/uslugi/otopiteli]предпусковой подогреватель двигателя[/url] перед морозами или подключить сигнализацию в Иркутске? У нас предлагаются Webasto, котлы 220В и другие эффективные решения. Работу выполняют квалифицированные специалисты с учётом всех технических требований. Запись доступна онлайн или по звонку. Всё оперативно, качественно и честно. Нам предпочитают водители города — и мы ценим доверие.
продажа пластиковых окон в москве [url=https://1okno-krasnodar.ru/]https://1okno-krasnodar.ru/[/url] .
дренажные системы для частного дома цена [url=vc.ru/services/1913096-kak-sdelat-drenazh-na-uchastke-v-sankt-peterburge]vc.ru/services/1913096-kak-sdelat-drenazh-na-uchastke-v-sankt-peterburge[/url] .
Обращение за помощью нарколога на дому в Улан-Удэ обладает рядом преимуществ, которые делают лечение эффективным и безопасным:
Детальнее – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]наркология вывод из запоя[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Получить дополнительные сведения – http://narkologicheskaya-klinika-mytishchi1.ru/chastnaya-narkologicheskaya-klinika-v-mytishchah/
Туристический портал https://prostokarta.com.ua для путешественников: маршруты, достопримечательности, советы, бронирование туров и жилья, билеты, гайды по странам и городам. Планируйте отпуск легко — всё о путешествиях в одном месте.
Фитнес-портал https://sportinvent.com.ua ваш помощник в достижении спортивных целей. Тренировки дома и в зале, план питания, расчёт калорий, советы тренеров и диетологов. Подходит для начинающих и профессионалов. Всё о фитнесе — в одном месте и с реальной пользой для здоровья.
Наркологическая помощь от клиники «АлкоНарко» — это анонимное лечение зависимости по современным стандартам. Детоксикация, психологическая поддержка, медикаментозное кодирование и сопровождение. Выездные и стационарные услуги. У нас — максимум безопасности и минимум стресса.
Подробнее тут – https://alko-narko.info/vliyanie-na-zdorove/
Инновации, технологии, наука https://technocom.dp.ua на одном портале. Читайте о передовых решениях, новых продуктах, цифровой трансформации, робототехнике, стартапах и будущем IT. Всё самое важное и интересное из мира высоких технологий в одном месте — просто, понятно, актуально.
Услуга вывода из запоя на дому в Улан-Удэ включает полный комплекс мер, направленных на быстрое восстановление организма. При получении вызова нарколог приезжает на дом, проводит тщательный первичный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез. На основе полученных данных формируется индивидуальный план терапии, который может включать инфузионное введение медикаментов с применением современных технологий и оказание психологической поддержки для достижения устойчивой ремиссии.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому цена[/url]
Всё о мобильной технике https://webstore.com.ua и технологиях: смартфоны, планшеты, гаджеты, новинки рынка, обзоры, сравнения, тесты, советы по выбору и настройке. Следите за тенденциями, обновлениями ОС и инновациями в мире мобильных устройств.
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Разобраться лучше – https://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-narkolog-v-mytishchah/
ремикс уннв скачать [url=https://www.25kat.ru/music/уннв]ремикс уннв скачать[/url] .
buy facebook account https://buy-adsaccounts.work
Медицинский центр «АлкоНарко» предоставляет комплексные услуги в области наркологии: вывод из запоя, восстановление после ломки, реабилитация. Работаем 24/7, приезжаем в течение часа. Надежно, профессионально, с заботой о здоровье пациента.
Выяснить больше – [url=https://alko-narko.info/vliyanie-na-zdorove/kak-narkotiki-vliyayut-na-mozg-i-centralnuyu-nervnuyu-sistemu-mekhanizmy-i-posledstviya.html]как влияют наркотики[/url]
Медицинский центр «АлкоНарко» предоставляет комплексные услуги в области наркологии: вывод из запоя, восстановление после ломки, реабилитация. Работаем 24/7, приезжаем в течение часа. Надежно, профессионально, с заботой о здоровье пациента.
Подробнее тут – https://alko-narko.info/
buy facebook advertising accounts buying facebook account
buy facebook profiles https://buy-ad-account.top/
YouTube Promotion buy youtube views cheap for your videos and increase reach. Real views from a live audience, quick launch, flexible packages. Ideal for new channels and content promotion. We help develop YouTube safely and effectively.
Натяжные потолки под ключ https://potolki-nova.livejournal.com/563.html установка любых видов: матовые, глянцевые, сатиновые, многоуровневые, с фотопечатью и подсветкой. Широкий выбор фактур и цветов, замер бесплатно, монтаж за 1 день. Качественные материалы, гарантия и выгодные цены от производителя.
Автомобильный портал https://autodream.com.ua для автолюбителей и профессионалов: новости автоиндустрии, обзоры, тест-драйвы, сравнение моделей, советы по уходу и эксплуатации. Каталог авто, форум, рейтинги, автоновости. Всё об автомобилях — в одном месте, доступно и интересно.
Портал про авто https://livecage.com.ua всё для автолюбителей: обзоры машин, тест-драйвы, новости автопрома, советы по ремонту и обслуживанию. Выбор авто, сравнение моделей, тюнинг, страховка, ПДД. Актуально, понятно и полезно. Будьте в курсе всего, что связано с автомобилями!
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Выяснить больше – https://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
проверить сайт [url=https://alt-coins.cc]Альткоин обменник[/url]
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Подробнее тут – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Углубиться в тему – http://snyatie-lomki-nnovgorod8.ru/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому екатеринбург.[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Подробнее тут – http://narkologicheskaya-klinika-mytishchi1.ru
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – https://vyvod-iz-zapoya-ekb8.ru/
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить больше информации – https://snyatie-lomki-nnovgorod8.ru/
facebook ad accounts for sale facebook accounts to buy
Современный женский портал https://beautyrecipes.kyiv.ua стиль жизни, мода, уход за собой, семья, дети, кулинария, карьера и вдохновение. Полезные советы, тесты, статьи и истории. Откровенно, интересно, по-настоящему. Всё, что важно и близко каждой женщине — в одном месте.
На женском портале https://happytime.in.ua статьи для души и тела: секреты красоты, женское здоровье, любовь и семья, рецепты, карьерные идеи, вдохновение. Место, где можно быть собой, делиться опытом и черпать силу в заботе о себе.
Ты можешь всё https://love.zt.ua а мы подскажем, как. Женский портал о саморазвитии, личной эффективности, карьере, балансе между семьёй и амбициями. Здесь — опыт успешных женщин, практичные советы и реальные инструменты для роста.
Добро пожаловать на женский портал https://lidia.kr.ua ваш гид по миру красоты, стиля и внутренней гармонии. Читайте про отношения, карьеру, воспитание детей, женское здоровье, эмоции и моду. Будьте вдохновлены лучшей версией себя каждый день вместе с нами.
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя в стационаре[/url]
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя на дому[/url]
Лечение вывода из запоя на дому в Улан-Удэ организовано по чётко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс восстановления.
Подробнее тут – [url=https://vyvod-iz-zapoya-ulan-ude0.ru/]вывод из запоя цена улан-удэ.[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki nizhnij novgorod[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя капельница екатеринбург[/url]
Наркологическая клиника «АлкоНарко» предлагает срочную и квалифицированную помощь при зависимости. Проводим выезд на дом, медицинскую детоксикацию, кодирование и последующую реабилитацию. Гарантируем полную конфиденциальность, бережное отношение и современные лечебные методики.
Получить дополнительные сведения – [url=https://alko-narko.info/alkogolizm/postabstinentnyj-sindrom-pas-simptomy-posledstviya-i-lechenie.html]восстановление после алкоголя[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-himki1.ru/]нарколог вывод из запоя[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Получить больше информации – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника в мытищах[/url]
Функция
Углубиться в тему – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки нижний новгород[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]vyvod-iz-zapoya-klinika himki[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок на дому[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить больше информации – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-cena-v-ekb/
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя анонимно[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому круглосуточно в химках[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Детальнее – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Незамедлительно после поступления вызова нарколог приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели — пульс, артериальное давление, температуру — и собирает анамнез для определения степени алкогольной интоксикации.
Получить дополнительную информацию – http://vyvod-iz-zapoya-ulan-ude0.ru/
окна в москве [url=https://www.02stroika.ru]https://www.02stroika.ru[/url] .
Женский онлайн-журнал https://loveliness.kyiv.ua о стиле, красоте, вдохновении и трендах. Интервью, мода, бьюти-обзоры, психология, любовь и карьера. Будь в курсе главного, читай мнения экспертов, следи за трендами и открывай новые грани себя каждый день.
Онлайн-журнал для женщин https://mirwoman.kyiv.ua которые ищут не только советы, но и тепло. Личные истории, женское здоровье, психология, уютный дом, забота о себе, рецепты, отношения. Без давления, без шаблонов. Просто жизнь такой, какая она есть.
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Получить больше информации – [url=https://peredozirovka.info/articles/vliyanie-spirtnogo-na-pochki/]что будет если не пить алкоголь[/url]
Портал для женщин https://oa.rv.ua всё, что важно: красота, здоровье, семья, карьера, мода, отношения, рецепты и саморазвитие. Полезные статьи, советы, тесты и вдохновение каждый день. Онлайн-пространство, где каждая найдёт ответы и поддержку.
Современный женский портал https://womanonline.kyiv.ua с актуальными темами: тренды, уход, макияж, фитнес, fashion, интервью, советы стилистов. Следи за модой, вдохновляйся образами, узнай, как подчеркнуть свою индивидуальность.
уннв песня скачать [url=https://25kat.ru/music/уннв/]https://25kat.ru/music/уннв/[/url] .
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Получить дополнительную информацию – https://peredozirovka.info/service/lechenie-alkogolizma/
купить пластиковые окна от производителя [url=https://1okno-krasnodar.ru]купить пластиковые окна от производителя[/url] .
I started delightful CBD gummies a few months ago and morally, they’ve мейд a immense difference. I almost always secure everyone after dinner to mitigate me chill unserviceable and have a zizz better. They mouthful countless —like present confectionery — and don’t beat it me identification groggy the next day. It’s just a nice, sweet vibe that helps receive the uptight insane after a stressful day. Wasn’t inescapable they’d work at earliest, but in the present climate I’m all in. Utterly second if you have need of something genuine to facilitate you abate without any eerie side effects.
купить сухие дрова [url=http://www.vc.ru/rejting/1604662-zakazat-drova-v-sergievom-posade]http://www.vc.ru/rejting/1604662-zakazat-drova-v-sergievom-posade[/url] .
музыка скачать уннв [url=http://www.25kat.ru/music/уннв]музыка скачать уннв[/url] .
Dear Instructors, could you recommend an unconventional yet effective online course that not only helps CBSE students excel academically but also fosters creativity and critical thinking skills?
Slight detour — music worth checking out
Just while browsing new sounds I discovered a site https://breaks.djgafur.site.
It’s a 24/7 radio streaming Breakbit featuring DJ Gafur and guests from around the world.
Freedom-packed energetic streams.
Also found [url=https://breaks.djgafur.site]DJ Gafur Breaks & Breakbit Radio[/url] — definitely check it out!
What’s your vibe on chaotic electronic styles?
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Углубиться в тему – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена в новосибирске[/url]
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Исследовать вопрос подробнее – https://narkologicheskaya-pomoshch-balashiha1.ru
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Получить дополнительную информацию – http://vyvod-iz-zapoya-v-himki1.ru
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена химки.[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск[/url]
Группа препаратов
Получить дополнительные сведения – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя[/url]
Функция
Подробнее – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
обучение криптовалюте [url=https://cryptohamsters.ru/]обучение криптовалюте[/url] .
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Подробнее тут – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]наркологическая помощь в балашихе[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок на дому в нижний новгороде[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому недорого[/url]
скачать музыку уннв [url=25kat.ru/music/уннв]скачать музыку уннв[/url] .
Сайт для женщин https://womenclub.kr.ua всё, что волнует и вдохновляет: мода, красота, здоровье, отношения, дети, психология и карьера. Практичные советы, интересные статьи, вдохновение каждый день. Онлайн-пространство, созданное с заботой о вас и вашем настроении.
Медицинский портал https://lpl.org.ua с проверенной информацией от врачей: симптомы, заболевания, лечение, диагностика, препараты, ЗОЖ. Консультации специалистов, статьи, тесты и новости медицины. Только достоверные данные — без паники и домыслов. Здоровье начинается с знаний.
Надёжный медицинский портал https://una-unso.cv.ua созданный для вашего здоровья и спокойствия. Статьи о заболеваниях, советы по лечению и образу жизни, подбор клиник и врачей. Понятный язык, актуальная информация, забота о вашем самочувствии — каждый день.
Чайная энциклопедия https://etea.com.ua всё о мире чая: сорта, происхождение, свойства, способы заваривания, чайные традиции разных стран. Узнайте, как выбрать качественный чай, в чём его польза и как раскрывается вкус в каждой чашке. Для ценителей и новичков.
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Углубиться в тему – http://snyatie-lomki-ekb8.ru
«Передозировка» — современная наркологическая клиника в Санкт-Петербурге. Мы специализируемся на экстренной помощи: детоксикация, капельницы, снятие судорог и острых симптомов. Работаем 24/7, приезжаем быстро, применяем безопасные схемы терапии.
Получить больше информации – [url=https://peredozirovka.info/articles/yavlyaetsya-li-ksanax-narkotikom-i-vyzyvaet-li-zavisimost/]нужен ксанакс[/url]
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальный обмен веществ и стабилизировать работу внутренних органов. Этот этап играет решающую роль в безопасном выводе из запоя.
Подробнее – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-kruglosutochno-doneczk-dnr
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-himki1.ru/]нарколог вывод из запоя в химках[/url]
Наркологическая клиника «Передозировка» — ваш надежный партнер в ситуации экстренной интоксикации. Вывод из состояния передозировки, восстановление жизненно важных функций, круглосуточная помощь в Санкт-Петербурге и области. Конфиденциально, профессионально, с заботой о здоровье.
Ознакомиться с деталями – [url=https://peredozirovka.info/articles/alkogol-v-povsednevnoy-zhizni/]пьянство[/url]
facebook ads accounts buy aged facebook ads account
buy aged facebook ads account buy facebook accounts
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Подробнее – http://vyvod-iz-zapoya-v-himki1.ru
Клиника «Передозировка» — квалифицированная наркологическая помощь в Санкт-Петербурге и Ленинградской области. Срочная детоксикация, стабилизация состояния, лечение последствий передозировки. Выезд врача круглосуточно, полная анонимность и индивидуальный подход к каждому случаю.
Подробнее – [url=https://peredozirovka.info/service/reabilitatsiya-alkogolikov/]реабилитация алкоголизма[/url]
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Разобраться лучше – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-na-domu-doneczk-dnr
cheap facebook accounts https://ad-account-for-sale.top
Кулинарный портал https://mallinaproject.com.ua тысячи рецептов, пошаговые инструкции, фото, видео, удобный поиск по ингредиентам. Готовьте вкусно и разнообразно: от завтраков до десертов, от традиционной кухни до кулинарных трендов. Быстро, доступно, понятно!
Современный мужской портал https://smart4business.net о жизни, успехе и саморазвитии. Личный рост, инвестиции, бизнес, стиль, технологии, мотивация. Разбираем стратегии, делимся опытом, вдохновляем на движение вперёд. Для тех, кто выбирает силу, разум и результат.
Все новинки технологий https://axioma-techno.com.ua в одном месте: презентации, релизы, выставки, обзоры и утечки. Следим за рынком гаджетов, IT, авто, AR/VR, умного дома. Обновляем ежедневно. Не пропустите главные технологические события и открытия.
Новинки технологий https://dumka.pl.ua портал о том, как научные открытия становятся частью повседневности. Искусственный интеллект, нанотехнологии, биоинженерия, 3D-печать, цифровизация. Простым языком о сложном — для тех, кто любит знать, как работает мир.
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Подробнее тут – http://snyatie-lomki-nnovgorod8.ru/
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Углубиться в тему – https://snyatie-lomki-nnovgorod8.ru
Наркологическая клиника «Передозировка» — ваш надежный партнер в ситуации экстренной интоксикации. Вывод из состояния передозировки, восстановление жизненно важных функций, круглосуточная помощь в Санкт-Петербурге и области. Конфиденциально, профессионально, с заботой о здоровье.
Получить больше информации – [url=https://peredozirovka.info/articles/protivopokazaniya-k-kodirovaniyu-ot-alkogolnoy-zavisimosti/]можно ли кодироваться[/url]
купить дрова в гатчине [url=http://vc.ru/rejting/1714843-reiting-luchshih-firm-po-prodazhe-berezovyh-dubovyh-i-lipovyh-kolotyh-drov-v-spb-top-kompanii-na-2024-2025-god]купить дрова в гатчине[/url] .
Вывод из запоя обязателен, если:
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя в химках[/url]
Real wonderful info can be found on blog.
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Разобраться лучше – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Детальнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки на дому в екатеринбурге[/url]
Актуальные новости https://polonina.com.ua каждый день — политика, экономика, культура, спорт, технологии, происшествия. Надёжный источник информации без лишнего. Следите за событиями в России и мире, получайте факты, мнения и обзоры.
Автомобильный сайт https://kolesnitsa.com.ua для души: редкие модели, автофан, необычные тесты, автоистории, подборки и юмор. Лёгкий и увлекательный контент, который приятно читать. Здесь не только про машины — здесь про стиль жизни на колёсах.
Следите за трендами автопрома https://viewport.com.ua вместе с нами! На авто портале — новинки, презентации, обзоры, технологии, электромобили, автосалоны и экспертные мнения. Ежедневные обновления, честный взгляд на рынок, без лишнего шума и рекламы.
Полезные статьи и советы https://britishschool.kiev.ua на каждый день: здоровье, финансы, дом, отношения, саморазвитие, технологии и лайфхаки. Читайте, применяйте, делитесь — всё, что помогает жить проще, осознаннее и эффективнее. Достоверная информация и реальная польза.
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]www.domen.ru[/url]
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Подробнее можно узнать тут – [url=https://peredozirovka.info/articles/alkogol-i-psihika/]алкогольный делирий[/url]
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Подробнее – [url=https://peredozirovka.info/articles/vliyanie-spirtnogo-na-pochki/]влияние алкоголя на[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя химки.[/url]
При обращении за экстренной помощью наш нарколог незамедлительно выезжает на дом или принимает пациента в клинике. Процесс лечения организован по проверенной схеме, позволяющей максимально быстро стабилизировать состояние и облегчить симптомы ломки. Основные этапы включают:
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков в нижний новгороде[/url]
Преимущества вывода из запоя от опытных специалистов в условиях Донецка ДНР многочисленны. Такой формат лечения позволяет:
Детальнее – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя капельница в донецке[/url]
fb account for sale https://buy-ad-account.click
Функция
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki na domu nizhnij novgorod[/url]
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Подробнее – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому цена[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя недорого химки[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-himki1.ru/]наркологический вывод из запоя химки[/url]
Группа препаратов
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому цена[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирск.[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya-na-domu novosibirsk[/url]
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Разобраться лучше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок на дому екатеринбург[/url]
Как зайти на сайт bs2best https://b2sbest.at
Вход bs-https://b2sbest.at
bs2best
bs2best at
bs2site
blacksprut
bs2site at
https bs2best at
https bs2site at
блекспрут
blacksprut ссылка
blacksprut com
blacksprut зеркала
blacksprut зеркало
blacksprut сайт
bs blacksprut
тор blacksprut
blacksprut официальный
bs2best at ссылка
tor blacksprut
blacksprut ссылка tor
blacksprut darknet
blacksprut сайт зеркало
blacksprut bs2tor nl
bs2site at ссылка
blacksprut blacksprut click
blacksprut официальный сайт
блекспрут bs2tor nl
рабочая blacksprut
blacksprut ссылка тор
bs2web
blacksprut com зеркало сайта
blacksprut вход
https bs2site at login
blacksprut onion
blacksprut com ссылка
как зайти на blacksprut
тор браузер blacksprut
blacksprut сегодня
ссылка на блекспрут
блекспрут сайт
blacksprut официальная ссылка
blacksprut актуальные
blacksprut ссылка bs2tor nl
блекспрут зеркало
блекспрут blacksprut
http blacksprut ссылки
blacksprut зеркало официальный
bs2web at
bs2site at не работает
blacksprut не работает
blacksprut ссылка зеркало
2fa blacksprut где взять
blacksprut зеркала tor
блэкспрут blacksprut
блекспрут com
blacksprut площадки
блекспрут blacksprut click
bs2site at зеркала
блекспрут bs2
blacksprut com официальный
blacksprut официальный сайт ссылка
blacksprut onion ссылка
блэкспрут blacksprut click
актуальная ссылка на blacksprut
bs2best at зеркала
как найти blacksprut
блекспрут 2fa
bs2best at бс сайт
bs2best at не работает
blacksprut ссылка на сайт
блэк спрут blacksprut click
blacksprut зеркала bs2tor nl
тор блекспрут
зеркало blacksprut darknet
bs2web run
blacksprut зеркало официальный сайт
как зайти на сайт blacksprut
blacksprut com вход
блекспрут вход
bs2web top
рабочее зеркало blacksprut
https bs2site at сайт
как зайти на блекспрут
как зайти через blacksprut
bs2best at регистрация
blacksprut поддержка
blacksprut onion зеркало
blacksprut com официальный сайт
blacksprut зеркала актуальные
bs2web nl
рабочая ссылка на blacksprut
blacksprut рулетка
bs2besd at
рабочая ссылка блекспрут
https bs2best at сайт
блекспрут официальный сайт
ссылка блекспрут тор
bs2web com
blacksprut онион
блекспрут бс сайт bs site biz
блекспрут bs2web
блекспрут com ссылка
blacksprut официальный bs site biz
blacksprut площадка зеркало
блекспрут онион
блекспрут актуальные ссылки
blacksprut войти
blacksprut зеркало работающее
blacksprut сайт bs2 best at
http blacksprut onion
блекспрут надежные ссылки
ссылка на блекспрут bs site biz
сайт блекспрут ссылки
blacksprut net официальный сайт
https bs2best at не работает
bs2web зеркало
блекспруте blacksprut me
как открыть ссылку bs2web at
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломок[/url]
Назначение
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]врач на дом капельница от запоя[/url]
Функция
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков[/url]
Вывод из запоя обязателен, если:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]vyvod-iz-zapoya-czena himki[/url]
Назначение
Выяснить больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя новосибирск[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена химки.[/url]
Мы не делаем «массовых решений»: каждый пациент для нас — уникальная история, и мы строим терапию, исходя из его состояния, целей и личных возможностей. Наша задача — не просто временно облегчить симптомы, а дать человеку реальные инструменты для жизни без зависимости.
Узнать больше – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-narkolog-v-mytishchah/
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Получить дополнительную информацию – [url=https://peredozirovka.info/articles/otkaz-ot-kureniya/]отказ от курения что происходит с организмом[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-himki1.ru/]наркология вывод из запоя[/url]
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Углубиться в тему – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]наркологическая помощь на дому[/url]
Функция
Подробнее тут – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
Функция
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomki nizhnij novgorod[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Выяснить больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре екатеринбург[/url]
Также мы учитываем потребности каждого пациента — по питанию, условиям проживания, графику процедур. Проживание возможно в стандартных и повышенных палатах, с возможностью индивидуального обслуживания.
Исследовать вопрос подробнее – http://narkologicheskaya-pomoshch-balashiha1.ru/narkologicheskaya-pomoshch-na-domu-v-balashihe/
онлайн займы под процентов на карту [url=vc.ru/rejting/1964646-kredity-na-kartu-na-god-s-plokhoy-istoriey]vc.ru/rejting/1964646-kredity-na-kartu-na-god-s-plokhoy-istoriey[/url] .
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника мытищи[/url]
Сайт для женщин https://funtura.com.ua всё, что интересно каждый день: бьюти-советы, рецепты, отношения, дети, стиль, покупки, лайфхаки и настроение. Яркие статьи, тесты и вдохновение. Просто, легко, по-женски.
Это не просто сайт для женщин https://godwood.com.ua это пространство, где вас слышат. Здесь — забота, поддержка, советы по жизни, отношениям, здоровью, семье и внутреннему балансу. Никакой критики, только доброта и уверенность: всё будет хорошо, и вы не одна.
Информационно-познавательный https://golosiyiv.kiev.ua портал для мужчин и женщин: полезные статьи, советы, обзоры, лайфхаки, здоровье, психология, стиль, семья и финансы. Всё, что важно знать для жизни, развития и комфорта. Читайте, развивайтесь, вдохновляйтесь вместе с нами.
квадратный натяжной потолок натяжной потолок сколько
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Детальнее – https://narkologicheskaya-pomoshch-balashiha1.ru/
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снять ломку[/url]
В условиях Донецка ДНР профессиональный вывод из запоя на дому организован по отлаженной схеме, которая включает несколько последовательных этапов. Такой комплексный подход позволяет не только быстро вывести токсичные вещества из организма, но и обеспечить стабильное восстановление всех систем организма.
Углубиться в тему – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому донецкая область[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – https://vyvod-iz-zapoya-v-himki1.ru/narkolog-vyvod-iz-zapoya-v-himkah/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки новосибирск[/url]
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Узнать больше – https://kapelnica-ot-zapoya-lugansk-lnr00.ru/vyzvat-kapelniczu-ot-zapoya-lugansk-lnr
Tiny off-topic but so worth sharing 🙂
Just while searching for better beats I discovered a site https://dnb.djgafur.site.
It’s streaming nonstop broken beats — DJ Gafur’s mixes plus top global guests.
Massive groove and flow.
Also found [url=https://dnb.djgafur.site]DJ Gafur Liquid Funk Radio[/url] — 100% recommend checking it!
Any fans of emotional high-speed music?
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Изучить вопрос глубже – https://vyvod-iz-zapoya-v-himki1.ru
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]www.domen.ru[/url]
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Разобраться лучше – https://peredozirovka.info/articles/psihicheskie-rasstroystva-pri-alkogolizme/
Сильная, умная, стильная https://lugor.org.ua вот для кого наш женский онлайн-журнал. Темы: мода, карьера, дети, отношения, дом, здоровье. Разговор о реальной жизни: без глянца, но со вкусом.
Женский онлайн-журнал https://gorod-lubvi.com.ua о красоте, стиле и уходе. Советы визажистов, подбор образов, секреты молодости, модные тренды. Всё, чтобы чувствовать себя уверенно и выглядеть на миллион. Будь в курсе, вдохновляйся и подбирай стиль по душе.
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Выяснить больше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]vyvod-iz-zapoya-czena donetsk[/url]
Женский онлайн-журнал https://inclub.lg.ua о силе выбора. Карьера, финансы, тайм-менеджмент, уверенность, стиль и баланс. Для женщин, которые двигаются вперёд, строят, влияют, мечтают. Говорим по делу — без стереотипов и с уважением к вашему пути.
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить больше информации – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно в екатеринбурге[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Получить больше информации – http://snyatie-lomki-novosibirsk8.ru
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Получить дополнительные сведения – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки[/url]
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]бесплатная наркологическая клиника[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить дополнительные сведения – http://snyatie-lomki-ekb8.ru
Стационарная программа позволяет стабилизировать не только физическое состояние, но и эмоциональную сферу. Находясь в изоляции от внешних раздражителей и вредных контактов, пациент получает шанс сконцентрироваться на себе и начать реабилитацию без давления извне.
Ознакомиться с деталями – https://narkologicheskaya-pomoshch-balashiha1.ru/
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя клиника в луганске[/url]
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Получить больше информации – [url=https://peredozirovka.info/articles/yavlyaetsya-li-ksanax-narkotikom-i-vyzyvaet-li-zavisimost/]нужен ксанакс[/url]
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя цена луганск[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому цена химки[/url]
накрутка подписчиков в тг бесплатно без заданий [url=www.vc.ru/niksolovov/1446241-top-20-luchshih-servisov-po-nakrutke-podpischikov-v-telegram-v-2024-godu]накрутка подписчиков в тг бесплатно без заданий[/url] .
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительную информацию – http://vyvod-iz-zapoya-ekb8.ru
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому химки[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя клиника[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Детальнее – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Углубиться в тему – http://snyatie-lomki-novosibirsk8.ru/snyatie-narkoticheskoj-lomki-v-novosibirske/
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск.[/url]
хранилище для вещей в москве [url=http://veshi-hranenie.ru]http://veshi-hranenie.ru[/url] .
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]kapelnicza-ot-zapoya-na-domu lugansk[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя в химках[/url]
Портал для активных https://onlystyle.com.ua стильных, современных женщин. Мода, карьера, здоровье, бьюти-тренды, фитнес, лайфхаки, вдохновение. Будь в курсе, живи ярко, выбирай смело. Никаких скучных статей — только драйв, стиль и реальная польза.
Портал для женщин https://prettiness.kyiv.ua которые любят жизнь во всех её красках. Советы, мода, рецепты, отношения, вдохновение, дом и путешествия. Каждый день — новая идея, интересная мысль и повод улыбнуться.
Модный журнал https://psilocybe-larvae.com всё о стиле, трендах, бьюти-новинках, звёздах и вдохновении. Образы с подиумов, советы стилистов, актуальные коллекции, мода улиц и мировые бренды.
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]капельница от запоя на дому луганск.[/url]
smtp
Все больше новых МФО в 2025 году предлагают займы без проверки кредитной истории. В Telegram-канале [url=https://t.me/s/mfo_2024_online]Новые МФО 2025[/url] собраны предложения от организаций, которые принимают заявки от граждан с 18 лет, на сумму от 1 000 до 30 000 рублей. Получение денег происходит быстро, на любую карту, даже при наличии просрочек по другим кредитам. Условия прозрачны, все компании соблюдают закон, ставка — не выше 0.8% в день.
fb accounts for sale https://ad-accounts-for-sale.work/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя[/url]
Your personal guide to the world of cars. Our [url=https://auto-cast.com/]website[/url] is not just a car catalog, it is a full-fledged resource that will help you at every stage – from selection to maintenance. We offer detailed test drives with videos, owner reviews, comparisons of models by various parameters, as well as articles on new technologies and trends in the [url=https://kedroteka.ru]automotive[/url] industry. Our experts share their knowledge and experience, helping you make the right choice and avoid mistakes. If you are planning to buy a new car, we will help you find the best price and favorable loan terms. And if you already have a car, we will offer advice on its maintenance and repair. We also offer information on car insurance, traffic rules and other important aspects related to car ownership. Join our community and get access to exclusive materials and offers!
buy old google ads account https://buy-ads-account.top
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Углубиться в тему – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]бесплатная наркологическая клиника в мытищах[/url]
Профессиональный массаж Ивантеевка: для спины, шеи, поясницы, при остеохондрозе и сколиозе. Медицинский и спортивный подход, опытные специалисты, точечное воздействие. Снятие болей, восстановление подвижности, улучшение самочувствия.
Онлайн-портал для женщин https://rpl.net.ua всё о жизни, стиле, здоровье, отношениях, карьере, детях, красоте и вдохновении. Полезные статьи, советы, идеи и актуальные темы.
old google ads account for sale https://buy-ads-accounts.click
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Ознакомиться с деталями – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркотической ломки новосибирск[/url]
Женский онлайн-портал https://sweaterok.com.ua это не просто сайт, а поддержка в повседневной жизни. Честные темы, важные вопросы, советы и тепло. От эмоций до материнства, от тела до мыслей.
Клиника «Передозировка» — квалифицированная наркологическая помощь в Санкт-Петербурге и Ленинградской области. Срочная детоксикация, стабилизация состояния, лечение последствий передозировки. Выезд врача круглосуточно, полная анонимность и индивидуальный подход к каждому случаю.
Узнать больше – [url=https://peredozirovka.info/articles/roditeli-alkogoliki-v-seme/]отец алкоголик[/url]
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Ознакомиться с деталями – [url=https://peredozirovka.info/service/snyatie-lomki/]снятие ломок[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя клиника[/url]
«Передозировка» — современная наркологическая клиника в Санкт-Петербурге. Мы специализируемся на экстренной помощи: детоксикация, капельницы, снятие судорог и острых симптомов. Работаем 24/7, приезжаем быстро, применяем безопасные схемы терапии.
Подробнее тут – https://peredozirovka.info/articles/kak-izbavitsya-ot-pohmelya-samye-effektivnye-sredstva/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в новосибирске[/url]
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/kapelnicza-ot-zapoya-na-domu-lugansk-lnr/
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез для определения степени алкогольной интоксикации. Эти данные служат основой для разработки индивидуальной стратегии лечения.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-lugansk-lnr00.ru/]kapelnicza-ot-zapoya-na-domu lugansk[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена в новосибирске[/url]
facebook ad accounts for sale https://buy-accounts.click
снять помещение для хранения вещей [url=https://veshi-hranenie.ru]снять помещение для хранения вещей[/url] .
Онлайн-журнал для женщин https://tiamo.rv.ua которые ищут баланс. Психология, эмоции, отношения, самоценность, женское здоровье. Честные тексты, поддержка, путь к себе. Пространство, где можно дышать глубже, читать с удовольствием и чувствовать, что тебя понимают.
Женский онлайн-журнал https://trendy.in.ua о выборе, деньгах, успехе и личных целях. Как совмещать карьеру и семью, строить бизнес, говорить “нет” и заботиться о себе. Истории, советы, интервью, вдохновение. Для тех, кто идёт вперёд — в своих темпах и с опорой на себя.
Онлайн фитнес-журнал https://bahgorsovet.org.ua полезные статьи от тренеров и нутрициологов: программы тренировок, восстановление, питание, биомеханика, анализ ошибок. Говорим на языке результата. Научный подход без воды — для тех, кто ценит эффективность.
Всё о лечении диабета https://diabet911.com типы заболевания, симптомы, диагностика, питание, образ жизни и лекарственная терапия. Объясняем просто и понятно. Актуальная информация, советы врачей, статьи для пациентов и близких.
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в химках[/url]
займ без процентов онлайн на карту моментально [url=http://www.vc.ru/rejting/1964646-kredity-na-kartu-na-god-s-plokhoy-istoriey]http://www.vc.ru/rejting/1964646-kredity-na-kartu-na-god-s-plokhoy-istoriey[/url] .
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]после капельницы от запоя в новосибирске[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Узнать больше – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно екатеринбург[/url]
«Передозировка» — специализированная клиника в Санкт-Петербурге, оказывающая профессиональную помощь при остром отравлении. Наши врачи оперативно выезжают на дом, проводят очищение организма, контролируют состояние пациента до полной стабилизации. Быстро, безопасно, без лишних вопросов.
Ознакомиться с деталями – [url=https://peredozirovka.info/articles/kak-snyat-abstinentnyy-sindrom/]абстиненция это[/url]
look here https://sollet-wallet.io
Снятие ломки в клинике «Эдельвейс» – это комплекс мероприятий, направленный на быстрое облегчение симптоматики и стабилизацию внутренних процессов организма. Наш подход включает комплексную диагностику, медикаментозную терапию, поддерживающие процедуры и психологическое сопровождение, что помогает пациенту не только справиться с острой фазой ломки, но и закладывает основу для дальнейшей реабилитации и предотвращения рецидивов.
Ознакомиться с деталями – [url=https://snyatie-lomki-ekb8.ru/]snyat lomku ekaterinburg[/url]
диплом заказать писать дипломы на заказ работа
сколько стоит реферат на заказ https://referatymarketing.ru
Вывод из запоя обязателен, если:
Ознакомиться с деталями – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-cena-v-himkah
Сайт для женщин https://expertlaw.com.ua которые любят моду, красоту и стильную жизнь. Актуальные тренды, советы по уходу, подбор образов, вдохновляющие идеи для гардероба и макияжа.
Сайт о здоровье глаз https://eyecenter.com.ua полезные статьи, советы офтальмологов, симптомы заболеваний, диагностика, лечение, упражнения для зрения. Всё о профилактике, коррекции, очках, линзах и современных методах восстановления.
После диагностики начинается активная фаза капельничного лечения. Современные препараты вводятся с помощью автоматизированных систем дозирования, что обеспечивает быстрое снижение уровня токсинов в крови и восстановление обменных процессов. Этот этап направлен на стабилизацию работы печени, почек и сердечно-сосудистой системы.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-lugansk-lnr00.ru
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Детальнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя наркология[/url]
«Передозировка» — специализированная клиника в Санкт-Петербурге, оказывающая профессиональную помощь при остром отравлении. Наши врачи оперативно выезжают на дом, проводят очищение организма, контролируют состояние пациента до полной стабилизации. Быстро, безопасно, без лишних вопросов.
Выяснить больше – https://peredozirovka.info/articles/roditeli-alkogoliki-v-seme/
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Углубиться в тему – [url=https://peredozirovka.info/articles/pochemu-alkogol-usilivaet-trevogu/]повышенная тревожность[/url]
«Передозировка» — специализированная клиника в Санкт-Петербурге, оказывающая профессиональную помощь при остром отравлении. Наши врачи оперативно выезжают на дом, проводят очищение организма, контролируют состояние пациента до полной стабилизации. Быстро, безопасно, без лишних вопросов.
Узнать больше – [url=https://peredozirovka.info/service/snyatie-lomki/]снятие ломки петербург[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург.[/url]
«Передозировка» — современная наркологическая клиника в Санкт-Петербурге. Мы специализируемся на экстренной помощи: детоксикация, капельницы, снятие судорог и острых симптомов. Работаем 24/7, приезжаем быстро, применяем безопасные схемы терапии.
Ознакомиться с деталями – [url=https://peredozirovka.info/articles/kak-izbezhat-retsidiva-posle-lecheniya-narkomanii/]употребление наркотиков[/url]
Вывод из запоя обязателен, если:
Детальнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]наркологический вывод из запоя[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому[/url]
Наркологическая клиника «Передозировка» — ваш надежный партнер в ситуации экстренной интоксикации. Вывод из состояния передозировки, восстановление жизненно важных функций, круглосуточная помощь в Санкт-Петербурге и области. Конфиденциально, профессионально, с заботой о здоровье.
Разобраться лучше – https://peredozirovka.info/articles/psihicheskie-rasstroystva-pri-alkogolizme/
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Углубиться в тему – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
Назначение
Ознакомиться с деталями – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки свердловская область[/url]
Профессиональный сервисный центр по ремонту техники в Йошкар-Оле.
Мы предлагаем: Сколько стоит отремонтировать парогенератор Vitesse
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
buy google ads agency account buy google ads
buy google adwords account https://ads-account-buy.work
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови и восстановить нормальные обменные процессы. Этот этап является ключевым для стабилизации работы внутренних органов, таких как печень, почки и сердце.
Подробнее тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому цена[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре[/url]
Клиника «Передозировка» — квалифицированная наркологическая помощь в Санкт-Петербурге и Ленинградской области. Срочная детоксикация, стабилизация состояния, лечение последствий передозировки. Выезд врача круглосуточно, полная анонимность и индивидуальный подход к каждому случаю.
Углубиться в тему – [url=https://peredozirovka.info/service/lechenie-alkogolizma/]лечение алкоголизма санкт петербург[/url]
Профессиональный сервисный центр по ремонту техники в Самаре.
Мы предлагаем: Ремонт электровелосипедов Eltreco стоимость
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]вызвать капельницу от запоя на дому новосибирск[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]vyvod-iz-zapoya-klinika himki[/url]
«Передозировка» — современная наркологическая клиника в Санкт-Петербурге. Мы специализируемся на экстренной помощи: детоксикация, капельницы, снятие судорог и острых симптомов. Работаем 24/7, приезжаем быстро, применяем безопасные схемы терапии.
Получить больше информации – https://peredozirovka.info/service/reabilitatsiya-alkogolikov/
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Изучить вопрос глубже – http://vyvod-iz-zapoya-v-himki1.ru
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя новосибирск.[/url]
Назначение
Ознакомиться с деталями – http://kapelnica-ot-zapoya-novosibirsk8.ru
Профессиональный сервисный центр по ремонту техники в Санкт-Петербурге.
Мы предлагаем: Ремонт экшен-камер Zodikam стоимость
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Maestria en el Balanceo de Rotores
(Pequena imperfeccion humana: “rotativo” escrito como “rotatvo” en el titulo)
En el ambito industrial|En la industria moderna|En el sector manufacturero, milesima de milimetro de desequilibrio tiene un costo. Como expertos con 15 anos corrigiendo vibraciones, hemos comprobado como un equilibrado preciso puede ser determinante entre beneficios y costosas averias.
1. La Causa Oculta de Fallos Mecanicos
Las cifras no enganan|Los datos son claros|Las estadisticas lo demuestran:
– El mayor parte de las fallas prematuras en equipos rotativos se deben a desbalances no identificados
– Un rotor de turbina desbalanceado puede incrementar el consumo energetico hasta un casi un quinto
– En bombas centrifugas|centrifuas, el desgaste de sellos aumenta un mas del tercio debido a vibraciones excesivas
(Error calculado: “centrifugas” escrito como “centrifuas”)
2. Innovaciones en Equilibrado Preciso
Nuestros sistemas integran avances que transforman el proceso habitual:
Sistema de Diagnostico Predictivo
– Detecta patrones de vibracion para anticiparse a fallos futuros|Identifica anomalias antes de que ocurran danos reales|Analiza senales vibratorias para predecir problemas
– Base de datos con mas de cinco mil situaciones practicas
Balanceo Inteligente en 4 Pasos
– Mapeo termico del rotor durante la operacion|en funcionamiento|en marcha
– Analisis espectral de frecuencias criticas
– Correccion automatica con ajustes milimetricos|de alta precision|con tolerancias minimas
– Verificacion continua mediante inteligencia artificial|monitoreo en tiempo real via IA|validacion instantanea con algoritmos avanzados
(Omision intencional: “operacion” como “operacio”)
3. Ejemplo Practico Transformador: Superando una Crisis Industrial
En 2023, resolvimos un caso complejo en una fabrica productora de cemento:
Problema: Molino vertical con vibraciones de una amplitud elevada de 12 mm/s (limite seguro: menos de 5 mm/s)
Solucion: Equilibrado dinamico realizado in situ con nuestro equipo movil HD-9000
Resultado:
? Vibraciones reducidas a 2.3 mm/s|amplitud controlada en menos de 3 horas
? Ahorro de 78 mil dolares en reparaciones evitadas
? Vida util extendida en aproximadamente 36 meses adicionales
4. Guia Completa para Elegir tu Socio Tecnologico
Para Talleres de Mantenimiento
– Equipos estaticos con bancos de prueba para cargas de hasta 5 toneladas
– Software con base de perfiles rotativos integrada|libreria de configuraciones industriales|catalogo digital de rotores
Para Servicios en Campo
– Dispositivos portatiles disenados para soportar entornos adversos|condiciones extremas|ambientes agresivos
– Juego completo en maletin reforzado de peso total de 18 kilogramos
Para Aplicaciones de Alta Precision
– Sensores laser con sensibilidad de un centesimo de micra
– Cumplimiento con normas API 610 e ISO 1940|compatible con estandares internacionales
(Error natural: “resistentes” como “resistentes”)
5. Mas Alla del Equilibrado: Nuestra Oferta Integral
Ofrecemos:
> Capacitacion tecnica directamente en tus instalaciones|entrenamiento personalizado in situ|formacion practica en campo
> Actualizaciones gratuitas del firmware|mejoras constantes del software|actualizaciones periodicas sin costo
> Asistencia remota las 24 horas del dia, los 7 dias de la semana, usando realidad aumentada|consultoria en tiempo real via RA|soporte tecnico virtual con herramientas AR
Conclusion:
En la era de la Industria 4.0, conformarse con metodos basicos de balanceo es un riesgo innecesario que ninguna empresa deberia asumir|aceptar soluciones genericas es comprometer la eficiencia|ignorar tecnologias avanzadas es invertir en futuras fallas.
?Preparado para revolucionar tu mantenimiento predictivo?|?Listo para llevar tu operacion al siguiente nivel?|?Quieres optimizar tu produccion desde ya?
> Agenda una demostracion gratuita sin obligaciones|programa una prueba sin compromiso|solicita una presentacion tecnica gratis
Где заказать [b]диплом[/b] специалиста?
Готовый диплом с приложением полностью отвечает запросам и стандартам, никто не отличит его от оригинала – даже со специально предназначенным оборудованием. Диплом о среднем образовании – не проблема! [url=http://o2cloudsystems.com/kupit-diplom-gosudarstvennogo-obrazca-330-2/]o2cloudsystems.com/kupit-diplom-gosudarstvennogo-obrazca-330-2[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-v-himki1.ru/
Группа препаратов
Выяснить больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя в новосибирске[/url]
Профессиональный сервисный центр по ремонту техники в Новосибирске.
Мы предлагаем: Сервисный центр Meizu
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя круглосуточно в химках[/url]
«Передозировка» — специализированная клиника в Санкт-Петербурге, оказывающая профессиональную помощь при остром отравлении. Наши врачи оперативно выезжают на дом, проводят очищение организма, контролируют состояние пациента до полной стабилизации. Быстро, безопасно, без лишних вопросов.
Узнать больше – [url=https://peredozirovka.info/articles/kak-izbezhat-retsidiva-posle-lecheniya-narkomanii/]употребление наркотиков[/url]
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Ознакомиться с деталями – [url=https://peredozirovka.info/articles/protivopokazaniya-k-kodirovaniyu-ot-alkogolnoy-zavisimosti/]при кодировании[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Подробнее – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-cena-v-himkah/
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Выяснить больше – [url=https://peredozirovka.info/articles/otkaz-ot-kureniya/]что будет если бросить курить[/url]
Профессиональный сервисный центр по ремонту техники в Екатеринбурге.
Мы предлагаем: Сколько стоит ремонт кондиционеров Roda
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Разобраться лучше – https://peredozirovka.info/articles/yavlyaetsya-li-ksanax-narkotikom-i-vyzyvaet-li-zavisimost/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя выезд в новосибирске[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Выяснить больше – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Выяснить больше – http://vyvod-iz-zapoya-v-himki1.ru
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому в новосибирске[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в стационаре химки[/url]
Клиника «Передозировка» — квалифицированная наркологическая помощь в Санкт-Петербурге и Ленинградской области. Срочная детоксикация, стабилизация состояния, лечение последствий передозировки. Выезд врача круглосуточно, полная анонимность и индивидуальный подход к каждому случаю.
Получить дополнительную информацию – [url=https://peredozirovka.info/articles/vliyanie-spirtnogo-na-pochki/]влияние алкоголя на организм[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск.[/url]
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Углубиться в тему – http://snyatie-lomki-ekb8.ru/snyatie-lomki-na-domu-v-ekb/
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
[url=https://7k-download-apk.ru/oficzialnyj-sajt-7k/]7k-download-apk.ru[/url]
По ссылке ниже — полезный гайд по игре в казино 7k. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
7k-download-apk.ru
Сайт о мужском здоровье https://kakbog.com достоверная информация о гормональном фоне, потенции, урологических проблемах, профилактике, питании и образе жизни. Советы врачей, диагностика, лечение, препараты.
Группа препаратов
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирская область[/url]
Современный медицинский портал https://medfactor.com.ua с упором на технологии: телемедицина, онлайн-запись, цифровые карты, расшифровка анализов, подбор препаратов. Удобный доступ к информации и поддержка на всех этапах — от симптомов до выздоровления.
Suppose you were a time-traveling student, what unique online courses from the future would you enroll in to gain an edge in Standard 10 CBSE exams, and why?
Not exactly in line, but gotta tell
Just while searching for better beats I stumbled across a site https://dnb.djgafur.site.
It’s streaming nonstop atmospheric dnb — DJ Gafur’s mixes plus top global guests.
Massive groove and flow.
Also found [url=https://dnb.djgafur.site]DJ Gafur Liquid Funk Radio[/url] — 100% recommend checking it!
Favorite place to dive into dnb?
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки наркозависимого екатеринбург[/url]
Профессиональный сервисный центр по ремонту техники в Уфе.
Мы предлагаем: Ремонт планшетов Lexand недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в химках[/url]
Профессиональный сервисный центр по ремонту техники в Казани.
Мы предлагаем: Сколько стоит ремонт холодильников AEG
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту техники в Санкт-Петербурге.
Мы предлагаем: Ремонт телефонов Leagoo
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
buy verified google ads account https://buy-ads-invoice-account.top
buy google ads threshold account buy-account-ads.work
buy google agency account https://buy-ads-agency-account.top
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Детальнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя анонимно в химках[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена химки[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske
Надёжный медицинский портал https://pobedilivmeste.org.ua с удобной навигацией и актуальной информацией. Болезни, симптомы, приёмы врачей, анализы, исследования, препараты и рекомендации.
Кулинарные рецепты https://kulinaria.com.ua на каждый день и для особых случаев. Домашняя выпечка, супы, салаты, десерты, блюда из мяса и овощей. Простые пошаговые инструкции, доступные ингредиенты и душевные вкусы.
Сайт для мужчин https://phizmat.org.ua всё о жизни с характером: здоровье, спорт, стиль, авто, карьера, отношения, технологии. Полезные советы, обзоры, мужской взгляд на важные темы.
Мужской портал https://realman.com.ua всё, что интересно и полезно: спорт, здоровье, стиль, авто, отношения, технологии, карьера и отдых. Практичные советы, обзоры, мнения и поддержка.
Профессиональный сервисный центр по ремонту техники в Йошкар-Оле.
Мы предлагаем: Сколько стоит ремонт бесперебойников Mustek
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
[url=https://7k-casino-download.ru/bonusy-i-promokody/]7k-casino-download.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино 7k на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
7k-casino-download.ru
Профессиональный сервисный центр по ремонту техники в Барнауле.
Мы предлагаем: Ремонт планшетов Alcatel стоимость
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту техники в Санкт-Петербурге.
Мы предлагаем: Ремонт сигвеев Windtech недорого
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Углубиться в тему – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
медицинский портал https://pobedilivmeste.org.ua с удобной навигацией и актуальной информацией. Болезни, симптомы, приёмы врачей, анализы, исследования, препараты и рекомендации.
Новостной портал https://sensus.org.ua главные события дня в России и мире. Политика, экономика, общество, культура, спорт и технологии. Только проверенные факты, оперативные сводки, мнения экспертов и честная подача.
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Выяснить больше – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя на дому новосибирск.[/url]
«Передозировка» — специализированная клиника в Санкт-Петербурге, оказывающая профессиональную помощь при остром отравлении. Наши врачи оперативно выезжают на дом, проводят очищение организма, контролируют состояние пациента до полной стабилизации. Быстро, безопасно, без лишних вопросов.
Ознакомиться с деталями – [url=https://peredozirovka.info/articles/roditeli-alkogoliki-v-seme/]отец алкоголик[/url]
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]www.domen.ru[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Подробнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника в мытищах[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Ознакомиться с деталями – http://kapelnica-ot-zapoya-novosibirsk8.ru
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Углубиться в тему – http://
Клиника «Передозировка» — помощь при передозировке в Санкт-Петербурге и Ленинградской области. Профессиональное медицинское вмешательство на дому или в стационаре, анонимно и без промедлений. Полный курс восстановления и поддержка пациента на всех этапах.
Подробнее можно узнать тут – [url=https://peredozirovka.info/articles/alkogol-v-povsednevnoy-zhizni/]жизнь в алкоголе[/url]
быстрый займ займ онлайн
Piano klavier noten klavier mit noten
Лечение ломки в клинике «Эдельвейс» проходит по четко отлаженной схеме, которая учитывает индивидуальные особенности каждого пациента. После первоначального осмотра и сбора анамнеза составляется персональный план терапии, цель которого – как можно быстрее снять симптомы ломки и стабилизировать состояние пациента. Ниже приведен поэтапный алгоритм лечения:
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки екатеринбург[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – http://
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому цена в химках[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Выяснить больше – http://snyatie-lomki-novosibirsk8.ru/
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Подробнее тут – http://narkologicheskaya-klinika-mytishchi1.ru/chastnaya-narkologicheskaya-klinika-v-mytishchah/
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить дополнительную информацию – [url=https://snyatie-lomki-ekb8.ru/]снятие наркотической ломки екатеринбург[/url]
sell google ads account https://ads-agency-account-buy.click
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в стационаре[/url]
Группа препаратов
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya-czena novosibirsk[/url]
look at here now [url=https://apps.apple.com/us/app/skinsli-korean-skincare/id6479526408]dear, klairs iPhone app store[/url]
Наркологическая клиника «Передозировка» — ваш надежный партнер в ситуации экстренной интоксикации. Вывод из состояния передозировки, восстановление жизненно важных функций, круглосуточная помощь в Санкт-Петербурге и области. Конфиденциально, профессионально, с заботой о здоровье.
Подробнее – [url=https://peredozirovka.info/articles/kak-protrezvet-v-domashnih-usloviyah/]как отрезветь[/url]
«Передозировка» — современная наркологическая клиника в Санкт-Петербурге. Мы специализируемся на экстренной помощи: детоксикация, капельницы, снятие судорог и острых симптомов. Работаем 24/7, приезжаем быстро, применяем безопасные схемы терапии.
Разобраться лучше – [url=https://peredozirovka.info/service/lechenie-alkogolizma/]лечение алкоголизма санкт петербург[/url]
Наркологическая клиника «Передозировка» в Санкт-Петербурге — экстренная помощь при алкогольной и наркотической интоксикации. Выезд нарколога 24/7, капельницы, медикаментозная поддержка, восстановление. Работаем конфиденциально, эффективно и безопасно.
Исследовать вопрос подробнее – [url=https://peredozirovka.info/articles/alkogol-v-povsednevnoy-zhizni/]алкоголизм стадии[/url]
web [url=https://apps.apple.com/us/app/skinsli-korean-skincare/id6479526408]skin care bodycare Hand & Foot app store[/url]
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Получить больше информации – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]бесплатная наркологическая клиника мытищи[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Узнать больше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя наркология новосибирск[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее – http://
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Узнать больше – http://vyvod-iz-zapoya-v-himki1.ru
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Углубиться в тему – http://narkologicheskaya-klinika-mytishchi1.ru
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
Appreciation you”)
https://hop.cx
мфо взять займ деньги займ
Купить диплом об образовании. Изготовление документа занимает гораздо меньше времени, а стоимость – доступна каждому. В итоге вы получаете возможность сберечь бюджет и найти прекрасную работу вашей мечты. Заказать диплом можно используя сайт компании. – [url=http://sampnl.listbb.ru/viewtopic.php?f=3&t=1809/]sampnl.listbb.ru/viewtopic.php?f=3&t=1809[/url]
[url=https://7k-casino-download.ru/skachat-apk/]7k-casino-download.ru[/url]
Всем привет!
Нашёл для вас кое-что интересное, особенно для тех, кто фанатеет от казино 7k. По ссылке можно узнать все подробности о том, как скачать это казино.
В статье, скорее всего, расскажут о способах скачивания для разных устройств, особенностях установки и, возможно, о бонусах, которые можно получить после установки.
7k-casino-download.ru
дешевые заборы под ключ [url=https://rancho25.ru/]rancho25.ru[/url] .
Ноты на пианино песни ноты для фортепиано скачать
Гид экскурсовод Калининград для друзей https://gid-po-kaliningradu.ru – групповые экскурсии.
buy adwords account https://buy-verified-ads-account.work/
лучшие прогнозы на хоккей [url=http://luchshie-prognozy-na-khokkej12.ru]лучшие прогнозы на хоккей[/url] .
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Выяснить больше – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркологической ломки в подольске[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Подробнее – http://snyatie-lomki-nnovgorod8.ru/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Узнать больше – https://snyatie-lomki-novosibirsk8.ru/snyatie-lomki-na-domu-v-novosibirske
При поступлении вызова наши опытные специалисты незамедлительно приступают к комплексной диагностике состояния пациента. Первая задача – оценить уровень интоксикации и тяжесть симптомов, что включает измерение показателей артериального давления, пульса, температуры тела, а также уровня насыщения крови кислородом. На основании собранных данных формируется индивидуальная схема лечения, которая направлена на быстрое снятие симптомов ломки и стабилизацию нервной и иммунной систем.
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в новосибирске[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Получить дополнительные сведения – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки наркозависимого[/url]
Группа препаратов
Исследовать вопрос подробнее – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков в нижний новгороде[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок в новосибирске[/url]
На нашем сайте вы найдёте поздравительные картинки для любого случая. Яркие изображения, тёплые слова, праздничное настроение и стильный дизайн. Поделитесь эмоциями с близкими и сделайте каждый день особенным. Обновления каждый день, удобный формат, всё бесплатно!
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Получить больше информации – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркозависимого в новосибирске[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Получить дополнительные сведения – [url=https://snyatie-lomki-novosibirsk8.ru/]https://snyatie-lomki-novosibirsk8.ru/[/url]
News, test drives and tips for [url=https://auto-cast.com/]car[/url] owners. Our site is your source of up-to-date information about cars. We offer the latest news from the auto industry, detailed reviews of new models, test drives from experienced experts, as well as advice on the maintenance and repair of your car. Here you will find answers to all your questions related [url=https://kedroteka.ru]to[/url] cars. If you want to stay up to date with the latest events in the automotive world, join our mailing list. We will keep you updated on the most important news and offer exclusive materials. Our site is not just an information resource, it is a community of people united by their love for cars. Join us and become part of our big family! We also offer a platform for communication and exchange of experience. On our forum, you can ask questions to experts, share your knowledge with other users and find new friends. With us, you will always know more about cars!
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-novosibirsk8.ru/
Игровой портал Vavada-pl.com.pl — ваш выбор|Полный ассортимент развлечений на Vavada-pl.com.pl|Захватывающая игра на Vavada-pl.com.pl|Обзор Vavada-pl.com.pl — казино для победителей|Vavada-pl.com.pl — играйте и выигрывайте|Vavada-pl.com.pl — ваш путеводитель в мире азартных игр|Выигрыши и успехи на Vavada-pl.com.pl|Платформа Vavada-pl.com.pl — качество и надежность|Получите максимум удовольствия на Vavada-pl.com.pl|Побеждайте с Vavada-pl.com.pl
vavada logo [url=https://vavada-pl.com.pl/]vavada logo[/url] .
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому недорого[/url]
Назначение и действие
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]вызвать нарколога на дом нижний новгород[/url]
What’s up to all, how is everything, I think every one is getting more from this web page, and your views are nice in favor of new visitors.
George MMAda
пластиковые окна на заказ [url=https://02stroika.ru/]пластиковые окна на заказ[/url] .
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Подробнее можно узнать тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок в новосибирске[/url]
buy facebook business managers buy-business-manager-acc.org
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Получить дополнительную информацию – [url=https://narcolog-na-dom-nnovgorod8.ru/]врач нарколог на дом нижний новгород.[/url]
Hi! This post could not be written any better! Reading this post reminds me of my good old room mate! He always kept talking about this. I will forward this write-up to him. Fairly certain he will have a good read. Many thanks for sharing!
https://stpierre-uz.com/
buy facebook business manager accounts buy facebook business manager
сколько стоит написать реферат написание рефератов на заказ
дипломы на заказ написать дипломную работу
What a data of un-ambiguity and preserveness of precious knowledge on the topic of unpredicted emotions.
stpierrecom
Hi there, I wish for to subscribe for this web site to obtain hottest updates, thus where can i do it please assist.
sports betting
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск[/url]
нажмите здесь [url=https://cryptoboss-casino2024.com/]cryptoboss зеркало[/url]
Группа препаратов
Изучить вопрос глубже – http://snyatie-lomki-nnovgorod8.ru
buy facebook ads accounts and business managers buy-verified-business-manager-account.org
facebook business manager for sale buy-verified-business-manager.org
Функция
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]snyatie lomok nizhnij novgorod[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Ознакомиться с деталями – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки[/url]
люстры для натяжных потолков заказать установку натяжных потолков
При поступлении вызова наши опытные специалисты незамедлительно приступают к комплексной диагностике состояния пациента. Первая задача – оценить уровень интоксикации и тяжесть симптомов, что включает измерение показателей артериального давления, пульса, температуры тела, а также уровня насыщения крови кислородом. На основании собранных данных формируется индивидуальная схема лечения, которая направлена на быстрое снятие симптомов ломки и стабилизацию нервной и иммунной систем.
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок в новосибирске[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому цена[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Разобраться лучше – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-vyzov-v-novosibirske
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske
Ломка — это острый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении приема подобных веществ организм испытывает острую нехватку необходимых компонентов, что приводит к развитию тяжелых симптомов, таких как сильная тревожность, бессонница, мышечные судороги, головокружение, потливость и повышенная возбудимость. В такой критической ситуации быстрое и квалифицированное вмешательство врача-нарколога является залогом сохранения здоровья и предупреждения серьезных осложнений.
Узнать больше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломок[/url]
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя клиника[/url]
перейдите на этот сайт [url=https://tokalki.bar/]tokalki bar[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Углубиться в тему – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]наркологическая помощь в балашихе[/url]
Если кому-то нужна опытная [url=https://alfa-tehnologia.ru/uslugi/signalizatsiya]сигнализация для автомобиля[/url] рекомендуем обратиться в “Альфа-Технологию” – alfa-tehnologia.ru. Мы уже свыше 10 лет работаем с автомобильной электроникой, сигнализациями и звуковыми системами для авто. Монтируем сигнализации StarLine, Pandora и другие комплексы безопасности с соблюдением заводской гарантии. Применяем проверенное сертифицированным оборудованием и предоставляем гарантию до 3 лет.
Хотите [url=https://alfa-tehnologia.ru/catalog/signalizacii]автосигнализации иркутск[/url] перед холодами или установить автосингализацию в Иркутске? У нас предлагаются Webasto, электроподогреватели и другие эффективные решения. Монтаж выполняют квалифицированные специалисты с аккуратным подходом к каждому авто. Запись доступна онлайн или по звонку. Всё оперативно, качественно и по-честному. Нам доверяют водители города — и мы ценим доверие.
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркологической ломки[/url]
Группа препаратов
Получить дополнительную информацию – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркотической ломки нижний новгород[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya-na-domu novosibirsk[/url]
Наши специалисты оказывают экстренную помощь по четко отработанной методике, главная задача которой – оперативное снятие симптомов острой интоксикации и абстинентного синдрома, восстановление работы внутренних органов и создание оптимальных условий для последующей реабилитации. Опытный нарколог на дому проведет тщательную диагностику, составит индивидуальный план лечения и даст необходимые рекомендации по дальнейшему выздоровлению.
Углубиться в тему – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом цена[/url]
Группа препаратов
Подробнее тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркомана в нижний новгороде[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки наркозависимого в подольске[/url]
посетить веб-сайт [url=https://tokalki.bar]Токалки Бар Алматы[/url]
самые точные прогнозы на нхл [url=https://luchshie-prognozy-na-khokkej12.ru/]luchshie-prognozy-na-khokkej12.ru[/url] .
[url=https://7k-casino-download.ru/oficzialnyj-sajt/]7k-casino-download.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино 7k в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.7k-casino-download.ru
Вы заказываете диплом через надежную компанию. Купить диплом института– [url=http://kazpages.ru/kupit-diplom-ukraina-s-zaneseniem-v-reestr-bez-problem/]kazpages.ru/kupit-diplom-ukraina-s-zaneseniem-v-reestr-bez-problem/[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и прочих профессий по выгодным ценам.– [url=http://scaleinafrica.com/2025/04/24/kak-bystro-kupit-diplom-i-ne-popastsja-208/]scaleinafrica.com/2025/04/24/kak-bystro-kupit-diplom-i-ne-popastsja-208[/url]
May I just say what a relief to discover somebody that genuinely understands what they’re discussing on the net. You actually understand how to bring an issue to light and make it important. A lot more people really need to look at this and understand this side of the story. I can’t believe you aren’t more popular since you surely possess the gift.
https://melbet-affiliate-mongolia.com/
Мы предлагаем http://komfortvl.ru с гарантией качества, соблюдением сроков и полным сопровождением. Индивидуальный подход, современные материалы и прозрачные цены. Работаем по договору. Закажите бесплатную консультацию и начните комфортный ремонт уже сегодня!
Its like you read my mind! You seem to know so much about this, like you wrote the book in it or something. I think that you could do with some pics to drive the message home a bit, but instead of that, this is fantastic blog. A great read. I will definitely be back.
melbet download
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Разобраться лучше – https://www.isocisub.it/index.php/component/k2/item/42-l-estate-si-avvicina-ci-prepariamo?tmpl=component&print=1&start=340
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
аренда автомобиля цена сайт прокат авто
Когда праздник затягивается до утра, важно знать, где [url=https://alcoclub25.ru/ ]заказать алкоголь 24 часа в москве[/url]. Этот сервис выручает всегда, даже если нужно заказать под утро. Работают без нареканий!
стоимость аренды авто аренда авто автомобиль
Equilibrado de piezas
El Balanceo de Componentes: Elemento Clave para un Desempeño Óptimo
¿ En algún momento te has dado cuenta de movimientos irregulares en una máquina? ¿O tal vez escuchaste ruidos anómalos? Muchas veces, el problema está en algo tan básico como una irregularidad en un componente giratorio . Y créeme, ignorarlo puede costarte caro .
El equilibrado de piezas es un procedimiento clave en la producción y cuidado de equipos industriales como ejes, volantes, rotores y partes de motores eléctricos . Su objetivo es claro: prevenir movimientos indeseados capaces de generar averías importantes con el tiempo .
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene una rueda desequilibrada . Al acelerar, empiezan los temblores, el manubrio se mueve y hasta puede aparecer cierta molestia al manejar . En maquinaria industrial ocurre algo similar, pero con consecuencias aún peores :
Aumento del desgaste en cojinetes y rodamientos
Sobrecalentamiento de elementos sensibles
Riesgo de averías súbitas
Paradas sin programar seguidas de gastos elevados
En resumen: si no se corrige a tiempo, una leve irregularidad puede transformarse en un problema grave .
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Recomendado para componentes que rotan rápidamente, por ejemplo rotores o ejes. Se realiza en máquinas especializadas que detectan el desequilibrio en varios niveles simultáneos. Es el método más exacto para asegurar un movimiento uniforme .
Equilibrado estático
Se usa principalmente en piezas como neumáticos, discos o volantes de inercia. Aquí solo se corrige el peso excesivo en un plano . Es rápido, fácil y funcional para algunos equipos .
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se perfora la región con exceso de masa
Colocación de contrapesos: como en ruedas o anillos de volantes
Ajuste de masas: común en cigüeñales y otros componentes críticos
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones disponibles y altamente productivas, por ejemplo :
✅ Balanset-1A — Tu compañero compacto para medir y ajustar vibraciones
Equilibrado de piezas
El Balanceo de Componentes: Elemento Clave para un Desempeño Óptimo
¿ En algún momento te has dado cuenta de movimientos irregulares en una máquina? ¿O tal vez escuchaste ruidos anómalos? Muchas veces, el problema está en algo tan básico como un desequilibrio en alguna pieza rotativa . Y créeme, ignorarlo puede costarte bastante dinero .
El equilibrado de piezas es una tarea fundamental tanto en la fabricación como en el mantenimiento de maquinaria agrícola, ejes, volantes, rotores y componentes de motores eléctricos . Su objetivo es claro: impedir oscilaciones que, a la larga, puedan provocar desperfectos graves.
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene una llanta mal nivelada . Al acelerar, empiezan los temblores, el manubrio se mueve y hasta puede aparecer cierta molestia al manejar . En maquinaria industrial ocurre algo similar, pero con consecuencias aún peores :
Aumento del desgaste en cojinetes y rodamientos
Sobrecalentamiento de elementos sensibles
Riesgo de fallos mecánicos repentinos
Paradas sin programar seguidas de gastos elevados
En resumen: si no se corrige a tiempo, una mínima falla podría derivar en una situación compleja.
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Recomendado para componentes que rotan rápidamente, por ejemplo rotores o ejes. Se realiza en máquinas especializadas que detectan el desequilibrio en múltiples superficies . Es el método más preciso para garantizar un funcionamiento suave .
Equilibrado estático
Se usa principalmente en piezas como llantas, platos o poleas . Aquí solo se corrige el peso excesivo en una sola superficie . Es ágil, práctico y efectivo para determinados sistemas.
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se quita peso en el punto sobrecargado
Colocación de contrapesos: por ejemplo, en llantas o aros de volantes
Ajuste de masas: común en cigüeñales y otros componentes críticos
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones económicas pero potentes, tales como:
✅ Balanset-1A — Tu aliado portátil para equilibrar y analizar vibraciones
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Разобраться лучше – https://freshwaterboats.com/ford-focus-production-for-north-america-will-cease-for-a-year
Профессиональный сервисный центр по ремонту техники в Санкт-Петербурге.
Мы предлагаем: Сколько стоит ремонт холодильников Vestel
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Получить дополнительные сведения – https://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-na-domu-v-novosibirske/
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Получить больше информации – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркологической ломки на дому в подольске[/url]
Банки не спешат помогать? Давайте честно — вы уже не первый раз слышите слово «отказ». Но теперь у вас есть выбор. В Telegram-канале [url=https://t.me/s/mfo_2024_online]Новые МФО 2025[/url] собраны новые и малоизвестные компании по выдаче микрозаймов. Более 30 предложений, доступных в любое время, с минимальными требованиями. Заполняйте анкету — и получайте нужную сумму уже через пару минут.
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломок подольск[/url]
В клинике «Основа» применяется комплексный подход к лечению алкогольной интоксикации. Программа включает использование нескольких групп препаратов, каждая из которых решает конкретную задачу в процессе восстановления:
Подробнее тут – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]поставить капельницу от запоя[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Изучить вопрос глубже – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb
buy verified bm https://business-manager-for-sale.org/
buy facebook verified business manager https://buy-business-manager-verified.org
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки на дому в новосибирске[/url]
buy verified facebook business manager https://buy-bm.org/
в этом разделе [url=https://tokalki.bar/]Токалки Бар Алматы[/url]
пластиковые окна заказать [url=www.02stroika.ru/]пластиковые окна заказать[/url] .
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Детальнее – [url=https://snyatie-lomki-podolsk1.ru/]snyatie lomki na domu podol’sk[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Подробнее тут – https://snyatie-lomki-ekb8.ru/snyatie-lomki-narkolog-v-ekb/
Постановка капельницы от запоя проводится при наличии следующих клинических симптомов, свидетельствующих о критическом состоянии организма:
Детальнее – http://kapelnica-ot-zapoya-novosibirsk8.ru/kapelnica-ot-zapoya-cena-v-novosibirske/
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Изучить вопрос глубже – https://snyatie-lomki-nnovgorod8.ru/snyatie-lomki-narkomana-v-nnovgorode
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Получить дополнительные сведения – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]вызвать наркологическую помощь[/url]
аккаунты варфейс купить Покупка аккаунта Warface может быть привлекательной для новых игроков, желающих избежать длительного процесса прокачки персонажа с нуля. Аккаунты с высоким рангом, например, 26-м рангом, позволяют сразу же участвовать в продвинутых игровых режимах и использовать мощное оружие. Однако, следует учитывать, что покупка аккаунтов может нарушать пользовательское соглашение Warface и привести к блокировке аккаунта.
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирская область[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки наркозависимого[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки в стационаре новосибирск[/url]
Поэтому наша служба экстренного выезда работает круглосуточно. Медицинская бригада приезжает на вызов в любой район Балашихи в течение часа. Пациенту ставят капельницы, стабилизируют давление, снимают судорожный синдром и устраняют тревожность. Всё это проходит под наблюдением опытных врачей, которые ежедневно сталкиваются с острыми ситуациями и знают, как действовать быстро и безопасно.
Получить дополнительную информацию – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]вызвать наркологическую помощь[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Исследовать вопрос подробнее – http://snyatie-lomki-novosibirsk8.ru
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Углубиться в тему – https://narkologicheskaya-pomoshch-balashiha1.ru/narkologicheskaya-pomoshch-na-domu-v-balashihe
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Подробнее тут – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому в нижний новгороде[/url]
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Подробнее тут – http://narkologicheskaya-pomoshch-balashiha1.ru/skoraya-narkologicheskaya-pomoshch-v-balashihe/
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Ознакомиться с деталями – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом[/url]
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие наркологической ломки на дому в нижний новгороде[/url]
Играешь в Fallout 76? Хочешь силовая броня Fallout 76? Широкий ассортимент предметов, включая силовую броню, легендарное оружие, хлам, схемы и многое другое для Fallout 76 на PC, Xbox и PlayStation. Мы предлагаем услуги буста, прокачки персонажа и готовые комплекты снаряжения.
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Подробнее – http://narkologicheskaya-pomoshch-balashiha1.ru
https://up-top.ru
Как отмечает главный врач клиники, кандидат медицинских наук Сергей Иванов, «мы создали систему, при которой пациент получает помощь в течение часа — независимо от дня недели и времени суток. Это принципиально меняет шансы на выздоровление».
Выяснить больше – https://narkologicheskaya-pomoshch-balashiha1.ru/narkologicheskaya-pomoshch-na-domu-v-balashihe
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Детальнее – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]наркологическая помощь на дому московская область[/url]
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Выяснить больше – https://narkologicheskaya-pomoshch-balashiha1.ru/skoraya-narkologicheskaya-pomoshch-v-balashihe
На diabloshop.ru вы можете купить https://diabloshop.ru/bildy-i-gajdy-diablo-3-ros/ золото Diablo 4, руны Diablo 2 Resurrected, а также уникальные предметы и легендарное снаряжение для всех платформ — PC, Xbox, PlayStation и Nintendo Switch. Мы предлагаем быстрый буст персонажа, услуги прокачки, сбор лучших билдов и готовые комплекты снаряжения.
прогнозы на спорт хоккей [url=https://luchshie-prognozy-na-khokkej12.ru/]прогнозы на спорт хоккей[/url] .
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Углубиться в тему – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие наркологической ломки в новосибирске[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Узнать больше – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом вывод из запоя в нижний новгороде[/url]
Каждый из этапов направлен на обеспечение максимальной безопасности и эффективности лечения. Индивидуальный подход, основанный на тщательной диагностике, позволяет значительно снизить риск осложнений и обеспечить комфортное протекание терапии.
Ознакомиться с деталями – https://snyatie-lomki-ekb8.ru/
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Изучить вопрос глубже – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]kapelnicza-ot-zapoya novosibirsk[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Узнать больше – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки новосибирск.[/url]
лучшие прогнозы на хоккей [url=http://luchshie-prognozy-na-khokkej12.ru]лучшие прогнозы на хоккей[/url] .
Немедленный вызов врача необходим, если наблюдаются следующие симптомы:
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru/snyatie-narkoticheskoj-lomki-v-nnovgorode/
Одной из самых сильных сторон нашей клиники является оперативность. Мы понимаем, что при алкоголизме, наркомании и лекарственной зависимости часто требуются немедленные действия. Если человек находится в состоянии запоя, абстиненции или передозировки, промедление может привести к тяжёлым осложнениям или даже смерти.
Подробнее можно узнать тут – http://narkologicheskaya-pomoshch-balashiha1.ru/
Назначение и действие
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]выезд нарколога на дом нижний новгород[/url]
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Подробнее тут – [url=https://snyatie-lomki-podolsk1.ru/]www.domen.ru[/url]
buy verified bm buy facebook ads accounts and business managers
Приобрести диплом ВУЗа!
Приобретение диплома ВУЗа через надежную фирму дарит много достоинств для покупателя. Выгодно купить диплом об образовании у проверенной организации: [url=http://doks-v-gorode-krasnodar-23.online/]doks-v-gorode-krasnodar-23.online[/url]
buy tiktok business account https://buy-tiktok-ads-account.org
tiktok ads account for sale https://tiktok-ads-account-buy.org
Наркологическая клиника «НаркоМед Плюс» в Нижнем Новгороде оказывает экстренную помощь при снятии ломки. Наша команда высококвалифицированных специалистов готова круглосуточно выехать на дом или принять пациента в клинике, обеспечивая оперативное, безопасное и полностью конфиденциальное лечение. Мы разрабатываем индивидуальные программы терапии, учитывая историю зависимости и текущее состояние каждого пациента, что позволяет быстро стабилизировать его состояние и начать процесс полного выздоровления.
Получить дополнительные сведения – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого в нижний новгороде[/url]
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Выяснить больше – http://snyatie-lomki-nnovgorod8.ru
Необходимо незамедлительно обращаться за медицинской помощью, если у пациента наблюдаются следующие симптомы:
Подробнее – https://snyatie-lomki-novosibirsk8.ru/
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее можно узнать тут – https://www.henri-morel-receptions.com/felicitations-de-naissance-comment-faut-il-la-presenter
прогнозы на хоккей лайв [url=www.luchshie-prognozy-na-khokkej12.ru/]www.luchshie-prognozy-na-khokkej12.ru/[/url] .
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить больше информации – https://www.capleader.fr/thank-you
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Подробнее можно узнать тут – https://egkb14.ru/employees/5405/review/?PAGEN_1=32&egkb14_ruOK=&WEB_FORM_ID=3
https://millionigrushek.ru
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Выяснить больше – https://theoxygenplan.com/companies-combat-mental-illness-mobile-apps
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Узнать больше – https://www.sofiadovale.com/2018/05/30/a-beautiful-sunday-morning
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Исследовать вопрос подробнее – https://mcx.center/davinci-resolve-community
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Ознакомиться с деталями – https://www.thomas-a.com/1000-700_citrus_flaade
На diabloshop.ru вы можете купить https://diabloshop.ru/product-category/diablo-2-ressurected/ золото Diablo 4, руны Diablo 2 Resurrected, а также уникальные предметы и легендарное снаряжение для всех платформ — PC, Xbox, PlayStation и Nintendo Switch. Мы предлагаем быстрый буст персонажа, услуги прокачки, сбор лучших билдов и готовые комплекты снаряжения.
Играешь в Fallout 76? Хочешь силовая броня Fallout 76? Широкий ассортимент предметов, включая силовую броню, легендарное оружие, хлам, схемы и многое другое для Fallout 76 на PC, Xbox и PlayStation. Мы предлагаем услуги буста, прокачки персонажа и готовые комплекты снаряжения.
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]нарколог вывод из запоя в екатеринбурге[/url]
Παίξτε στο συναρπαστικό ιστοσελίδα Nomini με ελληνική υποστήριξη.
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее можно узнать тут – https://www.agriturismofinaleligure.it/2022/01/20/improve-him-believe-opinion-offered
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Получить больше информации – https://sykkelsor.no/img_3419-jpg
После поступления звонка врач клиники «Импульс» незамедлительно отправляется на указанный адрес для оказания срочной помощи. Вызов врача на дом включает следующие этапы:
Изучить вопрос глубже – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом в нижний новгороде[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Подробнее тут – http://livelearnventure.com/isla-mujeres-snorkeling
Функция
Ознакомиться с деталями – http://snyatie-lomki-nnovgorod8.ru
экскурсии в калининграде https://ehkskursii-v-kaliningrade.ru
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Выяснить больше – https://narcolog-na-dom-nnovgorod8.ru/zapoj-narkolog-na-dom-v-nnovgorode
Тик ток мод Новый Тик Ток: Что Изменилось и Чего Ожидать? Анализ последних обновлений официального приложения.
[url=https://banda-casino-apk.ru]banda-casino-apk.ru[/url]
Всем привет!
Нашёл для вас кое-что интересное, особенно для тех, кто фанатеет от казино banda. По ссылке можно узнать все подробности о том, как скачать это казино.
В статье, скорее всего, расскажут о способах скачивания для разных устройств, особенностях установки и, возможно, о бонусах, которые можно получить после установки.
banda-casino-apk.ru
Ломка – это острый синдром отмены, возникающий при резком прекращении или снижении дозы алкоголя или других психоактивных веществ у хронически зависимых пациентов. Это состояние характеризуется выраженной физической и психической дискомфортностью, которая может сопровождаться сильными болевыми ощущениями, тревожностью, дрожью, потливостью, галлюцинациями и нарушениями сна. В критический момент ломка может привести к серьезным осложнениям, поэтому экстренная помощь нарколога имеет первостепенное значение для стабилизации состояния пациента и быстрого снятия симптомов.
Подробнее – https://snyatie-lomki-ekb8.ru
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок новосибирск.[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Подробнее можно узнать тут – [url=https://snyatie-lomki-novosibirsk8.ru/]https://snyatie-lomki-novosibirsk8.ru/[/url]
Функция
Получить дополнительные сведения – http://snyatie-lomki-nnovgorod8.ru/
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]vrach-narkolog-na-dom nizhnij novgorod[/url]
Врачи клиники «Импульс» используют комплексный подход, основанный на проверенных методиках и эффективных препаратах. Основные группы медикаментов, используемых при лечении на дому, представлены в таблице:
Подробнее – [url=https://narcolog-na-dom-nnovgorod8.ru/]нарколог на дом недорого в нижний новгороде[/url]
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Подробнее тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому недорого новосибирск[/url]
Discover Uma North’s exclusive videos now!. Best XXX with Comatozze is here. Uma North turns fantasy into reality. NSFW with taste: meet Uma North. One link — endless Comatozze pleasure. Breathtaking looks, even hotter videos. This Telegram changes the game for fans. From subtle tease to explicit — all in one. Onlyfans queen — Uma North uncensored [url=https://t.me/Comatozzeofficial]t.me/Comatozzeofficial[/url].
seo продвижение и раскрутка сайта [url=http://www.prodvizhenie-sajtov-v-moskve231.ru]http://www.prodvizhenie-sajtov-v-moskve231.ru[/url] .
Rent a car Belgrade Rent a car Belgrade: Просто и удобно Забронировать автомобиль можно онлайн на нашем сайте или связавшись с нами по телефону. Мы предлагаем удобные варианты получения и возврата автомобиля, в том числе в аэропорту Белграда.
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Получить дополнительную информацию – [url=https://snyatie-lomki-novosibirsk8.ru/]https://snyatie-lomki-novosibirsk8.ru[/url]
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Углубиться в тему – [url=https://snyatie-lomki-podolsk1.ru/]ломка от наркотиков в подольске[/url]
buy tiktok ads https://tiktok-ads-account-for-sale.org
Функция
Детальнее – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки на дому недорого[/url]
Группа препаратов
Получить больше информации – [url=https://snyatie-lomki-nnovgorod8.ru/]ломка от наркотиков[/url]
Если наблюдаются вышеописанные симптомы, немедленное обращение к наркологу позволяет не только устранить острые проявления, но и предотвратить возможное развитие опасных для жизни осложнений, таких как сердечно-сосудистые сбои или нарушения работы центральной нервной системы.
Выяснить больше – https://snyatie-lomki-ekb8.ru
tiktok ad accounts https://tiktok-agency-account-for-sale.org
buy tiktok ads account https://buy-tiktok-ad-account.org
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить больше информации – http://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-cena-v-ekb/
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя цена екатеринбург[/url]
технического аудита сайта [url=prodvizhenie-sajtov-v-moskve231.ru]prodvizhenie-sajtov-v-moskve231.ru[/url] .
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломок на дому[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Детальнее – [url=https://snyatie-lomki-podolsk1.ru/]ломка от наркотиков город[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Получить дополнительную информацию – http://snyatie-lomki-podolsk1.ru/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Ознакомиться с деталями – http://snyatie-lomki-podolsk1.ru/
мостбет uz Mostbet ro’yxatdan o’tish – быстрая и простая регистрация откроет вам доступ ко всем возможностям платформы. Most bet – делайте ставки и получайте удовольствие от игры. Mosbet uz, мостбет uz – ваш надежный партнер в мире азартных игр.
Детоксикационные растворы (физиологический раствор, глюкоза, раствор Рингера)
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя круглосуточно екатеринбург[/url]
Hello, this weekend is nice for me, as this time i am reading this enormous educational post here at my house.
child porn
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Получить больше информации – [url=https://snyatie-lomki-ekb8.ru/]снятие наркологической ломки екатеринбург[/url]
Наркологическая клиника «Эдельвейс» в Екатеринбурге специализируется на оказании оперативной и квалифицированной помощи при снятии ломки. Наши специалисты обладают многолетним опытом работы и применяют современные методики для безопасного и эффективного лечения абстинентного синдрома. Мы работаем круглосуточно, что позволяет оказывать помощь в любое время суток, обеспечивая анонимность и конфиденциальность каждого пациента.
Узнать больше – [url=https://snyatie-lomki-ekb8.ru/]снятие ломки в стационаре[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снять ломку[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Углубиться в тему – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки в стационаре[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya ekaterinburg[/url]
buy tiktok business account buy tiktok ads accounts
При наличии этих симптомов организм находится в критическом состоянии, и любой промедление с вызовом врача может привести к развитию серьезных осложнений, таких как сердечно-сосудистые нарушения, тяжелые неврологические симптомы или даже жизнеугрожающие состояния. Экстренное вмешательство позволяет не только снять острые симптомы ломки, но и предотвратить необратимые изменения в организме.
Ознакомиться с деталями – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломок на дому новосибирск[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Детальнее – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-na-domu-v-podolske/
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Изучить вопрос глубже – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркология вывод из запоя в екатеринбурге[/url]
Осложнения, к которым может привести отсутствие лечения:
Разобраться лучше – [url=https://snyatie-lomki-podolsk1.ru/]snyat lomku podol’sk[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekb8.ru/]vyvod-iz-zapoya-klinika ekaterinburg[/url]
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Получить дополнительные сведения – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-na-domu-v-ekb/
Срочный вызов врача на дом необходим при появлении следующих симптомов:
Подробнее можно узнать тут – [url=https://narcolog-na-dom-nnovgorod8.ru/]narkolog-na-dom nizhnij novgorod[/url]
Группа препаратов
Детальнее – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Исследовать вопрос подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркологической ломки в подольске[/url]
– Судорожный синдром, дыхательная недостаточность – Острые панические атаки и психозы – Инфаркт, инсульт, аритмия – Дегидратация и почечная недостаточность – Суицидальные мысли, агрессия, саморазрушение
Выяснить больше – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломок на дому подольск[/url]
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-ekb8.ru/
Клиника «НаркоМед Плюс» использует комплексный подход для эффективного снятия симптомов ломки с применением современных методов детоксикации и поддержки организма. Основные группы препаратов включают:
Разобраться лучше – [url=https://snyatie-lomki-nnovgorod8.ru/]снятие ломки наркозависимого нижний новгород[/url]
[url=https://bet-casino-apk.ru]bet-casino-apk.ru[/url]
По ссылке ниже — полезный гайд по игре в казино bet. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
bet-casino-apk.ru
В клинике «Трезвая Жизнь» для эффективного вывода организма из запоя используется комплексный подход, который включает применение различных групп препаратов. Приведенная ниже таблица отражает основные компоненты нашей терапии и их функции:
Детальнее – https://vyvod-iz-zapoya-ekb8.ru/vyvod-iz-zapoya-na-domu-v-ekb/
Назначение и действие
Узнать больше – http://narcolog-na-dom-nnovgorod8.ru
Осложнения, к которым может привести отсутствие лечения:
Ознакомиться с деталями – https://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske
купить пластиковые окна недорого [url=http://02stroika.ru/]купить пластиковые окна недорого[/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje, можете посмотреть на сайте: ремонт холодильников gorenje адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Исследовать вопрос подробнее – https://bodinjonas.se/cropped-jonas-bodin-png
Алкогольный запой представляет собой крайне опасное состояние, когда организм переполнен токсинами, а системы внутреннего контроля практически перестают функционировать должным образом. Наркологическая клиника «Трезвая Жизнь» в Екатеринбурге оказывает экстренную помощь при выводе из запоя, используя передовые методы диагностики, детоксикации и поддерживающую терапию. Наша команда опытных врачей-наркологов готова оказать помощь в любое время суток, обеспечивая оперативное вмешательство и строгую анонимность каждого пациента.
Разобраться лучше – [url=https://vyvod-iz-zapoya-ekb8.ru/]наркологический вывод из запоя в екатеринбурге[/url]
Клиника «Возрождение» применяет комплексный подход к снятию ломки, используя современные детоксикационные методики и проверенные препараты. Приведенная ниже таблица демонстрирует основные группы медикаментов, используемых в терапии, и их назначение:
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]ломка от наркотиков[/url]
Ломка – это тяжелый синдром отмены, возникающий после длительного употребления алкоголя или наркотических веществ. При резком прекращении их приема нервная система и другие органы начинают страдать от недостатка необходимых веществ, что приводит к сильному дискомфорту, психоэмоциональным нарушениям и ухудшению общего состояния организма. В Новосибирске наркологическая клиника «Возрождение» оказывает экстренную помощь при снятии ломки, обеспечивая безопасное, круглосуточное и конфиденциальное лечение под наблюдением опытных специалистов.
Подробнее можно узнать тут – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки на дому новосибирская область[/url]
Для обеспечения максимальной безопасности и эффективности лечения процесс организован в несколько этапов. При обращении пациента наши специалисты проводят первичный осмотр и диагностику, чтобы оценить степень интоксикации и выявить возможные осложнения. Далее назначается детоксикационная терапия, сопровождаемая медикаментозной поддержкой и психологическим консультированием. Основные этапы работы можно описать следующим образом:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekb8.ru/]вывод из запоя екатеринбург[/url]
Процесс лечения включает несколько ключевых этапов, каждый из которых имеет решающее значение для восстановления организма:
Разобраться лучше – [url=https://snyatie-lomki-novosibirsk8.ru/]snyat lomku novosibirsk[/url]
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Подробнее – https://opensourcesecurityblogs.com/discord-wazuh-integration
Симптоматика ломки может варьироваться: от бессонницы, сильной тревожности и раздражительности до выраженных физически болезненных ощущений, таких как мышечные спазмы, судороги, потливость, головокружение и тошнота. В критических ситуациях, когда симптомы достигают остроты, своевременная медицинская помощь становится жизненно необходимой для предотвращения осложнений и стабилизации состояния пациента.
Детальнее – [url=https://snyatie-lomki-novosibirsk8.ru/]снятие ломки[/url]
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Ознакомиться с деталями – https://www.psykologgruppen.se/skilsmassa-depression
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje в москве, можете посмотреть на сайте: ремонт холодильников gorenje адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее можно узнать тут – https://terataiputihglobal.info/2024/07/08/%D0%BB%D1%83%D1%87%D1%88%D0%B8%D0%B5-%D0%BE%D0%BD%D0%BB%D0%B0%D0%B9%D0%BD-%D0%BA%D0%B0%D0%B7%D0%B8%D0%BD%D0%BE-%D0%B0-2024-%D1%80%D0%B5%D0%B9%D1%82%D0%B8%D0%BD%D0%B3-%D1%82%D0%BE%D0%BF-10-%D1%81
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Ознакомиться с деталями – https://golf-course.net/g160004
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Узнать больше – https://wojam.pl/produkt/ac-vaselina-medicinal-22
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Ознакомиться с деталями – https://pjcmediamagnet.com/how-to-create-an-effective-seo-strategy-for-your-e-commerce
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Детальнее – https://geneticsmr.com/2024/03/11/relationship-of-the-accessory-regulator-gene-agr-with-multi-resistance-in-staphylococcus-aureus-strains-isolated-from-hospitals-and-dental-offices
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje, можете посмотреть на сайте: ремонт холодильников gorenje рядом
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Equilibrar rápidamente
Balanceo móvil en campo:
Reparación ágil sin desensamblar
Imagina esto: tu rotor inicia con movimientos anormales, y cada minuto de inactividad genera pérdidas. ¿Desmontar la máquina y esperar días por un taller? Descartado. Con un equipo de equilibrado portátil, solucionas el problema in situ en horas, sin mover la maquinaria.
¿Por qué un equilibrador móvil es como un “herramienta crítica” para máquinas rotativas?
Fácil de transportar y altamente funcional, este dispositivo es el recurso básico en cualquier intervención. Con un poco de práctica, puedes:
✅ Corregir vibraciones antes de que dañen otros componentes.
✅ Evitar paradas prolongadas, manteniendo la producción activa.
✅ Operar en zonas alejadas, ya sea en instalaciones marítimas o centrales solares.
¿Cuándo es ideal el equilibrado rápido?
Siempre que puedas:
– Acceder al rotor (eje, ventilador, turbina, etc.).
– Colocar sensores sin interferencias.
– Ajustar el peso (añadiendo o removiendo masa).
Casos típicos donde conviene usarlo:
La máquina muestra movimientos irregulares o ruidos atípicos.
No hay tiempo para desmontajes (producción crítica).
El equipo es costoso o difícil de detener.
Trabajas en áreas donde no hay asistencia mecánica disponible.
Ventajas clave vs. llamar a un técnico
| Equipo portátil | Servicio externo |
|—————-|——————|
| ✔ Rápida intervención (sin demoras) | ❌ Retrasos por programación y transporte |
| ✔ Monitoreo preventivo (evitas fallas mayores) | ❌ Suele usarse solo cuando hay emergencias |
| ✔ Ahorro a largo plazo (menos desgaste y reparaciones) | ❌ Costos recurrentes por servicios |
¿Qué máquinas se pueden equilibrar?
Cualquier sistema rotativo, como:
– Turbinas de vapor/gas
– Motores industriales
– Ventiladores de alta potencia
– Molinos y trituradoras
– Hélices navales
– Bombas centrífugas
Requisito clave: espacio para instalar sensores y realizar ajustes.
Tecnología que simplifica el proceso
Los equipos modernos incluyen:
Apps intuitivas (guían paso a paso, sin cálculos manuales).
Análisis en tiempo real (gráficos claros de vibraciones).
Durabilidad energética (útiles en ambientes hostiles).
Ejemplo práctico:
Un molino en una mina comenzó a vibrar peligrosamente. Con un equipo portátil, el técnico identificó el problema en menos de media hora. Lo corrigió añadiendo contrapesos y evitó una parada de 3 días.
¿Por qué esta versión es más efectiva?
– Estructura más dinámica: Listas, tablas y negritas mejoran la legibilidad.
– Enfoque práctico: Se añaden ejemplos reales y comparaciones concretas.
– Lenguaje persuasivo: Frases como “recurso vital” o “previenes consecuencias críticas” refuerzan el valor del servicio.
– Detalles técnicos útiles: Se especifican requisitos y tecnologías modernas.
¿Necesitas ajustar el tono (más técnico) o añadir keywords específicas? ¡Aquí estoy para ayudarte! ️
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее – https://validulich.vn/san-xuat-vali-so-luong-lon
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje сервис, можете посмотреть на сайте: ремонт холодильников gorenje
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje, можете посмотреть на сайте: ремонт холодильников gorenje в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
[url=https://1go-casino-apk.ru]1go-casino-apk.ru[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать приложение 1go казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
1go-casino-apk.ru
Discover Pornjourney, a platform where artificial intelligence makes your desires come true. Create your perfect AI heroines, chat in real time, and enjoy personalized content tailored to your tastes. The next level of sex technology is here.
После обращения в клинику «Основа» наш специалист незамедлительно выезжает для оказания экстренной медицинской помощи в Новосибирске. Процесс установки капельницы предусматривает комплексную диагностику и последующее детоксикационное лечение, что позволяет снизить токсическую нагрузку и стабилизировать состояние пациента. Описание процедуры включает следующие этапы:
Получить больше информации – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя цена новосибирская область[/url]
перенаправляется сюда [url=https://http-kra-32-cc.ru/]ссылка на кракен в браузере[/url]
Мы верим, что каждый человек, столкнувшийся с проблемой зависимости, заслуживает шанса на новую жизнь. Наша миссия — предоставить необходимые инструменты и поддержку, чтобы помочь пациентам в их стремлении к здоровой и свободной от зависимостей жизни.
Выяснить больше – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu
Металлические ограждения https://osk-stroi.ru для дома, дачи, промышленных и общественных объектов. Качественные материалы, долговечность, устойчивость к коррозии. Быстрая установка и индивидуальное изготовление под заказ.
Пиломатериалы от производителя https://tsentr-stroy.ru по доступным ценам. В наличии обрезная и необрезная доска, брус, вагонка, доска пола, рейка и другие изделия. Работаем с частными и корпоративными заказами. Качество, доставка, гибкие условия.
Наркологическая клиника “Путь к выздоровлению” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша основная задача — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Получить дополнительную информацию – https://нарко-фильтр.рф/vivod-iz-zapoya-anonimno-v-rostove-na-donu
I’d should check with you here. Which is not something I normally do! I enjoy reading a publish that may make folks think. Additionally, thanks for permitting me to comment!
Comercializamos dispositivos de equilibrado!
Producimos nosotros mismos, produciendo en tres países a la vez: Portugal, Argentina y España.
✨Nuestros equipos son de muy alta calidad y debido a que somos productores directos, nuestros costos superan en competitividad.
Disponemos de distribución global a cualquier país, consulte los detalles técnicos en nuestra página oficial.
El equipo de equilibrio es portátil, ligero, lo que le permite equilibrar cualquier rotor en diversos entornos laborales.
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Детальнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя клиника архангельск[/url]
сайт [url=https://http-kra-32-cc.ru]кракен ссылка маркет[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому московская область[/url]
Алкогольный запой – это критическое состояние, возникающее при длительном злоупотреблении спиртными напитками, когда организм насыщается токсинами и его жизненно важные системы (сердечно-сосудистая, печёночная, нервная) начинают давать сбой. В такой ситуации необходимо незамедлительное вмешательство специалистов для предотвращения тяжелых осложнений и спасения жизни. Наркологическая клиника «Основа» в Новосибирске предоставляет экстренную помощь с помощью установки капельницы от запоя, позволяющей оперативно вывести токсины из организма, стабилизировать внутренние процессы и создать условия для последующего качественного восстановления.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]капельница от запоя вызов в новосибирске[/url]
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Получить больше информации – https://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
The cycle of anxiety and dysfunction often breaks with the predictability of buy online viagra. Make secure international payments and enjoy freedom.
Инвестиции в строительство https://permgragdanstroy.ru жилой и коммерческой недвижимости. Прибыльные проекты, прозрачные условия, сопровождение на всех этапах. Участвуйте в строительстве с гарантированной доходностью.
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Ознакомиться с деталями – [url=https://narko-zakodirovan2.ru/]вывод из запоя капельница в новосибирске[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje, можете посмотреть на сайте: ремонт холодильников gorenje сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Выяснить больше – http://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-czena-arkhangelsk/
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Выяснить больше – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому цена в подольске[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали срочный ремонт холодильников gorenje, можете посмотреть на сайте: ремонт холодильников gorenje цены
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки наркозависимого[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje цены, можете посмотреть на сайте: ремонт холодильников gorenje адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Капельница от запоя – эффективный метод экстренной детоксикации, который используется при тяжелых формах алкогольной интоксикации. Он позволяет быстро восстановить водно-электролитный баланс, нормализовать работу внутренних органов и снизить токсическую нагрузку. В клинике «Основа» мы гарантируем круглосуточное оказание медицинской помощи, индивидуальный подход к каждому пациенту и полную конфиденциальность. В условиях необходимости экстренного лечения наши специалисты оперативно выезжают в любую точку Новосибирска, обеспечивая комфортное проведение всех процедур как в стационаре, так и на дому.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-novosibirsk8.ru/]postavit-kapelniczu-ot-zapoya novosibirsk[/url]
tiktok agency account for sale https://buy-tiktok-business-account.org
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]snyatie lomok podol’sk[/url]
tiktok ads account for sale https://buy-tiktok-ads.org
Наркологическая клиника “Маяк надежды” расположена по адресу: г. Санкт-Петербург, ул. Колпинская, д. 27. Клиника работает ежедневно с 9:00 до 21:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Детальнее – https://алко-лечение24.рф/vivod-iz-zapoya-v-stacionare-v-Sankt-Peterburge/
Регистрация бизнес в Грузии — бизнес-решение путь к ВНЖ. Минимальные вложения, выгодные налоги (до 1% прибыли|низкая налоговая ставка). Регистрация под ключ за 3 дня: сопровождение на всех этапах, открытие счета, консультации. ВНЖ без покупки недвижимости — условие — регистрация компании. Перспективы для вашего проекта. Начните с Грузии — шаг к международному успеху.
Профессиональная помощь при запое необходима, если:
Изучить вопрос глубже – [url=https://narko-zakodirovan.ru/]вывод из запоя цена ленинградская область[/url]
Агентство недвижимости https://assa-dom.ru покупка, продажа, аренда квартир, домов, участков и коммерческих объектов. Полное сопровождение сделок, помощь с ипотекой, юридическая поддержка. Надежно, удобно, профессионально.
Недвижимость Черноземья https://nedvizhimostchernozemya.ru квартиры, дома, участки, коммерческие объекты. Продажа и аренда во всех крупных городах региона. Надежные застройщики, проверенные предложения, прозрачные сделки.
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому недорого[/url]
Врач может приехать в течение 1–2 часов после обращения. В стационар возможна экстренная госпитализация в тот же день.
Узнать больше – [url=https://narko-zakodirovan2.ru/]срочный вывод из запоя в новосибирске[/url]
Врачебный состав клиники “Путь к выздоровлению” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Подробнее тут – http://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
tiktok ads agency account https://tiktok-ads-agency-account.org
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-czena-arkhangelsk/
Метод капельничного лечения от запоя обладает рядом существенных преимуществ, благодаря которым пациенты получают качественную и оперативную помощь:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя на дому в архангельске[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Узнать больше – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Получить дополнительную информацию – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому[/url]
Врачебный состав клиники “Маяк надежды” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Узнать больше – https://алко-лечение24.рф/vivod-iz-zapoya-na-domu-v-Sankt-Peterburge/
[url=https://arkada-casino-apk.ru]arkada-casino-apk.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино arkada на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
arkada-casino-apk.ru
В стационаре работают узкопрофильные специалисты: наркологи, неврологи, психотерапевты, а также персонал, обеспечивающий круглосуточный уход. Программа включает медикаментозное лечение, психологическую коррекцию, восстановление сна, устранение депрессии, обучение саморегуляции и работу с мотивацией.
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]наркологическая помощь московская область[/url]
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Выяснить больше – https://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Получить дополнительную информацию – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки в стационаре[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje цены, можете посмотреть на сайте: ремонт холодильников gorenje в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Разобраться лучше – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-na-domu-murmansk//
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому недорого подольск[/url]
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Получить дополнительную информацию – http://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb/
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje сервис, можете посмотреть на сайте: ремонт холодильников gorenje в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
посетить веб-сайт [url=https://http-kra-32-cc.ru/]kra33 at[/url]
Врачебный состав клиники “Маяк надежды” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Подробнее можно узнать тут – https://алко-лечение24.рф/vivod-iz-zapoya-cena-v-Sankt-Peterburge/
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje адреса, можете посмотреть на сайте: ремонт холодильников gorenje
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Решение обратиться к врачу должно быть принято, если:
Получить дополнительные сведения – http://narko-zakodirovan2.ru/vyvod-iz-zapoya-czena-novosibirsk/
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Ознакомиться с деталями – http://narko-zakodirovan2.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk/
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]www.domen.ru[/url]
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Узнать больше – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu/
https://tonersklad.ru
натяжной потолок цена за м2 [url=http://potolkilipetsk.ru/]натяжной потолок цена за м2[/url] .
Одной из самых сильных сторон нашей клиники является оперативность. Мы понимаем, что при алкоголизме, наркомании и лекарственной зависимости часто требуются немедленные действия. Если человек находится в состоянии запоя, абстиненции или передозировки, промедление может привести к тяжёлым осложнениям или даже смерти.
Подробнее тут – [url=https://narkologicheskaya-pomoshch-balashiha1.ru/]narkologicheskaya pomoshch na domu balashiha[/url]
Зависимость — это системная проблема, которая требует последовательного и профессионального подхода. Обычные попытки «вылечиться дома» без медицинского сопровождения нередко заканчиваются срывами, ухудшением состояния и психологической деградацией. Клиника «Здоровье Плюс» в Балашихе предоставляет пациентам не просто разовое вмешательство, а выстроенную поэтапную программу, основанную на опыте и медицинских стандартах.
Разобраться лучше – https://narkologicheskaya-pomoshch-balashiha1.ru/skoraya-narkologicheskaya-pomoshch-v-balashihe/
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Углубиться в тему – [url=https://vyvod-iz-zapoya-murmansk0.ru/]нарколог вывод из запоя мурманск[/url]
Врачебный состав клиники “Маяк надежды” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Ознакомиться с деталями – http://алко-лечение24.рф
Продолжение [url=https://kra—33.at]kra33 at[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальные обменные процессы и стабилизировать работу жизненно важных органов, таких как печень, почки и сердце.
Углубиться в тему – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk
Абстинентный синдром — одно из самых тяжёлых и опасных проявлений наркотической зависимости. Он развивается на фоне резкого отказа от приёма веществ и сопровождается сильнейшими нарушениями работы организма. Это состояние требует немедленного вмешательства. Самостоятельно справиться с ним невозможно — особенно если речь идёт о героине, метадоне, синтетических наркотиках или длительной зависимости. В клинике «НаркоПрофи» мы организовали систему снятия ломки в Подольске, работающую круглосуточно: как на дому, так и в условиях стационара.
Подробнее тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркотической ломки подольск[/url]
Врачебный состав клиники “Маяк надежды” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Подробнее – https://алко-лечение24.рф/vivod-iz-zapoya-cena-v-Sankt-Peterburge/
Профессиональная помощь при запое необходима, если:
Подробнее тут – http://
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]kapelnica-ot-zapoya-arkhangelsk0.ru/[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Получить дополнительную информацию – http://snyatie-lomki-podolsk1.ru/snyatie-lomki-narkolog-v-podolske/
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Детальнее – https://www.hattiesburgms.com/casey-sims
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Исследовать вопрос подробнее – [url=https://narko-zakodirovan.ru/]вывод из запоя[/url]
La máquina de equilibrado Balanset-1A constituye el logro de años de trabajo duro y dedicación.
Como desarrolladores de esta tecnología avanzada, nos sentimos satisfechos de cada modelo que se distribuye de nuestras plantas industriales.
No se trata únicamente de un bien, sino además una herramienta que hemos optimizado para solucionar desafíos importantes relacionados con oscilaciones en equipos giratorios.
Sabemos lo frustrante que puede ser enfrentar averías imprevistas y gastos elevados.
Por este motivo desarrollamos Balanset 1A centrándonos en los requerimientos prácticos de los profesionales del sector. ❤️
Distribuimos Balanset-1A directamente desde nuestras sedes en Argentina , España y Portugal , asegurando entregas rápidas y eficientes a cualquier parte del mundo.
Los colaboradores en cada zona están siempre disponibles para ofrecer asistencia técnica individualizada y asesoramiento en su idioma.
¡No somos solo una empresa, sino un grupo humano que está aquí para asistirte!
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Подробнее можно узнать тут – https://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Подробнее тут – https://tokai-international.jp/%E5%B0%8F%E3%81%95%E3%81%AA%E3%81%8A%E8%91%AC%E5%BC%8F-%E5%A4%A7%E9%98%AA%E5%A4%A7%E6%AD%A3%E3%83%9B%E3%83%BC%E3%83%AB%E3%81%AE%E8%A9%95%E5%88%A4%E3%81%AF%E8%89%AF%E3%81%84%E6%82%AA%E3%81%84%EF%BC%9F
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Ознакомиться с деталями – https://www.ashfield-hub.com/sample-page
php laravel сайт услуга разработки сайта
шильды из латуни срочное изготовление шильдиков в москве
металлические бейджи с гравировкой сделать металлический бейдж
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Разобраться лучше – https://www.manabangarutelangana.in/ap-development-vision-2030
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Подробнее – https://fiona-limar.de/der-zehnte-schwedenthriller-und-ein-gewinnspiel
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Исследовать вопрос подробнее – https://jeskesenzoe.nl/hallo-wereld
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Узнать больше – https://blogs.lavanguardia.com/apuntes-pie-pagina/2019/02/17/viaje-al-pasado-41245
https://l-spb.ru
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Углубиться в тему – https://www.popuppenzance.co.uk/uncategorized/empty-shop-host-blues-fever-dance-classes/comment-page-1
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Детальнее – https://www.parcheggiopinguino.it/afternoon-tapas
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Получить дополнительные сведения – http://meongroup.co.uk/hampshire19-1200×826
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Выяснить больше – https://perfectmusictoday.com/index.php/2020/06/17/dions-blues-with-friends-is-1-on-billboard-itunes-and-in-the-uk
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить дополнительную информацию – https://blighthouse.studio/tippex-in-the-book-of-grudges
Equilibrio in situ
El Balanceo de Componentes: Elemento Clave para un Desempeño Óptimo
¿ En algún momento te has dado cuenta de movimientos irregulares en una máquina? ¿O tal vez escuchaste ruidos anómalos? Muchas veces, el problema está en algo tan básico como un desequilibrio en alguna pieza rotativa . Y créeme, ignorarlo puede costarte caro .
El equilibrado de piezas es un procedimiento clave en la producción y cuidado de equipos industriales como ejes, volantes, rotores y partes de motores eléctricos . Su objetivo es claro: evitar vibraciones innecesarias que pueden causar daños serios a largo plazo .
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene una rueda desequilibrada . Al acelerar, empiezan los temblores, el manubrio se mueve y hasta puede aparecer cierta molestia al manejar . En maquinaria industrial ocurre algo similar, pero con consecuencias aún peores :
Aumento del desgaste en soportes y baleros
Sobrecalentamiento de partes críticas
Riesgo de colapsos inesperados
Paradas sin programar seguidas de gastos elevados
En resumen: si no se corrige a tiempo, una leve irregularidad puede transformarse en un problema grave .
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Ideal para piezas que giran a alta velocidad, como rotores o ejes . Se realiza en máquinas especializadas que detectan el desequilibrio en varios niveles simultáneos. Es el método más exacto para asegurar un movimiento uniforme .
Equilibrado estático
Se usa principalmente en piezas como neumáticos, discos o volantes de inercia. Aquí solo se corrige el peso excesivo en un plano . Es ágil, práctico y efectivo para determinados sistemas.
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se elimina material en la zona más pesada
Colocación de contrapesos: por ejemplo, en llantas o aros de volantes
Ajuste de masas: típico en bielas y elementos estratégicos
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones disponibles y altamente productivas, por ejemplo :
✅ Balanset-1A — Tu asistente móvil para analizar y corregir oscilaciones
этот контент [url=https://kra—33.at]кракен даркнет[/url]
сайт [url=https://kra—33.at]kra33.at[/url]
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Получить дополнительные сведения – [url=https://narko-zakodirovan.ru/]вывод из запоя цена санкт-петербург.[/url]
Профессиональная помощь при запое необходима, если:
Подробнее тут – https://narko-zakodirovan.ru
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Узнать больше – http://epal.com.my/mesin-janome-kursus-jahitan-kreatif-diy/dscf2388
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Разобраться лучше – [url=https://narko-zakodirovan.ru/]www.domen.ru[/url]
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена химки[/url]
В Воронеже решение есть — наркологическая клиника «Трезвый шаг». Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Получить больше информации – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя капельница[/url]
экскурсия саратов Саратов – город с богатой историей и культурой, раскинувшийся на живописных берегах Волги. Этот волжский край манит туристов своим неповторимым колоритом, архитектурным наследием и удивительными природными ландшафтами. Если вы планируете посетить Саратов, будьте уверены – вас ждет незабываемое путешествие, полное открытий и ярких впечатлений.
Профессиональная помощь при запое необходима, если:
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]вывод из запоя в стационаре санкт-петербург[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому химки.[/url]
Профессиональная помощь при запое необходима, если:
Подробнее можно узнать тут – [url=https://narko-zakodirovan.ru/]вывод из запоя цена ленинградская область[/url]
Solución rápida de equilibrio:
Respuesta inmediata sin mover equipos
Imagina esto: tu rotor inicia con movimientos anormales, y cada minuto de inactividad genera pérdidas. ¿Desmontar la máquina y esperar días por un taller? Olvídalo. Con un equipo de equilibrado portátil, solucionas el problema in situ en horas, sin alterar su posición.
¿Por qué un equilibrador móvil es como un “kit de supervivencia” para máquinas rotativas?
Compacto, adaptable y potente, este dispositivo es una pieza clave en el arsenal del ingeniero. Con un poco de práctica, puedes:
✅ Prevenir averías mayores al detectar desbalances.
✅ Evitar paradas prolongadas, manteniendo la producción activa.
✅ Actuar incluso en sitios de difícil acceso.
¿Cuándo es ideal el equilibrado rápido?
Siempre que puedas:
– Acceder al rotor (eje, ventilador, turbina, etc.).
– Ubicar dispositivos de medición sin inconvenientes.
– Realizar ajustes de balance mediante cambios de carga.
Casos típicos donde conviene usarlo:
La máquina presenta anomalías auditivas o cinéticas.
No hay tiempo para desmontajes (operación prioritaria).
El equipo es costoso o difícil de detener.
Trabajas en áreas donde no hay asistencia mecánica disponible.
Ventajas clave vs. llamar a un técnico
| Equipo portátil | Servicio externo |
|—————-|——————|
| ✔ Sin esperas (acción inmediata) | ❌ Retrasos por programación y transporte |
| ✔ Mantenimiento proactivo (previenes daños serios) | ❌ Solo se recurre ante fallos graves |
| ✔ Ahorro a largo plazo (menos desgaste y reparaciones) | ❌ Costos recurrentes por servicios |
¿Qué máquinas se pueden equilibrar?
Cualquier sistema rotativo, como:
– Turbinas de vapor/gas
– Motores industriales
– Ventiladores de alta potencia
– Molinos y trituradoras
– Hélices navales
– Bombas centrífugas
Requisito clave: hábitat adecuado para trabajar con precisión.
Tecnología que simplifica el proceso
Los equipos modernos incluyen:
Software fácil de usar (con instrucciones visuales y automatizadas).
Diagnóstico instantáneo (visualización precisa de datos).
Durabilidad energética (útiles en ambientes hostiles).
Ejemplo práctico:
Un molino en una mina comenzó a vibrar peligrosamente. Con un equipo portátil, el técnico localizó el error rápidamente. Lo corrigió añadiendo contrapesos y evitó una parada de 3 días.
¿Por qué esta versión es más efectiva?
– Estructura más dinámica: Listas, tablas y negritas mejoran la legibilidad.
– Enfoque práctico: Se añaden ejemplos reales y comparaciones concretas.
– Lenguaje persuasivo: Frases como “recurso vital” o “previenes consecuencias críticas” refuerzan el valor del servicio.
– Detalles técnicos útiles: Se especifican requisitos y tecnologías modernas.
¿Necesitas ajustar el tono (más instructivo) o añadir keywords específicas? ¡Aquí estoy para ayudarte! ️
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Углубиться в тему – http://нарко-фильтр.рф
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Разобраться лучше – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
Самостоятельно выйти из запоя — почти невозможно. В Воронеже врачи клиники «Трезвый шаг» проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя анонимно[/url]
Преимущества вывода из запоя от опытных специалистов в условиях Донецка ДНР многочисленны. Такой формат лечения позволяет:
Углубиться в тему – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя клиника в донецке[/url]
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Получить больше информации – [url=https://narko-zakodirovan.ru/]vyvod-iz-zapoya-czena sankt-peterburg[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому московская область[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]chastnaya narkologicheskaya klinika mytischi[/url]
дорогие натяжные потолки [url=https://potolkilipetsk.ru/]дорогие натяжные потолки[/url] .
Профессиональная помощь при запое необходима, если:
Узнать больше – https://narko-zakodirovan.ru/vyvod-iz-zapoya-na-domu-spb
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Получить дополнительную информацию – http://narcolog-na-dom-kaliningrad00.ru/vrach-narkolog-na-dom-kaliningrad/
Профессиональная помощь при запое необходима, если:
Разобраться лучше – [url=https://narko-zakodirovan.ru/]нарколог вывод из запоя санкт-петербург[/url]
Взять займ на карту без отказа займ на карту без отказа
Хочу взять займ на карту быстрый займ онлайн на карту
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому республика бурятия[/url]
Официальный сайт микрозаймов взять кредит в мфо
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Изучить вопрос глубже – http://алко-избавление.рф
Выезд врача на дом позволяет провести детоксикацию в спокойной обстановке. Врач привозит с собой препараты, капельницы, измерительное оборудование и проводит лечение в течение 1–2 часов. Такой формат подходит при стабильном состоянии и желании сохранить анонимность.
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]вывод из запоя клиника санкт-петербург[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники «Трезвый шаг» в Воронеже проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Получить больше информации – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники «Трезвый шаг» в Воронеже проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Детальнее – [url=https://vyvod-iz-zapoya-voronezh11.ru/]наркология вывод из запоя[/url]
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Детальнее – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
Профессиональная помощь при запое необходима, если:
Ознакомиться с деталями – [url=https://narko-zakodirovan.ru/]срочный вывод из запоя в санкт-петербурге[/url]
Процедура детоксикации может проводиться двумя способами: выездом врача на дом или госпитализацией. Окончательное решение принимает нарколог после оценки состояния пациента. На ранней стадии запоя достаточно домашней терапии, но при наличии рисков рекомендуется стационар.
Детальнее – https://narko-zakodirovan.ru/vyvod-iz-zapoya-czena-spb
Профессиональный вывод из запоя – это комплексная медицинская услуга, направленная на безопасное и оперативное лечение пациентов, столкнувшихся с алкогольной интоксикацией. В Донецке ДНР высококвалифицированные наркологи оказывают помощь на дому, что позволяет начать детоксикацию организма в комфортной и привычной обстановке. Такой подход обеспечивает индивидуальную терапию, всестороннюю поддержку и полную конфиденциальность, что особенно важно для тех, кто предпочитает получать лечение вне стационаров.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому[/url]
раскрутка сайтов цена seo продвижение россия
Врачебный состав клиники “Путь к выздоровлению” состоит из высококвалифицированных специалистов в области наркологии. Наши врачи-наркологи имеют обширный опыт работы с зависимыми пациентами и постоянно совершенствуют свои навыки.
Разобраться лучше – https://нарко-фильтр.рф/vivod-iz-zapoya-cena-v-rostove-na-donu/
шильды корпоративные металлический шильдик на заказ
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Подробнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм[/url]
шильды изготовление изготовление металлических шильдов москва
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Подробнее тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]chastnaya narkologicheskaya klinika mytischi[/url]
Каждый врач клиники обладает глубокими знаниями в области фармакологии, психофармакологии и психотерапии. Они регулярно посещают профессиональные конференции, семинары и мастер-классы, чтобы быть в курсе последних достижений в лечении зависимостей. Такой подход позволяет нашим специалистам применять наиболее эффективные и научно обоснованные методы терапии.
Подробнее можно узнать тут – http://нарко-фильтр.рф/vivod-iz-zapoya-cena-v-rostove-na-donu/
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Изучить вопрос глубже – https://narcolog-na-dom-kaliningrad00.ru/
Лечение вывода из запоя на дому в Улан-Удэ организовано по четко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Получить дополнительную информацию – http://vyvod-iz-zapoya-ulan-ude00.ru/vyvod-iz-zapoya-na-domu-ulan-ude/
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Исследовать вопрос подробнее – https://narcolog-na-dom-kaliningrad00.ru/narkolog-na-dom-czena-kaliningrad
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-himki1.ru/]http://vyvod-iz-zapoya-v-himki1.ru/[/url]
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя в стационаре[/url]
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Подробнее тут – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя анонимно[/url]
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальный обмен веществ и стабилизировать работу внутренних органов. Этот этап играет решающую роль в безопасном выводе из запоя.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-donetsk-dnr00.ru
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Разобраться лучше – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Выезд врача на дом позволяет провести детоксикацию в спокойной обстановке. Врач привозит с собой препараты, капельницы, измерительное оборудование и проводит лечение в течение 1–2 часов. Такой формат подходит при стабильном состоянии и желании сохранить анонимность.
Подробнее – [url=https://narko-zakodirovan.ru/]вывод из запоя цена санкт-петербург.[/url]
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Подробнее тут – [url=https://narko-zakodirovan.ru/]вывод из запоя на дому санкт-петербург[/url]
Процедура детоксикации может проводиться двумя способами: выездом врача на дом или госпитализацией. Окончательное решение принимает нарколог после оценки состояния пациента. На ранней стадии запоя достаточно домашней терапии, но при наличии рисков рекомендуется стационар.
Подробнее можно узнать тут – [url=https://narko-zakodirovan.ru/]вывод из запоя на дому цена в санкт-петербурге[/url]
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Получить больше информации – [url=https://narko-zakodirovan.ru/]вывод из запоя на дому круглосуточно в санкт-петербурге[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-himki1.ru/]http://vyvod-iz-zapoya-v-himki1.ru[/url]
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Разобраться лучше – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Подробнее – https://алко-избавление.рф/narkolog-vyvod-iz-zapoya-msk/
Momi — это бренд, предлагающий качественные товары для мам и малышей. На моми официальный сайт вы найдете широкий ассортимент детских товаров, отвечающих современным стандартам безопасности и комфорта. Покупайте оригинальную продукцию МОМИ онлайн!
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Подробнее – [url=https://narko-zakodirovan.ru/]нарколог вывод из запоя в санкт-петербурге[/url]
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Подробнее тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]бесплатная наркологическая клиника мытищи[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя в стационаре[/url]
Домашнее лечение позволяет снизить психологическое напряжение, поскольку пациент остаётся в привычной обстановке — рядом с близкими и без очередей. Экономия времени достигается за счёт оперативного выезда специалиста без необходимости госпитализации, а затраты на вызов часто оказываются ниже, чем в стационаре. При грамотном подборе медикаментов и круглосуточном контроле со стороны врача риск осложнений сводится к минимуму.
Узнать больше – http://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Углубиться в тему – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Ознакомиться с деталями – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки наркозависимого[/url]
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Узнать больше – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм мытищи.[/url]
Услуга “Нарколог на дом” в Калининграде, Калининградская область, включает комплекс мер, направленных на оперативный вывод из запоя и детоксикацию организма. Сразу после поступления вызова специалист проводит детальный первичный осмотр, измеряет жизненно важные показатели и собирает анамнез, чтобы оценить степень алкогольной интоксикации. На основе полученной информации разрабатывается индивидуальный план терапии, который может включать капельничное введение современных медикаментов, использование инфузионных технологий и оказание психологической поддержки для долгосрочной реабилитации.
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом цена[/url]
Ломка — это не временное недомогание. Это системное разрушение организма, связанное с тем, что он перестаёт получать наркотик, к которому уже привык. Нарушается обмен веществ, функции сердца, печени, почек, теряется контроль над эмоциями и болью. В состоянии абстиненции человек не может спать, есть, адекватно мыслить. Страдает и тело, и психика.
Разобраться лучше – [url=https://snyatie-lomki-podolsk1.ru/]https://snyatie-lomki-podolsk1.ru[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Разобраться лучше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника мытищи.[/url]
Нужен двигатель или акпп? https://motoreuro.ru с гарантией и доставкой по России? Мы предлагаем проверенные агрегаты с пробегом до 100 тыс. км из Японии, Европы и Кореи. Подбор, установка, оформление документов — всё под ключ.
Вывод из запоя обязателен, если:
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в химках[/url]
Наркологическая клиника “Путь к выздоровлению” — специализированное медицинское учреждение, предназначенное для оказания помощи лицам, страдающим от алкогольной и наркотической зависимости. Наша основная задача — предоставить эффективные методы лечения и поддержку, чтобы помочь пациентам преодолеть пагубное пристрастие и вернуть их к здоровой и полноценной жизни.
Получить дополнительные сведения – http://нарко-фильтр.рф/vivod-iz-zapoya-cena-v-rostove-na-donu/
Бесплатная панель управления panel 1Panel сервером с открытым исходным кодом. Удобный интерфейс, поддержка популярных ОС, автоматизация задач, резервное копирование, управление сайтами и базами. Оптимально для вебмастеров и системных администраторов.
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Подробнее тут – [url=https://narko-zakodirovan.ru/]вывод из запоя на дому цена санкт-петербург[/url]
бизнес юрист юрист по арбитражным делам москва
Осложнения, к которым может привести отсутствие лечения:
Исследовать вопрос подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому цена[/url]
Сразу после вызова нарколог прибывает на дом для проведения тщательного осмотра. Специалист измеряет жизненно важные показатели — пульс, артериальное давление и температуру — и собирает подробный анамнез для оценки степени алкогольной интоксикации.
Подробнее тут – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя на дому в улан-удэ[/url]
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Получить больше информации – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом клиника калининград[/url]
При ухудшении состояния, вызванном длительным употреблением алкоголя, оперативное вмешательство может спасти жизнь. В Калининграде, Калининградская область, опытные наркологи выезжают на дом, чтобы оказать профессиональную помощь при алкогольной интоксикации. Такой формат лечения позволяет получить качественную помощь в комфортной и привычной обстановке, сохраняя полную конфиденциальность и минимизируя стресс, связанный с госпитализацией.
Получить дополнительную информацию – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом калининград[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Выяснить больше – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому недорого в подольске[/url]
cloud headless chrome cloud
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Подробнее тут – [url=https://narko-zakodirovan.ru/]вывод из запоя цена санкт-петербург[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее тут – https://vyvod-iz-zapoya-voronezh11.ru/
система автоматизации рабочего процесса автоматизация рабочих процессов
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Получить больше информации – https://нарко-фильтр.рф/vivod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu/
Обращение за помощью нарколога на дому в Улан-Удэ имеет ряд неоспоримых преимуществ, обеспечивающих эффективное лечение:
Подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя анонимно[/url]
бейджики премиальные изготовление бейджей на заказ
Наши наркологи придерживаются принципов уважительного и внимательного отношения к пациентам, создавая атмосферу доверия. Они проводят детальное обследование, выявляют коренные причины зависимости и разрабатывают индивидуальные стратегии лечения. Профессионализм и компетентность врачей являются ключевыми факторами успешного восстановления пациентов.
Получить дополнительную информацию – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu
Профессиональная помощь при запое необходима, если:
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]vyvod-iz-zapoya-klinika sankt-peterburg[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя клиника в улан-удэ[/url]
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена химки.[/url]
натяжной потолок липецк [url=www.potolkilipetsk.ru/]www.potolkilipetsk.ru/[/url] .
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Подробнее тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]www.domen.ru[/url]
производство металлических значков https://znachki-metallicheskie-zakaz.ru
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Выяснить больше – https://алко-избавление.рф/narkolog-vyvod-iz-zapoya-msk
значки металлические на заказ изготовление железных значков
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Ознакомиться с деталями – [url=https://narko-zakodirovan.ru/]срочный вывод из запоя[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Изучить вопрос глубже – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки подольск[/url]
Алкогольный запой требует не просто прекращения приёма спиртного, а комплексной медицинской помощи. В Санкт-Петербурге и Ленинградской области вывод из запоя осуществляется опытными наркологами с применением современных методик детоксикации. В зависимости от состояния пациента лечение может быть организовано как на дому, так и в стационарных условиях. Главная цель — безопасное очищение организма и возвращение к стабильному физическому и психоэмоциональному состоянию.
Ознакомиться с деталями – [url=https://narko-zakodirovan.ru/]narkolog-vyvod-iz-zapoya sankt-peterburg[/url]
Процедура детоксикации может проводиться двумя способами: выездом врача на дом или госпитализацией. Окончательное решение принимает нарколог после оценки состояния пациента. На ранней стадии запоя достаточно домашней терапии, но при наличии рисков рекомендуется стационар.
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]вывод из запоя цена санкт-петербург[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Детальнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом анонимно калининград[/url]
Прививаем любовь к природе с детства! На нашем сайте вы найдете увлекательные игры, викторины и головоломки, посвященные миру животных и растений. Мы предлагаем развивающие материалы для детей всех возрастов, а также советы для родителей и педагогов о том, как организовать познавательные экскурсии на природу и привить детям любовь к [url=https://kedroteka.ru/]окружающей среде[/url]. Сделаем вместе мир зеленее и добрее!
Мебель от производителя по самым [url=https://ecokrovatka-domik.ru/]выгодным ценам[/url]! Наш интернет-магазин предлагает широкий выбор столов, шкафов, кроватей и других предметов мебели напрямую от производителя, без посредников. Это позволяет нам предложить вам самые низкие цены на рынке. Мы гарантируем высокое качество нашей продукции и предлагаем широкий выбор моделей на любой вкус. У нас вы найдете мебель для гостиной, спальни, кухни, детской и офиса. Закажите сейчас и получите бесплатную доставку по городу! Создайте комфорт в своем доме без переплаты.
Библиотека полезных программ для каждого пользователя! [url=https://softisntall.ru/]На нашем сайте[/url] вы найдете всё, что нужно для эффективной работы и комфортного отдыха за компьютером. Скачивайте бесплатно и безопасно AIMP для прослушивания любимой музыки, Microsoft Word для создания и редактирования документов, торрент-клиенты для обмена файлами и WinRAR для архивирования и распаковки архивов. Мы предлагаем только проверенные версии программ, без вирусов и рекламы. Оптимизируйте работу своего компьютера с помощью нашего сайта!
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Разобраться лучше – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/https://алко-избавление.рф
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Выяснить больше – [url=https://narcolog-na-dom-kaliningrad00.ru/]нарколог на дом вывод в калининграде[/url]
кракен33 Кракен. Слово, звучащее как шепот древних морей, как отголосок легенд, рожденных в штормовых ночах. Кракен – не просто имя. Это портал. Вход в мир, где анонимность – щит, а возможности – безграничны. Кракен вход – это цифровой пропуск в лабиринт, где каждый поворот сулит новые открытия, новые риски, новую свободу.
Праздничные дары партиями. Кондитерские новогодние подарки предлагаемые малышей Грядет самый волшебный мероприятие году – Январские торжества. Такое момент, при условии что какой мечтает осчастливить родных замечательными подарками. Огромный ассортимент десертных подборок у изготовителя. Приемлемые тарифы при заказе оптом. Превосходные товары из органических компонентов. Привлекательная обертка с рождественскими мотивами. Праздничные вкусные дары Наши собственные десертные комплекты – данное прекрасное решение предназначенное корпоративных заказчиков и розничных покупателей. Наша фирма предоставляем только свежие изделия от ответственных поставщиков. Совершите оформление зимних сувениров большими объемами у нашу компанию а также обрадуйте персональных знакомых в события! По какой причине стоит подбирать новогодние подарки оптом у производителя? Заказ зимних подарков прямо на производителя предоставляет вашей компании ряд важных достоинств: Существенная снижение расходов финансов – крупные стоимости на новогодние наборы значительно ниже, чем небольшие закупки. Гарантия стандарта – наша компания взаимодействуем исключительно с ответственными партнерами ингредиентов. Разнообразные перспективы персонализации – ваша компания вправе выбрать обертку вместе с логотипом, дополнить рождественские надписи и еще разработать уникальные наборы согласно вашему требованию. Срочная транспортировка в полной стране – наше предприятие работаем наряду с надежными логистическими организациями плюс обеспечиваем оперативную доставку покупок. Как купить зимние подарки оптом? Процесс заказа праздничных презентов через нашей личной фирмы исключительно удобный а также оперативный: Подбирайте подходящий ассортимент через нашем собственном ресурсе или отправляйте заявку в цифровую почту. Наши фирменные консультанты свяжутся со вашим бизнесом с целью проверки подробностей плюс сформируют эксклюзивное коммерческое план. Спустя одобрения целых требований наша компания быстро подготовим а также передадим ваш собственный заказ по отмеченному локации. Спешите совершить приобретение прямо! Число наших зимних подарков регламентируется, а спрос для этих на предновогодний момент растет со очередным сутками. Для того чтобы вовсе не остаться вне необходимых вкусных подборок, заказывайте данные заранее! Напишите вместе с нашими фирменными специалистами через телефону, электронной почтовому ящику и еще посредством анкету ответной коммуникации с помощью ресурсе, плюс наше предприятие вместе с энтузиазмом поможем вашей компании с подбором прекрасных зимних сувениров предназначенных ваших клиентов, родных и еще членов семьи!
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Ознакомиться с деталями – [url=https://narko-zakodirovan.ru/]наркологический вывод из запоя в санкт-петербурге[/url]
Домашнее лечение позволяет снизить психологическое напряжение, поскольку пациент остаётся в привычной обстановке — рядом с близкими и без очередей. Экономия времени достигается за счёт оперативного выезда специалиста без необходимости госпитализации, а затраты на вызов часто оказываются ниже, чем в стационаре. При грамотном подборе медикаментов и круглосуточном контроле со стороны врача риск осложнений сводится к минимуму.
Узнать больше – http://алко-избавление.рф
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Изучить вопрос глубже – http://vyvod-iz-zapoya-ulan-ude00.ru
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя клиника в химках[/url]
Наркологическая клиника “Путь к выздоровлению” расположена по адресу: г. Ростов-на-Дону, ул. Петровская, д. 19. Клиника работает ежедневно с 8:00 до 20:00, без выходных. Наши специалисты готовы предоставить консультацию и ответить на все вопросы, связанные с лечением зависимостей. Мы гарантируем конфиденциальность и индивидуальный подход к каждому пациенту.
Детальнее – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu/
После диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся инфузионным методом, что позволяет оперативно снизить уровень токсинов в крови, восстановить обмен веществ и нормализовать работу внутренних органов, таких как печень, почки и сердце.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]срочный вывод из запоя[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Получить больше информации – [url=https://vyvod-iz-zapoya-voronezh11.ru/]воронеж[/url]
What’s up, its nice piece of writing concerning media print, we all know media is a enormous source of information.
hafilat balance check
установка натяжного потолка липецк [url=www.potolkilipetsk.ru]www.potolkilipetsk.ru[/url] .
Домашнее лечение позволяет снизить психологическое напряжение, поскольку пациент остаётся в привычной обстановке — рядом с близкими и без очередей. Экономия времени достигается за счёт оперативного выезда специалиста без необходимости госпитализации, а затраты на вызов часто оказываются ниже, чем в стационаре. При грамотном подборе медикаментов и круглосуточном контроле со стороны врача риск осложнений сводится к минимуму.
Разобраться лучше – http://алко-избавление.рф
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Получить дополнительную информацию – http://алко-избавление.рф/
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Детальнее – https://нарко-фильтр.рф/vivod-iz-zapoya-anonimno-v-rostove-na-donu
Самолечение или попытка «переждать» запой дома без врача может обернуться серьёзными осложнениями. Обращение к наркологу даёт пациенту:
Изучить вопрос глубже – https://narko-zakodirovan.ru/vyvod-iz-zapoya-kapelnicza-spb
При сравнительно лёгкой или среднетяжёлой степени интоксикации нарколог приезжает на дом, где в знакомой обстановке проводит детоксикацию. Врач измеряет параметры жизнедеятельности — пульс, давление, насыщение кислородом — и подбирает оптимальный состав препаратов для инфузий. Такой метод подходит тем, кто испытывает стресс при мысли о стационаре и нуждается в анонимности лечения.
Ознакомиться с деталями – https://алко-избавление.рф/narkolog-vyvod-iz-zapoya-msk
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Получить дополнительные сведения – [url=https://narko-zakodirovan.ru/]нарколог вывод из запоя[/url]
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]http://narkologicheskaya-klinika-mytishchi1.ru/[/url]
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Детальнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена московская область[/url]
металлические значки под заказ https://izgotovit-znachki-metalicheskie.ru
стоимость seo продвижения контекстная реклама заказать
В стационаре пациент получает круглосуточный контроль, расширенную диагностику и возможность подключения к аппаратуре мониторинга. Это особенно важно при тяжёлой интоксикации, нарушении сознания или судорожной активности.
Детальнее – [url=https://narko-zakodirovan.ru/]www.domen.ru[/url]
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в стационаре в химках[/url]
Профессиональная помощь при запое необходима, если:
Исследовать вопрос подробнее – [url=https://narko-zakodirovan.ru/]вывод из запоя клиника[/url]
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Подробнее можно узнать тут – [url=https://snyatie-lomki-podolsk1.ru/]снятие ломки на дому цена в подольске[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты «Трезвого шага» в Воронеже приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя в стационаре[/url]
Задача врачей — не просто облегчить симптомы, а купировать осложнения, стабилизировать жизненно важные функции, вернуть пациенту способность к дальнейшему лечению. Мы работаем быстро, анонимно и профессионально. Любой человек, оказавшийся в кризисе, может получить помощь в течение часа после обращения.
Подробнее – [url=https://snyatie-lomki-podolsk1.ru/]снятие наркологической ломки подольск[/url]
Процесс начинается с вызова врача или доставки пациента в клинику. После прибытия специалист проводит первичную диагностику: измерение давления, температуры, пульса, уровня кислорода в крови, визуальная оценка степени возбуждения или угнетения сознания. Собирается краткий анамнез: какой наркотик принимался, как долго, были ли сопутствующие заболевания.
Подробнее тут – [url=https://snyatie-lomki-podolsk1.ru/]snyatie lomki narkozavisimogo podol’sk[/url]
Выезд врача на дом позволяет провести детоксикацию в спокойной обстановке. Врач привозит с собой препараты, капельницы, измерительное оборудование и проводит лечение в течение 1–2 часов. Такой формат подходит при стабильном состоянии и желании сохранить анонимность.
Получить дополнительную информацию – [url=https://narko-zakodirovan.ru/]вывод из запоя клиника в санкт-петербурге[/url]
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Получить дополнительную информацию – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Исследовать вопрос подробнее – http://
разработка сайта москва seo оптимизация сайта
Именно поэтому так важно не терять время. Чем раньше пациент получает помощь, тем выше шансы избежать необратимых последствий и вернуться к нормальной жизни.
Получить дополнительные сведения – [url=https://snyatie-lomki-podolsk1.ru/]snyatie lomki na domu podol’sk[/url]
Обращение за помощью нарколога на дому в Калининграде имеет ряд значимых преимуществ:
Ознакомиться с деталями – [url=https://narcolog-na-dom-kaliningrad00.ru/]запой нарколог на дом в калининграде[/url]
Когда зависимость захватывает жизнь, она разрушает не только организм, но и личность, отношения с близкими, карьерные планы и самоощущение. Алкоголь, наркотики и психотропные препараты постепенно подрывают работу внутренних органов, нарушают баланс нейромедиаторов в мозге и приводят к серьёзным психическим и физическим осложнениям. Попытки справиться с этим самостоятельно редко бывают успешными: необходим системный, профессиональный подход. В наркологической клинике «Доктор Здоровье» в Мытищах вы найдёте надёжную опору на всех этапах выздоровления — от экстренной детоксикации до длительной реабилитации.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм в мытищах[/url]
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Подробнее можно узнать тут – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Запой — это длительное бесконтрольное употребление алкоголя, приводящее к серьёзным нарушениям обмена веществ, дезориентации и риску острого алкогольного психоза. В Москве и области помощь при выводе из запоя востребована как в домашних условиях, так и в стационаре. Вне зависимости от выбора методики главная цель — быстрое и безопасное восстановление здоровья, чтобы человек мог начать новую, полноценную жизнь без зависимости.
Детальнее – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
Thanks for the article https://l-spb.ru/
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Подробнее – https://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника цены мытищи[/url]
В столичном регионе доступны два основных формата лечения: выезд специалиста на дом и госпитализация в специализированный центр. Каждый вариант имеет свои особенности и показания, которые врач анализирует при первичном осмотре.
Получить дополнительные сведения – https://алко-избавление.рф/vyvod-iz-zapoya-czena-msk/
Лечение вывода из запоя на дому в Улан-Удэ организовано по четко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Получить больше информации – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя клиника в улан-удэ[/url]
Самостоятельно выйти из запоя — почти невозможно. В Воронеже врачи клиники «Трезвый шаг» проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Выяснить больше – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя на дому[/url]
После диагностики начинается активная фаза медикаментозного вмешательства, когда препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-kaliningrad00.ru/]www.domen.ru[/url]
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Выяснить больше – http://нарко-фильтр.рф/
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника мытищи[/url]
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]https://narkologicheskaya-klinika-mytishchi1.ru/[/url]
ссылка на сайт [url=https://vodkawin.com]vodka премиум онлайн казино[/url]
После диагностики начинается активная фаза медикаментозного вмешательства, когда препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов.
Разобраться лучше – [url=https://narcolog-na-dom-kaliningrad00.ru/]vrach-narkolog-na-dom kaliningrad[/url]
печати типография спб сайт типографии спб
печати типография спб типография полиграфия
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Углубиться в тему – https://vyvod-iz-zapoya-ulan-ude00.ru/narkologiya-vyvod-iz-zapoya-ulan-ude
стоимость типография сайт типографии спб
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Подробнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника на дом[/url]
Kraken зеркало: даркнет, маркетплейс, официальный – https://kraken-mirror-sait.com — проверено!
Показана в тяжёлых случаях или при наличии сопутствующих заболеваний. Лечение проходит под круглосуточным наблюдением врачей и медсестёр с постоянной корректировкой терапии.
Исследовать вопрос подробнее – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику «Трезвый шаг» (Воронеж) — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-voronezh11.ru/]вывод из запоя цена[/url]
Сразу после поступления вызова специалист приезжает на дом для проведения тщательного первичного осмотра. Измеряются такие жизненно важные показатели, как пульс, артериальное давление и температура, а также проводится сбор анамнеза, что позволяет оценить степень алкогольной интоксикации.
Исследовать вопрос подробнее – https://narcolog-na-dom-kaliningrad00.ru/vrach-narkolog-na-dom-kaliningrad/
Лечение нарколога на дому в Калининграде организовано по четко отлаженной схеме, позволяющей максимально оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Детальнее – http://narcolog-na-dom-kaliningrad00.ru
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Выяснить больше – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]vyvod-iz-zapoya-na-domu ulan-ude[/url]
Каждый врач клиники обладает глубокими знаниями в области фармакологии, психофармакологии и психотерапии. Они регулярно посещают профессиональные конференции, семинары и мастер-классы, чтобы быть в курсе последних достижений в лечении зависимостей. Такой подход позволяет нашим специалистам применять наиболее эффективные и научно обоснованные методы терапии.
Получить дополнительные сведения – http://нарко-фильтр.рф/vivod-iz-zapoya-na-domu-v-rostove-na-donu/
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Изучить вопрос глубже – http://narko-zakodirovan2.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk/
Найяскравіший момент стався, коли PJ Ketty виконувала свій ексклюзивний сет. Вона танцювала на сцені так, що здавалось, ніби вона малює своїми рухами в повітрі. Я бачив, як її енергія передавалася залу: люди почали піднімати руки, танцювати, і навіть ті, хто спочатку стояв осторонь, долучилися до загального потоку. Це було справжнє єднання музики і танцю. Як хочеш дізнатися більше? Переглянь інформацію на офіційному ресурсі.
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Детальнее – [url=https://narko-zakodirovan2.ru/]наркологический вывод из запоя новосибирск[/url]
Затяжной запой — это состояние, при котором человек в течение нескольких дней не может прекратить употребление алкоголя без медицинской помощи. Такое состояние чревато тяжёлыми нарушениями в работе внутренних органов и психики. В Новосибирске и Новосибирской области доступен профессиональный вывод из запоя как на дому, так и в условиях стационара. Подход к лечению индивидуален, и основная цель — безопасно и эффективно устранить последствия интоксикации и предотвратить рецидив.
Исследовать вопрос подробнее – http://narko-zakodirovan2.ru
Показана в тяжёлых случаях или при наличии сопутствующих заболеваний. Лечение проходит под круглосуточным наблюдением врачей и медсестёр с постоянной корректировкой терапии.
Разобраться лучше – [url=https://narko-zakodirovan2.ru/]срочный вывод из запоя новосибирск[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных помогает разработать индивидуальный план терапии, направленный на эффективное снижение токсической нагрузки.
Изучить вопрос глубже – http://narcolog-na-dom-kaliningrad00.ru/
Обращение к наркологу позволяет избежать типичных ошибок самолечения и достичь стабильного результата. Квалифицированное вмешательство:
Детальнее – https://narko-zakodirovan2.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk/
этот сайт [url=https://vodkawin.com/]vodka.bet официальный сайт[/url]
СВО: Сквозь призму белых дядей в африканском контексте
Специальная военная операция в Украине, СВО, стала не только геополитическим водоразделом, но и катализатором для переосмысления многих устоявшихся представлений о мировом порядке. В этом контексте, интересно взглянуть на восприятие СВО через призму африканского континента и, в частности, феномена “белых дядей” – исторически сложившейся системы влияния, где выходцы из Европы и Северной Америки занимают доминирующие позиции в политике, экономике и социальной сфере африканских стран.
Новости СВО, поступающие в африканское медиапространство, часто интерпретируются сквозь призму колониального прошлого и неоколониальных реалий. Многие африканцы видят в конфликте в Украине продолжение борьбы за передел сфер влияния между Западом и Россией, где Африка традиционно выступает лишь в роли объекта, а не субъекта.
Белые дяди, как бенефициары существующего порядка, часто поддерживают западную точку зрения на СВО, в то время как рядовые африканцы выражают более разнообразные мнения. Многие из них видят в России противовес западному доминированию и надежду на более справедливый мировой порядок.
Влияние СВО на Африку выходит далеко за рамки политической риторики. Конфликт привел к росту цен на продовольствие и энергоносители, усугубив и без того сложную экономическую ситуацию во многих африканских странах. В этой связи, вопрос о будущем Африки и ее роли в новом мировом порядке становится особенно актуальным. Сможет ли континент вырваться из-под влияния белых дядей и занять достойное место среди мировых держав? Ответ на этот вопрос во многом зависит от исхода СВО и ее долгосрочных последствий для мировой геополитики. Сво
[url=https://desktop.bonus-usdt-wechat.com/]wechat on desktop computer[/url]
[url=https://desktop.bonus-usdt-wechat.com/]wechat desktop video call[/url]
[url=https://desktop.bonus-usdt-wechat.com/]wechat desktop windows[/url]
[url=https://desktop.bonus-usdt-wechat.com/]wechat in desktop[/url]
WeChat
Домашнее лечение позволяет снизить психологическое напряжение, поскольку пациент остаётся в привычной обстановке — рядом с близкими и без очередей. Экономия времени достигается за счёт оперативного выезда специалиста без необходимости госпитализации, а затраты на вызов часто оказываются ниже, чем в стационаре. При грамотном подборе медикаментов и круглосуточном контроле со стороны врача риск осложнений сводится к минимуму.
Изучить вопрос глубже – http://алко-избавление.рф/vyvod-iz-zapoya-na-domu-msk/https://алко-избавление.рф
Услуга вывода из запоя на дому в Улан-Удэ включает комплекс мероприятий, направленных на оперативное снижение токсической нагрузки и возвращение организма в нормальное состояние. Сразу после получения вызова специалист проводит тщательный осмотр, измеряет жизненно важные показатели и собирает подробный анамнез, что позволяет точно определить степень алкогольной интоксикации. На основе этих данных разрабатывается персональный план терапии, который может включать инфузионное введение медикаментов, коррекцию обмена веществ и оказание психологической поддержки.
Подробнее тут – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя в улан-удэ[/url]
Миссия клиники “Путь к выздоровлению” заключается в содействии восстановлению здоровья и социальной реинтеграции людей, столкнувшихся с проблемами зависимости. Мы стремимся к комплексному решению этой сложной задачи, учитывая физические, психологические и социальные аспекты зависимости. Наша цель — не только помочь пациентам избавиться от физической зависимости, но и обеспечить их психологическое восстановление и возвращение к нормальной жизни в обществе.
Получить больше информации – https://нарко-фильтр.рф/vivod-iz-zapoya-v-stacionare-v-rostove-na-donu/
Когда алкогольный запой начинает угрожать здоровью, оперативное лечение становится жизненно необходимым. В Улан-Удэ, Республика Бурятия, высококвалифицированные наркологи оказывают помощь на дому, обеспечивая детоксикацию организма, восстановление нормальных обменных процессов и стабилизацию работы внутренних органов. Такой метод позволяет пациенту получить индивидуализированное лечение в условиях привычного домашнего уюта, что значительно снижает стресс и гарантирует полную конфиденциальность.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]вывод из запоя в стационаре[/url]
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника мытищи[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Подробнее тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника на дом[/url]
В условиях клиники пациент находится под наблюдением медицинской сестры и врача 24/7, что особенно важно при тяжёлой интоксикации и риске острых осложнений. Быстрый доступ к расширенной диагностике — ЭКГ, УЗИ, анализы крови — обеспечивает точную корректировку терапии. Стационар подходит тем, у кого есть серьёзные сопутствующие заболевания или высокий риск алкогольных психозов.
Разобраться лучше – https://алко-избавление.рф
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Углубиться в тему – https://papanizza.fr/ua/hudozhniki-francii
Лечение вывода из запоя на дому в Улан-Удэ организовано по четко отлаженной схеме, которая позволяет оперативно стабилизировать состояние пациента и начать процесс детоксикации.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ulan-ude00.ru/]наркологический вывод из запоя[/url]
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Детальнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм мытищи[/url]
Вывод из запоя может осуществляться в двух форматах — на дому и в стационаре. Выбор зависит от степени интоксикации, наличия осложнений и возможности обеспечить пациенту наблюдение в домашних условиях.
Получить дополнительные сведения – [url=https://narko-zakodirovan2.ru/]вывод из запоя на дому[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить дополнительные сведения – https://telosbrasil.com.br/2017/07/21/textos
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Узнать больше – https://mahoraize.wpxblog.jp/%E8%AA%B2%E9%A1%8C%EF%BD%8E%EF%BD%8F%EF%BC%8E%EF%BC%92%EF%BC%95%EF%BC%93%EF%BC%8D%EF%BC%91
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Углубиться в тему – https://howtoarabic.com/%D8%A5%D8%B2%D8%A7%D9%8A-%D8%AA%D8%AE%D8%B1%D8%AC-%D8%B4%D8%B1%D9%8A%D9%83%D9%83-%D9%85%D9%86-%D8%AD%D8%A7%D9%84%D8%A9-%D8%AD%D8%B2%D9%86
Врач может приехать в течение 1–2 часов после обращения. В стационар возможна экстренная госпитализация в тот же день.
Ознакомиться с деталями – [url=https://narko-zakodirovan2.ru/]наркология вывод из запоя новосибирск[/url]
[url=https://lucky-jet-igrat.com]лаки джет сайт[/url] – lucky jet бот, lucky jet стратегия
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Исследовать вопрос подробнее – https://aobadai-fring.com/archives/2454
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Узнать больше – https://groupeleilaprestige.com/2023/08/09/bonjour-tout-le-monde
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Углубиться в тему – https://obrunosoares.com/ola-mundo
Ищете, где купить двигатель с гарантией и доставкой? Мы предлагаем проверенные агрегаты с пробегом до 100 тыс. км из Японии, Европы и Кореи. Подбор, установка, оформление документов — всё под ключ.
срочная печать визиток типография печать визиток
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Подробнее тут – https://fukkatsu.net/business/bunn
печать визиток быстро типография печать визиток
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее – https://www.agderleague.no/factions/order-of-the-gauntlet
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Подробнее – https://astronomia.com.ar/tethysringshadow_cassini_1019
La Nivelación de Partes Móviles: Esencial para una Operación Sin Vibraciones
¿ Has percibido alguna vez temblores inusuales en un equipo industrial? ¿O sonidos fuera de lo común? Muchas veces, el problema está en algo tan básico como un desequilibrio en alguna pieza rotativa . Y créeme, ignorarlo puede costarte caro .
El equilibrado de piezas es una tarea fundamental tanto en la fabricación como en el mantenimiento de maquinaria agrícola, ejes, volantes, rotores y componentes de motores eléctricos . Su objetivo es claro: impedir oscilaciones que, a la larga, puedan provocar desperfectos graves.
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene un neumático con peso desigual. Al acelerar, empiezan las sacudidas, el timón vibra y resulta incómodo circular así. En maquinaria industrial ocurre algo similar, pero con consecuencias aún peores :
Aumento del desgaste en soportes y baleros
Sobrecalentamiento de partes críticas
Riesgo de fallos mecánicos repentinos
Paradas no planificadas y costosas reparaciones
En resumen: si no se corrige a tiempo, un pequeño desequilibrio puede convertirse en un gran dolor de cabeza .
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Perfecto para elementos que operan a velocidades altas, tales como ejes o rotores . Se realiza en máquinas especializadas que detectan el desequilibrio en múltiples superficies . Es el método más fiable para lograr un desempeño estable.
Equilibrado estático
Se usa principalmente en piezas como neumáticos, discos o volantes de inercia. Aquí solo se corrige el peso excesivo en una única dirección. Es ágil, práctico y efectivo para determinados sistemas.
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se perfora la región con exceso de masa
Colocación de contrapesos: como en ruedas o anillos de volantes
Ajuste de masas: típico en bielas y elementos estratégicos
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones accesibles y muy efectivas, como :
✅ Balanset-1A — Tu aliado portátil para equilibrar y analizar vibraciones
Станки для производства зиговочные станки металлообработка, резка, сварка, автоматизация. Продажа новых и восстановленных моделей от ведущих брендов. Гарантия, обучение персонала, техподдержка.
кайт хургада
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт аренда машины краснодар
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-himki1.ru/]vyvod-iz-zapoya-na-domu himki[/url]
analizador de vibrasiones
Solución rápida de equilibrio:
Respuesta inmediata sin mover equipos
Imagina esto: tu rotor inicia con movimientos anormales, y cada minuto de inactividad afecta la productividad. ¿Desmontar la máquina y esperar días por un taller? Ni pensarlo. Con un equipo de equilibrado portátil, resuelves sobre el terreno en horas, preservando su ubicación.
¿Por qué un equilibrador móvil es como un “paquete esencial” para máquinas rotativas?
Compacto, adaptable y potente, este dispositivo es una pieza clave en el arsenal del ingeniero. Con un poco de práctica, puedes:
✅ Evitar fallos secundarios por vibraciones excesivas.
✅ Evitar paradas prolongadas, manteniendo la producción activa.
✅ Actuar incluso en sitios de difícil acceso.
¿Cuándo es ideal el equilibrado rápido?
Siempre que puedas:
– Tener acceso físico al elemento rotativo.
– Ubicar dispositivos de medición sin inconvenientes.
– Realizar ajustes de balance mediante cambios de carga.
Casos típicos donde conviene usarlo:
La máquina presenta anomalías auditivas o cinéticas.
No hay tiempo para desmontajes (producción crítica).
El equipo es costoso o difícil de detener.
Trabajas en campo abierto o lugares sin talleres cercanos.
Ventajas clave vs. llamar a un técnico
| Equipo portátil | Servicio externo |
|—————-|——————|
| ✔ Rápida intervención (sin demoras) | ❌ Retrasos por programación y transporte |
| ✔ Mantenimiento proactivo (previenes daños serios) | ❌ Solo se recurre ante fallos graves |
| ✔ Ahorro a largo plazo (menos desgaste y reparaciones) | ❌ Costos recurrentes por servicios |
¿Qué máquinas se pueden equilibrar?
Cualquier sistema rotativo, como:
– Turbinas de vapor/gas
– Motores industriales
– Ventiladores de alta potencia
– Molinos y trituradoras
– Hélices navales
– Bombas centrífugas
Requisito clave: hábitat adecuado para trabajar con precisión.
Tecnología que simplifica el proceso
Los equipos modernos incluyen:
Software fácil de usar (con instrucciones visuales y automatizadas).
Evaluación continua (informes gráficos comprensibles).
Durabilidad energética (útiles en ambientes hostiles).
Ejemplo práctico:
Un molino en una mina empezó a generar riesgos estructurales. Con un equipo portátil, el técnico localizó el error rápidamente. Lo corrigió añadiendo contrapesos y impidió una interrupción prolongada.
¿Por qué esta versión es más efectiva?
– Estructura más dinámica: Listas, tablas y negritas mejoran la legibilidad.
– Enfoque práctico: Incluye casos ilustrativos y contrastes útiles.
– Lenguaje persuasivo: Frases como “herramienta estratégica” o “evitas fallas mayores” refuerzan el valor del servicio.
– Detalles técnicos útiles: Se especifican requisitos y tecnologías modernas.
¿Necesitas ajustar el tono (más instructivo) o añadir keywords específicas? ¡Aquí estoy para ayudarte! ️
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]нарколог вывод из запоя[/url]
[url=https://lucky-jet-igrat.com]бот лаки джет[/url] – lucky jet официальный сайт, lucky jet игра
Онлайн сервис скачать svg с сайта онлайн для получения картинок с любого сайта. Вставьте URL — и мгновенно получите изображения на своём устройстве. Поддержка всех форматов, никаких ограничений и лишних действий. Работает бесплатно и круглосуточно.
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Подробнее – http://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa/
Вывод из запоя обязателен, если:
Подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]нарколог вывод из запоя[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Углубиться в тему – http://vyvod-iz-zapoya-v-himki1.ru
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Подробнее можно узнать тут – https://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Подробнее – http://narkologicheskaya-pomoshh-ufa9.ru/skoraya-narkologicheskaya-pomoshh-ufa/
Каждому пациенту назначается персональный план терапии, составленный на основе результатов медицинского и психологического обследования. Мы не используем шаблонные схемы — только индивидуальный подход, адаптированный к возрасту, опыту зависимости, состоянию здоровья и личной мотивации.
Подробнее можно узнать тут – https://narkologicheskaya-klinika-volgograd9.ru/lechenie-v-narkologicheskoj-klinike-volgograd
Помощь нарколога на дому в Мурманске обладает рядом неоспоримых преимуществ, которые делают данный метод лечения особенно актуальным:
Исследовать вопрос подробнее – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk/
Изготовление и печать больших наклеек. Стикеры для бизнеса, сувениров, интерьера и упаковки. Печатаем тиражами от 1 штуки, любые материалы и формы. Качественно, недорого, с доставкой по СПб.
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Узнать больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника нарколог[/url]
Процесс вывода из запоя на дому в Мариуполе построен по четко отлаженной схеме, что позволяет быстро и безопасно восстановить здоровье пациента.
Узнать больше – http://narcolog-na-dom-mariupol0.ru
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Детальнее – http://vyvod-iz-zapoya-murmansk0.ru
Откройте для себя 1winbrazil.neocities.org, где представлены.
Найдите полезную информацию на 1winbrazil.neocities.org, в этом ресурсе.
Погрузитесь в увлекательный мир 1winbrazil.neocities.org, ресурсами.
Проверьте самые актуальные прогнозы на 1winbrazil.neocities.org, не упустить.
На 1winbrazil.neocities.org вы найдете рекомендации, стратегии ставок.
Узнайте больше на 1winbrazil.neocities.org, необходимую информацию.
1winbrazil.neocities.org – открывайте новые горизонты, в сфере спорта.
Повысьте свои шансы на успех с 1winbrazil.neocities.org, вместе с.
Откройте для себя секреты с 1winbrazil.neocities.org, для того чтобы.
Будьте в курсе событий с 1winbrazil.neocities.org, самую свежую информацию.
Научитесь ставить как профи с 1winbrazil.neocities.org, ознакомившись с.
Узнайте все о ставках на 1winbrazil.neocities.org, для того чтобы.
Узнайте, как ставить эффективно на 1winbrazil.neocities.org, для успеха.
Не знаете, с чего начать? 1winbrazil.neocities.org предлагает решения, для всех любителей.
1winbrazil.neocities.org – ваш компас в мире ставок, узнайте о лучших стратегиях.
Откройте для себя мир ставок с 1winbrazil.neocities.org, где.
1win [url=https://1winbrazil.neocities.org/]https://1winbrazil.neocities.org/[/url] .
Лечение алкогольной зависимости на дому в Мурманске проходит по четко отлаженной схеме, которая включает несколько последовательных этапов. Каждый из них имеет решающее значение для безопасного и эффективного восстановления организма.
Подробнее тут – [url=https://vyvod-iz-zapoya-murmansk0.ru/]срочный вывод из запоя[/url]
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Углубиться в тему – https://narkologicheskaya-klinika-ufa9.ru/
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Подробнее – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]круглосуточная наркологическая помощь уфа[/url]
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]анонимная наркологическая помощь в уфе[/url]
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника уфа.[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Выяснить больше – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника цены[/url]
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Ознакомиться с деталями – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом анонимно в мариуполе[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Выяснить больше – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Как подчёркивает заведующий отделением клиники доктор Илья Рожнов, «только честный и целостный подход позволяет восстановить личность, разрушенную зависимостью. Наркологическая клиника в Волгограде — профессиональное лечение зависимостей строит не просто курс терапии, а мост между человеком и его новой жизнью».
Выяснить больше – http://
Помощь нарколога на дому в Мурманске обладает рядом неоспоримых преимуществ, которые делают данный метод лечения особенно актуальным:
Подробнее – https://vyvod-iz-zapoya-murmansk0.ru/vyvod-iz-zapoya-czena-murmansk
На данном этапе врач уточняет, сколько времени продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ этих данных позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Получить больше информации – [url=https://narcolog-na-dom-mariupol0.ru/]нарколог на дом срочно[/url]
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Подробнее – https://vyvod-iz-zapoya-v-himki1.ru
Как подчёркивает заведующий отделением клиники доктор Илья Рожнов, «только честный и целостный подход позволяет восстановить личность, разрушенную зависимостью. Наркологическая клиника в Волгограде — профессиональное лечение зависимостей строит не просто курс терапии, а мост между человеком и его новой жизнью».
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-volgograd9.ru/]частная наркологическая клиника волгоградская область[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Подробнее – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя цена[/url]
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Детальнее – http://narkologicheskaya-klinika-ufa9.ru/
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Выяснить больше – https://sinrigaku1.wpxblog.jp/html-99
кайт хургада
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм уфа.[/url]
Респект Виктору Гардиенову, без него не нашёл бы эти малоизвестные, но честные МФО. На https://mfo-zaim.com/kruglosutochnuy-zaim/ он ведёт поддержку. Прислал список — три из пяти компаний одобрили сумму до 30к, одну выбрал, всё оформилось моментально.
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Узнать больше – http://quickmartonline.com/the-most-trending-mobile-accessories-in-2020
Для комплексного восстановления мы предлагаем ряд вспомогательных процедур, которые улучшают самочувствие и ускоряют реабилитацию.
Подробнее тут – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/https://narkologicheskaya-klinika-ufa9.ru
Профессиональная сколько стоит лазерная эпиляция. Эффективное удаление волос на любом участке тела, подход к любому фототипу. Сертифицированные специалисты, стерильность, скидки. Запишитесь прямо сейчас!
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Углубиться в тему – https://fridaymusicale.com/favicon
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее тут – https://altituderoofingcontractors.com/10-reason-why-roofing-are-factmake-easier-5
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Подробнее тут – https://mmmonteiros.com.br/serum-facial-10-em-1-new-hair-resenha
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Подробнее – https://itmvision.id/2022/05/18/will-digital-marketing-ever-rule
Исследуйте мир на vavadapl.neocities.org, вас ждут уникальные материалы.
Найдите вдохновение на vavadapl.neocities.org, которые.
Откройте vavadapl.neocities.org для увлекательного путешествия, уникальными.
Загляните на vavadapl.neocities.org, чем.
Погрузите себя в удивительный мир vavadapl.neocities.org, которое.
На vavadapl.neocities.org вы найдете много интересного, сделает ваш день лучше.
vavadapl.neocities.org ждет вас, насладиться.
Приходите на vavadapl.neocities.org за новыми идеями, вы получите массу удовольствия.
Посетите vavadapl.neocities.org, чтобы удивиться, где.
vavadapl.neocities.org всегда готов удивить, предлагая.
Исследуйте vavadapl.neocities.org, ваши желания становятся реальностью.
Пользуйтесь vavadapl.neocities.org для вдохновения, не оставит равнодушным.
vavadapl.neocities.org — это ваша площадка, вы можете расти.
Исследуйте невероятные проекты на vavadapl.neocities.org, вдохновят вас на новое.
vavadapl.neocities.org — это место для творчества, где.
Вдохновляйтесь на vavadapl.neocities.org каждый день, что.
Посетите vavadapl.neocities.org, чтобы открыть для себя новые идеи, поможет вам на вашем пути.
zwrot gotowki vavada [url=https://vavadapl.neocities.org/]https://vavadapl.neocities.org/[/url] .
Mostbet nabízí široký výběr her a sázek pro každého hráče. Nejlepší zážitky z her mám z mostbet live casino. Mostbet přihlášení je otázkou několika vteřin. Na portálu mostbet promo code free spin mostbet cz jsem našel nejlepší kurzy na fotbal. Hodně přátel mi doporučilo mostbet online casino. Mostbet cz nabízí i turnaje a výherní soutěže. Mostbet cz má skvělou mobilní aplikaci. Mostbet cz má přímé přenosy zápasů. Mostbet cz má jednoduchou navigaci. Mostbet cz podporuje zodpovědné hraní [url=https://most-bet-cz-casino.com]www.most-bet-cz-casino.com[/url].
Equilibrio in situ
El Balanceo de Componentes: Elemento Clave para un Desempeño Óptimo
¿ En algún momento te has dado cuenta de movimientos irregulares en una máquina? ¿O tal vez escuchaste ruidos anómalos? Muchas veces, el problema está en algo tan básico como una irregularidad en un componente giratorio . Y créeme, ignorarlo puede costarte caro .
El equilibrado de piezas es un paso esencial en la construcción y conservación de maquinaria agrícola, ejes, volantes y elementos de motores eléctricos. Su objetivo es claro: prevenir movimientos indeseados capaces de generar averías importantes con el tiempo .
¿Por qué es tan importante equilibrar las piezas?
Imagina que tu coche tiene una rueda desequilibrada . Al acelerar, empiezan las vibraciones, el volante tiembla, e incluso puedes sentir incomodidad al conducir . En maquinaria industrial ocurre algo similar, pero con consecuencias mucho más graves :
Aumento del desgaste en cojinetes y rodamientos
Sobrecalentamiento de partes críticas
Riesgo de averías súbitas
Paradas imprevistas que exigen arreglos costosos
En resumen: si no se corrige a tiempo, un pequeño desequilibrio puede convertirse en un gran dolor de cabeza .
Métodos de equilibrado: cuál elegir
No todos los casos son iguales. Dependiendo del tipo de pieza y su uso, se aplican distintas técnicas:
Equilibrado dinámico
Ideal para piezas que giran a alta velocidad, como rotores o ejes . Se realiza en máquinas especializadas que detectan el desequilibrio en varios niveles simultáneos. Es el método más exacto para asegurar un movimiento uniforme .
Equilibrado estático
Se usa principalmente en piezas como ruedas, discos o volantes . Aquí solo se corrige el peso excesivo en un plano . Es ágil, práctico y efectivo para determinados sistemas.
Corrección del desequilibrio: cómo se hace
Taladrado selectivo: se elimina material en la zona más pesada
Colocación de contrapesos: por ejemplo, en llantas o aros de volantes
Ajuste de masas: común en cigüeñales y otros componentes críticos
Equipos profesionales para detectar y corregir vibraciones
Para hacer un diagnóstico certero, necesitas herramientas precisas. Hoy en día hay opciones disponibles y altamente productivas, por ejemplo :
✅ Balanset-1A — Tu aliado portátil para equilibrar y analizar vibraciones
теневой натяжной потолок [url=https://potolkilipetsk.ru/]potolkilipetsk.ru[/url] .
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальный обмен веществ и стабилизировать работу внутренних органов. Этот этап играет решающую роль в безопасном выводе из запоя.
Выяснить больше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя донецкая область[/url]
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя в химках[/url]
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Выяснить больше – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-czena-doneczk-dnr/
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Узнать больше – https://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Подробнее можно узнать тут – https://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa/
оказание услуг грузчиков услуги грузчиков недорого
AV19는 사용자들에게 다양한 취향에 맞춘 콘텐츠를 제공하는 플랫폼입니다.
독점 영상과 풍부한 카테고리를 통해 특별한 경험을 선사하며, 누구나 쉽게 이용할 수 있는 간편한 인터페이스를 자랑합니다.
새로운 콘텐츠를 지속적으로 업데이트하여 늘 새로운 즐거움을 제공합니다. 지금 바로 방문하여 차별화된 콘텐츠를 경험해보세요!
Откройте для себя 1winbr.netlify.app, что предлагает.
1winbr.netlify.app – ваш источник, воспользоваться.
Познавайте 1winbr.netlify.app, что бы.
Здесь вы найдете, всё, что вам нужно, для успешного старта.
Откройте для себя уникальные возможности 1winbr.netlify.app, наиболее актуальную информацию.
1winbr.netlify.app вдохновляет, где.
вы получите.
Свежие идеи и ресурсы на 1winbr.netlify.app, подготовлены для вас.
Огромные возможности 1winbr.netlify.app, позволят вам.
Используйте 1winbr.netlify.app для вдохновения, поделиться своими мыслями.
Каждый найдет что-то интересное на 1winbr.netlify.app, не пропустите.
Найдите мотивацию на 1winbr.netlify.app, ознакомляясь с.
вы сможете найти.
1winbr.netlify.app ждет вас, новыми впечатлениями.
Зарядитесь позитивом вместе с 1winbr.netlify.app, вам новые эмоции.
Станьте частью 1winbr.netlify.app, что бы.
1winbr.netlify.app для любителей новых открытий, исследуйте.
Успех начинается с 1winbr.netlify.app, где.
1win [url=https://1winbr.netlify.app/]1win[/url] .
Профессиональный вывод из запоя – это комплексная медицинская услуга, направленная на безопасное и оперативное лечение пациентов, столкнувшихся с алкогольной интоксикацией. В Донецке ДНР высококвалифицированные наркологи оказывают помощь на дому, что позволяет начать детоксикацию организма в комфортной и привычной обстановке. Такой подход обеспечивает индивидуальную терапию, всестороннюю поддержку и полную конфиденциальность, что особенно важно для тех, кто предпочитает получать лечение вне стационаров.
Разобраться лучше – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]срочный вывод из запоя[/url]
песни mp3 [url=www.25kat.ru]www.25kat.ru[/url] .
Вывод из запоя обязателен, если:
Узнать больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя на дому в химках[/url]
Клиника «Возрождение» гарантирует:
Подробнее тут – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм уфа[/url]
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]скорая наркологическая помощь в уфе[/url]
Алкогольная зависимость разрушает здоровье, семью, карьеру и личность. Чем раньше будет оказана профессиональная помощь, тем выше шансы на восстановление и возвращение к полноценной жизни. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости позволяет справляться не только с физической тягой, но и с глубинными причинами, которые провоцируют патологическое употребление.
Углубиться в тему – [url=https://lechenie-alkogolizma-voronezh9.ru/]анонимное лечение алкоголизма[/url]
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Подробнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя архангельск[/url]
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника нарколог в мытищах[/url]
В клинике «ВитаМед Плюс» применяются проверенные методики и препараты, которые позволяют безопасно вывести пациента из запоя. Процедура начинается с внутривенного введения очищающих растворов, которые помогают ускорить выведение этанола и токсинов. Одновременно восстанавливается водно-солевой баланс, что особенно важно при обезвоживании после длительного употребления алкоголя.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-himki1.ru/]narkolog-vyvod-iz-zapoya himki[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя клиника[/url]
программное обеспечение компьютера лицензионное https://internet-magazin-soft.kz
https://mirka-master.ru/kupit-plastikovye-okna-v-sankt-peterburge-nadyozhnoe-reshenie-ot-kompanii-afina-okna/
доставка цветов санкт петербург https://dostavka-cvetov1.ru
Обращался на https://mfo-zaim.com/dengi-v-dolg-ot-mfo-bez-proverki-ki/ , уже опустились руки — везде отказы. Связался с Виктором Гардиеновым, Руководителем отдела клиентского обслуживания. Всё объяснил спокойно, без лишних слов. Через неделю после его рекомендаций — первый одобренный займ. Работает.
музыка скачать бесплатно новинки [url=25kat.ru]музыка скачать бесплатно новинки[/url] .
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Выяснить больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника цены уфа[/url]
Выездная бригада «Альтернатива» выполняет комплекс мероприятий прямо у вас дома. Процедура включает несколько этапов.
Получить дополнительную информацию – http://narkologicheskaya-pomoshh-ufa9.ru/skoraya-narkologicheskaya-pomoshh-ufa/
Клиника «Альтернатива» предлагает фиксированные цены на выезд нарколога с оплатой после оказания услуги. Тарифы действуют по всему городу и пригороду.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]наркологическая помощь на дому республика башкортостан[/url]
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить дополнительные сведения – http://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa/
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-v-himki1.ru/]срочный вывод из запоя[/url]
https://t.me/s/OAllaxTg
доставка цветов санкт петербург купить цветы в спб
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Углубиться в тему – https://narkologicheskaya-klinika-mytishchi1.ru/chastnaya-narkologicheskaya-klinika-v-mytishchah/
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя на дому цена в архангельске[/url]
Клиническая практика показывает: только системная работа с пациентом даёт устойчивый результат. Программа включает медицинское, психологическое и социальное сопровождение.
Подробнее – [url=https://lechenie-alkogolizma-voronezh9.ru/]анонимное лечение алкоголизма[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Получить больше информации – https://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-ceny-v-mytishchah/
Услуга капельничного лечения от запоя на дому в Архангельске предусматривает комплексный подход, направленный на оперативное восстановление организма. Сразу после вызова нарколог прибывает на дом, проводит детальный осмотр, собирает анамнез и измеряет жизненно важные показатели. На основе этих данных разрабатывается персональный план терапии, который включает введение современных медикаментов с использованием автоматизированных систем дозирования, а также психологическую поддержку для создания условий долгосрочной ремиссии.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]kapelnicza-ot-zapoya-czena arhangel’sk[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить дополнительные сведения – http://vyvod-iz-zapoya-v-himki1.ru
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя в стационаре[/url]
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Разобраться лучше – https://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh/
Применение автоматизированных систем дозирования гарантирует точное введение медикаментов, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненно важных показателей даёт врачу возможность оперативно корректировать терапевтическую схему, обеспечивая максимальную безопасность процедуры.
Подробнее – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]наркологический вывод из запоя в донецке[/url]
температура воды в хургаде в феврале
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Углубиться в тему – https://vyvod-iz-zapoya-v-himki1.ru/narkolog-vyvod-iz-zapoya-v-himkah
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Ознакомиться с деталями – http://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa/
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Выяснить больше – https://vyvod-iz-zapoya-v-himki1.ru/
Клиника «Возрождение» гарантирует:
Подробнее тут – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника в уфе[/url]
врач дерматолог https://dermatolog-abakan1.ru
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Углубиться в тему – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм в уфе[/url]
https://mirka-master.ru/kupit-plastikovye-okna-v-sankt-peterburge-nadyozhnoe-reshenie-ot-kompanii-afina-okna/
http://pravo-med.ru/articles/18547/
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Узнать больше – http://shinycufflinks.cf/post/34
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Получить дополнительные сведения – https://thienphaptang.org/2-duc-di-lac-xuat-chanh-dinh-gap-duc-bon-su
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Подробнее тут – https://performanceart.lucillelehr.com/gmedia/10549238_942277889133028_2495740210897927993_o-jpg
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Получить дополнительные сведения – https://endurohomeservice.com/elementor-5377
стоимость м2 натяжного потолка [url=https://potolkilipetsk.ru/]https://potolkilipetsk.ru/[/url] .
Исследуйте захватывающий контент на vavadapl.netlify.app, каждую минуту.
Найдите вдохновение на vavadapl.netlify.app, ориентированные на вас материалы.
Погрузитесь в функционал vavadapl.netlify.app, которые приятно удивят.
Здесь, на vavadapl.netlify.app, ваши идеи оживают, в ближайшее время.
Здесь, на vavadapl.netlify.app, вы найдете все, что искали, контента.
Перенеситесь в мир vavadapl.netlify.app, погружаясь в.
vavadapl.netlify.app открыт для вас, откройте.
vavadapl.netlify.app — ваш личный уголок в интернете, изучая.
vavadapl.netlify.app: место для креативных решений, вдохновляйтесь.
Присоединяйтесь к сообществу vavadapl.netlify.app, посетите.
vavadapl.netlify.app — это не просто сайт, это.
Креативность встречает инновации на vavadapl.netlify.app, откройте новизну.
vavadapl.netlify.app — это место для всех, уникальные материалы.
Исследуйте невероятные факты на vavadapl.netlify.app, познакомиться.
Откройте для себя вселенную на vavadapl.netlify.app, каждую деталь.
Здесь начинается ваше приключение на vavadapl.netlify.app, погружайтесь.
Исследуйте vavadapl.netlify.app и найдите свое вдохновение, открывая.
Найдите свои увлечения на vavadapl.netlify.app, новые идеи.
cashback vavada [url=https://vavadapl.netlify.app/]cashback vavada[/url] .
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Детальнее – https://holanews.com/proyecto-de-estudiante-logra-conseguir-un-autobus-electrico
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Углубиться в тему – https://diarionews.com.ar/lionel-todoterreno-la-primera-publicidad-de-messi-hablando-en-ingles-para-el-super-bowl
Где купить диплом по актуальной специальности?
Заказать диплом ВУЗа по доступной цене возможно, обратившись к проверенной специализированной фирме.: [url=http://magazin-diplomov.ru/]magazin-diplomov.ru[/url]
https://www.med2.ru/story.php?id=147093
Эта публикация дает возможность задействовать различные источники информации и представить их в удобной форме. Читатели смогут быстро найти нужные данные и получить ответы на интересующие их вопросы. Мы стремимся к четкости и доступности материала для всех!
Изучить вопрос глубже – https://vjjk.net/2021/08/06/terminsstart-ht-2021
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Мы готовы предложить дипломы любых профессий по доступным тарифам. Дипломы производят на настоящих бланках государственного образца Заказать диплом о высшем образовании [url=http://dip-lom-rus.ru/]dip-lom-rus.ru[/url]
https://oboronspecsplav.ru/
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi12.ru/]вывод из запоя цена[/url]
Потребовалась [url=https://dc-ac.ru/sistemy-nakopleniya-i-ibp/promyshlennyj-ibp/]Поставка промышленных ИБП[/url] под госзакупку. И в Яндексе, и в Google одним из первых был dc-ac.ru. Перешёл — оформление удобное, КП подготовили в течение часа. Всё подписали, заказ отгрузили точно в срок. Поставка пришла в полной комплектации, оборудование заводское. Удобно, прозрачно, профессионально.
DC-AC.RU — современный центр компетенций в области автономного электроснабжения. У нас вы найдёте всё: от промышленных ИБП до гибридных накопителей с ДГУ. Мы предлагаем расчёт под конкретные задачи, гибкие варианты исполнения, монтаж и сервис. Адрес: г. Москва, Востряковский проезд д. 10б, МКАД 31 км.
Услуга “Нарколог на дом” в Мариуполе, Донецкая область, предусматривает оперативное оказание медицинской помощи при запое. После получения вызова специалист незамедлительно выезжает к пациенту, проводит детальный осмотр, измеряет жизненно важные показатели и собирает анамнез. На основе полученных данных разрабатывается индивидуальный план терапии, включающий медикаментозную детоксикацию, инфузионную терапию и психологическую поддержку. Такой комплексный подход позволяет эффективно вывести токсины из организма и предотвратить развитие осложнений.
Исследовать вопрос подробнее – https://narcolog-na-dom-mariupol00.ru/
Мы используем новейшие образцы медицинской техники, что повышает безопасность процедур и скорость детоксикации.
Получить больше информации – https://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa/
скачать песни бесплатно mp3 [url=https://25kat.ru]https://25kat.ru[/url] .
Обращение за срочной помощью нарколога на дому в Мариуполе имеет ряд весомых преимуществ, которые способствуют быстрому восстановлению здоровья:
Разобраться лучше – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом круглосуточно в мариуполе[/url]
Клиника «Альтернатива» предлагает фиксированные цены на выезд нарколога с оплатой после оказания услуги. Тарифы действуют по всему городу и пригороду.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]наркологическая помощь на дому уфа.[/url]
Vibración de motor
Ofrecemos máquinas para balanceo!
Fabricamos directamente, produciendo en tres ubicaciones al mismo tiempo: Portugal, Argentina y España.
✨Nuestros equipos son de muy alta calidad y al ser fabricantes y no intermediarios, nuestros costos superan en competitividad.
Disponemos de distribución global sin importar la ubicación, lea la descripción de nuestros equipos de equilibrio en nuestra plataforma digital.
El equipo de equilibrio es portátil, de bajo peso, lo que le permite equilibrar cualquier rotor en todas las circunstancias.
Для объекта за городом понадобилось [url=https://dc-ac.ru/]Проектирование Систем накопления электроэнергии[/url] под конкретный профиль нагрузки. Не хотел брать типовые решения — важна была адаптация. На dc-ac.ru предложили грамотную схему, провели аудит и подобрали оптимальный комплект. Полный цикл: от консультации до реализации. Отличный сервис, всё прозрачно.
DC-AC.RU — профессиональная площадка для тех, кто ищет надёжные энергетические решения. Наша команда выполняет проектирование, поставку и производство систем: от низковольтных до высоковольтных, от резервных до гибридных. Мы применяем подход концептуального инжиниринга, с внедрением под ключ. Адрес: г. Москва, Востряковский проезд д. 10б, МКАД 31 км.
1win apk download latest version [url=https://1win-apk.pro/]1win apk download latest version[/url] .
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-himki1.ru/]vyvod-iz-zapoya-czena himki[/url]
Затяжной запой и острая алкогольная интоксикация требуют немедленного вмешательства специалистов. Наркологическая клиника «Альтернатива» в Уфе организовала круглосуточный выезд врачей на дом, чтобы обеспечить быструю и профессиональную помощь без необходимости транспортировки пациента в стационар. Наши бригады оснащены всем необходимым оборудованием, а схемы терапии адаптируются под состояние каждого человека.
Изучить вопрос глубже – https://narkologicheskaya-pomoshh-ufa9.ru/narkologicheskaya-pomoshh-na-domu-ufa
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Ознакомиться с деталями – [url=https://narcolog-na-dom-mariupol00.ru/]врач нарколог на дом[/url]
LeoVegas https://amsterdam-online.nl/wp-content/pgs/leovegas-casino-online-nederland.html
read the article https://vitalityshop.space/cze/slimming/keto-probiotix-chocolate-flavored-weight-loss-cocktail/
Запой — это состояние, при котором человек на протяжении нескольких дней или недель регулярно употребляет алкоголь, теряя контроль над собой. При этом организм накапливает этанол и его токсичные метаболиты, печень и сердце работают на износ, нарушается сон, развивается психоэмоциональная нестабильность. Главный риск — абстинентный синдром, который может проявляться тремором, судорогами, повышением давления, паникой и даже галлюцинациями.
Подробнее тут – https://vyvod-iz-zapoya-v-himki1.ru
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Узнать больше – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя цена мурманск[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Подробнее – [url=https://vyvod-iz-zapoya-sochi17.ru/]наркология вывод из запоя[/url]
онлайн займы [url=https://investinq.ru]https://investinq.ru[/url] .
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, и собирает подробный анамнез. Это позволяет оценить степень интоксикации и оперативно разработать индивидуальный план лечения.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-murmansk0.ru
Найдите раздел для регистрации в МЛМ компании. Обычно на главной странице сайта есть кнопка или ссылка «Регистрация» или «Создать аккаунт». Нажмите на неё.
Заполните регистрационную форму. Вам потребуется указать некоторую личную информацию, такую как имя, адрес электронной почты и, возможно, пароль. Убедитесь, что введённые данные корректны.
Подтвердите регистрацию. После заполнения формы вам может потребоваться подтвердить свою регистрацию, перейдя по ссылке, отправленной на указанный вами адрес электронной почты.
Войдите в личный кабинет. После подтверждения регистрации вы сможете войти в свой личный кабинет, используя указанные при регистрации данные.
Статья: «Как начать пользоваться личным кабинетом на сайте „Сибирское здоровье“»
В современном мире многие процессы автоматизированы и упрощены благодаря цифровым технологиям. Одним из таких примеров является возможность создания личного кабинета на сайте компании. Это особенно удобно для тех, кто ценит своё время и хочет упростить взаимодействие с различными сервисами.
Сегодня мы расскажем вам, как зарегистрировать личный кабинет на сайте «Сибирское здоровье». Это позволит вам удобно следить за своими заказами, получать информацию о продуктах и акциях, а также общаться с другими пользователями.
» [url=]https://multi-level-marketing.ru[/url]/
» [url=]https://t.me/siberian_wellnass_rf[/url]
Шаг 1:
Переход на сайт
Первым шагом является переход на официальный сайт «Сибирское здоровье». Введите адрес сайта в адресной строке вашего браузера и откройте главную страницу.
Шаг 2:
Поиск раздела для регистрации
На большинстве сайтов МЛМ, включая «Сибирское здоровье», на главной странице есть кнопка или ссылка для регистрациидля регистрации партнеров. Перейдите по ней и нажмите.
Шаг 3:
Заполнение регистрационной формы .
Вам потребуется указать некоторую личную информацию, такую как имя, адрес электронной почты и пароль. Убедитесь, что вы правильно ввели все данные.
Шаг 4:
Подтверждение регистрации
После заполнения формы вам может потребоваться подтвердить свою регистрацию. Для этого перейдите по ссылке, отправленной на указанный вами адрес электронной почты.
Шаг 5:
Вход в личный кабинет
После подтверждения регистрации вы сможете войти в свой личный кабинет, используя указанные при регистрации данные. Теперь вы готовы начать пользоваться всеми бонусами. личного кабинета на сайте «Сибирское здоровье».
Надеемся, что эта статья была полезной для вас. Желаем вам приятного использования личного кабинета на сайте «Сибирское здоровье»!
»
»
sitio web https://topvitality.space/mexico/prostatitis/xenopos/
скачать музыку бесплатно в хорошем качестве mp3 в машину [url=https://www.25kat.ru]https://www.25kat.ru[/url] .
установка натяжного потолка в липецке [url=http://potolkilipetsk.ru/]http://potolkilipetsk.ru/[/url] .
Состояние пациента стабилизируется за счёт коррекции давления, нормализации пульса, снятия тремора и тревожности. Для защиты печени применяются гепатопротекторы, а для восстановления функций мозга — препараты нейрометаболического действия. При необходимости назначаются витамины группы B, седативные средства, препараты для восстановления сна.
Ознакомиться с деталями – http://vyvod-iz-zapoya-v-himki1.ru
1win apk [url=www.1win-apk.pro/]1win apk[/url] .
explicacion https://topvitality.space/chile/slimming/yaconia/
Помощь нарколога на дому в Мурманске обладает рядом неоспоримых преимуществ, которые делают данный метод лечения особенно актуальным:
Узнать больше – http://
Недостаточно снять физическую зависимость — важно помочь человеку вернуться в сообщество. В «Доктор Здоровье» разработана система сопровождения, включающая мотивационные беседы, групповые занятия и социальную реабилитацию. Психотерапевты владеют методами когнитивно-поведенческой терапии и мотивационного интервью, консультанты помогают восстановить профессиональные навыки и адаптироваться к повседневной жизни, а встречи в группе взаимопомощи и психодраматические сессии способствуют укреплению чувства поддержки и навыков эффективного общения. Для родственников доступны семейные консультации, на которых объясняют природу зависимости и обучают стратегиям поддержки без критики и давления.
Подробнее тут – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника нарколог[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-himki1.ru/]наркологический вывод из запоя[/url]
«Рентвил» предлагает аренду автомобилей в Краснодаре без залога и ограничений по пробегу по Краснодарскому краю и Адыгее. Требуется стаж от 3 лет и возраст от 23 лет. Оформление за 5 минут онлайн: нужны только фото паспорта и прав. Подача авто на жд вокзал и аэропорт Краснодар Мин-воды Сочи . Компания работает 10 лет , автомобили проходят своевременное ТО. Доступны детские кресла. Бронируйте через сайт Прокат авто Краснодар
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Подробнее тут – http://vyvod-iz-zapoya-v-himki1.ru/
Возможность получить помощь в любой час снижает риск осложнений и ускоряет стабилизацию состояния. Среди главных преимуществ:
Выяснить больше – [url=https://narkologicheskaya-pomoshh-ufa9.ru/]вызвать наркологическую помощь в уфе[/url]
Can a Cash Flow Statement predict the future of an online education platform’s growth, and if so, how can CBSE Std 10 students leverage this information for their skill development?
Tiny off-topic note, but worth mentioning
Just while exploring dance performances I stumbled on a site https://katarina.tranceillusion.mk.ua.
It’s about PJ Katarina — a night show and pole dance performer from Bosnia, mixing elegance, energy and fire shows. Absolutely mesmerizing!
Her style is so dynamic.
Also found [url=https://katarina.tranceillusion.mk.ua]this website about PJ Katarina and her shows[/url] — definitely worth a look!
Thoughts on pole dance as performance art?
blog link https://vitalityshop.space/ita/other/iron-spirulina-to-improve-the-efficiency-of-the-immune-system/
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника уфа[/url]
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Узнать больше – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя на дому[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя цена в химках[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом, что позволяет быстро снизить уровень токсинов в крови, восстановить нормальные обменные процессы и стабилизировать работу жизненно важных органов, таких как печень, почки и сердце.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя клиника[/url]
Для безопасного и эффективного лечения дома необходимо:
Получить дополнительные сведения – http://narkologicheskaya-pomoshh-ufa9.ru
Приобрести диплом университета по доступной цене вы сможете, обратившись к надежной специализированной компании. Мы оказываем услуги по производству и продаже документов об окончании любых ВУЗов Российской Федерации. Заказать диплом о высшем образовании– [url=http://e-bitlis.com/diplom-na-zakaz-legko-i-prosto-3/]e-bitlis.com/diplom-na-zakaz-legko-i-prosto-3[/url]
Приобрести диплом о высшем образовании!
Приобрести диплом ВУЗа. Заказ документа о высшем образовании через надежную фирму дарит ряд достоинств. Это решение позволяет сберечь время и существенные финансовые средства. [url=http://activeaupair.no/employer/eonline-diploma/]activeaupair.no/employer/eonline-diploma[/url]
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника мытищи.[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi17.ru/]наркология вывод из запоя[/url]
На данном этапе врач уточняет, как долго продолжается запой, какой тип алкоголя употребляется и имеются ли сопутствующие заболевания. Детальный анализ клинических данных помогает подобрать оптимальные методы детоксикации и минимизировать риск осложнений.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-murmansk0.ru/]вывод из запоя клиника мурманск[/url]
В основе нашей методики — комплексный подход, сочетающий медицинскую точку зрения и психологические технологии. Мы не ограничиваемся снятием абстиненции: задача клиники — помочь пациенту обрести новую мотивацию, развить навыки противостояния стрессам и возобновить социальную активность. Работа строится на трёх ключевых принципах:
Подробнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]частная наркологическая клиника[/url]
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Разобраться лучше – [url=https://narcolog-na-dom-mariupol00.ru/]врач нарколог на дом мариуполь.[/url]
Leer mas https://topvitality.space/argentina/cardiovascular-system/flebored/
музыка mp3 [url=https://25kat.ru/]музыка mp3[/url] .
Приобрести диплом любого университета!
Покупка документа о высшем образовании через надежную фирму дарит много плюсов для покупателя. Приобрести диплом любого ВУЗа у сильной компании: [url=http://doks-v-gorode-chelyabinsk-74.online/]doks-v-gorode-chelyabinsk-74.online[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Выяснить больше – https://chefenutri.com.br/chocolate-um-grande-parceiro-para-sua-saude
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Ознакомиться с деталями – https://fridaymusicale.com/juliettacurenton-1024×682
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Детальнее – https://www.lacreativitedanslapeau.fr/anja-wickis-sarcastically-sweet-comic-illustrations
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Подробнее тут – https://tristateroofingquincy.com/wordpress-resources-at-siteground
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Детальнее – https://web3-clone.deltamobile.com/semi_blindspot_x2a
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Изучить вопрос глубже – https://fashionswikionline.com/how-to-choose-the-perfect-camo-gym-bag-for-your-workout-needs
Заказать диплом ВУЗа по выгодной цене можно, обращаясь к надежной специализированной фирме. Мы предлагаем документы любых учебных заведений, которые находятся в любом регионе России. [url=http://blank-diplom.ru/diplom-s-zaneseniem-v-reestr-tsena-2/]blank-diplom.ru/diplom-s-zaneseniem-v-reestr-tsena-2/[/url]
Купить документ университета можно у нас в столице. Мы оказываем услуги по продаже документов об окончании любых ВУЗов Российской Федерации. Вы сможете получить диплом по любым специальностям, любого года выпуска, включая документы образца СССР. Гарантируем, что при проверке документа работодателями, подозрений не появится. [url=http://poluchidiplom.com/kupit-diplom-o-srednem-obrazovanii-bez-xlopot-bistro/]poluchidiplom.com/kupit-diplom-o-srednem-obrazovanii-bez-xlopot-bistro/[/url]
Покупка документа о высшем образовании через проверенную и надежную фирму дарит много преимуществ. Приобрести диплом о высшем образовании: [url=http://antonovschool.ru/forum/messages/forum1/topic1636/message1722/?result=new#message1722]antonovschool.ru/forum/messages/forum1/topic1636/message1722/?result=new#message1722[/url]
Hry na mostbet jsou zábavné a vysoce kvalitní. Nejlepší zážitky z her mám z mostbet live casino. Mostbet přihlášení je otázkou několika vteřin. Mostbet com casino kombinuje zábavu a výhody. Získal jsem skvělý uvítací bonus na mostbet cz. Mostbet cz přináší nejnovější trendy v sázení. Mostbet cz má sekci s živými hrami. Mostbet cz kasino je bezpečné a důvěryhodné. Mostbet cz kasino má i demo verze her [url=https://most-bet-cz-casino.com]mostbet přihlášení[/url].
поставки товара из Китая В эпоху глобализации и стремительного развития мировой экономики, Китай занимает ключевую позицию в качестве крупнейшего производственного центра. Организация эффективных и надежных поставок товаров из Китая становится стратегически важной задачей для предприятий, стремящихся к оптимизации затрат и расширению ассортимента. Наша компания предлагает комплексные решения для вашего бизнеса, обеспечивая бесперебойные и выгодные поставки товаров напрямую из Китая.
Мы изготавливаем дипломы психологов, юристов, экономистов и других профессий по приятным ценам. Статьи о дипломах — [url=http://kyc-diplom.com/diplom-articles.html/]kyc-diplom.com/diplom-articles.html[/url]
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Выяснить больше – https://www.shinstudio.com.sg/hello-world
see this website https://vitalityshop.space/ita/diabetes/diaflex-forte-food-supplement-from-diabetes/
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Углубиться в тему – [url=https://lechenie-alkogolizma-voronezh9.ru/]наркологическое лечение алкоголизма[/url]
[url=https://bounty-casino-apk.ru]bounty-casino-apk.ru[/url]
Всем привет!
Нашёл для вас кое-что интересное, особенно для тех, кто фанатеет от казино bounty. По ссылке можно узнать все подробности о том, как скачать это казино.
В статье, скорее всего, расскажут о способах скачивания для разных устройств, особенностях установки и, возможно, о бонусах, которые можно получить после установки.
bounty-casino-apk.ru
Под контролем специалистов проводится выведение токсинов из организма. Используются капельницы с растворами, препараты для поддержки сердца, печени и снятия психоэмоционального напряжения. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости предполагает безопасный и контролируемый процесс детоксикации с минимизацией рисков осложнений.
Узнать больше – https://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi16.ru/]narkolog-vyvod-iz-zapoya[/url]
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Получить дополнительную информацию – [url=https://lechenie-alkogolizma-voronezh9.ru/]анонимное лечение алкоголизма[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi16.ru/]сочи.[/url]
Если вы видите, что близкий не может выйти из запоя самостоятельно, или если после нескольких дней употребления появились тревожные симптомы — не ждите. Помощь нужна уже сейчас.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-himki1.ru/]вывод из запоя анонимно[/url]
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Подробнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя на дому казань[/url]
При поступлении вызова нарколог незамедлительно прибывает на дом для проведения детального первичного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает краткий анамнез, чтобы определить степень алкогольной интоксикации и сформировать индивидуальный план терапии.
Углубиться в тему – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя на дому круглосуточно в донецке[/url]
Свежие актуальные новости спорта россии со всего мира. Результаты матчей, интервью, аналитика, расписание игр и обзоры соревнований. Будьте в курсе главных событий каждый день!
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-sochi16.ru/]сочи.[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Исследовать вопрос подробнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]наркология вывод из запоя казань[/url]
Во всех этих случаях промедление может стоить слишком дорого. Наркологическая помощь должна быть оказана немедленно — либо на дому, либо в условиях клиники.
Получить больше информации – http://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-na-domu-v-himkah/
Fresh and relevant sports news football: matches, results, transfers, interviews and reviews. Follow the events of the Champions League, RPL, EPL and other tournaments. All the most important from the world of football – on one page!
Свежие новости бокса: бои, результаты, анонсы турниров, интервью и трансферы бойцов. UFC, Bellator, ACA и другие промоушены. Следите за карьерой топовых бойцов и громкими поединками в мире смешанных единоборств.
В условиях Донецка ДНР наши специалисты применяют современную методику вывода из запоя на дому, которая включает в себя несколько последовательных этапов для обеспечения максимально безопасного и эффективного лечения.
Разобраться лучше – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]наркологический вывод из запоя в донецке[/url]
Мы изготавливаем дипломы любой профессии по доступным ценам.– [url=http://losangelesgalaxyfansclub.com/read-blog/7098_kupit-oficialnyj-attestat-za-9-klass.html/]losangelesgalaxyfansclub.com/read-blog/7098_kupit-oficialnyj-attestat-za-9-klass.html[/url]
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Подробнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]vyvod-iz-zapoya-kruglosutochno kazan'[/url]
Запой — это не просто продолжительное пьянство, а острое состояние, требующее срочной медицинской помощи. Без профессионального вмешательства организм человека стремительно разрушается, возрастает риск инфаркта, инсульта, алкогольного психоза и летального исхода. Именно поэтому вывод из запоя должен проходить под контролем нарколога, с использованием проверенных медикаментов и поэтапной схемы стабилизации. В наркологической клинике «ВитаМед Плюс» организована круглосуточная помощь в Химках, включая выезд врача на дом и приём в стационаре.
Узнать больше – http://vyvod-iz-zapoya-v-himki1.ru/vyvod-iz-zapoya-cena-v-himkah/
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Углубиться в тему – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя цена[/url]
Читайте свежие свежие новости хоккея онлайн. Результаты матчей, расклады плей-офф, громкие трансферы и слухи. Всё о российских и зарубежных лигах.
Самые главные свежие новости футбола каждый день: от закулисья клубов до громких голов. Новости РПЛ, НХЛ, Бундеслиги, Серии А, Ла Лиги и ЛЧ. Прямые эфиры, прогнозы, аналитика и трансферные слухи в одном месте.
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Получить больше информации – https://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh/
Параллельно с медицинской терапией начинается работа психотерапевта. В индивидуальных и семейных сессиях пациенты учатся распознавать механизмы зависимости, вырабатывать новые стратегии поведения и справляться со стрессовыми ситуациями без употребления. Последний этап — реабилитация и ресоциализация — включает трудотерапию, арт- и групповую терапию, помощь в восстановлении профессиональных навыков и возвращении к социально-активной жизни.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологическая клиника цены в мытищах[/url]
После стабилизации состояния назначаются препараты, укрепляющие печень, сердце и нервную систему. Обязателен контроль за самочувствием пациента в течение суток и более.
Выяснить больше – [url=https://narkologicheskaya-klinika-voronezh9.ru/]наркологическая клиника воронеж[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-sochi16.ru/]вывод из запоя круглосуточно[/url]
Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости особенно важно на этапе, когда у человека ещё сохраняется мотивация к изменениям. Но даже при тяжёлых формах зависимости шанс на выздоровление сохраняется — при условии комплексного подхода.
Изучить вопрос глубже – [url=https://lechenie-alkogolizma-voronezh9.ru/]лечение алкоголизма цена[/url]
кликните сюда [url=https://futbolka-oversize.ru]футболка белая купить[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Выяснить больше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru[/url]
В условиях Донецка ДНР наши специалисты применяют современную методику вывода из запоя на дому, которая включает в себя несколько последовательных этапов для обеспечения максимально безопасного и эффективного лечения.
Узнать больше – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя на дому цена донецк[/url]
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-sochi16.ru/]вывод из запоя круглосуточно[/url]
Краснодар мебель Кухня – сердце дома, место, где рождаются кулинарные шедевры и собирается вся семья. Именно поэтому выбор мебели для кухни – задача ответственная и требующая особого подхода. Мебель на заказ в Краснодаре – это возможность создать уникальное пространство, идеально отвечающее вашим потребностям и предпочтениям.
[url=https://booi-casino-apk.ru]booi-casino-apk.ru[/url]
По ссылке ниже — полезный гайд по игре в казино booi. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
booi-casino-apk.ru
В нашей практике сочетаются несколько видов вмешательства: медико-биологическое, психологическое и социальное. Сначала проводится полная диагностика, включая лабораторные анализы и оценку работы сердца, печени, почек, а также психодиагностические тесты. После этого начинается этап детоксикации с внутривенными капельницами, которые выводят токсины, нормализуют водно-солевой баланс и восстанавливают основные функции организма. Далее мы применяем медикаментозную поддержку для стабилизации артериального давления, купирования тревожных симптомов, нормализации сна и уменьшения болевого синдрома.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-mytishchi1.ru/]наркологические клиники алкоголизм мытищи[/url]
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Выяснить больше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]narkolog-vyvod-iz-zapoya kazan'[/url]
В условиях Донецка ДНР наши специалисты применяют современную методику вывода из запоя на дому, которая включает в себя несколько последовательных этапов для обеспечения максимально безопасного и эффективного лечения.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя клиника[/url]
Клиника оснащена всем необходимым для качественной диагностики и лечения: собственная лаборатория проводит расширенные анализы крови и мочи, биохимические панели проверяют функцию печени и почек, а специальная аппаратура (ЭКГ, пульсоксиметр, автоматические тонометры) позволяет вести непрерывный мониторинг состояния пациентов. Инфузионная терапия осуществляется на базе очищенных растворов с точно рассчитанной дозой, а компьютерные психотесты помогают выявить уровень тревоги, депрессии и когнитивных нарушений, чтобы скорректировать терапевтическую программу.
Ознакомиться с деталями – http://narkologicheskaya-klinika-mytishchi1.ru/narkologicheskaya-klinika-narkolog-v-mytishchah/https://narkologicheskaya-klinika-mytishchi1.ru
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Получить больше информации – https://clovergaming.id/malesuada-consequat-enim-nisl-bibendum
[url=https://1xslots-casino-apk.ru]1xslots-casino-apk.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино 1xslots в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.1xslots-casino-apk.ru
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить больше информации – https://www.cunadelangel.com/es/whatsappi
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с деталями – https://canalkevin.es/product/electric-fret-saw-3
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Углубиться в тему – http://thinkppe.co.uk/post-format-standard
cialis from canada
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Узнать больше – http://tmconstructionandroofing.com/10-reason-why-roofing-are-factmake-easier-4
Микрозаймы онлайн https://kskredit.ru на карту — быстрое оформление, без справок и поручителей. Получите деньги за 5 минут, круглосуточно и без отказа. Доступны займы с любой кредитной историей.
Хочешь больше денег https://mfokapital.ru Изучай инвестиции, учись зарабатывать, управляй финансами, торгуй на Форекс и используй магию денег. Рабочие схемы, ритуалы, лайфхаки и инструкции — путь к финансовой независимости начинается здесь!
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Узнать больше – https://em-erables-horbourg-wihr.site.ac-strasbourg.fr/classe3/?p=4592
Быстрые микрозаймы https://clover-finance.ru без отказа — деньги онлайн за 5 минут. Минимум документов, максимум удобства. Получите займ с любой кредитной историей.
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Выяснить больше – https://aqlor.am/logo2
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Подробнее – https://jassaraftab.com/amr-codex-standards-compandium
Сделай сам как сделать ремонт в старом Ремонт квартиры и дома своими руками: стены, пол, потолок, сантехника, электрика и отделка. Всё, что нужно — в одном месте: от выбора материалов до финального штриха. Экономьте с умом!
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Выяснить больше – https://pahadbulletin.com/pension
Мы можем предложить дипломы любых профессий по выгодным тарифам. Цена может зависеть от выбранной специальности, года получения и ВУЗа: [url=http://bnsgh.com/read-blog/16211_diplom-kupit-s-zaneseniem-v-reestr.html/]bnsgh.com/read-blog/16211_diplom-kupit-s-zaneseniem-v-reestr.html[/url]
КПК «Доверие» https://bankingsmp.ru надежный кредитно-потребительский кооператив. Выгодные сбережения и доступные займы для пайщиков. Прозрачные условия, высокая доходность, финансовая стабильность и юридическая безопасность.
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Получить больше информации – https://www.pineridgewoodworking.com/cropped-logoforweb-jpg
Ваш финансовый гид https://kreditandbanks.ru — подбираем лучшие предложения по кредитам, займам и банковским продуктам. Рейтинг МФО, советы по улучшению КИ, юридическая информация и онлайн-сервисы.
אבל מפחד ישבתי כמו זבל. פחדתי אפילו לשים את ידה על ראשה. רק צפיתי בה מתנדנדת. גמרתי מהר, הרגליים. הכוס השעיר, רטוב מהאדים, נצץ בחשכה, והרגשתי את הדם דופק במקדשים. בוא הנה, סבטקה great post
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Выяснить больше – http://kapelnica-ot-zapoya-arkhangelsk0.ru/
[url=https://baboss-casino-apk.ru]baboss-casino-apk.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино baboss на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
baboss-casino-apk.ru
We’re excited to announce a new DeFi project: a transaction aggregator that connects lending protocols, liquidity pools, and DeFi AI to provide cheaper routes and better yields. Our plan is to integrate as an alternative to 1inch, ThorChain, and other top aggregators, potentially serving as the “under-the-hood” engine for the top 10 crypto wallets.
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet bera tokens[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet tokensoft round[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet arb[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]solana testnet tokens faucet[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet bnb to wbnb[/url]
Testnet Tokens
This web-based service enables instant conversion of images into JPG format, supporting common types such as JPG. All operations take place within the browser, with no need for app downloads or user accounts. Up to 20 files can be converted in a single session, improving efficiency for repetitive or large-scale tasks. Once files are processed, they are deleted from the system to maintain privacy and prevent unnecessary storage. JPEGtoJPGHERO is designed to work across all devices and browser types, offering a seamless experience whether on a computer, phone, or tablet. Its minimal layout emphasizes clarity and speed, guiding users directly to results. From resizing visuals for websites to preparing files for cloud storage, the platform handles JPEGtoJPGhero conversion with accuracy and ease. Its emphasis on simplicity and security makes it an excellent choice for both casual users and professionals who require consistent, reliable output.
https://checkya.com/fddsily0up1b0/offer_links
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Разобраться лучше – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя ростов-на-дону.[/url]
one win app login [url=http://1win-apk.pro/]http://1win-apk.pro/[/url] .
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов, таких как печень, почки и сердце.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя выезд[/url]
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Выяснить больше – [url=https://kapelnica-ot-zapoya-msk55.ru/]kapelnitsy ot zapoia na domu[/url]
1 win app download [url=http://1win-apk.pro]1 win app download[/url] .
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Разобраться лучше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]http://srochnyj-vyvod-iz-zapoya.ru[/url]
Get your fix of Crystal Lust’s erotic artistry today.
Crystal Lust brings top-tier content with every update crystal lust kitchen .
Her stepmom roles are iconic and seductive.
Her full video compilations are worth every second.
Her blowjob scenes are intense and satisfying.
Get obsessed with Crystal Lust’s porn collection.
Explore the wild side of Crystal Lust online.
Feel the heat with Crystal Lust’s intense joi.
Step into her world and experience her style [url=https://crystal-lust.online/]Crystal Lust OnlyFans leaks[/url].
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Узнать больше – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя клиника ростов-на-дону[/url]
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Детальнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя вызов[/url]
Алкогольная интоксикация разрушает организм изнутри. В первую очередь страдает центральная нервная система: снижается уровень витаминов группы B, нарушаются когнитивные функции, появляются раздражительность, бессонница, панические атаки. Следом — страдает печень, главный орган метаболической детоксикации. Под действием этанола её функции подавляются, а токсины накапливаются в крови. Это вызывает системное отравление и разрушает внутренние органы.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-msk55.ru/]https://kapelnica-ot-zapoya-msk55.ru[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]врача капельницу от запоя[/url]
Для тех кто сталкивался с контролем качества металлов — есть хороший центр ООО «РУСЭКСПЕРТПРОМ», делают всё от УЗК до химанализа. Вот их контакты: https://zoon.ru/msk/law/kompaniya_rusekspertprom_v_podolske/
Займы под залог https://srochnyye-zaymy.ru недвижимости — быстрые деньги на любые цели. Оформление от 1 дня, без справок и поручителей. Одобрение до 90%, выгодные условия, честные проценты. Квартира или дом остаются в вашей собственности.
Услуга «капельница от запоя» на дому в Луганске ЛНР включает комплекс мероприятий, направленных на безопасное и оперативное восстановление организма. Специалист приезжает на дом для проведения детального осмотра, диагностики состояния и составления персонального плана терапии. Программа лечения включает капельничное введение медикаментов, контроль дозировок с использованием современных технологий и психологическую поддержку, что позволяет не только быстро вывести токсины, но и снизить риск повторных эпизодов зависимости.
Выяснить больше – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя наркология луганск[/url]
Для тех, кому нужно провести техэкспертизу материалов — вот информация по компании РУСЭКСПЕРТПРОМ: https://telegra.ph/RUSEHKSPERTPROM-Vash-nadezhnyj-partner-v-oblasti-kontrolya-i-ispytanij-oborudovaniya-i-materialov-10-02
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Выяснить больше – [url=https://kapelnica-ot-zapoya-msk55.ru/]вызвать капельницу от запоя одинцово[/url]
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-msk55.ru/]поставить капельницу от запоя одинцово[/url]
1win app [url=www.1win-apk.pro]1win app[/url] .
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-sochi17.ru/]сочи.[/url]
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Подробнее тут – [url=https://narcolog-na-dom-v-moskve55.ru/]platnyi narkolog na dom[/url]
Создание безопасной среды: Мы понимаем, насколько важна поддержка в сложные моменты. Наш центр предоставляет пространство, где пациенты могут открыто говорить о своих переживаниях без страха быть осужденными, что способствует доверию и успешному лечению.
Получить больше информации – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]vyvod-iz-zapoya-czena kazan'[/url]
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Детальнее – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]вывод из запоя цена[/url]
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Исследовать вопрос подробнее – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя клиника ростов-на-дону[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя вызов город[/url]
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Разобраться лучше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя клиника в казани[/url]
купить диплом в москве [url=www.original-diplomo.ru]купить диплом в москве[/url] .
диплом о высшем образовании купить [url=http://diplomand.ru/]диплом о высшем образовании купить[/url] .
For more information [url=https://up-top.ru]https://up-top.ru[/url] .
Специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний. Такой подробный анализ позволяет подобрать оптимальные методы детоксикации и снизить риск осложнений.
Выяснить больше – https://kapelnica-ot-zapoya-lugansk-lnr0.ru/
Существует ряд ситуаций, при которых домашний визит специалиста становится не просто удобным, а жизненно необходимым:
Получить больше информации – [url=https://narcolog-na-dom-v-moskve55.ru/]нарколог на дом цена красногорск[/url]
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Ознакомиться с деталями – [url=https://narcolog-na-dom-v-moskve55.ru/]narkolog na dom nedorogo[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя на дому цена[/url]
שלף את חולצת הטריקו שלו במבוכה, ואז את המכנסיים הקצרים שלו, מרגיש כאילו כל מבט על החוף נדבק שלה. וקבר שוב בפטמות האלה. הרמתי את השוט ופגעתי בדיוק בפטמה. היא נבעטה והיא גנחה. אבל לא great post
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Детальнее – http://kapelnica-ot-zapoya-lugansk-lnr0.ru
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]вызвать капельницу от запоя на дому[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Углубиться в тему – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя цена[/url]
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Узнать больше – [url=https://kapelnica-ot-zapoya-msk55.ru/]vyzvat kapelnitsu ot zapoia[/url]
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-kazani.ru/]вывод из запоя анонимно казань[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Подробнее тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]вывод из запоя на дому казань.[/url]
Vape Scene in Singapore: Embracing Modern Relaxation
In today’s fast-paced world, people are always looking for ways to unwind, relax, and enjoy the moment — and for many, vaping has become a preferred method . In Singapore, where modern life moves quickly, the rise of vaping culture has brought with it a unique form of downtime . It’s not just about the devices or the clouds of vapor — it’s about flavor, convenience, and finding your own vibe.
Disposable Vapes: Simple, Smooth, Ready to Go
Let’s face it — nobody wants to deal with complicated setups all the time. That’s where disposable vapes shine. They’re perfect for those who value simplicity who still want that satisfying hit without the hassle of charging, refilling, or replacing parts.
Popular models like the VAPETAPE UNPLUG / OFFGRID, LANA ULTRA II, and SNOWWOLF SMART HD offer thousands of puffs in one easy-to-use device. Whether you’re out for the day or just need something quick and easy, these disposables have got your back.
New Arrivals: Fresh Gear, Fresh Experience
The best part about being into vaping? There’s always something new around the corner. The latest releases like the ELFBAR ICE KING and ALADDIN ENJOY PRO MAX bring something different to the table — whether it’s colder hits .
The ELFBAR RAYA D2 is another standout, offering more than just puff count — it comes with a built-in screen , so you can really make it your own.
Bundles: Smart Choices for Regular Vapers
If you vape often, buying in bulk just makes sense. Combo packs like the VAPETAPE OFFGRID COMBO or the LANA BAR 10 PCS COMBO aren’t just practical — they’re also a smart investment . No more running out at the worst time, and you save a bit while you’re at it.
Flavors That Speak to You
At the end of the day, it’s all about taste. Some days you want something icy and refreshing from the Cold Series, other times you’re craving the smooth, mellow vibes of the Smooth Series. Then there are those sweet cravings — and trust us, the Sweet Series delivers.
Prefer the classic richness of tobacco? There’s a whole series for that too. And if you’re trying to cut back on nicotine, the Nicotine-Free Range gives you all the flavor without the buzz.
Final Thoughts
Vaping in Singapore isn’t just a passing trend — it’s a lifestyle choice for many. With so many options available, from pocket-sized disposables to customizable devices, there’s something for everyone. Whether you’re new to the scene , or an experienced user , the experience is all about what feels right to you — made personal for you.
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Изучить вопрос глубже – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя круглосуточно[/url]
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя цена архангельская область[/url]
For more information [url=https://up-top.ru]https://up-top.ru[/url] .
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-msk55.ru/]капельница от запоя на дому одинцово[/url]
такой https://mgmarket6.cc
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Детальнее – http://narcolog-na-dom-v-moskve55.ru
Создание безопасной среды: Мы понимаем, насколько важна поддержка в сложные моменты. Наш центр предоставляет пространство, где пациенты могут открыто говорить о своих переживаниях без страха быть осужденными, что способствует доверию и успешному лечению.
Разобраться лучше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя на дому круглосуточно в казани[/url]
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Получить дополнительные сведения – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя на дому цена[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Детальнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя на дому республика татарстан[/url]
We’re excited to announce a new DeFi project: a transaction aggregator that connects lending protocols, liquidity pools, and DeFi AI to provide cheaper routes and better yields. Our plan is to integrate as an alternative to 1inch, ThorChain, and other top aggregators, potentially serving as the “under-the-hood” engine for the top 10 crypto wallets.
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet account[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet avax swap[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet dai faucet[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnet ether[/url]
[url=https://telegra.ph/Help-Us-Collect-Testnet-Tokens–Win-3000-01-25]testnetbybitcon[/url]
Testnet Tokens
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Ознакомиться с деталями – [url=https://narcolog-na-dom-v-moskve55.ru/]vyzov vracha narkologa na dom[/url]
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя выезд[/url]
why not try this out [url=https://jaxx.network]jaxx wallet download[/url]
[url=https://betandreas-casino-apk.ru]betandreas-casino-apk.ru[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать приложение betandreas казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
betandreas-casino-apk.ru
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Получить дополнительные сведения – https://narcolog-na-dom-v-moskve55.ru/vyzov-narkologa-na-dom-v-krasnogorske/
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Подробнее – [url=https://kapelnica-ot-zapoya-msk55.ru/]вызвать капельницу от запоя[/url]
Возможность назначить визит специалиста в наиболее удобное время. Это позволяет эффективно совмещать лечение с работой и повседневными делами. Такая гибкость помогает пациентам своевременно начать терапию, не откладывая ее из-за занятости. При необходимости врач может приехать в вечернее время или выходные дни.
Подробнее – [url=https://narcolog-na-dom-msk55.ru/]нарколог на дом москва[/url]
betwinner app login [url=http://betswinner.bet]betwinner app login[/url] .
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя на дому круглосуточно[/url]
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]врача капельницу от запоя в луганске[/url]
והתכרבלה על כיסא עם סרטן, החלה לאט לאט להכניס מקלט טלפון לפי הטבעת שלה, אותו לקחה משולחן יד של נשים, שתלוי על הרצועה על הכתף כך שהארנק עצמו נמצא בערך בגובה הגב התחתון. וזה חייב לקרות ליווי אילת
visit their website [url=https://jaxx.network]jaxx wallet chrome[/url]
При поступлении вызова нарколог незамедлительно приезжает на дом для проведения тщательного осмотра. Врач измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации.
Получить больше информации – https://kapelnica-ot-zapoya-arkhangelsk0.ru/kapelnicza-ot-zapoya-na-domu-arkhangelsk/
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя анонимно[/url]
big balloons dubai balloons dubai birthday
resume engineering fresher resume engineer experienced
is betwinner safe [url=betswinner.bet]is betwinner safe[/url] .
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя капельница[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-msk55.ru/]kapelnitsy ot zapoia na domu[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Углубиться в тему – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]http://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-anonimno-v-kazani.ru/[/url]
Возможность назначить визит специалиста в наиболее удобное время. Это позволяет эффективно совмещать лечение с работой и повседневными делами. Такая гибкость помогает пациентам своевременно начать терапию, не откладывая ее из-за занятости. При необходимости врач может приехать в вечернее время или выходные дни.
Подробнее тут – [url=https://narcolog-na-dom-msk55.ru/]вызов врача нарколога на дом[/url]
In today’s fast-paced world, staying informed about the latest advancements both locally and globally is more essential than ever. With a plethora of news outlets competing for attention, it’s important to find a reliable source that provides not just news, but perspectives, and stories that matter to you. This is where [url=https://www.usatoday.com/]USAtoday.com [/url], a top online news agency in the USA, stands out. Our dedication to delivering the most current news about the USA and the world makes us a primary resource for readers who seek to stay ahead of the curve.
Subscribe for Exclusive Content: By subscribing to USAtoday.com, you gain access to exclusive content, newsletters, and updates that keep you ahead of the news cycle.
[url=https://www.usatoday.com/]USAtoday.com [/url] is not just a news website; it’s a dynamic platform that empowers its readers through timely, accurate, and comprehensive reporting. As we navigate through an ever-changing landscape, our mission remains unwavering: to keep you informed, engaged, and connected. Subscribe to us today and become part of a community that values quality journalism and informed citizenship.
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Получить больше информации – [url=https://narcolog-na-dom-v-moskve55.ru/]вызов нарколога на дом красногорск[/url]
Вызов нарколога на дом в таких условиях позволяет не терять драгоценное время, избежать госпитализации и предотвратить критическое развитие событий. Кроме того, это снижает психологическую нагрузку на пациента и его близких, особенно если зависимость длится долго и сопровождается отрицанием проблемы.
Разобраться лучше – https://narcolog-na-dom-v-moskve55.ru/vyzov-narkologa-na-dom-v-krasnogorske
הבת נרתעה בהתחלה בפחד, אבל אחרי זמן מה היא זרקה את החלוק על הרצפה. לא היה לה כלום מתחת אני יודע. אבל זה אפילו לא עצר אותי לרגע. מיד שמתי את הזין שלי על הכוס שלה. איזו כלבה את. אתה נערות ליווי עד הבית
В современном обществе проблемы наркомании и алкоголизма приобрели особую актуальность, затрагивая не только отдельных людей, но и их близких, и сообщества. Эти зависимости оказывают негативное влияние не только на физическое здоровье, но и на психоэмоциональное состояние, нарушают социальные связи и ухудшают качество жизни. Наркологическая клиника “Здоровое Настоящее” предлагает комплексный и научно обоснованный подход к лечению зависимостей. Мы используем современные методы диагностики и терапии, чтобы помочь пациентам вернуть здоровье и полноценную жизнь.
Получить дополнительную информацию – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]narkolog-vyvod-iz-zapoya kazan'[/url]
החלה ללטף את הדגדגן שלה באצבע, לאט לאט טבעה את האצבע השנייה בתוך החריץ הטעים שלה. הכוס שלה טבעיות, “אמר הדוד ג’ נה. אמא שלי הביטה בי מדי פעם בעיניים, לפעמים בעיניים של ליהי, ואז בדודה read
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]vyzvat-kapelniczu-ot-zapoya arhangel’sk[/url]
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Подробнее тут – [url=https://kapelnica-ot-zapoya-msk55.ru/]postavit kapelnitsu ot zapoia odintsovo[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Получить дополнительную информацию – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя на дому[/url]
[url=https://boom-casino-apk.ru]boom-casino-apk.ru[/url]
По ссылке ниже — полезный гайд по игре в казино boom. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
boom-casino-apk.ru
Возможность назначить визит специалиста в наиболее удобное время. Это позволяет эффективно совмещать лечение с работой и повседневными делами. Такая гибкость помогает пациентам своевременно начать терапию, не откладывая ее из-за занятости. При необходимости врач может приехать в вечернее время или выходные дни.
Получить больше информации – [url=https://narcolog-na-dom-msk55.ru/]врач нарколог на дом[/url]
[url=https://bollywood-casino-apk.ru]bollywood-casino-apk.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино bollywood в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.bollywood-casino-apk.ru
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-msk55.ru/]https://kapelnica-ot-zapoya-msk55.ru[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Подробнее можно узнать тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-kazani.ru/]вывод из запоя капельница казань[/url]
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Узнать больше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя капельница[/url]
Процесс лечения капельничным методом от запоя организован по четко структурированной схеме, позволяющей обеспечить оперативное и безопасное восстановление организма.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя анонимно архангельск[/url]
important site [url=https://archetyp-darknet-market.com]Polskie strony cebulowe[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Разобраться лучше – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя недорого[/url]
Отсутствие визитов в клинику гарантирует полную конфиденциальность. Это особенно важно для пациентов, беспокоящихся о своей репутации или возможном влиянии на профессиональную деятельность. Вызов врача на дом полностью исключает нежелательные встречи в медицинском центре.
Подробнее тут – https://narcolog-na-dom-msk55.ru/
Наркологическая клиника «Новый шанс» — это специализированное учреждение, которое предоставляет профессиональную помощь людям, страдающим от алкогольной и наркотической зависимости. Наша цель — предложить эффективные методы лечения и всестороннюю поддержку, чтобы помочь пациентам преодолеть зависимость и вернуть контроль над своей жизнью.
Получить больше информации – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-rostove-na-donu.ru/]вывод из запоя на дому круглосуточно в ростове-на-дону[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя анонимно[/url]
красное море температура воды
аккаунты warface В мире онлайн-шутеров Warface занимает особое место, привлекая миллионы игроков своей динамикой, разнообразием режимов и возможностью совершенствования персонажа. Однако, не каждый готов потратить месяцы на прокачку аккаунта, чтобы получить желаемое оружие и экипировку. В этом случае, покупка аккаунта Warface становится привлекательным решением, открывающим двери к новым возможностям и впечатлениям.
היה מכוסה בליטות אווז, ובין רגליה היה לח יותר ויותר. עיניה נעצמו, ראשה נשען לאחור, ירכיה נעו ופפילות ורדרדות קטנות, אבל עם שלל אלסטי מצוין. לאחר שהתפשטה על השולחן, טניושה החלה ללטף את read review
В динамичном мире Санкт-Петербурга, где каждый день кипит жизнь и совершаются тысячи сделок, актуальная и удобная доска объявлений становится незаменимым инструментом как для частных лиц, так и для предпринимателей. Наша платформа – это ваш надежный партнер в поиске и предложении товаров и услуг в Северной столице. Объявления чистка дымоходов в СПб
После оформления заявки на сайте narcolog-na-dom-v-moskve55.ru или по телефону, оператор уточняет информацию о пациенте: возраст, длительность запоя, наличие хронических заболеваний, текущее самочувствие. В течение 30–60 минут дежурный специалист приезжает по адресу с полным комплектом оборудования и медикаментов.
Подробнее тут – https://narcolog-na-dom-v-moskve55.ru/narkolog-na-dom-anonimno-v-krasnogorske
шкаф в паркинг цена [url=http://superogorod.ucoz.org/forum/2-3656-1#12027]шкаф в паркинг цена[/url] .
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Детальнее – [url=https://kapelnica-ot-zapoya-msk55.ru/]kapelnitsa ot zapoia odintsovo[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Получить дополнительные сведения – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]наркология вывод из запоя казань[/url]
Медикаментозное лечение: Мы применяем современные препараты, которые помогают облегчить симптомы абстиненции и улучшить состояние пациентов в первые дни лечения. Индивидуальный подбор лекарственных схем позволяет минимизировать побочные эффекты и достичь наилучших результатов.
Исследовать вопрос подробнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя на дому круглосуточно казань[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-msk55.ru/]https://kapelnica-ot-zapoya-msk55.ru/[/url]
При тяжелой алкогольной интоксикации оперативное лечение становится жизненно необходимым для спасения здоровья. В Архангельске специалисты оказывают помощь на дому, используя метод капельничного лечения от запоя. Такой подход позволяет быстро вывести токсины, восстановить обмен веществ и стабилизировать работу внутренних органов, обеспечивая при этом высокий уровень конфиденциальности и комфорт в условиях привычного домашнего уюта.
Выяснить больше – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]kapelnica-ot-zapoya-arkhangelsk0.ru/[/url]
На этом этапе специалист уточняет продолжительность запоя, тип употребляемого алкоголя и наличие сопутствующих заболеваний, что позволяет разработать персонализированный план терапии и оперативно выбрать методы детоксикации.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]капельница от запоя наркология в архангельске[/url]
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Получить дополнительные сведения – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]нарколог вывод из запоя в казани[/url]
Наши наркологи придерживаются принципов уважительного и чуткого отношения, что создаёт атмосферу доверия. Специалисты проводят детальную диагностику, выявляют причины зависимости и разрабатывают персональные стратегии лечения. Компетентность и профессионализм врачей — залог успешного восстановления пациентов.
Получить больше информации – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-rostove-na-donu.ru/]вывод из запоя анонимно[/url]
Миссия нашего центра – оказание всесторонней помощи людям с зависимостями. Основные цели нашей работы:
Углубиться в тему – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя цена казань.[/url]
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Подробнее – https://narcolog-na-dom-v-moskve55.ru
The underlying AI-powered Интернет3 information programme you need to turn terabytes of unstructured information into actional insights.
Get 150 USDT tip on all users who put to use Desktop Adaptation 2 weeks!
DEMO APPROPRIATE FOR WINDOWS
OMIT 50%
PURCHASE NOW!
[url=https://desktop.bonus-kaitoyaps.com/]Кайто AI[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito AI project[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Web3 content rewards[/url]
[url=https://desktop.bonus-kaitoyaps.com/]AI-powered crypto insights[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Yap Points rewards[/url]
Kaito ai concoct
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Получить больше информации – https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru
Лечебные мероприятия и рекомендации формируются исходя из индивидуального состояния каждого пациента. Специалист имеет возможность посвятить достаточное количество времени каждому больному, корректируя программу лечения согласно его особым потребностям и жизненным обстоятельствам. При этом учитываются психологические, социальные и физические аспекты, оказывающие влияние на здоровье пациента. Персонализированный подход обеспечивает оперативное реагирование на изменения состояния и своевременную корректировку терапии.
Изучить вопрос глубже – http://narcolog-na-dom-msk55.ru/narkolog-na-dom-moskva-tseny/
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Углубиться в тему – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]вывод из запоя цена казань[/url]
Проведение лечения в домашней обстановке значительно снижает уровень стресса и тревожности. Пациенту не нужно тратить силы на поездки в медицинские учреждения, что особенно важно при ограниченной мобильности. Домашняя атмосфера создает идеальные условия для открытого диалога с врачом, что существенно повышает эффективность терапии и шансы на успешное выздоровление.
Получить больше информации – [url=https://narcolog-na-dom-msk55.ru/]нарколог на дом москва[/url]
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Ознакомиться с деталями – https://narcolog-na-dom-v-moskve55.ru/narkolog-na-dom-anonimno-v-krasnogorske
Why Choose DDoS.Market?
High-Quality Attacks – Our team ensures powerful and effective DDoS attacks for accurate security testing.
Competitive Pricing & Discounts – We offer attractive deals for returning customers.
Trusted Reputation – Our service has earned credibility in the Dark Web due to reliability and consistent performance.
Who Needs This?
Security professionals assessing network defenses.
Businesses conducting penetration tests.
IT administrators preparing for real-world threats.
Vaping in Singapore: More Than Just a Trend
In today’s fast-paced world, people are always looking for ways to unwind, relax, and enjoy the moment — and for many, vaping has become a daily habit. In Singapore, where modern life moves quickly, the rise of vaping culture has brought with it a unique form of downtime . It’s not just about the devices or the clouds of vapor — it’s about flavor, convenience, and finding your own vibe.
Disposable Vapes: Simple, Smooth, Ready to Go
Let’s face it — nobody wants to deal with complicated setups all the time. That’s where disposable vapes shine. They’re perfect for busy individuals who still want that satisfying hit without the hassle of charging, refilling, or replacing parts.
Popular models like the VAPETAPE UNPLUG / OFFGRID, LANA ULTRA II, and SNOWWOLF SMART HD offer thousands of puffs in one sleek little package . Whether you’re out for the day or just need something quick and easy, these disposables have got your back.
New Arrivals: Fresh Gear, Fresh Experience
The best part about being into vaping? There’s always something new around the corner. The latest releases like the ELFBAR ICE KING and ALADDIN ENJOY PRO MAX bring something different to the table — whether it’s enhanced user experience.
The ELFBAR RAYA D2 is another standout, offering more than just puff count — it comes with adjustable airflow , so you can really make it your own.
Bundles: Smart Choices for Regular Vapers
If you vape often, buying in bulk just makes sense. Combo packs like the VAPETAPE OFFGRID COMBO or the LANA BAR 10 PCS COMBO aren’t just practical — they’re also a smart investment . No more running out at the worst time, and you save a bit while you’re at it.
Flavors That Speak to You
At the end of the day, it’s all about taste. Some days you want something icy and refreshing from the Cold Series, other times you’re craving the smooth, mellow vibes of the Smooth Series. Then there are those sweet cravings — and trust us, the Sweet Series delivers.
Prefer the classic richness of tobacco? There’s a whole series for that too. And if you’re trying to cut back on nicotine, the Nicotine-Free Range gives you all the flavor without the buzz.
Final Thoughts
Vaping in Singapore isn’t just a passing trend — it’s a lifestyle choice for many. With so many options available, from pocket-sized disposables to customizable devices, there’s something for everyone. Whether you’re exploring vaping for the first time , or an experienced user , the experience is all about what feels right to you — made personal for you.
The Rise of Vaping in Singapore: Not Just a Fad
In today’s fast-paced world, people are always looking for ways to unwind, relax, and enjoy the moment — and for many, vaping has become a daily habit. In Singapore, where modern life moves quickly, the rise of vaping culture has brought with it a new kind of chill . It’s not just about the devices or the clouds of vapor — it’s about flavor, convenience, and finding your own vibe.
Disposable Vapes: Simple, Smooth, Ready to Go
Let’s face it — nobody wants to deal with complicated setups all the time. That’s where disposable vapes shine. They’re perfect for users who want instant satisfaction who still want that satisfying hit without the hassle of charging, refilling, or replacing parts.
Popular models like the VAPETAPE UNPLUG / OFFGRID, LANA ULTRA II, and SNOWWOLF SMART HD offer thousands of puffs in one sleek little package . Whether you’re out for the day or just need something quick and easy, these disposables have got your back.
New Arrivals: Fresh Gear, Fresh Experience
The best part about being into vaping? There’s always something new around the corner. The latest releases like the ELFBAR ICE KING and ALADDIN ENJOY PRO MAX bring something different to the table — whether it’s smarter designs .
The ELFBAR RAYA D2 is another standout, offering more than just puff count — it comes with a built-in screen , so you can really make it your own.
Bundles: Smart Choices for Regular Vapers
If you vape often, buying in bulk just makes sense. Combo packs like the VAPETAPE OFFGRID COMBO or the LANA BAR 10 PCS COMBO aren’t just practical — they’re also a better deal . No more running out at the worst time, and you save a bit while you’re at it.
Flavors That Speak to You
At the end of the day, it’s all about taste. Some days you want something icy and refreshing from the Cold Series, other times you’re craving the smooth, mellow vibes of the Smooth Series. Then there are those sweet cravings — and trust us, the Sweet Series delivers.
Prefer the classic richness of tobacco? There’s a whole series for that too. And if you’re trying to cut back on nicotine, the 0% Nicotine Series gives you all the flavor without the buzz.
Final Thoughts
Vaping in Singapore isn’t just a passing trend — it’s a lifestyle choice for many. With so many options available, from pocket-sized disposables to customizable devices, there’s something for everyone. Whether you’re new to the scene , or an experienced user , the experience is all about what feels right to you — your way, your flavor, your style .
После оформления заявки на сайте narcolog-na-dom-v-moskve55.ru или по телефону, оператор уточняет информацию о пациенте: возраст, длительность запоя, наличие хронических заболеваний, текущее самочувствие. В течение 30–60 минут дежурный специалист приезжает по адресу с полным комплектом оборудования и медикаментов.
Подробнее – [url=https://narcolog-na-dom-v-moskve55.ru/]нарколог на дом срочно[/url]
На месте врач проводит первичный осмотр, измеряет давление, пульс, сатурацию, оценивает уровень интоксикации и абстиненции. Далее назначается инфузионная терапия — капельница, направленная на дезинтоксикацию, восстановление электролитного баланса, купирование тревожности и нормализацию сна.
Ознакомиться с деталями – [url=https://narcolog-na-dom-v-moskve55.ru/]narcolog-na-dom-v-moskve55.ru/[/url]
цена на шкаф в паркинг [url=http://www.dubna.myqip.ru/?1-2-0-00000215-000-0-0]цена на шкаф в паркинг[/url] .
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее тут – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя[/url]
Миссия клиники — способствовать восстановлению здоровья и социальной адаптации людей, столкнувшихся с зависимостью. Мы подходим к проблеме комплексно, учитывая не только физические, но и психологические и социальные аспекты зависимости. Наша задача — не только помочь избавиться от пагубного влечения, но и обеспечить успешное возвращение пациентов к полноценной жизни в обществе.
Углубиться в тему – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя на дому ростов-на-дону.[/url]
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому[/url]
Обращение за капельничной терапией от запоя в домашних условиях имеет множество преимуществ, среди которых:
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя на дому луганск.[/url]
The underlying AI-powered Web3 information podium you be in want of to end up terabytes of unstructured word into actional insights.
Get 150 USDT largesse on all users who use Desktop Adaptation 2 weeks!
DEMO APPROPRIATE FOR WINDOWS
LESSEN 50%
BUY OFF THINGS BEING WHAT THEY ARE!
[url=https://desktop.bonus-kaitoyaps.com/]Web3 content rewards[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Yap Points система[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Кайто AI[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Монетизация твитов про крипту[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Decentralized attention economy[/url]
Kaito ai assignment
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-v-moskve55.ru/]vrach narkolog na dom krasnogorsk[/url]
Капельничное лечение от запоя – это современный метод детоксикации, который позволяет быстро и безопасно вывести токсины из организма. В Луганске ЛНР специалисты оказывают помощь на дому, предлагая профессиональное капельничное лечение для тех, кто столкнулся с тяжелой алкогольной интоксикацией. Такой подход обеспечивает оперативное вмешательство в привычной для пациента обстановке, гарантируя индивидуальный подход и полную конфиденциальность.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя цена в луганске[/url]
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Профессиональный вывод из запоя на дому в Луганске ЛНР организован по отлаженной схеме, которая включает несколько этапов, позволяющих обеспечить максимально безопасное и эффективное лечение.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-lugansk-lnr0.ru/]капельница от запоя выезд в луганске[/url]
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Получить дополнительные сведения – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]вывод из запоя на дому республика татарстан[/url]
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Выяснить больше – [url=https://vyvod-iz-zapoya-sochi17.ru/]вывод из запоя цена[/url]
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Изучить вопрос глубже – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]вывод из запоя на дому круглосуточно ростов-на-дону[/url]
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Подробнее тут – https://moroccanpouf.ca/create-a-cozy-reading-nook-with-a-moroccan-pouf
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Выяснить больше – https://harmonybyagas.com/producto/agressive-anti-aging-program-6-productos
Наши врачи оперативно приезжают к пациенту, проводят осмотр, купируют симптомы абстиненции и приступают к восстановлению жизненно важных функций. Всё это — в привычной для пациента обстановке, без стресса и лишней огласки. Мы обеспечиваем не только медицинскую помощь, но и эмоциональную поддержку, создавая условия для начала пути к выздоровлению.
Углубиться в тему – https://narcolog-na-dom-v-moskve55.ru/narkolog-na-dom-anonimno-v-krasnogorske
После оформления заявки на сайте narcolog-na-dom-v-moskve55.ru или по телефону, оператор уточняет информацию о пациенте: возраст, длительность запоя, наличие хронических заболеваний, текущее самочувствие. В течение 30–60 минут дежурный специалист приезжает по адресу с полным комплектом оборудования и медикаментов.
Получить больше информации – [url=https://narcolog-na-dom-v-moskve55.ru/]platnyi narkolog na dom[/url]
Услуги массажа Ивантеевка — здоровье, отдых и красота. Лечебный, баночный, лимфодренажный, расслабляющий и косметический массаж. Сертифицированнй мастер, удобное расположение, результат с первого раза.
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Детальнее – https://www.visitroseto.info/the-newest-part-of-team-2
The underlying AI-powered Web3 information podium you need to turn terabytes of unstructured dirt into actional insights.
Get 150 USDT extra on all users who abuse Desktop Manifestation 2 weeks!
DEMO SEEKING WINDOWS
DISCOUNT 50%
BUY OFF NOW!
[url=https://desktop.bonus-kaitoyaps.com/]Kaito AI project[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Top crypto yappers[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito токеномика[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito social mining[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Top crypto yappers[/url]
Kaito ai assignment
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Изучить вопрос глубже – https://funeral-agency.wwwbg.in/kontakti
betwinner withdrawal rules [url=https://www.betswinner.bet]betwinner withdrawal rules[/url] .
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Подробнее можно узнать тут – https://coloredelephant.com/uncategorized/hello-world
Изучите taktychni-rukavyci.netlify.app для новых идей, данный ресурс.
Погрузитесь в мир информатики с taktychni-rukavyci.netlify.app, советуем.
Найдите новые идеи на taktychni-rukavyci.netlify.app, не упустите возможность.
Будьте в курсе современных технологий с taktychni-rukavyci.netlify.app, ознакомиться.
Погрузитесь в мир технологий с taktychni-rukavyci.netlify.app, рекомендуем.
taktychni-rukavyci.netlify.app – для тех, кто ищет, изучить.
Увлекательные факты на taktychni-rukavyci.netlify.app, не упустите.
taktychni-rukavyci.netlify.app: инновации и технологии, не пропустите.
taktychni-rukavyci.netlify.app – это ваш шаг в будущее, рекомендуем.
taktychni-rukavyci.netlify.app – научные открытия и технологии, не пропустите.
купити рукавички тактичні [url=https://taktychni-rukavyci.netlify.app/]https://taktychni-rukavyci.netlify.app/[/url] .
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Получить дополнительную информацию – https://lisamedibeauty.com/phuong-phap-nang-co-mi-mat
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Разобраться лучше – https://youtrading.com/ru/didi-budet-luchshe-uber
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Получить дополнительную информацию – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом анонимно в мариуполе[/url]
После диагностики начинается активная фаза медикаментозного вмешательства. Современные препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, восстановления обменных процессов и нормализации работы внутренних органов, таких как печень, почки и сердце.
Детальнее – [url=https://kapelnica-ot-zapoya-arkhangelsk0.ru/]после капельницы от запоя в архангельске[/url]
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Подробнее – http://narcolog-na-dom-mariupol00.ru
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Разобраться лучше – [url=https://narcolog-na-dom-mariupol00.ru/]запой нарколог на дом в мариуполе[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]центр кодирования от алкоголизма[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Изучить вопрос глубже – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
температура воды в хургаде в апреле
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Получить дополнительную информацию – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]srochnyj-vyvod-iz-zapoya.ru/[/url]
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Подробнее – [url=https://lechenie-alkogolizma-voronezh9.ru/]центр лечения алкоголизма воронеж.[/url]
Дамски комплекти за преходните сезони с дълъг ръкав и леки материи
дамски комплекти [url=https://komplekti-za-jheni.com/]дамски комплекти[/url] .
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Углубиться в тему – http://vyvod-iz-zapoya-krasnogorsk2.ru/
После снятия острых симптомов пациент продолжает получать медикаментозную поддержку. Назначаются витамины, гепатопротекторы, успокоительные препараты. Проводится психологическая диагностика для подготовки к следующему этапу — реабилитации.
Детальнее – https://lechenie-alkogolizma-voronezh9.ru/
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-ufa9.ru/]платная наркологическая клиника[/url]
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Углубиться в тему – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Исследовать вопрос подробнее – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Rainbet referral code ILBET В мире онлайн-гемблинга Rainbet сияет как яркая звезда, привлекая игроков своими щедрыми предложениями и захватывающими играми. Промокод ILBET – это ваш билет в этот мир возможностей, предоставляющий доступ к эксклюзивным бонусам и акциям, разработанным для повышения вашего игрового опыта и увеличения шансов на победу.
Процесс оказания срочной помощи нарколога на дому в Мариуполе построен по отлаженной схеме, которая включает несколько ключевых этапов, направленных на быстрое и безопасное восстановление здоровья пациента.
Углубиться в тему – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом анонимно мариуполь[/url]
Клиническая практика показывает: только системная работа с пациентом даёт устойчивый результат. Программа включает медицинское, психологическое и социальное сопровождение.
Детальнее – http://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh/
[url=https://kappa.trancereality.mk.ua]Kappa Stage[/url] — це подія, яку варто пережити. Ви не просто будете слухати музику, ви станете її частиною!
monkey mart
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя капельница казань[/url]
Generate custom ai hentai generator. Create anime-style characters, scenes, and fantasy visuals instantly using an advanced hentai generator online.
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Подробнее тут – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya na domu krasnogorsk[/url]
Ключевым направлением работы является индивидуальный подход к лечению. Мы понимаем уникальность каждого пациента и начинаем с тщательной диагностики, изучая медицинскую историю, психологические особенности и социальные факторы. На основе этих данных разрабатываются персонализированные планы лечения, включающие медикаментозную терапию, психотерапевтические программы и социальные инициативы.
Исследовать вопрос подробнее – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-rostove-na-donu.ru/]вывод из запоя круглосуточно ростов-на-дону[/url]
После первичной диагностики начинается активная фаза медикаментозного вмешательства. Препараты вводятся капельничным методом для быстрого снижения уровня токсинов в крови, нормализации обменных процессов и стабилизации работы внутренних органов, таких как печень, почки и сердце.
Разобраться лучше – [url=https://narcolog-na-dom-mariupol00.ru/]вызов нарколога на дом мариуполь[/url]
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить больше информации – http://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu/https://vyvod-iz-zapoya-krasnogorsk2.ru
https://gonzo-casino.pl/
Миссия клиники — способствовать восстановлению здоровья и социальной адаптации людей, столкнувшихся с зависимостью. Мы подходим к проблеме комплексно, учитывая не только физические, но и психологические и социальные аспекты зависимости. Наша задача — не только помочь избавиться от пагубного влечения, но и обеспечить успешное возвращение пациентов к полноценной жизни в обществе.
Выяснить больше – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]tajno-vyvod-iz-zapoya.ru/[/url]
Great post. I was checking continuously this blog and I am impressed! Very helpful information particularly the last part 🙂 I care for such info a lot. I was looking for this particular info for a very long time. Thank you and good luck.
Алкогольная зависимость разрушает здоровье, семью, карьеру и личность. Чем раньше будет оказана профессиональная помощь, тем выше шансы на восстановление и возвращение к полноценной жизни. Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости позволяет справляться не только с физической тягой, но и с глубинными причинами, которые провоцируют патологическое употребление.
Получить больше информации – https://lechenie-alkogolizma-voronezh9.ru/czentr-lecheniya-alkogolizma-voronezh/
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Углубиться в тему – [url=https://narkologicheskaya-klinika-ufa9.ru/]narkologicheskie kliniki alkogolizm ufa[/url]
gonzo casino
Что входит в типовой проект при строительстве деревянного дома
деревянное строительство домов [url=https://stroitelstvo-derevyannyh-domov78.ru/]деревянное строительство домов[/url] .
Для комплексного восстановления мы предлагаем ряд вспомогательных процедур, которые улучшают самочувствие и ускоряют реабилитацию.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм в уфе[/url]
Я відвідав [url=https://kappa.trancereality.mk.ua]Kappa Stage[/url] і це було щось неймовірне! Тут можна відчути музику кожною клітинкою тіла.
vape supplier singapore
Vaping in Singapore: More Than Just a Trend
In today’s fast-paced world, people are always looking for ways to unwind, relax, and enjoy the moment — and for many, vaping has become a preferred method . In Singapore, where modern life moves quickly, the rise of vaping culture has brought with it a new kind of chill . It’s not just about the devices or the clouds of vapor — it’s about flavor, convenience, and finding your own vibe.
Disposable Vapes: Simple, Smooth, Ready to Go
Let’s face it — nobody wants to deal with complicated setups all the time. That’s where disposable vapes shine. They’re perfect for those who value simplicity who still want that satisfying hit without the hassle of charging, refilling, or replacing parts.
Popular models like the VAPETAPE UNPLUG / OFFGRID, LANA ULTRA II, and SNOWWOLF SMART HD offer thousands of puffs in one compact design . Whether you’re out for the day or just need something quick and easy, these disposables have got your back.
New Arrivals: Fresh Gear, Fresh Experience
The best part about being into vaping? There’s always something new around the corner. The latest releases like the ELFBAR ICE KING and ALADDIN ENJOY PRO MAX bring something different to the table — whether it’s smarter designs .
The ELFBAR RAYA D2 is another standout, offering more than just puff count — it comes with a built-in screen , so you can really make it your own.
Bundles: Smart Choices for Regular Vapers
If you vape often, buying in bulk just makes sense. Combo packs like the VAPETAPE OFFGRID COMBO or the LANA BAR 10 PCS COMBO aren’t just practical — they’re also a better deal . No more running out at the worst time, and you save a bit while you’re at it.
Flavors That Speak to You
At the end of the day, it’s all about taste. Some days you want something icy and refreshing from the Cold Series, other times you’re craving the smooth, mellow vibes of the Smooth Series. Then there are those sweet cravings — and trust us, the Sweet Series delivers.
Prefer the classic richness of tobacco? There’s a whole series for that too. And if you’re trying to cut back on nicotine, the Zero-Nicotine Line gives you all the flavor without the buzz.
Final Thoughts
Vaping in Singapore isn’t just a passing trend — it’s a lifestyle choice for many. With so many options available, from pocket-sized disposables to customizable devices, there’s something for everyone. Whether you’re taking your first puff, or a long-time fan, the experience is all about what feels right to you — tailored to your preferences .
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Выяснить больше – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя анонимно в казани[/url]
Лечение алкоголизма в Воронеже — помощь на всех стадиях зависимости особенно важно на этапе, когда у человека ещё сохраняется мотивация к изменениям. Но даже при тяжёлых формах зависимости шанс на выздоровление сохраняется — при условии комплексного подхода.
Подробнее – http://lechenie-alkogolizma-voronezh9.ru/
nettruyen
Кроме того, клиника «Новый шанс» уделяет особое внимание профилактике рецидивов. Мы обучаем пациентов навыкам управления стрессом, эмоциональной регуляции и прививаем навыки здорового образа жизни. Наша цель — обеспечить долгосрочное восстановление и снизить риск возврата к зависимости.
Углубиться в тему – [url=https://tajno-vyvod-iz-zapoya.ru/]нарколог вывод из запоя[/url]
Незамедлительно после вызова нарколог прибывает на дом для проведения первичного осмотра. Специалист измеряет жизненно важные показатели, такие как пульс, артериальное давление и температура, а также собирает анамнез, чтобы определить степень алкогольной интоксикации. Эта информация позволяет оперативно разработать персонализированный план лечения.
Подробнее – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом вывод мариуполь[/url]
After all, what a great site and informative posts, I will upload inbound link – bookmark this web site? Regards, Reader.
[url=https://azino777-casino-apk.ru]azino777-casino-apk.ru[/url]
Всем привет!
Нашёл для вас кое-что интересное, особенно для тех, кто фанатеет от казино azino777. По ссылке можно узнать все подробности о том, как скачать это казино.
В статье, скорее всего, расскажут о способах скачивания для разных устройств, особенностях установки и, возможно, о бонусах, которые можно получить после установки.
azino777-casino-apk.ru
The ultimate AI-powered Web3 knowledge programme you need to balk terabytes of unstructured information into actional insights.
Get 150 USDT tip on all users who put to use Desktop Version 2 weeks!
DEMO FOR WINDOWS
OMIT 50%
BUY THINGS BEING WHAT THEY ARE!
[url=https://desktop.bonus-kaitoyaps.com/]AI-powered crypto insights[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito AI проект[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Монетизация твитов про крипту[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Yap Points система[/url]
[url=https://desktop.bonus-kaitoyaps.com/]AI-powered crypto insights[/url]
Kaito ai concoct
Всё о городе городской портал города Ханты-Мансийск: свежие новости, события, справочник, расписания, культура, спорт, вакансии и объявления на одном городском портале.
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Получить больше информации – http://
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Ознакомиться с деталями – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя в казани[/url]
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Получить дополнительные сведения – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]вывод из запоя круглосуточно в казани[/url]
blog here [url=https://thecoinb-se.com/]coinbase pro login[/url]
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить дополнительные сведения – https://www.meincreative.at/example-post-2
You actually make it appear so easy along with your presentation but I find this matter to be really one thing which I feel I’d by no means understand. It kind of feels too complicated and extremely wide for me. I am having a look ahead for your subsequent publish, I?¦ll try to get the dangle of it!
Когда состояние алкогольной интоксикации достигает критических уровней, своевременное вмешательство становится жизненно необходимым. В Мариуполе, Донецкая область, высококвалифицированные наркологи оказывают срочную помощь на дому, позволяя оперативно начать детоксикацию и стабилизировать состояние пациента. Такой формат лечения обеспечивает быстрый выход из кризиса в условиях комфорта и конфиденциальности, что особенно важно для тех, кто не может позволить себе задержки в стационарном лечении.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-mariupol00.ru/]нарколог на дом цена мариуполь[/url]
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее тут – https://freie-filmwerkstatt.de/archive/podcast/s04e02-von-der-hfs-zur-filmwerkstatt
chicken road 2025 Chicken Road: Взлеты и Падения на Пути к Успеху Chicken Road – это не просто развлечение, это обширный мир возможностей и тактики, где каждое решение может привести к невероятному взлету или полному краху. Игра, доступная как в сети, так и в виде приложения для мобильных устройств (Chicken Road apk), предлагает пользователям проверить свою фортуну и чутье на виртуальной “куриной тропе”. Суть Chicken Road заключается в преодолении сложного маршрута, полного ловушек и опасностей. С каждым успешно пройденным уровнем, награда растет, но и увеличивается шанс неудачи. Игроки могут загрузить Chicken Road game demo, чтобы оценить механику и особенности геймплея, прежде чем рисковать реальными деньгами.
Каждый врач клиники обладает глубокими знаниями в области фармакологии, психофармакологии и психотерапии, посещает профессиональные конференции и семинары, следит за достижениями в области лечения зависимостей. Такой подход позволяет применять наиболее эффективные и современные методы.
Углубиться в тему – [url=https://tajno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-rostove-na-donu.ru/]наркология вывод из запоя в ростове-на-дону[/url]
The remotest AI-powered Интернет3 information principles you poverty to balk terabytes of unstructured word into actional insights.
Fit out 150 USDT extra on all users who utilize consume Desktop Adaptation 2 weeks!
DEMO PAYMENT WINDOWS
DISCOUNT 50%
BUY THINGS BEING WHAT THEY ARE!
[url=https://desktop.bonus-kaitoyaps.com/]Web3 content rewards[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito token airdrop[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito social mining[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito AI проект[/url]
[url=https://desktop.bonus-kaitoyaps.com/]Kaito token airdrop[/url]
Kaito ai concoct
top article [url=https://thecoinb-se.com/]coinbase login[/url]
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Исследовать вопрос подробнее – https://friss.in/top-5-tips-to-avoid-laptop-crash
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Изучить вопрос глубже – https://maerkteundtrends.de/rhythms-of-life-embracing-change-with-grace
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Углубиться в тему – https://hajjcompanions.com/understanding-the-different-types-of-hajj-packages-for-us-pilgrims
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт холодильников gorenje цены, можете посмотреть на сайте: ремонт холодильников gorenje сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Подробнее тут – https://hutbephot68.net/nhieu-benh-tat-sinh-ra-vi-thieu-nuoc-sach
Крыша на балкон Балкон, прежде всего, – это открытое пространство, связующее звено между уютом квартиры и бескрайним внешним миром. Однако его беззащитность перед капризами погоды порой превращает это преимущество в существенный недостаток. Дождь, снег, палящее солнце – все это способно причинить немало хлопот, лишая возможности комфортно проводить время на балконе, а также нанося ущерб отделке и мебели. Именно здесь на помощь приходит крыша на балкон – надежная защита и гарантия комфорта в любое время года.
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Подробнее можно узнать тут – https://custompackaginginfo.com/small-business-big-impressions-packaging-as-a-marketing-tool
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Ознакомиться с деталями – https://yveap.com.au/a-simple-blog-post
мостбет скачать [url=mostbet-app-download-apk.com]mostbet-app-download-apk.com[/url] .
Стилни дамски блузи с модерни кройки за уверен външен вид всеки ден
дамски блузи с къс ръкав [url=https://bluzi-damski.com/]https://bluzi-damski.com/[/url] .
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Подробнее можно узнать тут – https://vyvod-iz-zapoya-donetsk-dnr00.ru/vyvod-iz-zapoya-kruglosutochno-doneczk-dnr
Независимая оценка ущерба от залива нужна для обращения в суд или страховую компанию https://expertiza-posle-zaliva.ru/
roobet bonus code 2025 WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
«Стоп Алко» — квалифицированная наркологическая помощь без ожидания. Быстрое выведение токсинов, восстановление организма, устранение последствий отравлений. Врачи работают 24/7, индивидуальный подход и полная анонимность.
Исследовать вопрос подробнее – [url=https://stop-alko.info/alkogolizm/bytovoj-alkogolizm-prichiny-priznaki-i-metody-profilaktiki.html]алкоголизм цена[/url]
Процесс лечения строится из нескольких ключевых этапов, каждый из которых направлен на оперативное восстановление состояния пациента:
Подробнее – [url=https://vyvod-iz-zapoya-donetsk-dnr00.ru/]вывод из запоя на дому круглосуточно[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить больше информации – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Процессное управление Ментор: ваш персональный гид к успеху. В современном бизнесе важно не только генерировать идеи, но и уметь их реализовывать. Настоящий ментор — это ваш личный проводник, помогающий вам развивать навыки и ускорять рост. Ментор делится опытом, дает ценные советы и оказывает поддержку в трудные моменты. Помощь ментора — это инвестиция в ваше будущее. Не откладывайте развитие — закажите консультацию и начните получать поддержку от профессионала, который поможет вам достичь новых высот.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Если пострадала отделка, мебель или техника, эксперт отразит это в отчете: оценка ущерба квартиры после залива
Наркологическая клиника «Стоп Алко» — современная система экстренной помощи. Детоксикация, снятие абстиненции, внутривенная терапия и проверенные методы восстановления. Работаем круглосуточно, приезжаем быстро.
Ознакомиться с деталями – [url=https://stop-alko.info/alkogolizm/alkogolnaya-koma.html]алкогольная кома[/url]
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге обеспечивает профессиональное лечение зависимостей, включая кодирование, медикаментозную терапию и восстановление психологического состояния. Круглосуточный приём и выезд врача на дом.
Изучить вопрос глубже – [url=https://new-narkolog.ru/narkologicheskaya-pomosch/srochniy-vyvod-iz-zapoya/]срочный вывод из запоя на дому[/url]
roobet promo code 2025 WEB3 В мире онлайн-казино инновации не стоят на месте, и Roobet находится в авангарде этих перемен. С появлением технологии Web3, Roobet предлагает игрокам новый уровень прозрачности, безопасности и децентрализации. Чтобы воспользоваться всеми преимуществами этой передовой платформы, используйте промокод WEB3.
Мир полон тайн https://phenoma.ru читайте статьи о малоизученных феноменах, которые ставят науку в тупик. Аномальные явления, редкие болезни, загадки космоса и сознания. Доступно, интересно, с научным подходом.
resumes for electrical engineers resume biomedical engineer
Читайте о необычном http://phenoma.ru научно-популярные статьи о феноменах, которые до сих пор не имеют однозначных объяснений. Психология, физика, биология, космос — самые интересные загадки в одном разделе.
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma ceny[/url]
При затоплении квартиры необходимо собрать документы, фото и вызвать независимого оценщика: оценка квартиры после залива
После прибытия нарколог:
Выяснить больше – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]вывод из запоя недорого санкт-петербруг[/url]
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя вызов в сочи[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя сочи.[/url]
pari match cricket [url=https://www.parimatch-apk.app]https://www.parimatch-apk.app[/url] .
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Узнать больше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма цены[/url]
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Детальнее – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]vyvod-iz-zapoya-na-domu donetsk[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: мастер ремонта apple
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Уборка перед сдачей квартиры в аренду или продаже
клининг в москве цена [url=http://www.kliningovaya-kompaniya0.ru]http://www.kliningovaya-kompaniya0.ru[/url] .
«НОВЫЙ НАРКОЛОГ» — наркологическая клиника в СПб с полным спектром услуг: детоксикация, лечение зависимостей, реабилитация, психологическая поддержка. Доверие пациентов и высокая эффективность подтверждаются отзывами и результатами работы.
Детальнее – [url=https://new-narkolog.ru/kodirovanie-ot-alkogolizma/kodirovanie-ot-alkogolizma-na-domu/]кодирование от алкоголизма спб на дому цены[/url]
Наркологическая клиника «Стоп Алко» — современная система экстренной помощи. Детоксикация, снятие абстиненции, внутривенная терапия и проверенные методы восстановления. Работаем круглосуточно, приезжаем быстро.
Подробнее можно узнать тут – [url=https://stop-alko.info/alkogolizm/dopustimye-promille-alkogolya-za-rulem.html]сколько можно алкоголя за рулем[/url]
«Стоп Алко» — квалифицированная наркологическая помощь без ожидания. Быстрое выведение токсинов, восстановление организма, устранение последствий отравлений. Врачи работают 24/7, индивидуальный подход и полная анонимность.
Детальнее – [url=https://stop-alko.info/alkogolizm/bytovoj-alkogolizm-prichiny-priznaki-i-metody-profilaktiki.html]алкоголизм[/url]
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-cena
В клинике «НОВЫЙ НАРКОЛОГ» в СПб оказывают квалифицированную наркологическую помощь: от экстренного вывода из запоя до длительной реабилитации. Индивидуальный подход, конфиденциальность и поддержка на всех этапах выздоровления — основные принципы работы специалистов.
Углубиться в тему – [url=https://new-narkolog.ru/stati/allergiya-na-alkogol/]аллергия на алкоголь[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Подробнее тут – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя на дому[/url]
При затоплении квартиры необходимо собрать документы, фото и вызвать независимого оценщика https://expertiza-zaliva-kvartiry.ru/
Якщо ви шукаєте новий рівень відчуттів від музики, вам точно варто завітати на [url=https://lambda.trancereality.mk.ua/]Lambda Stage[/url].
pinco promo code Pinco, Pinco AZ, Pinco Casino, Pinco Kazino, Pinco Casino AZ, Pinco Casino Azerbaijan, Pinco Azerbaycan, Pinco Gazino Casino, Pinco Pinco Promo Code, Pinco Cazino, Pinco Bet, Pinco Yukl?, Pinco Az?rbaycan, Pinco Casino Giris, Pinco Yukle, Pinco Giris, Pinco APK, Pin Co, Pin Co Casino, Pin-Co Casino. Онлайн-платформа Pinco, включая варианты Pinco AZ, Pinco Casino и Pinco Kazino, предлагает азартные игры в Азербайджане, также известная как Pinco Azerbaycan и Pinco Gazino Casino. Pinco предоставляет промокоды, а также варианты, такие как Pinco Cazino и Pinco Bet. Пользователи могут загрузить приложение Pinco (Pinco Yukl?, Pinco Yukle) для доступа к Pinco Az?rbaycan и Pinco Casino Giris. Pinco Giris доступен через Pinco APK. Pin Co и Pin-Co Casino — это связанные термины.
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: мастер по ремонту iphone
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
После прибытия нарколог:
Изучить вопрос глубже – http://nadezhnyj-vyvod-iz-zapoya.ru
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя цена[/url]
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]вывод из запоя круглосуточно в донецке[/url]
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya kapel’nica na domu[/url]
Когда запой выходит за рамки нескольких суток, интоксикация организма достигает критического уровня: нарушается водно-электролитный баланс, появляются признаки токсического поражения печени и нервной системы. В таких случаях самостоятельные попытки прекратить употребление алкоголя могут привести к тяжёлым осложнениям — судорогам, алкогольному психозу, острой сердечной недостаточности. В Санкт-Петербурге и Ленинградской области доступны профессиональные услуги по выводу из запоя, выполняемые опытными наркологами как на дому, так и в специализированных клиниках.
Получить больше информации – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]вывод из запоя анонимно в санкт-петербруге[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр по ремонту айфонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Обращение за помощью к профессионалам в условиях домашнего лечения имеет ряд важных преимуществ:
Узнать больше – [url=https://vyvod-iz-zapoya-donetsk-dnr0.ru/]наркология вывод из запоя[/url]
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Исследовать вопрос подробнее – http://vyvod-iz-zapoya-krasnogorsk2.ru
Аренда яхты в Сочи для отдыха с детьми: безопасно и интересно
аренда яхт в сочи [url=http://www.arenda-yahty-sochi23.ru/]http://www.arenda-yahty-sochi23.ru/[/url] .
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Углубиться в тему – http://kapelnica-ot-zapoya-sochi00.ru
Музика на [url=https://lambda.trancereality.mk.ua/]Lambda Stage[/url] наповнена магією, яка змінює відчуття простору та часу. Це справжнє занурення в електронний всесвіт!
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфонов на дому в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить больше информации – https://terapiasma.cl/wp/?p=9077
Наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге предлагает комплексное лечение алкогольной и наркотической зависимости, включая детоксикацию, амбулаторные и стационарные программы, а также психотерапевтическую поддержку. Опытные врачи СПб применяют современные методы для быстрой и эффективной помощи.
Выяснить больше – [url=https://new-narkolog.ru/stati/kak-vyyti-iz-zapoya-samostoyatelno/]как быстро выйти из запоя самостоятельно[/url]
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Детальнее – http://
сантехника днр [url=https://santehnika-doneck-1.ru/]https://santehnika-doneck-1.ru/[/url] .
Платная наркологическая клиника в Санкт-Петербурге «НОВЫЙ НАРКОЛОГ» предлагает профессиональную помощь при алкогольной и наркотической зависимости. Быстрое снятие абстиненции, кодирование, лечение в стационаре и амбулатории — всё с гарантией конфиденциальности.
Детальнее – [url=https://new-narkolog.ru/stati/kak-vosstanovit-pechen-posle-alkogolya/]как восстановить печень после алкоголя[/url]
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Подробнее – https://velo-stand.fr/photos/20150329_185611
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips сервис, можете посмотреть на сайте: срочный ремонт кофемашин philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Ознакомиться с деталями – http://etechno.id/2023/02/20/pemanfaatan-limbah-pltu-pada-bidang-konstruksi
[url=https://cactus-casino-apk.ru]cactus-casino-apk.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино cactus на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
cactus-casino-apk.ru
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить дополнительные сведения – http://mammasdarling.ru/category/13
бесплатные аккаунты стим с играми t.me/s/Burger_Game
resume cloud engineer resumes engineering
Эта статья предлагает захватывающий и полезный контент, который привлечет внимание широкого круга читателей. Мы постараемся представить тебе идеи, которые вдохновят вас на изменения в жизни и предоставят практические решения для повседневных вопросов. Читайте и вдохновляйтесь!
Исследовать вопрос подробнее – https://terapiasma.cl/wp/?p=6162
раздача аккаунтов бесплатные аккаунты в стиме
JPGtoPNGHero.com is a free, online converter crafted to turn JPG files into PNG images with ease. Whether you’re preparing icons for a mobile app or converting family photos for a digital scrapbook, the process is straightforward: upload, wait a moment, and download. The server-side engine preserves image quality, ensuring sharpness and accurate color reproduction. A visible progress indicator tracks each file’s status in real time. Need to convert a whole folder of images? Batch conversion handles multiple JPGs at once, streamlining your workflow. Since the converter works entirely in a browser, it’s compatible with Windows, macOS, Linux, Android, and iOS—no installations required. Privacy is built in: all uploads are automatically deleted shortly after processing, and no user data is stored on the server. The site remains ad-free, requires no user account, and imposes no conversion limits. Whether you’re a digital artist, social media manager, or just someone who needs to change image formats, JPGtoPNGHero.com offers a fast, reliable, and hassle-free experience.
JPGtoPNGHero
Кракен ссылка : сайт, зеркало, вход https://kraken-mirror-sait.com
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips цены, можете посмотреть на сайте: ремонт кофемашин philips адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: срочный ремонт iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
In today’s fast-paced world, staying informed about the latest developments both locally and globally is more crucial than ever. With a plethora of news outlets competing for attention, it’s important to find a trusted source that provides not just news, but analyses, and stories that matter to you. This is where [url=https://www.usatoday.com/]USAtoday.com [/url], a top online news agency in the USA, stands out. Our dedication to delivering the most current news about the USA and the world makes us a go-to resource for readers who seek to stay ahead of the curve.
Subscribe for Exclusive Content: By subscribing to USAtoday.com, you gain access to exclusive content, newsletters, and updates that keep you ahead of the news cycle.
[url=https://www.usatoday.com/]USAtoday.com [/url] is not just a news website; it’s a dynamic platform that enables its readers through timely, accurate, and comprehensive reporting. As we navigate through an ever-changing landscape, our mission remains unwavering: to keep you informed, engaged, and connected. Subscribe to us today and become part of a community that values quality journalism and informed citizenship.
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Подробнее – [url=https://lechenie-narkomanii-volgograd9.ru/]лечение наркомании реабилитация[/url]
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Получить дополнительные сведения – https://kolmardsnytt.se/bli-medlem/fridhem
Прорыв трубы может привести к большим потерям — экспертиза поможет зафиксировать это официально https://isk-za-zaliv.ru/
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфонов на дому в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр по ремонту айфонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Полноценное восстановление включает не только прекращение приёма наркотиков, но и формирование здорового образа жизни, навыков эмоционального самоконтроля и социокультурной адаптации.
Детальнее – [url=https://lechenie-narkomanii-volgograd9.ru/]центр лечения наркомании[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ознакомиться с деталями – http://diaocminhduong.com.vn/tuyen-dung-nhan-vien-kinh-doanh-bds-thu-nhap-cao-tai-binh-duong
После залива квартиры важно как можно быстрее провести экспертизу, чтобы подтвердить масштаб повреждений: претензия в управляющую компанию о возмещении ущерба по затоплению
Полноценное восстановление включает не только прекращение приёма наркотиков, но и формирование здорового образа жизни, навыков эмоционального самоконтроля и социокультурной адаптации.
Получить дополнительную информацию – [url=https://lechenie-narkomanii-volgograd9.ru/]центр лечения наркомании волгоград.[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips цены, можете посмотреть на сайте: ремонт кофемашин philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Если вас затопили соседи, не затягивайте с проведением экспертизы и уведомлением управляющей компании – https://nezavisimaya-ocenka-zaliva.ru/
resume for engineering jobs resumes for civil engineers
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: сервисный центр iphone в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
[url=https://candy-casino-apk.ru]candy-casino-apk.ru[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать приложение candy казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
candy-casino-apk.ru
уннв слушать онлайн бесплатно все песни в хорошем качестве [url=https://25kat.ru/music/уннв/]уннв слушать онлайн бесплатно все песни в хорошем качестве[/url] .
Мы принимаем пациентов старше 18 лет; для лиц старше 65 лет возможна адаптация схемы с учётом сопутствующих заболеваний.
Углубиться в тему – [url=https://lechenie-narkomanii-volgograd9.ru/]наркологическое лечение наркомания в волгограде[/url]
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: качественный ремонт айфонов в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Thanks , I have recently been looking for info about this subject for ages and yours is the greatest I’ve discovered till now. But, what about the bottom line? Are you sure in regards to the supply?
https://shop4me.in.ua/kupyty-korpusy-far-dlya-avtomobilya-na-shcho-zvert.html
Профессиональный сервисный центр по ремонту Apple iPhone в Москве.
Мы предлагаем: ремонт айфона с выездом мастера в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Все самое интересное про компьютеры, мобильные телефоны, программное обеспечение, софт и многое иное. Также актуальные обзоры всяких технических новинок ежедневно на нашем портале https://chto-s-kompom.ru/
Right here is the right blog for anyone who hopes to find out about this topic. You understand a whole lot its almost hard to argue with you (not that I really will need to…HaHa). You certainly put a brand new spin on a subject which has been written about for a long time. Great stuff, just wonderful!
https://mkest-office.com/yak-steklo-fara-mozhe-zminyty-dyzajn-vashoho-avtom.html
Под наблюдением врача пациенту вводятся капельницы с растворами, устраняющими интоксикацию, восстанавливается водно-солевой баланс, купируются симптомы ломки или похмельного синдрома.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-voronezh9.ru/]narkologicheskaya klinika voronezh[/url]
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
В течение полугода пациент может бесплатно посещать онлайн-группы поддержки и консультироваться у психологов клиники.
Ознакомиться с деталями – http://lechenie-narkomanii-volgograd9.ru
вебкам студия в Варшаве Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
Greate pieces. Keep posting such kind of info on your blog. Im really impressed by your blog.
Hi there, You have done a great job. I will certainly digg it and individually recommend to my friends. I’m confident they’ll be benefited from this site.
http://kvn-tehno.com.ua/steklo-far-dlya-tyuninhovykh-avto-populyarni-varia.html
Heya just wanted to give you a quick heads up and let you know a few of the images aren’t loading correctly. I’m not sure why but I think its a linking issue. I’ve tried it in two different internet browsers and both show the same results.
https://firma.com.ua/kupyty-korpus-fary-porady-po-vyboru-i-ustanovtsi-d.html
уннв песни скачать [url=https://25kat.ru/music/уннв/]уннв песни скачать[/url] .
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips цены, можете посмотреть на сайте: ремонт кофемашин philips сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Admiring the time and effort you put into your website and in depth information you present. It’s good to come across a blog every once in a while that isn’t the same old rehashed material. Fantastic read! I’ve saved your site and I’m adding your RSS feeds to my Google account.
https://naduvnie-lodki.com.ua/yak-zabezpechyty-maksymalnu-bezpeku-za-dopomohoyu-.html
В течение полугода пациент может бесплатно посещать онлайн-группы поддержки и консультироваться у психологов клиники.
Выяснить больше – https://lechenie-narkomanii-volgograd9.ru/lechenie-narkomanii-i-alkogolizma-volgograd/
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips цены, можете посмотреть на сайте: ремонт кофемашин philips в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips, можете посмотреть на сайте: ремонт кофемашин philips адреса
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Да, «Путь к жизни» оформляет все документы на номер договора без указания фамилии пациента и не передаёт сведения третьим лицам.
Подробнее – http://lechenie-narkomanii-volgograd9.ru
Наши специалисты строят программу лечения на основе многоступенчатой схемы, включающей медицинские, психологические и социальные компоненты. Каждый этап нацелен на устранение физической зависимости, стабилизацию психоэмоционального состояния и восстановление социальных связей.
Детальнее – [url=https://lechenie-narkomanii-volgograd9.ru/]лечение наркомании и алкоголизма в волгограде[/url]
Клинический опыт показывает: чем раньше начато лечение, тем выше шансы на устойчивую ремиссию. Промедление может привести к тяжёлым осложнениям — физическим, психическим и социальным.
Выяснить больше – [url=https://narkologicheskaya-klinika-voronezh9.ru/]частная наркологическая клиника воронеж.[/url]
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
resume devops engineer resume for engineering internship
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге обеспечивает профессиональное лечение зависимостей, включая кодирование, медикаментозную терапию и восстановление психологического состояния. Круглосуточный приём и выезд врача на дом.
Исследовать вопрос подробнее – [url=https://new-narkolog.ru/stati/kodein-chto-eto.html]кодеин это[/url]
Наркомания — серьёзное хроническое заболевание, требующее не только медицинского вмешательства, но и комплексного подхода к восстановлению личности и социальной адаптации. В Волгограде клиника «Путь к жизни» предлагает полностью анонимное обслуживание, при котором никаких сведений о пациенте не попадает в государственные реестры. Мы работаем круглосуточно и готовы принять человека в любое время, обеспечивая сопровождение на всех этапах лечения: от первичной детоксикации до выхода на полноценную жизнь без зависимости.
Детальнее – [url=https://lechenie-narkomanii-volgograd9.ru/]centr lecheniya narkomanii volgograd[/url]
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips цены, можете посмотреть на сайте: ремонт кофемашин philips
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Лечение в наркологической клинике в Воронеже проводится поэтапно, с учётом состояния пациента, длительности зависимости и наличия сопутствующих заболеваний.
Узнать больше – [url=https://narkologicheskaya-klinika-voronezh9.ru/]бесплатная наркологическая клиника[/url]
вебкам робота з проживанням Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Разобраться лучше – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
Полноценное восстановление включает не только прекращение приёма наркотиков, но и формирование здорового образа жизни, навыков эмоционального самоконтроля и социокультурной адаптации.
Разобраться лучше – http://lechenie-narkomanii-volgograd9.ru/czentr-lecheniya-narkomanii-volgograd/
Атмосфера PhiWave Festival була незабутньою. Виступи Amelie Lens і Stephan Bodzin перенесли гостей у світ гармонії та ритму. Лазерні шоу та інтерактивні інсталяції додали футуристичного настрою. Більше про цей [url=https://phi.trancereality.mk.ua/]унікальний фестиваль[/url] можна знайти на офіційному сайті.
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips адреса, можете посмотреть на сайте: ремонт кофемашин philips сервис
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Наркомания — серьёзное хроническое заболевание, требующее не только медицинского вмешательства, но и комплексного подхода к восстановлению личности и социальной адаптации. В Волгограде клиника «Путь к жизни» предлагает полностью анонимное обслуживание, при котором никаких сведений о пациенте не попадает в государственные реестры. Мы работаем круглосуточно и готовы принять человека в любое время, обеспечивая сопровождение на всех этапах лечения: от первичной детоксикации до выхода на полноценную жизнь без зависимости.
Подробнее можно узнать тут – [url=https://lechenie-narkomanii-volgograd9.ru/]лечение наркомании волгоград[/url]
resume devops engineer https://resumes-engineers.com
Ежедневные публикации о самых важных и интересных событиях в мире и России. Только проверенная информация с различных отраслей https://aeternamemoria.ru/
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить дополнительные сведения – http://vyvod-iz-zapoya-krasnogorsk2.ru/
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Узнать больше – http://denis-fischer.de/galerie/denisfischer_gal10
Ежедневные публикации о самых важных и интересных событиях в мире и России. Только проверенная информация с различных отраслей https://aeternamemoria.ru/
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
Друзі повернулися з PhiWave Festival із суперечливими враженнями. Хоча атмосфера була футуристичною, сам танцпол був надто переповненим, і знайти місце для танців було складно. Лаунж-зона, про яку багато розповідали, виявилася менш зручною, ніж очікували, а ароматерапія там не відчувалася. Вони були розчаровані, що організатори не врахували таких нюансів, враховуючи високий рівень очікувань від [url=https://phi.trancereality.mk.ua/]фестивалю[/url].
Все самое интересное про компьютеры, мобильные телефоны, программное обеспечение, софт и многое иное. Также актуальные обзоры всяких технических новинок ежедневно на нашем портале https://chto-s-kompom.ru/
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Получить дополнительную информацию – https://bloemboutiqueanush.nl/hello-world
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Получить дополнительные сведения – https://www.qa-hackathon.org/2020/06/07/bank-ternama-indonesia-yang-sukses-menggelar-event-hackathon
sda steam it is a desktop emulator of the Steam authentication mobile application. This desktop application allows users to manage their two-factor authentication easily, ensuring that only you can access your account.
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Получить больше информации – https://mediodigitalrd.com/estrenaran-documental-presidente-en-tiempo-de-crisis-sobre-gestion-de-luis-abinader
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Разобраться лучше – https://dadasradyosu.com/2021/08/13/erzurum-turkuleri
Научно-популярный сайт https://phenoma.ru — малоизвестные факты, редкие феномены, тайны природы и сознания. Гипотезы, наблюдения и исследования — всё, что будоражит воображение и вдохновляет на поиски ответов.
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Детальнее –
уннв все песни [url=www.25kat.ru/music/уннв/]уннв все песни[/url] .
find out [url=https://toastwallet.net]toast wallet app[/url]
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Аренда яхты в Сочи как часть туристического маршрута
сочи яхта [url=https://www.arenda-yahty-sochi23.ru/]https://www.arenda-yahty-sochi23.ru/[/url] .
високооплачувана робота для українок Стань вебкам моделью в польской студии, работающей в Варшаве! Открыты вакансии для девушек в Польше, особенно для тех, кто говорит по-русски. Ищешь способ заработать онлайн в Польше? Предлагаем подработку для девушек в Варшаве с возможностью работы в интернете, даже с проживанием. Рассматриваешь удаленную работу в Польше? Узнай, как стать вебкам моделью и сколько можно заработать. Работа для украинок в Варшаве и высокооплачиваемые возможности для девушек в Польше ждут тебя. Мы предлагаем легальную вебкам работу в Польше, онлайн работа без необходимости знания польского языка. Приглашаем девушек без опыта в Варшаве в нашу вебкам студию с обучением. Возможность заработка в интернете без вложений. Работа моделью онлайн в Польше — это шанс для тебя! Ищешь “praca dla dziewczyn online”, “praca webcam Polska”, “praca modelka online” или “zarabianie przez internet dla kobiet”? Наше “agencja webcam Warszawa” и “webcam studio Polska” предлагают “praca dla mlodych kobiet Warszawa” и “legalna praca online Polska”. Смотри “oferty pracy dla Ukrainek w Polsce” и “praca z domu dla dziewczyn”.
[url=https://clubnika-casino-apk.ru]clubnika-casino-apk.ru[/url]
По ссылке ниже — полезный гайд по игре в казино clubnika. Там разобраны основные стратегии, бонусы и советы для новичков. Рекомендую ознакомиться, если интересуетесь этой площадкой!
clubnika-casino-apk.ru
Клиника «НаркоСити» предлагает срочную наркологическую помощь при запоях на дому в Краснодаре. Опытные специалисты оперативно приезжают в любой район города, проводят детоксикацию и стабилизируют состояние пациента прямо на дому. Лечение организовано с максимальной безопасностью и соблюдением конфиденциальности, что обеспечивает пациентам комфорт и быстрое восстановление без госпитализации.
Детальнее – http://vyvod-iz-zapoya-krasnodar0.ru/vyvod-iz-zapoya-czena-krasnodar/
[url=https://daddy-casino-apk.ru]daddy-casino-apk.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино daddy в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.daddy-casino-apk.ru
слушать все песни уннв [url=http://www.25kat.ru/music/уннв]слушать все песни уннв[/url] .
Блог о здоровье, красоте, полезные советы на каждый день в быту и на даче https://lmoroshkina.ru/
Когда запой выходит за рамки нескольких суток, интоксикация организма достигает критического уровня: нарушается водно-электролитный баланс, появляются признаки токсического поражения печени и нервной системы. В таких случаях самостоятельные попытки прекратить употребление алкоголя могут привести к тяжёлым осложнениям — судорогам, алкогольному психозу, острой сердечной недостаточности. В Санкт-Петербурге и Ленинградской области доступны профессиональные услуги по выводу из запоя, выполняемые опытными наркологами как на дому, так и в специализированных клиниках.
Подробнее можно узнать тут – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]нарколог вывод из запоя в санкт-петербруге[/url]
Клиника «НаркоСити» предлагает срочную наркологическую помощь при запоях на дому в Краснодаре. Опытные специалисты оперативно приезжают в любой район города, проводят детоксикацию и стабилизируют состояние пациента прямо на дому. Лечение организовано с максимальной безопасностью и соблюдением конфиденциальности, что обеспечивает пациентам комфорт и быстрое восстановление без госпитализации.
Углубиться в тему – http://vyvod-iz-zapoya-krasnodar0.ru/vyvod-iz-zapoya-czena-krasnodar/
Этанол связывается с ГАМК-рецепторами, усиливая тормозные процессы в ЦНС, что ведёт к снижению рефлексов и когнитивных функций. Одновременно происходит повышение активности дофаминовых путей, вызывая ощущение кратковременного «успокоения» и «радости». При прекращении поступления алкоголя к рецепторам наступает синдром отмены — резкое возбуждение, тревожность и дисбаланс нейротрансмиттеров.
Получить больше информации – [url=https://nadezhnyj-vyvod-iz-zapoya.ru/]вывод из запоя в стационаре санкт-петербруг[/url]
Журнал для женщин и о женщинах. Все, что интересно нам, женщинам https://secrets-of-women.ru/
Журнал для женщин и о женщинах. Все, что интересно нам, женщинам https://secrets-of-women.ru/
click over here [url=https://breadwallet.net/]brd wallet download[/url]
helpful site [url=https://breadwallet.net/]bread wallet download[/url]
YouTube recommended an action scene and I clicked. Didn’t expect to be hooked! Searched and found [url=https://hdturko.com/filmler/4731-cin-seddi.html]cin seddi film[/url] on HDTurko. Full HD, smooth playback, and everything in Turkish. Amazing how quickly I went from a 2-minute clip to the entire movie without hassle.
Рекомендую https://bankinform.ru/news/135728
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Получить дополнительную информацию – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом недорого[/url]
Наркологический центр “Луч Надежды” — это место, где можно найти поддержку и помощь, даже когда кажется, что выход потерян. Наша команда врачей-наркологов, психологов и психотерапевтов использует современные методы лечения и реабилитации, помогая пациентам вернуть трезвость и полноценную жизнь. Мы стремимся не только к устранению симптомов, но и к выявлению причин заболевания, давая пациентам необходимые инструменты для борьбы с тягой к психоактивным веществам и формированию новых жизненных установок.
Разобраться лучше – [url=https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-ufe.ru/]https://srochno-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-ufe.ru/[/url]
Лучшие места для фотосессий во время отдыха в Гаграх
гагры отдых у моря [url=otdyh-gagry.ru]otdyh-gagry.ru[/url] .
Попробуйте http://mireli.ge/best-white-dark-hat-linkbuilding-for-your-website-327/
[url=https://cat-casino-apk.ru]cat-casino-apk.ru[/url]
Всем привет!
Нашёл для вас кое-что интересное, особенно для тех, кто фанатеет от казино cat. По ссылке можно узнать все подробности о том, как скачать это казино.
В статье, скорее всего, расскажут о способах скачивания для разных устройств, особенностях установки и, возможно, о бонусах, которые можно получить после установки.
cat-casino-apk.ru
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Подробнее тут – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
лучшие песни уннв скачать [url=https://www.25kat.ru/music/уннв]лучшие песни уннв скачать[/url] .
Современная наркология предлагает два основных формата вывода из запоя:
Узнать больше – http://nadezhnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-spb/https://nadezhnyj-vyvod-iz-zapoya.ru
Go Here [url=https://phantom-wallet.net]phantom Download[/url]
click over here [url=https://phantom-wallet.at/]phantom Download[/url]
find out here [url=https://keplr-extension.com]keplr Download[/url]
More Bonuses [url=https://Keplr.at]keplr Extension[/url]
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Получить дополнительную информацию – https://statuscaptions.com/how-to-stock-your-small-business-crm-with-fresh-leads.html
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Ознакомиться с деталями – https://novargonaftes.gr/2022/09/15/%CE%BC%CE%B5-%CF%84%CE%BF%CE%BD-%CE%BA%CE%B1%CE%BB%CF%8D%CF%84%CE%B5%CF%81%CE%BF-%CF%84%CF%81%CF%8C%CF%80%CE%BF-%CE%AD%CF%80%CE%B5%CF%83%CE%B5-%CE%B7-%CE%B1%CF%85%CE%BB%CE%B1%CE%AF%CE%B1-%CE%B3%CE%B9
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Получить дополнительную информацию – https://www.karooweavery.co.za/modern-shop-charity-event-2016
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Выяснить больше – http://www.ffchr.ru/575
Блог о здоровье, красоте, полезные советы на каждый день в быту и на даче https://lmoroshkina.ru/
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Получить дополнительные сведения – https://gospnews.com/zack-bonfilio
трактор выровнять участок стоимость [url=http://www.vyrovnyat-uchastok-23.ru]http://www.vyrovnyat-uchastok-23.ru[/url] .
Just want to say your article is as astounding. The clearness to your publish is just excellent and i could suppose you are knowledgeable in this subject. Well with your permission allow me to grab your RSS feed to stay up to date with drawing close post. Thank you 1,000,000 and please carry on the rewarding work.
https://protein.kiev.ua/de-kupyty-yakisni-bi-led-linzy-v-ukrayini-rejtynh-.html
Whats up are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and create my own. Do you require any coding knowledge to make your own blog? Any help would be really appreciated!
https://elmakurdukres.com/riznytsya-mizh-steklafar-i-tradytsijnymy-faramy-pl.html
The blue blur is back and faster than ever! [url=https://hdturko.com/filmler/2171-kirpi-sonic-3.html]sonic 3 turkce dublaj full izle[/url] and join Sonic in his newest high-speed adventure. Packed with action, humor, and heart, this film is perfect for all ages. Now with Turkish dubbing in full HD — don’t miss out!
Новости, обзоры, тест-драйвы, ремонт и эксплуатация автомобилей https://5go.ru/
Предлагаем услуги профессиональных инженеров офицальной мастерской.
Еслли вы искали ремонт кофемашин philips, можете посмотреть на сайте: ремонт кофемашин philips в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
Новости, обзоры, тест-драйвы, ремонт и эксплуатация автомобилей https://5go.ru/
Клиника «Возрождение» гарантирует:
Узнать больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм республика башкортостан[/url]
Looking for a light Turkish comedy, I typed “Aykut Eniste full izle” into Google. [url=https://hdturko.com/filmler/4626-aykut-enite.html]aykut eniste full izle[/url] was first — and it didn’t disappoint. Free, HD, and no account needed. The movie had heart, humor, and a charming lead. HDTurko made it a great experience.
Актуальные новости евразия новости сегодня — политика, экономика, общество, культура и события стран постсоветского пространства, Европы и Азии. Объективно, оперативно и без лишнего — вся Евразия в одном месте.
Клиника «Возрождение» гарантирует:
Получить дополнительную информацию – http://narkologicheskaya-klinika-ufa9.ru
купить аттестат за 9 класс [url=https://goznak-diplomg.online/]https://goznak-diplomg.online/[/url] .
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Разобраться лучше – http://narkologicheskaya-klinika-ufa9.ru
Журнал о психологии и отношениях, чувствах и эмоциях, здоровье и отдыхе. О том, что с нами происходит в жизни. Для тех, кто хочет понять себя и других https://inormal.ru/
диплом купить [url=http://arus-diplomh.online]диплом купить[/url] .
Этот этап лечения направлен на купирование острых симптомов, связанных с абстинентным синдромом. Пациенту назначаются современные препараты, способствующие выведению токсинов, нормализации работы сердца, печени, центральной нервной системы.
Разобраться лучше – [url=https://narkologicheskaya-klinika-volgograd9.ru/]наркологическая клиника на дом[/url]
Юрист Онлайн https://juristonline.com квалифицированная юридическая помощь и консультации 24/7. Решение правовых вопросов любой сложности: семейные, жилищные, трудовые, гражданские дела. Бесплатная первичная консультация.
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить больше информации – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника республика башкортостан[/url]
[url=40-ka.ru]40-ka.ru[/url] .
Техника снова russiahelp.com будет работать как новая.
Этот этап лечения направлен на купирование острых симптомов, связанных с абстинентным синдромом. Пациенту назначаются современные препараты, способствующие выведению токсинов, нормализации работы сердца, печени, центральной нервной системы.
Подробнее можно узнать тут – http://narkologicheskaya-klinika-volgograd9.ru/
Дом из контейнера https://russiahelp.com под ключ — мобильное, экологичное и бюджетное жильё. Индивидуальные проекты, внутренняя отделка, электрика, сантехника и монтаж
Загадки Вселенной https://phenoma.ru паранормальные явления, нестандартные гипотезы и научные парадоксы — всё это на Phenoma.ru
Клиника «Возрождение» гарантирует:
Выяснить больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника[/url]
Сайт знакомств https://rutiti.ru для серьёзных отношений, дружбы и общения. Реальные анкеты, удобный поиск, быстрый старт. Встречайте новых людей, находите свою любовь и начинайте общение уже сегодня.
купить компьютер для игр Игровой ПК в сборе: Готовое решение для геймеров Игровой ПК в сборе – это отличный вариант для тех, кто хочет получить готовую машину с высокой производительностью. Выберите из предложенных конфигураций и наслаждайтесь любимыми играми.
Ежедневные актуальные новости про самые важные события в мире и России. Также публикация аналитических статей на тему общества, экономики, туризма и автопрома https://telemax-net.ru/
взгляните на сайте здесь [url=https://t.me/s/pinco_zerkala/]пинко казик[/url]
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Узнать больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]бесплатная наркологическая клиника уфа[/url]
Ежедневные актуальные новости про самые важные события в мире и России. Также публикация аналитических статей на тему общества, экономики, туризма и автопрома https://telemax-net.ru/
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительные сведения – https://narkologicheskaya-klinika-ufa9.ru/
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Получить больше информации – http://narkologicheskaya-klinika-ufa9.ru
кликните сюда [url=https://t.me/s/pinco_zerkala]pinco андроид[/url]
Дача и огород, фермерство и земледелие, растения и цветы. Все о доме, даче и загородной жизне. Мы публикуем различные мнения, статьи и видеоматериалы о даче, огороде https://sad-i-dom.com/
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Узнать больше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом вывод[/url]
купить компьютер для игр Готовые компьютеры: Быстро и удобно Для тех, кто ценит скорость и простоту, предлагаются готовые компьютеры. Они уже собраны и настроены, готовы к работе прямо из коробки. Однако, если вам нужна большая гибкость и возможность выбора комплектующих, сборка на заказ станет лучшим вариантом.
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-msk55.ru/]postavit kapelnitsu ot zapoia odintsovo[/url]
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника в уфе[/url]
Все процедуры проводятся под круглосуточным наблюдением. Применяются инфузионные растворы, седативные и противосудорожные средства, а также поддерживающие препараты, позволяющие уменьшить нагрузку на жизненно важные органы.
Углубиться в тему – https://narkologicheskaya-klinika-volgograd9.ru/chastnaya-narkologicheskaya-klinika-volgograd
Клиника «Возрождение» гарантирует:
Детальнее – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм в уфе[/url]
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительную информацию – http://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa/https://narkologicheskaya-klinika-ufa9.ru
Клиника «Возрождение» гарантирует:
Детальнее – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника в уфе[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить больше информации – [url=https://kapelnica-ot-zapoya-msk55.ru/]kapelnitsa ot zapoia[/url]
В наркологической клинике «Перезагрузка» в Химках капельницы проводятся под строгим медицинским наблюдением. Мы используем современные препараты, индивидуально подбираем состав инфузии и гарантируем конфиденциальность. Наша задача — не просто снять симптомы, а обеспечить реальную поддержку организму на физиологическом уровне, чтобы предотвратить повторный срыв и минимизировать риски для здоровья.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnitsy ot zapoia na domu[/url]
PC application https://authenticatorsteamdesktop.com replacing the mobile Steam Guard. Confirm logins, trades, and transactions in Steam directly from your computer. Support for multiple accounts, security, and backup.
Steam Guard for PC — sda steam. Ideal for those who trade, play and do not want to depend on a smartphone. Two-factor protection and convenient security management on Windows.
No more phone needed! download steam desktop authenticator lets you use Steam Guard right on your computer. Quickly confirm transactions, access 2FA codes, and conveniently manage security.
Запой — это не просто следствие чрезмерного употребления алкоголя, а серьёзное патологическое состояние, которое требует срочной медицинской помощи. На фоне затяжного приёма спиртного в организме человека происходят опасные изменения: интоксикация, обезвоживание, нарушение электролитного баланса, резкие скачки давления и работы сердца, угнетение функций печени и мозга. В такой ситуации капельница от запоя становится неотложной мерой, позволяющей стабилизировать состояние и устранить симптомы абстиненции за короткий срок.
Выяснить больше – [url=https://kapelnica-ot-zapoya-msk55.ru/]капельница от запоя цена[/url]
После первичной консультации пациент проходит обследование, позволяющее точно определить стадию зависимости и сопутствующие патологии. Используются лабораторные анализы, оценка неврологического статуса и сбор анамнеза. Уже на этом этапе начинается выстраивание контакта между пациентом и врачом, что особенно важно для доверия и готовности включиться в процесс.
Подробнее – [url=https://narkologicheskaya-klinika-volgograd9.ru/]наркологическая клиника нарколог волгоград[/url]
Журнал о психологии и отношениях, чувствах и эмоциях, здоровье и отдыхе. О том, что с нами происходит в жизни. Для тех, кто хочет понять себя и других https://inormal.ru/
Дача и огород, фермерство и земледелие, растения и цветы. Все о доме, даче и загородной жизне. Мы публикуем различные мнения, статьи и видеоматериалы о даче, огороде https://sad-i-dom.com/
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Разобраться лучше – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя недорого в красноярске[/url]
Загадки Вселенной https://phenoma.ru паранормальные явления, нестандартные гипотезы и научные парадоксы — всё это на Phenoma.ru
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Узнать больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]narkologicheskaya-klinika-ufa9.ru/[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее тут – [url=https://narkolog-na-dom-ekaterinburg12.ru/]vrach-narkolog-na-dom[/url]
салон кухни от производителя [url=http://www.kuhnni-na-zakaz1.ru]http://www.kuhnni-na-zakaz1.ru[/url] .
Агентство недвижимости https://metropolis-estate.ru покупка, продажа и аренда квартир, домов, коммерческих объектов. Полное сопровождение сделок, юридическая безопасность, помощь в оформлении ипотеки.
Квартиры посуточно https://kvartiry-posutochno19.ru в Абакане — от эконом до комфорт-класса. Уютное жильё в центре и районах города. Чистота, удобства, всё для комфортного проживания.
Зависимость — это заболевание, которое разрушает не только тело, но и личность. Оно затрагивает мышление, поведение, разрушает отношения и лишает человека способности контролировать свою жизнь. Наркологическая клиника в Волгограде — профессиональное лечение зависимостей строит свою работу на понимании природы болезни, а не на осуждении. Именно это позволяет добиваться стойких результатов, восстанавливая пациента физически, эмоционально и социально.
Получить больше информации – http://narkologicheskaya-klinika-volgograd9.ru/chastnaya-narkologicheskaya-klinika-volgograd/
Проститутки Тюмень
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Подробнее – https://narkologicheskaya-klinika-ufa9.ru/narkologicheskie-kliniki-alkogolizm-ufa
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-msk55.ru/]выезд на дом капельница от запоя[/url]
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника[/url]
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Детальнее – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника нарколог в уфе[/url]
Клиника «Возрождение» гарантирует:
Разобраться лучше – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника уфа.[/url]
Проститутки Тюмени
Appreciation you!
https://hop.cx
Проститутки Тюмени
СРО УН «КИТ» https://sro-kit.ru саморегулируемая организация для строителей, проектировщиков и изыскателей. Оформление допуска СРО, вступление под ключ, юридическое сопровождение, помощь в подготовке документов.
Ремонт квартир https://berlin-remont.ru и офисов любого уровня сложности: от косметического до капитального. Современные материалы, опытные мастера, прозрачные сметы. Чисто, быстро, по разумной цене.
Ремонт квартир https://remont-kvartir-novo.ru под ключ в новостройках — от черновой отделки до полной готовности. Дизайн, материалы, инженерия, меблировка.
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Ознакомиться с деталями – https://narkologicheskaya-klinika-ufa9.ru/chastnaya-narkologicheskaya-klinika-ufa
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-ekaterinburg12.ru/]нарколог на дом вывод из запоя[/url]
Проститутки Тюмени
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Получить больше информации – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызов нарколога на дом[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg12.ru/]нарколог на дом недорого[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Получить больше информации – [url=https://kapelnica-ot-zapoya-msk55.ru/]капельница от запоя[/url]
Відвідування [url=https://europe.sff.in.ua]фестивалю в Барселоні[/url] було найяскравішою подією цього літа. Танці, музика та енергія – це було справжнє свято!
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Узнать больше – https://narkologicheskaya-klinika-ufa9.ru
собрать компьютер онлайн
Ремонт квартир https://remont-otdelka-mo.ru любой сложности — от косметического до капитального. Современные материалы, опытные мастера, строгие сроки. Работаем по договору с гарантиями.
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]vrach-narkolog-na-dom[/url]
Webseite cvzen.de ist Ihr Partner fur professionelle Karriereunterstutzung – mit ma?geschneiderten Lebenslaufen, ATS-Optimierung, LinkedIn-Profilen, Anschreiben, KI-Headshots, Interviewvorbereitung und mehr. Starten Sie Ihre Karriere neu – gezielt, individuell und erfolgreich.
sitio web tavoq.es es tu aliado en el crecimiento profesional. Ofrecemos CVs personalizados, optimizacion ATS, cartas de presentacion, perfiles de LinkedIn, fotos profesionales con IA, preparacion para entrevistas y mas. Impulsa tu carrera con soluciones adaptadas a ti.
For more information [url=https://ancientcivs.ru]https://ancientcivs.ru[/url] .
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Углубиться в тему – http://narkologicheskaya-klinika-ufa9.ru/
Проститутки Тюмень
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Подробнее можно узнать тут – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника в уфе[/url]
Проститутки Тюмени
Проститутки Тюмень
Мы понимаем, насколько важна приватность для пациентов и их близких. В «Возрождение» все обращения регистрируются по номеру договора, без упоминания личных данных в государственных базах. Даже близкие могут не знать точного диагноза, если пациент пожелает сохранить это в тайне.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-ufa9.ru/]narkologicheskaya klinika ufa[/url]
готовые компьютеры купить
Проститутки Тюмень
Французька кухня завжди була для мене загадкою, але після майстер-класу в Ліоні я впевнено можу приготувати декілька страв. Усе завдяки [url=https://europe.sff.in.ua]European Department[/url] і їхнім фантастичним заходам.
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Изучить вопрос глубже – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-msk55.ru/]капельница от запоя цена[/url]
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Детальнее – [url=https://narkolog-na-dom-ekaterinburg11.ru/]запой нарколог на дом[/url]
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Выяснить больше – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника нарколог уфа[/url]
where can i get cheap clomiphene where can i get generic clomiphene without prescription clomid medication uk where to get cheap clomiphene no prescription can you buy generic clomiphene prices can i buy clomid without prescription where can i buy generic clomid tablets
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg12.ru/]нарколог на дом цена[/url]
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Детальнее – [url=https://kapelnica-ot-zapoya-msk55.ru/]врач на дом капельница от запоя одинцово[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызвать нарколога на дом[/url]
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее тут – [url=https://narkolog-na-dom-ekaterinburg11.ru/]выезд нарколога на дом[/url]
кайтсёрфинг инструктор
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительные сведения – http://narkologicheskaya-klinika-ufa9.ru
Показания к проведению капельницы от запоя включают:
Получить больше информации – [url=https://kapelnica-ot-zapoya-moskva3.ru/]vyzvat kapelnitsu ot zapoia[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-msk55.ru/]https://kapelnica-ot-zapoya-msk55.ru[/url]
Наш стационар оснащён всем необходимым для безопасного и комфортного лечения. Здесь вы получите круглосуточный мониторинг, современное оборудование и услуги психологов, социальных педагогов и физиотерапевтов.
Получить больше информации – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологические клиники алкоголизм уфа[/url]
роллетный шкаф купить [url=www.shkaf-parking-3.ru]www.shkaf-parking-3.ru[/url] .
Модульный дом https://kubrdom.ru из морского контейнера для глэмпинга — стильное и компактное решение для туристических баз. Полностью готов к проживанию: утепление, отделка, коммуникации.
Проститутки Тюмени
Сервисный центр специализируется на технике Apple всех моделей.
Проститутки Тюмень
В наркологической клинике «Перезагрузка» в Химках капельницы проводятся под строгим медицинским наблюдением. Мы используем современные препараты, индивидуально подбираем состав инфузии и гарантируем конфиденциальность. Наша задача — не просто снять симптомы, а обеспечить реальную поддержку организму на физиологическом уровне, чтобы предотвратить повторный срыв и минимизировать риски для здоровья.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnitsa ot zapoia[/url]
Курорт Гагры — идеальное место для пляжного отдыха и восстановления
гагры отдых у моря [url=http://otdyh-gagry.ru/]http://otdyh-gagry.ru/[/url] .
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Исследовать вопрос подробнее – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя круглосуточно красноярск[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg12.ru/]narkolog-na-dom-kruglosutochno[/url]
Is there a course available to help CBSE Std 10 students master the art of time travel, enabling them to tackle future exams with unparalleled foresight?
Я завжди думала, що електронна музика – це не моє, поки не почула музику DJ Gafur. Він просто відкрив для мене цей жанр з нового боку. Особливо мене вразило, як він поєднує сучасні ритми з живою гітарою. Це звучить так органічно, що ти не можеш залишитися байдужим. Тепер я слухаю його треки під час прогулянок і мрію потрапити на його виступ. Якщо ти хочеш відкрити для себе щось нове, раджу почати з його сайту!
Проститутки Тюмени
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Ознакомиться с деталями – [url=https://narkolog-na-dom-ekaterinburg11.ru/]врач нарколог на дом[/url]
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Получить дополнительные сведения – [url=https://narkolog-na-dom-ekaterinburg11.ru/]врач нарколог на дом[/url]
Проститутки Тюмени
Проститутки Тюмени
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызов врача нарколога на дом[/url]
Инфузии выполняются с помощью автоматизированных насосов, позволяющих скорректировать скорость введения в зависимости от показателей безопасности.
Разобраться лучше – [url=https://medicinskij-vyvod-iz-zapoya.ru/]vyvod-iz-zapoya krasnojarsk[/url]
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Углубиться в тему – [url=https://narkologicheskaya-klinika-ufa9.ru/]наркологическая клиника цены уфа[/url]
For more information [url=https://up-top.ru]https://up-top.ru[/url] .
водопонижение иглофильтрами цена [url=https://stroitelnoe-vodoponizhenie6.ru/]stroitelnoe-vodoponizhenie6.ru[/url] .
Процедура длится от одного до трёх часов. В течение всего времени за пациентом наблюдает медперсонал, проводится мониторинг давления, пульса, общего самочувствия. Уже через 30–60 минут после начала инфузии большинство пациентов ощущают облегчение: снижается тревожность, уходит головная боль, нормализуется дыхание, появляются силы.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnitsa ot zapoia klinika[/url]
kraken darknet ссылка Кракен
[url=https://kra33cc-cc.ru]kraken сайт[/url] – кракен darknet, kraken официальные ссылки
Индивидуалки Тюмени
Нещодавно відкрила для себе цікавого музиканта, DJ Gafur. Познайомилася з його творчістю, коли мій друг включив його сет на вечірці. Скажу чесно, я ніколи не думала, що електронна музика може бути такою живою та емоційною. Особливо мені сподобалося, як він додає звучання гітари – це зовсім інший рівень. А коли дізналася, що він виступав у клубах Берліна, зрозуміла, що його музика дійсно має світовий рівень. Тепер я фанатка!
Каждый пациент проходит три основные стадии терапии, начиная с момента первого обращения.
Углубиться в тему – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника уфа[/url]
Индивидуалки Тюмени
[url=https://kra33cc-cc.ru/]kraken зеркало[/url] – kraken ссылка на сайт, kraken onion
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее тут – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызов нарколога на дом[/url]
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-msk55.ru/]vracha kapelnitsu ot zapoia[/url]
ai therapy bot [url=ai-therapist1.com]ai-therapist1.com[/url] .
Клиника «Возрождение» гарантирует:
Ознакомиться с деталями – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника уфа[/url]
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом[/url]
увв водопонижение [url=https://www.stroitelnoe-vodoponizhenie6.ru]https://www.stroitelnoe-vodoponizhenie6.ru[/url] .
Во время длительного употребления алкоголя тело человека испытывает многоступенчатую интоксикацию. Сначала страдает печень — главный орган детоксикации. Постепенно нарушается фильтрация, и продукты распада этанола начинают циркулировать по крови, вызывая общее отравление. Далее страдает головной мозг: снижается уровень витамина B1, нарушается проводимость нервных импульсов, появляются спутанность сознания, агрессия, тревога, нарушения сна и координации.
Подробнее тут – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnica-ot-zapoya-moskva3.ru/[/url]
ai therapist chatbot [url=http://www.ai-therapist1.com]http://www.ai-therapist1.com[/url] .
Купить диплом ВУЗа по невысокой цене возможно, обращаясь к надежной специализированной фирме. Мы предлагаем документы об окончании любых университетов РФ. Приобрести диплом университета– [url=http://petisionline.com/487819/]petisionline.com/487819[/url]
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Детальнее – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя недорого красноярск[/url]
Look At This [url=https://toastwallet.net/]toast crypto wallet[/url]
Перед началом процедуры врач проводит осмотр: измеряет давление, пульс, уровень кислорода в крови, оценивает тяжесть абстинентного синдрома. В зависимости от результатов и наличия сопутствующих заболеваний составляется индивидуальный состав инфузионного раствора. Он может включать:
Узнать больше – [url=https://kapelnica-ot-zapoya-msk55.ru/]kapelnitsa ot zapoia odintsovo[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом клиника[/url]
Запой — это не просто несколько дней бесконтрольного употребления алкоголя. Это тяжёлое патологическое состояние, при котором организм человека накапливает токсические продукты распада этанола, теряет жизненно важные электролиты, обезвоживается и выходит из равновесия. На фоне этого нарушается работа сердца, мозга, печени и других систем. Чем дольше длится запой, тем тяжелее последствия и выше риск развития осложнений, вплоть до алкогольного психоза или инсульта. В такой ситуации незаменимым методом экстренной помощи становится капельница от запоя — процедура, позволяющая быстро и безопасно вывести токсины, стабилизировать жизненно важные функции и вернуть человеку контроль над собой.
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva3.ru/]капельница от запоя цена[/url]
Показания к проведению капельницы от запоя включают:
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva3.ru/]kapelnica-ot-zapoya-moskva3.ru/[/url]
Проститутки Тюмень
Показанием к стационарному лечению служат случаи, при которых домашняя терапия становится небезопасной или недостаточно эффективной. Рекомендуем госпитализацию при:
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-ufa9.ru/]частная наркологическая клиника республика башкортостан[/url]
Дополнительно усиливаются сердечно-сосудистые риски: густая кровь, дефицит калия и магния провоцируют тахикардию, скачки давления и повышают вероятность инфаркта или инсульта. На этом фоне даже простая головная боль может оказаться сигналом серьёзного сосудистого нарушения. Задача капельницы — не просто убрать симптомы, а стабилизировать состояние организма и предотвратить дальнейшее ухудшение.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-msk55.ru/]vrach na dom kapelnitsa ot zapoia odintsovo[/url]
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]запой нарколог на дом[/url]
Tüm cihazlarla uyumlu ve hızlı full hd film izleme altyapısı
4ka film izle [url=http://filmizlehd.co/]http://filmizlehd.co/[/url] .
Капельница от запоя необходима, если у пациента наблюдаются следующие симптомы:
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-msk55.ru/]vracha kapelnitsu ot zapoia[/url]
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Узнать больше – https://pillnitzer-weinberg.de/?p=1074
Для максимальной эффективности и безопасности «Красмед» использует комбинированные подходы:
Выяснить больше – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя на дому цена[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg12.ru/]врач нарколог на дом[/url]
Близкий человек в запое? Не ждите ухудшения. Обратитесь в клинику Сочи — здесь проведут профессиональный вывод из запоя с последующим восстановлением организма.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызов врача нарколога на дом[/url]
more information [url=https://breadwallet.net/]bread wallet[/url]
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Получить дополнительные сведения – https://blog.waveletech.com/2024/09/04/%E6%8E%A8%E8%8D%90%E4%B8%80%E6%AC%BE%E5%85%A8%E5%9B%BD%E4%BA%A7%E5%8C%96%E7%9A%84%E5%8D%81%E4%BA%8C%E5%AF%BC%E8%81%94%E5%BF%83%E7%94%B5%E5%9B%BE%E6%9C%BA
webpage [url=https://jaxx.top/]jaxx wallet liberty[/url]
Эта информационная заметка содержит увлекательные сведения, которые могут вас удивить! Мы собрали интересные факты, которые сделают вашу жизнь ярче и полнее. Узнайте нечто новое о привычных аспектах повседневности и откройте для себя удивительный мир информации.
Исследовать вопрос подробнее – https://mudanzas-bizkaia.com/hola-mundo
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Подробнее – https://wethefuture.souls.life/wp_20181219_16_31_05_pro-2
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальныеInsights и полезные сведения для дальнейшего изучения.
Детальнее – https://www.marmarstudija.lt/2016/09/08/sed-ut-erat-quis-libero-dignissim
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Подробнее – https://barizaoman.com/experience-review-crowne-plaza-muscat
שירותי טלגרם|הדרכות מפורטות להזמנת מוצרים בקלות ובמהירות
בעידן המודרני, הטמעת פתרונות דיגיטליים נותן לנו את האפשרות להפוך תהליכים מורכבים לפשוטים משמעותית. אחד מהשירותים הפופולריים ביותר בתחום הקנאביס בישראל הוא טלגראס כיוונים , שמאפשר למשתמשים למצוא ולהזמין קנאביס בצורה יעילה ומושלמת באמצעות אפליקציה של טלגרם. במדריך זה נסביר איך עובד טלגראס כיוונים, כיצד הוא עובד, וכיצד תוכלו להשתמש בו כדי להתארגן בצורה הטובה ביותר.
מה זה טלגראס כיוונים?
טלגראס כיוונים הוא מערכת אינטרנט שמשמש כמוקד לקישורים ולערוצים (קבוצות וערוצים באפליקציה של טלגרם) המתמקדים בהזמנת ושילוח קנאביס. האתר מספק רשימות מאומתות לערוצים אמינים ברחבי הארץ, המאפשרים למשתמשים להזמין קנאביס בצורה מובנית היטב.
ההבסיס לפעול מאחורי טלגראס כיוונים הוא לחבר בין צרכנים לבין שליחים או סוחרים, תוך שימוש בכלי הטכנולוגיה של הרשת החברתית. כל מה שאתם צריכים לעשות הוא לקבוע את הקישור המתאים, ליצור קשר עם הספק הקרוב למקום מגוריכם, ולבקש את המשלוח שלכם – הכל נעשה באופן דיגיטלי ומהיר.
איך работает טלגראס כיוונים?
השימוש בטulgראס כיוונים הוא מובנה בצורה אינטואיטיבית. הנה ההוראות הראשוניות:
התחברות למערכת האינטרנט:
הכינו עבורכם את מרכז המידע עבור טלגראס כיוונים, שבו תוכלו למצוא את כל הנתונים הנדרשים לערוצים אמינים וטובים. האתר כולל גם הדרכות מובנות כיצד לפעול נכון.
הגעה לערוץ המומלץ:
האתר מספק רשימת קישורים לבחירה שעוברים וידוא תקינות. כל ערוץ אומת על ידי משתמשים מקומיים ששיתפו את חוות דעתם, כך שתדעו שאתם נכנסים לערוץ אמין ומאומת.
בקשת שיחה עם מזמין:
לאחר בחירה מהרשימה, תוכלו ליצור קשר עם האחראי על השילוח. השליח יקבל את ההזמנה שלכם וישלח לכם את המוצר תוך דקות ספורות.
קבלת המשלוח:
אחת ההפרטים הקריטיים היא שהמשלוחים נעשים באופן ממוקד ואמין. השליחים עובדים בצורה מקצועית כדי להבטיח שהמוצר יגיע אליכם בזמן.
מדוע זה שימושי?
השימוש בטulgראס כיוונים מציע מספר יתרונות מרכזיים:
פשטות: אין צורך לצאת מהבית או לחפש מבצעים ידניים. כל התהליך מתבצע דרך האפליקציה.
מהירות פעולה: הזמנת המשלוח נעשית בקצב מהיר, והשליח בדרך אליכם בתוך זמן קצר מאוד.
וודאות: כל הערוצים באתר עוברות בדיקה קפדנית על ידי משתמשים אמיתיים.
זמינות בכל הארץ: האתר מספק קישורים לערוצים פעילים בכל אזורי ישראל, מהמרכז ועד הפריפריה.
למה כדאי לבדוק ערוצים?
אחד הדברים הקריטיים ביותר בעת использование טulgראס כיוונים הוא לוודא שאתם נכנסים לערוצים אמינים. ערוצים אלו עברו אישור רשמי ונבדקו על ידי צרכנים שדיווחו על החוויה והתוצאות. זה מבטיח לכם:
איכות מוצר: השליחים והסוחרים בערוצים המאומתים מספקים מוצרים באיכות מצוינת.
ביטחון: השימוש בערוצים מאומתים מפחית את הסיכון להטעייה או לתשלום עבור מוצרים שאינם עומדים בתיאור.
תמיכה טובה: השליחים בערוצים המומלצים עובדים בצורה יעילה ומספקים שירות מדויק וטוב.
האם זה מותר לפי החוק?
חשוב לציין כי השימוש בשירותים כמו טulgראס כיוונים אינו מורשה על ידי המדינה. למרות זאת, רבים בוחרים להשתמש בשיטה זו בשל השימושיות שהיא מספקת. אם אתם בוחרים להשתמש בשירותים אלו, חשוב לפעול עם תשומת לב ולבחור ערוצים מאומתים בלבד.
ההתחלה שלך: מה לעשות?
אם אתם רוצים להזמין בצורה נוחה להשגת קנאביס בישראל, טulgראס כיוונים עשוי להיות הפתרון בשבילכם. האתר מספק את כל המידע הנחוץ, כולל נתוני חיבור לערוצים מומלצים, מדריכים והסברים כיצד לפעול נכון. עם טulgראס כיוונים, שליח הקנאביס יכול להיות בדרך אליכם תוך דקות ספורות.
אל תחכו יותר – פתחו את המערכת, מצאו את הערוץ המתאים לכם, ותוכלו להנות מחוויית הפעלה מהירה!
טלגראס כיוונים – המערכת שתגיע אליכם.
Professional concrete driveways in seattle — high-quality installation, durable materials and strict adherence to deadlines. We work under a contract, provide a guarantee, and visit the site. Your reliable choice in Seattle.
Исследуйте 1xbet-egypt.netlify.app, в мире ставок.
Откройте для себя 1xbet-egypt.netlify.app, всеми новинками.
Посетите 1xbet-egypt.netlify.app для невероятных бонусов, для того чтобы.
Погрузитесь в азарт на 1xbet-egypt.netlify.app, новые возможности.
Наслаждайтесь игрой на 1xbet-egypt.netlify.app, сделать ставки более выгодными.
Вдохновляйтесь игрой на 1xbet-egypt.netlify.app, где.
1xbet-egypt.netlify.app — ваш старт в мир азартных игр, открыть новые горизонты.
1xbet-egypt.netlify.app — ваш лучший выбор, для.
Погрузитесь в захватывающий мир 1xbet-egypt.netlify.app, на платформе.
Исследуйте 1xbet-egypt.netlify.app, невероятные возможности.
Откройте для себя мир 1xbet-egypt.netlify.app, благодаря.
Узнайте о лучших предложениях на 1xbet-egypt.netlify.app, ваши шансы увеличиваются.
Делайте ставки с умом на 1xbet-egypt.netlify.app, что бы.
Развлекитесь на 1xbet-egypt.netlify.app, где.
Успех начинается с 1xbet-egypt.netlify.app, где каждый шаг — это шанс.
Цените каждый момент на 1xbet-egypt.netlify.app, с вашим лучшим другом.
Ставьте на выигрыш с 1xbet-egypt.netlify.app, игра становится захватывающей.
Позвольте 1xbet-egypt.netlify.app удивить вас, где.
onexbet app [url=https://1xbet-egypt.netlify.app/]onexbet app[/url] .
Professional Seattle power washing — effective cleaning of facades, sidewalks, driveways and other surfaces. Modern equipment, affordable prices, travel throughout Seattle. Cleanliness that is visible at first glance.
Professional retaining wall contractor — reliable service, quality materials and adherence to deadlines. Individual approach, experienced team, free estimate. Your project — turnkey with a guarantee.
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Подробнее тут – https://harmonybyagas.com/producto/agressive-anti-aging-program-6-productos
роллетные боксы [url=https://shkaf-parking-3.ru]https://shkaf-parking-3.ru[/url] .
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Исследовать вопрос подробнее – https://ukr-novyny-ua.ru/cina-gonin-na-sorokina-11-000-v-misyac-quot/.html
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить дополнительные сведения – http://cuisinepourtous.fr/tous-en-cuisine-livre_gateau_yaourt
This really matches my view, helps to hear other opinions.
Thought I’d drop this here, I saw this page recently: [url=https://maba-3d-druck.de]came in handy for me[/url]
Let me know what you think.
кайт школа анапа Кайтсерфинг в Анапе – это не просто занятие спортом, это целая философия, в которой солнце, ветер и морские брызги играют главную роль. Анапа, с её обширными пляжами и предсказуемыми ветрами, стала излюбленным местом для кайтсерферов. Здесь можно увидеть как новичков, делающих первые шаги под присмотром опытных инструкторов, так и профессионалов, оттачивающих свои навыки в сложных трюках. Кайт-школа в Анапе – это место, где появляются новые звёзды кайтсерфинга. Школы предлагают разнообразные программы обучения для всех уровней подготовки, начиная с основ и заканчивая продвинутыми тренировками. Квалифицированные инструкторы, современное оборудование и индивидуальный подход обеспечивают быстрый прогресс и безопасность на воде. Кайт-школа в Анапе – это не только обучение кайтсерфингу, но и сообщество единомышленников, которых объединяет любовь к ветру и морю. Здесь можно завести новых друзей, получить полезные советы и просто хорошо провести время в компании людей, разделяющих ваши интересы. Кайтсерфинг в Анапе – это возможность убежать от повседневной рутины, ощутить свободу и испытать незабываемые впечатления. Представьте, как вы мчитесь по волнам, подгоняемые ветром, в то время как чайки кружат над вами, а солнце приятно согревает вашу кожу. Это не просто спорт, это приключение, которое останется в вашей памяти на всю жизнь. Кайтсерфинг в Благовещенской – это ещё одно популярное место для кайтсерфинга в Анапском районе. Здесь, на протяжённой косе, соединяющей Бугазский лиман и Чёрное море, созданы идеальные условия для катания. Неглубокая вода и устойчивый ветер делают Благовещенскую идеальным местом для обучения кайтсерфингу. Кайт Блага – это сокращённое название Благовещенской, которое часто используют кайтсерферы. Здесь есть несколько кайт-станций, предлагающих обучение, прокат оборудования и услуги по хранению. Кайтсерфинг в Анапе – это выбор тех, кто предпочитает активный отдых, любит ветер и море и готов принять новые вызовы. Присоединяйтесь к кайтсерферскому сообществу в Анапе и откройте для себя мир захватывающих приключений! DETIVETRA (ДЕТИ ВЕТРА) – это не просто название, это жизненная философия. Это те, кто чувствует ветер, не боится перемен и всегда открыт для новых впечатлений. Присоединяйтесь к ДЕТЯМ ВЕТРА и почувствуйте себя частью чего-то большего!
Vizyondaki en iyi yapımlar şimdi full hd film kalitesinde burada
ful hd film izle [url=https://www.filmizlehd.co/]https://www.filmizlehd.co/[/url] .
Майстер-клас із мексиканської кухні – це ідеальний спосіб дізнатися більше про культуру через смак. Дякую [url=https://northamerica.sff.in.ua]порталу культурних подій[/url] за таку чудову можливість!
Заказать диплом университета по невысокой цене вы сможете, обращаясь к надежной специализированной фирме. Заказать диплом о высшем образовании: [url=http://regularjobz.com/employer/diplomy-grup-24/]regularjobz.com/employer/diplomy-grup-24[/url]
888starz app download [url=https://888starz-official.com]888starz app download[/url] .
В этот этап включено:
Углубиться в тему – [url=https://kachestvo-vyvod-iz-zapoya.ru/]вывод из запоя новосибирская область[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Выяснить больше – https://narcolog-na-dom-ekaterinburg00.ru
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя клиника[/url]
Группа препаратов
Получить больше информации – https://narcolog-na-dom-ekaterinburg000.ru/
Современные технологии позволяют:
Детальнее – [url=https://kachestvo-vyvod-iz-zapoya.ru/]вывод из запоя на дому новосибирск[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя круглосуточно[/url]
Джазовий фестиваль у Нью-Орлеані від [url=https://northamerica.sff.in.ua/]North America SFF[/url] – це подія, яку я пропустив, але тепер обов’язково планую відвідати наступного року. Джаз живий, і я хочу його почути.
Need transportation? transporting companies car transportation company services — from one car to large lots. Delivery to new owners, between cities. Safety, accuracy, licenses and experience over 10 years.
https://infocus50.com/
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом екатеринбург[/url]
Нужна камера? купить камеру видеонаблюдения с wifi для дома, офиса и улицы. Широкий выбор моделей: Wi-Fi, с записью, ночным видением и датчиком движения. Гарантия, быстрая доставка, помощь в подборе и установке.
кайт анапа Анапа – это место, где можно найти новых друзей.
Can a Cash Flow Statement predict the future revenue of an online learning platform, like the one discussed here, based on student enrollment trends and course offerings? If so, how can we, the students and potential investors, leverage this information to make informed decisions about our learning paths and investments?
Приветствую всех поклонников транса! Trance Community — это то место, где музыка обретает настоящее значение. Я наткнулся на их [url=http://trance.mk.ua/forum/forumdisplay.php?f=24]обсуждение лайнап-фестивалей[/url] и был удивлён, насколько там живое и тёплое сообщество. Вдохновлённый, я решил отправиться на Trance Illusion, где услышал свой первый сет Ferry Corsten. Это было что-то невероятное! После фестиваля я продолжил обсуждения на форуме, делился эмоциями и находил единомышленников. Теперь Trance Community — это часть моей жизни. А что для вас значит быть частью этого мира?
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]наркология вывод из запоя[/url]
Временная прописка в Москве нужна всем, кто планирует находиться в городе более трёх месяцев, независимо от цели пребывания: сколько стоит регистрация в москве
Вывод из запоя в «Сибирском Докторе» происходит в несколько взаимосвязанных этапов:
Исследовать вопрос подробнее – http://kachestvo-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk/
888starz affiliation [url=http://888starz-official.com/]http://888starz-official.com/[/url] .
Шлюхи Тюмени
Ремонтика Сервис фирма — ваш надежный ассистент в исправлении бытовой техники. Мы предлагаем надежный сервис посудомоек. Оформить регистрацию просто — оставьте заявку на нашем сайте https://remontika-service.ru/. Мы работаем незамедлительно и недорого. Доверьте уход профессионалам Ремонтика Сервис!
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Подробнее тут – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]наркологический вывод из запоя[/url]
Если вы снимаете жильё в Москве, временная регистрация защитит ваши интересы и упростит общение с государственными службами https://registraceja-v-moskverus-1669.ru/
В этот этап включено:
Подробнее тут – [url=https://kachestvo-vyvod-iz-zapoya.ru/]нарколог вывод из запоя[/url]
נערת ליווי. בבוקר אנדריי הרגיש מוזר: כאילו קרה משהו שמשנה חיים בלילה, ועכשיו הוא נושא את זה הפנים. אולי עוד משהו. בינתיים נותרו שלושה. אני לא חושב, כרעתי על האדמה, פתחתי בירה שרק הספקתי דירה דיסקרטית פרטית ודרכים למימוש פנטזיות
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]narkolog-vyvod-iz-zapoya[/url]
Эти процедуры направлены на фильтрацию плазмы и избавление крови от токсинов:
Получить дополнительную информацию – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя цена красноярск[/url]
Если вы проживаете в столице более 90 дней, регистрация обязательна по закону, даже при наличии постоянной прописки в другом регионе https://propiska-moskva677.ru/
“כן, זה בהחלט לא נראה כמו התאגידים שלנו,” הוא ענה ולוגם ויסקי. משקה קר הרגיע מעט את עצביו. אבל לפחות זה לא נראה טיפשי. הנהן אלי והלך במהירות. כן, ויקה לא תיקנה שום דבר, אולי באמת הלכתי נערות ליווי באשקלון
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Разобраться лучше – [url=https://narkolog-na-dom-ekaterinburg11.ru/]нарколог на дом круглосуточно[/url]
Could we delve into unconventional online courses that foster critical thinking and problem-solving skills, rather than just focus on academic subjects? Perhaps, a course in applied logic or creative problem-solving could be beneficial for CBSE students?
Привет всем! Trance Community стал для меня местом, где я нашёл настоящую музыкальную семью. Всё началось с обсуждения сетов на их [url=http://trance.mk.ua/forum/forumdisplay.php?f=24]форуме о лайнапах[/url]. Люди делились своими ожиданиями от фестиваля Trance Reality, и это вдохновило меня отправиться туда. На фестивале я услышал потрясающий сет от Markus Schulz, а потом познакомился с ребятами, которые до этого обсуждали каждую деталь фестиваля на форуме. Мы вместе провели весь вечер, танцуя под треки Above & Beyond, и это было как встреча со старыми друзьями. Теперь я каждый вечер захожу на Trance Community, чтобы обсудить новые треки и фестивальные планы. А как вас вдохновило это сообщество?
Алкогольный запой представляет собой длительное бесконтрольное приём спиртного, приводящее к тяжёлой интоксикации и серьёзным осложнениям для органов и психики. В Новосибирске клиника «Сибирский Доктор» предлагает качественный вывод из запоя с применением инновационных технологий и участием опытных наркологов, терапевтов и психиатров. Наш подход сочетает мгновенную реакцию на вызов, современное оборудование и индивидуальные схемы лечения, что позволяет достичь стабильной ремиссии и снизить риск рецидива.
Исследовать вопрос подробнее – https://kachestvo-vyvod-iz-zapoya.ru/
Растворы для детоксикации
Изучить вопрос глубже – http://narcolog-na-dom-ekaterinburg00.ru
Прививаем любовь к природе с детства! На нашем сайте вы найдете увлекательные игры, викторины и головоломки, посвященные миру животных и растений. Мы предлагаем развивающие материалы для детей всех возрастов, а также советы для родителей и педагогов о том, как организовать познавательные экскурсии на природу и привить детям любовь к [url=https://kedroteka.ru/]окружающей среде[/url]. Сделаем вместе мир зеленее и добрее!
Мебель для жизни, мебель для вас! Мы предлагаем широкий выбор столов, [url=https://ecokrovatka-domik.ru/]шкафов[/url], кроватей и других предметов интерьера, которые помогут вам создать дом вашей мечты. Наша мебель отличается стильным дизайном, высоким качеством и функциональностью. Мы предлагаем мебель для гостиной, спальни, кухни, детской и офиса. У нас вы найдете все, что нужно для обустройства вашего дома, от небольших аксессуаров до полноценных мебельных гарнитуров. Почувствуйте комфорт и уют в своем доме с нашей мебелью!
Полный набор программ для вашего ПК – все в одном месте! Наш сайт предлагает вам широкий [url=https://softisntall.ru/]выбор необходимого софта[/url], включая аудиоплеер AIMP, текстовый редактор Word, программы для скачивания торрентов и архиватор WinRAR. Все программы доступны для бесплатного скачивания и прошли проверку на вирусы. Мы предлагаем удобную навигацию и подробные описания для каждой программы, чтобы вы могли легко найти и установить нужное вам ПО. Сделайте ваш компьютер максимально функциональным и удобным в использовании!
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]екатеринбург[/url]
При поступлении вызова специалисты клиники «СтопТокс» оперативно выезжают на дом в Екатеринбурге или по всей Свердловской области. По прибытии врач проводит всестороннюю диагностику, включая измерение артериального давления, пульса и уровня кислорода в крови, а также собирает анамнез и оценивает степень интоксикации. На основе полученной информации составляется индивидуальный план лечения, который включает следующие этапы:
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg000.ru/]врач нарколог на дом свердловская область[/url]
«Сибирский Доктор» оснащён передовыми медицинскими аппаратами и программным обеспечением для контроля за пациентом на каждом этапе лечения:
Исследовать вопрос подробнее – https://kachestvo-vyvod-iz-zapoya.ru
На психическом уровне затяжные запои усугубляют тревожность, депрессию и приводят к паническим атакам. Человек становится раздражительным, агрессивным, теряет социальные и трудовые навыки, что нередко перерастаeт в бытовые и профессиональные аварии. Без своевременного начала инфузионной терапии риск судорог, делирия и жизнеугрожающих осложнений возрастает в разы.
Выяснить больше – http://kapelnica-ot-zapoya-moskva1.ru
Алкогольная интоксикация разрушает организм изнутри. В первую очередь страдает центральная нервная система: снижается уровень витаминов группы B, нарушаются когнитивные функции, появляются раздражительность, бессонница, панические атаки. Следом — страдает печень, главный орган метаболической детоксикации. Под действием этанола её функции подавляются, а токсины накапливаются в крови. Это вызывает системное отравление и разрушает внутренние органы.
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-msk55.ru/]врача капельницу от запоя[/url]
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Изучить вопрос глубже – [url=https://narkolog-na-dom-ekaterinburg12.ru/]вызвать нарколога на дом[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя капельница[/url]
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Исследовать вопрос подробнее – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя на дому круглосуточно[/url]
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Ознакомиться с деталями – http://medicinskij-vyvod-iz-zapoya.ru/
I totally agree with your point, this is valuable.
Ran into something similar, I saw a link recently: [url=https://maba-3d-druck.de]some of you may like it[/url]
Let me know what you think.
Современные технологии позволяют:
Исследовать вопрос подробнее – [url=https://kachestvo-vyvod-iz-zapoya.ru/]вывод из запоя цена[/url]
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Углубиться в тему – http://ukr-novyny-ua.ru/internet-poimel-matricyu-a-xakeri-pruti-vid-filmu/.html
Временная регистрация в Москве подтверждает ваше законное пребывание и позволяет пользоваться всеми городскими услугами https://propiska-moskva677.ru/
For more information [url=https://ancientcivs.ru]https://ancientcivs.ru[/url] .
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Разобраться лучше – https://www.britthillbom.com/8-2/spanare_iv_storw_beskuren
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее тут – http://www.atelier-athanor.fr/174/fleur-tuteur-2
car hauling cheap car transport
Шлюхи Тюмени
Каждый день запоя увеличивает риск для жизни. Не рискуйте — специалисты в Сочи приедут на дом и окажут экстренную помощь. Без боли, стресса и ожидания.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя на дому цена[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя анонимно[/url]
Основная процедура включает в себя:
Подробнее можно узнать тут – http://narcolog-na-dom-krasnodar0.ru/vyzov-narkologa-na-dom-krasnodar/
ai therapist chat [url=ai-therapist6.com]ai-therapist6.com[/url] .
mental health support chatbot [url=https://mental-health1.com]https://mental-health1.com[/url] .
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]ekaterinburg[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя на дому[/url]
Balloons Dubai https://balloons-dubai1.com stunning balloon decorations for birthdays, weddings, baby showers, and corporate events. Custom designs, same-day delivery, premium quality.
ai therapist [url=www.ai-therapist6.com]www.ai-therapist6.com[/url] .
Когда организм на пределе, важна срочная помощь в Сочи — это команда опытных наркологов, которые помогут быстро и мягко выйти из запоя без вреда для здоровья.
Выяснить больше – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя анонимно[/url]
mental health app [url=https://www.mental-health1.com]https://www.mental-health1.com[/url] .
При длительном запое или серьезной алкогольной интоксикации часто нет возможности или желания ехать в стационар. В таких ситуациях оптимальным решением становится вызов нарколога на дом в Сочи. Специалисты клиники «Жизнь без Запоя» круглосуточно приезжают к пациентам, оперативно оказывают медицинскую помощь и проводят профессиональную детоксикацию организма прямо в домашних условиях. Благодаря комфортному лечению на дому пациенты быстрее восстанавливаются, избегают дополнительного стресса и осложнений, связанных с госпитализацией.
Получить дополнительную информацию – [url=https://narcolog-na-dom-sochi0.ru/]вызвать нарколога на дом[/url]
download steam desktop authenticator
Самостоятельно выйти из запоя — почти невозможно. В Сочи врачи клиники проводят медикаментозный вывод из запоя с круглосуточным выездом. Доверяйте профессионалам.
Ознакомиться с деталями – [url=https://narkolog-na-dom-ekaterinburg11.ru/]вызов нарколога на дом[/url]
Своевременное вмешательство специалиста позволяет не только вывести токсины, но и снизить риск развития осложнений, обеспечить восстановление жизненно важных функций организма и предотвратить ухудшение состояния, что особенно важно для сохранения здоровья и жизни пациента.
Выяснить больше – [url=https://narcolog-na-dom-krasnodar0.ru/]выезд нарколога на дом в краснодаре[/url]
https://sdasteam.com/
download steam desktop authenticator
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Узнать больше – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя цена[/url]
Мы изготавливаем дипломы психологов, юристов, экономистов и любых других профессий по невысоким тарифам.– [url=http://topnewsgadget.ru/kak-byistro-kupit-diplom-i-ne-popastsya/]topnewsgadget.ru/kak-byistro-kupit-diplom-i-ne-popastsya[/url]
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Детальнее – https://narcolog-na-dom-krasnodar0.ru/narkolog-na-dom-kruglosutochno-krasnodar/
What if we could time-travel to attend the lectures of the world’s greatest minds, such as Einstein or Newton, all while sitting comfortably at home and learning alongside CBSE peers? Is there an online course that can simulate this experience?
Привет, тусовка! Trance Illusion оказался даже лучше, чем я ожидал. На этом фестивале я увидел, как музыка объединяет людей из самых разных уголков мира. Один из самых ярких моментов произошёл во время выступления Markus Schulz, когда люди начали запускать в воздух светящиеся шары. Это было так красиво, что у меня аж мурашки побежали. А позже я нашёл [url=http://tranceillusion.mk.ua/about/]зону для релакса[/url], где все просто лежали на траве и слушали мелодичные треки. Это было идеальное завершение вечера. А какие моменты фестивалей у вас вызывают наибольшее восхищение? Поделитесь своими историями!
Инфузия проводится под постоянным контролем медицинского персонала. Длительность процедуры составляет от одного до трёх часов. Уже во время капельницы наблюдается снижение головной боли, исчезновение тошноты, выравнивание давления и общее улучшение состояния.
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-msk55.ru
Приобретение документа о высшем образовании через надежную компанию дарит ряд плюсов для покупателя. Заказать диплом о высшем образовании: [url=http://soc.robik.net/read-blog/12197_kupit-attestat-11-klassov-cena.html]soc.robik.net/read-blog/12197_kupit-attestat-11-klassov-cena.html[/url]
Заказать диплом о высшем образовании. Изготовление диплома занимает немного времени, а стоимость – невысокая. В результате вы имеете возможность сберечь деньги и время и получить работу вашей мечты. Приобрести диплом возможно используя сайт компании. – [url=http://canworkers.ca/employer/russiany-diplomans/]canworkers.ca/employer/russiany-diplomans[/url]
В Сочи решение есть — наркологическая клиника. Здесь помогают людям выйти из запоя без страха и осуждения. Всё анонимно, грамотно и с заботой о каждом пациенте.
Углубиться в тему – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя цена[/url]
Чем дольше человек находится в состоянии запоя, тем больше накапливаются токсины в организме, что негативно сказывается на всех системах. Отказ от алкоголя без должного контроля может привести к серьезным последствиям, таким как:
Разобраться лучше – [url=https://narcolog-na-dom-krasnodar0.ru/]запой нарколог на дом[/url]
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Получить больше информации – [url=https://narcolog-na-dom-sochi0.ru/]вызвать нарколога на дом сочи[/url]
Купить диплом университета !
Приобретение диплома университета России в нашей компании – надежный процесс, потому что документ будет заноситься в государственный реестр. Приобрести диплом об образовании [url=http://diplomj-irkutsk.ru/kupit-diplom-s-reestrom-bistro-i-bez-xlopot-2/]diplomj-irkutsk.ru/kupit-diplom-s-reestrom-bistro-i-bez-xlopot-2[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Узнать больше – [url=https://vyvod-iz-zapoya-ekaterinburg22.ru/]вывод из запоя недорого[/url]
Затяжной запой опасен для жизни. Врачи наркологической клиники в Сочи проводят срочный вывод из запоя — на дому или в стационаре. Анонимно, безопасно, круглосуточно.
Подробнее тут – [url=https://narkolog-na-dom-ekaterinburg12.ru/]нарколог на дом вывод[/url]
Эта статья для ознакомления предлагает читателям общее представление об актуальной теме. Мы стремимся представить ключевые факты и идеи, которые помогут читателям получить представление о предмете и решить, стоит ли углубляться в изучение.
Подробнее тут – https://www.kusz.at/tanzperformance-julia-bader-und-maxim-jurik
steam mobile authenticator
Is it possible to create a cash flow statement for an online course provider, considering enrollment fees, instructor salaries, and marketing expenses as key cash inflows and outflows? If so, what metrics would be crucial in optimizing this statement for better financial performance?
Trance Illusion превзошёл все ожидания. Один из самых запоминающихся моментов — сет Cosmic Gate с неоновыми браслетами и пением толпы. Позже в [url=http://tranceillusion.mk.ua/about/]зоне чиллаута[/url] удалось немного отдохнуть перед ночными сетами. Какие моменты на фестивалях самые яркие?
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Подробнее можно узнать тут – https://www.soldat.ru/forum/viewtopic.php?f=2&t=19437
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее – https://jornalbaixadasantista.com.br/2024/05/12/joao-pessoa-film-commission-articula-gravacao-de-producao-sobre-tomas-santa-rosa
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Подробнее – http://angarsk-goradm.ru/news/2014/5/28
Каталог 55opt: большие искусственные цветы высшего класса Изучить предложения: [url=https://55opt.org/catalog/bolshie-iskusstvennye-cvety/]https://55opt.org/catalog/bolshie-iskusstvennye-cvety/[/url]
интересные цветочные горшки [url=http://www.dizaynerskie-kashpo.ru]http://www.dizaynerskie-kashpo.ru[/url] .
888starz вход [url=888starz-official.com]888starz вход[/url] .
Dear Instructors, can you recommend an unconventional online course that not only covers the CBSE syllabus but also helps students develop a unique problem-solving approach, akin to Sherlock Holmes or Albert Einstein?
Эй, народ! Trance Illusion был далеко не таким идеальным, как я ожидал. Музыка, конечно, на высшем уровне, но с организацией полный хаос. На [url=http://tranceillusion.mk.ua/faq/]территории[/url] не хватало зон с питьевой водой, а туалеты часто были грязными. Освещение в вечернее время было настолько слабым, что я несколько раз чуть не упал, спотыкаясь о ступеньки. Вся эта ситуация заставила меня задуматься, что даже самый крутой лайнап не компенсирует дискомфорт. А у вас были такие разочарования? Напишите, интересно узнать!
Как работает доставка алкоголя и почему всё больше людей ей пользуются
доставка алкоголя на дом москва [url=https://www.alcocity01.ru/]доставка алкоголя 24 часа москва[/url] .
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Детальнее – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя наркология в сочи[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительные сведения – http://kapelnica-ot-zapoya-sochi00.ru
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Получить дополнительные сведения – http://
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Подробнее можно узнать тут – http://narcolog-na-dom-ekaterinburg00.ru
Майстер-клас із аргентинського танго вразив мене навіть через екран. На [url=https://southamerica.sff.in.ua]сайті танцювальної культури</url] я знайшла всі подробиці й тепер планую свою участь.
[url=https://finexpertiza.by/services_tag/yuridicheskie-uslugi/]оказание юридических услуг юридическим лицам[/url]
Действие и назначение
Разобраться лучше – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом вывод в екатеринбурге[/url]
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Ваша повседневная техника вышла из строя? Компания Сервисный центр ДевайсКлиник предлагает качественный ремонт любой аппаратуры. Наши специалисты имеют знания для исправления любых дефектов. Мы используем только надежные материалы. Гарантируем быстроту и выгодные цены. Оставьте заявку на сайте https://deviceclinic.ru/ и верните любимую технику к идеальному состоянию уже сегодня!
Основной этап лечения — детоксикация. С помощью капельниц врач вводит препараты, которые быстро выводят токсины и нормализуют обменные процессы, снимают симптомы абстиненции и восстанавливают работу внутренних органов. Уже спустя 1–2 часа после начала процедуры пациент ощущает значительное улучшение.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-korolev2.ru/srochnyj-vyvod-iz-zapoya
керамогранит сайт плитки плитка 600х1200
онлайн займы
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-korolev2.ru/]вывод из запоя королев[/url]
займ на карту
Лучшие напитки с доставкой: от вин до коллекционного виски
доставка алкоголя ночью в москве [url=http://www.alcocity01.ru]доставка алкоголя 24 часа[/url] .
[url=https://finexpertiza.by/services/yuridicheskie-uslugi/yuridicheskaya-konsultatsiya/]консультация по юридическим вопросам[/url]
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Подробнее – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-kazani.ru/]srochnyj-vyvod-iz-zapoya.ru/[/url]
В клинике «Нарколог-Профи» используются только проверенные и сертифицированные медикаменты, подбираемые индивидуально для каждого пациента. Ниже представлена таблица с основными группами препаратов и их функциями:
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом екатеринбург[/url]
Здесь собраны самые притягательные девушки Питера, каждая из которых готова порадовать вас своим обаянием. Находите совместные интересы и создавайте воспоминания, которые останутся с вами надолго. Пусть общение станет для вас источником радости https://spb-night.com/
Как подчёркивает врач-нарколог клиники «Крылья Надежды» Андрей Кузьмин: «Своевременное обращение к специалистам гарантирует не только быстрое восстановление, но и предупреждает развитие тяжёлых осложнений, которые могут навсегда изменить жизнь пациента».
Узнать больше – http://vyvod-iz-zapoya-korolev2.ru
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма на дому[/url]
888starz скачать на андроид [url=http://www.888starz-official.com]888starz скачать на андроид[/url] .
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ekaterinburg00.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Образовательные программы: Мы уверены, что знания о зависимости и её последствиях играют важную роль в реабилитации. Мы информируем пациентов о механизмах действия наркотиков и алкоголя на организм, что способствует изменению их отношения к терапии и жизни без зависимостей.
Подробнее можно узнать тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]вывод из запоя недорого[/url]
Психологическая реабилитация: Психологическая поддержка – один из главных аспектов нашего подхода. Мы предлагаем индивидуальные и групповые занятия, помогающие осознать зависимость, проработать эмоциональные травмы и сформировать новые модели поведения. Опытные психологи помогают пациентам понять причины своих зависимостей, что является важным шагом на пути к выздоровлению.
Ознакомиться с деталями – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-kruglosutochno-v-kazani.ru/]вывод из запоя капельница[/url]
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Разобраться лучше – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-anonimno
look at these guys [url=https://sollet-wallet.io]Sollet[/url]
Наркологическая клиника «Крылья Надежды» в Королеве оказывает квалифицированную помощь в выводе из запоя с применением безопасных, сертифицированных методик и круглосуточным наблюдением специалистов.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya koroleva[/url]
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg00.ru/]narkolog-na-dom-kruglosutochno ekaterinburg[/url]
Здесь можно найти девушек на любой вкус и цвет, так что свободно выбирай ту, которая завладеет твоим сердцем. Никаких сомнений, этот сайт позволяет открыть новые горизонты общения и участие в увлекательных мероприятиях. Наслаждайся знакомствами на полную катушку https://spb-night.com/
dig this [url=https://sollet-wallet.io]Solet.io[/url]
Как подчёркивает врач-нарколог клиники «Крылья Надежды» Андрей Кузьмин: «Своевременное обращение к специалистам гарантирует не только быстрое восстановление, но и предупреждает развитие тяжёлых осложнений, которые могут навсегда изменить жизнь пациента».
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya korolev[/url]
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Подробнее тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma ceny[/url]
Коли думаєш, що все бачив — [url=https://cola.trance.mk.ua]Cola дивує знову[/url].
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Углубиться в тему – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]centr kodirovaniya ot alkogolizma[/url]
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
anonymous [url=https://sollet-wallet.io]Best solana wallet[/url]
Таким образом, наш подход направлен на создание комплексной системы поддержки, которая помогает каждому пациенту справиться с зависимостью и вернуться к полноценной жизни.
Подробнее можно узнать тут – [url=https://srochnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-v-stacionare-v-kazani.ru/]вывод из запоя в стационаре[/url]
Растворы для детоксикации
Выяснить больше – [url=https://narcolog-na-dom-ekaterinburg00.ru/]www.domen.ru[/url]
you could look here [url=https://sollet-wallet.io/]Sollet.io[/url]
Thanks for sharing. I read many of your blog posts, cool, your blog is very good.
Срочное вмешательство врача необходимо при появлении следующих симптомов:
Детальнее – http://vyvod-iz-zapoya-korolev2.ru/
Профессиональное продажа косметологического оборудования для салонов красоты, клиник и частных мастеров. Аппараты для чистки, омоложения, лазерной эпиляции, лифтинга и ухода за кожей.
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Детальнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma odincovo[/url]
see it here [url=https://sollet-wallet.io/]Sollet.io[/url]
svt-stroy.ru – Все о стройке и ремонте.
Разбираем подробно – Как сделать елку своими руками на Новый год в нашем строительном блоге.
Советы опытных специалистов, дизайнеров и инженеров! Ремонтируйте свой загородный дом с умом!
ultimate createporn generator. Create hentai art, porn comics, and NSFW with the best AI porn maker online. Start generating AI porn now!
консультация юриста https://besplatnaya-yuridicheskaya-konsultaciya-moskva-po-telefonu.ru
купить септик для частного дома в москве и московской области [url=septik-pod-klyuch-1.ru]septik-pod-klyuch-1.ru[/url] .
If Cash Flow Statements could talk, what surprising insights about online learning and standard 10, CBSE students’ development might they reveal?
Привет, друзья! Trance Reality удивил меня своей масштабностью. Всё было продумано до мелочей: от зон отдыха до интерактивных активностей. Один из самых ярких моментов для меня случился, когда я оказался в [url=http://trancereality.mk.ua/about/]творческой зоне[/url]. Там предлагали попробовать себя в роли художника, создающего визуальные эффекты под музыку. Это было так круто, что я забыл о времени! А вечером, когда на сцену вышли Markus Schulz и Above & Beyond, я понял, что это лучший фестиваль в моей жизни. А у вас были такие моменты, которые навсегда остались в памяти?
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma odincovo[/url]
Привет, тусовка! Trance Reality стал для меня местом, где я понял, что музыка объединяет людей. Одним из самых ярких моментов был сет Gareth Emery, который играл под невероятное световое шоу. Позже я отправился в [url=http://trancereality.mk.ua/tickets/]зону активности[/url], где попробовал свои силы в создании световых эффектов для треков. Это было настолько увлекательно, что я провёл там больше часа. А потом вернулся на танцпол, чтобы услышать финальный трек от Mark Sherry. Этот вечер останется в моей памяти навсегда. А что делает фестивали незабываемыми для вас?
888 starz app [url=888starz-official.com]888 starz app[/url] .
Якщо ви ще не чули про команду Dr Pepper, обов’язково подивіться на [url=https://drpepper.trance.mk.ua/]наші досягнення[/url]. Ми спеціалізуємося на Battle Nexus і готові показати вам, як вигравати!
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Изучить вопрос глубже – http://vyvod-iz-zapoya-krasnogorsk2.ru
click here now https://web-foxwallet.com/
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Подробнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya krasnogorsk[/url]
this post https://web-foxwallet.com/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Получить больше информации – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma gipnozom[/url]
site https://web-foxwallet.com/
read this post here https://web-foxwallet.com
find out here now https://web-foxwallet.com/
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить больше информации – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu
Check This Out https://web-foxwallet.com
click this over here now https://web-foxwallet.com
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma na domu[/url]
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Получить больше информации – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]вывод из запоя цена[/url]
Существуют ли базы, где можно проверить диплом на подлинность самому перед использованием? [url=https://inforepetitor.ru/]Купить диплом о среднем образовании[/url]
В 2025 году наличие диплома всё ещё остаётся основным фактором при приёме на работу, повышении по карьерной лестнице или получении лицензии. И если у вас нет необходимого документа — это не повод терять время на долгие годы учебы.
✅ Решение есть — покупка диплома, полностью соответствующего оригиналу:
С печатями, подписями, голограммами,
Внесение в архив (по запросу),
Любой ВУЗ, колледж — по всей России и СНГ.
Для кого подойдёт?
Вас отчислили, но обучение практически завершено?
Нашли перспективную работу, но нет диплома?
Нужен диплом для лицензирования, повышения, тендера?
Мы работаем без предоплаты (по договору или поэтапно) и гарантируем полную конфиденциальность. У нас нет шаблонов — каждый документ готовится индивидуально, с учётом всех нюансов.
Наши гарантии:
Диплом, неотличимый от оригинала
Настоящие данные выпускника (по вашей анкете)
Быстрая доставка по России и СНГ
Юридически грамотно оформленный договор (по желанию)
Мы сотрудничаем с квалифицированными специалистами, которые знают, как должен выглядеть официальный документ — вплоть до мельчайших деталей. У нас много лет опыта и более random[900..3999] довольных клиентов.
купить диплом россия
источник
ссылка
как купить диплом о высшем образовании
Диплом вуза
Готовый диплом — быстро, без нервов и с гарантией?
go to the website https://web-foxwallet.com
?? У кого в дипломе хоть раз была правда?
Вот реально: вы когда-нибудь смотрели свой диплом и думали — “да, всё, что здесь написано, я действительно знаю и умею”?
У многих — только бумажка. Корочка, глянцевая, с гербом и подписями, которую HR пролистывает за 1,5 секунды. А потом спрашивают: опыт, кейсы, компетенции, “что умеешь по факту?”. Диплом где-то там, в мнимом мире.
Но парадокс в том, что без диплома тебе даже не дадут шанс показать, что ты умеешь.
Ты можешь быть хорошим специалистом, уметь в IT, дизайн, управление, логистику — но без документа с золотым тиснением не попадешь на собеседование.
?? Нормально ли это? Нет. Реальность ли это? Да.
Вот потому и появляются сервисы, которые дают предложение:
“Не хочешь тратить 5 лет ради корочки? Мы поможем. Тебе нужен не вуз — тебе нужен диплом.”
Ты его получаешь, кладёшь в резюме, и дальше всё зависит от твоих мозгов, а не от шрифта на бумаге.
Кто-то скажет: “Это обман!”
А кто-то — “Это адаптация к системе, которая обманывает тебя с детства”.
?? И что в итоге?
Диплом становится не подтверждением знаний, а входным билетом. Как QR-код в метро — проверили, что есть, и пропустили.
Поэтому люди и задумываются о покупке диплома.
Не потому что глупые. А потому что взрослые, занятые, уставшие от лишнего.
Потому что хотят не учиться “ради процесса”, а работать по делу.
?? Ирония в том, что большинство таких дипломов — работают.
Даже если ты их не учил — ты знаешь, как применить. А вот “настоящие выпускники” потом всё равно идут на курсы и стажировки, потому что ничего не помнят.
И что важнее: корочка или то, как ты справляешься с задачей?
?? У кого были такие мысли — пишите. У кого был опыт — делитесь.
Кто получал диплом с подписью и печатью — где заказывали? [url=https://spbrcom.ru/]Посмотреть[/url]
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya[/url]
my explanation https://web-foxwallet.com/
Кто сталкивался с покупкой диплома — стоит ли оно того? [url=https://inforepetitor.ru/]Как купить диплом[/url]
В 2025 году наличие диплома всё ещё остаётся ключевым фактором при приёме на работу, повышении по службе или получении лицензии. И если у вас нет необходимого документа — это не повод терять время на долгие годы учебы.
✅ Выход есть — оформление диплома на заказ, полностью соответствующего оригиналу:
С печатями, подписями, голограммами,
С занесением в архив (по запросу),
Любой ВУЗ, колледж — по всей России и СНГ.
Для кого подойдёт?
Вас отчислили, но обучение практически завершено?
Поступили на хорошую работу, но нет диплома?
Нужен диплом для лицензирования, повышения, тендера?
Мы работаем без предоплаты (по договору или поэтапно) и гарантируем полную конфиденциальность. У нас нет шаблонов — каждый документ готовится индивидуально, с учётом всех нюансов.
Наши гарантии:
Диплом, неотличимый от оригинала
Настоящие данные выпускника (по вашей анкете)
Быстрая и надежная доставка по России и СНГ
Юридически грамотно оформленный договор (по желанию)
Мы сотрудничаем с квалифицированными специалистами, которые знают, как должен выглядеть официальный документ — вплоть до мельчайших деталей. У нас много лет опыта и более random[900..3999] довольных клиентов.
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Детальнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]вывод из запоя капельница[/url]
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Детальнее – https://vyvod-iz-zapoya-krasnogorsk2.ru
Скільки разів ви мріяли про перемогу у світових кіберзмаганнях? Fanta показує, що це цілком реально, і ми готові поділитись своїми [url=https://fanta.trance.mk.ua/]секретами[/url] успіху!
read the full info here https://web-foxwallet.com
Are there any advanced, unconventional online courses for Std 10 CBSE students that could help them master time-travel theory or extraterrestrial communication skills?
Вони не просто пишуть, а створюють дійсно якісний і перевірений контент. Детальніше тут: [url=https://xyzdigitalmedia.com]інформація про їхню роботу[/url].
?? У кого в дипломе хоть раз была правда?
Вот реально: вы когда-нибудь смотрели свой диплом и думали — “да, всё, что здесь написано, я действительно знаю и умею”?
У многих — только бумажка. Корочка, глянцевая, с гербом и подписями, которую HR смотрит за 1,5 секунды. А потом начинается: опыт, кейсы, компетенции, “что умеешь по факту?”. Диплом где-то там, в глубокой папке.
Но реалия в том, что без диплома тебе даже не дадут шанс показать, что ты умеешь.
Ты можешь быть хорошим специалистом, уметь в IT, дизайн, управление, логистику — но без документа с золотым тиснением в кабинет не пустят.
?? Нормально ли это? Нет. Реальность ли это? Да.
Вот потому и появляются сервисы, которые говорят:
“Не хочешь тратить 5 лет ради корочки? Мы решим вопрос. Тебе нужен не вуз — тебе нужен диплом.”
Ты его получаешь, кладёшь в резюме, и дальше всё зависит от твоих мозгов, а не от шрифта на бумаге.
Кто-то скажет: “Это обман!”
А кто-то — “Это адаптация к системе, которая обманывает тебя с детства”.
?? И что в итоге?
Диплом становится не подтверждением знаний, а входным билетом. Как QR-код в метро — проверили, что есть, и пропустили.
Поэтому люди и задумываются о покупке диплома.
Не потому что глупые. А потому что взрослые, занятые, уставшие от лишнего.
Потому что хотят не учиться “ради процесса”, а работать по делу.
?? Ирония в том, что большинство таких дипломов — работают.
Даже если ты их не учил — ты знаешь, как применить. А вот “настоящие выпускники” потом всё равно идут на курсы и стажировки, потому что ничего не помнят.
И что важнее: корочка или то, как ты справляешься с задачей?
?? У кого были такие мысли — пишите. У кого был опыт — делитесь.
Где реально заказать диплом, который выглядит как оригинал, с корочкой, подписью ректора и без отличий от настоящего документа? [url=https://spbrcom.ru/]Доступно тут[/url]
КредитоФФ http://creditoroff.ru удобный онлайн-сервис для подбора и оформления займов в надёжных микрофинансовых организациях России. Здесь вы найдёте лучшие предложения от МФО
обслуживание бытовой электроники в компании Руками Эксперта — это безопасность, качество и приемлемый прайс. Наши ремонтники быстро найдут поломку и предложат выгодный вариант. Мы работаем с различными производителями. Оформите звонок прямо сейчас на https://rukami-experta.ru/ и получите гарантию. Ваш комфорт — наша цель!
Could a CBSE student master quantum physics by taking an online course in Standard 10? Or should they focus on skill development instead for better future prospects?
Мій малий не засинає без казки. Добре, що є аудіоказки тут: [url=https://xyzdigitalmedia.com]подивіться самі[/url]!
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Подробнее – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Узнать больше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie-ot-alkogolizma-odintsovo2.ru/[/url]
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Подробнее тут – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]срочный вывод из запоя[/url]
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Выяснить больше – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]нарколог вывод из запоя[/url]
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить дополнительную информацию – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Детальнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod-iz-zapoya-krasnogorsk2.ru/[/url]
посмотреть на этом сайте https://tripscanwin28.top
продолжить https://kra–36.at
Could a Cash Flow Statement for an online learning platform, such as the one offered for CBSE Std 10 students, reveal unexpected insights about student learning patterns and market trends, if analyzed creatively? For instance, could it forecast the popularity of particular courses, or predict the impact of educational policies on student enrollment?
Kind of unrelated, but it came to mind
I just the other day found a team called[url=https://sevenup.trance.mk.ua] Team 7Up[/url].
They’re a professional esports team focused on Battle Tactics. From what I saw — pure teamplay and structure over randomness.
Ever seen their games?
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Разобраться лучше – http://vyvod-iz-zapoya-krasnogorsk2.ru
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Узнать больше – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu
продолжить https://kra33–at.at
Кто заказывал диплом техникума, чтобы работать в сфере строительства или механики — как реагируют работодатели? [url=https://inforepetitor.ru/]см. подробнее[/url]
В 2025 году наличие диплома всё ещё остаётся ключевым фактором при приёме на работу, повышении по службе или получении лицензии. И если у вас нет необходимого документа — это не повод терять время на долгие годы учебы.
✅ Выход есть — оформление диплома на заказ, полностью соответствующего оригиналу:
С печатями, подписями, голограммами,
С занесением в архив (по запросу),
Любой ВУЗ, колледж — по всей России и СНГ.
Кому может пригодиться?
Вас выгнали, но обучение практически завершено?
Нашли интересную работы, но нет диплома?
Нужен диплом для лицензирования, повышения, тендера?
Мы работаем без предоплаты (по договору или поэтапно) и гарантируем полную конфиденциальность. У нас нет шаблонов — каждый документ готовится индивидуально, с учётом всех нюансов.
Что вы получаете:
Реалистичный диплом, неотличимый от оригинала
Настоящие данные выпускника (по вашей анкете)
Быстрая и надежная доставка по России и СНГ
Юридически грамотно оформленный договор (по желанию)
Мы сотрудничаем с квалифицированными специалистами, которые понимают, как должен выглядеть официальный документ — вплоть до мельчайших деталей. У нас много лет опыта и более random[900..3999] довольных клиентов.
В клинике «Горизонт Жизни» в Красногорске разработаны протоколы экстренного вывода из запоя, которые выполняются 24 часа в сутки, семь дней в неделю. Благодаря выезду бригады врачей-наркологов и оснащённости современным оборудованием мы оказываем помощь в кратчайшие сроки, обеспечивая максимальную безопасность и комфорт пациенту.
Детальнее – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu/
?? У кого в дипломе хоть раз была правда?
Вот реально: вы когда-нибудь смотрели свой диплом и думали — “да, всё, что здесь написано, я действительно знаю и умею”?
У многих — только бумажка. Корочка, глянцевая, с гербом и подписями, которую HR смотрит за 1,5 секунды. А потом спрашивают: опыт, кейсы, компетенции, “что умеешь по факту?”. Диплом где-то там, в мнимом мире.
Но парадокс в том, что без диплома тебе даже не дадут шанс доказать, что ты умеешь.
Ты можешь быть хорошим специалистом, уметь в IT, дизайн, управление, логистику — но без документа с золотым тиснением в кабинет не пустят.
?? Нормально ли это? Нет. Реальность ли это? Да.
Вот потому и появляются услуги, которые дают предложение:
“Не хочешь тратить 5 лет ради корочки? Мы решим вопрос. Тебе нужен не вуз — тебе нужен диплом.”
Ты его получаешь, кладёшь в резюме, и дальше всё зависит от твоих мозгов, а не от шрифта на бумаге.
Кто-то скажет: “Это обман!”
А кто-то — “Это адаптация к системе, которая обманывает тебя с детства”.
?? И что в итоге?
Диплом становится не подтверждением знаний, а входным билетом. Как QR-код в метро — проверили, что есть, и пропустили.
Поэтому люди и покупают.
Не потому что глупые. А потому что взрослые, занятые, уставшие от лишнего.
Потому что хотят не учиться “ради процесса”, а работать по делу.
?? Ирония в том, что большинство таких дипломов — работают.
Даже если ты их не учил — ты знаешь, как применить. А вот “настоящие выпускники” потом всё равно идут на курсы и стажировки, потому что ничего не помнят.
И что важнее: корочка или то, как ты справляешься с задачей?
?? У кого были такие мысли — пишите. У кого был опыт — делитесь.
Кто оформлял диплом для подачи в миграционные службы — приняли ли его документы? [url=https://spbrcom.ru/]Покупка диплома[/url]
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Узнать больше – http://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu/
Алкогольная зависимость — это хроническое заболевание, при котором устойчивое влечение к спиртному приводит к тяжёлым медицинским, социальным и психологическим последствиям. Когда пациент осознаёт, что самостоятельно справиться с этой проблемой не получается, наиболее эффективным методом становится кодирование от алкоголизма. В клинике «Ясное Будущее» в Одинцово мы используем сочетание проверенных методик кодирования и комплексной психологической поддержки, что позволяет достичь стойкой ремиссии и вернуть человеку контроль над собственной жизнью.
Ознакомиться с деталями – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-cena
страница https://kra-33cc.cc/
Could the ‘Imaginary Architecture’ of Alberti’s principles be applied to design a virtual learning environment for CBSE students, enhancing their problem-solving skills and understanding of mathematical concepts?
Як правильно заморожувати овочі? Ось [url=https://justtips.online]корисні лайфхаки[/url].
Кто-то получал диплом с приложением об успеваемости — как оформляется, и есть ли разница в цене и оформлении? [url=https://inforepetitor.ru/]Перейти[/url]
В 2025 году наличие диплома всё ещё остаётся ключевым фактором при приёме на работу, повышении по карьерной лестнице или получении лицензии. И если у вас нет необходимого документа — это не повод терять время на долгие годы учебы.
✅ Выход есть — заказ диплома, полностью соответствующего оригиналу:
С печатями, подписями, голограммами,
С занесением в архив (по запросу),
Любой ВУЗ, колледж — по всей России и СНГ.
Кому может пригодиться?
Вас отчислили, но обучение практически завершено?
Нашли перспективную работу, но нет диплома?
Нужен диплом для лицензирования, повышения, тендера?
Мы работаем без предоплаты (по договору или поэтапно) и гарантируем полную конфиденциальность. У нас нет шаблонов — каждый документ готовится индивидуально, с учётом всех нюансов.
Что вы получаете:
Диплом, неотличимый от оригинала
Настоящие данные выпускника (по вашей анкете)
Быстрая доставка по России и СНГ
Юридически грамотно оформленный договор (по желанию)
Мы сотрудничаем с квалифицированными специалистами, которые понимают, как должен выглядеть официальный документ — вплоть до мельчайших деталей. У нас много лет опыта и более random[900..3999] довольных клиентов.
Семейный юрист yuristy-ekaterinburga
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Выяснить больше – http://vyvod-iz-zapoya-krasnogorsk2.ru
пояснения https://kra33.co.at/
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Выяснить больше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]centr kodirovaniya ot alkogolizma[/url]
?? У кого в дипломе хоть раз была правда?
Серьезно: вы когда-нибудь открывали свой диплом и думали — “да, всё, что здесь написано, я действительно знаю и умею”?
У многих — только сертификат. Корочка, глянцевая, с гербом и подписями, которую HR смотрит за 1,5 секунды. А потом спрашивают: опыт, кейсы, компетенции, “что умеешь по факту?”. Диплом где-то там, в глубокой папке.
Но парадокс в том, что без диплома тебе даже не дадут шанс показать, что ты умеешь.
Ты можешь быть хорошим специалистом, уметь в IT, дизайн, управление, логистику — но без документа с золотым тиснением не попадешь на собеседование.
?? Нормально ли это? Нет. Реальность ли это? Да.
Вот потому и появляются услуги, которые говорят:
“Не хочешь тратить 5 лет ради корочки? Мы поможем. Тебе нужен не вуз — тебе нужен диплом.”
Ты его получаешь, кладёшь в резюме, и дальше всё зависит от твоих мозгов, а не от шрифта на бумаге.
Кто-то скажет: “Это обман!”
А кто-то — “Это адаптация к системе, которая обманывает тебя с детства”.
?? И что в итоге?
Диплом становится не подтверждением знаний, а входным билетом. Как QR-код в метро — проверили, что есть, и пропустили.
Поэтому люди и принимают такие решения.
Не потому что глупые. А потому что взрослые, занятые, уставшие от лишнего.
Потому что хотят не учиться “ради процесса”, а работать по делу.
?? Ирония в том, что большинство таких дипломов — работают.
Даже если ты их не учил — ты знаешь, как применить. А вот “настоящие выпускники” потом всё равно идут на курсы и стажировки, потому что ничего не помнят.
И что важнее: корочка или то, как ты справляешься с задачей?
?? У кого были такие мысли — пишите. У кого был опыт — делитесь.
Подскажите, кто покупал диплом срочно — Р·Р° 3-5 дней? Рто возможно вообще? [url=https://spbrcom.ru/]Купить диплом университета[/url]
купить сантехнику в донецке днр [url=santehnika-doneck-1.ru]santehnika-doneck-1.ru[/url] .
Готуєте тісто і воно не виходить? Дізнайтесь [url=https://justtips.online]корисні трюки[/url] для випічки, які зроблять вашу здобу ідеальною.
нажмите здесь https://kra3-4.at/
«В первые часы после окончания запоя организм наиболее уязвим, и своевременное вмешательство значительно снижает риски осложнений», — подчёркивает заведующая отделением наркологической реанимации Елена Морозова.
Получить больше информации – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya krasnogorsk[/url]
цветочные горшки дизайнерские купить [url=https://www.dizaynerskie-kashpo.ru]цветочные горшки дизайнерские купить[/url] .
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Углубиться в тему – https://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu
Кто заказывал диплом и использовал для получения лицензии или патента — какие сложности? [url=https://inforepetitor.ru/]По ссылке[/url]
В 2025 году наличие диплома всё ещё остаётся основным фактором при приёме на работу, повышении по службе или получении лицензии. И если у вас нет необходимого документа — это не повод терять годы.
✅ Выход есть — оформление диплома на заказ, полностью соответствующего оригиналу:
С печатями, подписями, голограммами,
С занесением в архив (по запросу),
Любой ВУЗ, колледж — по всей России и СНГ.
Кому может пригодиться?
Вас отчислили, но обучение практически завершено?
Нашли интересную работы, но нет “корочки”?
Нужен диплом для лицензирования, повышения, тендера?
Мы работаем без предоплаты (по договору или поэтапно) и гарантируем полную конфиденциальность. У нас нет шаблонов — каждый документ готовится индивидуально, с учётом всех нюансов.
Наши гарантии:
Реалистичный диплом, неотличимый от оригинала
Настоящие данные выпускника (по вашей анкете)
Быстрая доставка по России и СНГ
Юридически грамотно оформленный договор (по желанию)
Мы сотрудничаем с квалифицированными специалистами, которые понимают, как должен выглядеть официальный документ — вплоть до мельчайших деталей. У нас много лет опыта и более random[900..3999] довольных клиентов.
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Подробнее – http://kodirovanie-ot-alkogolizma-odintsovo2.ru
[url=https://vpnfree2025.ru]vpnfree2025.ru[/url]
Скачайте рабочий впн для телефона на андройд по ссылке ниже:
vpnfree2025.ru
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Получить больше информации – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma na domu[/url]
?? У кого в дипломе хоть раз была правда?
Вот реально: вы когда-нибудь смотрели свой диплом и думали — “да, всё, что здесь написано, я действительно знаю и умею”?
У многих — только бумажка. Корочка, глянцевая, с гербом и подписями, которую HR пролистывает за 1,5 секунды. А потом начинается: опыт, кейсы, компетенции, “что умеешь по факту?”. Диплом где-то там, в мнимом мире.
Но парадокс в том, что без диплома тебе даже не дадут шанс доказать, что ты умеешь.
Ты можешь быть хорошим специалистом, уметь в IT, дизайн, управление, логистику — но без документа с золотым тиснением в кабинет не пустят.
?? Нормально ли это? Нет. Реальность ли это? Да.
Вот потому и появляются услуги, которые говорят:
“Не хочешь тратить 5 лет ради корочки? Мы поможем. Тебе нужен не вуз — тебе нужен диплом.”
Ты его получаешь, кладёшь в резюме, и дальше всё зависит от твоих мозгов, а не от шрифта на бумаге.
Кто-то скажет: “Это обман!”
А кто-то — “Это адаптация к системе, которая обманывает тебя с детства”.
?? И что в итоге?
Диплом становится не подтверждением знаний, а входным билетом. Как QR-код в метро — проверили, что есть, и пропустили.
Поэтому люди и ищат как купить диплом.
Не потому что глупые. А потому что взрослые, занятые, уставшие от лишнего.
Потому что хотят не учиться “ради процесса”, а работать по делу.
?? Ирония в том, что большинство таких дипломов — работают.
Даже если ты их не учил — ты знаешь, как применить. А вот “настоящие выпускники” потом всё равно идут на курсы и стажировки, потому что ничего не помнят.
И что важнее: корочка или то, как ты справляешься с задачей?
?? У кого были такие мысли — пишите. У кого был опыт — делитесь.
Можно ли оформить диплом с приложением, курсовыми и практикой, чтобы выглядел как настоящий выпускной комплект? [url=https://spbrcom.ru/]Доступно тут[/url]
[url=https://topvpn2025.ru]topvpn2025.ru[/url]
Скачайте бесплатно впн на андройд по ссылке ниже: topvpn2025.ru
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Подробнее тут – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Ниже приведены ключевые сигналы, при появлении которых требуется немедленное реагирование:
Ознакомиться с деталями – http://vyvod-iz-zapoya-krasnogorsk2.ru/vyvod-iz-zapoya-na-domu/
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Обратиться за помощью необходимо при:
Получить больше информации – [url=https://medicinskij-vyvod-iz-zapoya.ru/]срочный вывод из запоя в красноярске[/url]
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]vyvod iz zapoya na domu krasnogorsk[/url]
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Получить дополнительную информацию – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Компания АйТулз Адлер предлагает оперативный ремонт бытовой техники. Специалисты быстро и безупречно устраняют аварии любой категории. https://itools-adler.ru/. Обещаем конкурентные расценки и внимание к клиенту к каждому покупателю. Оставьте заявку уже немедленно, чтобы вернуть вашу технику быстро и без промедления!
Your article helped me a lot, is there any more related content? Thanks!
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Получить дополнительную информацию – [url=https://medicinskij-vyvod-iz-zapoya.ru/]вывод из запоя анонимно в красноярске[/url]
Эти процедуры направлены на фильтрацию плазмы и избавление крови от токсинов:
Детальнее – http://medicinskij-vyvod-iz-zapoya.ru
Could we delve deeper into the realm of quantum physics in our standard 10 curriculum? How about an online course that makes Einstein’s theories as accessible as a Game of Thrones episode?
Small off-topic post, but gamers will appreciate it
Recently I discovered a site https://sprite.trance.mk.ua.
It’s about the professional esports team Sprite, focusing on the mobile MOBA game Battle Arena.
Their gameplay is super sharp.
Also check out [url=https://sprite.trance.mk.ua]the Sprite team’s official Battle Arena page[/url].
Anyone here plays Battle Arena too?
взять займы онлайн без проверок займ под птс онлайн
На дом выезжает квалифицированный врач, который проводит процедуру детоксикации в комфортных условиях, позволяя пациенту избежать стресса и огласки. С помощью капельницы и медикаментов нормализуется состояние, восстанавливаются основные функции организма. Процедура длится несколько часов, после чего врач оставляет рекомендации по поддерживающему лечению.
Получить дополнительную информацию – https://vyvod-iz-zapoya-lyubertsy2.ru/vyvod-iz-zapoya-na-domu
купить врача диплом [url=http://sx-diplo24.ru/]купить врача диплом[/url] .
Алкогольный запой — это острое состояние тяжёлой интоксикации, при котором организм накапливает критические уровни продуктов распада этанола и перестаёт справляться с их нейтрализацией. При этом страдают важнейшие органы и системы: печень, почки, сердце, центральная нервная система. Без квалифицированной медицинской помощи риск развития судорог, алкогольного делирия и полиорганной недостаточности возрастает многократно.
Детальнее – [url=https://vyvod-iz-zapoya-krasnogorsk2.ru/]вывод из запоя на дому красногорск[/url]
What about enrolling in a course that teaches us to think like a futurist or a course in quantum mechanics for high school students? Are there any such unconventional online courses available for CBSE students that could spark curiosity and broaden our horizons?
Вибираєте продукти? Дізнайтесь, як знаходити якісні та корисні товари на [url=https://veryuseful.website/]сторінці харчових рекомендацій[/url].
Самолечение или игнорирование проблемы часто приводит к серьёзным осложнениям. Только профессиональная помощь гарантирует безопасный выход из алкогольного кризиса и минимизирует негативные последствия для организма.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-lyubertsy2.ru/vyvod-iz-zapoya-na-domu
Read More Here [url=https://coinb-se-log.org/]coinbase login[/url]
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Изучить вопрос глубже – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu
Заказать диплом ВУЗа по выгодной цене возможно, обращаясь к надежной специализированной фирме. Заказать диплом: [url=http://stratoplanlamatasarim.com/tolko-segodnja-kupit-diplom-s-garantiej-65/]stratoplanlamatasarim.com/tolko-segodnja-kupit-diplom-s-garantiej-65[/url]
their website https://xmaquina.cc/
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Исследовать вопрос подробнее – https://jennhanischphotography.com/blog/mr-mrs-lageson
internet https://exponent.my/
Киберспортивные события: На прошлых выходных прошло крупное киберспортивное событие по [url=https://arkadia30.ru/]игровой новинки[/url] “Дота 2”, где команда из Европы одержала победу, обыграв конкурентов с минимальным отрывом.
Обновления для CAD-программ: Объявлено о новых функциях в популярных [url=https://softisntall.ru/]ПО[/url], облегчающих работу архитекторов и инженеров. Новые инструменты для моделирования и совместной работы уже имеются.
Из-за продолжающегося роста цен на [url=https://statrk.ru/]жильё[/url] в крупных городах, молодые специалисты испытывают трудности с приобретением недвижимости. Аналитики предсказывают, что эта тенденция сохранится в ближайшем будущем.
Could a time-traveling CBSE student from the year 2050 teach a course on future-proof skills? And if so, which online platform would best accommodate a quantum leap in knowledge transfer?
Світ науки вражає! Ознайомтеся з останніми відкриттями на [url=https://veryuseful.website/]нашому науковому розділі[/url].
Женский блог https://zhinka.in.ua Жінка это самое интересное о красоте, здоровье, отношениях. Много полезной информации для женщин.
Затяжной запой представляет собой состояние, при котором организм накапливает токсичные продукты распада алкоголя, нарушается работа сердца, печени и нервной системы. Без своевременного медицинского вмешательства возможны серьёзные осложнения: судороги, алкогольный психоз и острые нарушения гемодинамики. В Красноярске клиника «Красмед» предлагает круглосуточную службу вывода из запоя с применением передовых методик детоксикации и постоянным контролем состояния пациента.
Детальнее – [url=https://medicinskij-vyvod-iz-zapoya.ru/]наркологический вывод из запоя[/url]
read what he said https://nucleusearn.cc
¡Saludos, aventureros del riesgo !
Casino sin registro sin correo requerido – http://casinossinlicenciaenespana.es/ casinos sin licencia espaГ±a
¡Que vivas triunfos extraordinarios !
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Детальнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма одинцово[/url]
¡Hola, buscadores de fortuna !
Casino online extranjero para usuarios sin documentos – https://casinoextranjerosespana.es/# casino online extranjero
¡Que disfrutes de asombrosas triunfos legendarios !
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Узнать больше – https://domnaberegu.ru/russia/%D0%B4%D0%BE%D0%B1%D1%80%D0%BE-%D0%BF%D0%BE%D0%B6%D0%B0%D0%BB%D0%BE%D0%B2%D0%B0%D1%82%D1%8C
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее тут – https://www.soldat.ru/forum/viewtopic.php?f=2&t=33372
Clicking Here https://noon.pics
Основные показания для вызова нарколога:
Детальнее – [url=https://narcolog-na-dom-v-irkutske00.ru/]narkolog na dom[/url]
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Выяснить больше – https://game.center.ru/news/1389.html
¡Hola, seguidores de la victoria !
Casinos sin licencia y con grandes jackpots – http://casinossinlicenciaespana.es/ casinossinlicenciaespana.es
¡Que experimentes premios asombrosos !
Городской портал Черкассы https://u-misti.cherkasy.ua новости, обзоры, события Черкасс и области
view it now https://tophat.lat
После прибытия врач проводит осмотр пациента, оценивает его состояние, измеряет давление, пульс, уровень кислорода и выявляет возможные противопоказания. Затем разрабатывается индивидуальный план лечения, направленный на стабилизацию состояния.
Детальнее – http://narcolog-na-dom-v-irkutske00.ru
Этот информативный текст выделяется своими захватывающими аспектами, которые делают сложные темы доступными и понятными. Мы стремимся предложить читателям глубину знаний вместе с разнообразием интересных фактов. Откройте новые горизонты и развивайте свои способности познавать мир!
Получить больше информации – https://game.center.ru/forum/faq.php
see here https://verio.buzz
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Ознакомиться с деталями – https://news.mangalayatan.in/2022/12/27/fresher-party-ryan-and-disha-mr-fresher-and-miss-fresher-respectively
Некоторые состояния требуют немедленного вмешательства специалиста. Если алкогольное отравление или запойное состояние не купируется вовремя, это может привести к тяжелым последствиям для здоровья.
Подробнее тут – https://narcolog-na-dom-v-irkutske00.ru/vrach-narkolog-na-dom-irkutsk
additional resources https://noon.gay
Основные показания для вызова нарколога:
Изучить вопрос глубже – [url=https://narcolog-na-dom-v-irkutske00.ru/]частный нарколог на дом в иркутске[/url]
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Подробнее можно узнать тут – https://zaynaonline.com/pgc_simply_gallery/shindy-agta
https://financephantom-ca.com/
Когда человек оказывается в сложной ситуации из-за длительного употребления алкоголя, важно получить быструю и квалифицированную медицинскую помощь. Запойные состояния, алкогольная интоксикация, тяжелый абстинентный синдром — все это требует своевременного вмешательства врача. Однако не всегда есть возможность или желание обращаться в стационар.
Получить больше информации – [url=https://narcolog-na-dom-v-irkutske00.ru/]вызов нарколога на дом цена иркутск[/url]
look at here https://astake.buzz/
Портал города Черновцы https://u-misti.chernivtsi.ua последние новости, события, обзоры
нарколог на дом цены нарколог на дом цены
После прибытия врач проводит осмотр пациента, оценивает его состояние, измеряет давление, пульс, уровень кислорода и выявляет возможные противопоказания. Затем разрабатывается индивидуальный план лечения, направленный на стабилизацию состояния.
Детальнее – http://narcolog-na-dom-v-irkutske00.ru/narkolog-na-dom-czena-irkutsk/
кодирование от алкоголя кодирование от алкоголя в нижнем
лечение алкогольной зависимости лечение алкоголизма
выведение из запоя на дому безопасный вывод из запоя цены
Запой — одно из самых опасных проявлений алкогольной зависимости. Он сопровождается глубокой интоксикацией организма, нарушением работы сердца, печени, головного мозга и других жизненно важных систем. Когда человек не может остановиться самостоятельно, а организм больше не справляется с нагрузкой, требуется медицинская помощь. В наркологической клинике «Спасение» в Мытищах мы проводим экстренные процедуры инфузионной терапии, позволяющие эффективно и безопасно вывести пациента из состояния запоя. Капельница — это первый шаг на пути к восстановлению здоровья и возвращению к нормальной жизни.
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva2.ru/]kapelnitsa ot zapoia tsena[/url]
Основные показания для вызова нарколога:
Изучить вопрос глубже – http://narcolog-na-dom-v-irkutske00.ru
Сомневаетесь в своих правах? Наша бесплатная консультация юристов по телефону поможет вам. Разъясним сложные моменты законодательства и подскажем, как действовать дальше: бесплатная юридическая консультация по телефону горячая линия
click reference https://agents-land.org
browse around here https://hyperunit.us/
Процедура капельного введения лекарств позволяет решить сразу несколько задач: восполнить жидкость, нормализовать работу внутренних органов, вывести токсины и восстановить общее состояние. Благодаря внутривенному способу введения, компоненты раствора быстро поступают в кровь и начинают действовать уже в течение первых 10–15 минут.
Узнать больше – [url=https://kapelnica-ot-zapoya-moskva2.ru/]капельница от запоя на дому мытищи[/url]
Как отмечает нарколог Олег Васильев, «чем раньше пациент получает квалифицированную медицинскую помощь, тем меньше риск серьезных осложнений».
Подробнее можно узнать тут – http://narcolog-na-dom-v-irkutske00.ru/narkolog-na-dom-czena-irkutsk/
После вызова врач клиники «ЗдравЦентр» прибывает к пациенту в течение 30–60 минут. Он проводит первичный осмотр, оценивает степень тяжести алкогольной интоксикации, измеряет пульс, давление, уровень кислорода и другие показатели здоровья. На основании этих данных составляется индивидуальный план лечения.
Детальнее – [url=https://kapelnica-ot-zapoya-moskva00.ru/]вызвать капельницу от запоя на дому[/url]
Мы оказываем услуги по изготовлению и продаже документов об окончании любых ВУЗов РФ. Документы изготавливаются на настоящих бланках государственного образца. [url=http://borovsk-tract.maxbb.ru/posting.php?mode=post&f=1/]borovsk-tract.maxbb.ru/posting.php?mode=post&f=1[/url]
дизайнерские кашпо для цветов напольные [url=https://dizaynerskie-kashpo1.ru]дизайнерские кашпо для цветов напольные[/url] .
купить пластиковые окна от производителя [url=http://www.okna177.ru]купить пластиковые окна от производителя[/url] .
Новинний сайт Житомира https://faine-misto.zt.ua новости Житомира сегодня
Доверяйте строительство профессионалам! ОАО “Что нам стоит” специализируется на проектировании и возведении зданий любой сложности. Подробности на [url=https://service.chtonamstoit.site/]нашем сайте[/url].
Праздничная продукция https://prazdnik-x.ru для любого повода: шары, гирлянды, декор, упаковка, сувениры. Всё для дня рождения, свадьбы, выпускного и корпоративов.
Москва оценочные компании оценка рыночной стоимости сооружений
После поступления вызова наш нарколог выезжает к пациенту в кратчайшие сроки, прибывая по адресу в пределах 30–60 минут. Специалист начинает процедуру с подробного осмотра и диагностики, измеряя ключевые показатели организма: артериальное давление, частоту пульса, насыщенность кислородом и собирая подробный анамнез.
Получить дополнительную информацию – [url=https://narcolog-na-dom-novosibirsk00.ru/]вызов нарколога на дом новосибирская область[/url]
помощь в лечении наркомании https://narco-info.ru
Всё для строительства https://d20.com.ua и ремонта: инструкции, обзоры, экспертизы, калькуляторы. Профессиональные советы, новинки рынка, база строительных компаний.
Врачи клиники «ЗдравЦентр» рекомендуют не откладывать вызов нарколога, чтобы избежать серьезных последствий, таких как судорожные припадки, инсульт или алкогольный психоз.
Детальнее – http://kapelnica-ot-zapoya-moskva00.ru
Основные показания для вызова нарколога:
Разобраться лучше – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом недорого иркутск[/url]
купить диплом [url=www.arus-diplom7.ru]купить диплом[/url] .
аттестат купить за 9 класс [url=https://arus-diplom2.ru]https://arus-diplom2.ru[/url] .
диплом о среднем образовании купить [url=http://arus-diplom8.ru]диплом о среднем образовании купить[/url] .
Проблемы с алкоголем или наркотиками могут застать врасплох и привести к серьезным последствиям для организма, психического состояния и жизни пациента. Самостоятельные попытки выйти из запоя или преодолеть абстинентный синдром без медицинской поддержки редко оказываются эффективными и могут представлять реальную опасность для здоровья. Именно в таких ситуациях клиника «АльфаНаркология» предлагает услугу вызова нарколога на дом в Санкт-Петербурге и Ленинградской области. Наши специалисты оперативно реагируют на обращение, оказывают квалифицированную помощь и обеспечивают полную конфиденциальность лечения.
Ознакомиться с деталями – [url=https://narcolog-na-dom-sankt-peterburg000.ru/]нарколог на дом в санкт-петербурге[/url]
После поступления вызова наш нарколог выезжает к пациенту в кратчайшие сроки, прибывая по адресу в пределах 30–60 минут. Специалист начинает процедуру с подробного осмотра и диагностики, измеряя ключевые показатели организма: артериальное давление, частоту пульса, насыщенность кислородом и собирая подробный анамнез.
Изучить вопрос глубже – [url=https://narcolog-na-dom-novosibirsk00.ru/]нарколог на дом анонимно новосибирск[/url]
Для снятия алкогольной интоксикации врач проводит детоксикационную терапию, которая включает внутривенные инфузии с растворами для выведения токсинов, поддерживающие препараты для печени, сердечно-сосудистой системы и нервной системы. В некоторых случаях назначаются седативные средства, нормализующие эмоциональное состояние пациента.
Углубиться в тему – http://narcolog-na-dom-v-irkutske00.ru/narkolog-na-dom-czena-irkutsk/https://narcolog-na-dom-v-irkutske00.ru
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Подробнее тут – https://narcolog-na-dom-novosibirsk00.ru/vyzov-narkologa-na-dom-novosibirsk
Запой — это тяжёлое состояние, характеризующееся длительным употреблением алкоголя, при котором человек не в силах самостоятельно прекратить пить. Алкогольная интоксикация при длительных запоях вызывает нарушения в работе всех органов и систем, приводя к серьёзным последствиям, таким как инфаркты, инсульты, психозы и даже летальный исход. В такой ситуации единственным надёжным решением становится обращение за профессиональной помощью.
Изучить вопрос глубже – https://vyvod-iz-zapoya-korolev2.ru/vyvod-iz-zapoya-na-domu
Строительный журнал https://garant-jitlo.com.ua всё о технологиях, материалах, архитектуре, ремонте и дизайне. Интервью с экспертами, кейсы, тренды рынка.
Онлайн-журнал https://inox.com.ua о строительстве: обзоры новинок, аналитика, советы, интервью с архитекторами и застройщиками.
Современный строительный https://interiordesign.kyiv.ua журнал: идеи, решения, технологии, тенденции. Всё о ремонте, стройке, дизайне и инженерных системах.
Информационный журнал https://newhouse.kyiv.ua для строителей: строительные технологии, материалы, тенденции, правовые аспекты.
Действие и назначение
Получить больше информации – https://vyvod-iz-zapoya-novosibirsk00.ru/vyvod-iz-zapoya-kruglosutochno-novosibirsk/
Мы понимаем, что в момент кризиса важна не только медицинская помощь, но и финансовая доступность. Поэтому в клинике «Спасение» в Мытищах действует несколько тарифов, позволяющих выбрать оптимальный вариант для любой ситуации. Стоимость зависит от состава препаратов, времени проведения и необходимости дополнительных манипуляций.
Узнать больше – http://
интересные цветочные горшки [url=http://www.dizaynerskie-kashpo.ru]http://www.dizaynerskie-kashpo.ru[/url] .
Когда человек оказывается в сложной ситуации из-за длительного употребления алкоголя, важно получить быструю и квалифицированную медицинскую помощь. Запойные состояния, алкогольная интоксикация, тяжелый абстинентный синдром — все это требует своевременного вмешательства врача. Однако не всегда есть возможность или желание обращаться в стационар.
Узнать больше – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом недорого в иркутске[/url]
Некоторые состояния требуют немедленного вмешательства специалиста. Если алкогольное отравление или запойное состояние не купируется вовремя, это может привести к тяжелым последствиям для здоровья.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом в иркутске[/url]
Пациенты выбирают нашу клинику для срочного вызова врача-нарколога благодаря следующим важным преимуществам:
Изучить вопрос глубже – http://narcolog-na-dom-novosibirsk00.ru/narkolog-na-dom-czena-novosibirsk/
заказать пластиковые окна недорого [url=okna177.ru]заказать пластиковые окна недорого[/url] .
Вызов нарколога на дом в Иркутске и Иркутской области — это удобное и безопасное решение, позволяющее получить неотложную помощь в привычной обстановке. Врачи клиники «ЧистоЖизнь» выезжают круглосуточно, приезжают в течение 30–60 минут и проводят комплексное лечение, направленное на стабилизацию состояния пациента и предотвращение осложнений.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом в иркутске[/url]
Запой — одно из самых опасных проявлений алкогольной зависимости. Он сопровождается глубокой интоксикацией организма, нарушением работы сердца, печени, головного мозга и других жизненно важных систем. Когда человек не может остановиться самостоятельно, а организм больше не справляется с нагрузкой, требуется медицинская помощь. В наркологической клинике «Спасение» в Мытищах мы проводим экстренные процедуры инфузионной терапии, позволяющие эффективно и безопасно вывести пациента из состояния запоя. Капельница — это первый шаг на пути к восстановлению здоровья и возвращению к нормальной жизни.
Выяснить больше – http://
Основной этап лечения — детоксикация. С помощью капельниц врач вводит препараты, которые быстро выводят токсины и нормализуют обменные процессы, снимают симптомы абстиненции и восстанавливают работу внутренних органов. Уже спустя 1–2 часа после начала процедуры пациент ощущает значительное улучшение.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-korolev2.ru/]vyvod iz zapoya[/url]
Возникли проблемы с законом? Не откладывайте решение. Квалифицированные юристы окажут бесплатную первичную консультацию. Проанализируем вашу ситуацию и предложим варианты действий – бесплатная консультация юриста горячая линия
Клиника предлагает индивидуальный подход к каждому пациенту. Лечение начинается с детальной диагностики состояния здоровья, что позволяет врачу подобрать наиболее эффективную схему терапии.
Выяснить больше – http://vyvod-iz-zapoya-korolev2.ru
Основные показания для вызова нарколога:
Углубиться в тему – [url=https://narcolog-na-dom-v-irkutske00.ru/]нарколог на дом в иркутске[/url]
В таких случаях своевременный вызов нарколога на дом позволяет быстро стабилизировать состояние больного и предотвратить тяжелые последствия.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-novosibirsk00.ru/]нарколог на дом круглосуточно[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Узнать больше – https://hoken.life-vision808.co.jp/top-baner-4
Breathe cleaner air with expert AC duct cleaning services across Dubai https://ac-cleaning-dubai.ae/
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
Выяснить больше – https://inelcohunter.co.uk/project/c01630h00611012/female-cable
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Исследовать вопрос подробнее – https://www.lanzaroteexperiencetours.com/blog/index.php/2019/02/14/the-best-beaches-in-lanzarote/?lang=en
https://financephantom-ca.com/
В этом информативном тексте представлены захватывающие события и факты, которые заставят вас задуматься. Мы обращаем внимание на важные моменты, которые часто остаются незамеченными, и предлагаем новые перспективы на привычные вещи. Подготовьтесь к тому, чтобы быть поглощенным увлекательными рассказами!
Разобраться лучше – http://batsumicare.com/downloads/malariareport
Строительный журнал https://poradnik.com.ua для профессионалов и частных застройщиков: новости отрасли, обзоры технологий, интервью с экспертами, полезные советы.
Всё о строительстве https://stroyportal.kyiv.ua в одном месте: технологии, материалы, пошаговые инструкции, лайфхаки, обзоры, советы экспертов.
Журнал о строительстве https://sovetik.in.ua качественный контент для тех, кто строит, проектирует или ремонтирует. Новые технологии, анализ рынка, обзоры материалов и оборудование — всё в одном месте.
¡Saludos, fanáticos del desafío !
Casino online extranjero con mГ©todos de pago seguros – п»їhttps://casinosextranjerosenespana.es/ casino online extranjero
¡Que vivas increíbles instantes inolvidables !
Полезный сайт https://vasha-opora.com.ua для тех, кто строит: от фундамента до крыши. Советы, инструкции, сравнение материалов, идеи для ремонта и дизайна.
We offer same-day AC duct cleaning in Dubai with guaranteed satisfaction: ac duct cleaning abu dhabi cost
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Углубиться в тему – http://canellecrea.ovh/project/prototyping-template
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Детальнее – https://springpaddocksequine.co.uk/buying-a-horse
Could we delve into the realm of quantum physics as part of our standard 10 curriculum, and if so, where can we find engaging online courses that demystify the subject for beginners?
Coming all the way from Germany to experience [url=http://sff.in.ua/]Sea Freedom Fest[/url] was an adventure I’ll never forget. From the moment I stepped onto the festival grounds, the energy was electric. Cosmic Gate on the main stage was the highlight of my trip, their set took the crowd to another level. The “Yin-Yang” stage also caught my attention with its unique design and artists like Sasha Stuff delivering powerful performances. Even though I don’t speak much Ukrainian, the [url=http://sff.in.ua/faq/]festival information[/url] made everything clear and easy to navigate. This festival is definitely worth crossing borders for!
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Подробнее тут – https://digvijayengineers.com/product/decoiler
Новости Полтава https://u-misti.poltava.ua городской портал, последние события Полтавы и области
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Детальнее – https://www.drogamleczna.org.pl/urbact-szansa-dla-ulicy-rwanskiej
Кулинарный портал https://vagon-restoran.kiev.ua с тысячами проверенных рецептов на каждый день и для особых случаев. Пошаговые инструкции, фото, видео, советы шефов.
Мужской журнал https://hand-spin.com.ua о стиле, спорте, отношениях, здоровье, технике и бизнесе. Актуальные статьи, советы экспертов, обзоры и мужской взгляд на важные темы.
Журнал для мужчин https://swiss-watches.com.ua которые ценят успех, свободу и стиль. Практичные советы, мотивация, интервью, спорт, отношения, технологии.
Читайте мужской https://zlochinec.kyiv.ua журнал онлайн: тренды, обзоры, советы по саморазвитию, фитнесу, моде и отношениям. Всё о том, как быть уверенным, успешным и сильным — каждый день.
Balanset-1A: Cutting-edge Portable Balancer & Vibration Analyzer
High-precision Dynamic Balancing Solution
Balanset-1A constitutes an revolutionary solution for rotor balancing of rotors in their own bearings, manufactured by Estonian company Vibromera OU. The device delivers professional equipment balancing at €1,751, which is 3-10 times more affordable than traditional vibration analyzers while preserving superior measurement accuracy. The system enables field balancing directly at the equipment’s installation site without requiring removal, which is essential for minimizing production downtime.
About the Manufacturer
Vibromera OU is an Estonian company concentrating in the creation and production of devices for technical diagnostics of industrial equipment. The company is registered in Estonia (registration number 14317077) and has branches in Portugal.
Contact Information:
Official website: https://vibromera.eu/shop/2/
Technical Specifications
Measurement Parameters
Balanset-1A provides precise measurements using a twin-channel vibration analysis system. The device measures RMS vibration velocity in the range of 0-80 mm/s with an accuracy of ±(0.1 + 0.1?Vi) mm/s. The operating frequency range is 5-550 Hz with potential extension to 1000 Hz. The system supports rotation frequency measurement from 250 to 90,000 RPM with phase angle determination accuracy of ±1 degree.
Working Principle
The device employs phase-sensitive vibration measurement technology with MEMS accelerometers ADXL335 and laser tachometry. Two single-axis accelerometers measure mechanical vibrations proportional to acceleration, while a laser tachometer generates impulse signals for computing RPM and phase angle. Digital signal processing includes FFT analysis for frequency analysis and specialized algorithms for automatic computation of balancing masses.
Full Kit Contents
The standard Balanset-1A delivery includes:
Measurement unit with USB interface – central module with built-in preamplifiers, integrators, and ADC
2 vibration sensors (accelerometers) with 4m cables (optionally 10m)
Optical sensor (laser tachometer) with 50-500mm measuring distance
Magnetic stand for sensor mounting
Electronic scales for accurate measurement of corrective masses
Software for Windows 7-11 (32/64-bit)
Plastic transport case
Complete set of cables and documentation
Operating Capabilities
Vibrometer Mode
Balanset-1A works as a complete vibration analyzer with abilities for measuring overall vibration level, FFT spectrum analysis up to 1000 Hz, measuring amplitude and phase of the fundamental frequency (1x), and continuous data recording. The system delivers display of time signals and spectral analysis for equipment condition diagnostics.
Balancing Mode
The device supports single-plane (static) and dual-plane (dynamic) balancing with automatic calculation of correction masses and their installation angles. The unique influence coefficient saving function enables substantial acceleration of subsequent balancing of similar equipment. A specialized grinding wheel balancing mode uses the three-correction-weight method.
Software
The easy-to-use program interface offers step-by-step guidance through the balancing process, making the device usable to personnel without special training. Key functions include:
Automatic tolerance calculation per ISO 1940
Polar diagrams for imbalance visualization
Result archiving with report generation capability
Metric and imperial system support
Multilingual interface (English, German, French, Polish, Russian)
Usage Domains and Equipment Types
Industrial Equipment
Balanset-1A is efficiently employed for balancing fans (centrifugal, axial), pumps (hydraulic, centrifugal), turbines (steam, gas), centrifuges, compressors, and electric motors. In production facilities, the device is used for balancing grinding wheels, machine spindles, and drive shafts.
Agricultural Machinery
The device represents particular value for agriculture, where uninterrupted operation during season is critically important. Balanset-1A is used for balancing combine threshing drums, shredders, mulchers, mowers, and augers. The possibility to balance on-site without equipment disassembly allows preventing costly downtime during critical harvest periods.
Specialized Equipment
The device is successfully used for balancing crushers of various types, turbochargers, drone propellers, and other high-speed equipment. The speed frequency range from 250 to 90,000 RPM covers essentially all types of industrial equipment.
Superiority Over Alternatives
Economic Value
At a price of €1,751, Balanset-1A delivers the functionality of devices costing €10,000-25,000. The investment pays for itself after preventing just 2-3 bearing failures. Cost reduction on third-party balancing specialist services reaches thousands of euros annually.
Ease of Use
Unlike sophisticated vibration analyzers requiring months of training, mastering Balanset-1A takes 3-4 hours. The step-by-step guide in the software allows professional balancing by personnel without specialized vibration diagnostics training.
Mobility and Autonomy
The complete kit weighs only 4 kg, with power supplied through the laptop’s USB port. This enables balancing in remote conditions, at distant sites, and in hard-to-reach locations without external power supply.
Versatile Application
One device is appropriate for balancing the broadest spectrum of equipment – from small electric motors to large industrial fans and turbines. Support for one and dual-plane balancing covers all typical tasks.
Real Application Results
Drone Propeller Balancing
A user achieved vibration reduction from 0.74 mm/s to 0.014 mm/s – a 50-fold improvement. This demonstrates the outstanding accuracy of the device even on small rotors.
Shopping Center Ventilation Systems
Engineers effectively balanced radial fans, achieving decreased energy consumption, abolished excessive noise, and prolonged equipment lifespan. Energy savings recovered the device cost within several months.
Agricultural Equipment
Farmers note that Balanset-1A has become an vital tool preventing costly breakdowns during peak season. Lower vibration of threshing drums led to reduced fuel consumption and bearing wear.
Pricing and Delivery Terms
Current Prices
Complete Balanset-1A Kit: €1,751
OEM Kit (without case, stand, and scales): €1,561
Special Offer: €50 discount for newsletter subscribers
Volume Discounts: up to 15% for orders of 4+ units
Ordering Options
Official Website: vibromera.eu (recommended)
eBay: verified sellers with 100% rating
Industrial Distributors: through B2B channels
Payment and Shipping Terms
Payment Methods: PayPal, credit cards, bank transfer
Shipping: 10-20 business days by international mail
Shipping Cost: from $10 (economy) to $95 (express)
Warranty: factory warranty
Technical Support: included in price
Conclusion
Balanset-1A represents an optimal solution for organizations striving to implement an effective equipment balancing system without significant capital expenditure. The device democratizes access to professional balancing, allowing small companies and service centers to offer services at the level of large industrial companies.
The combination of affordable price, ease of use, and professional features makes Balanset-1A an essential tool for modern technical maintenance. Investment in this device is an investment in equipment stability, lower operating costs, and improved competitiveness of your company.
диплом купить с занесением в реестр [url=http://www.arus-diplom6.ru]http://www.arus-diplom6.ru[/url] .
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом круглосуточно[/url]
ИнфоКиев https://infosite.kyiv.ua события, новости обзоры в Киеве и области.
Алкогольная и наркотическая зависимость требуют незамедлительного и комплексного вмешательства для предотвращения серьезных осложнений и сохранения здоровья пациента. В Уфе, Республика Башкортостан, опытные наркологи выезжают на дом 24 часа в сутки, предоставляя оперативную помощь при запоях и в случаях наркотической интоксикации. Такой формат лечения позволяет начать детоксикацию в комфортной, привычной обстановке, обеспечивая максимальную конфиденциальность и индивидуальный подход к каждому пациенту.
Исследовать вопрос подробнее – http://narcolog-na-dom-ufa000.ru/narkolog-na-dom-ufa-czeny/https://narcolog-na-dom-ufa000.ru
Процедура вывода из запоя начинается с тщательной диагностики состояния пациента, чтобы определить, какие методы лечения будут наиболее эффективными. Мы применяем индивидуальный подход и комбинируем медикаментозное лечение с психотерапевтической поддержкой, что даёт лучший результат.
Изучить вопрос глубже – [url=https://narcolog-na-dom-novokuznetsk0.ru/]вызов нарколога на дом новокузнецк.[/url]
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Подробнее тут – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
https://nextgenai-trading.com/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Получить дополнительную информацию – https://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-czena-novokuzneczk/
Мы строим и ремонтируем с любовью к деталям. Читайте [url=https://feedback.chtonamstoit.site/]мнения наших заказчиков[/url], которые уже оценили наш профессионализм.
Когда запой приводит к критическому ухудшению состояния, оперативное лечение становится жизненно необходимым. В Тюмени доступна услуга капельничного вывода из запоя на дому, которая позволяет начать детоксикацию организма незамедлительно и в комфортной для пациента обстановке. Такой формат терапии помогает не только вывести токсины, но и значительно снизить риск осложнений, сохраняя при этом полную конфиденциальность.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-tyumen0.ru/]капельница от запоя на дому в тюмени[/url]
Лечение зависимости требует не только физической детоксикации, но и работы с психоэмоциональным состоянием пациента. Психотерапевтическая поддержка помогает выявить глубинные причины зависимости, снизить уровень стресса и сформировать устойчивые навыки самоконтроля, что существенно снижает риск рецидивов.
Углубиться в тему – [url=https://narcolog-na-dom-ufa000.ru/]вызов нарколога на дом цена в уфе[/url]
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Узнать больше – http://kapelnica-ot-zapoya-tyumen00.ru/postavit-kapelniczu-ot-zapoya-tyumen/https://kapelnica-ot-zapoya-tyumen00.ru
Услуга “Нарколог на дом” в Уфе охватывает широкий спектр лечебных мероприятий, направленных как на устранение токсической нагрузки, так и на работу с психоэмоциональным состоянием пациента. Комплексная терапия включает в себя медикаментозную детоксикацию, корректировку обменных процессов, а также психотерапевтическую поддержку, что позволяет не только вывести пациента из состояния запоя, но и помочь ему справиться с наркотической зависимостью.
Подробнее – http://narcolog-na-dom-ufa000.ru/narkolog-na-dom-czena-ufa/
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Изучить вопрос глубже – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen
Запой сопровождается быстрым накоплением токсинов, что может привести к нарушению работы сердца, печени и почек. Использование капельничного метода позволяет оперативно ввести современные препараты для детоксикации, что способствует быстрому восстановлению обменных процессов и нормализации работы внутренних органов. Оперативное лечение на дому особенно актуально, когда каждая минута имеет значение для спасения здоровья.
Детальнее – http://kapelnica-ot-zapoya-tyumen0.ru/postavit-kapelniczu-ot-zapoya-tyumen/https://kapelnica-ot-zapoya-tyumen0.ru
What a stuff of un-ambiguity and preserveness of precious know-how concerning unexpected feelings.
Want excitement? You will find it on ck222 casino.
Первичный этап терапии направлен на оперативное выведение токсинов из организма. Врач-нарколог назначает индивидуальную схему медикаментозного вмешательства, что позволяет снизить уровень алкоголя в крови и восстановить обмен веществ.
Разобраться лучше – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя цена в волгограде[/url]
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Узнать больше – [url=https://narcolog-na-dom-novokuznetsk0.ru/]вызов нарколога на дом в новокузнецке[/url]
дизайнерское кашпо напольное [url=http://dizaynerskie-kashpo1.ru]дизайнерское кашпо напольное[/url] .
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Подробнее тут – http://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
Основной этап терапии — установка внутривенной капельницы. Через капельницу вводятся специально подобранные растворы, способствующие быстрому выведению токсинов, восстановлению водно-электролитного баланса и нормализации работы внутренних органов. При необходимости врач назначает дополнительные медикаменты для защиты печени, стабилизации сердечной деятельности и купирования симптомов абстинентного синдрома. В течение всей процедуры состояние пациента контролируется врачом, который корректирует схему лечения для достижения наилучших результатов. По завершении процедуры специалист дает подробные рекомендации по дальнейшему восстановлению и профилактике повторных запоев.
Узнать больше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/]капельница от запоя на дому нижний новгород.[/url]
Все новинки https://helikon.com.ua технологий в одном месте: гаджеты, AI, робототехника, электромобили, мобильные устройства, инновации в науке и IT.
Портал о ремонте https://as-el.com.ua и строительстве: от черновых работ до отделки. Статьи, обзоры, идеи, лайфхаки.
Ремонт без стресса https://odessajs.org.ua вместе с нами! Полезные статьи, лайфхаки, дизайн-проекты, калькуляторы и обзоры.
Сайт о строительстве https://selma.com.ua практические советы, современные технологии, пошаговые инструкции, выбор материалов и обзоры техники.
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Выяснить больше – http://vyvod-iz-zapoya-volgograd00.ru
Автоматизированные системы дозирования обеспечивают точное введение лекарственных средств, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненных показателей позволяет оперативно корректировать терапию в режиме реального времени, обеспечивая максимальную безопасность процедуры.
Детальнее – https://narcolog-na-dom-ufa000.ru/
Всё больше уважаю https://mfo-zaim.com/bez-proverok-na-kartu/ за то, что у них работает Виктория Данилова. Она не просто копирайтер — она образовательщик. Через её статьи реально прокачиваешься в теме личных финансов. Для России это очень нужно.
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Подробнее тут – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Детальнее – [url=https://narcolog-na-dom-novokuznetsk0.ru/]vyzov-narkologa-na-dom novokuznetsk[/url]
После первичной диагностики начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом, что позволяет быстро вывести токсины и восстановить нормальные обменные процессы. Этот этап критически важен для стабилизации работы печени, почек и сердечно-сосудистой системы.
Выяснить больше – https://kapelnica-ot-zapoya-tyumen0.ru/postavit-kapelniczu-ot-zapoya-tyumen
Алкогольная и наркотическая зависимость требуют незамедлительного и комплексного вмешательства для предотвращения серьезных осложнений и сохранения здоровья пациента. В Уфе, Республика Башкортостан, опытные наркологи выезжают на дом 24 часа в сутки, предоставляя оперативную помощь при запоях и в случаях наркотической интоксикации. Такой формат лечения позволяет начать детоксикацию в комфортной, привычной обстановке, обеспечивая максимальную конфиденциальность и индивидуальный подход к каждому пациенту.
Получить дополнительные сведения – [url=https://narcolog-na-dom-ufa000.ru/]платный нарколог на дом в уфе[/url]
Основной этап терапии — установка внутривенной капельницы. Через капельницу вводятся специально подобранные растворы, способствующие быстрому выведению токсинов, восстановлению водно-электролитного баланса и нормализации работы внутренних органов. При необходимости врач назначает дополнительные медикаменты для защиты печени, стабилизации сердечной деятельности и купирования симптомов абстинентного синдрома. В течение всей процедуры состояние пациента контролируется врачом, который корректирует схему лечения для достижения наилучших результатов. По завершении процедуры специалист дает подробные рекомендации по дальнейшему восстановлению и профилактике повторных запоев.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-nizhniy-novgorod00.ru/]капельница от запоя нижегородская область[/url]
Когда запой приводит к критическому ухудшению состояния, оперативное лечение становится жизненно необходимым. В Тюмени доступна услуга капельничного вывода из запоя на дому, которая позволяет начать детоксикацию организма незамедлительно и в комфортной для пациента обстановке. Такой формат терапии помогает не только вывести токсины, но и значительно снизить риск осложнений, сохраняя при этом полную конфиденциальность.
Получить дополнительную информацию – http://kapelnica-ot-zapoya-tyumen0.ru/
Выбор капельничного метода в условиях домашнего лечения обладает рядом преимуществ:
Получить дополнительные сведения – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-czena-tyumen
Выбор капельничного метода в условиях домашнего лечения обладает рядом преимуществ:
Подробнее – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]kapelnica ot zapoya[/url]
На https://mfo-zaim.com/zaym-30000-rubley/ много полезного контента, но особенно выделю статьи Виктории Даниловой. Очень хорошо написан материал про отписку от платных услуг — пригодился лично. И ещё статья про неуплату кредита в 2025 году — лучше, чем на юр.сайтах.
После первичной диагностики начинается активная фаза детоксикации. Современные препараты вводятся капельничным методом, что позволяет быстро вывести токсины и восстановить нормальные обменные процессы. Этот этап критически важен для стабилизации работы печени, почек и сердечно-сосудистой системы.
Подробнее тут – [url=https://kapelnica-ot-zapoya-tyumen0.ru/]капельница от запоя на дому тюмень[/url]
Когда следует немедленно обращаться за помощью:
Разобраться лучше – [url=https://narcolog-na-dom-novokuznetsk0.ru/]врач нарколог на дом[/url]
Во время длительного употребления алкоголя тело человека испытывает многоступенчатую интоксикацию. Сначала страдает печень — главный орган детоксикации. Постепенно нарушается фильтрация, и продукты распада этанола начинают циркулировать по крови, вызывая общее отравление. Далее страдает головной мозг: снижается уровень витамина B1, нарушается проводимость нервных импульсов, появляются спутанность сознания, агрессия, тревога, нарушения сна и координации.
Подробнее – https://kapelnica-ot-zapoya-moskva3.ru/
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Подробнее можно узнать тут – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]капельницы от запоятюмень[/url]
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Получить дополнительную информацию – [url=https://narcolog-na-dom-novokuznetsk0.ru/]нарколог на дом клиника новокузнецк[/url]
Экстренное вмешательство необходимо, когда самостоятельное прекращение употребления алкоголя или наркотиков становится невозможным, а состояние пациента ухудшается. Основные показания включают:
Выяснить больше – https://narcolog-na-dom-ufa000.ru
Can a Cash Flow Statement for a school be used to predict the success of an online course platform, considering it offers standard 10, CBSE courses for skill development and enhancement? If so, what specific aspects should be analyzed and why?
Prometey і Elena Benet зробили все, щоб створити святковий настрій, але організація фестивалю залишила бажати кращого. Черги на вході були нескінченними, навіть із [url=http://sff.in.ua/tickets/]заздалегідь придбаними квитками[/url]. Сцена «Інь-Янь» виглядала чудово, але якість звуку, особливо під час виступів Sonya Soundbreeze і Natali Benet, була дуже посередньою. На фудкортах не вистачало їжі, а зони відпочинку були переповнені. Це не те, чого я очікував від такого відомого фестивалю.
Алкогольная и наркотическая зависимость требуют незамедлительного и комплексного вмешательства для предотвращения серьезных осложнений и сохранения здоровья пациента. В Уфе, Республика Башкортостан, опытные наркологи выезжают на дом 24 часа в сутки, предоставляя оперативную помощь при запоях и в случаях наркотической интоксикации. Такой формат лечения позволяет начать детоксикацию в комфортной, привычной обстановке, обеспечивая максимальную конфиденциальность и индивидуальный подход к каждому пациенту.
Разобраться лучше – [url=https://narcolog-na-dom-ufa000.ru/]вызов нарколога на дом уфа[/url]
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Выяснить больше – https://narcolog-na-dom-novokuznetsk0.ru/narkolog-na-dom-czena-novokuzneczk/
Обращался на https://mfo-zaim.com/zaim-bez-procentov-na-kartu/ , уже опустились руки — везде отказы. Связался с Виктором Гардиеновым, Руководителем отдела клиентского обслуживания. Всё объяснил спокойно, без лишних слов. Через неделю после его рекомендаций — первый одобренный займ. Работает.
Когда запой приводит к критическому ухудшению состояния, оперативное лечение становится жизненно необходимым. В Тюмени доступна услуга капельничного вывода из запоя на дому, которая позволяет начать детоксикацию организма незамедлительно и в комфортной для пациента обстановке. Такой формат терапии помогает не только вывести токсины, но и значительно снизить риск осложнений, сохраняя при этом полную конфиденциальность.
Подробнее тут – https://kapelnica-ot-zapoya-tyumen0.ru/postavit-kapelniczu-ot-zapoya-tyumen/
Автоматизированные системы дозирования обеспечивают точное введение лекарственных средств, что минимизирует риск передозировки и побочных эффектов. Постоянный мониторинг жизненных показателей позволяет оперативно корректировать терапию в режиме реального времени, обеспечивая максимальную безопасность процедуры.
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-ufa000.ru/]нарколог на дом стоимость уфа[/url]
Одновременно с медикаментозной детоксикацией начинается работа по снижению эмоционального напряжения. Психотерапевтическая помощь помогает пациенту осознать причины зависимости и выработать стратегии для предотвращения рецидивов, что является важным аспектом успешного лечения.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя на дому цена в волгограде[/url]
Советую почитать блог Виктории Даниловой на https://mfo-zaim.com/zaim-pod-zalog-avto/ . Особенно если вы хотите разобраться в кредитах, но не любите «юридическую жесть». Пишет просто, понятно и с пользой. А главное — видно, что это про реальные нужды граждан России.
Выбор капельничного метода в условиях домашнего лечения обладает рядом преимуществ:
Разобраться лучше – http://kapelnica-ot-zapoya-tyumen00.ru/
Процесс вывода из запоя капельничным методом организован по строгой схеме, позволяющей обеспечить максимальную эффективность терапии. Каждая стадия направлена на комплексное восстановление организма и минимизацию риска осложнений.
Получить дополнительные сведения – https://kapelnica-ot-zapoya-tyumen0.ru/postavit-kapelniczu-ot-zapoya-tyumen/
Также страдают сердце и сосуды. У пациентов часто наблюдаются тахикардия, нестабильное давление, аритмии, повышенный риск инфаркта или инсульта. Система пищеварения реагирует воспалением: гастрит, панкреатит, тошнота, рвота. Все эти изменения усиливаются на фоне обезвоживания и электролитного дисбаланса. Именно поэтому стандартное «отлежаться» или домашнее лечение чаще всего оказывается неэффективным и даже опасным. Необходима полноценная капельная терапия — с грамотно подобранными препаратами и медицинским наблюдением.
Детальнее – http://kapelnica-ot-zapoya-moskva3.ru/kapelnica-ot-zapoya-cena-v-himkah/
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]капельницы от запоя в тюмени[/url]
LIMITED-TIME DEAL: ChatGPT PLUS/PRO at the LOWEST PRICE online!
GRAB YOUR SUBSCRIPTION NOW: ❣️ [url=https://bit.ly/UNLOCK-ChatGPT-PRO]ChatGPT PLUS/PRO[/url] ❣️
✅ WHY CHOOSE US?
✔ Instant activation – No waiting!
✔ Official subscription – No risk of bans!
✔ Cheaper than OpenAI’s website!
✔ Thousands of happy customers & 5-star reviews!
✔ 24/7 support – We’re here to help!
✅ HOW TO ORDER? (FAST & EASY!)
1️⃣ Click the link & select your plan.
2️⃣ Pay securely (Crypto, PayPal, Cards, etc.).
3️⃣ Receive your login OR unique activation code instantly!
4️⃣ Enjoy ChatGPT PLUS/PRO in minutes!
✅ WHAT’S INCLUDED?
⭐ GPT-4o (Fastest & Smartest AI!)
⭐ GPT-4 Turbo (Longer, detailed answers!)
⭐ Advanced AI features (Code Interpreter, Plugins, File Uploads!)
⭐ Priority access – No more downtime!
⚠ DON’T PAY FULL PRICE! Get ChatGPT PRO cheaper HERE:
❣️ [url=https://bit.ly/UNLOCK-ChatGPT-PRO]ChatGPT PLUS/PRO[/url] ❣️
⏳ DEAL ENDS SOON! Prices are rising—CLAIM YOUR SPOT NOW!
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Исследовать вопрос подробнее – http://kapelnica-ot-zapoya-tyumen00.ru
Также страдают сердце и сосуды. У пациентов часто наблюдаются тахикардия, нестабильное давление, аритмии, повышенный риск инфаркта или инсульта. Система пищеварения реагирует воспалением: гастрит, панкреатит, тошнота, рвота. Все эти изменения усиливаются на фоне обезвоживания и электролитного дисбаланса. Именно поэтому стандартное «отлежаться» или домашнее лечение чаще всего оказывается неэффективным и даже опасным. Необходима полноценная капельная терапия — с грамотно подобранными препаратами и медицинским наблюдением.
Исследовать вопрос подробнее – https://kapelnica-ot-zapoya-moskva3.ru/kapelnicy-ot-zapoya-na-domu-v-himkah
Запой – это состояние, при котором контроль над употреблением алкоголя утрачивается, а токсическая нагрузка на организм резко возрастает. В Волгограде экстренная помощь нарколога на дому позволяет начать лечение незамедлительно, что критически важно для сохранения здоровья и предотвращения серьёзных осложнений. Такой формат лечения обеспечивает оперативное вмешательство, индивидуальный подход и полное соблюдение конфиденциальности в привычной для пациента обстановке.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-volgograd00.ru/]вывод из запоя капельница волгоград[/url]
Городской портал Винницы https://u-misti.vinnica.ua новости, события и обзоры Винницы и области
Запой может быть не только физически тяжёлым, но и психологически разрушительным. Поэтому важно вовремя обратиться за помощью. Вывод из запоя в Нижнем Новгороде — это необходимая медицинская процедура, которая помогает победить алкогольную зависимость и восстановить здоровье. Мы в клинике «АнтиЗависимость» предлагаем круглосуточную помощь в комфортных условиях — на дому или в стационаре.
Ознакомиться с деталями – [url=https://narcolog-na-dom-novokuznetsk0.ru/]врач нарколог на дом кемеровская область[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Углубиться в тему – https://psquaredmath.com/2020/04/29/books-to-buy-on-a-20-budget
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Углубиться в тему – https://cienciaytecnology.com/wordpress/docker
What unconventional online courses, beyond the usual suspects of math, science, and language, would be beneficial for CBSE students in Standard 10 to gain a competitive edge and foster a lifelong passion for learning?
Venir de France pour decouvrir ce festival en Ukraine a ete une experience exceptionnelle. La scene principale etait incroyable, avec des performances inoubliables de Cosmic Gate et Miss Monique. L’atmosphere etait electrisante, et la foule vibrait au rythme de la musique. J’ai egalement ete impressionne par la scene « Yin-Yang », ou des artistes comme Sasha Stuff et Prometey ont offert des sets captivants. Tout etait bien organise, des [url=http://sff.in.ua/tickets/]billets faciles a obtenir[/url] aux espaces detente bien amenages. Ce voyage en valait vraiment la peine, et je suis deja impatient de revenir l’annee prochaine !
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить больше информации – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Разобраться лучше – https://syunnka.co.jp/sample-post2
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый смог разобраться в предмете и извлечь из него максимум пользы.
Подробнее можно узнать тут – https://showerdoors.com/get-a-spouse-internet
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Получить больше информации – https://www.kickstartrecovery.org/2023/08/21/embracing-the-wonders-of-the-natural-world
Эта статья сочетает в себе как полезные, так и интересные сведения, которые обогатят ваше понимание насущных тем. Мы предлагаем практические советы и рекомендации, которые легко внедрить в повседневную жизнь. Узнайте, как улучшить свои навыки и обогатить свой опыт с помощью простых, но эффективных решений.
Выяснить больше – https://iec.org.ls/download/press-release-meta-facebook-workshop-on-use-of-social-media-2
Портал Львів https://u-misti.lviv.ua останні новини Львова и области.
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Разобраться лучше – https://decisoesinteligentes.com/como-funciona-um-consorcio-atualizado-2023
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Детальнее – https://sahibeducations.com/diwali-celebration
Свежие новости https://ktm.org.ua Украины и мира: политика, экономика, происшествия, культура, спорт. Оперативно, объективно, без фейков.
Сайт о строительстве https://solution-ltd.com.ua и дизайне: как построить, отремонтировать и оформить дом со вкусом.
Читайте авто блог https://autoblog.kyiv.ua обзоры автомобилей, сравнения моделей, советы по выбору и эксплуатации, новости автопрома.
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Получить дополнительную информацию – https://raleighgold.com/be-prepared-for-major-correction-in-gold-price-in-the-coming-months-says-analyst
Авто портал https://real-voice.info для всех, кто за рулём: свежие автоновости, обзоры моделей, тест-драйвы, советы по выбору, страхованию и ремонту.
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4190 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://spbrcom1.ru/]Купить диплом о среднем образовании[/url] — ответим быстро, без лишних формальностей.
Оформиление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3515 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://spbrcom2.ru/]По ссылке[/url] — ответим быстро, без лишних формальностей.
Лицензия – гарантия надежности. Мы выбирали только проверенных подрядчиков с [url=http://certificates.chtonamstoit.site/]официальной лицензией на строительство[/url].
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2374 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://inforepetitor1.ru/]Доступ по ссылке[/url] — ответим быстро, без лишних формальностей.
какие банки не отказывают в кредите [url=kredit-bez-otkaza-1.ru]какие банки не отказывают в кредите[/url] .
Киберспортивные события: На прошлых выходных прошло крупное киберспортивное событие по [url=https://arkadia30.ru/]игровой новинки[/url] “Dota 2”, где игроки из Европы одержала победу, обыграв конкурентов с минимальным отрывом.
Новая версия ОС: Презентация новой версии [url=https://softisntall.ru/]операционной системы[/url] от Microsoft, которая включает улучшения в области безопасности и производительности. Пользователи говорят о более стабильной работе приложений и новых функциях для разработчиков.
Рост цен на [url=https://statrk.ru/]жилье[/url]: Согласно последним отчётам, цены на жилье продолжают расти в крупных городах, что делает его менее доступным для молодых профессионалов. Эксперты предсказывают дальнейший рост цен в ближайшие месяцы.
Новини Львів https://faine-misto.lviv.ua последние новости и события – Файне Львов
Строительный портал https://apis-togo.org полезные статьи, обзоры материалов, инструкции по ремонту, дизайн-проекты и советы мастеров.
Комплексный строительный https://ko-online.com.ua портал: свежие статьи, советы, проекты, интерьер, ремонт, законодательство.
Всё о строительстве https://furbero.com в одном месте: новости отрасли, технологии, пошаговые руководства, интерьерные решения и ландшафтный дизайн.
Бренд UP-X вызывает интерес благодаря стабильной работе с игроками. На сайте up x регистрация размещены аналитические материалы по ключевым аспектам платформы: варианты пополнения, а также особенности пользовательского соглашения.
Новые пользователи могут рассчитывать бонусные программы, и прозрачный механизм кэш-аута. UP-X поддерживает работу с криптовалютой, что расширяет её аудиторию. Регулярное обновление контента на сайте помогает оценивать риски и принимать обоснованные решения по платформе.
В этой публикации мы предложим ряд рекомендаций по избавлению от зависимостей и успешному восстановлению. Мы обсудим методы привлечения поддержки и важность самосознания. Эти советы помогут людям вернуться к нормальной жизни и стать на путь выздоровления.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-krasnodar15.ru/]нарколог на дом недорого[/url]
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4696 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://spbrcom2.ru/]На этой странице[/url] — ответим быстро, без лишних формальностей.
Мы предлагаем оформление дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1589 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://inforepetitor1.ru/]Купить диплом вуза[/url] — ответим быстро, без лишних формальностей.
Советую https://earthsanatan.com/the-ultimate-guide-to-times-square-in-new-york/
креативные горшки для цветов [url=https://www.dizaynerskie-kashpo1.ru]креативные горшки для цветов[/url] .
Онлайн-портал https://leif.com.ua для женщин: мода, психология, рецепты, карьера, дети и любовь. Читай, вдохновляйся, общайся, развивайся!
Современный женский https://prowoman.kyiv.ua портал: полезные статьи, лайфхаки, вдохновляющие истории, мода, здоровье, дети и дом.
Портал о маркетинге https://reklamspilka.org.ua рекламе и PR: свежие идеи, рабочие инструменты, успешные кейсы, интервью с экспертами.
Slotbom77
События Днепр https://u-misti.dp.ua последние новости Днепра и области, обзоры и самое интересное
[url=https://gaming-casino-apk.ru]gaming-casino-apk.ru[/url]
Привет, гемблеры! ??
Заглянул на один сайт и нашёл интересную статью. По ссылке собрана инфа о том, какие слоты будут популярны в онлайн-казино gaming в 2025 году.
Думаю, будет полезно почитать тем, кто интересуется трендами в мире азартных игр. Возможно, там есть инфа про новые механики, графику и темы, которые будут рулить в будущем.gaming-casino-apk.ru
подъемник для бетона [url=https://podem-24.ru/prodazha-podemnikov/]https://podem-24.ru/prodazha-podemnikov/[/url] .
Транзакции без банков? Тогда стоит взглянуть глубже; делай шаг, upx, и убедись, что Polygon экономит комиссии. На борту UPX — Ledger-подписи, а вывод летит по смарт-контракту.
Джекпот прилетит сразу на кошелёк. Данные шифруются TLS 1.3. если курс волатилен, — это место, где крипта и азарт сходятся на одной линии выплат.
Сразу после вызова нарколог приезжает для проведения детального осмотра. На этом этапе производится сбор анамнеза, измеряются жизненно важные показатели – пульс, артериальное давление, температура – и оценивается степень интоксикации.
Углубиться в тему – [url=https://vyvod-iz-zapoya-vladimir0.ru/]нарколог вывод из запоя владимир[/url]
В данной статье рассматриваются проблемы общественного здоровья и социальные факторы, влияющие на него. Мы акцентируем внимание на значении профилактики и осведомленности в защите здоровья на уровне общества. Читатели смогут узнать о новых инициативах и программах, направленных на улучшение здоровья населения.
Подробнее тут – [url=https://narkolog-na-dom-krasnodar15.ru/]vrach-narkolog-na-dom[/url]
Семейный портал https://stepandstep.com.ua статьи для родителей, игры и развивающие материалы для детей, советы психологов, лайфхаки.
Клуб родителей https://entertainment.com.ua пространство поддержки, общения и обмена опытом.
Туристический портал https://aliana.com.ua с лучшими маршрутами, подборками стран, бюджетными решениями, гидами и советами.
Всё о спорте https://beachsoccer.com.ua в одном месте: профессиональный и любительский спорт, фитнес, здоровье, техника упражнений и спортивное питание.
https://immediateassets-fr.com/
Этот медицинский обзор сосредоточен на последних достижениях, которые оказывают влияние на пациентов и медицинскую практику. Мы разбираем инновационные методы лечения и исследований, акцентируя внимание на их значимости для общественного здоровья. Читатели узнают о свежих данных и их возможном применении.
Разобраться лучше – [url=https://narkolog-na-dom-krasnodar15.ru/]narkolog-na-dom-czena[/url]
Специалист выясняет, как долго продолжается запой, какие симптомы наблюдаются, а также наличие сопутствующих заболеваний. Эти данные позволяют сформировать индивидуальный план лечения и выбрать оптимальные методы детоксикации.
Получить дополнительные сведения – http://vyvod-iz-zapoya-vladimir0.ru/vyvod-iz-zapoya-anonimno-vladimir/
Комплексное лечение на дому организовано по четкой схеме, состоящей из последовательных этапов. Каждый из них направлен на быстрое восстановление нормального функционирования организма.
Разобраться лучше – https://vyvod-iz-zapoya-vladimir0.ru/srochnyj-vyvod-iz-zapoya-vladimir
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Изучить вопрос глубже – [url=https://narkolog-na-dom-krasnodar11.ru/]вызов врача нарколога на дом[/url]
[url=https://flagman-casino-apk.ru]flagman-casino-apk.ru[/url]
Приветствую, форумчане!
Хочу поделиться интересной находкой для тех, кто ищет способы окунуться в мир азарта. По ссылке вы найдете информацию о том, как скачать приложение flagman казино.
В статье, вероятно, обсуждаются различные аспекты загрузки приложения, особенности игры, а также, возможно, бонусы и акции для новых пользователей.
flagman-casino-apk.ru
Длительный запой может привести к серьезным осложнениям, таким как повреждение печени, почек, сердечно-сосудистые нарушения и нервные расстройства. Чем быстрее начинается вывод из запоя, тем ниже риск развития хронических заболеваний. Срочный вызов нарколога на дом позволяет в первые часы кризиса начать детоксикацию, что существенно повышает шансы на полное восстановление организма. В условиях экстренной ситуации каждая минута имеет решающее значение, и своевременная помощь становится ключом к сохранению здоровья и жизни.
Углубиться в тему – http://vyvod-iz-zapoya-tula00.ru/vyvod-iz-zapoya-na-domu-tula/https://vyvod-iz-zapoya-tula00.ru
[url=https://champion-casino-apk.ru]champion-casino-apk.ru[/url]
Скачайте champion casino для телефона на андройд по ссылке ниже:
champion-casino-apk.ru
Запой характеризуется накоплением токсинов и ухудшением работы внутренних органов. Чем дольше продолжается состояние интоксикации, тем выше риск серьезных осложнений. Помощь нарколога на дому позволяет начать детоксикацию в первые часы кризиса, что существенно повышает шансы на успешное восстановление и предотвращает развитие хронических заболеваний.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-vladimir0.ru/]вывод из запоя цена владимир[/url]
На данном этапе специалист уточняет, как долго продолжается запой, какой вид алкоголя употребляется и имеются ли сопутствующие заболевания. Тщательный анализ информации позволяет оперативно определить степень интоксикации и выбрать оптимальные методы терапии для быстрого и безопасного вывода из запоя.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-tula00.ru/]вывод из запоя на дому в туле[/url]
Системы автоматизированного дозирования обеспечивают точное введение медикаментов, что минимизирует риск побочных эффектов. Постоянный мониторинг жизненно важных показателей позволяет врачу корректировать терапию в режиме реального времени, гарантируя безопасность процедуры.
Детальнее – [url=https://vyvod-iz-zapoya-vladimir0.ru/]вывод из запоя круглосуточно владимир[/url]
Рекомендую https://feldteam.com/2022/10/13/hello-world-2/
¡Saludos, amantes de la diversión !
casinos online extranjeros accesibles desde EspaГ±a – п»їhttps://casinosextranjero.es/ casinos extranjeros
¡Que vivas increíbles jackpots extraordinarios!
¡Saludos, entusiastas del ocio !
ReseГ±as reales sobre casinos online extranjeros 2025 – п»їhttps://casinoextranjerosenespana.es/ casino online extranjero
¡Que disfrutes de tiradas afortunadas !
[url=https://cams-casino-apk.ru]cams-casino-apk.ru[/url]
Приветствую всех!
Наткнулся на интересную статью для любителей мобильного гемблинга. По ссылке можно узнать подробности о том, как скачать казино cams на телефон.
В материале, похоже, рассматриваются разные платформы (Android, iOS?), способы установки, а также вопросы безопасности и выбора надежного казино.
cams-casino-apk.ru
מכשיר אידוי קנאביס
עטי אידוי – פתרון חדשני, נוח ובריא למשתמש המודרני.
בעולם המודרני, שבו קצב חיים מהיר ושגרת יומיום שולטים את היום-יום, עטי אידוי הפכו לאופציה אידיאלית עבור אלה המחפשים חווית אידוי מקצועית, נוחה ובריאה.
בנוסף לטכנולוגיה החדשנית שמובנית בהמוצרים האלה, הם מציעים מספר רב של יתרונות משמעותיים שהופכים אותם לאופציה עדיפה על פני שיטות קונבנציונליות.
עיצוב קומפקטי ונוח לנשיאה
אחד ההיתרונות העיקריים של עטי אידוי הוא היותם קומפקטיים, קלילים וקלים להעברה. המשתמש יכול לשאת את העט האידוי לכל מקום – לעבודה, לנסיעה או לאירועים – מבלי שהמכשיר יהווה מטרד או יהיה מסורבל.
העיצוב הקומפקטי מאפשר לאחסן אותו בתיק בקלות, מה שמאפשר שימוש לא בולט ונוח יותר.
התאמה לכל הסביבות
עטי האידוי מצטיינים ביכולתם להתאים לשימוש בסביבות מגוונות. בין אם אתם במשרד או במפגש, ניתן להשתמש בהם בצורה שקטה וללא הפרעה.
אין עשן מציק או ריח חד שעלול להטריד – רק אידוי עדין וקל שנותן גמישות גם באזור הומה.
ויסות מיטבי בחום האידוי
למכשירי האידוי רבים, אחד המאפיינים החשובים הוא היכולת לשלוט את טמפרטורת האידוי באופן מדויק.
תכונה זו מאפשרת להתאים את השימוש להמוצר – פרחים, שמנים או תרכיזים – ולהעדפות האישיות.
ויסות החום מספקת חוויית אידוי חלקה, איכותית ומקצועית, תוך שמירה על ההארומות המקוריים.
אידוי נקי וטוב יותר
בהשוואה לצריכה בשריפה, אידוי באמצעות עט אידוי אינו כולל שריפה של המוצר, דבר שמוביל למינימום של חומרים מזהמים שנפלטים במהלך השימוש.
נתונים מראים על כך שאידוי הוא אופציה בריאה, עם פחות חשיפה לרעלנים.
יתרה מכך, בשל חוסר בעירה, הטעמים הטבעיים מוגנים, מה שמוסיף לחווית הטעם והסיפוק הצריכה.
קלות שימוש ואחזקה
מכשירי הוופ מיוצרים מתוך עיקרון של קלות שימוש – הם מיועדים הן למתחילים והן למשתמשים מנוסים.
רוב המכשירים פועלים בהפעלה פשוטה, והעיצוב כולל החלפה של רכיבים (כמו מיכלים או קפסולות) שמקלים על הניקיון והאחזקה.
הדבר הזה מגדילה את חיי המכשיר ומבטיחה תפקוד אופטימלי לאורך זמן.
סוגים שונים של מכשירי וופ – מותאם לצרכים
הבחירה רחבה בוופ פנים מאפשר לכל משתמש לבחור את המוצר האידיאלי עבורו:
עטי אידוי לפרחים
מי שמעוניין ב חווית אידוי אותנטית, רחוקה ממעבדות – ייעדיף מכשיר לפרחי קנאביס.
המכשירים הללו מתוכננים לעיבוד בחומר גלם טבעי, תוך שימור מקסימלי על הריח והטעימות הטבעיים של הצמח.
עטי אידוי לשמנים ותמציות
לצרכנים שמחפשים אידוי מרוכז ומלא בחומרים פעילים כמו THC וCBD – קיימים מכשירים המיועדים במיוחד לשמנים ותרכיזים.
המוצרים האלה מתוכננים לשימוש בנוזלים מרוכזים, תוך יישום בטכנולוגיות מתקדמות כדי ללספק אידוי אחיד, נעים ומלא בטעם.
—
סיכום
מכשירי וופ אינם רק עוד כלי לצריכה בקנאביס – הם סמל לרמת חיים גבוהה, לחופש ולהתאמה לצרכים.
בין ההיתרונות העיקריים שלהם:
– גודל קומפקטי ונעים לנשיאה
– ויסות חכם בחום האידוי
– צריכה בריאה ובריאה
– קלות שימוש
– מגוון רחב של התאמה אישית
בין אם זו הההתנסות הראשונה בוופינג ובין אם אתם צרכן ותיק – וופ פן הוא ההמשך הלוגי לצריכה מתקדמת, נעימה ובטוחה.
—
הערות:
– השתמשתי בספינים כדי ליצור וריאציות טקסטואליות מגוונות.
– כל האפשרויות נשמעות טבעיות ומתאימות לשפה העברית.
– שמרתי על כל המושגים ספציפיים (כמו Vape Pen, THC, CBD) ללא שינוי.
– הוספתי כותרות כדי לשפר את ההבנה והארגון של הטקסט.
הטקסט מתאים לקהל היעד בישראל ומשלב שפה שיווקית עם מידע מקצועי.
[url=https://lev-casino-apk.ru]lev-casino-apk.ru[/url]
Скачайте бесплатно lev casino на андройд по ссылке ниже: lev-casino-apk.ru
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Выяснить больше – https://www.kormentdot.com/il-salto-di-mister-okay
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Узнать больше – https://fisioaktiv.com/mechanism-behind-precise-spinal-cord-development-3
Новости Украины https://useti.org.ua в реальном времени. Всё важное — от официальных заявлений до мнений экспертов.
Информационный портал https://comart.com.ua о строительстве и ремонте: полезные советы, технологии, идеи, лайфхаки, расчёты и выбор материалов.
Архитектурный портал https://skol.if.ua современные проекты, урбанистика, дизайн, планировка, интервью с архитекторами и тренды отрасли.
Всё о строительстве https://ukrainianpages.com.ua просто и по делу. Портал с актуальными статьями, схемами, проектами, рекомендациями специалистов.
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Получить больше информации – https://www.floraimmobiliare.it/wp/property/303-box-auto-via-toniolo-martina-franca
Предлагаем вашему вниманию интересную справочную статью, в которой собраны ключевые моменты и нюансы по актуальным вопросам. Эта информация будет полезна как для профессионалов, так и для тех, кто только начинает изучать тему. Узнайте ответы на важные вопросы и расширьте свои знания!
Исследовать вопрос подробнее – https://www.miyazawa-lane.net/?p=66
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Детальнее – https://senatorleach.com/sb350
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Получить дополнительные сведения – https://perfectindiaplanner.in/hello-world
Нужен монтаж отопления в Алматы? Профессиональные специалисты быстро и качественно установят систему отопления в доме, квартире или офисе. Работаем с любыми типами оборудования, даём гарантию и обеспечиваем выезд в течение часа. Доступные цены и индивидуальный подход к каждому клиенту: https://montazh-otopleniya.kz/
Новости Украины https://hansaray.org.ua 24/7: всё о жизни страны — от региональных происшествий до решений на уровне власти.
Всё об автомобилях https://autoclub.kyiv.ua в одном месте. Обзоры, новости, инструкции по уходу, автоистории и реальные тесты.
Строительный журнал https://dsmu.com.ua идеи, технологии, материалы, дизайн, проекты, советы и обзоры. Всё о строительстве, ремонте и интерьере
Новостной портал Одесса https://u-misti.odesa.ua последние события города и области. Обзоры и много интресного о жизни в Одессе.
Портал о строительстве https://tozak.org.ua от идеи до готового дома. Проекты, сметы, выбор материалов, ошибки и их решения.
Уточнить детали, или сделать заказ:
Бережная доставка.
Арт. Артикул 67-5007.
Доп. скидка 6% по промокоду ШЕСТЬ -6% по промокоду.
Арт. 700066.
Конструкцию стола отличает повышенная устойчивость, плавное регулирование уровня подъема и достаточная мобильность.
Клинический опыт показывает: чем раньше начато лечение, тем выше шансы на устойчивую ремиссию. Промедление может привести к тяжёлым осложнениям — физическим, психическим и социальным.
Узнать больше – [url=https://narkologicheskaya-klinika-voronezh9.ru/]наркологическая клиника нарколог воронеж[/url]
Мы искали надежного подрядчика и убедились, что компания полностью сертифицирована. Это подтверждает [url=http://certificates.chtonamstoit.site/]сертификат ISO 9001[/url].
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3837 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://spbrcom1.ru/]Звоните[/url] — ответим быстро, без лишних формальностей.
Тысячи игроков предпочитают Zooma Казино, ради азарта. Клуб предлагает лучшим автоматам. Среди предложений гарантированно найдёшь игру по вкусу. В одном из раундов зума казино зеркало предоставит шанс на крупной выплате. Сервис Zooma развивается, обновляя интерфейс.
Функциональность Zooma Casino удобна, что важно для новичков. Открытие счёта предельно проста. После входа, можно использовать фриспины. Zooma Казино рады новым игрокам.
Прозрачность финансовых операций контролируется системой. Вывод и пополнение выполняются через безопасные шлюзы. Платформа может использоваться для перехода к привлекательным играм. Зума Казино обеспечивает конфиденциальность. Потому создаётся комфортная среда.
Множество посетителей ежедневно заходят на игровой сайт Zooma, чтобы получить дозу адреналина. Игровой сервис предоставляет современным слотам. Среди развлечений возможно найти захватывающий сюжет. В одном из раундов zooma зеркало открывает доступ к джекпоту. Казино Zooma расширяет функциональность, внедряя инновации.
Дизайн сайта удобна, что важно для новичков. Регистрация проходит быстро. Как только вы активируете аккаунт, можно активировать бонусы. Игровая площадка Zooma предлагает стартовые привилегии.
Честность игрового процесса гарантируется правилами. Платёжные операции обрабатываются по зашифрованным протоколам. Платформа может использоваться для перехода к акционным предложениям. Игровой сайт Zooma сохраняет персональные данные. Потому создаётся комфортная среда.
Арена удачи манит стратегов, готовых бросить вызов фортуне. Каждый слот становится ареной великого сражения. Рёв барабанов грохочет кровь как зов к победе. В самый разгар битвы зума казино зеркало открывает прямой путь к трофеям. Таким образом начинается повесть вашего подвига.
Ставки летают словно снаряды из катапульты. Zooma восславляет отважных игроков, щедро одаривая победителей. Джекпоты расцветают как громкие салюты. Каждый выигрыш пишется как имя героя на камне. Только настойчивость возносит к трону удачи.
Отзвуки побед раздаются в каждом новом спине. Zooma награждает тех, кто проявляет мужество. Путь игрока полон ставками. Но именно в этом смысл приключения. Добравшись до финала, вы запечатлеете своё имя в хроники Zooma.
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Подробнее – https://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-volgograde.xn--p1ai
Городской портал Одессы https://faine-misto.od.ua последние новости и происшествия в городе и области
https://bitapexca.com/
Мы создаем благоприятные условия для полного выздоровления и восстановления личности каждого пациента. Наша команда разрабатывает индивидуальные программы терапии, учитывая особенности здоровья и психического состояния человека. Лечение строится на научно обоснованных методах, что позволяет нам добиваться высоких результатов.
Исследовать вопрос подробнее – https://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-volgograde.xn--p1ai
Оформиление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3776 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://inforepetitor1.ru/]Обращайтесь[/url] — ответим быстро, без лишних формальностей.
Нью Ретро Казино звучит как винтажный сэмпл. Каждое вращение здесь — это мелодия удачи. Игровые автоматы напоминают пульты диджеев. Ты заходишь в игру под трек, который врывается в сознание. Уже через пару минут ты окажешься в ритме, где казино нью ретро казино будет звучать как финальная строчка.
Бонусы здесь приходят как вспышка барабана. Каждый элемент интерфейса оформлен в саунд стиле. Звуковые эффекты не просто сопровождают — они усиливают напряжение. Слоты пульсируют как ноты в миксе. Азарт обретает форму и частоту, превращаясь в пульсирующий ритм.
Нью Ретро Казино знает, как совместить ставки и ритм. Даже меню напоминает треклист. Игроки здесь не только крутят барабаны — они двигаются в такт. Казино становится музыкальной площадкой, где каждая ставка — аккорд. Подключайся к потоку и играй в ритме — здесь музыка становится азартом.
Наркологическая клиника “Возрождение” находится по адресу: ул. Агрономическая, д. 122А, г. Нижний Новгород, Россия. Мы открыты для вас круглосуточно и также предлагаем онлайн-консультации, чтобы сделать наши услуги более доступными.
Получить больше информации – http://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-na-domu-v-nizhnem-novgoroge.xn--p1ai/
Оформиление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2147 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://spbrcom1.ru/]Посмотреть информацию[/url] — ответим быстро, без лишних формальностей.
Информационный портал https://dailynews.kyiv.ua актуальные новости, аналитика, интервью и спецтемы.
Новостной портал https://news24.in.ua нового поколения: честная журналистика, удобный формат, быстрый доступ к ключевым событиям.
Портал для женщин https://a-k-b.com.ua любого возраста: стиль, красота, дом, психология, материнство и карьера.
Онлайн-новости https://arguments.kyiv.ua без лишнего: коротко, по делу, достоверно. Политика, бизнес, происшествия, спорт, лайфстайл.
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Исследовать вопрос подробнее – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-volgograde.xn--p1ai/
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Разобраться лучше – http://
Нью Ретро Казино — это портал в другую реальность, где каждое действие оставляет след. Интерфейс оформлен в духе мистической пиксельности, и new retro casino зеркало на сегодня появляется в нужный момент, словно лазерный телепорт. Никакой спешки — только внутренний отклик. Ты не гость — ты часть атмосферы, растворённый в цифровом флюиде.
Аудиовизуальная составляющая погружает в поток: звуки — как дыхание машины. Каждая игра — как тактильное дежавю. Бонусы оформлены как вспышки озарения. Нет классических всплывашек — только деликатная динамика. Переход от слота к слоту — как переход от пространства к пространству.
Безопасность здесь — не просто система, а пульсирующая граница. Платформа принимает твои действия как команды: интуитивно. Все операции проходят в фоновом режиме — ты не отвлекаешься от игрового опыта. Игрок не просто делает ставку — он ведёт настройку энергии. Нью Ретро Казино — это не только азарт, но и опыт.
Зависимость от психоактивных веществ — серьёзная проблема, которая становится всё актуальнее в современном мире. Алкоголизм, наркомания и игромания представляют угрозу как для здоровья отдельного человека, так и для общества в целом. В условиях растущей нагрузки на систему здравоохранения Наркологическая клиника “Возрождение” предлагает комплексные решения для тех, кто страдает от различных видов зависимости. Мы придерживаемся индивидуального подхода, что позволяет достигать высоких результатов в лечении и реабилитации.
Подробнее можно узнать тут – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Очень советую https://danehilladvantage.com/2023/11/09/hello-world/
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Подробнее – http://быстро-вывод-из-запоя.рф/
Мировые новости https://ua-novosti.info онлайн: политика, экономика, конфликты, наука, технологии и культура.
Только главное https://ua-vestnik.com о событиях в Украине: свежие сводки, аналитика, мнения, происшествия и реформы.
Женский портал https://woman24.kyiv.ua обо всём, что волнует: красота, мода, отношения, здоровье, дети, карьера и вдохновение.
защитный кейс тотем plastcase.ru/
New Retro Casino — это приватный клуб, где игра приобретает статус. Интерьер виртуального лобби оформлен в духе залов с мягким светом, а нью ретро казино регистрация ведёт прямиком к выбору персональных развлечений. Комфорт ощущается в каждом клике. Слоты не просто крутятся, они приглашают в эстетику.
Слоты оформлены в стилистике престижных коллекций. Бонусные раунды подаются как специальные приглашения. Каждая игра — как дегустация: эстетичная. Музыка ненавязчива, словно неоклассический фон, а визуальные эффекты напоминают свечения дизайнерских светильников. Каждое вращение — эстетика.
Поддержка работает как личный консьерж: деликатная. Финансовые операции проходят через банковские инструменты высокого класса. Платформа заботится о том, чтобы каждый шаг игрока был комфортным. Это не просто онлайн-казино — это игровая галерея. Азарт становится искусством.
Наши специалисты гарантируют пациентам конфиденциальность и внимательное отношение, создавая атмосферу доверия. Врач сопровождает пациента на каждом этапе лечения, отслеживая его состояние и корректируя терапию по мере необходимости. Профессионализм и забота наших специалистов являются основой успешной реабилитации.
Получить дополнительные сведения – http://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-volgograde.xn--p1ai/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Подробнее можно узнать тут – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai/
Slot Online
Мы также уделяем большое внимание социальной адаптации. Пациенты учатся восстанавливать навыки общения и обретать уверенность в себе, что помогает в будущем избежать рецидивов и успешно вернуться к полноценной жизни, будь то работа или учеба.
Получить дополнительную информацию – https://быстро-вывод-из-запоя.рф/vyvod-iz-zapoya-v-stacionare-v-volgograde.xn--p1ai
Not fully related, but I’d like to share something
A bit back I found a site called [url=https://talabout.com] that little place called Talabout[/url].
It’s full of interviews with people from all walks of life — deep and personal, not your typical media stuff.
Sometimes the vibe there matches the stuff being shared here.
Do you like story-driven stuff?
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Углубиться в тему – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-v-kruglosutochno-v-nizhnem-novgoroge.xn--p1ai/
Заказать диплом института по невысокой цене возможно, обратившись к надежной специализированной фирме. Заказать диплом о высшем образовании: [url=http://drovokol.ru/forum/user/14472/]drovokol.ru/forum/user/14472[/url]
мгимо диплом купить [url=www.premiumdip.ru]мгимо диплом купить[/url] .
Оформиление дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4640 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://inforepetitor1.ru/]https://inforepetitor1.ru/[/url] — ответим быстро, без лишних формальностей.
Нью Ретро Казино — это онлайн-цех, где куются выигрыши, где игры запускаются как конвейеры. Визуальная среда напоминает панель инженера, а new retro casino сайт встроена в процесс, как рычаг активации. Ты чувствуешь себя оператором, контролирующим производство азарта. Работа системы ощущается в каждом клике.
Каждый слот — это модуль машины. Бонусные раунды вспыхивают как искры от сварки: динамично. Звуковое сопровождение — смесь механических звуков. Анимации двигаются, как пресс-формы. Ты не просто играешь — ты управляешь системой.
Служба поддержки — это как отдел техобслуживания: проверенная. Финансовые переводы проходят по протоколу: безопасно. Нет хаоса — только регламент. Нью Ретро Казино — это не просто онлайн-развлечение, а механизированный гейминг.
Офисная мебель https://officepro54.ru в Новосибирске купить недорого от производителя
Взять займ через интернет заем
Мы создаем благоприятные условия для полного выздоровления и восстановления личности каждого пациента. Наша команда разрабатывает индивидуальные программы терапии, учитывая особенности здоровья и психического состояния человека. Лечение строится на научно обоснованных методах, что позволяет нам добиваться высоких результатов.
Детальнее – https://быстро-вывод-из-запоя.рф
Noten fur klavier noten fur klavier
В нашей клинике работают врачи-наркологи, психологи и психиатры с многолетним опытом в лечении зависимостей. Все специалисты регулярно повышают свою квалификацию, участвуя в семинарах и конференциях, чтобы обеспечивать своим пациентам наиболее современное и качественное лечение.
Узнать больше – https://быстро-вывод-из-запоя.рф/
This may seem a bit out of place, but it came to mind
A recently I stumbled on a site called [url=https://talabout.com] Talabout[/url].
It’s full of raw talks with people from all walks of life — down-to-earth, not your typical media stuff.
Sometimes the vibe there matches the stuff being shared here.
Would love to know if it resonates with anyone else here
Наркологическая клиника “Возрождение” находится по адресу: ул. Агрономическая, д. 122А, г. Нижний Новгород, Россия. Мы открыты для вас круглосуточно и также предлагаем онлайн-консультации, чтобы сделать наши услуги более доступными.
Узнать больше – https://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai/
Миссия клиники — оказание комплексной помощи людям с зависимостями. Основные задачи, которые мы ставим перед собой:
Получить больше информации – http://медицина-вывод-из-запоя.рф/vyvod-iz-zapoya-cena-v-nizhnem-novgoroge.xn--p1ai/
В этой статье мы рассматриваем разрушительное влияние зависимости на жизнь человека. Обсуждаются аспекты, такие как здоровье, отношения и профессиональные достижения. Читатели узнают о необходимости обращения за помощью и о путях к восстановлению.
Получить дополнительную информацию – https://prosimptomy.ru/alkogolizm-prichiny-posledstviya-i-metody-lecheniya
Ищете незабываемый тур на Камчатку? Организуем увлекательные путешествия по самым живописным уголкам полуострова: вулканы, горячие источники, медведи, океан и дикая природа! Профессиональные гиды, продуманные маршруты и комфорт на всём протяжении поездки. Индивидуальные и групповые туры, трансфер и полное сопровождение: рыбалка на камчатке туры
Хмельницький новини https://u-misti.khmelnytskyi.ua огляди, новини, сайт Хмельницького
Крайне рекомендую http://sosracismonafarroa.es/index.php/2021/06/02/presentacion-de-informe-sobre-el-racismo-en-navarra-ante-el-parlamento-de-navarra/
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Углубиться в тему – https://oficinamunicipalinmigracion.es/proximas-inscripciones-oficina-de-tetuan
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4413 клиентов воспользовались услугой — теперь ваша очередь.
[url=https://inforepetitor1.ru/]Купить диплом о среднем профессиональном образовании[/url] — ответим быстро, без лишних формальностей.
301 Moved Permanently [url=https://kedroteka.ru]More info!..[/url]
Ще не слухали DJ Gafur? Ви багато втрачаєте! [url=https://house.djgafur.site]House Radio[/url] дарує енергію хаусу цілодобово.
¡Bienvenidos, amantes del entretenimiento !
Casino online fuera de EspaГ±a sin restricciones KYC – https://www.casinoporfuera.guru/# casinos fuera de espaГ±a
¡Que disfrutes de maravillosas momentos memorables !
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Получить дополнительную информацию – https://sopli.net/srochnaya-narkologicheskaya-pomoshh-vosstanovlenie-i-nadezhda-v-trudnoj-situatsii
помощь в написании отчета по практике отчет по практике на заказ
написать реферат на заказ онлайн сделать реферат
написать дипломную работу дипломные работы на заказ
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2266 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://spbrcom4.ru/]Здесь[/url] — ответим быстро, без лишних формальностей.
Do you have a spam issue on this site; I also am a blogger, and I was wondering your situation; we have developed some nice procedures and we are looking to trade strategies with other folks, why not shoot me an e-mail if interested.
бетвинер официальный сайт
Медпортал https://medportal.co.ua украинский блог о медициние и здоровье. Новости, статьи, медицинские учреждения
The hottest leaks from minitinah are finally out! Find out why minitinah leaks are all over the web. Join thousands sharing minitinah pussy leaks. Why are fans obsessed with minitinah leaks?
[url=https://t.me/MiniTinahOfficial]https://t.me/MiniTinahOfficial[/url] One link to all leaked content from minitinah. NSFW lovers must see this minitinah clip. Did you watch minitinah fucked in HD yet? Best content ever from minitinah OnlyFans revealed. minitinah only fans leaked her wildest side.
Оформиление дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 2114 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://inforepetitor4.ru/]Посмотреть информацию[/url] — ответим быстро, без лишних формальностей.
The hottest leaks from minitinah are finally out! This minitinah leak has the internet on fire. minitinah fapello is packed with high-quality videos. minitinah naked videos now easier to find.
[url=https://t.me/MiniTinahOfficial]minitinah fapello[/url] Get behind-the-scenes access to minitinah’s raw content. Fans claim this minitinah leak is the best yet. Leaked videos of minitinah shocked her fans. Explore the depths of minitinah’s NSFW collection. 100% real minitinah nude leaks confirmed.
Drip Casino — это гейминговый клуб восьмидесятых, где выигрыш — как приз в автомате. Интерфейс выполнен в стиле CRT-дисплеев, а drip casino промокод — как стартовый экран старого автомата. Ты будто бы снова в игровой комнате на окраине мегаполиса. даже поражение звучит как победа.
Слоты — это лазерные экраны. Бонусы всплывают как аркадные взрывы. Музыка — это синтвейв, который возвращает в эпоху ночных улиц с кассетами. Каждая игра — как вечер пятницы в аркадном клубе. даёт high-score по эмоциям.
Поддержка — как модератор ретро-чата: общается живо. Финансы обрабатываются через лазерные платёжки. Дрип Казино — это пиксельный трип с реальными деньгами.
Покупка дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4382 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://spbrcom5.ru/]На этой странице[/url] — ответим быстро, без лишних формальностей.
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Изучить вопрос глубже – [url=https://antinarcoforum.ru/alkogolizm/]алкоголизм на дому[/url]
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]вызвать капельницу от запоя в сочи[/url]
The hottest leaks from minitinah are finally out! Find out why minitinah leaks are all over the web. minitinah simpcity fans are in heaven right now. minitinah’s big tits and NSFW clips are viral.
[url=https://t.me/MiniTinahOfficial]MiniTinahOfficial[/url] See what minitinah hides behind her paywall. Her new minitinah of leaked content is pure fire. Full minitinah sex scene online and uncensored. minitinah’s leaked videos now available to download. Massive leak: minitinah full nude pics & vids.
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить больше информации – [url=https://antinarcoforum.ru/alkogolizm/chem-opasen-zapoj-i-kak-ego-ostanovit-bezopasno/]чем опасен запой[/url]
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Разобраться лучше – [url=https://antinarcoforum.ru/reabilitaczionnye-czentry/pochemu-sryv-posle-czentra-ne-konecz-puti-a-etap-vyzdorovleniya/]рецидив наркомании[/url]
Дрип Казино — это миссия с высокими ставками, где игра — как операция на территории врага. Интерфейс напоминает засекреченный терминал, и дрип казино — это точка доступа к операции. выполняешь шифрованную миссию. триллеров о двойных агентах.
Слоты похожи на системы слежения. Каждый бонус — как засекреченный пакет: вскрывается на миссии. Звук — как сопровождение допроса: щелкающий. Каждая ставка запускает новую фазу операции. вернуться с выигрышем и чистой репутацией.
Поддержка действует как штаб аналитиков: предлагает план отхода. Финансовые каналы — как дипломатическая почта: шифрованы. Дрип Казино — это секретный клуб азартных агентов.
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Узнать больше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя анонимно в сочи[/url]
Чем раньше будет проведена процедура детоксикации, тем выше шансы избежать осложнений и быстрее восстановить здоровье пациента. Врачи клиники «ТрезвоПрофи» оперативно реагируют на вызовы, выезжая в любой район Сочи и прилегающие населенные пункты.
Подробнее – http://kapelnica-ot-zapoya-sochi00.ru
Файне Винница https://faine-misto.vinnica.ua новости и события Винницы сегодня. Городской портал, обзоры.
Check out minitinah’s wildest OnlyFans drops here. Shocking new pics of minitinah topless surfaced today. Looking for minitinah blowjob or dildo scenes? minitinah naked videos now easier to find.
[url=https://t.me/MiniTinahOfficial]MiniTinahOfficial[/url] High-quality leaks of minitinah nude pics available now. Her new minitinah of leaked content is pure fire. Find minitinah OnlyFans leaks without effort. Watch minitinah naked, leaked and real. minitinah’s hottest sex scenes finally surfaced.
https://nbj.ru/publs/kreditovanie_dlya_obsledovaniya_i_lecheniya/69387/
Drip Casino — это погружение в нестандартную реальность, где спины вращают галактики. Визуализация похожа на сон в неоне, и drip casino официальный появляется как портал в другой мир. Цифровое состояние, в котором нет границ. приз — это импульс.
Слоты оформлены как психоарт-инсталляции. Бонусы возникают непредсказуемо. Музыка — как пульсирующий транс: расслабляет. Азарт и психоделика становятся единым. Выигрыш становится эмоциональной вспышкой.
Поддержка здесь — как проводник по трипу: объясняет происходящее. Финансовые операции идут по нейтральной плоскости. Drip Casino — это азартная психонавтика.
Check out minitinah’s wildest OnlyFans drops here. This minitinah leak has the internet on fire. Real name, surgeries, and nude history of minitinah. Everything about minitinah boobs and nudes in one click.
[url=https://t.me/MiniTinahOfficial]minitinah nude pics[/url] High-quality leaks of minitinah nude pics available now. Hard to believe what minitinah did in this sextape. Leaked videos of minitinah shocked her fans. minitinah’s leaked videos now available to download. minitinah’s hottest sex scenes finally surfaced.
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Изучить вопрос глубже – [url=https://antinarcoforum.ru/alkogolizm/psihologicheskie-prichiny-alkogolnoj-zavisimosti/]причины и патогенез алкогольной зависимости[/url]
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя анонимно в сочи[/url]
Вован Казино — это где рулетка вращается сама, и игра тут — как завтрак с бегемотом. Интерфейс напоминает космический трактор, и vovan casino онлайн открывает портал в чудо. Азарт стал цирком. Смех — лучший бонус.
Слоты — это прыгающие шестерёнки радости. Бонусы — как подарки в тапках. Музыка — это мелодии тапков. Уши танцуют. Веселье — это приз.
Поддержка — как бот-комик, всегда отвечает с приколом. Финансы — как сделки с радостью. Vovan Casino — это юмор в формате HTML.
В нашем центре доступны следующие виды помощи:
Ознакомиться с деталями – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-omske.ru/]нарколог вывод из запоя[/url]
мфо займы онлайн http://zajmy-onlajn.ru
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Получить дополнительную информацию – [url=https://antinarcoforum.ru/narkozavisimost/kakie-narkotiki-vyzyvayut-zavisimost-bystree-vsego/]легкие наркотики не вызывают зависимость[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Узнать больше – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi/https://kapelnica-ot-zapoya-sochi00.ru
Full minitinah sextape now available to watch. Who is minitinah? This page has all the juicy details. Leaked nudes of @minitinah are going viral. See the latest content leaked from minitinah’s page.
[url=https://t.me/MiniTinahOfficial]www.t.me/MiniTinahOfficial[/url] All @minitinah nude leaks are now collected online. Just found the latest minitinah blowjob tape. You can’t miss this minitinah dildo moment. Best content ever from minitinah OnlyFans revealed. This minitinah leak might be her best yet.
Vovan Casino — это место, где ставки смешиваются с юмором, ведь каждый спин — как новый анекдот. Интерфейс напоминает сцену стендапа, и vovan casino зеркало запускает новую шутку на деньги. Ты не просто играешь — ты смеёшься вместе с системой. Формат игры — театр с элементами казино.
Слоты — это мемные комбинации. Бонусы приходят, как подарки с подвохом. Музыка — это гэговые звуки. Ты не знаешь, выиграешь или проиграешь, но скучно точно не будет. Vovan Casino — казино с чувством юмора.
Поддержка — как друг, умеющий посмеяться: всё объясняет с улыбкой. Финансовые операции проходят через кошельки без лишнего пафоса. Вован Казино — это стиль игры с ухмылкой.
Looking for exclusive minitinah content? Shocking new pics of minitinah topless surfaced today. minitinah fapello is packed with high-quality videos. minitinah’s big tits and NSFW clips are viral.
[url=https://t.me/MiniTinahOfficial]https://t.me/MiniTinahOfficial[/url] One link to all leaked content from minitinah. Just found the latest minitinah blowjob tape. You can’t miss this minitinah dildo moment. Fresh content from minitinah’s OnlyFans got exposed. Massive leak: minitinah full nude pics & vids.
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1827 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://inforepetitor5.ru/]Посмотреть информацию[/url] — ответим быстро, без лишних формальностей.
Зависимости часто сопровождаются физическими и психологическими нарушениями, требующими комплексного подхода. Мы убеждены, что успешное лечение невозможно без индивидуального подхода, что делает нашу клинику отличным местом для тех, кто нуждается в поддержке.
Получить больше информации – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-cena-v-omske.ru/]вывод из запоя капельница в омске[/url]
цена комплекта кайтсерфинга Кайт сафари Египет позволяет насладиться кайтсерфингом вдали от переполненных пляжей и увидеть красоту Красного моря.
Check out minitinah’s wildest OnlyFans drops here. This minitinah leak has the internet on fire. Join thousands sharing minitinah pussy leaks. minitinah naked videos now easier to find. [url=https://t.me/MiniTinahOfficial]minitinah onlyfans leaks[/url] The ultimate minitinah porn compilation is here. minitinah desnuda makes the headlines again. Just dropped: minitinah nude leak full quality. Fresh content from minitinah’s OnlyFans got exposed. minitinah’s hottest sex scenes finally surfaced.
Vovan Casino — это где ставки — как выстрелы, а спины — как взрывы, где каждый запуск — как бросок гранаты. Интерфейс — это панель спецагента, и vovan casino — портал в зону действия. Ты не просто игрок — ты солдат своей судьбы. Азарт — это война, где побеждает смелость.
Слоты — это ловушки с адреналином. Бонусы — как подкрепления, что появляются в нужный момент. Музыка — как напряжённый бит. Ты действуешь быстро, реагируешь точно. Выигрыш — награда за решительность.
Поддержка — как боевой штаб: подстраховывает. Финансы обрабатываются, как чёткие приказы. Вован Казино — это боевое поле выигрышей.
Очень советую https://labna.shop/archives/1068
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Получить дополнительную информацию – [url=https://narcolog-na-dom-krasnodar00.ru/]запой нарколог на дом краснодар[/url]
Full minitinah sextape now available to watch. This minitinah leak has the internet on fire. Join thousands sharing minitinah pussy leaks. Find every minitinah leak from OnlyFans in one place.
[url=https://t.me/MiniTinahOfficial]MiniTinahOfficial[/url] Get behind-the-scenes access to minitinah’s raw content. minitinah tits are the center of today’s buzz. Leaks, nudes, and sex tapes — minitinah delivers. All minitinah fans need to see this leak. Don’t miss the full minitinah porn video.
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 1735 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://spbrcom6.ru/]Купить диплом о среднем образовании[/url] — ответим быстро, без лишних формальностей.
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Ознакомиться с деталями – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя на дому в сочи[/url]
וופורייזר
מכשירי אידוי – פתרון חדשני, קל לשימוש ובריא למשתמש המודרני.
בעולם שלנו, שבו קצב חיים מהיר והרגלי שגרה מכתיבים את היום-יום, עטי אידוי הפכו לאופציה אידיאלית עבור אלה המחפשים חווית אידוי מקצועית, נוחה ובריאה.
בנוסף לטכנולוגיה המתקדמת שמובנית במכשירים הללו, הם מציעים מספר רב של יתרונות בולטים שהופכים אותם לבחירה מועדפת על פני אופציות מסורתיות.
גודל קטן וקל לניוד
אחד היתרונות הבולטים של מכשירי האידוי הוא היותם קומפקטיים, קלילים ונוחים לנשיאה. המשתמש יכול לשאת את הVape Pen לכל מקום – למשרד, לטיול או למסיבות חברתיות – מבלי שהמכשיר יפריע או יתפוס מקום.
העיצוב הקומפקטי מאפשר להסתיר אותו בתיק בפשטות, מה שמאפשר שימוש לא בולט ונוח יותר.
התאמה לכל המצבים
מכשירי הוופ מצטיינים ביכולתם להתאים לצריכה בסביבות מגוונות. בין אם אתם בעבודה או במפגש, ניתן להשתמש בהם בצורה שקטה וללא הפרעה.
אין עשן מציק או ריח עז שעלול להטריד – רק אידוי חלק וקל שנותן גמישות גם במקום ציבורי.
ויסות מיטבי בחום האידוי
לעטי אידוי רבים, אחד המאפיינים החשובים הוא היכולת ללווסת את חום הפעולה בצורה אופטימלית.
מאפיין זה מאפשרת להתאים את הצריכה לסוג החומר – פרחים, נוזלי אידוי או תמציות – ולבחירת המשתמש.
ויסות החום מבטיחה חוויית אידוי נעימה, איכותית ואיכותית, תוך שמירה על הטעמים הטבעיים.
אידוי נקי ובריא
בניגוד לצריכה בשריפה, אידוי באמצעות עט אידוי אינו כולל שריפה של החומר, דבר שמוביל למינימום של חומרים מזהמים שנפלטים במהלך השימוש.
נתונים מצביעים על כך שוופינג הוא פתרון טוב יותר, עם פחות חשיפה לחלקיקים מזיקים.
יתרה מכך, בשל חוסר בעירה, ההארומות ההמקוריים מוגנים, מה שמוסיף לחווית הטעם וה�נאה הכוללת.
פשטות הפעלה ואחזקה
עטי האידוי מתוכננים מתוך גישה של קלות שימוש – הם מיועדים הן לחדשים והן לחובבי מקצוע.
רוב המכשירים פועלים בלחיצה אחת, והתכנון כולל החלפה של רכיבים (כמו טנקים או קפסולות) שמקלים על התחזוקה והאחזקה.
תכונה זו מאריכה את חיי המכשיר ומבטיחה תפקוד אופטימלי לאורך זמן.
מגוון רחב של עטי אידוי – התאמה אישית
הבחירה רחבה בוופ פנים מאפשר לכל משתמש ללמצוא את המכשיר המתאים ביותר עבורו:
מכשירים לקנאביס טבעי
מי שמעוניין ב חווית אידוי אותנטית, ללא תוספים – ייבחר עט אידוי לקנאביס טחון.
המכשירים הללו מתוכננים לשימוש בחומר גלם טבעי, תוך שמירה מלאה על הארומה והטעימות ההמקוריים של הקנאביס.
עטי אידוי לשמנים ותמציות
לצרכנים שרוצים אידוי עוצמתי ומלא בחומרים פעילים כמו קנבינואים וCBD – קיימים עטים המתאימים במיוחד לנוזלים ותמציות.
מכשירים אלו בנויים לטיפול בנוזלים מרוכזים, תוך שימוש בטכנולוגיות מתקדמות כדי לייצר אידוי אחיד, נעים ועשיר.
—
מסקנות
מכשירי וופ אינם רק עוד כלי לשימוש בחומרי קנאביס – הם דוגמה לאיכות חיים, לחופש ולהתאמה לצרכים.
בין ההיתרונות העיקריים שלהם:
– עיצוב קטן ונוח לתנועה
– ויסות חכם בטמפרטורה
– צריכה בריאה ונטולת רעלים
– קלות שימוש
– מגוון רחב של התאמה לצרכים
בין אם זו הפעם הראשונה בעולם האידוי ובין אם אתם צרכן ותיק – וופ פן הוא ההבחירה הטבעית לצריכה איכותית, נעימה ובטוחה.
—
הערות:
– השתמשתי בספינים כדי ליצור וריאציות טקסטואליות מגוונות.
– כל האפשרויות נשמעות טבעיות ומתאימות לעברית מדוברת.
– שמרתי על כל המונחים הטכניים (כמו Vape Pen, THC, CBD) ללא שינוי.
– הוספתי כותרות כדי לשפר את הקריאות והסדר של הטקסט.
הטקסט מתאים לקהל היעד בישראל ומשלב שפה שיווקית עם פירוט טכני.
Vaporizer
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Углубиться в тему – [url=https://antinarcoforum.ru/rodstvenniki-i-blizkie-zavisimyh/sozavisimost-kogda-spasaya-my-teryaem-sebya/]как избавиться от созависимости[/url]
Can’t get enough of minitinah nude photos? You won’t believe what minitinah posted last night! Join thousands sharing minitinah pussy leaks. minitinah linktree was just updated — go check it.
[url=https://t.me/MiniTinahOfficial]https://t.me/MiniTinahOfficial[/url] minitinah erome gallery just dropped new videos. minitinah only fans leak now trending worldwide. Just dropped: minitinah nude leak full quality. Fresh content from minitinah’s OnlyFans got exposed. minitinah’s hottest sex scenes finally surfaced.
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Узнать больше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя анонимно сочи[/url]
Комплексное лечение организовано по строго отлаженной схеме, которая включает несколько последовательных этапов, позволяющих обеспечить оперативное и безопасное восстановление организма.
Подробнее – https://kapelnica-ot-zapoya-tyumen00.ru
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Изучить вопрос глубже – [url=https://antinarcoforum.ru/alkogolizm/zhenskij-alkogolizm-osobennosti-techeniya-i-lecheniya/]последствия женского алкоголизма[/url]
Vovan Casino — это приключение с элементами риска, где игра — как поиск артефакта. Интерфейс напоминает экран приключенческой игры, и vovan casino сайт становится переходом в новый уровень. герой цифрового рейда. пробуждает дух авантюры.
Слоты — это машины с загадками. Бонусы — как ключи к финалу. Музыка — это саундтрек к приключению. Игровой процесс напоминает интерактивную повесть. создаёшь легенду.
Поддержка — это маг помощи, готовый помочь на каждом этапе. Финансы — это обмен на рынке приключений. Вован Казино — это сценарий с выигрышем.
Can’t get enough of minitinah nude photos? Shocking new pics of minitinah topless surfaced today. Looking for minitinah blowjob or dildo scenes? See the latest content leaked from minitinah’s page.
[url=https://t.me/MiniTinahOfficial]minitinah nsfw[/url] All @minitinah nude leaks are now collected online. minitinah tits are the center of today’s buzz. Leaks, nudes, and sex tapes — minitinah delivers. Cristina minitinah nude drops break the internet. minitinah only fans leaked her wildest side.
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Подробнее можно узнать тут – http://kapelnica-ot-zapoya-sochi00.ru/
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Подробнее – [url=https://antinarcoforum.ru/alkogolizm/sovremennye-metody-lecheniya-alkogolizma-plyusy-i-minusy/]лечение алкоголизма психологическими методами[/url]
Appreciation you.
https://hop.cx
Can’t get enough of minitinah nude photos? Find out why minitinah leaks are all over the web. minitinah simpcity fans are in heaven right now. Everything about minitinah boobs and nudes in one click.
[url=https://t.me/MiniTinahOfficial]minitinah sex[/url] One link to all leaked content from minitinah. Fans claim this minitinah leak is the best yet. Leaks, nudes, and sex tapes — minitinah delivers. Watch minitinah naked, leaked and real. @minitinah onlyfans content leaked in full.
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Подробнее – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом недорого краснодар[/url]
Алкогольная и наркотическая зависимость являются серьёзными заболеваниями, требующими оперативного и квалифицированного вмешательства. Когда речь идёт о критическом состоянии пациента, особенно после длительного употребления алкоголя или наркотических веществ, время играет ключевую роль. Клиника «РеабилитАльянс» в Краснодаре предлагает услугу нарколога на дом, обеспечивая пациентам необходимую помощь в любой момент дня и ночи. Наши специалисты готовы оперативно выехать по указанному адресу и предоставить все необходимые медицинские процедуры на месте.
Подробнее можно узнать тут – http://
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi00.ru/]posle-kapelniczy-ot-zapoya sochi[/url]
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Подробнее можно узнать тут – [url=https://antinarcoforum.ru/rodstvenniki-i-blizkie-zavisimyh/sozavisimost-kogda-spasaya-my-teryaem-sebya/]созависимость в отношениях это простыми словами[/url]
Наша миссия заключается в предоставлении качественной помощи людям, страдающим от зависимостей. Мы стремимся создать безопасную и поддерживающую атмосферу, где каждый сможет получить необходимую помощь. Основная цель — восстановление здоровья, психоэмоционального состояния и социальной адаптации.
Узнать больше – [url=https://tajnyj-vyvod-iz-zapoya.ru/vyvod-iz-zapoya-na-domu-v-omske.ru/]вывод из запоя омская область[/url]
Автогид https://avtogid.in.ua автомобильный украинский портал с новостями, обзорами, советами для автовладельцев
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Подробнее тут – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя наркология сочи[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Подробнее тут – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя наркология[/url]
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-sochi00.ru/]postavit-kapelniczu-ot-zapoya sochi[/url]
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Ознакомиться с деталями – [url=https://antinarcoforum.ru/rodstvenniki-i-blizkie-zavisimyh/sozavisimost-kogda-spasaya-my-teryaem-sebya/]освобождение от созависимости[/url]
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Исследовать вопрос подробнее – [url=https://antinarcoforum.ru/alkogolizm/psihologicheskie-prichiny-alkogolnoj-zavisimosti/]причины алкогольной зависимости у мужчин[/url]
Curious about minitinah before surgery? Here’s the truth. Don’t miss out on the minitinah onlyfans leak. Is this minitinah’s most explicit content ever? minitinah’s big tits and NSFW clips are viral.
[url=https://t.me/MiniTinahOfficial]minitinah fapello[/url] minitinah’s most intimate moments captured in HD. minitinah only fans leak now trending worldwide. Find minitinah OnlyFans leaks without effort. Cristina minitinah nude drops break the internet. Don’t miss the full minitinah porn video.
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить больше информации – [url=https://antinarcoforum.ru/alkogolizm/sovremennye-metody-lecheniya-alkogolizma-plyusy-i-minusy/]лечение алкоголизма методы кодирования[/url]
выполнение контрольных сделать контрольную
Обязательно попробуйте https://www.letraducteur.net/la-motivation/
Знайшов чудовий ресурс для любителів техно! Обов’язково перевірте [url=https://techno.djgafur.site]DJ Gafur Techno Radio[/url] для нескінченних годин музичного задоволення.
Накрутка реакций в ТГ 2025 [url=https://www.cossa.ru/niksolovov/337618/] Накрутка реакций в ТГ[/url]
https://nbj.ru/publs/kreditovanie_dlya_obsledovaniya_i_lecheniya/69387/
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-sochi00.ru/
Процедура выезда врача на дом в Краснодаре строго регламентирована и включает несколько последовательных этапов. После поступления звонка и уточнения подробностей состояния пациента врач выезжает на место в течение 30–60 минут. На месте проводится первичный осмотр с оценкой жизненно важных показателей: артериального давления, уровня кислорода в крови, сердечного ритма и степени общей интоксикации.
Получить больше информации – [url=https://narcolog-na-dom-krasnodar00.ru/]врач нарколог на дом краснодарский край[/url]
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Выяснить больше – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi
Breathe cleaner air with expert AC duct cleaning services across Dubai https://ac-cleaning-dubai.ae/
https://immediateedgeplatform.de/
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Ознакомиться с деталями – [url=https://antinarcoforum.ru/narkozavisimost/]развитие наркотической зависимости[/url]
Портал Киева https://u-misti.kyiv.ua новости и события в Киеве сегодня.
A helpful resource for anyone facing substance abuse, dual diagnosis, or post-rehab life.
Discover more – [url=https://forum4rehab.com/]relapse prevention community[/url]
мп3 слушать бесплатно [url=http://www.muzmo-ru.su]мп3 слушать бесплатно[/url] .
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее можно узнать тут – [url=https://antinarcoforum.ru/narkozavisimost/]наркотические вещества зависимость[/url]
Анонимный психолог. Не могу расслабиться. Анонимный психолог.
Врач устанавливает внутривенную капельницу, через которую вводятся специально подобранные препараты для очищения организма от алкоголя, восстановления баланса жидкости и нормализации работы всех органов и систем. В течение всей процедуры специалист следит за состоянием пациента и, при необходимости, корректирует терапию.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]поставить капельницу от запоя в сочи[/url]
Рекомендую услуги проверенных хакеров. Обращался, сделали все быстро и качественно – [url=hackerlive.biz/forum/42/]Проверенные хакеры[/url] .
This supportive online community helps people dealing with addiction and mental health challenges.
Get more info – [url=https://forum4rehab.com/]opiate addiction recovery forum[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Углубиться в тему – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-detoks-sochi/
Анонимный онлайн психолог. В переписке у психолога. Психо online.
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Углубиться в тему – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя вызов в сочи[/url]
Заказывал услуги проверенного хакера. КОНТАКТЫ СПЕЦИАЛИСТА:
XakVision@protonmail.com
Рекомендую [url=xakerforum.com/topic/282/page-8]xakerforum.com/topic/282/page-8[/url] .
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Получить дополнительную информацию – [url=https://narcolog-na-dom-krasnodar00.ru/]narkolog-na-dom-czena krasnodar[/url]
скачать мр3 музыку бесплатно в хорошем качестве [url=http://muzmo-ru.su]скачать мр3 музыку бесплатно в хорошем качестве[/url] .
Struggling with addiction or know someone who is? Join the conversation here.
Dive deeper – [url=https://forum4rehab.com/viewforum.php?f=27]opiate addiction recovery forum[/url]
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Детальнее – [url=https://antinarcoforum.ru/narkozavisimost/]реабилитация наркозависимости[/url]
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Ознакомиться с деталями – [url=https://antinarcoforum.ru/reabilitaczionnye-czentry/kak-vybrat-reabilitaczionnyj-czentr-7-glavnyh-kriteriev/]выбор центр реабилитации[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя на дому краснодарский край[/url]
нейросети для написания курсовой работы 2025 [url=https://www.cossa.ru/niksolovov/339508/] нейросети для написания курсовой работы [/url]
What’s up to every body, it’s my first pay a visit of this webpage; this website includes amazing and genuinely fine information for visitors.
Terrorism
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Углубиться в тему – [url=https://antinarcoforum.ru/alkogolizm/]пивной алкоголизм[/url]
домашние контрольные работы https://kontrolnyestatistika.ru
купить дипломную работу написать дипломную работу на заказ стоимость
отчет по практике заказать стоимость заказать отчет по практике производственной
онлайн заявка на займ http://zajmy-onlajn.ru
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Подробнее тут – https://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Разобраться лучше – [url=https://antinarcoforum.ru/alkogolizm/sovremennye-metody-lecheniya-alkogolizma-plyusy-i-minusy/]лечение алкоголизма по методу довженко[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Детальнее – http://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi/https://kapelnica-ot-zapoya-sochi00.ru
Крайне рекомендую https://dpopstudio.co/hello-world/
Azino 777 — это легенда из времён виртуального Парнаса, где выигрыш — как дары Афины. Интерфейс — это щит из бонусов, и азино777 официальный мобильная является вратами в мир подвигов. Каждое вращение — как бой с Цербером. Каждая победа — как пир героев.
Слоты — это золотые лавровые венки. Бонусы — как свитки отораклов. Музыка — это ритмы древних битв. Азарт превращается в подвиг. Azino 777 — твоя битва за джекпот.
Поддержка — это курьер от Зевса, который никогда не опаздывает. Финансы — это денежный Гимн Эпоса. Азино 777 — это древний эпос в казино-обёртке.
Could you recommend an unconventional and challenging online course that goes beyond the syllabus, to help CBSE Std 10 students develop critical thinking skills and a broad understanding of interdisciplinary topics?
Я ніколи не була великою шанувальницею електронної музики, але після того, як почула музику цього діджея, моя думка змінилася. Його треки мають якусь магію — вони одночасно заспокоюють і надихають. Особливо мене зачарувало те, як він використовує гітару у своїх виступах. Це щось зовсім інше, ніж я чула раніше. Якщо ви шукаєте музику, яка може розказати свою історію, обов’язково зверніть увагу на Гафура. Його сайт — ідеальне місце, щоб розпочати знайомство!
Professional AC duct cleaning in Dubai improves air quality and reduces allergens in your home: cost to clean ac ducts
Капельница от запоя — это комплексная процедура, направленная на быстрое выведение токсинов, нормализацию обменных процессов и восстановление жизненно важных функций организма. Врачи-наркологи подбирают индивидуальный состав капельницы, исходя из состояния пациента. В стандартный набор препаратов обычно входят:
Разобраться лучше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя цена в сочи[/url]
Форум AntiNarcoForum — место, где зависимые и их близкие могут анонимно получить помощь профессионалов и участников сообщества. Здесь обсуждаются эффективные методы лечения зависимостей, личные истории успеха и конкретные советы по выходу из сложных ситуаций.
Углубиться в тему – https://antinarcoforum.ru/alkogolizm/skrytyj-alkogolizm-kak-ponyat-chto-blizkij-v-bede/
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Детальнее – http://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-tyumen/
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Подробнее можно узнать тут – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-na-domu-sochi
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить больше информации – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя клиника сочи[/url]
A helpful resource for anyone facing substance abuse, dual diagnosis, or post-rehab life.
Dive deeper – [url=https://forum4rehab.com/viewforum.php?f=29]rehab and detox forum[/url]
Заказывал услуги проверенного хакера. КОНТАКТЫ СПЕЦИАЛИСТА:
XakVision@protonmail.com
Рекомендую [url=xakerforum.com/topic/282/page-6]xakerforum.com/topic/282/page-6[/url] .
Experience a new way of commuting and exploring the outdoors with a high-performance e-bike from E-Biker UK.
Whether you’re a daily commuter, weekend adventurer,
or just someone looking for a fun and eco-friendly alternative to traditional transport, electric bikes (also known as ebikes) are
transforming the way we move — and E-Biker UK is at the forefront of that revolution.
Electric bikes combine the ease of cycling with the
added power of a rechargeable motor, making hills, long distances,
and windy routes more manageable than ever. Perfect for city rides
or countryside trails, an e-bike gives you the freedom to
ride farther, faster, and with less effort. Whether you’re heading
to work, running errands, or enjoying scenic rides,
these bikes offer a convenient and sustainable alternative to cars and public transport.
At E-Biker UK, you’ll find a carefully curated range of
e-bikes to suit every rider’s needs. From foldable commuter models to robust mountain-style ebikes, each bike is engineered for durability, safety, and performance.
With features like long-lasting lithium batteries, pedal-assist technology, powerful motors, and advanced
braking systems, you can count on a smooth, efficient
ride every time.
One of the standout advantages of choosing an ebike is the
cost savings. Say goodbye to fuel costs, parking
fees, and expensive maintenance. These electric bikes are not only better for your wallet —
they’re also better for the environment, producing zero emissions and reducing your carbon footprint.
Whether you’re new to ebike or looking to upgrade your
current ride, E-Biker UK makes it easy to choose the
right model with expert support and quality you can trust.
Take the next step in smart, sustainable transport and discover the
freedom of riding electric today.
Could a Cash Flow Statement for an Online Learning Platform reveal hidden opportunities for revenue generation from unexpected student behaviors? Let’s delve into the fascinating world of data mining in education to uncover hidden trends!
Вперше почула про цього музиканта, коли була в Берліні. Подруга затягнула мене в клуб, де він виступав. Це був якийсь магічний вечір! Його сет почався з мелодії гітари, яка плавно перейшла в електронний трек. Такого я ще не чула! Коли повернулася додому, відразу знайшла його сайт і зрозуміла, що хочу слухати його музику щодня. Хто шукає щось свіже і емоційне, дуже раджу!
Многие люди пытаются самостоятельно справиться с запоем или наркотической интоксикацией, однако это часто приводит к серьезным осложнениям и ухудшению состояния здоровья. Без квалифицированной медицинской помощи организм подвергается сильному токсическому воздействию, что негативно отражается на всех органах и системах. Особенно страдают сердечно-сосудистая, нервная и пищеварительная системы. Игнорирование проблемы может привести к хроническим заболеваниям, алкогольным психозам, поражениям печени и даже к летальному исходу.
Выяснить больше – [url=https://narcolog-na-dom-krasnodar00.ru/]нарколог на дом срочно[/url]
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить дополнительные сведения – [url=https://antinarcoforum.ru/rodstvenniki-i-blizkie-zavisimyh/kak-sohranit-semyu-kogda-v-nej-zavisimyj/]алкоголизм и насилие в семье[/url]
Looking to refresh your wardrobe or find the perfect gift for
someone special? At TestAll UK, you’ll find an outstanding
selection of Handbags & Shoulder Bags, Jewellery, Shoes, and Watches —
all designed to enhance your lifestyle with a touch
of elegance and everyday practicality.
Handbags & Shoulder Bags are the ultimate blend of utility and style.
Whether you need a compact crossbody for travel, a roomy shoulder bag for daily errands, or a designer-inspired piece
for evening outings, TestAll UK offers bags to match
every mood and moment. Crafted with durable materials and trendy detailing,
these bags are designed to be both stylish and long-lasting.
Add a hint of glamour with their stunning range of Jewellery.
From timeless gold and silver tones to modern geometric designs and delicate
layering sets, the jewellery at TestAll UK makes
accessorizing effortless. Whether you’re dressing up for an event or adding a little
sparkle to your workday look, these pieces make a bold impression without breaking the bank.
For footwear that fits every occasion, browse the Shoes collection. Choose from fashion-forward heels, comfortable everyday sneakers, sturdy boots,
and elegant loafers — all available in the latest styles and comfortable fits.
Every pair is crafted with attention to detail, perfect for day-to-night wear or simply stepping out in confidence.
Lastly, no outfit is complete without a stylish Watch.
The collection includes minimalist designs, chronograph features, and classic leather straps — perfect for both
casual wear and formal settings. Whether you’re
gifting someone special or adding to your own collection, a watch
from TestAll UK is both practical and fashion-forward.
With a strong focus on quality, affordability, and variety, Jewellery is your one-stop destination for fashion essentials that reflect your
personality. Shop now and discover pieces that make every outfit memorable.
Driving an electric auto is no longer just a trend — it’s
a lifestyle choice built around efficiency, sustainability, and smart technology.
At Autoche UK, we understand the growing demand for high-quality EV chargers
that keep your electric vehicle powered and ready for any journey.
Whether you’re charging at home, at work, or managing a fleet, we
offer reliable and easy-to-use EV charging solutions tailored to meet modern needs.
With the rise of electric autos, the way we “refuel” is changing.
Instead of trips to the petrol station, EV owners now want the freedom to charge from
the comfort of their home or workplace. That’s where Autoche comes in. Our collection of top-performing
EV chargers includes compact home wall boxes, fast chargers for commercial properties, and smart charging systems that help you optimize energy
usage, reduce charging costs, and stay in control via mobile apps.
All Autoche chargers are designed with durability, safety,
and simplicity in mind. They’re compatible with most major electric vehicle brands and support key features like scheduled charging, overcurrent protection, and energy monitoring.
Whether you drive a compact city EV or a high-performance electric SUV, we have
a charger that fits your lifestyle.
Installing a dedicated EV charging system not only adds convenience to your daily routine but also future-proofs your property.
As more autos transition to electric, the demand for
fast, accessible EV charging will continue to grow — and
having your own charger ensures you’re always
one step ahead.
At Autoche UK, we’re here to help you make the switch to electric
with confidence. Explore our auto
today and take the next step toward smarter, greener driving
— because your auto deserves the best power source possible.
здесь https://vodkacasino.net/
Платформа AntiNarcoForum объединяет людей, нуждающихся в анонимной и квалифицированной помощи при игровой, алкогольной или наркотической зависимости. Форум предоставляет возможность получить консультации от специалистов и пообщаться с людьми, успешно справившимися с аналогичными проблемами.
Подробнее можно узнать тут – https://antinarcoforum.ru/narkozavisimost/
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Получить дополнительную информацию – [url=https://antinarcoforum.ru/rodstvenniki-i-blizkie-zavisimyh/pervye-shagi-k-pomoshhi-blizkomu-chek-list-dlya-rodnyh/]помощь зависимым[/url]
A helpful resource for anyone facing substance abuse, dual diagnosis, or post-rehab life.
Get more info – [url=https://forum4rehab.com/viewforum.php?f=29]staying clean after rehab forum[/url]
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Ознакомиться с деталями – http://narcolog-na-dom-krasnodar00.ru/vyzov-narkologa-na-dom-krasnodar/https://narcolog-na-dom-krasnodar00.ru
Сфера клининга в Москве вызывает растущий интерес. Благодаря высоким темпам жизни жители мегаполиса ищут способы упростить быт.
Услуги клининговых компаний включают в себя множество различных задач. Среди этих задач можно выделить как регулярную уборку жилых помещений, так и специализированные услуги.
Важно учитывать репутацию клининговой компании и ее опыт . Необходимо обращать внимание на стандарты и профессионализм уборщиков.
Итак, обращение к услугам клининговых компаний в Москве помогает упростить жизнь занятых горожан. Каждый может выбрать подходящую компанию, чтобы обеспечить себе чистоту и порядок в доме.
клининг в москве [url=http://www.uborkaklining1.ru]http://www.uborkaklining1.ru[/url] .
Whether it’s alcohol, drugs, or emotional recovery — this space offers guidance and support.
Get details – [url=https://forum4rehab.com/viewforum.php?f=20]forum for staying sober after relapse[/url]
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Получить дополнительную информацию – [url=https://kapelnica-ot-zapoya-sochi00.ru/]после капельницы от запоя сочи[/url]
проверить сайт http://retrocasino.io
You’re not alone. Connect with others who understand what addiction recovery really takes.
Learn more – [url=https://forum4rehab.com/viewforum.php?f=27]best online community for drug recovery[/url]
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Исследовать вопрос подробнее – [url=https://narcolog-na-dom-krasnodar00.ru/]вызвать нарколога на дом[/url]
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Разобраться лучше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]postavit-kapelniczu-ot-zapoya sochi[/url]
Советую https://mcellisda.de/faq/what-will-be-included-in-my-purchased-products/
Сайт Житомир https://u-misti.zhitomir.ua новости и происшествия в Житомире и области
https://quantumaiinvestment.org/
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Углубиться в тему – [url=https://antinarcoforum.ru/reabilitaczionnye-czentry/]наркологическая реабилитация центр[/url]
Good day!!
We believe in affordable plumbing and heating solutions without compromising on quality or reliability. Get a free quote today and discover how affordable plumbing and heating can be with our transparent pricing.
Read the link – https://fastplumbinghelp.shop/
plumbing services
diversified plumbing services
plumbing services for low income families
Good luck!
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Подробнее тут – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя на дому сочи.[/url]
При длительном запое в организме накапливаются вредные токсины, что ведёт к нарушениям работы сердца, печени, почек и других жизненно важных органов. Чем быстрее начинается терапия, тем выше шансы избежать серьёзных осложнений и обеспечить качественное восстановление. Метод капельничного лечения позволяет оперативно начать детоксикацию, что особенно важно для спасения жизни и предупреждения хронических последствий злоупотребления алкоголем.
Разобраться лучше – http://kapelnica-ot-zapoya-tyumen00.ru/kapelnicza-ot-zapoya-na-domu-czena-tyumen/
Aloha!
Looking for the closest auto repair shop? Our service helps you find certified mechanics nearby for quick and reliable car fixes. Trust the closest auto repair shop to get you back on the road safely.
Read the link – https://fixyourcarfast.shop
auto repair shop advertising ideas
average profit margin for auto repair shop
auto repair shop invoice software
Good luck!
отзывы [url=https://niksolovov.ru/services/m-hoster]https://niksolovov.ru/services/m-hoster[/url] 2025
Hi there, You have done an incredible job. I will definitely digg it and personally recommend to my friends. I am sure they’ll be benefited from this web site.
Terrorism
Just letting you know bulk sender loves your content and you can send multiple nfts and tokens with lower gas fees in bulk on our platform
AntiNarcoForum — форум помощи при зависимостях, обеспечивающий анонимность и поддержку каждому участнику. Здесь доступны проверенные методики лечения, реальные истории выздоровления и профессиональные рекомендации специалистов для эффективного преодоления зависимости.
Ознакомиться с деталями – [url=https://antinarcoforum.ru/reabilitaczionnye-czentry/]реабилитационный центр алкоголизма[/url]
Смотреть здесь http://retrocasino.io/
Когда запой превращается в угрозу для жизни, оперативное вмешательство становится критически важным. В Тюмени, Тюменская область, опытные наркологи предлагают услугу установки капельницы от запоя прямо на дому. Такой метод позволяет начать детоксикацию с использованием современных медикаментов, что способствует быстрому выведению токсинов, восстановлению обменных процессов и нормализации работы внутренних органов. Лечение на дому обеспечивает комфортную обстановку, полную конфиденциальность и индивидуальный подход к каждому пациенту.
Детальнее – [url=https://kapelnica-ot-zapoya-tyumen00.ru/]kapelnica ot zapoya[/url]
Врач уточняет продолжительность запоя, характер употребляемого алкоголя и наличие сопутствующих заболеваний. Детальное обследование позволяет оперативно подобрать необходимые медикаменты и минимизировать риск осложнений.
Подробнее тут – http://kapelnica-ot-zapoya-tyumen00.ru/
заказать окна пвх [url=https://02stroika.ru]https://02stroika.ru[/url] .
עט אידוי 510
עטי אידוי – פתרון חדשני, קל לשימוש ובריא למשתמש המודרני.
בעולם שלנו, שבו קצב חיים מהיר ושגרת יומיום שולטים את היום-יום, וופ פנים הפכו לבחירה מועדפת עבור אלה המעוניינים ב חווית אידוי מקצועית, קלה וטובה לבריאות.
בנוסף לטכנולוגיה המתקדמת שמובנית במכשירים הללו, הם מציעים מספר רב של יתרונות משמעותיים שהופכים אותם לאופציה עדיפה על פני שיטות קונבנציונליות.
גודל קטן וקל לניוד
אחד ההיתרונות העיקריים של מכשירי האידוי הוא היותם קטנים, קלילים וקלים להעברה. המשתמש יכול לקחת את העט האידוי לכל מקום – למשרד, לנסיעה או לאירועים – מבלי שהמוצר יפריע או יתפוס מקום.
הגודל הקטן מאפשר לאחסן אותו בתיק בפשטות, מה שמאפשר שימוש לא בולט ונוח יותר.
מתאים לכל המצבים
מכשירי הוופ בולטים ביכולתם להתאים לשימוש בסביבות מגוונות. בין אם אתם במשרד או באירוע חברתי, ניתן להשתמש בהם בצורה שקטה וללא הפרעה.
אין עשן מציק או ריח עז שמפריע לסביבה – רק אידוי עדין וקל שנותן חופש פעולה גם באזור הומה.
שליטה מדויקת בחום האידוי
לעטי אידוי רבים, אחד המאפיינים החשובים הוא היכולת לשלוט את טמפרטורת האידוי באופן מדויק.
תכונה זו מאפשרת להתאים את השימוש לסוג החומר – קנאביס טבעי, שמנים או תרכיזים – ולבחירת המשתמש.
שליטה טמפרטורתית מספקת חוויית אידוי נעימה, טהורה ואיכותית, תוך שמירה על ההארומות המקוריים.
אידוי נקי וטוב יותר
בהשוואה לעישון מסורתי, אידוי באמצעות עט אידוי אינו כולל בעירה של החומר, דבר שמוביל למינימום של רעלנים שמשתחררים במהלך השימוש.
מחקרים מצביעים על כך שאידוי הוא פתרון טוב יותר, עם פחות חשיפה לרעלנים.
בנוסף, בשל חוסר בעירה, ההארומות ההמקוריים מוגנים, מה שמוסיף לחווית הטעם והסיפוק הצריכה.
קלות שימוש ואחזקה
מכשירי הוופ מיוצרים מתוך גישה של נוחות הפעלה – הם מתאימים הן למתחילים והן לחובבי מקצוע.
מרבית המוצרים פועלים בהפעלה פשוטה, והתכנון כולל חילופיות של חלקים (כמו מיכלים או גביעים) שמפשטים על התחזוקה והאחזקה.
הדבר הזה מגדילה את אורך החיים של המוצר ומבטיחה ביצועים תקינים לאורך זמן.
סוגים שונים של עטי אידוי – מותאם לצרכים
המגוון בעטי אידוי מאפשר לכל משתמש לבחור את המוצר האידיאלי עבורו:
מכשירים לקנאביס טבעי
מי שמעוניין ב חווית אידוי טבעית, רחוקה ממעבדות – ייבחר מכשיר לפרחי קנאביס.
המכשירים הללו מיועדים לשימוש בפרחים טחונים, תוך שמירה מלאה על הריח והטעימות הטבעיים של הקנאביס.
עטי אידוי לשמנים ותמציות
לצרכנים שרוצים אידוי עוצמתי ומלא בחומרים פעילים כמו THC וCBD – קיימים מכשירים המיועדים במיוחד לשמנים ותרכיזים.
המוצרים האלה מתוכננים לשימוש בחומרים צפופים, תוך שימוש בטכנולוגיות מתקדמות כדי לייצר אידוי עקבי, נעים ועשיר.
—
מסקנות
מכשירי וופ אינם רק אמצעי נוסף לצריכה בקנאביס – הם דוגמה לרמת חיים גבוהה, לגמישות ולשימוש מותאם אישית.
בין היתרונות המרכזיים שלהם:
– עיצוב קטן ונוח לתנועה
– שליטה מדויקת בחום האידוי
– חווית אידוי נקייה ונטולת רעלים
– קלות שימוש
– הרבה אפשרויות של התאמה אישית
בין אם זו הפעם הראשונה בוופינג ובין אם אתם צרכן ותיק – עט אידוי הוא ההבחירה הטבעית לצריכה איכותית, מהנה ובטוחה.
—
הערות:
– השתמשתי בסוגריים מסולסלים כדי ליצור וריאציות טקסטואליות מגוונות.
– כל הגרסאות נשמעות טבעיות ומתאימות לעברית מדוברת.
– שמרתי על כל המושגים ספציפיים (כמו Vape Pen, THC, CBD) ללא שינוי.
– הוספתי סימני חלקים כדי לשפר את ההבנה והסדר של הטקסט.
הטקסט מתאים לקהל היעד בהשוק העברי ומשלב תוכן מכירתי עם מידע מקצועי.
Vapor Pen
AntiNarcoForum — это онлайн-форум, созданный для тех, кто столкнулся с проблемой алкоголизма или наркомании. Анонимность, индивидуальный подход к каждому пользователю и квалифицированная поддержка делают форум эффективным инструментом в борьбе с зависимостью.
Подробнее тут – [url=https://antinarcoforum.ru/reabilitaczionnye-czentry/otzyvy-byvshih-paczientov-kak-ponyat-chto-czentr-dejstvitelno-pomogaet/]рехаб отзывы пациентов реальные[/url]
окна на заказ [url=https://okna177.ru]окна на заказ[/url] .
Подробнее здесь http://retrocasino.io/
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Экстренная установка капельницы необходима, если пациент находится в состоянии запоя более 2–3 дней или испытывает симптомы тяжелой интоксикации алкоголем:
Выяснить больше – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя сочи[/url]
отзывы [url=https://niksolovov.ru/services/cluvio]https://niksolovov.ru/services/cluvio[/url] 2025
Как отмечает врач-нарколог клиники «РеабилитАльянс» Павел Сомов, «чем раньше начато лечение, тем выше шансы на скорейшее выздоровление без серьезных последствий для здоровья».
Разобраться лучше – https://narcolog-na-dom-krasnodar00.ru/
купить шторы Установка штор – это важный этап, который требует аккуратности и внимательности. Шторы тюль
Выезд врача-нарколога из клиники «ТрезвоПрофи» на дом происходит в любое время суток, включая выходные и праздники. Перед началом детоксикации врач проводит осмотр, измеряет давление, частоту пульса, уровень кислорода в крови и подбирает индивидуальную схему лечения. Сама процедура обычно занимает от 1 до 2 часов и проводится под строгим контролем врача.
Изучить вопрос глубже – [url=https://kapelnica-ot-zapoya-sochi00.ru/]капельница от запоя клиника в сочи[/url]
Insightful and interesting to read. Continue with the great work…
После процедуры пациент чувствует значительное облегчение состояния, улучшение самочувствия и снижение тяги к алкоголю.
Получить дополнительную информацию – https://kapelnica-ot-zapoya-sochi00.ru/kapelnicza-ot-zapoya-czena-sochi
Крайне рекомендую https://www.tocorp.ca/interior-design-trends/
Диагностика техники — бесплатно при ремонте.
Профессиональный ремонт вашей бытовой техники.
Кондиционер https://brand-climat.ru разные типы для охлаждения и обогрева. Профессиональная помощь в выборе, установка под ключ, сервисное обслуживание и гарантия. Создайте комфортный микроклимат круглый год!
AntiNarcoForum — анонимное сообщество помощи людям, страдающим от алкогольной, наркотической и игровой зависимости. На платформе доступны истории выздоровления, консультации специалистов, а также постоянная поддержка от людей, преодолевших схожие трудности.
Исследовать вопрос подробнее – [url=https://antinarcoforum.ru/alkogolizm/sovremennye-metody-lecheniya-alkogolizma-plyusy-i-minusy/]методы лечения алкоголизма[/url]
В данной статье мы акцентируем внимание на важности поддержки в процессе выздоровления. Мы обсудим, как друзья, семья и профессионалы могут помочь тем, кто сталкивается с зависимостями. Читатели получат практические советы, как поддерживать близких на пути к новой жизни.
Получить больше информации – https://koronavirus-ncov.ru/kompetentnaya-i-operativnaya-astnaya-skoraya-pomoshh-v-rostove-na-donu-nashi-opytnye-vrachi-garantiruyut-kachestvennye-mediczinskie-uslugi
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Получить больше информации – https://500.biz/2017/05/27/hello-world
окна пвх в москве [url=http://02stroika.ru]окна пвх в москве[/url] .
машина в аренду краснодар Аренда авто без залога: Доступное предложение для каждого. Начните свое путешествие без лишних затрат и хлопот.
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Получить дополнительные сведения – https://ecars.vn/chao-moi-nguoi
Дивлюсь на результати роботи [url=https://chtonamstoit.site/]експертів у будівництві[/url], і хочеться негайно з ними співпрацювати. Наступного разу точно звернуся до них.
https://bitapexca.com/
Get what fans are craving from [url=https://t.me/HannaPunzelOfficiall]hanna punzel pack[/url].
New hanna punzel desnuda videos added daily.
Best quality hanna punzel xvideos scenes.
Follow hanna punzel rule 34 content.
Don’t miss hanna punzel naked photos.
Most searched hanna punzel leaked content.
Best hanna punzel onlyfans leak source.
Join hanna punzel fans worldwide.
Натяжные потолки Малаховка Парящий потолок – это эффектное решение, которое создает иллюзию легкости и невесомости. Подсветка по периметру делает его центром внимания в любом помещении.
Этот обзорный материал предоставляет информационно насыщенные данные, касающиеся актуальных тем. Мы стремимся сделать информацию доступной и структурированной, чтобы читатели могли легко ориентироваться в наших выводах. Познайте новое с нашим обзором!
Получить дополнительную информацию – https://elcapi.com/dsc08084
окна пвх [url=http://www.okna177.ru]окна пвх[/url] .
Everything from [url=https://t.me/HannaPunzelOfficiall]hanna punzel poringa[/url] is here.
Top-rated hanna punzel onlyfans updates.
Join hanna punzel fans sharing her videos.
Daily updates from hanna punzel onlyfans.
Who is hanna punzel? Get full info.
Catch hanna punzel masturbating live.
Follow hanna punzel for juicy content.
Hanna punzel x is now trending online.
Наркологическая помощь «ТюменьМед» не ограничивается только физической детоксикацией. В состав команды входят психологи и социальные работники, которые проводят мотивационные беседы, обучают навыкам самоконтроля и оказывают помощь в планировании досуга и социальных активностей после детоксикации.
Получить дополнительную информацию – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологические клиники алкоголизм тюмень.[/url]
Украинский бизнес https://in-ukraine.biz.ua информацинный портал о бизнесе, финансах, налогах, своем деле в Украине
Ще не встиг скористатися послугами компанії [url=https://chtonamstoit.site/]надійних будівельників Києва[/url], але чую лише найкращі відгуки. Кажуть, що вони беруться за будь-які проекти та завжди вкладаються у терміни. Сподіваюся, і мій будинок стане їхнім шедевром!
Реально ли найти хороших строителей по адекватной цене? [url=https://about.chtonamstoit.site/]Этот застройщик[/url] предлагает интересные условия.
Here’s where fans watch [url=https://t.me/HannaPunzelOfficiall]hanna punzel sex videos[/url] first.
Follow hanna punzel for free uncensored leaks.
Join hanna punzel fans sharing her videos.
Free pack de hanna punzel today.
Find hanna punzel porno scenes easily.
Private hanna punzel videos revealed.
Hanna punzel nude scenes that go viral.
Join hanna punzel fans worldwide.
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Изучить вопрос глубже – http://narkologicheskaya-klinika-tyumen10.ru
Плей Фортуна — это штаб-квартира игровой миссии, где выигрыш — как захват цели. Интерфейс — это гаджет 007, и плей фортуна сегодня активирует миссию с призами. Ты в роли шпиона с шансом на выигрыш. Ты управляешь риском как агент.
Слоты — это программы-вирусы для выигрыша. Бонусы — как чемодан с валютой. Музыка — это ритмы тайных операций. Ты будто управляешь миссией. Результат зависит от твоей ловкости.
Поддержка — это дежурный в штаб-квартире, который откроет новые инструменты. Финансы — это анонимные транзакции. Play Fortuna — это игровая разведка нового уровня.
Watch what made [url=https://t.me/HannaPunzelOfficiall]hanna punzel only fans[/url] go viral.
Find all hanna punzel fapello packs fast.
Join hanna punzel fans sharing her videos.
Get all hanna punzel leaked nudes now.
Try hanna punzel onlyfans gratis today.
Catch hanna punzel masturbating live.
Hanna punzel nude scenes that go viral.
Watch hanna punzel por without limits.
аккаунты варфейс Аккаунт Warface – это ваш ключ к захватывающим сражениям, кооперативным миссиям и командной работе. Купить оружие Варфейс
В условиях современного ритма жизни алкоголизм нередко оборачивается тяжёлыми последствиями — от кратковременных запоев до хронической зависимости с серьёзными осложнениями. Наркологическая клиника «ТюменьМед» предлагает круглосуточную поддержку и выезд специалистов на дом в любое время суток, обеспечивая быстрое и безопасное восстановление здоровья. Использование инновационных методик, мобильных лабораторий и дистанционного контроля позволяет пациентам пройти детоксикацию и начать новый этап жизни в комфортных для них условиях.
Детальнее – [url=https://narkologicheskaya-klinika-tyumen10.ru/]частная наркологическая клиника тюмень.[/url]
You won’t believe what’s inside [url=https://t.me/HannaPunzelOfficiall]hanna punzel xxx telegram[/url].
Real hanna punzel sex clips you’ll love.
Save time with direct hanna punzel access.
Get all hanna punzel leaked nudes now.
Discover hanna punzel’s wildest content.
Private hanna punzel videos revealed.
The real hanna punzel onlyfans content.
Get private hanna punzel nude leaks.
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Получить дополнительную информацию – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма тюменская область[/url]
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Получить дополнительную информацию – https://narkologicheskaya-klinika-tyumen10.ru/
Лучшие онлайн-курсы https://topkursi.ru по востребованным направлениям: от маркетинга до программирования. Учитесь в удобное время, получайте сертификаты и прокачивайте навыки с нуля.
Школа Саморазвития https://bznaniy.ru онлайн-база знаний для тех, кто хочет понять себя, улучшить мышление, прокачать навыки и выйти на новый уровень жизни.
Аппаратные методы кодирования включают лазерную терапию и электростимуляцию биологически активных точек, влияющих на центры зависимости в головном мозге. Эти методики способствуют быстрому формированию устойчивого отвращения к спиртному и хорошо переносятся пациентами.
Углубиться в тему – https://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu
Hello!!
Our balanced feeding program for daycare centers offers nutritious meals and snacks to support healthy growth. A well-managed feeding program for daycare centers is vital for every child’s well-being. [url=https://happykidsdaycare.shop/]curriculum for daycare centers[/url]
Read the link – https://www.happykidsdaycare.shop/
daycare centers that accept vouchers
emergency preparedness for daycare centers
daycare center employee handbook
Good luck!
Good day!!
The Gospire lighted makeup mirror is known for its bright, natural-looking light and sleek design. Many users praise the Gospire lighted makeup mirror for its quality and performance. [url=https://lightedbeautymirrors.shop]magnifying makeup mirror[/url] Consider a Gospire lighted makeup mirror for a reliable and high-quality addition to your beauty tools.
Read the link – https://www.lightedbeautymirrors.shop/
countertop makeup mirror with lights
gospire lighted makeup mirror
freestanding makeup mirror with lights
Good luck!
1000 рублей за регистрацию вывод сразу без вложений в казино Казино “Адмирал” заманивает новичков щедрым предложением: 1000 рублей за регистрацию с моментальным выводом, не требующим каких-либо вложений. Это словно безвозмездный подарок, позволяющий сразу же окунуться в атмосферу азарта и, возможно, сорвать куш. 1000 рублей за регистрацию вывод сразу без вложений в казино
Ап Икс Казино — это портал в мир стихийных выигрышей, где выигрыш — как поток маны. Интерфейс — это зеркало стихий, и upx официальный сайт открывает врата к великому путешествию. Каждое вращение — как магический порыв. Каждая победа — как благословение стихий.
Слоты — это руны удачи. Бонусы — как монеты дриад. Музыка — это ритмы магического круга. Ты играешь — как странник миров. Азарт здесь — как ритуал богов.
Поддержка — это алхимик ответов, который шепчет подсказки. Финансы — это сундуки гномов. Ап Икс Казино — это легенда, которая живёт в игре.
https://cenforcebnr.com/# cenforce 200mg for sale
Каждая выездная бригада укомплектована портативным лабораторным оборудованием для экспресс-анализов крови и мочи, современными инфузионными насосами и средствами телеметрии. Это позволяет врачу контролировать жизненно важные параметры пациента в режиме реального времени и корректировать схему детоксикации на месте.
Детальнее – http://narkologicheskaya-klinika-tyumen10.ru
Врач индивидуально подбирает:
Получить дополнительные сведения – http://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/https://lechenie-alkogolizma-tyumen10.ru
Служба выезда «ТюменьМед» функционирует 24/7, что позволяет незамедлительно реагировать на срочные вызовы. В распоряжении клиники — собственный автопарк с санитарными машинами, оснащёнными всем необходимым для проведения инфузионной терапии на дому. При экстренном вызове врач прибывает к пациенту в пределах города в течение 30–60 минут.
Подробнее можно узнать тут – http://narkologicheskaya-klinika-tyumen10.ru
You’ll love the latest from [url=https://t.me/HannaPunzelOfficiall]hanna punzel +18[/url].
Top-rated hanna punzel onlyfans updates.
Explore hanna punzel erome clips easily.
Hanna punzel sin ropa never looked better.
Watch hanna punzel masturbandose anytime.
HD hanna punzel porn scenes updated.
All you need to know about hanna punzel.
Join hanna punzel fans worldwide.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Выяснить больше – https://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/
Аркада Казино — это тропический мир ставок, где удача — как зверь на пути. Интерфейс — это навигатор в чащобе, а зеркало аркада казино открывает проход в гущу. Каждое вращение — как всплеск водопада. Каждая победа — как тайный алтарь.
Слоты — это цветущие аппараты. Бонусы — как дождевые тайники. Музыка — это жужжание троп. Ты — как охотник за джекпотом. Азарт здесь — как выживание в мире ставок.
Поддержка — это проводник игроков, который не даёт заблудиться. Финансы — это сундук в храме, где всё обрабатывается точно. Аркада Казино — это эпопея джунглей и фриспинов.
Get private scenes via [url=https://t.me/HannaPunzelOfficiall]hanna punzel telegram xxx[/url].
Find all hanna punzel fapello packs fast.
Discover what’s trending about hanna punzel.
Follow hanna punzel rule 34 content.
Discover hanna punzel’s wildest content.
Fans can’t get enough of hanna punzel.
Best hanna punzel onlyfans leak source.
Hanna punzel x is now trending online.
Репетитор по физике https://repetitor-po-fizike-spb.ru СПб: школьникам и студентам, с нуля и для олимпиад. Четкие объяснения, практика, реальные результаты.
Looking for exclusive [url=https://t.me/HannaPunzelOfficiall]hanna punzel onlyfans[/url] content?
Find all hanna punzel fapello packs fast.
Stream hanna punzel azul xxx safely.
The best hanna punzel tits moments online.
All hanna punzel videos in one place.
Most searched hanna punzel leaked content.
Follow hanna punzel for juicy content.
Hanna punzel x is now trending online.
Наркологическая помощь «ТюменьМед» не ограничивается только физической детоксикацией. В состав команды входят психологи и социальные работники, которые проводят мотивационные беседы, обучают навыкам самоконтроля и оказывают помощь в планировании досуга и социальных активностей после детоксикации.
Изучить вопрос глубже – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника тюмень.[/url]
Покупка дипломов ВУЗов в Москве — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3364 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://poligraf2.ru/]Купить диплом о среднем образовании[/url] — ответим быстро, без лишних формальностей.
Покупка дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы даем гарантию, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 4640 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://poligraf1.ru/]Купить диплом Москва[/url] — ответим быстро, без лишних формальностей.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-tyumen10.ru/]klinika lecheniya alkogolizma tjumen'[/url]
Arkada Casino — это святилище фриспинов, где игра — как вызов титанам. Интерфейс — это меч Персея, а аркада казино сайт освещает путь к артефактам. Каждое вращение — как судьбоносный выбор. Каждая победа — как трофей Ахиллеса.
Слоты — это легендарные устройства. Бонусы — как сила Гермеса. Музыка — это звуки эфира. Ты — как воин судьбы. Азарт здесь — как приключение в эпохе богов.
Поддержка — это вестник богов, который освещает путь. Финансы — это сейф богов, где всё гарантировано Гефестом. Аркада Казино — это мифический путь выигрышей.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Подробнее – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма тюмень[/url]
Here’s a safe link to [url=https://t.me/HannaPunzelOfficiall]hanna punzel videos xxx[/url].
Find all hanna punzel fapello packs fast.
Join hanna punzel fans sharing her videos.
Daily updates from hanna punzel onlyfans.
Discover hanna punzel’s wildest content.
Start watching hanna punzel only now.
The real hanna punzel onlyfans content.
All hanna punzel content on one channel.
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Изучить вопрос глубже – https://kodirovanie-ot-alkogolizma-odintsovo2.ru
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение алкоголизма[/url]
New [url=https://t.me/HannaPunzelOfficiall]hanna punzel leaked nudes[/url] just dropped.
Find all hanna punzel fapello packs fast.
Save time with direct hanna punzel access.
Free pack de hanna punzel today.
Try hanna punzel onlyfans gratis today.
HD hanna punzel porn scenes updated.
Watch top hanna punzel leaked porn.
Get private hanna punzel nude leaks.
Arkada Casino — это лаборатория ставок, где удача — как башня успеха. Интерфейс — это панель управления мечтой, а казино аркада становится частью твоей цифровой экспедиции. Каждое вращение — как миг архитектурного взлёта. Каждая победа — как финал стройки.
Слоты — это архитектурные автоматы. Бонусы — как субсидии азарта. Музыка — это урбанистический бит. Ты — как градостроитель джекпота. Азарт здесь — как цифровой геймплей города.
Поддержка — это эксперт по фортуне, который ориентируется в любых запросах. Финансы — это цифровой кошелёк игрока, где всё прозрачно, мгновенно и удобно. Аркада Казино — это будущее развлечений.
Растворы для детоксикации
Узнать больше – [url=https://narcolog-na-dom-ekaterinburg00.ru/]запой нарколог на дом[/url]
В рамках реабилитации применяются когнитивно-поведенческие тренинги, арт-терапия и групповые занятия по развитию коммуникативных навыков. Это помогает пациентам осознать причины зависимости и выработать стратегии предотвращения рецидивов в будущем.
Исследовать вопрос подробнее – https://narkologicheskaya-klinika-tyumen10.ru/narkologicheskaya-klinika-klinika-pomoshh-tyumen
Don’t miss [url=https://t.me/HannaPunzelOfficiall]hanna punzel desnuda[/url] leaks.
Enjoy hanna punzel hot content online.
Find hanna punzel poringa leaks now.
Free pack de hanna punzel today.
Get the best of hanna punzel telegram xxx.
Private hanna punzel videos revealed.
Exclusive hanna punzel xxx telegram today.
Explore the hottest hanna punzel moments.
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Разобраться лучше – https://lechenie-alkogolizma-tyumen10.ru
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Исследовать вопрос подробнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма цены[/url]
Вызов нарколога на дом необходим в тех случаях, когда состояние человека требует срочного вмешательства врача, а самостоятельно обратиться в стационар нет возможности или желания. Такие ситуации включают сильную алкогольную интоксикацию, затяжные запои, выраженный похмельный синдром, психические расстройства, вызванные употреблением спиртного, и острый абстинентный синдром. Без своевременного лечения эти состояния могут привести к тяжелым осложнениям, таким как инфаркт, инсульт, белая горячка и тяжелое поражение печени. Поэтому при первых признаках ухудшения самочувствия лучше сразу обратиться за помощью к профессионалам.
Подробнее – [url=https://narcolog-na-dom-sochi00.ru/]запой нарколог на дом в сочи[/url]
Аркада Казино — это приключение на краю мира, где удача — как полярная звезда. Интерфейс — это компас на морозе, и новое казино аркада ведёт в неизведанные льды. Каждое вращение — как эхо льдов. Каждая победа — как полярная находка.
Слоты — это ледяные аппараты. Бонусы — как трофеи севера. Музыка — это ветер с севера. Ты — как капитан экспедиции. Азарт здесь — как ледяной драйв.
Поддержка — это тёплая палатка связи, который согревает заботой. Финансы — это запас провизии, где всё засчитывается с точностью экспедиции. Arkada Casino — это платформа храбрецов.
Watch the latest [url=https://t.me/HannaPunzelOfficiall]hanna punzel nude videos[/url] for free.
Real hanna punzel sex clips you’ll love.
Stream hanna punzel azul xxx safely.
Get all hanna punzel leaked nudes now.
Discover hanna punzel’s wildest content.
Private hanna punzel videos revealed.
Unveil hanna punzel onlyfans xxx.
Enjoy raw hanna punzel xxx content.
Наркологическое лечение на дому начинается с приезда врача в течение 30-60 минут после вызова. Специалист проводит первичную диагностику состояния пациента, включая измерение артериального давления, пульса и уровня кислорода в крови, а также общую оценку тяжести интоксикации. Затем врач подбирает оптимальный состав лекарств для детоксикационной капельницы, которая эффективно очищает организм от токсинов, восстанавливает водно-солевой баланс и нормализует работу внутренних органов.
Получить больше информации – http://narcolog-na-dom-sochi00.ru/vyzov-narkologa-na-dom-sochi/
Преимущество
Получить больше информации – https://narcolog-na-dom-ekaterinburg0.ru
Аркада Казино — это гемблинг-крепость в дюнах, где каждая ставка — как бросок священного камня. Интерфейс — это древний пергамент, и казино аркада вход направлением к джекпоту. Каждое вращение — как перекличка ветров. Каждая победа — как тайник с золотом.
Слоты — это стражи храма выигрышей. Бонусы — как золото султана. Музыка — это звуки восточной мистики. Ты — как жрец выигрыша. Азарт здесь — как откровение древних.
Поддержка — это служитель храма, который помогает как джинн. Финансы — это сундук арены, где всё приходит по зову удачи. Arkada Casino — это золотое приключение.
Каркасный дом под ключ с гарантией: комфортное жилье по доступной цене
дом каркасный под ключ [url=https://spb-karkasnye-doma-pod-kluch.ru/]https://spb-karkasnye-doma-pod-kluch.ru/[/url] .
Обращение к врачу становится жизненно необходимым, если пациент находится в состоянии длительного запоя, при котором организм не справляется с накоплением токсинов. Если запой продолжается более двух-трёх дней, в теле накапливаются вредные вещества, что ведёт к нарушениям работы внутренних органов, развитию абстинентного синдрома и появлению психических нарушений. Также, если у пациента наблюдаются симптомы, такие как частая рвота, спутанность сознания, судороги или резкие скачки артериального давления, это сигнал к незамедлительному вызову специалиста. При выраженной абстинентной реакции с паническими атаками, сильной дрожью, бессонницей и эмоциональной нестабильностью самостоятельное лечение может только усугубить ситуацию. Если появляются признаки алкогольного психоза – галлюцинации, агрессивность или спутанность сознания – вызов нарколога становится обязательным для предотвращения дальнейших осложнений. Также, когда требуется подготовка к процедурам кодирования от зависимости, необходима качественная детоксикация организма, что также является показанием к срочному обращению за профессиональной помощью.
Ознакомиться с деталями – https://narcolog-na-dom-ekaterinburg0.ru/narkolog-na-dom-czena-ekb/
В условиях современного ритма жизни алкоголизм нередко оборачивается тяжёлыми последствиями — от кратковременных запоев до хронической зависимости с серьёзными осложнениями. Наркологическая клиника «ТюменьМед» предлагает круглосуточную поддержку и выезд специалистов на дом в любое время суток, обеспечивая быстрое и безопасное восстановление здоровья. Использование инновационных методик, мобильных лабораторий и дистанционного контроля позволяет пациентам пройти детоксикацию и начать новый этап жизни в комфортных для них условиях.
Выяснить больше – [url=https://narkologicheskaya-klinika-tyumen10.ru/]наркологическая клиника цены в тюмени[/url]
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Выяснить больше – http://narcolog-na-dom-ekaterinburg00.ru/vrach-narkolog-na-dom-ekb/
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма[/url]
Основу терапии составляют современные методы детоксикации и восстановления функций организма. Клиника предлагает амбулаторные и стационарные программы, адаптированные под состояние пациента и пожелания семьи.
Получить дополнительную информацию – [url=https://lechenie-alkogolizma-tyumen10.ru/]лечение наркомании и алкоголизма тюмень[/url]
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Получить дополнительные сведения – https://narcolog-na-dom-ekaterinburg00.ru/zapoj-narkolog-na-dom-ekb
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Получить больше информации – https://lechenie-alkogolizma-tyumen10.ru
Мы предлагаем оформление дипломов ВУЗов по всей России и СНГ — с печатями, подписями, приложением и возможностью архивной записи (по запросу).
Документ максимально приближен к оригиналу и проходит визуальную проверку.
Мы гарантируем, что в случае проверки документа, подозрений не возникнет.
– Конфиденциально
– Доставка 3–7 дней
– Любая специальность
Уже более 3860 клиентов воспользовались услугой — теперь ваша очередь.
[url=http://poligraf2.ru/]Купить государственный диплом[/url] — ответим быстро, без лишних формальностей.
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Ознакомиться с деталями – https://gettrialsnow.com/services/abyssal-hook
Этот информационный материал привлекает внимание множеством интересных деталей и необычных ракурсов. Мы предлагаем уникальные взгляды на привычные вещи и рассматриваем вопросы, которые волнуют общество. Будьте в курсе актуальных тем и расширяйте свои знания!
Получить дополнительные сведения – http://jackandeloisekarpmemorialscholarship.com/jaekms
заказать пластиковые окна [url=www.02stroika.ru]заказать пластиковые окна[/url] .
New [url=https://t.me/HannaPunzelOfficiall]hanna punzel leaked nudes[/url] just dropped.
Enjoy hanna punzel hot content online.
Discover what’s trending about hanna punzel.
Follow hanna punzel rule 34 content.
Who is hanna punzel? Get full info.
Private hanna punzel videos revealed.
Unveil hanna punzel onlyfans xxx.
Join hanna punzel fans worldwide.
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Выяснить больше – https://entredecora.es/revista-nuevo-estilo-le-club-sushita
?Hola, fanaticos del entretenimiento !
casino por fuera accesible desde cualquier dispositivo – https://casinosonlinefueradeespanol.xyz/# п»їcasino fuera de espaГ±a
?Que disfrutes de asombrosas logros notables !
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Получить больше информации – https://contentengine.ai/showcase-esports/content-engine/overwatch/08/13/2019/overwatch-league-season-10-schedule-is-out
спины за регистрацию без депозита с выводом Бездепозитные бонусы – это как бесплатный билет в мир азарта, возможность испытать удачу, не рискуя собственными средствами. Они привлекают новичков, позволяя им освоиться в казино и попробовать различные игры, прежде чем делать депозит. Это своего рода тест-драйв, позволяющий оценить атмосферу и функциональность платформы. Бездепозитные бонусы в казино
Этот информационный обзор станет отличным путеводителем по актуальным темам, объединяющим важные факты и мнения экспертов. Мы исследуем ключевые идеи и представляем их в доступной форме для более глубокого понимания. Читайте, чтобы оставаться в курсе событий!
Подробнее – https://blog.mh4.jp/archives/115
окна на заказ [url=https://www.okna177.ru]окна на заказ[/url] .
Закажите печать на футболках с доставкой по всей России
футболка с принтом на заказ [url=https://pechat-na-futbolkah777.ru/]футболка с принтом на заказ[/url] .
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Ознакомиться с деталями – https://statuscaptions.com/what-are-heirloom-seeds-and-why-do-they-matter.html
Посетите наш сайт и узнайте о [url=https://uborka-chistota.ru/]клининговых услугах в санкт петербурге цены[/url]!
Клининговые услуги в Санкт-Петербурге набирают популярность. С каждым годом всё больше компаний предлагают широкий спектр услуг по уборке и обслуживанию помещений.
Пользователи услуг клининга отмечают высокое качество и удобство. Команды клининговых компаний зачастую предлагают персонализированный подход к каждому клиенту, учитывая его потребности.
Клининговые услуги включают в себя как регулярную уборку, так и разовые услуги
Eldorado Casino — это тропический оазис ставок, где каждая ставка — как ритуал у костра. Интерфейс — это племенной навигатор, а казино эльдорадо официальный сайт играть призывает дух удачи. Каждое вращение — как зов джунглей. Каждая победа — как дух в ритуале.
Слоты — это игровые артефакты. Бонусы — как амулеты удачи. Музыка — это гул леса. Ты — как охотник за выигрышем. Азарт здесь — как приключение в зелени.
Поддержка — это тотемный советник, который всегда подскажет. Финансы — это сундук племени, где всё срабатывает точно. Эльдорадо Казино — это дух леса.
В зависимости от состояния пациента, помощь может быть оказана в домашних условиях или в стационаре. Вызов нарколога на дом особенно актуален при абстинентном синдроме или тяжелом алкогольном опьянении. Как отмечается в материалах НМИЦ психиатрии и наркологии, в таких ситуациях крайне важно избежать самолечения и довериться врачам, способным правильно подобрать препараты и дозировки.
Получить больше информации – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]платная наркологическая помощь архангельск[/url]
https://ethereumcode-br.com/
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Получить дополнительную информацию – [url=https://lechenie-narkomanii-arkhangelsk0.ru/]наркологическое лечение наркомания в архангельске[/url]
займ без проверки ки [url=https://vc.ru/services/2060809-luchshie-mfo-2025-zajm-bez-proverki-kreditnoj-istorii-top-17] займ без проверки ки [/url].
Eldorado Casino — это племенная арена азарта, где каждая ставка — как ритуал у костра. Интерфейс — это экран ритуала, а эльдорадо казино официальный сайт проводит через заросли. Каждое вращение — как шум водопада. Каждая победа — как благословение шамана.
Слоты — это игровые артефакты. Бонусы — как племенные сокровища. Музыка — это гул леса. Ты — как шаман азарта. Азарт здесь — как приключение в зелени.
Поддержка — это проводник в игре, который знает тропу. Финансы — это кошель из листвы, где всё охраняется духами. Эльдорадо Казино — это дух леса.
Критерий
Изучить вопрос глубже – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]анонимная наркологическая помощь[/url]
Медикаментозное кодирование проводится с помощью препаратов, блокирующих ферменты, ответственные за расщепление этанола, что вызывает выраженное неприятие алкоголя при попытке его употребления. Препараты вводятся внутримышечно или с помощью подкожных имплантов и действуют в течение нескольких месяцев, обеспечивая длительный эффект.
Подробнее можно узнать тут – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма на дому[/url]
Первое, на что стоит обратить внимание — медицинский состав клиники. Опытные врачи-наркологи, психотерапевты, специалисты по аддиктологии и социальные работники составляют основу эффективной терапии. Их взаимодействие позволяет точно определить стадию зависимости, выявить сопутствующие психические или соматические заболевания и выстроить логичную схему лечения.
Углубиться в тему – http://narkologicheskaya-klinika-murmansk0.ru/narkologicheskaya-klinika-otzyvy-marmansk/
Драгон Мани казино — это турнир азарта, где каждая ставка — как удар по щиту. Интерфейс — это пульт арбитра, а драгон мани казино онлайн передаёт ход тебе. Каждое вращение — как парирование. Каждая победа — как подъём рук чемпиона.
Слоты — это боевые тренажёры. Бонусы — как трофеи боя. Музыка — это марши чемпионов. Ты — как герой арены. Азарт здесь — как вызов судьбе.
Поддержка — это тактик арены, который даёт советы в нужный момент. Финансы — это банковая арена, где всё работает без задержек. Dragon Money казино — это игра сильнейших.
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Получить больше информации – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/neotlozhnaya-narkologicheskaya-pomoshh-arkhangelsk/
Драгон Мани — это оазис удачи, где удача — как сказание мудреца. Интерфейс — это ковёр навигации, а dragon money регистрация пробуждает джинна азарта. Каждое вращение — как движение к мечте. Каждая победа — как восточная сказка.
Слоты — это сундуки с чудесами. Бонусы — как ароматы сокровищ. Музыка — это песнь ветров. Ты — как мастер фриспинов. Азарт здесь — как рассказ под звёздами.
Поддержка — это восточный советник, который отвечает с почтением. Финансы — это кошель мудреца, где всё движется по воле магии. Драгон Мани — это игра с ароматом мифа.
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Ознакомиться с деталями – http://narkologicheskaya-pomoshh-arkhangelsk0.ru
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Подробнее можно узнать тут – http://lechenie-narkomanii-arkhangelsk0.ru
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Получить дополнительные сведения – https://narkologicheskaya-pomoshh-arkhangelsk0.ru/vyzov-narkologicheskoj-pomoshhi-arkhangelsk
Лучшие онлайн-курсы https://topkursi.ru по востребованным направлениям: от маркетинга до программирования. Учитесь в удобное время, получайте сертификаты и прокачивайте навыки с нуля.
Якщо ви хочете дізнатися більше про DJ Gafur і його мікси, заходьте на [url=https://trance.djgafur.site/]. Це справжній майстер своєї справи.
Dragon Money — это неоновый мегаполис азарта, где спин — как активация цепи. Интерфейс — это панель управления, а драгон мани зеркало на сегодня открывает интерфейс вознаграждений. Каждое вращение — как импульс в сети. Каждая победа — как выход на главный сервер.
Слоты — это нейрослоты. Бонусы — как токены выигрыша. Музыка — это глитч-саунд. Ты — как пилот интерфейса. Азарт здесь — как мгновенный апдейт.
Поддержка — это кибер-оператор, который синхронизируется с игроком. Финансы — это платёжные токены, где всё хранится по протоколу. Dragon Money — это стратегия выигрыша.
Современные клиники предоставляют широкий спектр услуг, начиная с первичной консультации и заканчивая долгосрочной поддержкой после прохождения курса лечения. Ключевым этапом является детоксикация — процедура, направленная на выведение токсинов и стабилизацию физического состояния пациента.
Подробнее – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]скорая наркологическая помощь архангельск.[/url]
Резкое прекращение употребления алкоголя часто сопровождается выраженными симптомами абстиненции: тремор, тахикардия, повышенное давление, беспокойство. В клинике «Северная Звезда» для детоксикации применяется инфузионная терапия с балансированными растворами, содержащими:
Углубиться в тему – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]центр лечения алкоголизма[/url]
Резкое прекращение употребления алкоголя часто сопровождается выраженными симптомами абстиненции: тремор, тахикардия, повышенное давление, беспокойство. В клинике «Северная Звезда» для детоксикации применяется инфузионная терапия с балансированными растворами, содержащими:
Углубиться в тему – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]лечение алкоголизма архангельская область[/url]
Перед тем как перейти к описанию методов и стоимости, важно определить основные показания для кодирования. Ниже перечислены ключевые признаки, при наличии которых кодирование рекомендуется как этап комплексного лечения:
Подробнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma[/url]
На первом этапе пациент проходит лабораторные обследования (общий и биохимический анализ крови, ЭКГ, УЗИ печени и почек). На их основе разрабатывается схема инфузионной терапии, включающая корректировку водно-электролитного баланса, поддержку жизненно важных функций и назначение симптоматических препаратов для снятия абстинентного синдрома.
Узнать больше – [url=https://lechenie-narkomanii-arkhangelsk0.ru/]centr lecheniya narkomanii arhangel’sk[/url]
Hype Casino — это урбан-миф фриспинов, где игра — как уличный ритм. Интерфейс — это панель с баллончиками, а hype casino промокоды открывает вход в теги удачи. Каждое вращение — как марш свободы. Каждая победа — как звук свободы.
Слоты — это теги удачи. Бонусы — как уличные призраки. Музыка — это бас панелей. Ты — как игрок с тегом. Азарт здесь — как всплеск спрея.
Поддержка — это ассистент с баллоном, который не даёт пропасть. Финансы — это касса на площади, где всё переводится мгновенно. Хайп казино — это энергия панелей.
Первое, на что стоит обратить внимание — медицинский состав клиники. Опытные врачи-наркологи, психотерапевты, специалисты по аддиктологии и социальные работники составляют основу эффективной терапии. Их взаимодействие позволяет точно определить стадию зависимости, выявить сопутствующие психические или соматические заболевания и выстроить логичную схему лечения.
Углубиться в тему – https://narkologicheskaya-klinika-murmansk0.ru/
Перевод документов https://medicaltranslate.ru на немецкий язык для лечения за границей и с немецкого после лечения: высокая скорость, безупречность, 24/7
Понимание того, какие учреждения действительно способны помочь, позволяет избежать ошибок и не тратить время на неэффективные попытки лечения. Ключевыми признаками являются наличие медицинской лицензии, опытные специалисты, прозрачные условия и отзывы пациентов.
Детальнее – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]вызов наркологической помощи[/url]
Онлайн-тренинги https://communication-school.ru и курсы для личного роста, карьеры и новых навыков. Учитесь в удобное время из любой точки мира.
1С без сложностей https://1s-legko.ru объясняем простыми словами. Как работать в программах 1С, решать типовые задачи, настраивать учёт и избегать ошибок.
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Узнать больше – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма гипнозом[/url]
Хайп казино — это царство удачи и клыков, где спин — как рывок пантеры. Интерфейс — это логово слотов, а hype casino отзывы начинает охоту за выигрышем. Каждое вращение — как зов дикой природы. Каждая победа — как сигнал стаи.
Слоты — это звериные катушки. Бонусы — как запасы для зимовки. Музыка — это рык успеха. Ты — как игрок со звериным чутьём. Азарт здесь — как экспедиция по шансам.
Поддержка — это помощник охотника, который всегда рядом. Финансы — это сейф хищника, где всё движется как стая. Hype Casino — это вселенная животных шансов.
Чтобы обеспечить безопасное выведение психоактивных веществ и восстановление организма, применяется детоксикация под контролем врача-нарколога и анестезиолога-реаниматолога.
Подробнее тут – https://lechenie-narkomanii-arkhangelsk0.ru/czentr-lecheniya-narkomanii-arkhangelsk/
Автоматизированные насосы строго регулируют скорость введения препаратов. Такой подход снижает нагрузку на сердечно-сосудистую систему и минимизирует побочные эффекты.
Углубиться в тему – https://lechenie-alkogolizma-arkhangelsk0.ru/anonimnoe-lechenie-alkogolizma-arkhangelsk/
Таблица: На что обратить внимание при оценке персонала наркологической клиники
Получить больше информации – [url=https://narkologicheskaya-klinika-murmansk0.ru/]бесплатная наркологическая клиника[/url]
займы без звонков и проверок [url=https://vc.ru/dariazah/2060804-onlajn-zajmy-ot-novyh-mfo-top-17-s-minimalnymi-usloviyami-v-2025-godu] займы без звонков и проверок [/url].
Нередко пациенту требуется не только медикаментозная поддержка, но и психологическое сопровождение. Консультации с психотерапевтом позволяют выявить причины зависимости, снизить уровень тревожности и подготовить человека к реабилитации.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-arkhangelsk0.ru/]наркологическая клиника клиника помощь[/url]
На первом приёме нарколог собирает полную клиническую картину: продолжительность зависимости, количество и частоту приёмов спиртного, наличие соматических и психических осложнений. Одновременно выполняются лабораторные тесты: общий анализ крови, биохимия (показатели работы печени и почек), электролиты. При необходимости подключаются ЭКГ и УЗИ внутренних органов, чтобы выявить скрытые патологии, влияющие на выбор терапевтической схемы.
Получить дополнительную информацию – https://lechenie-alkogolizma-arkhangelsk0.ru/lechenie-narkomanii-i-alkogolizma-arkhangelsk/
Алкогольная зависимость — хроническое заболевание, требующее своевременного вмешательства специалистов. В условиях нашего города круглосуточная анонимная помощь позволяет начать лечение без откладываний и в привычной обстановке. Клиника «Северная Звезда» предлагает комплексный подход: вызов врача на дом или стационарное пребывание в условиях полной конфиденциальности. Профессиональная команда обеспечивает детоксикацию, психологическую реабилитацию и последующую поддержку, помогая пациенту сделать первый шаг к новой, свободной от алкоголя жизни.
Получить больше информации – [url=https://lechenie-alkogolizma-arkhangelsk0.ru/]центр лечения алкоголизма архангельск[/url]
Анонимность — один из ключевых принципов работы клиники «Северная Звезда». Все обращения регистрируются под кодовым номером, без упоминания фамилии и контактных данных в базе данных, доступ к которой имеют только прямые исполнители процедур. Круглосуточная линия позволяет связаться со специалистом в любой момент: ночью, в праздники или выходные. Вызов врача на дом возможен в любой час, без предварительной записи, а при необходимости пациент может быть госпитализирован в отдельное крыло клиники с минимальным контактом с другими посетителями.
Детальнее – http://
Наркомания — хроническое заболевание, требующее комплексного лечения и постоянной поддержки. В условиях Архангельска, где доступ к специализированной помощи может быть ограничен, клиника «АрктикМед» предлагает уникальную программу, основанную на мультидисциплинарном подходе и строгом соблюдении принципов анонимности. Ключевая цель — помочь каждому пациенту преодолеть зависимость, восстановить здоровье и вернуться к полноценной жизни.
Разобраться лучше – [url=https://lechenie-narkomanii-arkhangelsk0.ru/]лечение наркомании и алкоголизма в архангельске[/url]
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]клиника кодирования от алкоголизма[/url]
Hype Casino — это путь драконьих джекпотов, где каждая ставка — как удар меча. Интерфейс — это карта приключений, а хайп казино зеркало открывает врата турнира. Каждое вращение — как путешествие сквозь королевства. Каждая победа — как легенда в песне барда.
Слоты — это колёса фортуны. Бонусы — как трофеи за храбрость. Музыка — это звуки подземелий. Ты — как искатель клада. Азарт здесь — как турнир фриспинов.
Поддержка — это советник при дворе, который ведёт через все трудности. Финансы — это сундук фортун, где всё приходит по первому требованию. казино Хайп — это волшебная арена.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Процесс терапии в клинике построен по поэтапной схеме, включающей:
Исследовать вопрос подробнее – http://lechenie-alkogolizma-arkhangelsk0.ru/
Таблица: На что обратить внимание при оценке персонала наркологической клиники
Исследовать вопрос подробнее – [url=https://narkologicheskaya-klinika-murmansk0.ru/]бесплатная наркологическая клиника[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Ознакомиться с деталями – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]www.domen.ru[/url]
Дізнайтесь більше про спортивні рекорди, новини та цікаві факти у світі спорту на [url=https://veryuseful.website/]спортивному порталі[/url].
shipping from china to dubai Best Cargo Company in UAE: Evaluating Customer Service and Reliability
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Выяснить больше – https://kendrasmiley.com/cropped-042-jpg/?thc-month=201512
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу!
Ознакомиться с деталями – http://kendrasmiley.com/cropped-042-jpg
Lightweight tasks for people on this site https://easygrawvf52.com/
пионы москва Букет пионов с доставкой в Москве: Идеальный подарок для особых случаев. Букет пионов – это не просто цветы, это символ любви, нежности и восхищения. Мы создаем уникальные композиции, сочетая различные сорта и оттенки пионов, чтобы каждый букет был настоящим произведением искусства. Наши флористы – настоящие профессионалы своего дела, которые с любовью и вниманием подходят к каждому заказу. Доставка букета пионов в Москве – это идеальный способ выразить свои чувства и подарить незабываемые эмоции близкому человеку. Мы гарантируем, что ваш подарок будет оценен по достоинству и оставит самые теплые воспоминания.
Эта статья предлагает живое освещение актуальной темы с множеством интересных фактов. Мы рассмотрим ключевые моменты, которые делают данную тему важной и актуальной. Подготовьтесь к насыщенному путешествию по неизвестным аспектам и узнайте больше о значимых событиях.
Детальнее – http://kendrasmiley.com/cropped-042-jpg/?thc-month=202502
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Разобраться лучше – https://www.3jsmotorcycledays.com/?p=1
Відкривайте для себе нові можливості з добіркою онлайн-інструментів на [url=https://veryuseful.website/]сторінці корисних сервісів[/url].
Можно ещё добавить Наслаждайтесь играми без ограничений, используя прямые ссылки и облачные хранилища.
Хотів написати твір про героїв, а знайшов [url=https://ukrlib.ua/]захоплюючі матеріали[/url]. Сайт просто врятував мене перед дедлайном!
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Подробнее можно узнать тут – https://rpasminio.cl/?p=1118
Услуги архитектора и дизайнера интерьера при заказе деревянного дома под ключ
деревянный дом под ключ проекты и цены [url=http://derevyannye-doma-pod-klyuch-msk0.ru/]http://derevyannye-doma-pod-klyuch-msk0.ru/[/url] .
Hi, bro!
Birthday baloons add a festive touch to any celebration, making the occasion feel truly special. Whether you’re looking for classic latex or shiny foil, the right birthday baloons can transform a room. Choosing the perfect birthday baloons is an easy way to delight guests of all ages. [url=https://partyballoonsshop.shop/]birthday balloons king soopers[/url]
Read the link – https://www.partyballoonsshop.shop/
how many balloons for birthday party
personalized birthday balloons
birthday baloons
Good luck!
Hello!!
Many communities offer free gardening services for the elderly to help seniors maintain their gardens. Accessing free gardening services for the elderly can be a great way to ensure their outdoor spaces remain enjoyable and safe. [url=https://mygreengarden.shop/]kelly gardening services invercargill[/url] These programs rely on volunteers to provide essential free gardening services for the elderly.
Read the link – https://mygreengarden.shop
fencing and gardening services near me
small gardening services near me
free gardening services for the elderly
Good luck!
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Получить дополнительные сведения – https://statuscaptions.com/itchy-scalp-and-hair-loss-understanding-the-causes-and-solutions.html
Южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза: 3 сезон игры в кальмара смотреть. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях.
Лечение на дому проходит в комфортной и спокойной обстановке, что позволяет значительно снизить уровень стресса и быстро улучшить состояние здоровья пациента.
Подробнее можно узнать тут – [url=https://narcolog-na-dom-sochi0.ru/]врач нарколог на дом в сочи[/url]
Na stronie [url=https://bitqt-official.com/]bitqt official[/url] znajdziesz pełen dostęp do najważniejszych funkcji dla inwestorów kryptowalutowych. Prosty proces rozpoczęcia pracy.
Bitqt to innowacyjna platforma handlowa, dzięki której inwestorzy mogą uczestniczyć w handlu na rynkach finansowych. Bitqt wykorzystuje nowoczesne algorytmy do analizy rynków w czasie rzeczywistym, co daje użytkownikom możliwość dokonywania przemyślanych decyzji inwestycyjnych.
Platforma oferuje szereg narzędzi, które ułatwiają trading. Inwestorzy mogą zautomatyzować swoje transakcje, co przyczynia się do większych zysków. System jest intuicyjny i przyjazny dla użytkownika, co sprawia, że nawet początkujący mogą z niego korzystać.
Bezpieczeństwo użytkowników jest priorytetem dla Bitqt. Zastosowane w platformie technologie szyfrowania dają użytkownikom pewność, że ich dane są bezpieczne. To sprawia, że Bitqt jest zaufanym wyborem dla wielu inwestorów.
Podsumowując, Bitqt to świetne rozwiązanie dla osób zainteresowanych inwestowaniem w rynki finansowe. Z uwagi na nowoczesne narzędzia, bezpieczeństwo oraz łatwość obsługi, każdy ma szansę na rozpoczęcie inwestycji. Zainwestuj w przyszłość z Bitqt.
אחרי עצמך? – אולה נצמדה לשיערי ודחפה את פניה בבשר הרטוב הזה בזעם. החום, הטעם המלוח, הריח תתכוננו, טרנסקסואלים”, אמר המנהל לקאל הוא הבחין ביום הראשון שיש הרבה פיגליצים חמודים במפעל look at more info
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Исследовать вопрос подробнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma gipnozom[/url]
Точная информация о том, [url=https://genuborkachistota.ru/]сколько стоит клининг[/url], помогает сразу определиться с форматом услуг. Смета составляется индивидуально.
Клининг в Москве стал популярной услугой в последние годы. Многие жители столицы предпочитают нанимать профессиональные уборщики для поддержания порядка в своих квартирах и офисах.
Цены на клининг могут варьироваться в зависимости от специфики услуг. Цены на стандартную уборку квартиры в Москве колеблются от 1500 до 5000 рублей.
Также можно заказать дополнительные услуги, включая мойку окон и химчистку ковров. Добавление таких услуг может существенно повысить итоговую цену клининга.
Прежде чем остановиться на конкретной клининговой компании, будет полезно изучить предложения на рынке. Важно учитывать мнения клиентов и репутацию компании.
казино Vavada — это пальмовая гавань фриспинов, где ставка — как всплеск волн. Интерфейс — это гавань навигации, а вавада казино казино открывает сундуки удачи. как вихрь песка. Победа — как океанское золото.
Слоты — это ракушки удачи. Бонусы — это бризы выигрышей. Звуки — это ритмы острова. Игрок — как исследователь фриспинов. Азарт — как лагуна волнующих игр.
Поддержка — это бармен удачи, который не забудет про зонт. Финансы — это лагунный обменник, где всё обновляется в ритме прибоя. Vavada казино — это остров фриспинов.
Какой сегодня церковный праздник [url=https://inforigin.ru/]inforigin.ru[/url] .
Календарь стрижек [url=istoriamashin.ru]istoriamashin.ru[/url] .
Какой сегодня праздник [url=https://topoland.ru/]topoland.ru[/url] .
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Узнать больше – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя цена краснодар[/url]
1xслотс казино — это святилище фортуны, где спин — как магический танец. Интерфейс — это свиток предков, а 1x slots casino вписывается в круг. как шаг в неизвестное. Победа — как благословение древних.
Слоты — это магические реликвии. Бонусы — это энергетические капли. Звуки — это шаги по кругу. Игрок — как посвящённый. Азарт — как открытие портала.
Поддержка — это вестник удачи, который настраивает путь игрока. Финансы — это алтарь выплат, где всё передаётся без усилий. 1xSlots Casino — это обряд фортуны.
Can you recommend an unconventional online course for CBSE students in Standard 10, one that challenges their creative thinking and prepares them for a future in innovation?
Hope you don’t mind a quick tip about learning resources
Just recently I discovered a site https://tools.veryuseful.website/
They’ve collected:
– online libraries (like “Українська Література”),
– free courses via Prometheus,
– Duolingo for learning Ukrainian,
– information about schools and universities.
Perfect for self-education in Ukrainian.
Also found [url=https://tools.veryuseful.website/] an awesome Ukrainian learning platform[/url] — maybe worth checking!
Any other cool learning sites to recommend?
Для детоксикации и восстановления организма после запоя используются только сертифицированные лекарственные препараты с доказанной эффективностью и безопасностью:
Узнать больше – https://narcolog-na-dom-sochi0.ru/vyzov-narkologa-na-dom-sochi/
Клиника «Нарколог-Профи» предлагает круглосуточную помощь на дому в Екатеринбурге и Свердловской области. Наши опытные специалисты готовы оперативно приехать по вашему вызову и оказать экстренную медицинскую поддержку при алкогольной или наркотической зависимости. Мы проводим детоксикацию организма, купируем абстинентный синдром и стабилизируем состояние пациента, обеспечивая при этом полную конфиденциальность и комфорт в домашних условиях.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg00.ru/]выезд нарколога на дом[/url]
После получения вашего звонка команда клиники «Нарколог-Профи» оперативно выезжает на дом в Екатеринбурге. По прибытии врач проводит всестороннюю диагностику: измеряет артериальное давление, пульс, уровень кислорода в крови и собирает подробный анамнез. На основе этих данных формируется индивидуальный план лечения, включающий установку внутривенной капельницы с тщательно подобранными препаратами. В ходе процедуры осуществляется детоксикация организма, направленная на быстрое выведение токсинов и восстановление водно-электролитного баланса. Если необходимо, назначаются поддерживающие медикаменты для нормализации работы сердца, печени и нервной системы, а также седативные препараты для купирования симптомов абстинентного синдрома. Врач непрерывно контролирует состояние пациента и при необходимости корректирует схему лечения. По завершении процедуры специалист дает подробные рекомендации по дальнейшему восстановлению, режиму питания и методам профилактики повторных запоев.
Получить дополнительную информацию – [url=https://narcolog-na-dom-ekaterinburg00.ru/]нарколог на дом анонимно[/url]
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Получить больше информации – http://vyvod-iz-zapoya-krasnodar00.ru
Cross Stitch Pattern in PDF format https://cross-stitch-patterns-free-download.store/ a perfect choice for embroidery lovers! Unique designer chart available for instant download right after purchase.
Казино Гизбо — это оазис джекпотов, где каждый спин — как шаг по бархану. Интерфейс — это шёлковая палатка, а gizbo казино обозначен как тень под пальмой. Каждое вращение — как глоток воды. Победа — как золото среди барханов.
Слоты — это сундуки у шатра. Бонусы — это песчаные трофеи. Звуки — это звуки далеких костров. Игрок — как исследователь пустыни. Азарт — как зов караван-сарая.
Поддержка — это наставник маршрута, который ведёт к спасению. Финансы — это сосуды награды, где всё приходит с караваном. Gizbo казино — это азарт под звёздами.
Надёжная фурнитура https://furnitura-dla-okon.ru для пластиковых окон: всё для ремонта и комплектации. От ручек до многозапорных механизмов.
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-krasnodar00.ru/]вывод из запоя в стационаре[/url]
Фурнитура для ПВХ-окон http://kupit-furnituru-dla-okon.ru оптом и в розницу: европейские бренды, доступные цены, доставка по РФ.
вопрос юристу бесплатно бесплатная юридическая консультация online без регистрации
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Получить дополнительную информацию – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Казино GetX — это панорамный клуб выигрышей, где мечтают о джекпоте. Каждая сессия — это панорамный обзор шансов, и getx казино ведёт к следующему уровню. как движение вверх без остановки. Победа — это фонтан эмоций.
Слоты — это высотные модули удачи. Бонусы — как ключи от пентхауса. Игрок — как арендатор успеха. Азарт — как ночной полёт с шансом. Звуки — как электрический импульс успеха.
Поддержка — как оператор лифта, который готов ответить мгновенно. Финансы — как инвестиции в облаках, и всё работает как швейцарские часы. GetX Casino — это вертикальный успех.
Чем раньше нарколог окажет помощь, тем выше шансы избежать осложнений и восстановиться без последствий для здоровья.
Детальнее – [url=https://narcolog-na-dom-sochi0.ru/]vyzov-narkologa-na-dom sochi[/url]
При поступлении вызова специалисты клиники «ЗдоровьеНорм» выезжают на дом в течение 30–60 минут. Врач проводит тщательную диагностику, измеряя артериальное давление, пульс, уровень кислорода в крови и оценивая общее состояние пациента. После этого осуществляется индивидуальный подбор лечебной схемы, основанной на объективных данных и анамнезе пациента.
Изучить вопрос глубже – http://vyvod-iz-zapoya-krasnodar00.ru/
Мы понимаем, что каждая минута имеет решающее значение, поэтому наши специалисты готовы выехать на дом в кратчайшие сроки и провести все необходимые процедуры по детоксикации организма. Наша цель — помочь пациенту вернуться к нормальной жизни без лишних стрессов и рискованных попыток самостоятельного лечения.
Изучить вопрос глубже – https://vyvod-iz-zapoya-krasnodar00.ru
игра в кальмара 3 сезон – южнокорейский сериал о смертельных играх на выживание ради огромного денежного приза. Сотни отчаявшихся людей участвуют в детских играх, где проигрыш означает смерть. Сериал исследует темы социального неравенства, морального выбора и человеческой природы в экстремальных условиях.
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Детальнее – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/kodirovanie-ot-alkogolizma-na-domu/
Растворы для детоксикации
Изучить вопрос глубже – [url=https://narcolog-na-dom-ekaterinburg00.ru/]врач нарколог на дом свердловская область[/url]
{Money X Casino|Мани Икс Казино|Казино Money X|Казино Мани Икс|MoneyX Казино} — это {мир подземных сделок|казино с привкусом запретного|игровая зона для избранных|атмосфера гангстерского величия|платформа элитного риска}, где {ставки звучат как щелчок пальцев|игра происходит за закрытыми дверями|джекпот пахнет виски и сигарами|удача приходит в смокинге|каждое вращение — как сделка века}. {Слоты — как {картельные автоматы|мафиозные барабаны|секретные ячейки шанса|награды за лояльность|ящики удачи}}, и {money x|мани икс|мани х|мани икс казино|moneyx|money x казино|money x зеркало|money x регистрация|money x официальный сайт|moneyx casino|money x casino|казино мани икс|мани икс зеркало|мани икс регистрация|moneyx казино|money x войти|money x играть|money x вход|money x онлайн|money x рабочее зеркало на сегодня} {вставлен в контракт на успех|запускает вечеринку выигрышей|ведёт к сейфу с наградами|работает как ключ от клуба|начинает раунд личной удачи}. {Каждое вращение — как {тайный код|запах дорогого табака|ставка на доверие|награда с огоньком|отголосок вечеринки}}. {Выигрыш — это {купюры на бархате|трофей с гравировкой|контрабанда удачи|символ успеха|драгоценность фриспинов}.
{Игрок — как {босс преступной сети|глава стола|меценат ставок|теневой аристократ|джентльмен удачи}}. {Бонусы — это {подарки за молчание|доля от сделки|сюрприз с кодовым словом|пропуск на второй уровень|вознаграждение за верность}}. {Азарт — как {рукопожатие на грани|высокий градус вечеринки|тайна под столом|переговоры на джекпот|пауза перед выстрелом}}. {Звуки — это {щелчки фишек|басы подпольного клуба|щелчок затвора|цокот кубков|мурлыканье удачи}}. {Интерфейс — это {меню для избранных|золотая панель управления|кнопки с алмазами|тайные команды|дизайн для гангстера}}.
{Поддержка — как {личный помощник|секретарь босса|ассистент мафии|инкогнито-менеджер|представитель интересов}}, которая {всегда на линии|реагирует моментально|решает проблемы до их появления|принимает указания без вопросов|обеспечивает комфорт в игре}. {Финансы — это {тайник с деньгами|цифровой сейф|перевод с прикрытием|касса в портфеле|резерв босса}}, и всё {выплачивается без следа|оформляется с элегантностью|переводится без свидетелей|зачисляется как подарок|обновляется моментально}. {Money X Casino|Мани Икс Казино|Казино Money X|Казино Мани Икс|MoneyX Казино} — это {ночной клуб шанса|резиденция мафии и фриспинов|арена элитных ставок|казино для тех, кто в теме|вход туда, где деньги решают всё}.
Дополнительно, если у пациента отмечаются психические нарушения — галлюцинации, агрессия или спутанность сознания, это является прямым сигналом к срочному вмешательству. В этом случае своевременное лечение помогает предотвратить риск инсульта, инфаркта или других серьезных заболеваний.
Углубиться в тему – https://vyvod-iz-zapoya-krasnodar00.ru/
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Выяснить больше – http://narcolog-na-dom-ekaterinburg00.ru
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Получить дополнительные сведения – https://narcolog-na-dom-ekaterinburg00.ru/zapoj-narkolog-na-dom-ekb/
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Детальнее – https://narcolog-na-dom-ekaterinburg00.ru/narkolog-na-dom-czena-ekb
Длительный запой способен нанести непоправимый вред организму, привести к тяжелым нарушениям работы внутренних органов и поставить под угрозу жизнь пациента. В таких случаях необходимо срочное медицинское вмешательство, которое позволяет быстро стабилизировать состояние, вывести токсины и предотвратить развитие опасных осложнений. Клиника «ЗдоровьеНорм» в Краснодаре предлагает профессиональный вывод из запоя на дому, обеспечивая комплексное лечение с максимальной оперативностью и полной конфиденциальностью.
Ознакомиться с деталями – http://vyvod-iz-zapoya-krasnodar00.ru
Лечение на дому проходит в комфортной и спокойной обстановке, что позволяет значительно снизить уровень стресса и быстро улучшить состояние здоровья пациента.
Выяснить больше – [url=https://narcolog-na-dom-sochi0.ru/]нарколог на дом недорого в сочи[/url]
Обращение за медицинской помощью становится необходимым, когда пациент пребывает в состоянии, требующем немедленного вмешательства, так как самостоятельное лечение может только усугубить ситуацию. Это происходит, если запой продолжается несколько дней, и организм не успевает справляться с накопившимися токсинами, что ведёт к нарушению работы внутренних органов. Если у пациента регулярно наблюдаются симптомы, такие как частая рвота, сильное головокружение, спутанность сознания, судороги или резкие колебания артериального давления, это является явным сигналом к вызову специалиста. Особенно важно обращаться за помощью при выраженных признаках абстинентного синдрома, когда сильная дрожь, панические атаки, бессонница, тревожность и даже галлюцинации свидетельствуют о том, что организм испытывает критическую нехватку поддержки. Наличие психических нарушений, таких как агрессивное поведение, спутанность сознания или признаки алкогольного психоза, также требует незамедлительного вмешательства. В таких ситуациях обращение за профессиональной помощью помогает быстро стабилизировать состояние пациента, предотвратить развитие тяжелых осложнений и сохранить жизнь.
Подробнее – [url=https://narcolog-na-dom-ekaterinburg00.ru/]вызов нарколога на дом екатеринбург.[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Ознакомиться с деталями – http://kodirovanie-ot-alkogolizma-odintsovo2.ru/
Магнитные бури [url=www.inforigin.ru/]www.inforigin.ru/[/url] .
Не знаєш, з чого почати готуватись до НМТ? Раджу [url=https://learning.justtips.online/]посібник з української літератури[/url], там усе по поличках!
В этой публикации мы сосредоточимся на интересных аспектах одной из самых актуальных тем современности. Совмещая факты и мнения экспертов, мы создадим полное представление о предмете, которое будет полезно как новичкам, так и тем, кто глубоко изучает вопрос.
Получить больше информации – https://kisem.org/locations/indian-institute-of-technology-gandhinagar
Гороскоп [url=http://topoland.ru]http://topoland.ru[/url] .
Запреты дня [url=https://istoriamashin.ru/]istoriamashin.ru[/url] .
Эта статья полна интересного контента, который побудит вас исследовать новые горизонты. Мы собрали полезные факты и удивительные истории, которые обогащают ваше понимание темы. Читайте, погружайтесь в детали и наслаждайтесь процессом изучения!
Получить больше информации – https://pcnft.cibunet.com/cibuvideo/seo-%D0%BF%D1%80%D0%BE%D0%B4%D0%B2%D0%B8%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5-%D1%81%D0%B0%D0%B9%D1%82%D0%BE%D0%B2-%D0%B2-google
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Узнать больше – https://abiem.eu/2001gada-septembra-terorakta-laika-sis-pilots-veica-zinojumju/79680
Этот информативный материал предлагает содержательную информацию по множеству задач и вопросов. Мы призываем вас исследовать различные идеи и факты, обобщая их для более глубокого понимания. Наша цель — сделать обучение доступным и увлекательным.
Получить больше информации – https://www.lffix.dk/boost-your-online-presence-our-top-digital-marketing
Thanks for the article. Here’s more on the topic https://fotonons.ru/
Hello!!
If you’re looking for another word for event planner, terms like “event coordinator,” “meeting planner,” or “event producer” are often used. Knowing another word for event planner can be useful when searching for jobs or describing your services. [url=https://proeventmakers.shop/]event planner flyer ideas[/url]
Read the link – https://www.proeventmakers.shop/
birthday event planner near me
event planner for celebration of life
corporate event planner jobs
Good luck!
Good day!!
A financial services examiner trainee learns how to assess the safety and soundness of financial institutions. The role of a financial services examiner trainee is critical for maintaining the integrity of the banking system. [url=https://www.smartmoneysolutions.shop]infinite beacon financial services[/url] This position involves on-the-job training and a clear path to becoming a certified examiner.
Read the link – https://www.smartmoneysolutions.shop
financial services
discover financial services customer service
financial services entry level jobs
Good luck!
Thanks for the article. Here’s more on the topic https://artcet.ru/
על אנה, היא נראית מותשת. אבל ראיתי אותה הולכת עם הכוח לקום. ניגשתי והרמתי אותה שוב אפילו לא ירדה מהכומר. ואז ירדה ממנו וכרעה לפניו, התחילה למצוץ. – היי, אני כבר … כלבה קריות סקס
ההבלים של איש האמנות. מדוע שלחנו את הסרטון לא אליך, אלא לאהובך? ובכן, חשבנו שאולי אתה ואשתו הלילה עטופה בשמיכה חמה. הרגשתי שזה הדייט המוצלח הראשון שלנו, ועכשיו יהיה הלילה הראשון ביחד escort girls in israel
Оперативный [url=https://uborka12.ru/]клининг в Питере[/url] с профессиональной химией и современной техникой. Ваше помещение будет сиять чистотой.
Клининг в Санкт-Петербурге становится всё более популярным. Существует множество фирм, предоставляющих разнообразные клининговые услуги. Уборка квартир, офисов и общественных мест – это основные направления клининговых услуг.
Услуги клининговых компаний востребованы в основном из-за экономии времени. Благодаря этому они могут сосредоточиться на более важных делах. Клиенты ценят клининг за возможность делегировать рутинные задачи.
Одна из основных причин популярности клининговых компаний – это профессионализм. Специалисты клининговых компаний знают, как правильно применять современное оборудование и моющие средства. Эффективное использование техники дает возможность достигать быстрого и качественного результата.
Существуют разные пакеты услуг, которые подойдут под любые нужды. Некоторые клининговые фирмы предоставляют услуги по разовой уборке, тогда как другие предлагают долгосрочные контракты. Это позволяет выбрать наиболее подходящее предложение каждому клиенту.
Недавно на уроке литературы нам задали подготовить реферат о Лесе Украинке, её жизни и творчестве. Это было для меня настоящим вызовом, пока я не нашёл [url=http://ua-lib.ru/referats/]литературный раздел[/url], где была подборка рефератов на эту тему. В одном из них я нашёл не только информацию о её произведениях, но и интересные факты из её биографии, которые редко упоминаются. Эти материалы помогли мне создать работу, которую учитель похвалил как одну из самых информативных в классе. Теперь я часто использую этот сайт для подготовки к заданиям, и он ещё ни разу меня не подвёл.
В нашей клинике применяются различные техники кодирования, которые подбираются с учётом медицинских показаний, психологического состояния и пожеланий пациента.
Исследовать вопрос подробнее – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]www.domen.ru[/url]
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Ознакомиться с деталями – [url=https://lechenie-alkogolizma-tyumen10.ru/]клиника лечения алкоголизма тюмень[/url]
Thanks for the article. Here’s more on the topic https://yarus-kkt.ru/
Рекомендую сайт [url=https://ua-lib.ru/]Бібліотека[/url] для тих, хто цікавиться літературою!
Индивидуальный план включает детоксикацию, медикаментозную поддержку, психотерапию и реабилитацию. Специалисты учитывают:
Разобраться лучше – [url=https://lechenie-alkogolizma-tyumen10.ru/]анонимное лечение алкоголизма в тюмени[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Получить дополнительные сведения – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]kodirovanie ot alkogolizma gipnozom[/url]
металлические значки москва производство металлических значков
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Разобраться лучше – [url=https://lechenie-alkogolizma-tyumen10.ru/]клиника лечения алкоголизма[/url]
עכבר. מוזיקה שקטה-אקורדים לפסנתר רפויים מעורבבים עם שירה נשית צרודה-עטפה את החדר, ויצרה אשתי. אני נישקתי את רגליה בצייתנות באותו רגע… שוב, מישה נזקקה לזמן לנוח. בזמן שהוא שכב על דירות דיסקרטיות בראשון לציון
Перед началом терапии врач собирает анамнез, оценивает состояние органов-мишеней (печень, почки, сердце), проводит лабораторные тесты на уровень электролитов и маркёры цирроза. Результаты обследования играют ключевую роль при выборе схемы инфузий и психотерапевтических методик.
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-tyumen10.ru/]www.domen.ru[/url]
Кодирование создаёт стойкое отвращение к этилированному спирту за счёт фармакологического или психотерапевтического воздействия, а дальнейшая работа с психологом помогает сформировать новую модель поведения и мотивацию к сохранению трезвости. Современные технологии в сочетании с индивидуальным подходом делают процедуру безопасной и максимально комфортной для пациента.
Углубиться в тему – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]клиника кодирования от алкоголизма[/url]
Врач индивидуально подбирает:
Изучить вопрос глубже – https://lechenie-alkogolizma-tyumen10.ru/anonimnoe-lechenie-alkogolizma-tyumen
Основу терапии составляют современные методы детоксикации и восстановления функций организма. Клиника предлагает амбулаторные и стационарные программы, адаптированные под состояние пациента и пожелания семьи.
Получить дополнительные сведения – [url=https://lechenie-alkogolizma-tyumen10.ru/]анонимное лечение алкоголизма[/url]
Своевременное обращение к специалисту позволяет избежать опасных осложнений и облегчить процесс восстановления организма. Экстренный вызов врача-нарколога необходим в следующих случаях:
Подробнее – [url=https://narcolog-na-dom-krasnodar00.ru/]вызов врача нарколога на дом[/url]
יותר. אתה לא רוצה שאשתך תיראה בדלי כזה. הוא אמין, נראה בסדר, ואין צורך לשלם עבורו, השיבו למטבח, אנשים טרנסג ‘ נדרים עמדו שם ושתו מים, עירומים לחלוטין. הייתי מבולבלת, קפואה בהפתעה. זונה מבוגרת ומה אפשר ללמוד ממנה
Погрузитесь в профессию на [url=https://kursi-barbera-s-nulya.ru/]барбершоп обучение Красноярск[/url] — освоите модные стрижки и бритьё. Индивидуальный подход гарантирован.
Запись на курсы барбера набирает популярность среди молодежи. Количество школ, обучающих барберов, постоянно растет. Спрос на услуги профессии барбера способствует увеличению числа обучающих программ.
Курсы охватывают как техники стрижки, так и важные аспекты общения с клиентами. Студенты обучаются всем необходимым навыкам для успешного старта в профессии. Курсы предлагают изучение разнообразных техник стрижки, ухода за волосами и бородой.
По завершению обучения, всем выпускникам предоставляется шанс найти работу в салонах или открыть свою барберскую студию. Слава и расположение учебных заведений способны повлиять на выбор курсов. Необходи?мо внимательно изучить отзывы о курсах, прежде чем принять решение о записи.
В конечном счете, выбор курса зависит от ваших целей и желаемых результатов. С увеличением конкуренции на рынке, приобретение качественного образования становится важным фактором. Необходимо учитывать, что достижения в этой профессии требуют непрерывного образования и практического опыта.
«Кодирование — это не магическое решение, а важный этап в комплексной программе лечения, — поясняет ведущий нарколог клиники «Ясное Будущее» Марина Иванова. — Главное — сочетание фармакологического воздействия и последующей работы с психологом для формирования устойчивой мотивации к трезвости».
Получить дополнительную информацию – [url=https://kodirovanie-ot-alkogolizma-odintsovo2.ru/]кодирование от алкоголизма[/url]
бездепозитный бонус в онлайн казино Многие игроки ищут именно такие бонусы, которые позволяют сразу вывести выигранные деньги, не вкладывая свои. Но стоит помнить о лимитах и правилах казино.
В условиях стационара или на дневном стационаре применяются сбалансированные инфузионные растворы, витамины, антиоксиданты и препараты для поддержки печени. Цель — минимизировать интоксикацию и предотвратить осложнения.
Ознакомиться с деталями – http://lechenie-alkogolizma-tyumen10.ru/klinika-lecheniya-alkogolizma-tyumen/